No cenário atual de interações individuais com os clientes para fazer pedidos, a prática predominante continua a depender de atendentes humanos, mesmo em ambientes como cafeterias drive-thru e estabelecimentos de fast-food. Esta abordagem tradicional apresenta vários desafios: depende fortemente de processos manuais, luta para escalar de forma eficiente com as crescentes demandas dos clientes, introduz o potencial para erros humanos e opera dentro de horas específicas de disponibilidade. Além disso, em mercados competitivos, as empresas que aderem apenas a processos manuais podem ter dificuldade em fornecer serviços eficientes e competitivos. Apesar dos avanços tecnológicos, o modelo centrado no ser humano permanece profundamente enraizado no processamento de pedidos, levando a estas limitações.
A perspectiva de utilizar tecnologia para assistência individual no processamento de pedidos já está disponível há algum tempo. No entanto, as soluções existentes podem muitas vezes enquadrar-se em duas categorias: sistemas baseados em regras que exigem tempo e esforço substanciais para configuração e manutenção, ou sistemas rígidos que carecem da flexibilidade necessária para interações humanas com os clientes. Como resultado, as empresas e organizações enfrentam desafios na implementação rápida e eficiente de tais soluções. Felizmente, com o advento IA generativa e modelos de linguagem grande (LLMs), agora é possível criar sistemas automatizados que possam lidar com a linguagem natural de forma eficiente e com um cronograma de aceleração acelerado.
Rocha Amazônica é um serviço totalmente gerenciado que oferece uma escolha de modelos básicos (FMs) de alto desempenho de empresas líderes de IA como AI21 Labs, Anthropic, Cohere, Meta, Stability AI e Amazon por meio de uma única API, juntamente com um amplo conjunto de recursos que você pode usar. necessidade de construir aplicações generativas de IA com segurança, privacidade e IA responsável. Além do Amazon Bedrock, você pode usar outros serviços AWS como JumpStart do Amazon SageMaker e Amazon-Lex para criar agentes de processamento de pedidos de IA generativos totalmente automatizados e facilmente adaptáveis.
Nesta postagem, mostramos como criar um agente de processamento de pedidos com capacidade de fala usando Amazon Lex, Amazon Bedrock e AWS Lambda.
Visão geral da solução
O diagrama a seguir ilustra nossa arquitetura de solução.
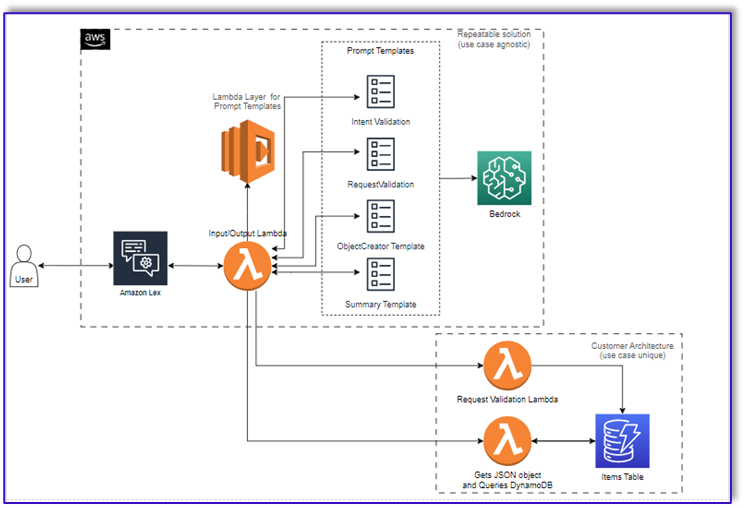
O fluxo de trabalho consiste nas seguintes etapas:
- Um cliente faz o pedido usando o Amazon Lex.
- O bot do Amazon Lex interpreta as intenções do cliente e aciona um
DialogCodeHook.
- Uma função Lambda extrai o modelo de prompt apropriado da camada Lambda e formata os prompts do modelo adicionando a entrada do cliente no modelo de prompt associado.
- A
RequestValidation O prompt verifica o pedido com o item de menu e informa ao cliente, por meio do Amazon Lex, se há algo que ele deseja pedir que não faz parte do menu e fornecerá recomendações. O prompt também realiza uma validação preliminar da conclusão do pedido.
- A
ObjectCreator prompt converte as solicitações de linguagem natural em uma estrutura de dados (formato JSON).
- A função Lambda validadora do cliente verifica os atributos necessários para o pedido e confirma se todas as informações necessárias estão presentes para processar o pedido.
- Uma função Lambda do cliente usa a estrutura de dados como entrada para processar o pedido e passa o total do pedido de volta para a função Lambda de orquestração.
- A função de orquestração do Lambda chama o endpoint do Amazon Bedrock LLM para gerar um resumo final do pedido, incluindo o total do pedido do sistema de banco de dados do cliente (por exemplo, Amazon DynamoDB).
- O resumo do pedido é comunicado ao cliente por meio do Amazon Lex. Após o cliente confirmar o pedido, o pedido será processado.
Pré-requisitos
Esta postagem pressupõe que você tenha uma conta AWS ativa e familiaridade com os seguintes conceitos e serviços:
Além disso, para acessar o Amazon Bedrock a partir das funções do Lambda, você precisa garantir que o tempo de execução do Lambda tenha as seguintes bibliotecas:
- boto3>=1.28.57
- awscli>=1.29.57
- botocore>=1.31.57
Isso pode ser feito com um camada lambda ou usando uma AMI específica com as bibliotecas necessárias.
Além disso, essas bibliotecas são necessárias ao chamar a API Amazon Bedrock de Estúdio Amazon SageMaker. Isso pode ser feito executando uma célula com o seguinte código:
%pip install --no-build-isolation --force-reinstall
"boto3>=1.28.57"
"awscli>=1.29.57"
"botocore>=1.31.57"
Por fim, você cria a seguinte política e posteriormente a anexa a qualquer função que acessa o Amazon Bedrock:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": "bedrock:*",
"Resource": "*"
}
]
}
Crie uma tabela DynamoDB
Em nosso cenário específico, criamos uma tabela DynamoDB como nosso sistema de banco de dados de clientes, mas você também pode usar Serviço de banco de dados relacional da Amazon (Amazon RDS). Conclua as etapas a seguir para provisionar sua tabela do DynamoDB (ou personalize as configurações conforme necessário para seu caso de uso):
- No console do DynamoDB, escolha Tabelas no painel de navegação.
- Escolha Criar tabela.
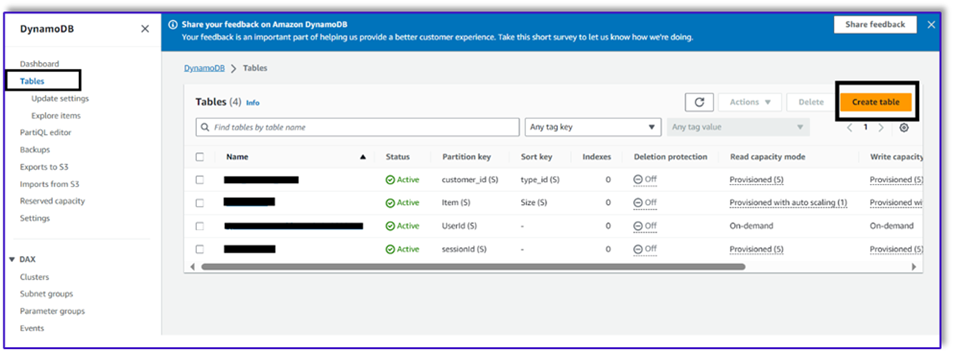
- Escolha Nome da mesa, insira um nome (por exemplo,
ItemDetails).
- Escolha Chave de partição, insira uma chave (para esta postagem, usamos
Item).
- Escolha Chave de classificação, insira uma chave (para esta postagem, usamos
Size).
- Escolha Criar tabela.

