Hoje, temos o prazer de anunciar que os modelos básicos Code Llama, desenvolvidos pela Meta, estão disponíveis para clientes através de JumpStart do Amazon SageMaker para implantar com um clique para executar inferência. Code Llama é um modelo de linguagem grande (LLM) de última geração, capaz de gerar código e linguagem natural sobre código a partir de prompts de código e de linguagem natural. Você pode experimentar este modelo com o SageMaker JumpStart, um hub de aprendizado de máquina (ML) que fornece acesso a algoritmos, modelos e soluções de ML para que você possa começar a usar o ML rapidamente. Nesta postagem, explicamos como descobrir e implantar o modelo Code Llama por meio do SageMaker JumpStart.
Código Lhama
Code Llama é um modelo lançado pela Meta que é construído sobre o Llama 2. Este modelo de última geração foi projetado para melhorar a produtividade das tarefas de programação para desenvolvedores, ajudando-os a criar código bem documentado e de alta qualidade. Os modelos são excelentes em Python, C++, Java, PHP, C#, TypeScript e Bash e têm o potencial de economizar tempo dos desenvolvedores e tornar os fluxos de trabalho de software mais eficientes.
Ele vem em três variantes, projetadas para cobrir uma ampla variedade de aplicações: o modelo fundamental (Code Llama), um modelo especializado em Python (Code Llama Python) e um modelo de seguimento de instruções para entender instruções de linguagem natural (Code Llama Instruct). Todas as variantes do Code Llama vêm em quatro tamanhos: parâmetros 7B, 13B, 34B e 70B. As variantes base e de instrução 7B e 13B suportam preenchimento com base no conteúdo circundante, tornando-as ideais para aplicativos de assistente de código. Os modelos foram projetados usando o Llama 2 como base e depois treinados em 500 bilhões de tokens de dados de código, com a versão especializada em Python treinada em 100 bilhões de tokens incrementais. Os modelos Code Llama fornecem gerações estáveis com até 100,000 tokens de contexto. Todos os modelos são treinados em sequências de 16,000 tokens e mostram melhorias em entradas com até 100,000 tokens.
O modelo é disponibilizado sob o mesmo licença comunitária como Llama 2.
Modelos de fundação no SageMaker
O SageMaker JumpStart fornece acesso a uma variedade de modelos de hubs de modelos populares, incluindo Hugging Face, PyTorch Hub e TensorFlow Hub, que você pode usar em seu fluxo de trabalho de desenvolvimento de ML no SageMaker. Avanços recentes em ML deram origem a uma nova classe de modelos conhecida como modelos de fundação, que normalmente são treinados em bilhões de parâmetros e são adaptáveis a uma ampla categoria de casos de uso, como resumo de texto, geração de arte digital e tradução de idiomas. Como o treinamento desses modelos é caro, os clientes desejam usar modelos básicos pré-treinados existentes e ajustá-los conforme necessário, em vez de treinar eles próprios esses modelos. O SageMaker fornece uma lista selecionada de modelos que você pode escolher no console do SageMaker.
Você pode encontrar modelos de base de diferentes fornecedores de modelos no SageMaker JumpStart, permitindo que você comece a usar modelos de base rapidamente. Você pode encontrar modelos básicos baseados em diferentes tarefas ou provedores de modelos e revisar facilmente as características do modelo e os termos de uso. Você também pode experimentar esses modelos usando um widget de IU de teste. Quando quiser usar um modelo básico em escala, você pode fazer isso sem sair do SageMaker usando notebooks pré-construídos de fornecedores de modelos. Como os modelos são hospedados e implantados na AWS, você pode ter certeza de que seus dados, sejam usados para avaliação ou para uso do modelo em escala, nunca serão compartilhados com terceiros.
Descubra o modelo Code Llama no SageMaker JumpStart
Para implantar o modelo Code Llama 70B, conclua as etapas a seguir em Estúdio Amazon SageMaker:
- Na página inicial do SageMaker Studio, escolha Acelerador no painel de navegação.
