Os modelos básicos (FMs) são grandes modelos de aprendizado de máquina (ML) treinados em um amplo espectro de conjuntos de dados generalizados e não rotulados. Os FMs, como o nome sugere, fornecem a base para a construção de aplicações downstream mais especializadas e são únicos em sua adaptabilidade. Eles podem realizar uma ampla gama de tarefas diferentes, como processamento de linguagem natural, classificação de imagens, previsão de tendências, análise de sentimentos e resposta a perguntas. Essa escala e adaptabilidade de uso geral são o que diferencia os FMs dos modelos tradicionais de ML. Os FMs são multimodais; eles trabalham com diferentes tipos de dados, como texto, vídeo, áudio e imagens. Modelos de linguagem grande (LLMs) são um tipo de FM e são pré-treinados em grandes quantidades de dados de texto e normalmente têm usos de aplicativos como geração de texto, chatbots inteligentes ou resumo.
A transmissão de dados facilita o fluxo constante de informações diversas e atualizadas, melhorando a capacidade dos modelos de se adaptarem e gerarem resultados mais precisos e contextualmente relevantes. Esta integração dinâmica de dados de streaming permite IA generativa aplicativos para responder prontamente às mudanças nas condições, melhorando sua adaptabilidade e desempenho geral em diversas tarefas.
Para entender melhor isso, imagine um chatbot que ajude os viajantes a reservar suas viagens. Neste cenário, o chatbot precisa de acesso em tempo real ao inventário da companhia aérea, ao status do voo, ao inventário do hotel, às últimas alterações de preços e muito mais. Esses dados geralmente vêm de terceiros, e os desenvolvedores precisam encontrar uma maneira de ingerir esses dados e processar as alterações nos dados conforme elas acontecem.
O processamento em lote não é a melhor opção neste cenário. Quando os dados mudam rapidamente, processá-los em lote pode resultar no uso de dados obsoletos pelo chatbot, fornecendo informações imprecisas ao cliente, o que afeta a experiência geral do cliente. O processamento de fluxo, no entanto, pode permitir que o chatbot acesse dados em tempo real e se adapte às mudanças na disponibilidade e no preço, fornecendo a melhor orientação ao cliente e melhorando a experiência do cliente.
Outro exemplo é uma solução de observabilidade e monitoramento orientada por IA, onde os FMs monitoram métricas internas em tempo real de um sistema e produzem alertas. Quando o modelo encontrar uma anomalia ou valor métrico anormal, deverá produzir imediatamente um alerta e notificar o operador. No entanto, o valor desses dados importantes diminui significativamente ao longo do tempo. Idealmente, essas notificações devem ser recebidas em segundos ou mesmo enquanto estão acontecendo. Se os operadores receberem essas notificações minutos ou horas depois de terem ocorrido, tal insight não será acionável e potencialmente perderá seu valor. Você pode encontrar casos de uso semelhantes em outros setores, como varejo, fabricação de automóveis, energia e setor financeiro.
Nesta postagem, discutimos por que o streaming de dados é um componente crucial das aplicações generativas de IA devido à sua natureza em tempo real. Discutimos o valor dos serviços de streaming de dados da AWS, como Amazon Managed Streaming para Apache Kafka (Amazônia MSK), Fluxos de dados do Amazon Kinesis, Serviço gerenciado da Amazon para Apache Flink e Mangueira de incêndio de dados do Amazon Kinesis na construção de aplicativos generativos de IA.
Aprendizagem no contexto
Os LLMs são treinados com dados pontuais e não têm capacidade inerente de acessar dados novos no momento da inferência. À medida que novos dados aparecem, você terá que ajustar continuamente ou treinar ainda mais o modelo. Esta não é apenas uma operação cara, mas também muito limitante na prática, porque a taxa de geração de novos dados supera em muito a velocidade do ajuste fino. Além disso, os LLMs carecem de compreensão contextual e dependem apenas dos seus dados de formação, sendo, portanto, propensos a alucinações. Isso significa que eles podem gerar uma resposta fluente, coerente e sintaticamente correta, mas factualmente incorreta. Eles também são desprovidos de relevância, personalização e contexto.
