Imagem gerada com DALL-E 3
Um banco de dados vetorial é um tipo especializado de banco de dados projetado para armazenar e indexar embeddings de vetores para recuperação eficiente e pesquisa de similaridade. É usado em diversas aplicações que envolvem grandes modelos de linguagem, IA generativa e pesquisa semântica. Incorporações vetoriais são representações matemáticas de dados que capturam informações semânticas e permitem a compreensão de padrões, relacionamentos e estruturas subjacentes.
Os bancos de dados vetoriais tornaram-se cada vez mais importantes no campo das aplicações de IA, pois são excelentes no tratamento de dados de alta dimensão e na facilitação de pesquisas complexas de similaridade.
Neste blog, exploraremos os cinco principais bancos de dados vetoriais que você deve experimentar em 2024. Esses bancos de dados foram selecionados com base em sua escalabilidade, versatilidade e desempenho no tratamento de dados vetoriais.
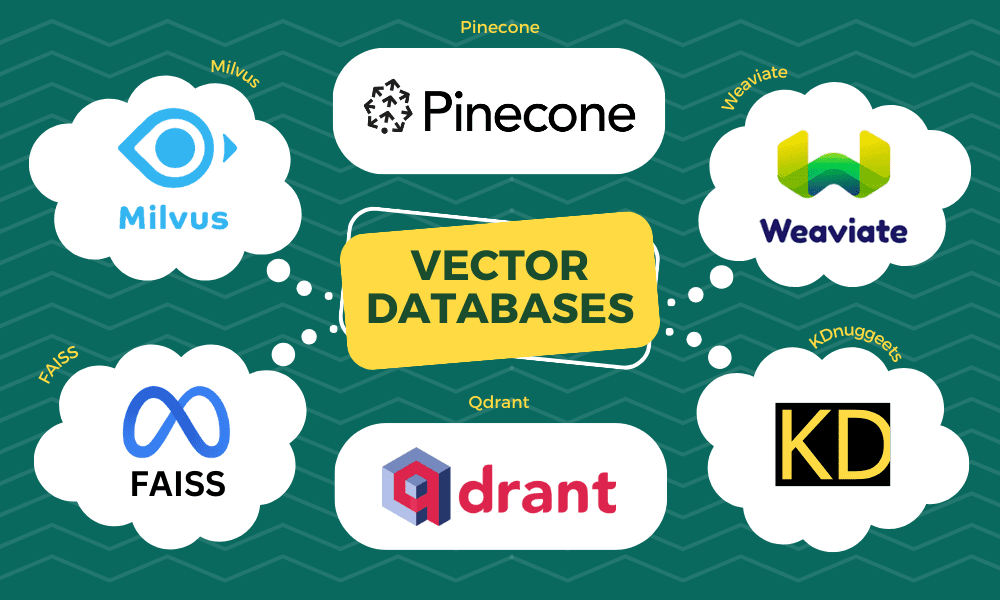
Imagem do autor
Quadrante é um mecanismo de pesquisa de similaridade vetorial de código aberto e banco de dados vetorial que fornece um serviço pronto para produção com uma API conveniente. Você pode armazenar, pesquisar e gerenciar incorporações de vetores. O Qdrant é adaptado para suportar filtragem estendida, o que o torna útil para uma ampla variedade de aplicações que envolvem rede neural ou correspondência baseada em semântica, pesquisa facetada e muito mais. Como está escrito na linguagem de programação rápida e confiável Rust, o Qdrant pode lidar com altas cargas de usuários com eficiência.
Ao usar o Qdrant, você pode criar aplicativos completos com codificadores incorporados para tarefas como correspondência, pesquisa, recomendação e muito mais. Também está disponível como Qdrant Cloud, uma versão totalmente gerenciada que inclui um nível gratuito, proporcionando uma maneira fácil para os usuários aproveitarem suas habilidades de pesquisa vetorial em seus projetos.
Pinecone é um banco de dados de vetores gerenciado que foi projetado especificamente para enfrentar os desafios associados a dados de alta dimensão. Com recursos avançados de indexação e pesquisa, a Pinecone permite que engenheiros e cientistas de dados construam e implantem aplicativos de aprendizado de máquina em grande escala que podem processar e analisar dados de alta dimensão com eficiência.
Os principais recursos do Pinecone incluem um serviço totalmente gerenciado e altamente escalável, permitindo ingestão de dados em tempo real e pesquisa de baixa latência. A Pinecone também oferece integração com LangChain para permitir aplicativos de processamento de linguagem natural. Com seu foco especializado em dados de alta dimensão, a Pinecone fornece uma plataforma otimizada para a implantação de projetos impactantes de aprendizado de máquina.
