Os dados são o seu diferenciador de IA generativa e um sucesso IA generativa a implementação depende de uma estratégia de dados robusta que incorpore uma abordagem abrangente governança de dados abordagem. Trabalhar com grandes modelos de linguagem (LLMs) para casos de uso corporativo requer a implementação de considerações de qualidade e privacidade para impulsionar uma IA responsável. No entanto, os dados empresariais gerados a partir de fontes isoladas, combinados com a falta de uma estratégia de integração de dados, criam desafios para o fornecimento de dados para aplicações generativas de IA. A necessidade de uma ponta a ponta estratégia para gerenciamento de dados e a governança de dados em cada etapa da jornada – desde a ingestão, armazenamento e consulta de dados até a análise, visualização e execução de modelos de inteligência artificial (IA) e aprendizado de máquina (ML) – continua a ser de suma importância para as empresas.
Nesta postagem, discutimos as necessidades de governança de dados de pipelines de dados de aplicativos de IA generativos, um alicerce crítico para governar os dados usados pelos LLMs para melhorar a precisão e a relevância de suas respostas às solicitações do usuário de maneira segura e transparente. As empresas estão fazendo isso usando dados proprietários com abordagens como Retrieval Augmented Generation (RAG), ajuste fino e pré-treinamento contínuo com modelos básicos.
A governança de dados é um alicerce crítico em todas essas abordagens e vemos duas áreas emergentes de foco. Primeiro, muitos casos de uso de LLM dependem de conhecimento empresarial que precisa ser extraído de dados não estruturados, como documentos, transcrições e imagens, além de dados estruturados de data warehouses. Os dados não estruturados são normalmente armazenados em sistemas isolados em formatos variados e geralmente não são gerenciados ou governados com o mesmo nível de rigor que os dados estruturados. Em segundo lugar, as aplicações de IA generativa introduzem um número maior de interações de dados do que as aplicações convencionais, o que exige que as políticas de segurança de dados, privacidade e controlo de acesso sejam implementadas como parte dos fluxos de trabalho dos utilizadores de IA generativa.
Nesta postagem, abordamos a governança de dados para a construção de aplicativos generativos de IA na AWS com foco em fontes de conhecimento empresarial estruturadas e não estruturadas e a função da governança de dados durante os fluxos de trabalho de solicitação e resposta do usuário.
Visão geral do caso de uso
Vamos explorar um exemplo de assistente de IA de suporte ao cliente. A figura a seguir mostra o fluxo de trabalho de conversação típico iniciado com um prompt do usuário.

O fluxo de trabalho inclui as seguintes etapas principais de governança de dados:
- Solicitar controle de acesso do usuário e políticas de segurança.
- Políticas de acesso para extrair permissões com base em dados relevantes e filtrar resultados com base na função e nas permissões do usuário solicitado.
- Aplique políticas de privacidade de dados, como redações de informações de identificação pessoal (PII).
- Aplique controle de acesso refinado.
- Conceda permissões de função de usuário para informações confidenciais e políticas de conformidade.
Para fornecer uma resposta que inclua o contexto empresarial, cada solicitação do usuário precisa ser ampliada com uma combinação de insights de dados estruturados do data warehouse e dados não estruturados do data lake corporativo. No back-end, os processos de engenharia de dados em lote que atualizam o data lake corporativo precisam ser expandidos para ingerir, transformar e gerenciar dados não estruturados. Como parte da transformação, os objetos precisam ser tratados para garantir a privacidade dos dados (por exemplo, redação de PII). Finalmente, as políticas de controle de acesso também precisam ser estendidas aos objetos de dados não estruturados e aos armazenamentos de dados vetoriais.
Vejamos como a governança de dados pode ser aplicada aos pipelines de dados de fontes de conhecimento corporativo e aos fluxos de trabalho de solicitação-resposta do usuário.
Conhecimento empresarial: gerenciamento de dados
A figura a seguir resume as considerações de governação de dados para pipelines de dados e o fluxo de trabalho para aplicar a governação de dados.
