Grandes modelos de linguagem (LLMs) geralmente são treinados em grandes conjuntos de dados disponíveis publicamente que são independentes de domínio. Por exemplo, Lhama de Meta modelos são treinados em conjuntos de dados como Rastreamento comum, C4, Wikipédia e ArXiv. Esses conjuntos de dados abrangem uma ampla gama de tópicos e domínios. Embora os modelos resultantes produzam resultados surpreendentemente bons para tarefas gerais, como geração de texto e reconhecimento de entidades, há evidências de que modelos treinados com conjuntos de dados específicos de domínio podem melhorar ainda mais o desempenho do LLM. Por exemplo, os dados de treinamento usados para BloombergGPT é 51% de documentos específicos de domínio, incluindo notícias financeiras, registros e outros materiais financeiros. O LLM resultante supera os LLMs treinados em conjuntos de dados não específicos de domínio quando testados em tarefas específicas de finanças. Os autores de BloombergGPT concluíram que o seu modelo supera todos os outros modelos testados para quatro das cinco tarefas financeiras. O modelo proporcionou um desempenho ainda melhor quando testado para as tarefas financeiras internas da Bloomberg por uma ampla margem – até 60 pontos melhor (em 100). Embora você possa aprender mais sobre os resultados abrangentes da avaliação no papel, a seguinte amostra capturada do BloombergGPT O artigo pode dar uma ideia dos benefícios de treinar LLMs usando dados específicos de domínio financeiro. Conforme mostrado no exemplo, o modelo BloombergGPT forneceu respostas corretas, enquanto outros modelos não específicos de domínio tiveram dificuldades:
Esta postagem fornece um guia para treinar LLMs especificamente para o domínio financeiro. Cobrimos as seguintes áreas principais:
- Coleta e preparação de dados – Orientação sobre a obtenção e curadoria de dados financeiros relevantes para um treinamento de modelo eficaz
- Pré-treinamento contínuo vs. ajuste fino – Quando usar cada técnica para otimizar o desempenho do seu LLM
- Pré-treinamento contínuo eficiente – Estratégias para agilizar o processo contínuo de pré-formação, poupando tempo e recursos
Esta postagem reúne a experiência da equipe de pesquisa científica aplicada da Amazon Finance Technology e da equipe de especialistas mundiais da AWS para o setor financeiro global. Parte do conteúdo é baseado no artigo Pré-treinamento contínuo e eficiente para a construção de grandes modelos de linguagem específicos de domínio.
Coletando e preparando dados financeiros
O pré-treinamento contínuo do domínio precisa de um conjunto de dados em grande escala, de alta qualidade e específico do domínio. A seguir estão as principais etapas para curadoria de conjunto de dados de domínio:
- Identificar fontes de dados – Fontes de dados potenciais para corpus de domínio incluem web aberta, Wikipedia, livros, mídias sociais e documentos internos.
- Filtros de dados de domínio – Como o objetivo final é selecionar o corpus do domínio, talvez seja necessário aplicar etapas adicionais para filtrar amostras irrelevantes para o domínio de destino. Isso reduz o corpus inútil para pré-treinamento contínuo e reduz o custo de treinamento.
- Pré-processando – Você pode considerar uma série de etapas de pré-processamento para melhorar a qualidade dos dados e a eficiência do treinamento. Por exemplo, certas fontes de dados podem conter um número razoável de tokens ruidosos; a desduplicação é considerada uma etapa útil para melhorar a qualidade dos dados e reduzir custos de treinamento.
Para desenvolver LLMs financeiros, você pode usar duas fontes de dados importantes: News CommonCrawl e arquivos da SEC. Um arquivamento na SEC é uma demonstração financeira ou outro documento formal submetido à Comissão de Valores Mobiliários dos EUA (SEC). As empresas de capital aberto são obrigadas a apresentar vários documentos regularmente. Isso cria um grande número de documentos ao longo dos anos. Notícias CommonCrawl é um conjunto de dados lançado pela CommonCrawl em 2016. Ele contém artigos de notícias de sites de notícias de todo o mundo.