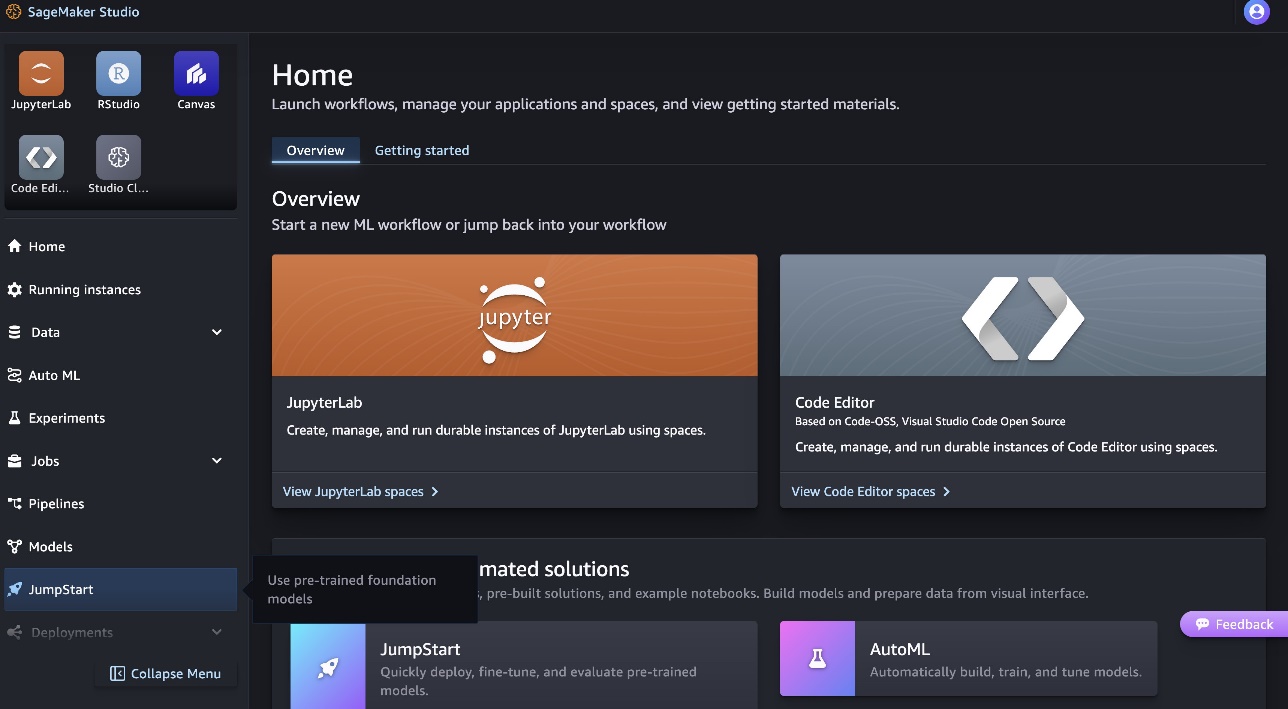
- Pesquise os modelos Code Llama e escolha o modelo Code Llama 70B na lista de modelos mostrada.
