Esta postagem foi co-escrita com Justin Miles, Liv d'Aliberti e Joe Kovba da Leidos.
Leidos é líder em soluções de ciência e tecnologia da Fortune 500 e trabalha para enfrentar alguns dos desafios mais difíceis do mundo nos mercados de defesa, inteligência, segurança interna, civil e de saúde. Nesta postagem, discutimos como Leidos trabalhou com a AWS para desenvolver uma abordagem para inferência de modelo de linguagem grande (LLM) com preservação de privacidade usando Enclaves AWS Nitro.
Os LLMs são projetados para compreender e gerar uma linguagem semelhante à humana e são usados em muitos setores, incluindo governo, saúde, financeiro e propriedade intelectual. LLMs têm ampla aplicabilidade, incluindo chatbots, geração de conteúdo, tradução de idiomas, análise de sentimentos, sistemas de resposta a perguntas, mecanismos de pesquisa e geração de código. A introdução de inferência baseada em LLM em um sistema também tem o potencial de introduzir ameaças à privacidade, incluindo exfiltração de modelos, violações de privacidade de dados e manipulação não intencional de serviços baseados em LLM. Arquiteturas técnicas precisam ser implementadas para garantir que os LLMs não exponham informações confidenciais durante a inferência.
Esta postagem discute como o Nitro Enclaves pode ajudar a proteger implantações de modelos LLM, especificamente aquelas que usam informações de identificação pessoal (PII) ou informações de saúde protegidas (PHI). Esta postagem tem apenas fins educacionais e não deve ser usada em ambientes de produção sem controles adicionais.
Visão geral de LLMs e Nitro Enclaves
Um caso de uso potencial é um chatbot de consulta confidencial baseado em LLM, projetado para realizar um serviço de perguntas e respostas contendo PII e PHI. A maioria das soluções atuais de chatbot LLM informa explicitamente aos usuários que eles não devem incluir PII ou PHI ao inserir perguntas devido a questões de segurança. Para mitigar essas preocupações e proteger os dados dos clientes, os proprietários de serviços contam principalmente com proteções do usuário, como as seguintes:
- Redação – O processo de identificação e ocultação de informações confidenciais, como PII, em documentos, textos ou outras formas de conteúdo. Isso pode ser feito com dados de entrada antes de serem enviados para um modelo ou LLM treinado para redigir suas respostas automaticamente.
- Autenticação multifatores – Um processo de segurança que exige que os usuários forneçam vários métodos de autenticação para verificar sua identidade e obter acesso ao LLM.
- Transport Layer Security (TLS) – Um protocolo criptográfico que fornece comunicação segura que aumenta a privacidade dos dados em trânsito entre os usuários e o serviço LLM.
Embora estas práticas melhorem a postura de segurança do serviço, não são suficientes para salvaguardar todas as informações sensíveis do utilizador e outras informações sensíveis que podem persistir sem o conhecimento do utilizador.
Em nosso caso de uso de exemplo, um serviço LLM foi projetado para responder a perguntas sobre benefícios de saúde de funcionários ou fornecer um plano de aposentadoria pessoal. Vamos analisar o exemplo de arquitetura a seguir e identificar áreas de risco à privacidade de dados.
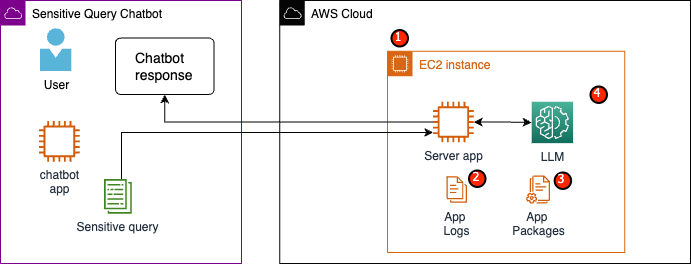
Figura 1 – Diagrama de áreas de risco de privacidade de dados
As áreas de risco potencial são as seguintes:
- Usuários privilegiados têm acesso à instância que hospeda o servidor. Alterações não intencionais ou não autorizadas no serviço podem resultar na exposição de dados confidenciais de maneiras não intencionais.