Notícias CommonCrawl está disponível em Serviço de armazenamento simples da Amazon (Amazon S3) no commoncrawl balde em crawl-data/CC-NEWS/. Você pode obter as listagens de arquivos usando o Interface de linha de comando da AWS (AWS CLI) e o seguinte comando:
In Pré-treinamento contínuo e eficiente para a construção de grandes modelos de linguagem específicos de domínio, os autores usam uma abordagem baseada em URL e palavras-chave para filtrar artigos de notícias financeiras de notícias genéricas. Especificamente, os autores mantêm uma lista de importantes veículos de notícias financeiras e um conjunto de palavras-chave relacionadas a notícias financeiras. Identificamos um artigo como notícia financeira se ele vier de meios de comunicação financeiros ou se alguma palavra-chave aparecer no URL. Essa abordagem simples, mas eficaz, permite identificar notícias financeiras não apenas de meios de comunicação financeiros, mas também de seções financeiras de meios de comunicação genéricos.
Os registros da SEC estão disponíveis on-line por meio do banco de dados EDGAR (Electronic Data Gathering, Analysis, and Retrieval) da SEC, que fornece acesso aberto aos dados. Você pode extrair os registros diretamente do EDGAR ou usar APIs em Amazon Sage Maker com algumas linhas de código, para qualquer período de tempo e para um grande número de tickers (ou seja, o identificador atribuído pela SEC). Para saber mais, consulte Recuperação de arquivamento SEC.
A tabela a seguir resume os principais detalhes de ambas as fontes de dados.
| . | Notícias CommonCrawl | Arquivo SEC |
| Cobertura | 2016-2022 | 1993-2022 |
| Tamanho | 25.8 bilhões de palavras | 5.1 bilhões de palavras |
Os autores passam por algumas etapas extras de pré-processamento antes que os dados sejam inseridos em um algoritmo de treinamento. Primeiro, observamos que os arquivos da SEC contêm texto ruidoso devido à remoção de tabelas e figuras, de modo que os autores removem frases curtas que são consideradas rótulos de tabelas ou figuras. Em segundo lugar, aplicamos um algoritmo de hashing sensível à localidade para desduplicar os novos artigos e arquivos. Para registros da SEC, desduplicamos no nível da seção, e não no nível do documento. Por último, concatenamos documentos em uma string longa, tokenizamos e dividimos a tokenização em pedaços de comprimento máximo de entrada suportado pelo modelo a ser treinado. Isso melhora o rendimento do pré-treinamento contínuo e reduz o custo do treinamento.
Pré-treinamento contínuo vs. ajuste fino
A maioria dos LLMs disponíveis são de uso geral e carecem de habilidades específicas de domínio. Os LLMs de domínio têm mostrado desempenho considerável nos domínios médico, financeiro ou científico. Para que um LLM adquira conhecimento específico de domínio, existem quatro métodos: treinamento do zero, pré-treinamento contínuo, ajuste fino de instruções em tarefas de domínio e geração aumentada de recuperação (RAG).
Nos modelos tradicionais, o ajuste fino geralmente é usado para criar modelos específicos de tarefas para um domínio. Isso significa manter vários modelos para diversas tarefas, como extração de entidades, classificação de intenções, análise de sentimento ou resposta a perguntas. Com o advento dos LLMs, a necessidade de manter modelos separados tornou-se obsoleta através do uso de técnicas como aprendizagem contextual ou prompts. Isso economiza o esforço necessário para manter uma pilha de modelos para tarefas relacionadas, mas distintas.
Intuitivamente, você pode treinar LLMs do zero com dados específicos do domínio. Embora a maior parte do trabalho para criar LLMs de domínio tenha se concentrado no treinamento do zero, ele é proibitivamente caro. Por exemplo, o modelo GPT-4 custa mais de $ 100 milhões treinar. Esses modelos são treinados em uma combinação de dados de domínio aberto e dados de domínio. O pré-treinamento contínuo pode ajudar os modelos a adquirir conhecimento específico do domínio sem incorrer no custo do pré-treinamento do zero, porque você pré-treina um LLM de domínio aberto existente apenas nos dados do domínio.
Com o ajuste fino de instruções em uma tarefa, você não pode fazer o modelo adquirir conhecimento de domínio porque o LLM adquire apenas informações de domínio contidas no conjunto de dados de ajuste fino de instruções. A menos que um grande conjunto de dados para ajuste fino de instruções seja usado, não será suficiente adquirir conhecimento do domínio. Obter conjuntos de dados de instruções de alta qualidade geralmente é um desafio e é a razão para usar LLMs em primeiro lugar. Além disso, o ajuste fino das instruções em uma tarefa pode afetar o desempenho em outras tarefas (como visto em Neste artigo). No entanto, o ajuste fino da instrução é mais rentável do que qualquer uma das alternativas de pré-treinamento.
