Com o uso de computação em nuvem, ferramentas de big data e aprendizado de máquina (ML), como Amazona atena or Amazon Sage Maker tornaram-se disponíveis e utilizáveis por qualquer pessoa sem muito esforço de criação e manutenção. As empresas industriais recorrem cada vez mais à análise de dados e à tomada de decisões baseadas em dados para aumentar a eficiência dos recursos em todo o seu portfólio, desde as operações até à realização de manutenção preditiva ou planeamento.
Devido à velocidade das mudanças na TI, os clientes dos setores tradicionais enfrentam um dilema de conjunto de habilidades. Por um lado, os analistas e especialistas do domínio têm um conhecimento muito profundo dos dados em questão e da sua interpretação, mas muitas vezes não têm exposição a ferramentas de ciência de dados e linguagens de programação de alto nível, como Python. Por outro lado, os especialistas em ciência de dados muitas vezes não têm experiência para interpretar o conteúdo dos dados da máquina e filtrá-los pelo que é relevante. Este dilema dificulta a criação de modelos eficientes que utilizem dados para gerar insights relevantes para os negócios.
Tela do Amazon SageMaker resolve esse dilema fornecendo aos especialistas do domínio uma interface sem código para criar análises poderosas e modelos de ML, como previsões, classificação ou modelos de regressão. Ele também permite implantar e compartilhar esses modelos com especialistas em ML e MLOps após a criação.
Nesta postagem, mostramos como usar o SageMaker Canvas para selecionar e selecionar os recursos corretos em seus dados e, em seguida, treinar um modelo de previsão para detecção de anomalias, usando a funcionalidade sem código do SageMaker Canvas para ajuste de modelo.
Detecção de anomalias para a indústria de manufatura
No momento em que este artigo foi escrito, o SageMaker Canvas se concentrava em casos de uso de negócios típicos, como previsão, regressão e classificação. Nesta postagem, demonstramos como esses recursos também podem ajudar a detectar pontos de dados anormais complexos. Este caso de uso é relevante, por exemplo, para identificar mau funcionamento ou operações incomuns de máquinas industriais.
A detecção de anomalias é importante no domínio da indústria, porque as máquinas (de trens a turbinas) são normalmente muito confiáveis, com intervalos de anos entre falhas. A maioria dos dados dessas máquinas, como leituras de sensores de temperatura ou mensagens de status, descrevem a operação normal e têm valor limitado para a tomada de decisões. Os engenheiros procuram dados anormais ao investigar as causas raízes de uma falha ou como indicadores de alerta para falhas futuras, e os gerentes de desempenho examinam dados anormais para identificar possíveis melhorias. Portanto, o primeiro passo típico para avançar em direção a uma tomada de decisão baseada em dados depende da descoberta desses dados relevantes (anormais).
Nesta postagem, usamos o SageMaker Canvas para selecionar e selecionar os recursos corretos nos dados e, em seguida, treinar um modelo de previsão para detecção de anomalias, usando a funcionalidade sem código do SageMaker Canvas para ajuste do modelo. Em seguida, implantamos o modelo como um endpoint do SageMaker.
Visão geral da solução
Para nosso caso de uso de detecção de anomalias, treinamos um modelo de previsão para prever um recurso característico para a operação normal de uma máquina, como a temperatura do motor indicada em um carro, a partir de recursos de influência, como a velocidade e o torque recente aplicado no carro . Para detecção de anomalias em uma nova amostra de medições, comparamos as previsões do modelo para o recurso característico com as observações fornecidas.
Para o exemplo do motor de um carro, um especialista no domínio obtém medições da temperatura normal do motor, do torque recente do motor, da temperatura ambiente e de outros fatores de influência potencial. Isso permite treinar um modelo para prever a temperatura a partir de outros recursos. Então podemos usar o modelo para prever a temperatura do motor regularmente. Quando a temperatura prevista para esses dados é semelhante à temperatura observada nesses dados, o motor está funcionando normalmente; uma discrepância indicará uma anomalia, como falha no sistema de refrigeração ou defeito no motor.
O diagrama a seguir ilustra a arquitetura da solução.