- Os usuários devem confiar que o serviço não exporá ou reterá informações confidenciais nos logs de aplicativos.
- Alterações nos pacotes de aplicativos podem causar alterações no serviço, resultando na exposição de dados confidenciais.
- Usuários privilegiados com acesso à instância têm acesso irrestrito ao LLM usado pelo serviço. As alterações podem fazer com que informações incorretas ou imprecisas sejam devolvidas aos usuários.
Nitro Enclaves fornece isolamento adicional ao seu Amazon Elastic Compute Nuvem (Amazon EC2), protegendo os dados em uso contra acesso não autorizado, incluindo usuários de nível administrativo. Na arquitetura anterior, é possível que uma alteração não intencional resulte na persistência de dados confidenciais em texto simples e seja acidentalmente revelada a um usuário que talvez não precise acessar esses dados. Com o Nitro Enclaves, você cria um ambiente isolado da sua instância EC2, permitindo alocar recursos de CPU e memória para o enclave. Este enclave é uma máquina virtual altamente restritiva. Ao executar o código que lida com dados confidenciais dentro do enclave, nenhum dos processos pai poderá visualizar os dados do enclave.
Nitro Enclaves oferece os seguintes benefícios:
- Isolamento de memória e CPU – Ele depende do hipervisor Nitro para isolar a CPU e a memória do enclave de usuários, aplicativos e bibliotecas na instância pai. Esse recurso ajuda a isolar o enclave e seu software e reduz significativamente a área de superfície para eventos não intencionais.
- Máquina virtual separada – Enclaves são máquinas virtuais separadas conectadas a uma instância EC2 para proteger ainda mais e processar com segurança dados altamente confidenciais.
- Sem acesso interativo – Os enclaves fornecem apenas conectividade de soquete local segura com sua instância pai. Eles não possuem armazenamento persistente, acesso interativo ou rede externa.
- Atestado criptográfico – Ofertas Nitro Enclaves atestado criptográfico, um processo usado para provar a identidade de um enclave e verificar se apenas o código autorizado está em execução no seu enclave.
- Integração AWS – Nitro Enclaves está integrado com Serviço de gerenciamento de chaves AWS (AWS KMS), permitindo descriptografar arquivos que foram criptografados usando AWS KMS dentro do enclave. Gerenciador de certificados da AWS (ACM) para Nitro Enclaves permite que você use certificados SSL/TLS públicos e privados com seus aplicativos web e servidores em execução em instâncias EC2 com Nitro Enclaves.
Você pode usar esses recursos fornecidos pelo Nitro Enclaves para ajudar a mitigar os riscos associados aos dados PII e PHI. Recomendamos incluir Nitro Enclaves em um serviço LLM ao lidar com dados confidenciais do usuário.
Visão geral da solução
Vamos examinar a arquitetura do serviço de exemplo, agora incluindo Nitro Enclaves. Ao incorporar Nitro Enclaves, conforme mostrado na figura a seguir, o LLM se torna um chatbot mais seguro para lidar com dados PHI ou PII.