A figura a seguir compara o ajuste fino específico da tarefa tradicional. vs paradigma de aprendizagem em contexto com LLMs.
 RAG é a forma mais eficaz de orientar um LLM para gerar respostas baseadas em um domínio. Embora possa orientar um modelo para gerar respostas, fornecendo fatos do domínio como informações auxiliares, ele não adquire a linguagem específica do domínio porque o LLM ainda depende do estilo de linguagem fora do domínio para gerar as respostas.
RAG é a forma mais eficaz de orientar um LLM para gerar respostas baseadas em um domínio. Embora possa orientar um modelo para gerar respostas, fornecendo fatos do domínio como informações auxiliares, ele não adquire a linguagem específica do domínio porque o LLM ainda depende do estilo de linguagem fora do domínio para gerar as respostas.
O pré-treinamento contínuo é um meio-termo entre o pré-treinamento e o ajuste fino da instrução em termos de custo, ao mesmo tempo que é uma forte alternativa para adquirir conhecimento e estilo específicos de um domínio. Ele pode fornecer um modelo geral sobre o qual o ajuste fino adicional de instruções em dados de instrução limitados pode ser realizado. O pré-treinamento contínuo pode ser uma estratégia econômica para domínios especializados onde o conjunto de tarefas posteriores é grande ou desconhecido e os dados de ajuste de instruções rotuladas são limitados. Em outros cenários, o ajuste fino de instruções ou RAG pode ser mais adequado.
Para saber mais sobre ajuste fino, RAG e treinamento de modelo, consulte Ajustar um modelo de base, Geração Aumentada de Recuperação (RAG) e Treinar um modelo com o Amazon SageMaker, respectivamente. Para esta postagem, nos concentramos no pré-treinamento contínuo e eficiente.
Metodologia de pré-treinamento contínuo eficiente
O pré-treinamento contínuo consiste na seguinte metodologia:
- Pré-treinamento contínuo adaptativo de domínio (DACP) - No papel Pré-treinamento contínuo e eficiente para a construção de grandes modelos de linguagem específicos de domínio, os autores pré-treinam continuamente o conjunto de modelos da linguagem Pythia no corpus financeiro para adaptá-lo ao domínio financeiro. O objetivo é criar LLMs financeiros, alimentando dados de todo o domínio financeiro num modelo de código aberto. Como o corpus de formação contém todos os conjuntos de dados selecionados no domínio, o modelo resultante deve adquirir conhecimentos específicos de finanças, tornando-se assim um modelo versátil para diversas tarefas financeiras. Isso resulta em modelos FinPythia.
- Pré-treinamento contínuo adaptativo à tarefa (TACP) – Os autores pré-treinam os modelos ainda mais em dados de tarefas rotulados e não rotulados para adaptá-los para tarefas específicas. Em certas circunstâncias, os desenvolvedores podem preferir modelos que proporcionem melhor desempenho em um grupo de tarefas no domínio, em vez de um modelo genérico de domínio. O TACP foi concebido como um pré-treinamento contínuo com o objetivo de melhorar o desempenho em tarefas específicas, sem requisitos de dados rotulados. Especificamente, os autores pré-treinam continuamente os modelos de código aberto nos tokens de tarefa (sem rótulos). A principal limitação do TACP reside na construção de LLMs específicos para tarefas em vez de LLMs básicos, devido ao uso exclusivo de dados de tarefas não rotulados para treinamento. Embora o DACP utilize um corpus muito maior, é proibitivamente caro. Para equilibrar essas limitações, os autores propõem duas abordagens que visam construir LLMs básicos de domínio específico, preservando ao mesmo tempo um desempenho superior nas tarefas alvo:
- DACP eficiente para tarefas semelhantes (ETS-DACP) – Os autores propõem selecionar um subconjunto de corpus financeiro que seja altamente semelhante aos dados da tarefa usando similaridade de incorporação. Este subconjunto é usado para pré-treinamento contínuo para torná-lo mais eficiente. Especificamente, os autores pré-treinam continuamente o LLM de código aberto em um pequeno corpus extraído do corpus financeiro que está próximo das tarefas alvo na distribuição. Isso pode ajudar a melhorar o desempenho das tarefas porque adotamos o modelo para a distribuição de tokens de tarefas, apesar de os dados rotulados não serem necessários.