Tecer é um banco de dados vetorial de código aberto que permite armazenar objetos de dados e incorporações vetoriais de seus modelos de ML favoritos, dimensionando perfeitamente para bilhões de objetos de dados. Com o Weaviate, você ganha velocidade – ele pode pesquisar rapidamente dez vizinhos mais próximos de milhões de objetos em apenas alguns milissegundos. Há flexibilidade para vetorizar dados durante a importação ou carregar seus próprios vetores, aproveitando módulos que se integram a plataformas como OpenAI, Cohere, HuggingFace e muito mais.
Weaviate se concentra em escalabilidade, replicação e segurança para prontidão de produção, desde protótipos até implantação em larga escala. Além de pesquisas rápidas de vetores, o Weaviate também oferece recomendações, resumos e integrações de estruturas de pesquisa neural. Ele fornece um banco de dados vetorial flexível e escalável para uma variedade de casos de uso.
Milvus é um poderoso banco de dados de vetores de código aberto para aplicações de IA e pesquisa de similaridade. Torna a pesquisa de dados não estruturados mais acessível e fornece uma experiência de usuário consistente, independentemente do ambiente de implantação.
Milvus 2.0 é um banco de dados vetorial nativo da nuvem com armazenamento e computação separados por design, usando componentes sem estado para maior elasticidade e flexibilidade. Lançado sob a licença Apache 2.0, o Milvus oferece pesquisa em milissegundos em trilhões de conjuntos de dados vetoriais, gerenciamento simplificado de dados não estruturados por meio de APIs ricas e experiência consistente em todos os ambientes, além de pesquisa incorporada em tempo real em aplicativos. É altamente escalonável e elástico, suportando escalonamento em nível de componente sob demanda.
Milvus combina filtragem escalar com similaridade vetorial para uma solução de pesquisa híbrida. Com suporte da comunidade e mais de 1,000 usuários corporativos, Milvus fornece um banco de dados de vetores de código aberto confiável, flexível e escalável para uma variedade de casos de uso.
Faiss é uma biblioteca de código aberto para pesquisa eficiente de similaridade e agrupamento de vetores densos, capaz de pesquisar conjuntos de vetores massivos que excedem a capacidade da RAM. Ele contém vários métodos para pesquisa de similaridade com base em comparações vetoriais usando distâncias L2, produtos escalares e similaridade de cosseno. Alguns métodos, como a quantização de vetores binários, permitem representações vetoriais compactadas para escalabilidade, enquanto outros, como HNSW e NSG, usam indexação para pesquisa acelerada.
Faiss é codificado principalmente em C++, mas integra-se totalmente com Python/NumPy. Algoritmos principais estão disponíveis para execução de GPU, aceitando entrada da memória da CPU ou GPU. A implementação da GPU permite a substituição imediata de índices de CPU para resultados mais rápidos, manipulando automaticamente cópias CPU-GPU. Desenvolvido pelo grupo Fundamental AI Research da Meta, Faiss fornece um kit de ferramentas de código aberto que permite pesquisa rápida e agrupamento em grandes conjuntos de dados vetoriais, tanto na infraestrutura de CPU quanto de GPU.
Os bancos de dados vetoriais estão rapidamente se tornando um componente essencial das aplicações modernas de IA. Conforme exploramos nesta postagem do blog, há várias opções atraentes a serem consideradas ao selecionar um banco de dados vetorial em 2024. Qdrant oferece recursos versáteis de código aberto, Pinecone fornece um serviço gerenciado projetado para dados de alta dimensão, Weaviate se concentra em escalabilidade e flexibilidade , o Milvus oferece experiências consistentes em todos os ambientes e o faiss permite uma pesquisa eficiente de similaridade por meio de algoritmos otimizados.
Cada banco de dados tem seus próprios pontos fortes e benefícios, dependendo do seu caso de uso e da infraestrutura. À medida que os modelos de IA e a pesquisa semântica continuam a avançar, será fundamental ter o banco de dados de vetores correto para armazenar, indexar e consultar incorporações de vetores. Você pode aprender mais sobre bancos de dados vetoriais lendo O que são bancos de dados de vetores e por que são importantes para os LLMs?
Abid Ali Awan (@ 1abidaliawan) é um profissional de cientista de dados certificado que adora criar modelos de aprendizado de máquina. Atualmente, ele está se concentrando na criação de conteúdo e escrevendo blogs técnicos sobre tecnologias de aprendizado de máquina e ciência de dados. Abid é mestre em Gestão de Tecnologia e bacharel em Engenharia de Telecomunicações. Sua visão é construir um produto de IA usando uma rede neural gráfica para estudantes que lutam contra doenças mentais.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.kdnuggets.com/the-5-best-vector-databases-you-must-try-in-2024?utm_source=rss&utm_medium=rss&utm_campaign=the-5-best-vector-databases-you-must-try-in-2024