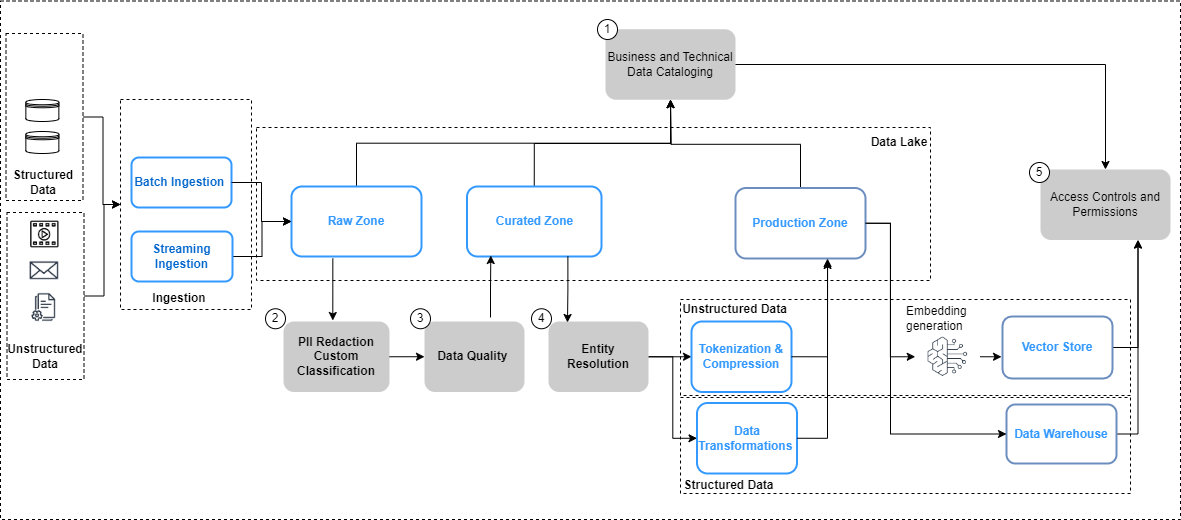
Na figura acima, os pipelines de engenharia de dados incluem as seguintes etapas de governança de dados:
- Crie e atualize um catálogo por meio da evolução de dados.
- Implementar políticas de privacidade de dados.
- Implemente a qualidade dos dados por tipo e fonte de dados.
- Vincule conjuntos de dados estruturados e não estruturados.
- Implemente controles de acesso unificados e refinados para conjuntos de dados estruturados e não estruturados.
Vejamos algumas das principais mudanças nos pipelines de dados, ou seja, catalogação de dados, qualidade de dados e segurança de incorporação de vetores com mais detalhes.
Descoberta de dados
Ao contrário dos dados estruturados, que são gerenciados em linhas e colunas bem definidas, os dados não estruturados são armazenados como objetos. Para que os usuários possam descobrir e compreender os dados, o primeiro passo é construir um catálogo abrangente usando os metadados gerados e capturados nos sistemas de origem. Isso começa com os objetos (como documentos e arquivos de transcrição) sendo ingeridos dos sistemas de origem relevantes na zona bruta no lago de dados in Serviço de armazenamento simples da Amazon (Amazon S3) em seus respectivos formatos nativos (conforme ilustrado na figura anterior). A partir daqui, os metadados do objeto (como proprietário do arquivo, data de criação e nível de confidencialidade) são extraído e consultado usando recursos do Amazon S3. Os metadados podem variar de acordo com a fonte de dados e é importante examinar os campos e, quando necessário, derivar os campos necessários para completar todos os metadados necessários. Por exemplo, se um atributo como a confidencialidade do conteúdo não estiver marcado no nível do documento no aplicativo de origem, pode ser necessário derivar isso como parte do processo de extração de metadados e adicioná-lo como um atributo no catálogo de dados. O processo de ingestão precisa capturar atualizações de objetos (alterações, exclusões), além de novos objetos de forma contínua. Para obter orientações detalhadas de implementação, consulte Gerenciamento e governança de dados não estruturados usando IA/ML da AWS e serviços analíticos. Para simplificar ainda mais a descoberta e a introspecção entre glossários comerciais e catálogos de dados técnicos, você pode usar Zona de dados da Amazon para que usuários corporativos descubram e compartilhem dados armazenados em silos de dados.
Dados privados
As fontes de conhecimento empresarial geralmente contêm PII e outros dados confidenciais (como endereços e números de Seguro Social). Com base nas suas políticas de privacidade de dados, esses elementos precisam ser tratados (mascarados, tokenizados ou redigidos) das fontes antes que possam ser usados em casos de uso downstream. Na zona bruta do Amazon S3, os objetos precisam ser processados antes de poderem ser consumidos por modelos de IA generativos downstream. Um requisito fundamental aqui é Identificação e redação de PII, que você pode implementar com Amazon Comprehend. É importante lembrar que nem sempre será viável eliminar todos os dados confidenciais sem impactar o contexto dos dados. Contexto semântico é um dos principais fatores que impulsionam a precisão e a relevância dos resultados do modelo de IA generativo, e é fundamental trabalhar retroativamente a partir do caso de uso e encontrar o equilíbrio necessário entre os controles de privacidade e o desempenho do modelo.