- DACP eficiente e independente de tarefas (ETA-DACP) – Os autores propõem o uso de métricas como perplexidade e entropia do tipo token que não requerem dados de tarefas para selecionar amostras do corpus financeiro para um pré-treinamento contínuo e eficiente. Essa abordagem foi projetada para lidar com cenários onde os dados da tarefa não estão disponíveis ou onde modelos de domínio mais versáteis para o domínio mais amplo são preferidos. Os autores adotam duas dimensões para selecionar amostras de dados importantes para a obtenção de informações de domínio de um subconjunto de dados de domínio pré-treinamento: novidade e diversidade. A novidade, medida pela perplexidade registrada pelo modelo alvo, refere-se às informações que antes não eram vistas pelo LLM. Dados com alta novidade indicam conhecimento novo para o LLM, e tais dados são vistos como mais difíceis de aprender. Isso atualiza LLMs genéricos com conhecimento intensivo de domínio durante o pré-treinamento contínuo. A diversidade, por outro lado, captura a diversidade de distribuições de tipos de tokens no corpus de domínio, o que foi documentado como um recurso útil na pesquisa de aprendizagem curricular em modelagem de linguagem.
A figura a seguir compara um exemplo de ETS-DACP (esquerda) com ETA-DACP (direita).

Adotamos dois esquemas de amostragem para selecionar ativamente pontos de dados do corpus financeiro selecionado: amostragem rígida e amostragem suave. O primeiro é feito classificando primeiro o corpus financeiro pelas métricas correspondentes e depois selecionando as k principais amostras, onde k é predeterminado de acordo com o orçamento de treinamento. Para este último, os autores atribuem pesos amostrais para cada ponto de dados de acordo com os valores da métrica e, em seguida, amostram aleatoriamente k pontos de dados para atender ao orçamento de treinamento.
Resultado e análise
Os autores avaliam os LLMs financeiros resultantes em uma série de tarefas financeiras para investigar a eficácia do pré-treinamento contínuo:
- Banco de frases financeiras – Uma tarefa de classificação de sentimentos sobre notícias financeiras.
- FiQA SA – Uma tarefa de classificação de sentimento baseada em aspectos com base em notícias e manchetes financeiras.
- Manchete – Uma tarefa de classificação binária sobre se um título de uma entidade financeira contém determinadas informações.
- NER – Uma tarefa de extração de entidade financeira nomeada com base na seção de avaliação de risco de crédito dos relatórios da SEC. As palavras nesta tarefa são anotadas com PER, LOC, ORG e MISC.
Como os LLMs financeiros são instruídos com ajuste fino, os autores avaliam modelos em uma configuração de 5 tentativas para cada tarefa por uma questão de robustez. Em média, o FinPythia 6.9B supera o Pythia 6.9B em 10% em quatro tarefas, o que demonstra a eficácia do pré-treinamento contínuo específico do domínio. Para o modelo 1B, a melhoria é menos profunda, mas o desempenho ainda melhora 2% em média.
A figura a seguir ilustra a diferença de desempenho antes e depois do DACP em ambos os modelos.

A figura a seguir mostra dois exemplos qualitativos gerados pelo Pythia 6.9B e FinPythia 6.9B. Para duas questões relacionadas a finanças relacionadas a um gestor investidor e um termo financeiro, o Pythia 6.9B não entende o termo nem reconhece o nome, enquanto o FinPythia 6.9B gera respostas detalhadas corretamente. Os exemplos qualitativos demonstram que a pré-formação contínua permite que os LLMs adquiram conhecimentos de domínio durante o processo.