Agora você pode carregar os dados na tabela do DynamoDB. Para esta postagem, usamos um arquivo CSV. Você pode carregar os dados na tabela DynamoDB usando código Python em um notebook SageMaker.
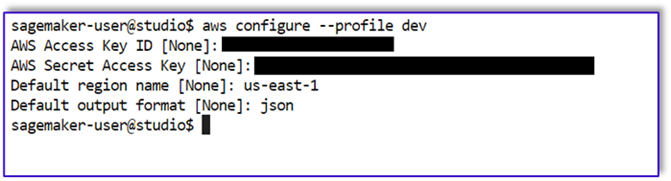
Primeiro, precisamos configurar um perfil chamado dev.
- Abra um novo terminal no SageMaker Studio e execute o seguinte comando:
aws configure --profile dev
Este comando solicitará que você insira o ID da chave de acesso da AWS, a chave de acesso secreta, a região padrão da AWS e o formato de saída.
- Retorne ao notebook SageMaker e escreva um código Python para configurar uma conexão com o DynamoDB usando a biblioteca Boto3 em Python. Este snippet de código cria uma sessão usando um perfil específico da AWS chamado dev e, em seguida, cria um cliente DynamoDB usando essa sessão. A seguir está o exemplo de código para carregar os dados:
%pip install boto3
import boto3
import csv
# Create a session using a profile named 'dev'
session = boto3.Session(profile_name='dev')
# Create a DynamoDB resource using the session
dynamodb = session.resource('dynamodb')
# Specify your DynamoDB table name
table_name = 'your_table_name'
table = dynamodb.Table(table_name)
# Specify the path to your CSV file
csv_file_path = 'path/to/your/file.csv'
# Read CSV file and put items into DynamoDB
with open(csv_file_path, 'r', encoding='utf-8-sig') as csvfile:
csvreader = csv.reader(csvfile)
# Skip the header row
next(csvreader, None)
for row in csvreader:
# Extract values from the CSV row
item = {
'Item': row[0], # Adjust the index based on your CSV structure
'Size': row[1],
'Price': row[2]
}
# Put item into DynamoDB
response = table.put_item(Item=item)
print(f"Item added: {response}")
print(f"CSV data has been loaded into the DynamoDB table: {table_name}")
Alternativamente, você pode usar Bancada de trabalho NoSQL ou outras ferramentas para carregar rapidamente os dados em sua tabela do DynamoDB.
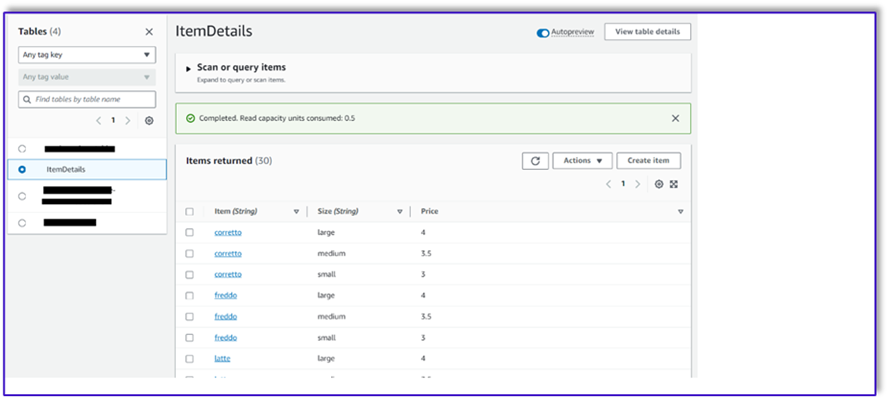
A seguir está uma captura de tela após os dados de amostra serem inseridos na tabela.
Crie modelos em um notebook SageMaker usando a API de invocação do Amazon Bedrock
Para criar nosso modelo de prompt para este caso de uso, usamos Amazon Bedrock. Você pode acessar o Amazon Bedrock no Console de gerenciamento da AWS e por meio de invocações de API. Em nosso caso, acessamos o Amazon Bedrock via API a partir da conveniência de um notebook SageMaker Studio para criar não apenas nosso modelo de prompt, mas nosso código completo de invocação de API que podemos usar posteriormente em nossa função Lambda.
- No console do SageMaker, acesse um domínio existente do SageMaker Studio ou crie um novo para acessar o Amazon Bedrock a partir de um notebook SageMaker.

- Depois de criar o domínio e o usuário do SageMaker, escolha o usuário e escolha Apresentação livro e Studio. Isso abrirá um ambiente JupyterLab.
- Quando o ambiente JupyterLab estiver pronto, abra um novo notebook e comece a importar as bibliotecas necessárias.
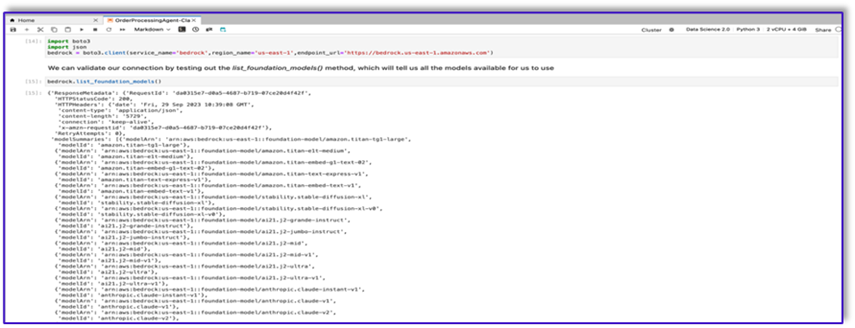
Existem muitos FMs disponíveis por meio do Amazon Bedrock Python SDK. Neste caso, usamos Claude V2, um poderoso modelo fundamental desenvolvido pela Anthropic.
O agente de processamento de pedidos precisa de alguns modelos diferentes. Isso pode mudar dependendo do caso de uso, mas criamos um fluxo de trabalho geral que pode ser aplicado a diversas configurações. Para este caso de uso, o modelo Amazon Bedrock LLM realizará o seguinte:
- Valide a intenção do cliente
- Valide a solicitação
- Crie a estrutura de dados do pedido
- Passe um resumo do pedido ao cliente
- Para invocar o modelo, crie um objeto bedrock-runtime do Boto3.

#Model api request parameters
modelId = 'anthropic.claude-v2' # change this to use a different version from the model provider
accept = 'application/json'
contentType = 'application/json'
import boto3
import json
bedrock = boto3.client(service_name='bedrock-runtime')
Vamos começar trabalhando no modelo de prompt do validador de intent. Este é um processo iterativo, mas graças ao guia de engenharia de prompt da Anthropic, você pode criar rapidamente um prompt que pode realizar a tarefa.
- Crie o primeiro modelo de prompt junto com uma função utilitária que ajudará a preparar o corpo para as invocações da API.
A seguir está o código para prompt_template_intent_validator.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to identify the intent that the human wants to accomplish and respond appropriately. The valid intents are: Greeting,Place Order, Complain, Speak to Someone. Always put your response to the Human within the Response tags. Also add an XML tag to your output identifying the human intent.nHere are some examples:n<example><Conversation> H: hi there.nnA: Hi, how can I help you today?nnH: Yes. I would like a medium mocha please</Conversation>nnA:<intent>Place Order</intent><Response>nGot it.</Response></example>n<example><Conversation> H: hellonnA: Hi, how can I help you today?nnH: my coffee does not taste well can you please re-make it?</Conversation>nnA:<intent>Complain</intent><Response>nOh, I am sorry to hear that. Let me get someone to help you.</Response></example>n<example><Conversation> H: hinnA: Hi, how can I help you today?nnH: I would like to speak to someone else please</Conversation>nnA:<intent>Speak to Someone</intent><Response>nSure, let me get someone to help you.</Response></example>n<example><Conversation> H: howdynnA: Hi, how can I help you today?nnH:can I get a large americano with sugar and 2 mochas with no whipped cream</Conversation>nnA:<intent>Place Order</intent><Response>nSure thing! Please give me a moment.</Response></example>n<example><Conversation> H: hinn</Conversation>nnA:<intent>Greeting</intent><Response>nHi there, how can I help you today?</Response></example>n</instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 1, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"
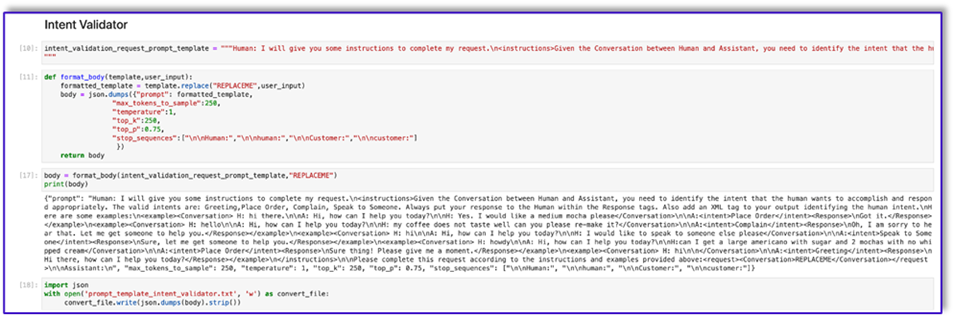