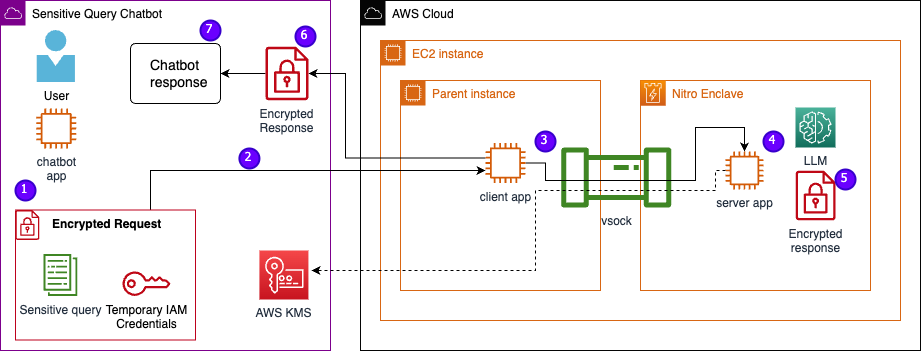
Figura 2 – Diagrama de visão geral da solução
Os dados do usuário, incluindo PII, PHI e perguntas, permanecem criptografados durante todo o processo de solicitação e resposta quando o aplicativo está hospedado em um enclave. As etapas realizadas durante a inferência são as seguintes:
- O aplicativo chatbot gera credenciais temporárias da AWS e pede ao usuário para inserir uma pergunta. A pergunta, que pode conter PII ou PHI, é então criptografada via AWS KMS. A entrada criptografada do usuário é combinada com as credenciais temporárias para criar a solicitação criptografada.
- Os dados criptografados são enviados para um servidor HTTP hospedado pelo Flask como uma solicitação POST. Antes de aceitar dados confidenciais, este endpoint deve ser configurado para HTTPs.
- O aplicativo cliente recebe a solicitação POST e a encaminha por meio de um canal local seguro (por exemplo, vsock) para o aplicativo servidor em execução dentro do Nitro Enclaves.
- O aplicativo do servidor Nitro Enclaves usa as credenciais temporárias para descriptografar a solicitação, consulta o LLM e gera a resposta. As configurações específicas do modelo são armazenadas nos enclaves e protegidas com atestado criptográfico.
- O aplicativo do servidor usa as mesmas credenciais temporárias para criptografar a resposta.
- A resposta criptografada é retornada ao aplicativo chatbot por meio do aplicativo cliente como uma resposta da solicitação POST.
- O aplicativo chatbot descriptografa a resposta usando sua chave KMS e exibe o texto simples ao usuário.
Pré-requisitos
Antes de começarmos, você precisa dos seguintes pré-requisitos para implantar a solução:
Configurar uma instância EC2
Conclua as etapas a seguir para configurar uma instância do EC2:
- Lançar um r5.8xgrande Instância EC2 usando o amzn2-ami-kernel-5.10-hvm-2.0.20230628.0-x86_64-gp2 AMI com Nitro Enclaves habilitados.
- Instale a CLI do Nitro Enclaves para criar e executar aplicativos Nitro Enclaves:
sudo amazon-linux-extras install aws-nitro-enclaves-cli -ysudo yum install aws-nitro-enclaves-cli-devel -y
- Verifique a instalação da CLI do Nitro Enclaves:
nitro-cli –version- A versão usada neste post é 1.2.2
- Instale o Git e o Docker para criar imagens do Docker e baixe o aplicativo do GitHub. Adicione o usuário da sua instância ao grupo Docker ( é o usuário da sua instância do IAM):
sudo yum install git -ysudo usermod -aG ne <USER>sudo usermod -aG docker <USER>sudo systemctl start docker && sudo systemctl enable docker
- Inicie e ative o alocador Nitro Enclaves e os serviços de proxy vsock:
sudo systemctl start nitro-enclaves-allocator.service && sudo systemctl enable nitro-enclaves-allocator.servicesudo systemctl start nitro-enclaves-vsock-proxy.service && sudo systemctl enable nitro-enclaves-vsock-proxy.service
O Nitro Enclaves usa uma conexão de soquete local chamada vsock para criar um canal seguro entre a instância pai e o enclave.
Depois que todos os serviços forem iniciados e habilitados, reinicie a instância para verificar se todos os grupos de usuários e serviços estão funcionando corretamente:
sudo shutdown -r now
Configurar o serviço de alocador do Nitro Enclaves
Nitro Enclaves é um ambiente isolado que designa uma parte da CPU e memória da instância para executar o enclave. Com o serviço alocador Nitro Enclaves, você pode indicar quantas CPUs e quanta memória será retirada da instância pai para executar o enclave.
