Introdução
Identificar a palavra a seguir é a tarefa de previsão da próxima palavra, também conhecida como modelagem de linguagem. Um dos PNLAs tarefas de benchmark do são a modelagem de linguagem. Em sua forma mais básica, envolve escolher a palavra que segue uma sequência de palavras com base nelas com maior probabilidade de ocorrer. Em muitos campos diferentes, a modelagem de linguagem tem uma ampla variedade de aplicações.
Objetivo do aprendizado
- Reconheça as ideias e princípios subjacentes aos vários modelos usados em análise estatística, aprendizado de máquina e ciência de dados.
- Aprenda a criar modelos preditivos, incluindo regressão, classificação, agrupamento etc., para gerar previsões e tipos precisos com base nos dados.
- Compreenda os princípios de overfitting e underfitting e aprenda a avaliar o desempenho do modelo usando medidas como exatidão, precisão, recall, etc.
- Aprenda como pré-processar dados e identificar características pertinentes para modelagem.
- Aprenda como ajustar hiperparâmetros e otimizar modelos usando pesquisa de grade e validação cruzada.
Este artigo foi publicado como parte do Blogatona de Ciência de Dados.
Índice
Aplicações de Modelagem de Linguagem
Aqui estão algumas aplicações notáveis de modelagem de linguagem:
Recomendação de texto para teclado móvel
Uma função nos teclados do smartphone chamada recomendação de texto do teclado móvel, ou texto preditivo ou sugestões automáticas, sugere palavras ou frases enquanto você escreve. Ele procura tornar a digitação mais rápida e menos propensa a erros e oferecer recomendações mais precisas e contextualmente apropriadas.
Leia também: Construindo um sistema de recomendação baseado em conteúdo
Preenchimento automático da pesquisa do Google
Sempre que usamos um mecanismo de busca como o Google para procurar algo, recebemos muitas ideias e, à medida que adicionamos frases, as recomendações ficam melhores e mais relevantes para nossa pesquisa atual. Como isso acontecerá, então?

A tecnologia de processamento de linguagem natural (NLP) torna isso viável. Aqui, empregaremos o processamento de linguagem natural (NLP) para criar um modelo de previsão utilizando um modelo LSTM (memória de longo prazo) bidirecional para prever as palavras restantes da frase.
Saiba mais: O que é LSTM? Introdução à Memória de Longo Prazo
Importar bibliotecas e pacotes necessários
Seria melhor importar as bibliotecas e pacotes necessários para construir um modelo de previsão da próxima palavra usando um LSTM bidirecional. Uma amostra das bibliotecas geralmente necessárias é mostrada abaixo:
import pandas as pd
import os
import numpy as np import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import AdamInformações do conjunto de dados
Compreender os recursos e atributos do conjunto de dados com o qual você está lidando requer conhecimento. Os artigos médios das sete publicações a seguir, selecionados aleatoriamente e publicados em 2019, estão incluídos neste conjunto de dados:
- Rumo à ciência de dados
- Coletivo UX
- A inicialização
- A Cooperativa de Redação
- Investidor orientado por dados
- Humanos melhores
- Melhor Marketing
Link do conjunto de dados: https://www.kaggle.com/code/ysthehurricane/next-word-prediction-bi-lstm-tutorial-easy-way/input
medium_data = pd.read_csv('../input/medium-articles-dataset/medium_data.csv')
medium_data.head()
Aqui, temos dez campos diferentes e 6508 registros, mas usaremos apenas o campo de título para prever a próxima palavra.
print("Number of records: ", medium_data.shape[0])
print("Number of fields: ", medium_data.shape[1])
Ao examinar e compreender as informações do conjunto de dados, você pode escolher os procedimentos de pré-processamento, modelo e métricas de avaliação para seu próximo desafio de previsão de palavras.
Exibir títulos de vários artigos e pré-processá-los
Vamos dar uma olhada em alguns exemplos de títulos para ilustrar a preparação de títulos de artigos:
medium_data['title']
Remoção de caracteres e palavras indesejadas em títulos
O pré-processamento de dados de texto para tarefas de previsão às vezes inclui a remoção de letras e frases indesejáveis dos títulos. Letras e palavras indesejadas podem contaminar os dados com ruído e adicionar complexidade desnecessária, diminuindo assim o desempenho e a precisão do modelo.