Enriquecimento de dados
Além disso, pode ser necessário extrair metadados adicionais dos objetos. O Amazon Comprehend oferece recursos para reconhecimento de entidade (por exemplo, identificar dados específicos do domínio, como números de apólices e números de sinistros) e classificação personalizada (por exemplo, categorizar uma transcrição de bate-papo de atendimento ao cliente com base na descrição do problema). Além disso, pode ser necessário combinar os dados não estruturados e estruturados para criar uma imagem holística das principais entidades, como os clientes. Por exemplo, em um cenário de fidelidade de uma companhia aérea, haveria um valor significativo em vincular a captura de dados não estruturados de interações com clientes (como transcrições de bate-papos e avaliações de clientes) com sinais de dados estruturados (como compras de passagens e resgate de milhas) para criar um cenário mais completo. perfil do cliente que pode então permitir a entrega de recomendações de viagem melhores e mais relevantes. Resolução de entidade AWS é um serviço de ML que ajuda na correspondência e vinculação de registros. Este serviço ajuda a vincular conjuntos de informações relacionadas para criar dados mais profundos e conectados sobre entidades-chave, como clientes, produtos e assim por diante, o que pode melhorar ainda mais a qualidade e a relevância dos resultados do LLM. Ele está disponível na zona transformada no Amazon S3 e está pronto para ser consumido posteriormente para armazenamento de vetores, ajuste fino ou treinamento de LLMs. Após essas transformações, os dados podem ser disponibilizados na zona selecionada no Amazon S3.
Qualidade dos dados
Um fator crítico para concretizar todo o potencial da IA generativa depende da qualidade dos dados usados para treinar os modelos, bem como dos dados usados para aumentar e aprimorar a resposta do modelo a uma entrada do usuário. Compreender os modelos e seus resultados no contexto de precisão, viés e confiabilidade é diretamente proporcional à qualidade dos dados usados para construir e treinar os modelos.
Monitor de modelo do Amazon SageMaker fornece uma detecção proativa de desvios no desvio da qualidade dos dados do modelo e no desvio das métricas de qualidade do modelo. Ele também monitora o desvio de polarização nas previsões do seu modelo e na atribuição de recursos. Para mais detalhes, consulte Monitoramento de modelos de ML em produção em grande escala usando o Amazon SageMaker Model Monitor. Detectar preconceitos em seu modelo é um alicerce fundamental para uma IA responsável, e Esclarecimento do Amazon SageMaker ajuda a detectar potenciais distorções que podem produzir um resultado negativo ou menos preciso. Para saber mais, consulte Saiba como o Amazon SageMaker Clarify ajuda a detectar vieses.
Uma nova área de foco na IA generativa é o uso e a qualidade dos dados em prompts de armazenamentos de dados corporativos e proprietários. Uma melhor prática emergente a ser considerada aqui é shift-esquerda, que coloca uma forte ênfase em mecanismos de garantia de qualidade precoces e proativos. No contexto de pipelines de dados projetados para processar dados para aplicações generativas de IA, isso implica identificar e resolver problemas de qualidade de dados mais cedo, a montante, para mitigar o impacto potencial de problemas de qualidade de dados posteriormente. Qualidade de dados do AWS Glue não apenas mede e monitora a qualidade de seus dados em repouso em seus data lakes, data warehouses e bancos de dados transacionais, mas também permite a detecção precoce e a correção de problemas de qualidade em seus pipelines de extração, transformação e carregamento (ETL) para garantir que seus dados atende aos padrões de qualidade antes de ser consumido. Para mais detalhes, consulte Conceitos básicos do AWS Glue Data Quality do Catálogo de dados do AWS Glue.