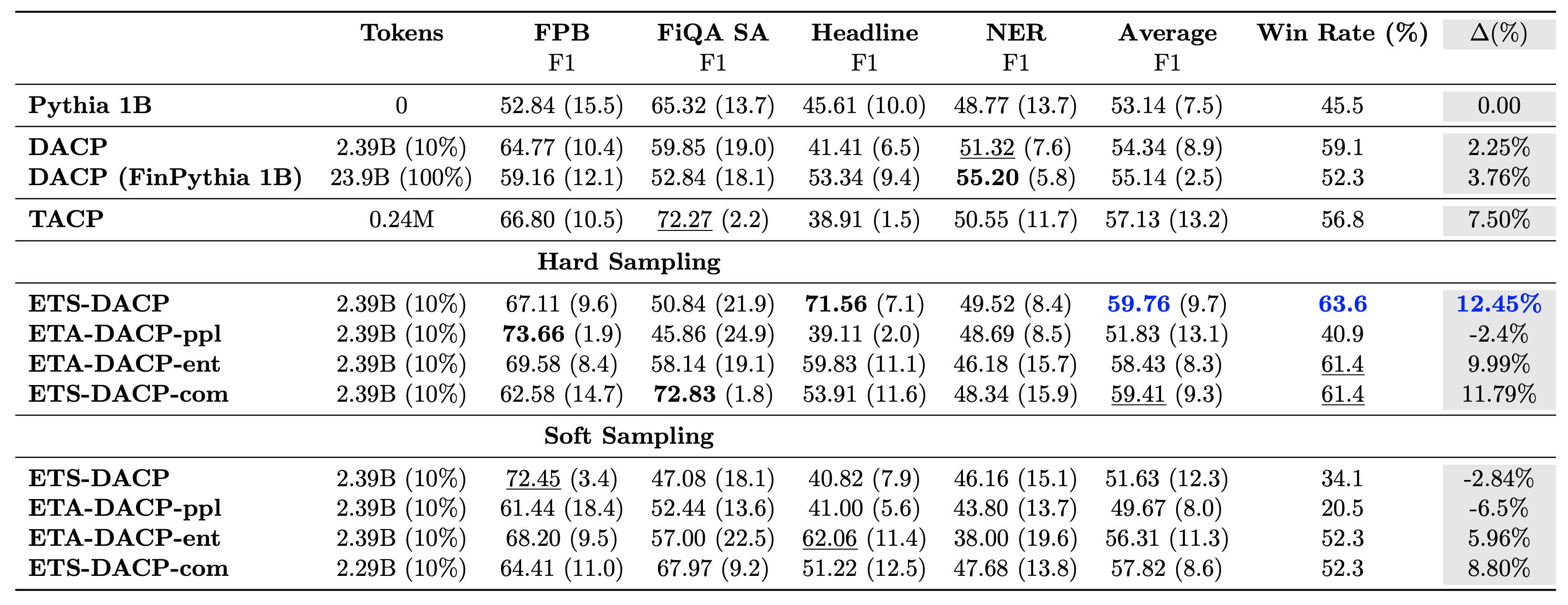
A tabela a seguir compara várias abordagens eficientes de pré-treinamento contínuo. ETA-DACP-ppl é ETA-DACP baseado na perplexidade (novidade), e ETA-DACP-ent é baseado na entropia (diversidade). ETS-DACP-com é semelhante ao DACP com seleção de dados calculando a média de todas as três métricas. A seguir estão algumas conclusões dos resultados:
- Os métodos de seleção de dados são eficientes – Eles superam o pré-treinamento contínuo padrão com apenas 10% dos dados de treinamento. Pré-treinamento contínuo e eficiente, incluindo DACP de tarefa semelhante (ETS-DACP), DACP independente de tarefa baseado em entropia (ESA-DACP-ent) e DACP de tarefa semelhante baseado em todas as três métricas (ETS-DACP-com) supera o DACP padrão em média, apesar de terem formação em apenas 10% do corpus financeiro.
- A seleção de dados com reconhecimento de tarefa funciona melhor de acordo com a pesquisa de modelos de linguagem pequena – ETS-DACP registra o melhor desempenho médio entre todos os métodos e, com base nas três métricas, registra o segundo melhor desempenho da tarefa. Isto sugere que o uso de dados de tarefas não rotulados ainda é uma abordagem eficaz para aumentar o desempenho das tarefas no caso de LLMs.
- A seleção de dados independente de tarefa está em segundo lugar – ESA-DACP-ent segue o desempenho da abordagem de seleção de dados conscientes de tarefas, o que implica que ainda poderíamos aumentar o desempenho das tarefas selecionando ativamente amostras de alta qualidade não vinculadas a tarefas específicas. Isso abre caminho para a construção de LLMs financeiros para todo o domínio, ao mesmo tempo que alcança um desempenho superior nas tarefas.