- Personagens indesejados:
- Pontuação: Você deve remover pontos de exclamação, pontos de interrogação, vírgulas e outras pontuações. Normalmente, você pode descartá-los com segurança porque eles geralmente não ajudam na atribuição de previsão
- Caracteres especiais: Remova símbolos não alfanuméricos, como cifrões, símbolos @, hashtags e outros caracteres especiais desnecessários para o trabalho de previsão.
- Etiquetas HTML: Se os títulos tiverem marcações ou tags HTML, remova-os usando as ferramentas ou bibliotecas adequadas para extrair o texto.
- Palavras indesejadas:
- Palavras de parada: Remova palavras de parada comuns, como “um”, “uma”, “o”, “é”, “em” e outras palavras frequentes que não carregam significado significativo ou poder preditivo.
- Palavras irrelevantes: Identifique e remova palavras específicas que não são relevantes para a tarefa ou domínio de previsão. Por exemplo, se você estiver prevendo gêneros de filmes, palavras como “filme” ou “filme” podem não fornecer informações úteis.
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace(u'xa0',u' '))
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace('u200a',' '))
tokenization
tokenization divide o texto em tokens, palavras, subpalavras ou caracteres e, em seguida, atribui um ID ou índice exclusivo a cada token, criando um índice de palavras ou vocabulário.
O processo de tokenização envolve as seguintes etapas:
Pré-processamento de texto: Pré-processe o texto eliminando a pontuação, alterando-a para minúsculas e cuidando de qualquer tarefa específica ou necessidades específicas do domínio.
Tokenização: Dividir o texto pré-processado em tokens separados por regras ou métodos predeterminados. Expressões regulares, separando por espaço em branco e empregando tokenizadores especializados são técnicas comuns de tokenização.
Aumentando o vocabulário Você pode criar um dicionário, também chamado de índice de palavras, atribuindo a cada token um ID ou índice exclusivo. Nesse processo, cada ticket é mapeado para o valor de índice relevante.
tokenizer = Tokenizer(oov_token='<oov>') # For those words which are not found in word_index
tokenizer.fit_on_texts(medium_data['title'])
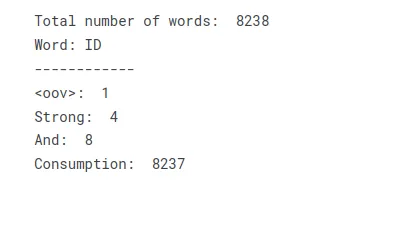
total_words = len(tokenizer.word_index) + 1 print("Total number of words: ", total_words)
print("Word: ID")
print("------------")
print("<oov>: ", tokenizer.word_index['<oov>'])
print("Strong: ", tokenizer.word_index['strong'])
print("And: ", tokenizer.word_index['and'])
print("Consumption: ", tokenizer.word_index['consumption'])Ao transformar o texto em um vocabulário ou índice de palavras, você pode criar uma tabela de pesquisa que representa o texto como uma coleção de índices numéricos. Cada palavra única no texto recebe um valor de índice correspondente, permitindo processamento adicional ou operações de modelagem que requerem entrada numérica.
Texto de títulos em sequências e modelo de N_gram.
Esses estágios podem ser usados para construir um modelo n-gram para previsão precisa com base nas sequências de título:
- Converter títulos em sequências: Use um tokenizador para transformar cada título em uma sequência de tokens ou separe manualmente cada deslizamento em suas palavras constituintes. Atribua a cada palavra no léxico um índice numérico distinto.
- Gerar n-gramas: A partir das sequências, faça n-gramas. Uma execução contínua de tokens de n títulos é chamada de n-gram.
- Conte a frequência: Determine a frequência com que cada n-grama aparece no conjunto de dados.
- Construa o modelo n-gram: Crie o modelo n-gram usando as frequências n-gram. O modelo acompanha a probabilidade de cada token dados os n-1 tokens anteriores. Isso pode ser exibido como uma tabela de pesquisa ou um dicionário.
- Preveja a próxima palavra: O próximo token esperado em uma sequência n-1-token pode ser identificado usando o modelo n-gram. Para fazer isso, é necessário encontrar a probabilidade no algoritmo e selecionar um token com a maior probabilidade.
Saiba mais: O que são N-gramas e como implementá-los em Python?
Você pode usar esses estágios para criar um modelo n-gram que utiliza as sequências dos títulos para prever a próxima palavra ou token. Com base nos dados de treinamento, esse método pode produzir previsões precisas, pois captura as relações estatísticas e as tendências no uso do idioma dos títulos.