Governança da loja vetorial
Incorporações em bancos de dados vetoriais elevar a inteligência e os recursos de aplicativos generativos de IA, habilitando recursos como pesquisa semântica e reduzindo alucinações. As incorporações normalmente contêm dados privados e confidenciais, e criptografar os dados é uma etapa recomendada no fluxo de trabalho de entrada do usuário. Amazon OpenSearch sem servidor armazena e pesquisa seus embeddings de vetores e criptografa seus dados em repouso com Serviço de gerenciamento de chaves AWS (AWS KMS). Para mais detalhes, consulte Apresentando o mecanismo vetorial para Amazon OpenSearch Serverless, agora em versão prévia. Da mesma forma, opções adicionais de mecanismo vetorial na AWS, incluindo Amazona Kendra e Aurora Amazônica, criptografe seus dados em repouso com o AWS KMS. Para obter mais informações, consulte Criptografia em repouso e Protegendo dados usando criptografia.
À medida que os embeddings são gerados e armazenados em um armazenamento de vetores, controlar o acesso aos dados com controle de acesso baseado em função (RBAC) torna-se um requisito fundamental para manter a segurança geral. Serviço Amazon OpenSearch fornece controles de acesso refinados (FGAC) recursos com Gerenciamento de acesso e identidade da AWS (IAM) que podem ser associadas a Amazon Cognito Usuários. Mecanismos correspondentes de controle de acesso do usuário também são fornecidos por OpenSearch sem servidor, Amazona Kendrae Aurora. Para saber mais, consulte Controle de acesso a dados para Amazon OpenSearch Serverless, Controlando o acesso do usuário a documentos com tokens e Gerenciamento de identidade e acesso para Amazon Aurora, Respectivamente.
Fluxos de trabalho de solicitação-resposta do usuário
Os controles no plano de governança de dados precisam ser integrados à aplicação de IA generativa como parte do plano geral implantação de solução para garantir a conformidade com políticas de segurança de dados (com base em controles de acesso baseados em funções) e privacidade de dados (com base em acesso baseado em funções a dados confidenciais). A figura a seguir ilustra o fluxo de trabalho para aplicar a governança de dados.
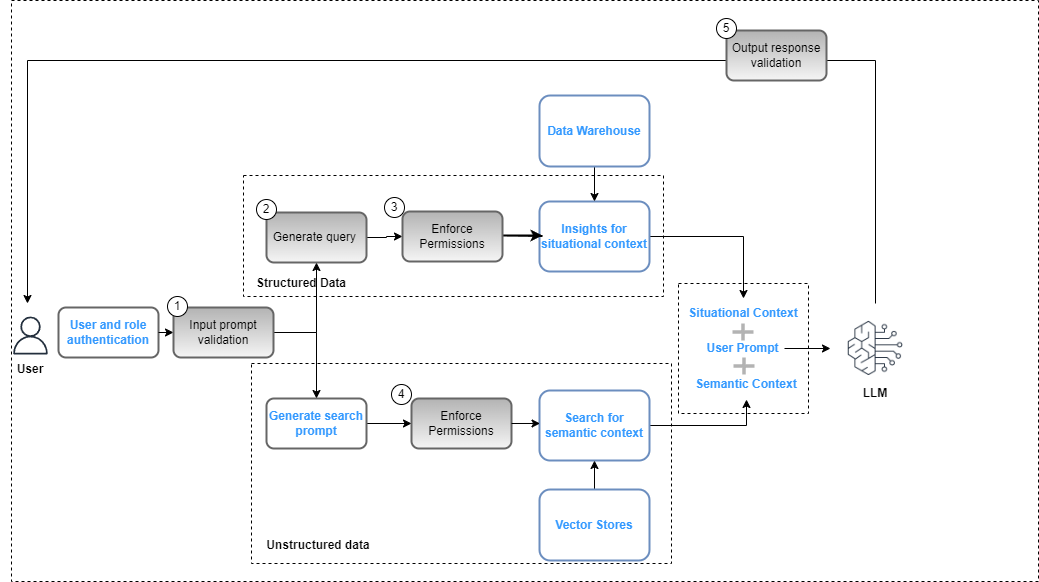
O fluxo de trabalho inclui as seguintes etapas principais de governança de dados:
- Forneça uma solicitação de entrada válida para alinhamento com as políticas de conformidade (por exemplo, preconceito e toxicidade).
- Gere uma consulta mapeando palavras-chave de prompt com o catálogo de dados.
- Aplique políticas FGAC com base na função do usuário.
- Aplique políticas RBAC com base na função do usuário.
- Aplique a redação de dados e conteúdo à resposta com base nas permissões de função do usuário e nas políticas de conformidade.