- Salve este modelo em um arquivo para fazer upload no Amazon S3 e chamar a partir da função Lambda quando necessário. Salve os modelos como strings serializadas JSON em um arquivo de texto. A captura de tela anterior mostra o exemplo de código para fazer isso também.
- Repita os mesmos passos com os outros modelos.
A seguir estão algumas capturas de tela dos outros modelos e os resultados ao chamar o Amazon Bedrock com alguns deles.
A seguir está o código para prompt_template_request_validator.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the context do the following steps: 1. verify that the items in the input are valid. If customer provided an invalid item, recommend replacing it with a valid one. 2. verify that the customer has provided all the information marked as required. If the customer missed a required information, ask the customer for that information. 3. When the order is complete, provide a summary of the order and ask for confirmation always using this phrase: 'is this correct?' 4. If the customer confirms the order, Do not ask for confirmation again, just say the phrase inside the brackets [Great, Give me a moment while I try to process your order]</instructions>n<context>nThe VALID MENU ITEMS are: [latte, frappe, mocha, espresso, cappuccino, romano, americano].nThe VALID OPTIONS are: [splenda, stevia, raw sugar, honey, whipped cream, sugar, oat milk, soy milk, regular milk, skimmed milk, whole milk, 2 percent milk, almond milk].nThe required information is: size. Size can be: small, medium, large.nHere are some examples: <example>H: I would like a medium latte with 1 Splenda and a small romano with no sugar please.nnA: <Validation>:nThe Human is ordering a medium latte with one splenda. Latte is a valid menu item and splenda is a valid option. The Human is also ordering a small romano with no sugar. Romano is a valid menu item.</Validation>n<Response>nOk, I got: nt-Medium Latte with 1 Splenda and.nt-Small Romano with no Sugar.nIs this correct?</Response>nnH: yep.nnA:n<Response>nGreat, Give me a moment while I try to process your order</example>nn<example>H: I would like a cappuccino and a mocha please.nnA: <Validation>:nThe Human is ordering a cappuccino and a mocha. Both are valid menu items. The Human did not provide the size for the cappuccino. The human did not provide the size for the mocha. I will ask the Human for the required missing information.</Validation>n<Response>nSure thing, but can you please let me know the size for the Cappuccino and the size for the Mocha? We have Small, Medium, or Large.</Response></example>nn<example>H: I would like a small cappuccino and a large lemonade please.nnA: <Validation>:nThe Human is ordering a small cappuccino and a large lemonade. Cappuccino is a valid menu item. Lemonade is not a valid menu item. I will suggest the Human a replacement from our valid menu items.</Validation>n<Response>nSorry, we don't have Lemonades, would you like to order something else instead? Perhaps a Frappe or a Latte?</Response></example>nn<example>H: Can I get a medium frappuccino with sugar please?nnA: <Validation>:n The Human is ordering a Frappuccino. Frappuccino is not a valid menu item. I will suggest a replacement from the valid menu items in my context.</Validation>n<Response>nI am so sorry, but Frappuccino is not in our menu, do you want a frappe or a cappuccino instead? perhaps something else?</Response></example>nn<example>H: I want two large americanos and a small latte please.nnA: <Validation>:n The Human is ordering 2 Large Americanos, and a Small Latte. Americano is a valid menu item. Latte is a valid menu item.</Validation>n<Response>nOk, I got: nt-2 Large Americanos and.nt-Small Latte.nIs this correct?</Response>nnH: looks correct, yes.nnA:n<Response>nGreat, Give me a moment while I try to process your order.</Response></example>nn</Context>nnPlease complete this request according to the instructions and examples provided above:<request>REPLACEME</request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"
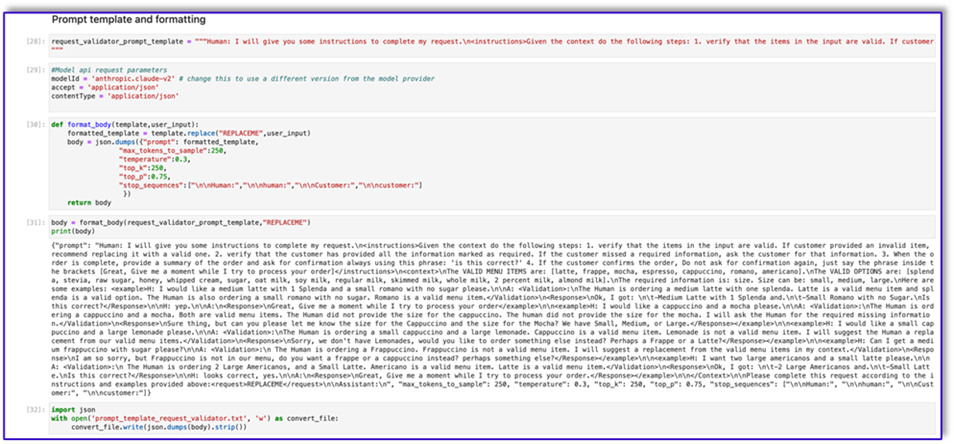
A seguir está nossa resposta do Amazon Bedrock usando este modelo.

Segue o código para prompt_template_object_creator.txt:
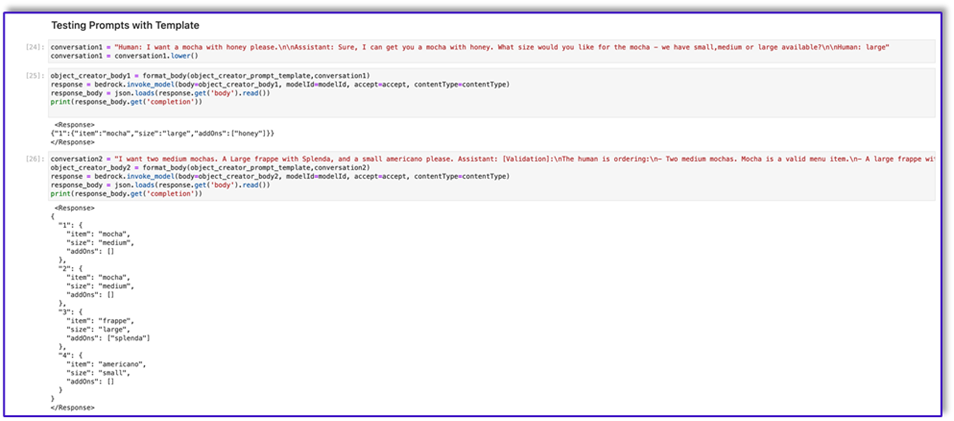
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to create a json object in Response with the appropriate attributes.nHere are some examples:n<example><Conversation> H: I want a latte.nnA:nCan I have the size?nnH: Medium.nnA: So, a medium latte.nIs this Correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"latte","size":"medium","addOns":[]}}</Response></example>n<example><Conversation> H: I want a large frappe and 2 small americanos with sugar.nnA: Okay, let me confirm:nn1 large frappenn2 small americanos with sugarnnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"frappe","size":"large","addOns":[]},"2":{"item":"americano","size":"small","addOns":["sugar"]},"3":{"item":"americano","size":"small","addOns":["sugar"]}}</Response>n</example>n<example><Conversation> H: I want a medium americano.nnA: Okay, let me confirm:nn1 medium americanonnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"americano","size":"medium","addOns":[]}}</Response></example>n<example><Conversation> H: I want a large latte with oatmilk.nnA: Okay, let me confirm:nnLarge latte with oatmilknnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"latte","size":"large","addOns":["oatmilk"]}}</Response></example>n<example><Conversation> H: I want a small mocha with no whipped cream please.nnA: Okay, let me confirm:nnSmall mocha with no whipped creamnnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"mocha","size":"small","addOns":["no whipped cream"]}}</Response>nn</example></instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"