input_sequences = []
for line in medium_data['title']: token_list = tokenizer.texts_to_sequences([line])[0] #print(token_list) for i in range(1, len(token_list)): n_gram_sequence = token_list[:i+1] input_sequences.append(n_gram_sequence) # print(input_sequences)
print("Total input sequences: ", len(input_sequences))
Faça com que todos os títulos tenham o mesmo comprimento usando preenchimento
Você pode usar preenchimento para garantir que cada título tenha o mesmo tamanho seguindo estas etapas:
- Encontre o título mais longo em seu conjunto de dados comparando todos os outros títulos.
- Repita esse processo para cada título, comparando o comprimento de cada um com o limite geral.
- Quando um título é muito curto, ele deve ser estendido usando um token ou caractere de preenchimento específico.
- Para cada título em seu conjunto de dados, execute o procedimento de preenchimento novamente.
O preenchimento garantirá que todos os títulos tenham o mesmo tamanho e fornecerá consistência para pós-processamento ou treinamento de modelo.
# pad sequences max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
input_sequences[1]
Preparar recursos e rótulos
No cenário dado, se considerarmos o último elemento de cada sequência de entrada como o rótulo, podemos executar codificação one-hot nos títulos para representá-los como vetores correspondentes ao número total de palavras únicas.
# create features and label
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words) print(xs[5])
print(labels[5])
print(ys[5][14])
A arquitetura da rede neural LSTM bidirecional
Redes neurais recorrentes (RNNs) com Long Short-Term Memory (LSTM) pode coletar e armazenar informações em sequências extensas. As redes LSTM usam células de memória especializadas e técnicas de gating para superar as restrições de RNNs regulares, que frequentemente lutam com o problema do gradiente de desaparecimento e têm problemas para manter a dependência de longo prazo.
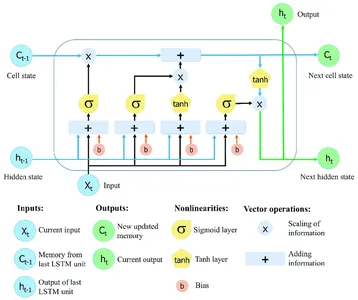
A característica crítica das redes LSTM é o estado da célula, que serve como uma unidade de memória que pode armazenar informações ao longo do tempo. O estado da célula é protegido e controlado por três portas principais: a porta de esquecimento, a porta de entrada e a porta de saída. Esses portões regulam o fluxo de informações para dentro, para fora e dentro da célula LSTM, permitindo que a rede lembre ou esqueça seletivamente as informações em diferentes intervalos de tempo.
Saiba mais: Memória de Longo Curto Prazo | Arquitetura do LSTM
LSTM Bidirecional
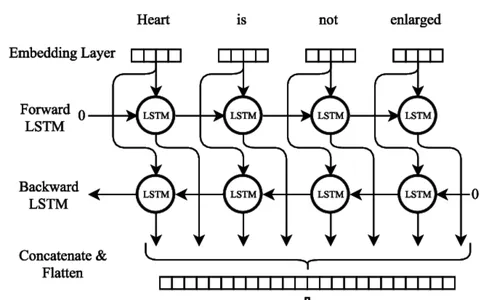
Treinamento do Modelo de Rede Neural Bi-LSTM
Numerosos procedimentos cruciais devem ser seguidos durante o treinamento de um modelo de rede neural bidirecional LSTM (Bi-LSTM). O primeiro passo é compilar um conjunto de dados de treinamento com sequências de entrada e saída correspondentes a eles, indicando a próxima palavra. Os dados do texto devem ser pré-processados, sendo divididos em linhas separadas, removendo a pontuação e alterando a caixa para minúscula.
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150)))
model.add(Dense(total_words, activation='softmax'))
adam = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
history = model.fit(xs, ys, epochs=50, verbose=1)
#print model.summary()
print(model)
Ao chamar o método fit(), o modelo é treinado. Os dados de treinamento consistem nas sequências de entrada (xs) e nas sequências de saída correspondentes (ys). O modelo prossegue por 50 iterações, passando por todo o conjunto de treinamento. Durante o processo de treinamento, o progresso do treinamento é mostrado (verbose=1).