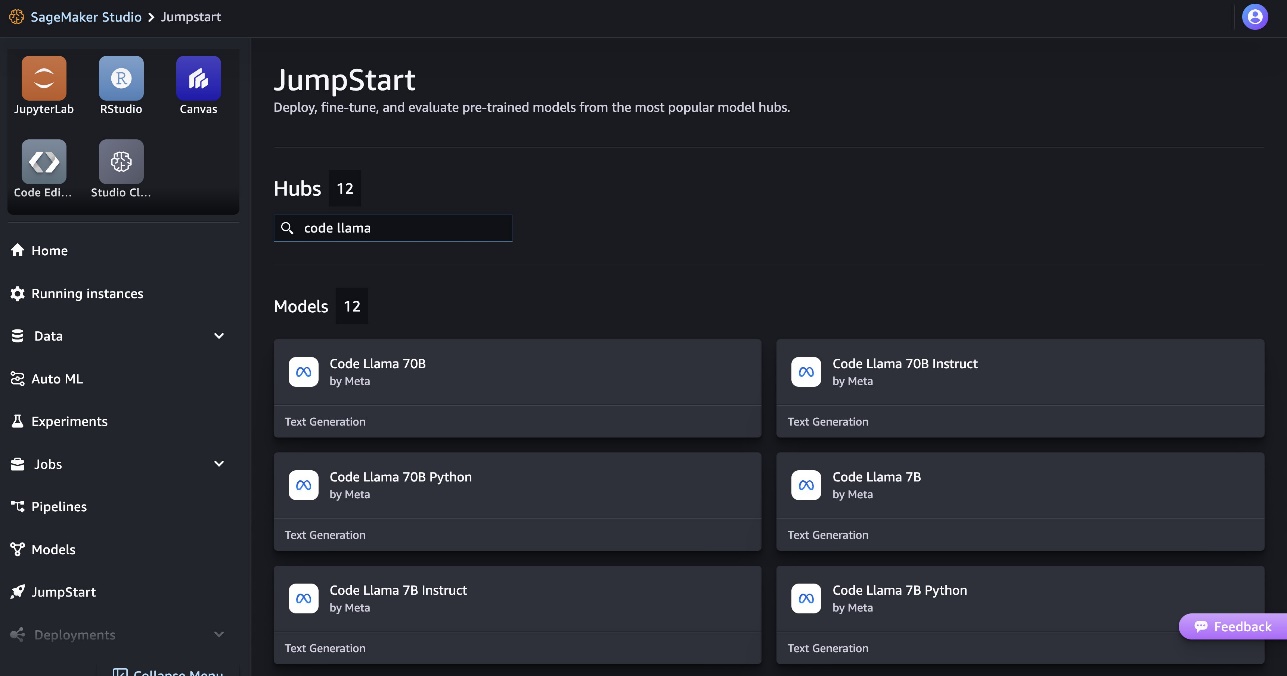
Você pode encontrar mais informações sobre o modelo na placa do modelo Code Llama 70B.
A captura de tela a seguir mostra as configurações do endpoint. Você pode alterar as opções ou usar as padrão.
- Aceite o Contrato de Licença do Usuário Final (EULA) e escolha Implantação.
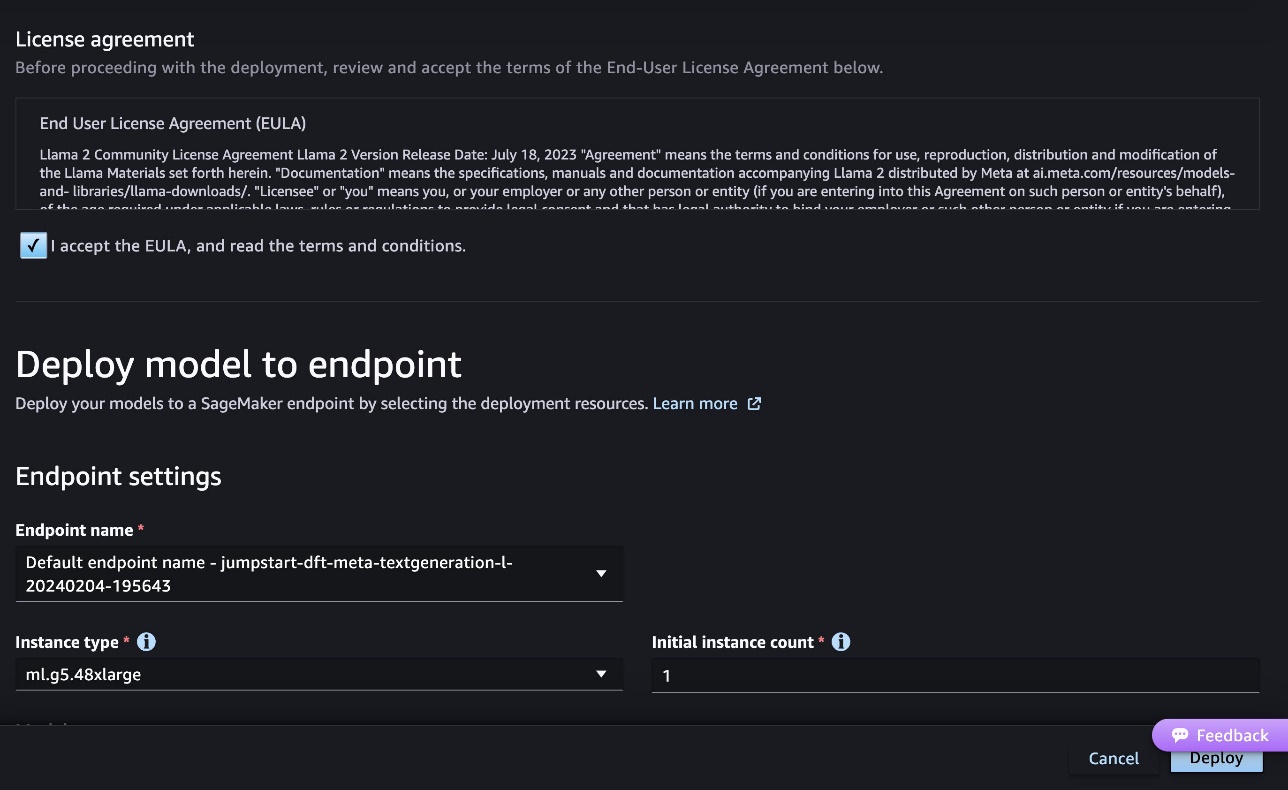