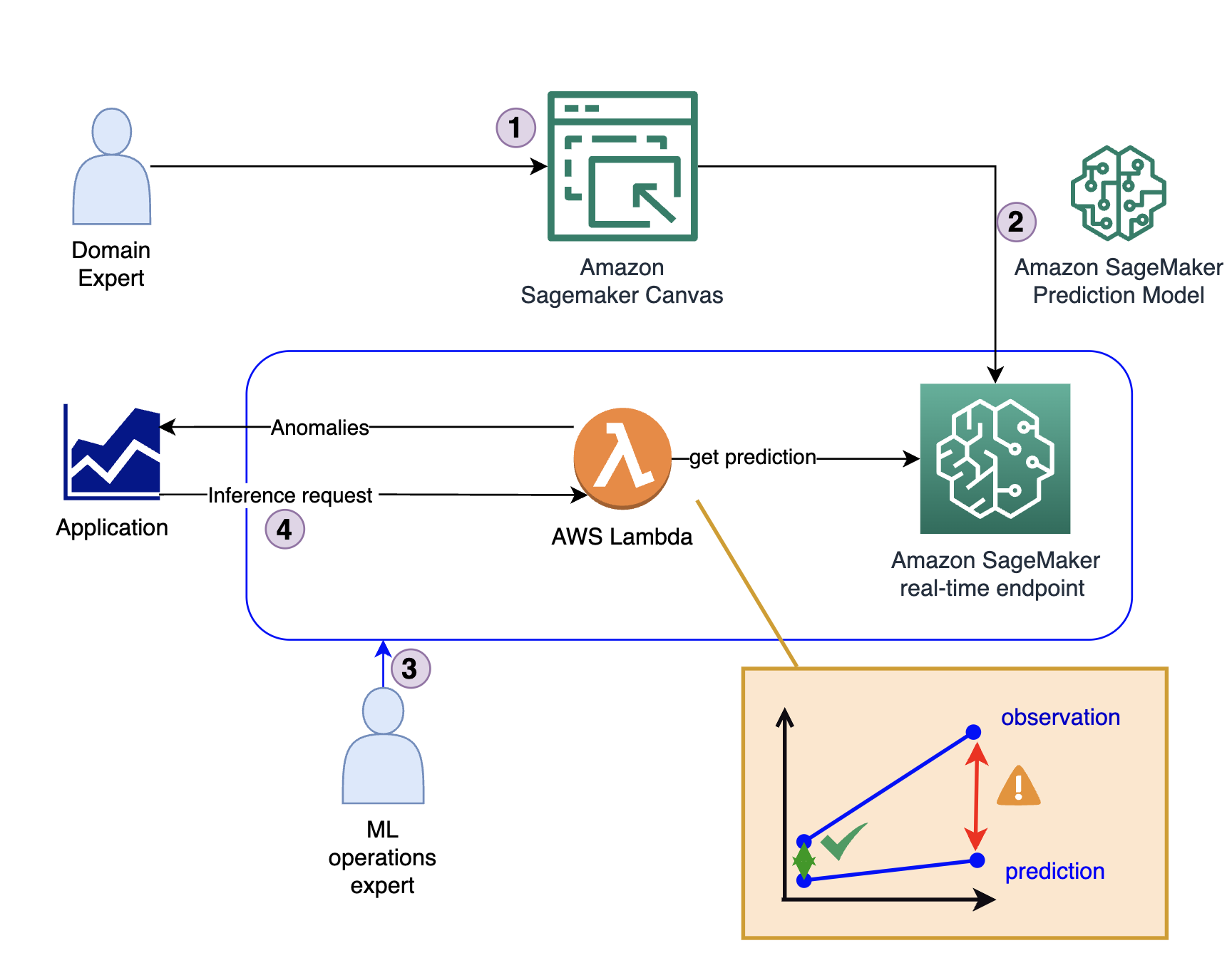
A solução consiste em quatro etapas principais:
- O especialista do domínio cria o modelo inicial, incluindo análise de dados e curadoria de recursos usando o SageMaker Canvas.
- O especialista do domínio compartilha o modelo por meio do Registro de modelos do Amazon SageMaker ou implanta-o diretamente como um endpoint em tempo real.