Os LLMs, no entanto, têm a capacidade de aprender com os dados que recebem do contexto para responder com mais precisão, sem modificar os pesos do modelo. Isso é chamado aprendizagem no contextoe pode ser usado para produzir respostas personalizadas ou fornecer uma resposta precisa no contexto das políticas da organização.
Por exemplo, em um chatbot, os eventos de dados podem pertencer a um inventário de voos e hotéis ou a alterações de preços que são constantemente ingeridos em um mecanismo de armazenamento de streaming. Além disso, os eventos de dados são filtrados, enriquecidos e transformados em um formato consumível usando um processador de fluxo. O resultado é disponibilizado para o aplicativo consultando o snapshot mais recente. O instantâneo é atualizado constantemente por meio do processamento de fluxo; portanto, os dados atualizados são fornecidos no contexto de um prompt do usuário para o modelo. Isso permite que o modelo se adapte às últimas mudanças de preço e disponibilidade. O diagrama a seguir ilustra um fluxo de trabalho básico de aprendizagem no contexto.
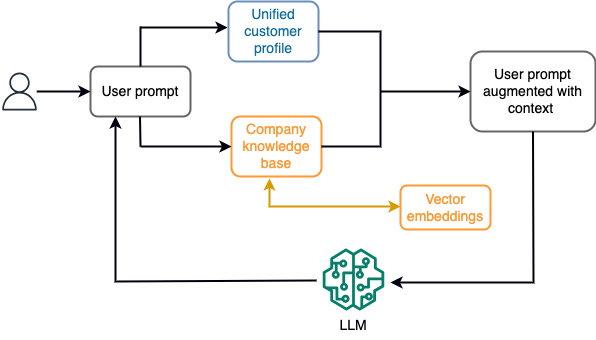
Uma abordagem de aprendizagem em contexto comumente usada é usar uma técnica chamada Retrieval Augmented Generation (RAG). No RAG, você fornece as informações relevantes, como a política mais relevante e os registros do cliente, juntamente com a pergunta do usuário no prompt. Dessa forma, o LLM gera uma resposta à pergunta do usuário utilizando informações adicionais fornecidas como contexto. Para saber mais sobre RAG, consulte Resposta a perguntas usando geração aumentada de recuperação com modelos de base no Amazon SageMaker JumpStart.
Uma aplicação de IA generativa baseada em RAG só pode produzir respostas genéricas com base em seus dados de treinamento e nos documentos relevantes da base de conhecimento. Esta solução é insuficiente quando se espera uma resposta personalizada quase em tempo real do aplicativo. Por exemplo, espera-se que um chatbot de viagens considere as reservas atuais do usuário, o inventário de hotéis e voos disponíveis e muito mais. Além disso, os dados pessoais relevantes do cliente (vulgarmente conhecidos como perfil de cliente unificado) geralmente está sujeito a alterações. Se um processo em lote for empregado para atualizar o banco de dados de perfis de usuário da IA generativa, o cliente poderá receber respostas insatisfatórias com base em dados antigos.
Nesta postagem, discutimos a aplicação de processamento de fluxo para aprimorar uma solução RAG usada para construir agentes respondedores de perguntas com contexto de acesso em tempo real a perfis de clientes unificados e base de conhecimento organizacional.
Atualizações de perfil de cliente quase em tempo real
Os registros de clientes normalmente são distribuídos entre armazenamentos de dados dentro de uma organização. Para que seu aplicativo generativo de IA forneça um perfil de cliente relevante, preciso e atualizado, é vital construir pipelines de dados de streaming que possam realizar resolução de identidade e agregação de perfil em todos os armazenamentos de dados distribuídos. Os trabalhos de streaming ingerem constantemente novos dados para sincronizar entre sistemas e podem realizar enriquecimento, transformações, junções e agregações em janelas de tempo com mais eficiência. Os eventos de captura de dados de alteração (CDC) contêm informações sobre o registro de origem, atualizações e metadados, como horário, origem, classificação (inserir, atualizar ou excluir) e o iniciador da alteração.