A seguir está o código para prompt_template_order_summary.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to create a summary of the order with bullet points and include the order total.nHere are some examples:n<example><Conversation> H: I want a large frappe and 2 small americanos with sugar.nnA: Okay, let me confirm:nn1 large frappenn2 small americanos with sugarnnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>10.50</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nn1 large frappenn2 small americanos with sugar.nYour Order total is $10.50</Response></example>n<example><Conversation> H: I want a medium americano.nnA: Okay, let me confirm:nn1 medium americanonnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>3.50</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nn1 medium americano.nYour Order total is $3.50</Response></example>n<example><Conversation> H: I want a large latte with oat milk.nnA: Okay, let me confirm:nnLarge latte with oat milknnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>6.75</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nnLarge latte with oat milk.nYour Order total is $6.75</Response></example>n<example><Conversation> H: I want a small mocha with no whipped cream please.nnA: Okay, let me confirm:nnSmall mocha with no whipped creamnnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>4.25</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nnSmall mocha with no whipped cream.nYour Order total is $6.75</Response>nn</example>n</instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation>nn<OrderTotal>REPLACETOTAL</OrderTotal></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:", "[Conversation]"]}"


Como você pode ver, usamos nossos modelos de prompt para validar itens de menu, identificar informações necessárias ausentes, criar uma estrutura de dados e resumir o pedido. Os modelos básicos disponíveis no Amazon Bedrock são muito poderosos, então você pode realizar ainda mais tarefas por meio desses modelos.
Você concluiu a engenharia dos prompts e salvou os modelos em arquivos de texto. Agora você pode começar a criar o bot do Amazon Lex e as funções do Lambda associadas.
Crie uma camada Lambda com os modelos de prompt
Conclua as etapas a seguir para criar sua camada Lambda:
- No SageMaker Studio, crie uma nova pasta com uma subpasta chamada
python.
- Copie seus arquivos de prompt para o
python pasta.

- Você pode adicionar a biblioteca ZIP à instância do notebook executando o comando a seguir.
!conda install -y -c conda-forge zip
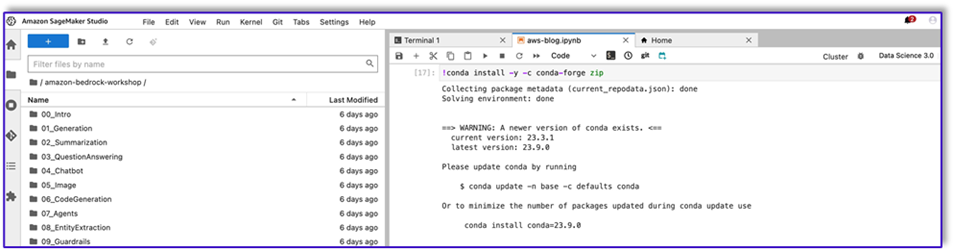
- Agora, execute o seguinte comando para criar o arquivo ZIP para upload na camada Lambda.
!zip -r prompt_templates_layer.zip prompt_templates_layer/.
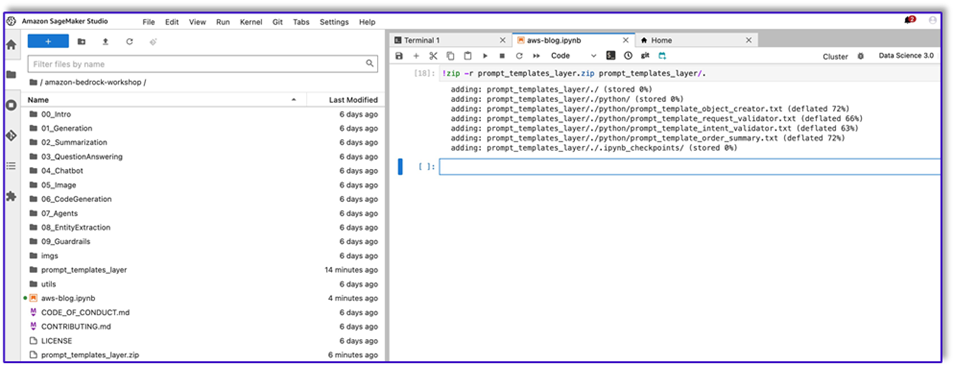
- Depois de criar o arquivo ZIP, você pode fazer download do arquivo. Vá para Lambda, crie uma nova camada fazendo upload do arquivo diretamente ou fazendo upload primeiro para o Amazon S3.
- Em seguida, anexe essa nova camada à função Lambda de orquestração.
Agora, seus arquivos de modelo de prompt estão armazenados localmente no ambiente de execução do Lambda. Isso irá acelerar o processo durante a execução do bot.
Crie uma camada Lambda com as bibliotecas necessárias
Conclua as etapas a seguir para criar sua camada Lambda com as bibliotecas necessárias:
- Abra uma Nuvem AWS9 ambiente de instância, crie uma pasta com uma subpasta chamada
python.
- Abra um terminal dentro do
python pasta.
- Execute os seguintes comandos no terminal:
pip install “boto3>=1.28.57” -t .
pip install “awscli>=1.29.57" -t .
pip install “botocore>=1.31.57” -t .
- Execute
cd .. e posicione-se dentro de sua nova pasta onde você também tem o python subpasta.
- Execute o seguinte comando:
- Depois de criar o arquivo ZIP, você pode fazer download do arquivo. Vá para Lambda, crie uma nova camada fazendo upload do arquivo diretamente ou fazendo upload primeiro para o Amazon S3.
- Em seguida, anexe essa nova camada à função Lambda de orquestração.
Crie o bot no Amazon Lex v2
Para este caso de uso, construímos um bot Amazon Lex que pode fornecer uma interface de entrada/saída para a arquitetura a fim de chamar o Amazon Bedrock usando voz ou texto de qualquer interface. Como o LLM cuidará da conversa desse agente de processamento de pedidos e o Lambda orquestrará o fluxo de trabalho, você pode criar um bot com três intenções e sem slots.
- No console do Amazon Lex, crie um novo bot com o método Crie um bot em branco.
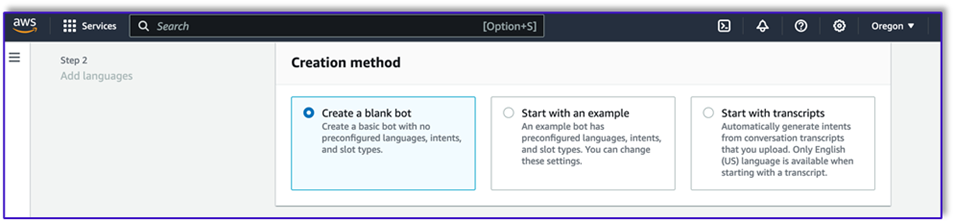
Agora você pode adicionar uma intenção com qualquer expressão inicial apropriada para que os usuários finais iniciem a conversa com o bot. Usamos saudações simples e adicionamos uma resposta inicial do bot para que os usuários finais possam fornecer suas solicitações. Ao criar o bot, certifique-se de usar um gancho de código Lambda com as intenções; isso acionará uma função Lambda que orquestrará o fluxo de trabalho entre o cliente, o Amazon Lex e o LLM.
- Adicione sua primeira intenção, que aciona o fluxo de trabalho e usa o modelo de prompt de validação de intenção para chamar o Amazon Bedrock e identificar o que o cliente está tentando realizar. Adicione algumas declarações simples para os usuários finais iniciarem uma conversa.