Modifique os recursos reservados do enclave usando um editor de texto (para nossa solução, alocamos 8 CPU e 70,000 MiB de memória para fornecer recursos suficientes):
vi /etc/nitro_enclaves/allocatory.yaml
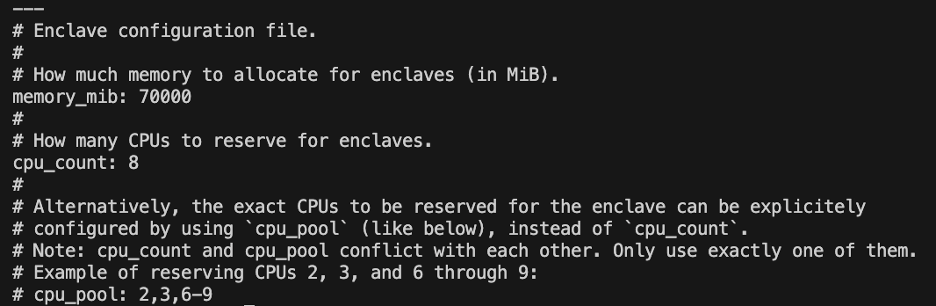
Figura 3 – Configuração do serviço AWS Nitro Enclaves Allocator
Clonar o projeto
Depois de configurar a instância do EC2, você pode fazer download do código para executar o chatbot confidencial com um LLM dentro do Nitro Enclaves.
Você precisa atualizar o server.py arquivo com o ID da chave KMS apropriado que você criou no início para criptografar a resposta LLM.
- Clone o projeto GitHub:
cd ~/ && git clone https://<THE_REPO.git>
- Navegue até a pasta do projeto para construir o
enclave_baseImagem Docker que contém o Kit de desenvolvimento de software Nitro Enclaves (SDK) para documentos de atestado criptográfico do hipervisor Nitro (esta etapa pode levar até 15 minutos):cd /nitro_llm/enclave_basedocker build ./ -t “enclave_base”
Salve o LLM na instância EC2
Estamos usando o Bloom 560m LLM de código aberto para processamento de linguagem natural para gerar respostas. Este modelo não está ajustado para PII e PHI, mas demonstra como um LLM pode viver dentro de um enclave. O modelo também precisa ser salvo na instância pai para que possa ser copiado para o enclave por meio do Dockerfile.
- Navegue até o projeto:
cd /nitro_llm
- Instale os requisitos necessários para salvar o modelo localmente:
pip3 install requirements.txt
- execute o
save_model.pyaplicativo para salvar o modelo dentro do/nitro_llm/enclave/bloomdiretório:python3 save_model.py
Crie e execute a imagem do Nitro Enclaves
Para executar o Nitro Enclaves, você precisa criar um arquivo de imagem de enclave (EIF) a partir de uma imagem Docker do seu aplicativo. O Dockerfile localizado no diretório do enclave contém os arquivos, o código e o LLM que serão executados dentro do enclave.
A construção e a execução do enclave levarão vários minutos para serem concluídas.
- Navegue até a raiz do projeto:
cd /nitro_llm
- Construa o arquivo de imagem do enclave como
enclave.eif:nitro-cli build-enclave --docker-uri enclave:latest --output-file enclave.eif
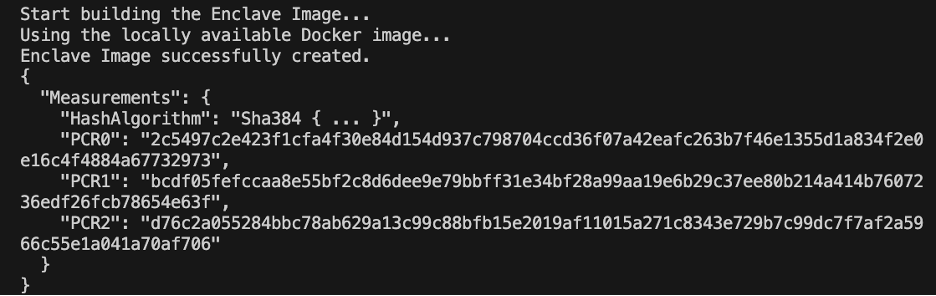
Figura 4 – Resultado da construção do AWS Nitro Enclaves
Quando o enclave for construído, uma série de hashes exclusivos e registros de configuração de plataforma (PCRs) serão criados. Os PCRs são uma medida contígua para comprovar a identidade do hardware e da aplicação. Esses PCRs serão necessários para atestado criptográfico e usados durante a etapa de atualização da política de chaves KMS.