O diagrama a seguir ilustra um exemplo de fluxo de trabalho para ingestão e processamento de streaming do CDC para perfis de clientes unificados.

Nesta seção, discutimos os principais componentes de um padrão de streaming CDC necessário para suportar aplicações de IA generativa baseadas em RAG.
Ingestão de streaming do CDC
Um replicador de CDC é um processo que coleta alterações de dados de um sistema de origem (geralmente lendo logs de transações ou binlogs) e grava eventos de CDC exatamente na mesma ordem em que ocorreram em um fluxo de dados ou tópico de streaming. Isso envolve uma captura baseada em log com ferramentas como Serviço de migração de banco de dados AWS (AWS DMS) ou conectores de código aberto, como Debezium para conexão Apache Kafka. O Apache Kafka Connect faz parte do ambiente Apache Kafka, permitindo que os dados sejam ingeridos de várias fontes e entregues a vários destinos. Você pode executar seu conector Apache Kafka em Amazon MSK Conectar em minutos, sem se preocupar com configuração, configuração e operação de um cluster Apache Kafka. Você só precisa fazer upload do código compilado do seu conector para Serviço de armazenamento simples da Amazon (Amazon S3) e configure seu conector com a configuração específica da sua carga de trabalho.
Existem também outros métodos para capturar alterações de dados. Por exemplo, Amazon DynamoDB fornece um recurso para streaming de dados CDC para Streams do Amazon DynamoDB ou fluxos de dados do Kinesis. O Amazon S3 fornece um gatilho para invocar um AWS Lambda função quando um novo documento é armazenado.
Armazenamento de streaming
O armazenamento de streaming funciona como um buffer intermediário para armazenar eventos de CDC antes de serem processados. O armazenamento de streaming fornece armazenamento confiável para dados de streaming. Por design, ele é altamente disponível e resiliente a falhas de hardware ou de nós e mantém a ordem dos eventos à medida que são gravados. O armazenamento de streaming pode armazenar eventos de dados permanentemente ou por um determinado período de tempo. Isso permite que os processadores de fluxo leiam parte do fluxo se houver uma falha ou necessidade de reprocessamento. Kinesis Data Streams é um serviço de streaming de dados sem servidor que simplifica a captura, o processamento e o armazenamento de fluxos de dados em escala. O Amazon MSK é um serviço totalmente gerenciado, altamente disponível e seguro fornecido pela AWS para executar o Apache Kafka.
Processamento de fluxo
Os sistemas de processamento de fluxo devem ser projetados para paralelismo para lidar com alto rendimento de dados. Eles devem particionar o fluxo de entrada entre diversas tarefas executadas em diversos nós de computação. As tarefas devem ser capazes de enviar o resultado de uma operação para a próxima pela rede, possibilitando o processamento de dados em paralelo enquanto realizam operações como junções, filtragem, enriquecimento e agregações. Os aplicativos de processamento de fluxo devem ser capazes de processar eventos com relação ao horário do evento para casos de uso em que os eventos podem chegar atrasados ou a computação correta depende do horário em que os eventos ocorrem, e não do horário do sistema. Para obter mais informações, consulte Noções de Tempo: Tempo de Evento e Tempo de Processamento.