Você não precisa usar nenhum slot ou leitura inicial em nenhuma das intenções do bot. Na verdade, você não precisa adicionar enunciados à segunda ou terceira intenções. Isso ocorre porque o LLM orientará o Lambda durante todo o processo.
- Adicione um prompt de confirmação. Você pode personalizar essa mensagem na função Lambda posteriormente.
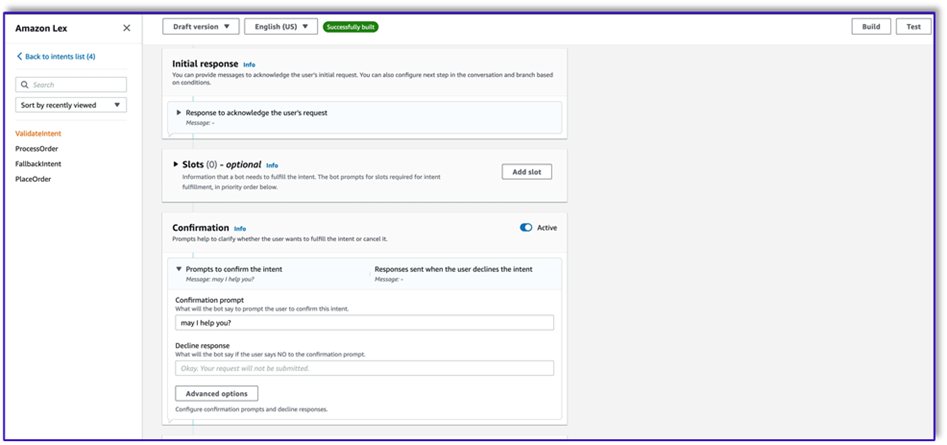
- Debaixo Ganchos de código, selecione Use uma função Lambda para inicialização e validação.
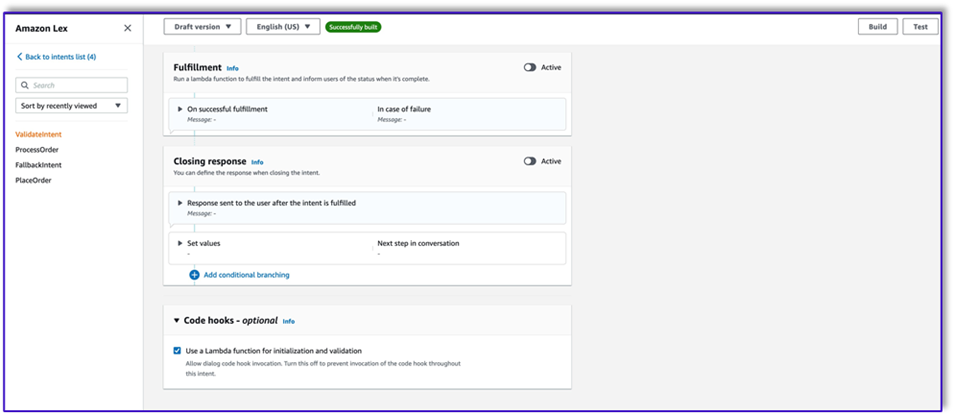
- Crie uma segunda intenção sem expressão e sem resposta inicial. Isto é o
PlaceOrder intenção.
Quando o LLM identifica que o cliente está tentando fazer um pedido, a função Lambda acionará essa intenção e validará a solicitação do cliente no menu, garantindo que nenhuma informação necessária esteja faltando. Lembre-se de que tudo isso está nos modelos de prompt, portanto você pode adaptar esse fluxo de trabalho para qualquer caso de uso alterando os modelos de prompt.
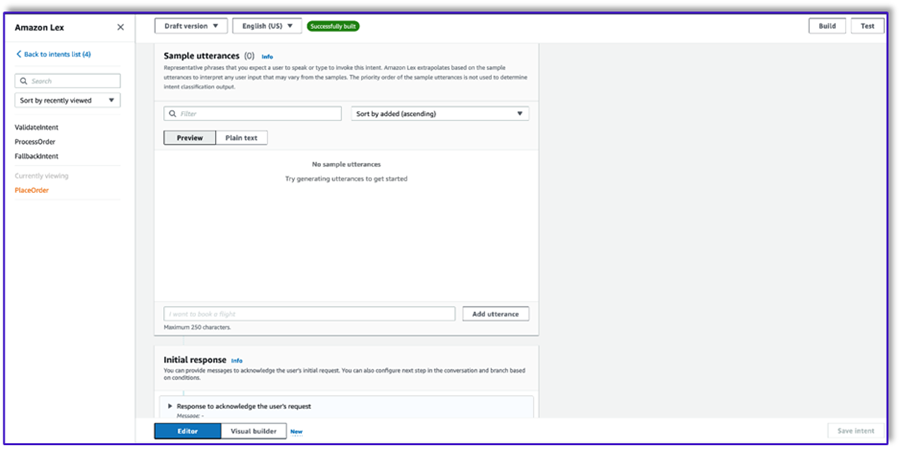
- Não adicione nenhum espaço, mas adicione um prompt de confirmação e recuse a resposta.
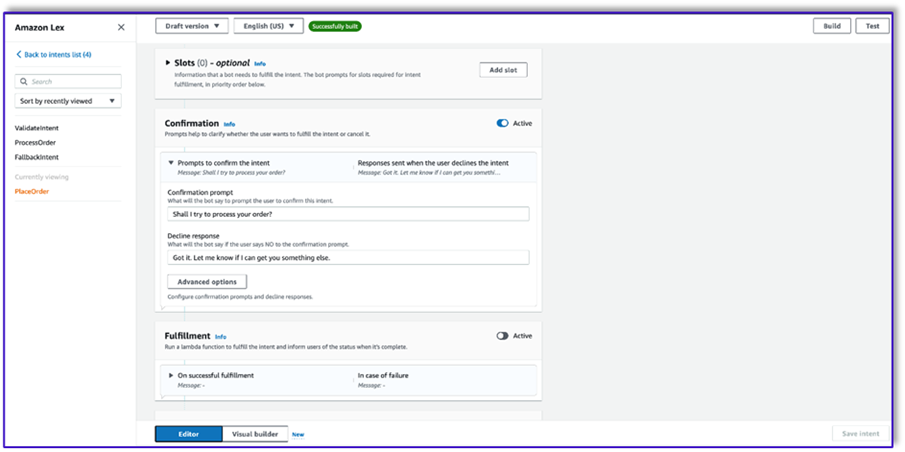
- Selecionar Use uma função Lambda para inicialização e validação.

- Crie uma terceira intenção chamada
ProcessOrder sem declarações de amostra e sem slots.
- Adicione uma resposta inicial, um prompt de confirmação e uma resposta de recusa.
Após o LLM validar a solicitação do cliente, a função Lambda aciona a terceira e última intenção de processar o pedido. Aqui, o Lambda usará o modelo de criador de objeto para gerar a estrutura de dados JSON do pedido para consultar a tabela do DynamoDB e, em seguida, usará o modelo de resumo do pedido para resumir todo o pedido junto com o total para que o Amazon Lex possa passá-lo ao cliente.
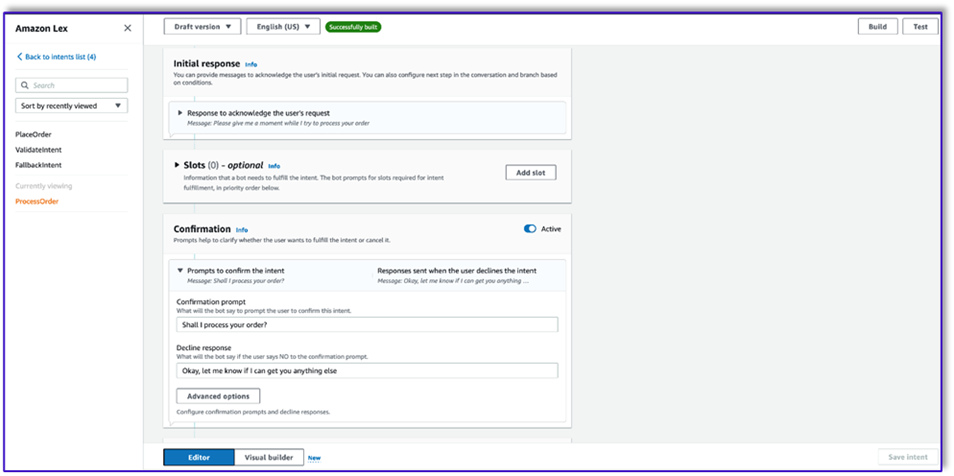
- Selecionar Use uma função Lambda para inicialização e validação. Isso pode usar qualquer função Lambda para processar o pedido após o cliente ter dado a confirmação final.

- Depois de criar todas as três intenções, acesse o construtor Visual para o
ValidateIntent, adicione uma etapa de intenção de acesso e conecte a saída da confirmação positiva a essa etapa.
- Depois de adicionar a intenção de acesso, edite-a e escolha a intenção PlaceOrder como o nome da intenção.