- Um especialista em MLOps cria a infraestrutura de inferência e o código que traduz a saída do modelo de uma previsão em um indicador de anomalia. Este código normalmente é executado dentro de um AWS Lambda função.
- Quando um aplicativo requer uma detecção de anomalia, ele chama a função Lambda, que usa o modelo para inferência e fornece a resposta (seja ou não uma anomalia).
Pré-requisitos
Para acompanhar esta postagem, você deve atender aos seguintes pré-requisitos:
Crie o modelo usando SageMaker
O processo de criação do modelo segue as etapas padrão para criar um modelo de regressão no SageMaker Canvas. Para obter mais informações, consulte Introdução ao uso do Amazon SageMaker Canvas.
Primeiro, o especialista do domínio carrega dados relevantes no SageMaker Canvas, como uma série temporal de medições. Para esta postagem, usamos um arquivo CSV contendo as medições (geradas sinteticamente) de um motor elétrico. Para obter detalhes, consulte Importar dados para o Canvas. Os dados de amostra utilizados estão disponíveis para download como um CSV.
Organize os dados com SageMaker Canvas
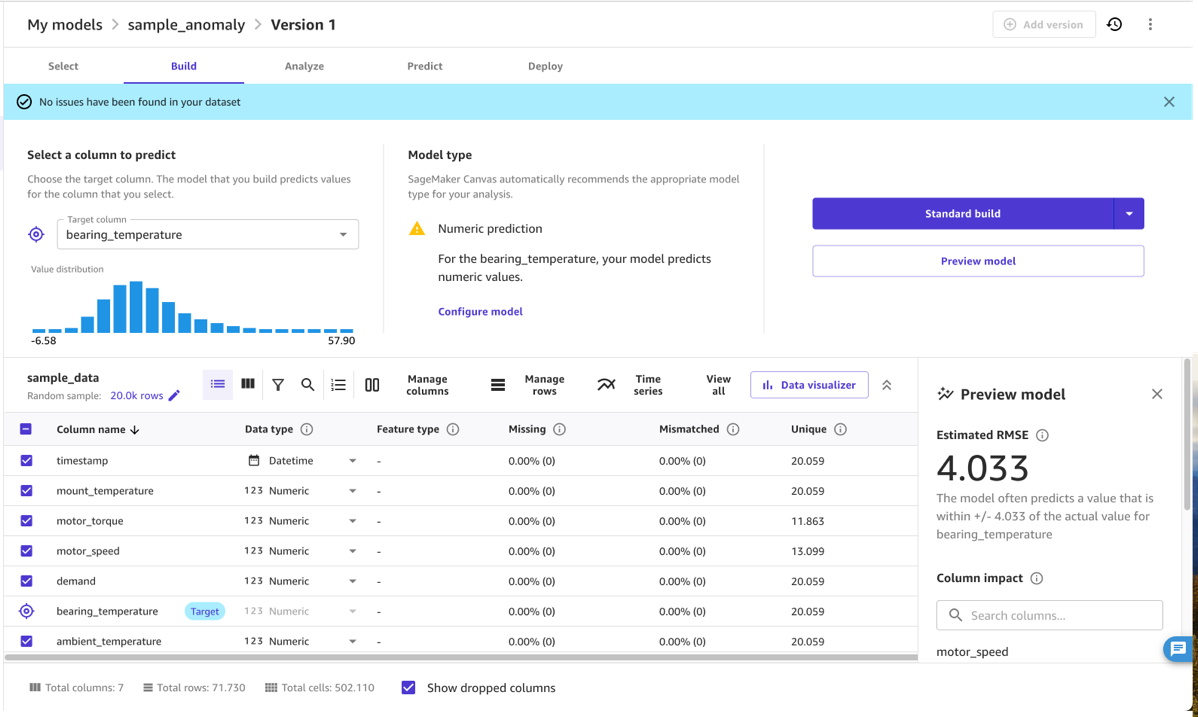
Após o carregamento dos dados, o especialista do domínio pode usar o SageMaker Canvas para selecionar os dados usados no modelo final. Para isso, o especialista seleciona aquelas colunas que contêm medidas características do problema em questão. Mais precisamente, o especialista seleciona colunas que estão relacionadas entre si, por exemplo, por uma relação física, como uma curva de pressão-temperatura, e onde uma alteração nessa relação é uma anomalia relevante para o seu caso de uso. O modelo de detecção de anomalias aprenderá a relação normal entre as colunas selecionadas e indicará quando os dados não estão em conformidade com ela, como uma temperatura do motor anormalmente alta dada a carga atual do motor.