Os processos de fluxo produzem resultados continuamente na forma de eventos de dados que precisam ser enviados para um sistema de destino. Um sistema alvo pode ser qualquer sistema que possa ser integrado diretamente ao processo ou via armazenamento de streaming como intermediário. Dependendo da estrutura escolhida para processamento de fluxo, você terá opções diferentes para sistemas de destino, dependendo dos conectores de coletor disponíveis. Se você decidir gravar os resultados em um armazenamento de streaming intermediário, poderá criar um processo separado que leia eventos e aplique alterações ao sistema de destino, como executar um conector de coletor Apache Kafka. Independentemente da opção escolhida, os dados do CDC precisam de tratamento extra devido à sua natureza. Como os eventos do CDC transportam informações sobre atualizações ou exclusões, é importante que eles sejam mesclados no sistema de destino na ordem correta. Se as alterações forem aplicadas na ordem errada, o sistema de destino ficará fora de sincronia com sua origem.
Apache Flink é uma poderosa estrutura de processamento de fluxo conhecida por sua baixa latência e recursos de alto rendimento. Ele suporta processamento de tempo de evento, semântica de processamento exatamente uma vez e alta tolerância a falhas. Além disso, fornece suporte nativo para dados CDC por meio de uma estrutura especial chamada tabelas dinâmicas. As tabelas dinâmicas imitam as tabelas do banco de dados de origem e fornecem uma representação colunar dos dados de streaming. Os dados nas tabelas dinâmicas mudam com cada evento processado. Novos registros podem ser anexados, atualizados ou excluídos a qualquer momento. As tabelas dinâmicas abstraem a lógica extra que você precisa implementar para cada operação de registro (inserir, atualizar, excluir) separadamente. Para obter mais informações, consulte Tabelas Dinâmicas.
Com o Serviço gerenciado da Amazon para Apache Flink, você pode executar trabalhos do Apache Flink e integrá-los a outros serviços da AWS. Não há servidores e clusters para gerenciar e não há infraestrutura de computação e armazenamento para configurar.
Cola AWS é um serviço de extração, transformação e carregamento (ETL) totalmente gerenciado, o que significa que a AWS cuida do provisionamento, escalonamento e manutenção da infraestrutura para você. Embora seja conhecido principalmente por seus recursos de ETL, o AWS Glue também pode ser usado para aplicativos de streaming do Spark. O AWS Glue pode interagir com serviços de streaming de dados, como Kinesis Data Streams e Amazon MSK, para processar e transformar dados de CDC. O AWS Glue também pode integrar-se perfeitamente a outros serviços da AWS, como Lambda, Funções de etapa da AWSe DynamoDB, que oferece um ecossistema abrangente para criar e gerenciar pipelines de processamento de dados.
Perfil de cliente unificado
Superar a unificação do perfil do cliente em vários sistemas de origem requer o desenvolvimento de pipelines de dados robustos. Você precisa de pipelines de dados que possam reunir e sincronizar todos os registros em um armazenamento de dados. Esse armazenamento de dados fornece à sua organização a visão holística dos registros do cliente necessária para a eficiência operacional de aplicativos de IA generativos baseados em RAG. Para construir tal armazenamento de dados, um armazenamento de dados não estruturado seria o melhor.
Um gráfico de identidade é uma estrutura útil para criar um perfil de cliente unificado porque consolida e integra dados de clientes de várias fontes, garante a precisão e a desduplicação dos dados, oferece atualizações em tempo real, conecta insights entre sistemas, permite a personalização, aprimora a experiência do cliente e apoia a conformidade regulatória. Esse perfil de cliente unificado capacita o aplicativo generativo de IA para compreender e interagir com os clientes de maneira eficaz e aderir às regulamentações de privacidade de dados, melhorando, em última análise, as experiências do cliente e impulsionando o crescimento dos negócios. Você pode construir sua solução de gráfico de identidade usando Amazon Netuno, um serviço de banco de dados gráfico rápido, confiável e totalmente gerenciado.