- Da mesma forma, para acessar o construtor Visual do
PlaceOrder intenção e conecte a saída da confirmação positiva ao ProcessOrder intenção de ir. Nenhuma edição é necessária para o ProcessOrder intenção.
- Agora você precisa criar a função Lambda que orquestra o Amazon Lex e chama a tabela DynamoDB, conforme detalhado na seção a seguir.
Crie uma função Lambda para orquestrar o bot do Amazon Lex
Agora você pode criar a função Lambda que orquestra o bot e o fluxo de trabalho do Amazon Lex. Conclua as seguintes etapas:
- Crie uma função Lambda com a política de execução padrão e deixe o Lambda criar uma função para você.
- Na janela de código da sua função, adicione algumas funções utilitárias que ajudarão: formate os prompts adicionando o contexto lex ao modelo, chame a API Amazon Bedrock LLM, extraia o texto desejado das respostas e muito mais. Veja o seguinte código:
import json
import re
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
bedrock = boto3.client(service_name='bedrock-runtime')
def CreatingCustomPromptFromLambdaLayer(object_key,replace_items):
folder_path = '/opt/order_processing_agent_prompt_templates/python/'
try:
file_path = folder_path + object_key
with open(file_path, "r") as file1:
raw_template = file1.read()
# Modify the template with the custom input prompt
#template['inputs'][0].insert(1, {"role": "user", "content": '### Input:n' + user_request})
for key,value in replace_items.items():
value = json.dumps(json.dumps(value).replace('"','')).replace('"','')
raw_template = raw_template.replace(key,value)
modified_prompt = raw_template
return modified_prompt
except Exception as e:
return {
'statusCode': 500,
'body': f'An error occurred: {str(e)}'
}
def CreatingCustomPrompt(object_key,replace_items):
logger.debug('replace_items is: {}'.format(replace_items))
#retrieve user request from intent_request
#we first propmt the model with current order
bucket_name = 'your-bucket-name'
#object_key = 'prompt_template_order_processing.txt'
try:
s3 = boto3.client('s3')
# Retrieve the existing template from S3
response = s3.get_object(Bucket=bucket_name, Key=object_key)
raw_template = response['Body'].read().decode('utf-8')
raw_template = json.loads(raw_template)
logger.debug('raw template is {}'.format(raw_template))
#template_json = json.loads(raw_template)
#logger.debug('template_json is {}'.format(template_json))
#template = json.dumps(template_json)
#logger.debug('template is {}'.format(template))
# Modify the template with the custom input prompt
#template['inputs'][0].insert(1, {"role": "user", "content": '### Input:n' + user_request})
for key,value in replace_items.items():
raw_template = raw_template.replace(key,value)
logger.debug("Replacing: {} nwith: {}".format(key,value))
modified_prompt = json.dumps(raw_template)
logger.debug("Modified template: {}".format(modified_prompt))
logger.debug("Modified template type is: {}".format(print(type(modified_prompt))))
#modified_template_json = json.loads(modified_prompt)
#logger.debug("Modified template json: {}".format(modified_template_json))
return modified_prompt
except Exception as e:
return {
'statusCode': 500,
'body': f'An error occurred: {str(e)}'
}
def validate_intent(intent_request):
logger.debug('starting validate_intent: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
#Preparing validation prompt by adding context to prompt template
object_key = 'prompt_template_intent_validator.txt'
#replace_items = {"REPLACEME":full_context}
#replace_items = {"REPLACEME":dialog_context}
replace_items = {"REPLACEME":dialog_context}
#validation_prompt = CreatingCustomPrompt(object_key,replace_items)
validation_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for request validation
intent_validation_completion = prompt_bedrock(validation_prompt)
intent_validation_completion = re.sub(r'["]','',intent_validation_completion)
#extracting response from response completion and removing some special characters
validation_response = extract_response(intent_validation_completion)
validation_intent = extract_intent(intent_validation_completion)
#business logic depending on intents
if validation_intent == 'Place Order':
return validate_request(intent_request)
elif validation_intent in ['Complain','Speak to Someone']:
##adding session attributes to keep current context
full_context = full_context + 'nn' + intent_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
intent_request['sessionState']['sessionAttributes']['customerIntent'] = validation_intent
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close',validation_response)
if validation_intent == 'Greeting':
##adding session attributes to keep current context
full_context = full_context + 'nn' + intent_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
intent_request['sessionState']['sessionAttributes']['customerIntent'] = validation_intent
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'InProgress','ConfirmIntent',validation_response)
def validate_request(intent_request):
logger.debug('starting validate_request: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
#Preparing validation prompt by adding context to prompt template
object_key = 'prompt_template_request_validator.txt'
replace_items = {"REPLACEME":dialog_context}
#validation_prompt = CreatingCustomPrompt(object_key,replace_items)
validation_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for request validation
request_validation_completion = prompt_bedrock(validation_prompt)
request_validation_completion = re.sub(r'["]','',request_validation_completion)
#extracting response from response completion and removing some special characters
validation_response = extract_response(request_validation_completion)
##adding session attributes to keep current context
full_context = full_context + 'nn' + request_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
return close(intent_request['sessionState']['sessionAttributes'],'PlaceOrder','InProgress','ConfirmIntent',validation_response)
def process_order(intent_request):
logger.debug('starting process_order: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
# Preparing object creator prompt by adding context to prompt template
object_key = 'prompt_template_object_creator.txt'
replace_items = {"REPLACEME":dialog_context}
#object_creator_prompt = CreatingCustomPrompt(object_key,replace_items)
object_creator_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for object creation
object_creation_completion = prompt_bedrock(object_creator_prompt)
#extracting response from response completion
object_creation_response = extract_response(object_creation_completion)
inputParams = json.loads(object_creation_response)
inputParams = json.dumps(json.dumps(inputParams))
logger.debug('inputParams is: {}'.format(inputParams))
client = boto3.client('lambda')
response = client.invoke(FunctionName = 'arn:aws:lambda:us-east-1:<AccountNumber>:function:aws-blog-order-validator',InvocationType = 'RequestResponse',Payload = inputParams)
responseFromChild = json.load(response['Payload'])
validationResult = responseFromChild['statusCode']
if validationResult == 205:
order_validation_error = responseFromChild['validator_response']
return close(intent_request['sessionState']['sessionAttributes'],'PlaceOrder','InProgress','ConfirmIntent',order_validation_error)
#invokes Order Processing lambda to query DynamoDB table and returns order total
response = client.invoke(FunctionName = 'arn:aws:lambda:us-east-1: <AccountNumber>:function:aws-blog-order-processing',InvocationType = 'RequestResponse',Payload = inputParams)
responseFromChild = json.load(response['Payload'])
orderTotal = responseFromChild['body']
###Prompting the model to summarize the order along with order total
object_key = 'prompt_template_order_summary.txt'
replace_items = {"REPLACEME":dialog_context,"REPLACETOTAL":orderTotal}
#order_summary_prompt = CreatingCustomPrompt(object_key,replace_items)
order_summary_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
order_summary_completion = prompt_bedrock(order_summary_prompt)
#extracting response from response completion
order_summary_response = extract_response(order_summary_completion)
order_summary_response = order_summary_response + '. Shall I finalize processing your order?'
##adding session attributes to keep current context
full_context = full_context + 'nn' + order_summary_completion
dialog_context = dialog_context + 'nnAssistant: ' + order_summary_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
return close(intent_request['sessionState']['sessionAttributes'],'ProcessOrder','InProgress','ConfirmIntent',order_summary_response)
""" --- Main handler and Workflow functions --- """
def lambda_handler(event, context):
"""
Route the incoming request based on intent.
The JSON body of the request is provided in the event slot.
"""
logger.debug('event is: {}'.format(event))
return dispatch(event)
def dispatch(intent_request):
"""
Called when the user specifies an intent for this bot. If intent is not valid then returns error name
"""
logger.debug('intent_request is: {}'.format(intent_request))
intent_name = intent_request['sessionState']['intent']['name']
confirmation_state = intent_request['sessionState']['intent']['confirmationState']
# Dispatch to your bot's intent handlers
if intent_name == 'ValidateIntent' and confirmation_state == 'None':
return validate_intent(intent_request)
if intent_name == 'PlaceOrder' and confirmation_state == 'None':
return validate_request(intent_request)
elif intent_name == 'PlaceOrder' and confirmation_state == 'Confirmed':
return process_order(intent_request)
elif intent_name == 'PlaceOrder' and confirmation_state == 'Denied':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Got it. Let me know if I can help you with something else.')
elif intent_name == 'PlaceOrder' and confirmation_state not in ['Denied','Confirmed','None']:
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Sorry. I am having trouble completing the request. Let me get someone to help you.')
logger.debug('exiting intent {} here'.format(intent_request['sessionState']['intent']['name']))
elif intent_name == 'ProcessOrder' and confirmation_state == 'None':
return validate_request(intent_request)
elif intent_name == 'ProcessOrder' and confirmation_state == 'Confirmed':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Perfect! Your order has been processed. Please proceed to payment.')
elif intent_name == 'ProcessOrder' and confirmation_state == 'Denied':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Got it. Let me know if I can help you with something else.')
elif intent_name == 'ProcessOrder' and confirmation_state not in ['Denied','Confirmed','None']:
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Sorry. I am having trouble completing the request. Let me get someone to help you.')
logger.debug('exiting intent {} here'.format(intent_request['sessionState']['intent']['name']))
raise Exception('Intent with name ' + intent_name + ' not supported')
def prompt_bedrock(formatted_template):
logger.debug('prompt bedrock input is:'.format(formatted_template))
body = json.loads(formatted_template)
modelId = 'anthropic.claude-v2' # change this to use a different version from the model provider
accept = 'application/json'
contentType = 'application/json'
response = bedrock.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
response_completion = response_body.get('completion')
logger.debug('response is: {}'.format(response_completion))
#print_ww(response_body.get('completion'))
#print(response_body.get('results')[0].get('outputText'))
return response_completion
#function to extract text between the <Response> and </Response> tags within model completion
def extract_response(response_completion):
if '<Response>' in response_completion:
customer_response = response_completion.replace('<Response>','||').replace('</Response>','').split('||')[1]
logger.debug('modified response is: {}'.format(response_completion))
return customer_response
else:
logger.debug('modified response is: {}'.format(response_completion))
return response_completion
#function to extract text between the <Response> and </Response> tags within model completion
def extract_intent(response_completion):
if '<intent>' in response_completion:
customer_intent = response_completion.replace('<intent>','||').replace('</intent>','||').split('||')[1]
return customer_intent
else:
return customer_intent
def close(session_attributes, intent, fulfillment_state, action_type, message):
#This function prepares the response in the appropiate format for Lex V2
response = {
"sessionState": {
"sessionAttributes":session_attributes,
"dialogAction": {
"type": action_type
},
"intent": {
"name":intent,
"state":fulfillment_state
},
},
"messages":
[{
"contentType":"PlainText",
"content":message,
}]
,
}
return response
- Anexe a camada Lambda que você criou anteriormente a esta função.
- Além disso, anexe a camada aos modelos de prompt que você criou.
- Na função de execução do Lambda, anexe a política de acesso ao Amazon Bedrock, que foi criada anteriormente.