- Execute o enclave com os recursos do
allocator.service(adicionando o--attach-consoleargumento no final executará o enclave no modo de depuração):nitro-cli run-enclave --cpu-count 8 --memory 70000 --enclave-cid 16 --eif-path enclave.eif
Você precisa alocar pelo menos quatro vezes o tamanho do arquivo EIF. Isto pode ser modificado no allocator.service das etapas anteriores.
- Verifique se o enclave está em execução com o seguinte comando:
nitro-cli describe-enclaves
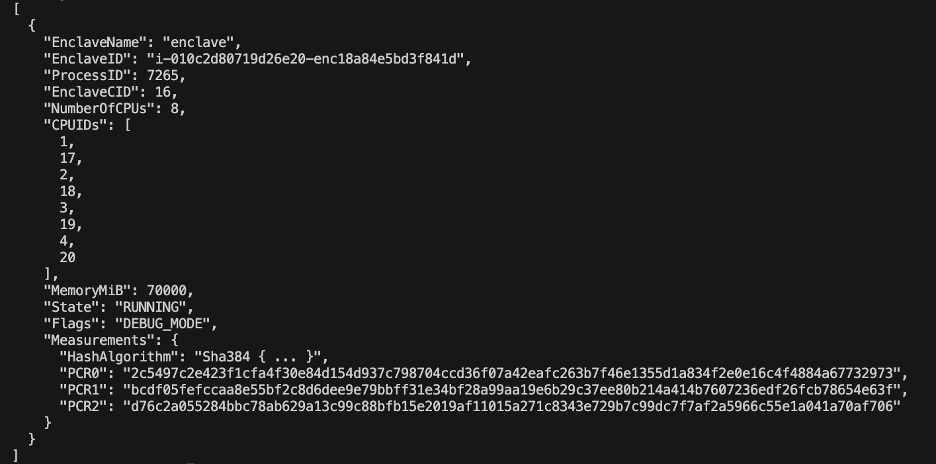
Figura 5 – Comando de descrição do AWS Nitro Enclave
Atualizar a política de chaves KMS
Conclua as etapas a seguir para atualizar sua política de chaves KMS:
- No console do AWS KMS, escolha Chaves gerenciadas pelo cliente no painel de navegação.
- Procure a chave que você gerou como pré-requisito.
- Escolha Editar sobre a política-chave.
- Atualize a política principal com as seguintes informações:
- ID da sua conta
- Seu nome de usuário IAM
- A função atualizada da instância do ambiente Cloud9
- Opções
kms:Encryptekms:Decrypt - Enclave PCRs (por exemplo, PCR0, PCR1, PCR2) em sua política de chave com uma declaração de condição
Consulte o seguinte código de política principal:
Salve o aplicativo chatbot
Para imitar um aplicativo de chatbot de consulta confidencial que reside fora da conta da AWS, você precisa salvar o chatbot.py app e execute-o dentro do ambiente Cloud9. Seu ambiente Cloud9 usará sua função de instância para credenciais temporárias para desassociar permissões do EC2 que executa o enclave. Conclua as seguintes etapas:
- No console Cloud9, abra o ambiente que você criou.
- Copie o código a seguir em um novo arquivo como
chatbot.pyno diretório principal. - Instale os módulos necessários:
pip install boto3Pip install requests
- No console do Amazon EC2, observe o IP associado à sua instância do Nitro Enclaves.