A AWS fornece algumas outras ofertas de serviços de armazenamento NoSQL gerenciados e sem servidor para objetos de valor-chave não estruturados. Amazon DocumentDB (com compatibilidade com MongoDB) é uma empresa rápida, escalável, altamente disponível e totalmente gerenciada banco de dados de documentos serviço que oferece suporte a cargas de trabalho JSON nativas. DynamoDB é um serviço de banco de dados NoSQL totalmente gerenciado que oferece desempenho rápido e previsível com escalabilidade perfeita.
Atualizações da base de conhecimento organizacional quase em tempo real
Semelhante aos registros dos clientes, os repositórios de conhecimento interno, como políticas da empresa e documentos organizacionais, ficam isolados em sistemas de armazenamento. Normalmente são dados não estruturados e são atualizados de forma não incremental. O uso de dados não estruturados para aplicações de IA é eficaz usando incorporações vetoriais, que é uma técnica de representação de dados de alta dimensão, como arquivos de texto, imagens e arquivos de áudio, como numéricos multidimensionais.
A AWS fornece vários serviços de mecanismo vetorial, como Amazon OpenSearch sem servidor, Amazona Kendra e Edição compatível com Amazon Aurora PostgreSQL com a extensão pgvector para armazenar embeddings de vetores. Os aplicativos de IA generativos podem aprimorar a experiência do usuário, transformando o prompt do usuário em um vetor e usando-o para consultar o mecanismo de vetor para recuperar informações contextualmente relevantes. Tanto o prompt quanto os dados vetoriais recuperados são então passados para o LLM para receber uma resposta mais precisa e personalizada.
O diagrama a seguir ilustra um exemplo de fluxo de trabalho de processamento de fluxo para incorporações de vetores.
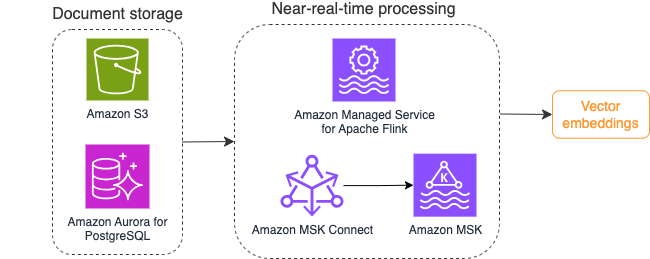
O conteúdo da base de conhecimento precisa ser convertido em incorporações vetoriais antes de ser gravado no armazenamento de dados vetoriais. Rocha Amazônica or Amazon Sage Maker pode ajudá-lo a acessar o modelo de sua escolha e expor um endpoint privado para essa conversão. Além disso, você pode usar bibliotecas como LangChain para integração com esses endpoints. Construir um processo em lote pode ajudá-lo a converter o conteúdo da sua base de conhecimento em dados vetoriais e armazená-los inicialmente em um banco de dados vetorial. No entanto, você precisa contar com um intervalo para reprocessar os documentos para sincronizar seu banco de dados de vetores com alterações no conteúdo da sua base de conhecimento. Com um grande número de documentos, este processo pode ser ineficiente. Entre esses intervalos, os usuários do seu aplicativo de IA generativa receberão respostas de acordo com o conteúdo antigo ou receberão uma resposta imprecisa porque o novo conteúdo ainda não foi vetorizado.
O processamento de fluxo é uma solução ideal para esses desafios. Ele produz inicialmente eventos de acordo com os documentos existentes e monitora ainda mais o sistema de origem e cria um evento de alteração de documento assim que eles ocorrem. Esses eventos podem ser armazenados no armazenamento de streaming e aguardar para serem processados por um trabalho de streaming. Uma tarefa de streaming lê esses eventos, carrega o conteúdo do documento e transforma o conteúdo em uma matriz de tokens de palavras relacionados. Cada token se transforma ainda mais em dados vetoriais por meio de uma chamada de API para um FM incorporado. Os resultados são enviados para armazenamento no armazenamento vetorial por meio de um operador coletor.