A função de execução do Lambda deve ter as seguintes permissões.

Anexe a função Orchestration Lambda ao bot do Amazon Lex
- Depois de criar a função na seção anterior, retorne ao console do Amazon Lex e navegue até o bot.
- Debaixo Idiomas no painel de navegação, escolha Inglês.
- Escolha fonte, escolha seu bot de processamento de pedidos.
- Escolha Versão da função Lambda ou alias, escolha $ LATEST.
- Escolha Salvar.

Crie funções auxiliares do Lambda
Conclua as etapas a seguir para criar funções Lambda adicionais:
- Crie uma função Lambda para consultar a tabela do DynamoDB criada anteriormente:
import json
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# Initialize the DynamoDB client
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('your-table-name')
def calculate_grand_total(input_data):
# Initialize the total price
total_price = 0
try:
# Loop through each item in the input JSON
for item_id, item_data in input_data.items():
item_name = item_data['item'].lower() # Convert item name to lowercase
item_size = item_data['size'].lower() # Convert item size to lowercase
# Query the DynamoDB table for the item based on Item and Size
response = table.get_item(
Key={'Item': item_name,
'Size': item_size}
)
# Check if the item was found in the table
if 'Item' in response:
item = response['Item']
price = float(item['Price'])
total_price += price # Add the item's price to the total
return total_price
except Exception as e:
raise Exception('An error occurred: {}'.format(str(e)))
def lambda_handler(event, context):
try:
# Parse the input JSON from the Lambda event
input_json = json.loads(event)
# Calculate the grand total
grand_total = calculate_grand_total(input_json)
# Return the grand total in the response
return {'statusCode': 200,'body': json.dumps(grand_total)}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps('An error occurred: {}'.format(str(e)))
- Navegue até a Configuração guia na função Lambda e escolha Permissões.
- Anexe uma declaração de política baseada em recursos que permita que a função Lambda de processamento de pedidos invoque essa função.
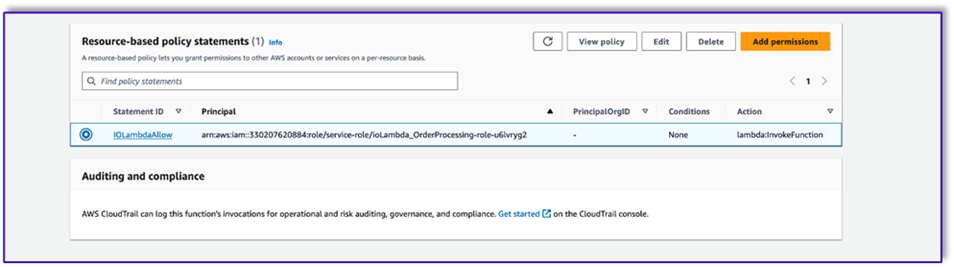
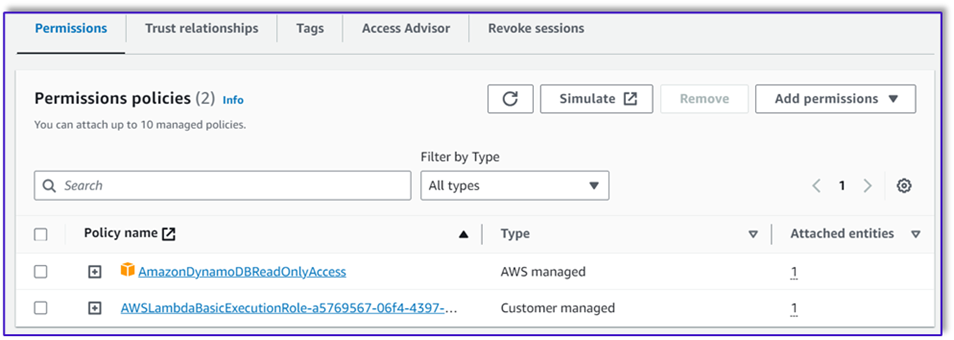
- Navegue até a função de execução do IAM para esta função do Lambda e adicione uma política para acessar a tabela do DynamoDB.
- Crie outra função Lambda para validar se todos os atributos necessários foram passados do cliente. No exemplo a seguir, validamos se o atributo size é capturado para um pedido:
import json
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
def lambda_handler(event, context):
# Define customer orders from the input event
customer_orders = json.loads(event)
# Initialize a list to collect error messages
order_errors = {}
missing_size = []
error_messages = []
# Iterate through each order in customer_orders
for order_id, order in customer_orders.items():
if "size" not in order or order["size"] == "":
missing_size.append(order['item'])
order_errors['size'] = missing_size
if order_errors:
items_missing_size = order_errors['size']
error_message = f"could you please provide the size for the following items: {', '.join(items_missing_size)}?"
error_messages.append(error_message)
# Prepare the response message
if error_messages:
response_message = "n".join(error_messages)
return {
'statusCode': 205,
'validator_response': response_message
}
else:
response_message = "Order is validated successfully"
return {
'statusCode': 200,
'validator_response': response_message
}
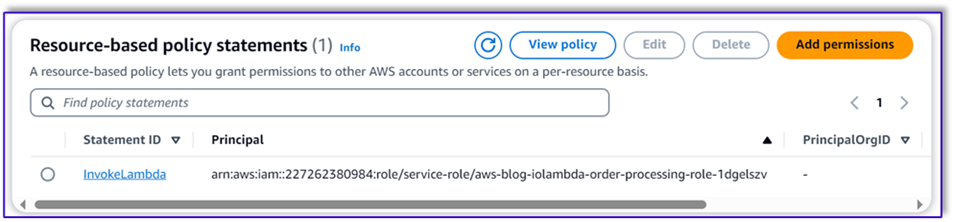
- Navegue até a Configuração guia na função Lambda e escolha Permissões.
- Anexe uma declaração de política baseada em recursos que permita que a função Lambda de processamento de pedidos invoque essa função.
Teste a solução
Agora podemos testar a solução com exemplos de pedidos que os clientes fazem por meio do Amazon Lex.
No nosso primeiro exemplo, o cliente pediu um frappuccino, que não está no cardápio. O modelo valida com a ajuda do modelo de validador de pedidos e sugere algumas recomendações com base no menu. Depois que o cliente confirma seu pedido, ele é notificado sobre o total e o resumo do pedido. A encomenda será processada com base na confirmação final do cliente.
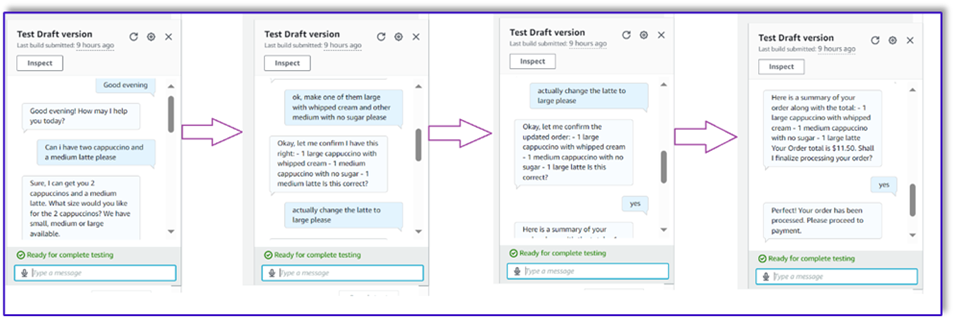
Em nosso próximo exemplo, o cliente está pedindo um cappuccino grande e depois modificando o tamanho de grande para médio. O modelo captura todas as alterações necessárias e solicita ao cliente a confirmação do pedido. O modelo apresenta o total e o resumo do pedido, e processa o pedido com base na confirmação final do cliente.