Na prática, o especialista do domínio precisa selecionar um conjunto de colunas de entrada adequadas e uma coluna de destino. As entradas são normalmente a coleção de quantidades (numéricas ou categóricas) que determinam o comportamento de uma máquina, desde configurações de demanda até carga, velocidade ou temperatura ambiente. A saída é normalmente uma quantidade numérica que indica o desempenho da operação da máquina, como uma temperatura que mede a dissipação de energia ou outra métrica de desempenho que muda quando a máquina funciona em condições abaixo do ideal.
Para ilustrar o conceito de quais quantidades selecionar para entrada e saída, vamos considerar alguns exemplos:
- Para equipamentos rotativos, como o modelo que construímos neste post, as entradas típicas são a velocidade de rotação, o torque (corrente e histórico) e a temperatura ambiente, e os alvos são as temperaturas resultantes dos mancais ou do motor, indicando boas condições operacionais das rotações.
- Para uma turbina eólica, as entradas típicas são o histórico atual e recente da velocidade do vento e das configurações das pás do rotor, e a quantidade alvo é a potência produzida ou a velocidade de rotação.
- Para um processo químico, as entradas típicas são a percentagem de diferentes ingredientes e a temperatura ambiente, e os alvos são o calor produzido ou a viscosidade do produto final.
- Para equipamentos móveis, como portas deslizantes, as entradas típicas são a entrada de energia para os motores, e o valor alvo é a velocidade ou o tempo de conclusão do movimento.
- Para um sistema HVAC, as entradas típicas são a diferença de temperatura alcançada e as configurações de carga, e a quantidade alvo é o consumo de energia medido
Em última análise, as entradas e os alvos corretos para um determinado equipamento dependerão do caso de uso e do comportamento anômalo a ser detectado, e são mais conhecidos por um especialista no domínio que esteja familiarizado com as complexidades do conjunto de dados específico.
Na maioria dos casos, selecionar quantidades de entrada e de destino adequadas significa selecionar apenas as colunas corretas e marcar a coluna de destino (para este exemplo, bearing_temperature). No entanto, um especialista em domínio também pode usar os recursos sem código do SageMaker Canvas para transformar colunas e refinar ou agregar os dados. Por exemplo, você pode extrair ou filtrar datas ou carimbos de data/hora específicos dos dados que não são relevantes. O SageMaker Canvas suporta esse processo, mostrando estatísticas sobre as quantidades selecionadas, permitindo entender se uma quantidade possui outliers e spreads que podem afetar os resultados do modelo.
Treine, ajuste e avalie o modelo
Depois que o especialista do domínio selecionar colunas adequadas no conjunto de dados, ele poderá treinar o modelo para aprender a relação entre as entradas e as saídas. Mais precisamente, o modelo aprenderá a prever o valor alvo selecionado nas entradas.