Se estiver usando o Amazon S3 para armazenar seus documentos, você poderá criar uma arquitetura de origem de eventos baseada em gatilhos de alteração de objeto do S3 para Lambda. Uma função Lambda pode criar um evento no formato desejado e gravá-lo em seu armazenamento de streaming.
Você também pode usar o Apache Flink para executar como um trabalho de streaming. Apache Flink fornece o conector de origem FileSystem nativo, que pode descobrir arquivos existentes e ler seu conteúdo inicialmente. Depois disso, ele pode monitorar continuamente seu sistema de arquivos em busca de novos arquivos e capturar seu conteúdo. O conector oferece suporte à leitura de um conjunto de arquivos de sistemas de arquivos distribuídos, como Amazon S3 ou HDFS com formato de texto simples, Avro, CSV, Parquet e muito mais, e produz um registro de streaming. Como um serviço totalmente gerenciado, o Managed Service for Apache Flink elimina a sobrecarga operacional de implantação e manutenção de jobs do Flink, permitindo que você se concentre na criação e no dimensionamento de seus aplicativos de streaming. Com integração perfeita aos serviços de streaming da AWS, como Amazon MSK ou Kinesis Data Streams, ele fornece recursos como escalonamento automático, segurança e resiliência, fornecendo aplicativos Flink confiáveis e eficientes para lidar com dados de streaming em tempo real.
Com base na sua preferência de DevOps, você pode escolher entre o Kinesis Data Streams ou o Amazon MSK para armazenar os registros de streaming. O Kinesis Data Streams simplifica as complexidades de criação e gerenciamento de aplicativos de dados de streaming personalizados, permitindo que você se concentre na obtenção de insights de seus dados, em vez de na manutenção da infraestrutura. Os clientes que usam o Apache Kafka geralmente optam pelo Amazon MSK devido à sua simplicidade, escalabilidade e confiabilidade na supervisão de clusters Apache Kafka no ambiente da AWS. Como um serviço totalmente gerenciado, o Amazon MSK assume as complexidades operacionais associadas à implantação e manutenção de clusters Apache Kafka, permitindo que você se concentre na construção e na expansão de seus aplicativos de streaming.
Como uma integração de API RESTful se adapta à natureza desse processo, você precisa de uma estrutura que ofereça suporte a um padrão de enriquecimento com estado por meio de chamadas de API RESTful para rastrear falhas e tentar novamente a solicitação com falha. Apache Flink novamente é uma estrutura que pode realizar operações com estado na velocidade da memória. Para entender as melhores maneiras de fazer chamadas de API via Apache Flink, consulte Padrões comuns de enriquecimento de dados de streaming no Amazon Kinesis Data Analytics para Apache Flink.
O Apache Flink fornece conectores de coletor nativos para gravar dados em datastores vetoriais, como Amazon Aurora para PostgreSQL com pgvector ou Serviço Amazon OpenSearch com VectorDB. Como alternativa, você pode preparar a saída do trabalho do Flink (dados vetorizados) em um tópico MSK ou em um fluxo de dados do Kinesis. O OpenSearch Service fornece suporte para ingestão nativa de fluxos de dados do Kinesis ou tópicos MSK. Para obter mais informações, consulte Apresentando o Amazon MSK como fonte para ingestão do Amazon OpenSearch e Carregar dados de streaming do Amazon Kinesis Data Streams.
Análise de feedback e ajuste fino
É importante que os gerentes de operações de dados e desenvolvedores de IA/ML obtenham insights sobre o desempenho do aplicativo generativo de IA e dos FMs em uso. Para conseguir isso, você precisa construir pipelines de dados que calculem dados importantes de indicadores-chave de desempenho (KPI) com base no feedback do usuário e na variedade de logs e métricas de aplicativos. Essas informações são úteis para que as partes interessadas obtenham insights em tempo real sobre o desempenho do FM, do aplicativo e a satisfação geral do usuário sobre a qualidade do suporte que recebem do seu aplicativo. Você também precisa coletar e armazenar o histórico de conversas para ajustar ainda mais seus FMs e melhorar sua capacidade de executar tarefas específicas de domínio.