Isso iniciará o processo de implantação do endpoint, conforme mostrado na captura de tela a seguir.
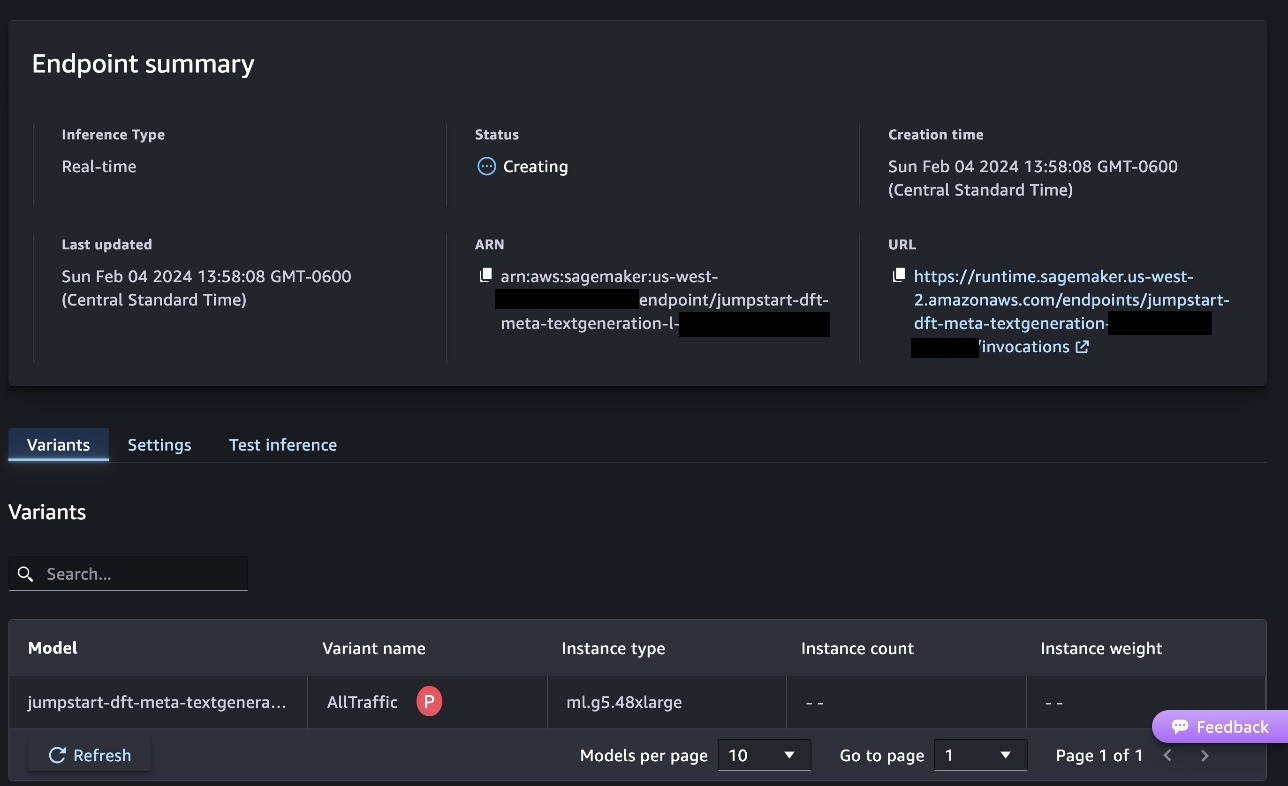
Implante o modelo com o SageMaker Python SDK
Como alternativa, você pode implantar por meio do notebook de exemplo escolhendo Abra o Notebook na página de detalhes do modelo do Classic Studio. O caderno de exemplo fornece orientação completa sobre como implantar o modelo para inferência e limpeza de recursos.