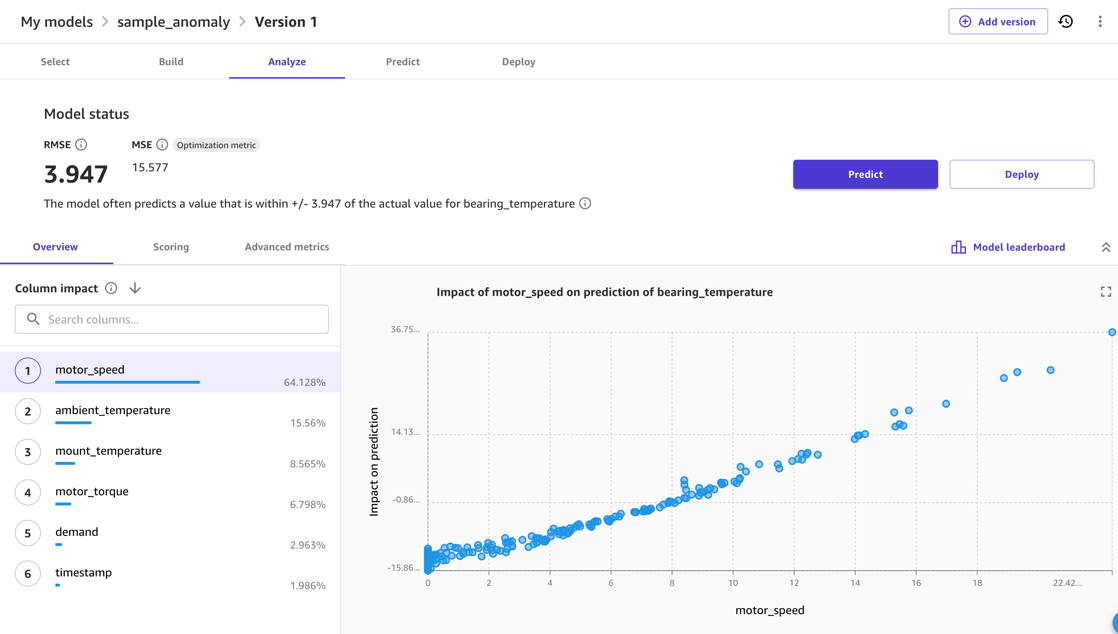
Normalmente, você pode usar o SageMaker Canvas Visualização do modelo opção. Isso fornece uma indicação rápida da qualidade esperada do modelo e permite investigar o efeito que diferentes entradas têm na métrica de saída. Por exemplo, na captura de tela a seguir, o modelo é mais afetado pelo motor_speed e ambient_temperature métricas ao prever bearing_temperature. Isto é sensato, porque estas temperaturas estão intimamente relacionadas. Ao mesmo tempo, o atrito adicional ou outros meios de perda de energia provavelmente afetarão isso.
Para a qualidade do modelo, o RMSE do modelo é um indicador de quão bem o modelo foi capaz de aprender o comportamento normal nos dados de treinamento e reproduzir as relações entre as medidas de entrada e saída. Por exemplo, no modelo a seguir, o modelo deve ser capaz de prever o correto motor_bearing temperatura dentro de 3.67 graus Celsius, então podemos considerar um desvio da temperatura real de uma previsão do modelo que seja maior que, por exemplo, 7.4 graus como uma anomalia. O limite real que você usaria, entretanto, dependerá da sensibilidade necessária no cenário de implantação.
Finalmente, após a conclusão da avaliação e ajuste do modelo, você pode iniciar o treinamento completo do modelo que criará o modelo a ser usado para inferência.
Implantar o modelo
Embora o SageMaker Canvas possa usar um modelo para inferência, a implantação produtiva para detecção de anomalias exige que você implante o modelo fora do SageMaker Canvas. Mais precisamente, precisamos implantar o modelo como um endpoint.
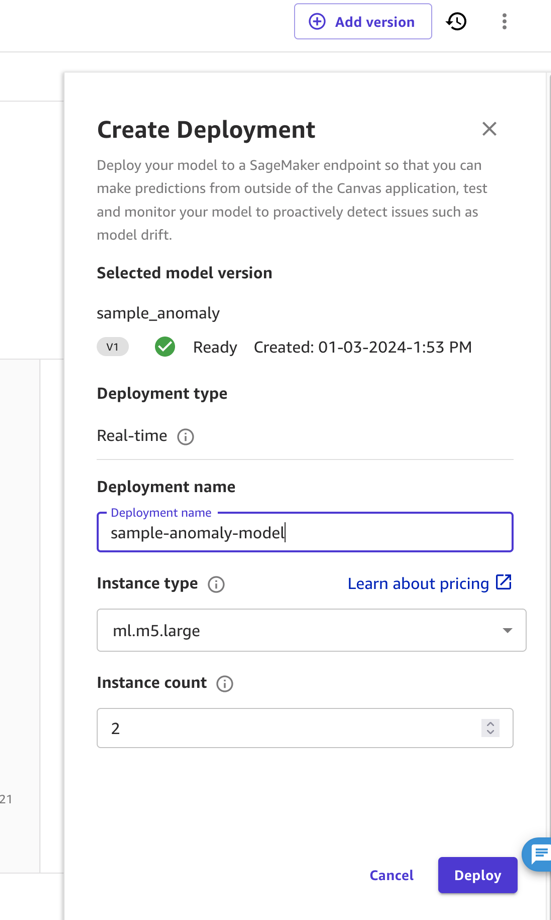
Nesta postagem e para simplificar, implantamos o modelo como um endpoint diretamente do SageMaker Canvas. Para obter instruções, consulte Implante seus modelos em um endpoint. Anote o nome da implantação e considere o preço do tipo de instância em que você implanta (para esta postagem, usamos ml.m5.large). O SageMaker Canvas criará então um endpoint de modelo que pode ser chamado para obter previsões.