Este caso de uso se encaixa muito bem no domínio da análise de streaming. Seu aplicativo deve armazenar cada conversa no armazenamento de streaming. Seu aplicativo pode solicitar aos usuários a classificação da precisão de cada resposta e sua satisfação geral. Esses dados podem estar em um formato de escolha binária ou em um texto de formato livre. Esses dados podem ser armazenados em um fluxo de dados do Kinesis ou tópico MSK e processados para gerar KPIs em tempo real. Você pode colocar FMs para trabalhar na análise de sentimento dos usuários. Os FMs podem analisar cada resposta e atribuir uma categoria de satisfação do usuário.
A arquitetura do Apache Flink permite agregação complexa de dados em intervalos de tempo. Ele também fornece suporte para consultas SQL em fluxo de eventos de dados. Portanto, usando o Apache Flink, você pode analisar rapidamente as entradas brutas do usuário e gerar KPIs em tempo real, escrevendo consultas SQL familiares. Para obter mais informações, consulte API de tabela e SQL.
Com o Serviço gerenciado da Amazon para Apache Flink Studio, você pode criar e executar aplicativos de processamento de fluxo Apache Flink usando SQL, Python e Scala padrão em um notebook interativo. Os notebooks Studio são desenvolvidos com Apache Zeppelin e usam Apache Flink como mecanismo de processamento de fluxo. Os notebooks Studio combinam perfeitamente essas tecnologias para tornar a análise avançada de fluxos de dados acessível a desenvolvedores de todos os conjuntos de habilidades. Com suporte para funções definidas pelo usuário (UDFs), o Apache Flink permite a construção de operadores personalizados para integração com recursos externos, como FMs, para executar tarefas complexas, como análise de sentimento. Você pode usar UDFs para calcular diversas métricas ou enriquecer os dados brutos de feedback do usuário com insights adicionais, como o sentimento do usuário. Para saber mais sobre esse padrão, consulte Abordar proativamente as preocupações dos clientes em tempo real com GenAI, Flink, Apache Kafka e Kinesis.
Com o serviço gerenciado para Apache Flink Studio, você pode implantar seu notebook Studio como uma tarefa de streaming com um clique. Você pode usar conectores de coletor nativos fornecidos pelo Apache Flink para enviar a saída para o armazenamento de sua preferência ou prepará-la em um fluxo de dados do Kinesis ou tópico MSK. Amazon RedShift e o OpenSearch Service são ideais para armazenar dados analíticos. Ambos os mecanismos fornecem suporte de ingestão nativa do Kinesis Data Streams e do Amazon MSK por meio de um pipeline de streaming separado para um data lake ou data warehouse para análise.
O Amazon Redshift usa SQL para analisar dados estruturados e semiestruturados em data warehouses e data lakes, usando hardware e machine learning projetados pela AWS para oferecer a melhor relação custo-benefício em escala. O OpenSearch Service oferece recursos de visualização com tecnologia OpenSearch Dashboards e Kibana (versões 1.5 a 7.10).
Você pode usar o resultado dessa análise combinado com os dados de prompt do usuário para ajustar o FM quando necessário. SageMaker é a maneira mais direta de ajustar seus FMs. Usar o Amazon S3 com o SageMaker oferece uma integração poderosa e perfeita para ajustar seus modelos. O Amazon S3 serve como uma solução de armazenamento de objetos escalável e durável, permitindo armazenamento e recuperação simples de grandes conjuntos de dados, dados de treinamento e artefatos de modelo. SageMaker é um serviço de ML totalmente gerenciado que simplifica todo o ciclo de vida do ML. Ao usar o Amazon S3 como back-end de armazenamento do SageMaker, você pode se beneficiar da escalabilidade, confiabilidade e economia do Amazon S3, integrando-o perfeitamente aos recursos de treinamento e implantação do SageMaker. Essa combinação permite o gerenciamento eficiente de dados, facilita o desenvolvimento colaborativo de modelos e garante que os fluxos de trabalho de ML sejam simplificados e escalonáveis, melhorando, em última análise, a agilidade geral e o desempenho do processo de ML. Para obter mais informações, consulte Ajuste o Falcon 7B e outros LLMs no Amazon SageMaker com @remote decorator.