Para implantar usando notebook, começamos selecionando um modelo apropriado, especificado pelo model_id. Você pode implantar qualquer um dos modelos selecionados no SageMaker com o seguinte código:
Isso implanta o modelo no SageMaker com configurações padrão, incluindo tipo de instância padrão e configurações de VPC padrão. Você pode alterar essas configurações especificando valores não padrão em Modelo JumpStart. Observe que, por padrão, accept_eula está definido para False. Você precisa definir accept_eula=True para implantar o endpoint com sucesso. Ao fazer isso, você aceita o contrato de licença do usuário e a política de uso aceitável mencionados anteriormente. Você também pode download o contrato de licença.
Invocar um endpoint do SageMaker
Depois que o endpoint for implantado, você poderá realizar inferência usando Boto3 ou o SageMaker Python SDK. No código a seguir, usamos o SageMaker Python SDK para chamar o modelo para inferência e imprimir a resposta:
A função print_response pega uma carga útil que consiste na carga útil e na resposta do modelo e imprime a saída. Code Llama oferece suporte a muitos parâmetros ao realizar inferência:
- comprimento máximo – O modelo gera texto até que o comprimento de saída (que inclui o comprimento do contexto de entrada) atinja
max_length. Se especificado, deve ser um número inteiro positivo. - max_new_tokens – O modelo gera texto até que o comprimento de saída (excluindo o comprimento do contexto de entrada) atinja
max_new_tokens. Se especificado, deve ser um número inteiro positivo. - num_beams – Especifica o número de feixes usados na busca gananciosa. Se especificado, deve ser um número inteiro maior ou igual a
num_return_sequences. - no_repeat_ngram_size – O modelo garante que uma sequência de palavras de
no_repeat_ngram_sizenão é repetido na sequência de saída. Se especificado, deve ser um número inteiro positivo maior que 1. - temperatura – Isso controla a aleatoriedade na saída. Mais alto
temperatureresulta em uma sequência de saída com palavras de baixa probabilidade e menortemperatureresulta em uma sequência de saída com palavras de alta probabilidade. Setemperatureé 0, resulta em decodificação gananciosa. Se especificado, deve ser um ponto flutuante positivo. - Early_stopping - Se
True, a geração do texto termina quando todas as hipóteses de feixe atingem o token de final da frase. Se especificado, deve ser booleano. - do_sample - Se
True, o modelo amostra a próxima palavra de acordo com a probabilidade. Se especificado, deve ser booleano. - topo_k – Em cada etapa da geração de texto, o modelo faz amostras apenas do
top_kpalavras mais prováveis. Se especificado, deve ser um número inteiro positivo. - topo_p – Em cada etapa da geração de texto, o modelo amostra o menor conjunto possível de palavras com probabilidade cumulativa
top_p. Se especificado, deve ser um valor flutuante entre 0 e 1. - retorno_texto_completo - Se
True, o texto de entrada fará parte do texto gerado de saída. Se especificado, deve ser booleano. O valor padrão para isso éFalse. - Pare – Se especificado, deve ser uma lista de strings. A geração de texto é interrompida se qualquer uma das strings especificadas for gerada.
Você pode especificar qualquer subconjunto desses parâmetros ao invocar um terminal. A seguir, mostramos um exemplo de como invocar um endpoint com esses argumentos.
Conclusão de código
Os exemplos a seguir demonstram como executar o preenchimento de código onde a resposta esperada do terminal é a continuação natural do prompt.