Em ambientes industriais, um modelo precisa passar por testes completos antes de poder ser implantado. Para isso, o especialista do domínio não irá implantá-lo, mas sim compartilhar o modelo com o SageMaker Model Registry. Aqui, um especialista em operações MLOps pode assumir o controle. Normalmente, esse especialista testará o endpoint do modelo, avaliará o tamanho do equipamento de computação necessário para o aplicativo de destino e determinará a implantação mais econômica, como implantação para inferência sem servidor ou inferência em lote. Estas etapas são normalmente automatizadas (por exemplo, usando Pipelines do Amazon Sagemaker ou de SDK da Amazon).

Use o modelo para detecção de anomalias
Na etapa anterior, criamos um modelo de implantação no SageMaker Canvas, chamado canvas-sample-anomaly-model. Podemos usá-lo para obter previsões de um bearing_temperature valor com base nas outras colunas do conjunto de dados. Agora, queremos usar este endpoint para detectar anomalias.
Para identificar dados anômalos, nosso modelo usará o ponto final do modelo de previsão para obter o valor esperado da métrica alvo e, em seguida, comparará o valor previsto com o valor real nos dados. O valor previsto indica o valor esperado para nossa métrica alvo com base nos dados de treinamento. A diferença deste valor é, portanto, uma métrica para a anormalidade dos dados reais observados. Podemos usar o seguinte código:
O código anterior executa as seguintes ações:
- Os dados de entrada são filtrados para os recursos corretos (função “
input_transformer"). - O endpoint do modelo SageMaker é invocado com os dados filtrados (função “
do_inference“), onde tratamos da formatação de entrada e saída de acordo com o código de exemplo fornecido ao abrir a página de detalhes de nossa implantação no SageMaker Canvas. - O resultado da chamada é unido aos dados de entrada originais e a diferença é armazenada na coluna de erro (função “
output_transform").
Encontre anomalias e avalie eventos anômalos
Em uma configuração típica, o código para obter anomalias é executado em uma função Lambda. A função Lambda pode ser chamada de um aplicativo ou Gateway de API da Amazon. A função principal retorna uma pontuação de anomalia para cada linha dos dados de entrada – neste caso, uma série temporal de uma pontuação de anomalia.
Para teste, também podemos executar o código em um notebook SageMaker. Os gráficos a seguir mostram as entradas e saídas do nosso modelo ao usar os dados de amostra. Picos no desvio entre os valores previstos e reais (pontuação de anomalia, mostrada no gráfico inferior) indicam anomalias. Por exemplo, no gráfico, podemos ver três picos distintos onde a pontuação de anomalia (diferença entre a temperatura esperada e a real) ultrapassa 7 graus Celsius: o primeiro após um longo tempo ocioso, o segundo com uma queda acentuada de bearing_temperature, e o último onde bearing_temperature é alto em comparação com motor_speed.