Com um conector de coletor do sistema de arquivos, os trabalhos do Apache Flink podem entregar dados ao Amazon S3 em arquivos de formato aberto (como JSON, Avro, Parquet e mais) como objetos de dados. Se você preferir gerenciar seu data lake usando uma estrutura de data lake transacional (como Apache Hudi, Apache Iceberg ou Delta Lake), todas essas estruturas fornecem um conector personalizado para Apache Flink. Para mais detalhes, consulte Crie um pipeline de fonte para data lake de baixa latência usando Amazon MSK Connect, Apache Flink e Apache Hudi.
Resumo
Para um aplicativo generativo de IA baseado em um modelo RAG, você precisa considerar a construção de dois sistemas de armazenamento de dados e construir operações de dados que os mantenham atualizados com todos os sistemas de origem. Os trabalhos em lote tradicionais não são suficientes para processar o tamanho e a diversidade dos dados necessários para integração com seu aplicativo generativo de IA. Atrasos no processamento das alterações nos sistemas de origem resultam em respostas imprecisas e reduzem a eficiência da sua aplicação de IA generativa. O streaming de dados permite ingerir dados de vários bancos de dados em vários sistemas. Ele também permite transformar, enriquecer, unir e agregar dados de muitas fontes de forma eficiente e quase em tempo real. O streaming de dados fornece uma arquitetura de dados simplificada para coletar e transformar as reações ou comentários dos usuários em tempo real sobre as respostas do aplicativo, ajudando você a entregar e armazenar os resultados em um data lake para ajuste fino do modelo. O streaming de dados também ajuda a otimizar pipelines de dados processando apenas os eventos de alteração, permitindo responder às alterações de dados com mais rapidez e eficiência.
Saiba mais sobre Serviços de streaming de dados da AWS e comece a criar sua própria solução de streaming de dados.
Sobre os autores
 Ali Alemi é um arquiteto de soluções especialista em streaming na AWS. Ali aconselha os clientes da AWS com as melhores práticas de arquitetura e os ajuda a projetar sistemas de dados analíticos em tempo real que são confiáveis, seguros, eficientes e econômicos. Ele trabalha de trás para frente a partir dos casos de uso do cliente e projeta soluções de dados para resolver seus problemas de negócios. Antes de ingressar na AWS, Ali deu suporte a vários clientes do setor público e parceiros de consultoria da AWS em sua jornada de modernização de aplicativos e migração para a nuvem.
Ali Alemi é um arquiteto de soluções especialista em streaming na AWS. Ali aconselha os clientes da AWS com as melhores práticas de arquitetura e os ajuda a projetar sistemas de dados analíticos em tempo real que são confiáveis, seguros, eficientes e econômicos. Ele trabalha de trás para frente a partir dos casos de uso do cliente e projeta soluções de dados para resolver seus problemas de negócios. Antes de ingressar na AWS, Ali deu suporte a vários clientes do setor público e parceiros de consultoria da AWS em sua jornada de modernização de aplicativos e migração para a nuvem.
 Imtiaz (Taz) Sayed é o líder mundial de tecnologia para análises na AWS. Ele gosta de se envolver com a comunidade em todas as questões relacionadas a dados e análises. Ele pode ser contatado através LinkedIn.
Imtiaz (Taz) Sayed é o líder mundial de tecnologia para análises na AWS. Ele gosta de se envolver com a comunidade em todas as questões relacionadas a dados e análises. Ele pode ser contatado através LinkedIn.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