- Atualize a variável URL em
http://<ec2instanceIP>:5001.
- Execute o aplicativo chatbot:
-
python3 chat.py
Quando estiver em execução, o terminal solicitará a entrada do usuário e seguirá o diagrama arquitetônico anterior para gerar uma resposta segura.
Execute o chatbot privado de perguntas e respostas
Agora que o Nitro Enclaves está instalado e funcionando na instância EC2, você pode fazer perguntas sobre PHI e PII ao seu chatbot com mais segurança. Vejamos um exemplo.
Dentro do ambiente Cloud9, fazemos uma pergunta ao nosso chatbot e fornecemos nosso nome de usuário.
Figura 6 – Fazendo uma pergunta ao Chat Bot
O AWS KMS criptografa a pergunta, que se parece com a captura de tela a seguir.

Figura 7 – Pergunta Criptografada
Em seguida, ele é enviado ao enclave e solicitado ao LLM seguro. A pergunta e a resposta do LLM serão semelhantes à captura de tela a seguir (o resultado e a resposta criptografada são visíveis dentro do enclave apenas no modo de depuração).

Figura 8 – Resposta do LLM
O resultado é então criptografado usando AWS KMS e retornado ao ambiente Cloud9 para ser descriptografado.
Figura 9 – Resposta final descriptografada
limpar
Conclua as etapas a seguir para limpar seus recursos:
- Pare a instância do EC2 criada para hospedar seu enclave.
- Exclua o ambiente Cloud9.
- Exclua a chave KMS.
- Remova a função de instância do EC2 e as permissões de usuário do IAM.
Conclusão
Nesta postagem, mostramos como usar o Nitro Enclaves para implantar um serviço de perguntas e respostas LLM que envia e recebe informações de PII e PHI com mais segurança. Isso foi implantado no Amazon EC2 e os enclaves são integrados ao AWS KMS, restringindo o acesso a uma chave KMS, portanto, apenas os Nitro Enclaves e o usuário final têm permissão para usar a chave e descriptografar a pergunta.
Se você planeja dimensionar essa arquitetura para suportar cargas de trabalho maiores, certifique-se de que o processo de seleção do modelo corresponda aos requisitos do seu modelo com recursos do EC2. Além disso, você deve considerar o tamanho máximo da solicitação e o impacto que isso terá no servidor HTTP e no tempo de inferência em relação ao modelo. Muitos desses parâmetros são personalizáveis por meio das configurações do modelo e do servidor HTTP.
A melhor maneira de determinar as configurações e requisitos específicos para sua carga de trabalho é por meio de testes com um LLM ajustado. Embora esta postagem inclua apenas o processamento de linguagem natural de dados confidenciais, você pode modificar esta arquitetura para oferecer suporte a LLMs alternativos que suportam áudio, visão computacional ou multimodalidades. Os mesmos princípios de segurança aqui destacados podem ser aplicados a dados em qualquer formato. Os recursos utilizados para construir este post estão disponíveis no site GitHub repo.
Compartilhe como você vai adaptar esta solução ao seu ambiente na seção de comentários.
Sobre os autores
Justin Miles é engenheiro de nuvem do Setor de Modernização Digital de Leidos do Escritório de Tecnologia. Nas horas vagas, ele gosta de jogar golfe e viajar.
Liv d'Aliberti é pesquisador do Leidos AI/ML Accelerator do Office of Technology. A pesquisa deles se concentra no aprendizado de máquina que preserva a privacidade.
Chris Renzo é arquiteto de soluções sênior na organização AWS Defense and Aerospace. Fora do trabalho, ele gosta de equilibrar clima quente e viagens.
Joe Kovba é Vice-Presidente do Setor de Modernização Digital da Leidos. Nas horas vagas, ele gosta de arbitrar jogos de futebol e jogar softball.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/large-language-model-inference-over-confidential-data-using-aws-nitro-enclaves/