Primeiro executamos o seguinte código:
Obtemos a seguinte saída:
Para nosso próximo exemplo, executamos o seguinte código:
Obtemos a seguinte saída:
Geração de código
Os exemplos a seguir mostram a geração de código Python usando Code Llama.
Primeiro executamos o seguinte código:
Obtemos a seguinte saída:
Para nosso próximo exemplo, executamos o seguinte código:
Obtemos a seguinte saída:
Estes são alguns exemplos de tarefas relacionadas ao código usando o Code Llama 70B. Você pode usar o modelo para gerar códigos ainda mais complicados. Incentivamos você a experimentá-lo usando seus próprios casos de uso e exemplos relacionados ao código!
limpar
Depois de testar os endpoints, exclua os endpoints de inferência do SageMaker e o modelo para evitar cobranças. Use o seguinte código:
Conclusão
Nesta postagem, apresentamos o Code Llama 70B no SageMaker JumpStart. Code Llama 70B é um modelo de última geração para gerar código a partir de prompts de linguagem natural, bem como de código. Você pode implantar o modelo com algumas etapas simples no SageMaker JumpStart e, em seguida, usá-lo para realizar tarefas relacionadas ao código, como geração e preenchimento de código. Na próxima etapa, tente usar o modelo com seus próprios casos de uso e dados relacionados ao código.
Sobre os autores
 Dr. é cientista aplicado da equipe Amazon SageMaker JumpStart. Seus interesses de pesquisa incluem algoritmos escaláveis de aprendizado de máquina, visão computacional, séries temporais, não paramétricos bayesianos e processos gaussianos. Seu doutorado é pela Duke University e publicou artigos em NeurIPS, Cell e Neuron.
Dr. é cientista aplicado da equipe Amazon SageMaker JumpStart. Seus interesses de pesquisa incluem algoritmos escaláveis de aprendizado de máquina, visão computacional, séries temporais, não paramétricos bayesianos e processos gaussianos. Seu doutorado é pela Duke University e publicou artigos em NeurIPS, Cell e Neuron.
 Dr. Farooq Sabir é arquiteto sênior de soluções de inteligência artificial e aprendizado de máquina da AWS. Ele possui doutorado e mestrado em Engenharia Elétrica pela Universidade do Texas em Austin e mestrado em Ciência da Computação pelo Georgia Institute of Technology. Ele tem mais de 15 anos de experiência profissional e também gosta de ensinar e orientar estudantes universitários. Na AWS, ele ajuda os clientes a formular e resolver seus problemas de negócios em ciência de dados, aprendizado de máquina, visão computacional, inteligência artificial, otimização numérica e domínios relacionados. Com sede em Dallas, Texas, ele e sua família adoram viajar e fazer longas viagens.
Dr. Farooq Sabir é arquiteto sênior de soluções de inteligência artificial e aprendizado de máquina da AWS. Ele possui doutorado e mestrado em Engenharia Elétrica pela Universidade do Texas em Austin e mestrado em Ciência da Computação pelo Georgia Institute of Technology. Ele tem mais de 15 anos de experiência profissional e também gosta de ensinar e orientar estudantes universitários. Na AWS, ele ajuda os clientes a formular e resolver seus problemas de negócios em ciência de dados, aprendizado de máquina, visão computacional, inteligência artificial, otimização numérica e domínios relacionados. Com sede em Dallas, Texas, ele e sua família adoram viajar e fazer longas viagens.
 junho ganhou é gerente de produto do SageMaker JumpStart. Ele se concentra em tornar os modelos básicos facilmente detectáveis e utilizáveis para ajudar os clientes a criar aplicativos generativos de IA. Sua experiência na Amazon também inclui aplicativos de compras móveis e entrega de última milha.
junho ganhou é gerente de produto do SageMaker JumpStart. Ele se concentra em tornar os modelos básicos facilmente detectáveis e utilizáveis para ajudar os clientes a criar aplicativos generativos de IA. Sua experiência na Amazon também inclui aplicativos de compras móveis e entrega de última milha.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/code-llama-70b-is-now-available-in-amazon-sagemaker-jumpstart/