Como parte do ciclo de prompt, o prompt do usuário deve ser analisado e as palavras-chave extraídas para garantir o alinhamento com as políticas de conformidade usando um serviço como o Amazon Comprehend (consulte Novidade no Amazon Comprehend – Detecção de toxicidade) ou Guarda-corpos para Amazon Bedrock (visualização). Quando isso for validado, se o prompt exigir a extração de dados estruturados, as palavras-chave poderão ser usadas no catálogo de dados (comercial ou técnico) para extrair as tabelas e campos de dados relevantes e construir uma consulta no data warehouse. As permissões do usuário são avaliadas usando Formação AWS Lake para filtrar os dados relevantes. No caso de dados não estruturados, os resultados da pesquisa são restritos com base nas políticas de permissão do usuário implementadas no armazenamento de vetores. Como etapa final, a resposta de saída do LLM precisa ser avaliada em relação às permissões do usuário (para garantir a privacidade e segurança dos dados) e a conformidade com a segurança (por exemplo, diretrizes de preconceito e toxicidade).
Embora este processo seja específico para uma implementação RAG e seja aplicável a outras estratégias de implementação LLM, existem controlos adicionais:
- Engenharia imediata – O acesso aos modelos de prompt a serem invocados precisa ser restrito com base em controles de acesso aumentado pela lógica de negócios.
- Modelos de ajuste fino e modelos básicos de treinamento – Nos casos em que os objetos da zona selecionada no Amazon S3 são usados como dados de treinamento para ajuste fino dos modelos básicos, as políticas de permissões precisam ser configuradas com Gerenciamento de identidade e acesso do Amazon S3 no nível do bucket ou do objeto com base nos requisitos.
Resumo
A governança de dados é fundamental para permitir que as organizações criem aplicações corporativas de IA generativas. À medida que os casos de utilização empresarial continuam a evoluir, será necessário expandir a infraestrutura de dados para governar e gerir conjuntos de dados novos, diversos e não estruturados, a fim de garantir o alinhamento com as políticas de privacidade, segurança e qualidade. Essas políticas precisam ser implementadas e gerenciadas como parte da ingestão, armazenamento e gerenciamento de dados da base de conhecimento empresarial, juntamente com os fluxos de trabalho de interação do usuário. Isto garante que as aplicações generativas de IA não só minimizam o risco de partilha de informações imprecisas ou erradas, mas também protegem contra preconceitos e toxicidade que podem levar a resultados prejudiciais ou difamatórios. Para saber mais sobre governança de dados na AWS, consulte O que é governança de dados?
Nas postagens subsequentes, forneceremos orientações de implementação sobre como expandir a governança da infraestrutura de dados para apoiar casos de uso de IA generativa.
Sobre os autores
 Krishna Rupanagunta lidera uma equipe de especialistas em dados e IA na AWS. Ele e sua equipe trabalham com os clientes para ajudá-los a inovar com mais rapidez e tomar melhores decisões usando dados, análises e IA/ML. Ele pode ser contatado via LinkedIn.
Krishna Rupanagunta lidera uma equipe de especialistas em dados e IA na AWS. Ele e sua equipe trabalham com os clientes para ajudá-los a inovar com mais rapidez e tomar melhores decisões usando dados, análises e IA/ML. Ele pode ser contatado via LinkedIn.
 Imtiaz (Taz) Sayed é o líder técnico da WW para análises na AWS. Ele gosta de se envolver com a comunidade em todas as questões relacionadas a dados e análises. Ele pode ser contatado via LinkedIn.
Imtiaz (Taz) Sayed é o líder técnico da WW para análises na AWS. Ele gosta de se envolver com a comunidade em todas as questões relacionadas a dados e análises. Ele pode ser contatado via LinkedIn.
 Raghvender Arni (Arni) lidera a Equipe de Aceleração de Clientes (CAT) nas Indústrias AWS. O CAT é uma equipe multifuncional global de arquitetos de nuvem voltados para o cliente, engenheiros de software, cientistas de dados e especialistas e designers de IA/ML que impulsionam a inovação por meio de prototipagem avançada e impulsionam a excelência operacional em nuvem por meio de conhecimento técnico especializado.
Raghvender Arni (Arni) lidera a Equipe de Aceleração de Clientes (CAT) nas Indústrias AWS. O CAT é uma equipe multifuncional global de arquitetos de nuvem voltados para o cliente, engenheiros de software, cientistas de dados e especialistas e designers de IA/ML que impulsionam a inovação por meio de prototipagem avançada e impulsionam a excelência operacional em nuvem por meio de conhecimento técnico especializado.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/data-governance-in-the-age-of-generative-ai/