Para nosso exemplo final, o cliente fez um pedido de vários itens e falta o tamanho de alguns itens. O modelo e a função Lambda verificarão se todos os atributos necessários estão presentes para processar o pedido e então solicitarão ao cliente que forneça as informações que faltam. Depois que o cliente fornece as informações que faltam (neste caso, o tamanho do café), é mostrado o total e o resumo do pedido. A encomenda será processada com base na confirmação final do cliente.
Limitações do LLM
Os resultados do LLM são estocásticos por natureza, o que significa que os resultados do nosso LLM podem variar em formato ou mesmo na forma de conteúdo falso (alucinações). Portanto, os desenvolvedores precisam contar com uma boa lógica de tratamento de erros em todo o seu código para lidar com esses cenários e evitar uma experiência degradada do usuário final.
limpar
Se você não precisar mais desta solução, poderá excluir os seguintes recursos:
- Funções lambda
- Caixa Amazon Lex
- Mesa DynamoDB
- Caçamba S3
Além disso, encerre a instância do SageMaker Studio se o aplicativo não for mais necessário.
Avaliação de custos
Para obter informações sobre preços dos principais serviços utilizados por esta solução, consulte o seguinte:
Observe que você pode usar o Claude v2 sem a necessidade de provisionamento, portanto, os custos gerais permanecem mínimos. Para reduzir ainda mais os custos, você pode configurar a tabela do DynamoDB com a configuração sob demanda.
Conclusão
Esta postagem demonstrou como criar um agente de processamento de pedidos de IA habilitado para fala usando Amazon Lex, Amazon Bedrock e outros serviços da AWS. Mostramos como a engenharia rápida com um poderoso modelo de IA generativo como o Claude pode permitir uma compreensão robusta da linguagem natural e fluxos de conversação para processamento de pedidos sem a necessidade de extensos dados de treinamento.
A arquitetura da solução usa componentes sem servidor como Lambda, Amazon S3 e DynamoDB para permitir uma implementação flexível e escalável. Armazenar os modelos de prompt no Amazon S3 permite personalizar a solução para diferentes casos de uso.
Os próximos passos podem incluir a expansão das capacidades do agente para lidar com uma gama mais ampla de solicitações de clientes e casos extremos. Os modelos de prompt fornecem uma maneira de melhorar iterativamente as habilidades do agente. Personalizações adicionais podem envolver a integração dos dados do pedido com sistemas de back-end, como estoque, CRM ou POS. Por fim, o agente pode ser disponibilizado em vários pontos de contato com o cliente, como aplicativos móveis, drive-thru, quiosques e muito mais, usando os recursos multicanais do Amazon Lex.
Para saber mais, consulte os seguintes recursos relacionados:
- Implantando e gerenciando bots multicanais:
- Engenharia imediata para Claude e outros modelos:
- Padrões de arquitetura sem servidor para assistentes de IA escaláveis:
Sobre os autores
 Moumita Dutta é arquiteto de soluções parceiras na Amazon Web Services. Na sua função, ela colabora estreitamente com parceiros para desenvolver ativos escaláveis e reutilizáveis que agilizam as implementações na nuvem e melhoram a eficiência operacional. Ela é membro da comunidade de IA/ML e especialista em IA generativa na AWS. Nos tempos livres, gosta de jardinagem e de andar de bicicleta.
Moumita Dutta é arquiteto de soluções parceiras na Amazon Web Services. Na sua função, ela colabora estreitamente com parceiros para desenvolver ativos escaláveis e reutilizáveis que agilizam as implementações na nuvem e melhoram a eficiência operacional. Ela é membro da comunidade de IA/ML e especialista em IA generativa na AWS. Nos tempos livres, gosta de jardinagem e de andar de bicicleta.
 Fernando Lammoglia é arquiteto de soluções parceiras na Amazon Web Services e trabalha em estreita colaboração com parceiros da AWS para liderar o desenvolvimento e a adoção de soluções de IA de ponta em unidades de negócios. Um líder estratégico com experiência em arquitetura de nuvem, IA generativa, aprendizado de máquina e análise de dados. Ele é especialista na execução de estratégias de entrada no mercado e no fornecimento de soluções de IA impactantes alinhadas com os objetivos organizacionais. Nas horas vagas adora ficar com a família e viajar para outros países.
Fernando Lammoglia é arquiteto de soluções parceiras na Amazon Web Services e trabalha em estreita colaboração com parceiros da AWS para liderar o desenvolvimento e a adoção de soluções de IA de ponta em unidades de negócios. Um líder estratégico com experiência em arquitetura de nuvem, IA generativa, aprendizado de máquina e análise de dados. Ele é especialista na execução de estratégias de entrada no mercado e no fornecimento de soluções de IA impactantes alinhadas com os objetivos organizacionais. Nas horas vagas adora ficar com a família e viajar para outros países.
 Mitul Patel é arquiteto de soluções sênior na Amazon Web Services. Em sua função de facilitador de tecnologia em nuvem, ele trabalha com os clientes para entender seus objetivos e desafios e fornece orientação prescritiva para atingir seus objetivos com as ofertas da AWS. Ele é membro da comunidade de IA/ML e embaixador de IA generativa na AWS. Nas horas vagas gosta de fazer caminhadas e jogar futebol.
Mitul Patel é arquiteto de soluções sênior na Amazon Web Services. Em sua função de facilitador de tecnologia em nuvem, ele trabalha com os clientes para entender seus objetivos e desafios e fornece orientação prescritiva para atingir seus objetivos com as ofertas da AWS. Ele é membro da comunidade de IA/ML e embaixador de IA generativa na AWS. Nas horas vagas gosta de fazer caminhadas e jogar futebol.