Precisão e perda do modelo de plotagem
A plotagem da precisão e perda de um modelo durante o treinamento oferece informações perspicazes sobre o desempenho dele e o andamento do treinamento. O erro ou disparidade entre os valores previstos e reais é chamado de perda. Considerando que a porcentagem de previsões precisas geradas pelo modelo é conhecida como precisão.
import matplotlib.pyplot as plt def plot_graphs(history, string): plt.plot(history.history[string]) plt.xlabel("Epochs") plt.ylabel(string) plt.show() plot_graphs(history, 'accuracy')
plot_graphs(history, 'loss')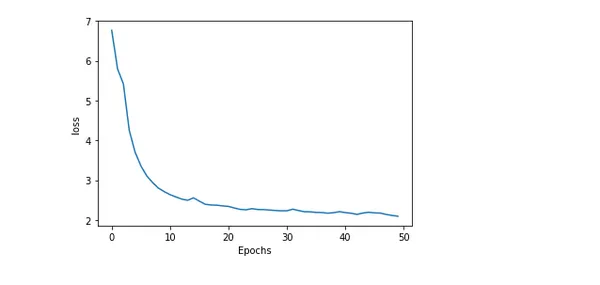
Prevendo a Próxima Palavra do Título
Um desafio fascinante no processamento de linguagem natural é adivinhar a seguinte palavra em um título. Os modelos podem propor a conversa mais provável procurando padrões e correlações em dados de texto. Esse poder preditivo possibilita aplicativos como sistemas de sugestão de texto e preenchimento automático. Abordagens sofisticadas como RNNs e arquiteturas baseadas em transformadores aumentam a precisão e capturam relacionamentos contextuais.
seed_text = "implementation of"
next_words = 2 for _ in range(next_words): token_list = tokenizer.texts_to_sequences([seed_text])[0] token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre') predicted = model.predict_classes(token_list, verbose=0) output_word = "" for word, index in tokenizer.word_index.items(): if index == predicted: output_word = word break seed_text += " " + output_word
print(seed_text)
Conclusão
Em conclusão, treinar um modelo para prever a palavra subsequente em uma sequência de palavras é o emocionante desafio de processamento de linguagem natural conhecido como previsão da próxima palavra usando um LSTM bidirecional. Aqui está a conclusão resumida em pontos:
- A poderosa arquitetura de aprendizado profundo BI-LSTM para processamento de dados sequenciais pode capturar relacionamentos de longo alcance e contexto de frase.
- Para preparar dados de texto bruto para treinamento BI-LSTM, a preparação de dados é essencial. Isso inclui tokenização, geração de vocabulário e vetorização de texto.
- Criar uma função de perda, construir o modelo usando um otimizador, adequá-lo aos dados pré-processados e avaliar seu desempenho em conjuntos de validação são as etapas do treinamento do modelo BI-LSTM.
- A previsão da próxima palavra do BI-LSTM requer uma combinação de conhecimento teórico e experimentação prática para dominar.
- Os algoritmos de preenchimento automático, criação de linguagem e sugestão de texto são exemplos de aplicativos de modelo de previsão da próxima palavra.
Os aplicativos para previsão da próxima palavra incluem chatbots, tradução automática e conclusão de texto. Você pode criar modelos de previsão de próxima palavra mais precisos e sensíveis ao contexto com mais pesquisa e aprimoramento.
Perguntas Frequentes
A. A previsão da próxima palavra é uma tarefa de NLP em que um modelo prevê a palavra mais provável para seguir uma determinada sequência de palavras ou contexto. O objetivo é gerar sugestões coerentes e contextualmente relevantes para a próxima palavra com base nos padrões e relacionamentos aprendidos com os dados de treinamento.
A. A previsão da próxima palavra geralmente usa Redes Neurais Recorrentes (RNNs) e suas variantes, como Long Short-Term Memory (LSTM) e Gated Recurrent Unit (GRU). Além disso, modelos como arquiteturas baseadas em Transformer, como os modelos GPT (Generative Pre-trained Transformer), também mostraram avanços significativos nessa tarefa.
R. Normalmente, ao preparar dados de treinamento para previsão da próxima palavra, você divide o texto em sequências de palavras e cria pares de entrada-saída. A saída correspondente representa a seguinte palavra no texto para cada sequência de entrada. O pré-processamento do texto envolve a remoção da pontuação, a conversão de palavras em minúsculas e a tokenização do texto em palavras individuais.
R. Você pode avaliar o desempenho de um modelo de previsão da próxima palavra usando métricas de avaliação, como perplexidade, precisão ou precisão máxima. A perplexidade mede o quão bem o modelo prevê a próxima palavra dado o contexto. As métricas de precisão comparam a palavra prevista com a verdade, enquanto a precisão top-k considera a previsão do modelo dentro dos k comentários mais prováveis.
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do Autor.
Relacionado
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Automotivo / EVs, Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2023/07/next-word-prediction-with-bidirectional-lstm/