Uma questão crítica em relação ao pré-treinamento contínuo é se ele afeta negativamente o desempenho em tarefas fora do domínio. Os autores também avaliam o modelo continuamente pré-treinado em quatro tarefas genéricas amplamente utilizadas: ARC, MMLU, TruthQA e HellaSwag, que medem a capacidade de resposta, raciocínio e conclusão de perguntas. Os autores descobriram que o pré-treinamento contínuo não afeta negativamente o desempenho fora do domínio. Para mais detalhes, consulte Pré-treinamento contínuo e eficiente para a construção de grandes modelos de linguagem específicos de domínio.
Conclusão
Esta postagem ofereceu insights sobre a coleta de dados e estratégias contínuas de pré-treinamento para treinar LLMs no domínio financeiro. Você pode começar a treinar seus próprios LLMs para tarefas financeiras usando Treinamento Amazon SageMaker or Rocha Amazônica hoje mesmo.
Sobre os autores
 Yong Xie é um cientista aplicado na Amazon FinTech. Ele se concentra no desenvolvimento de grandes modelos de linguagem e aplicações de IA generativa para finanças.
Yong Xie é um cientista aplicado na Amazon FinTech. Ele se concentra no desenvolvimento de grandes modelos de linguagem e aplicações de IA generativa para finanças.
 Karan Aggarwal é cientista aplicado sênior da Amazon FinTech com foco em IA generativa para casos de uso financeiro. Karan tem ampla experiência em análise de séries temporais e PNL, com interesse particular em aprender com dados rotulados limitados
Karan Aggarwal é cientista aplicado sênior da Amazon FinTech com foco em IA generativa para casos de uso financeiro. Karan tem ampla experiência em análise de séries temporais e PNL, com interesse particular em aprender com dados rotulados limitados
 Aitzaz Ahmad é gerente de ciências aplicadas na Amazon, onde lidera uma equipe de cientistas que desenvolvem diversas aplicações de aprendizado de máquina e IA generativa em finanças. Seus interesses de pesquisa são em PNL, IA Generativa e Agentes LLM. Ele recebeu seu PhD em Engenharia Elétrica pela Texas A&M University.
Aitzaz Ahmad é gerente de ciências aplicadas na Amazon, onde lidera uma equipe de cientistas que desenvolvem diversas aplicações de aprendizado de máquina e IA generativa em finanças. Seus interesses de pesquisa são em PNL, IA Generativa e Agentes LLM. Ele recebeu seu PhD em Engenharia Elétrica pela Texas A&M University.
 Qingwei Li é especialista em aprendizado de máquina na Amazon Web Services. Ele recebeu seu Ph.D. em Pesquisa Operacional depois de quebrar a conta da bolsa de pesquisa de seu orientador e não entregar o Prêmio Nobel que havia prometido. Atualmente, ele ajuda clientes de serviços financeiros a criar soluções de machine learning na AWS.
Qingwei Li é especialista em aprendizado de máquina na Amazon Web Services. Ele recebeu seu Ph.D. em Pesquisa Operacional depois de quebrar a conta da bolsa de pesquisa de seu orientador e não entregar o Prêmio Nobel que havia prometido. Atualmente, ele ajuda clientes de serviços financeiros a criar soluções de machine learning na AWS.
 Raghvender Arni lidera a Equipe de Aceleração de Clientes (CAT) nas Indústrias AWS. O CAT é uma equipe multifuncional global de arquitetos de nuvem voltados para o cliente, engenheiros de software, cientistas de dados e especialistas e designers de IA/ML que impulsionam a inovação por meio de prototipagem avançada e impulsionam a excelência operacional em nuvem por meio de conhecimento técnico especializado.
Raghvender Arni lidera a Equipe de Aceleração de Clientes (CAT) nas Indústrias AWS. O CAT é uma equipe multifuncional global de arquitetos de nuvem voltados para o cliente, engenheiros de software, cientistas de dados e especialistas e designers de IA/ML que impulsionam a inovação por meio de prototipagem avançada e impulsionam a excelência operacional em nuvem por meio de conhecimento técnico especializado.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