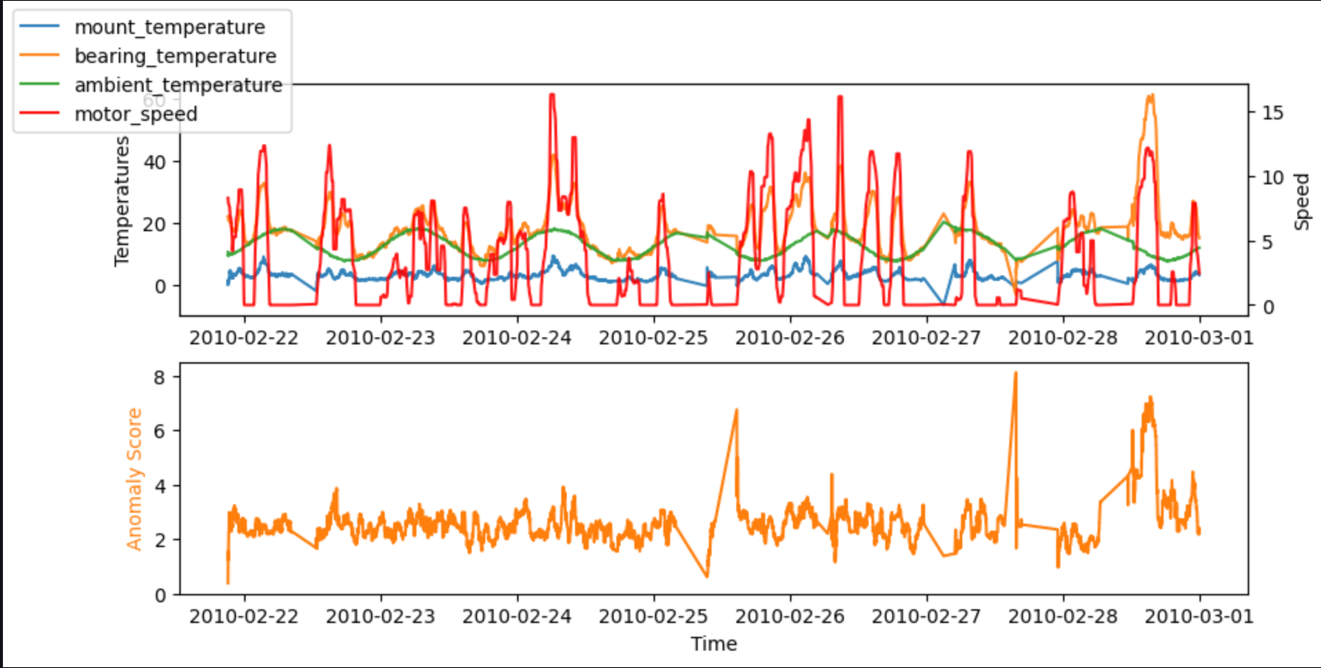
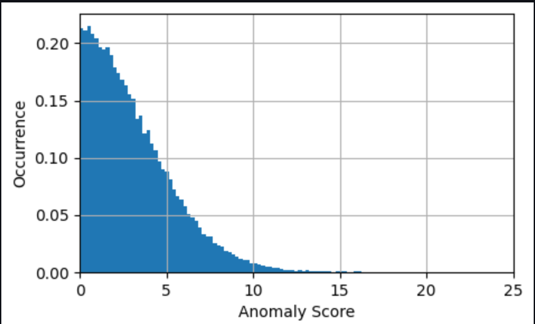
Em muitos casos, conhecer a série temporal da pontuação da anomalia já é suficiente; você pode configurar um limite para avisar sobre uma anomalia significativa com base na necessidade de sensibilidade do modelo. A pontuação atual indica então que uma máquina apresenta um estado anormal que precisa ser investigado. Por exemplo, para o nosso modelo, o valor absoluto da pontuação da anomalia é distribuído conforme mostrado no gráfico a seguir. Isto confirma que a maioria das pontuações de anomalia estão abaixo dos (2xRMS=)8 graus encontrados durante o treinamento do modelo como o erro típico. O gráfico pode ajudá-lo a escolher um limite manualmente, de modo que a porcentagem correta das amostras avaliadas seja marcada como anomalia.
Se a saída desejada forem eventos de anomalias, então as pontuações de anomalias fornecidas pelo modelo requerem refinamento para serem relevantes para uso comercial. Para isso, o especialista em ML normalmente adicionará pós-processamento para remover ruído ou grandes picos na pontuação de anomalia, como adicionar uma média móvel. Além disso, o especialista normalmente avaliará a pontuação da anomalia por uma lógica semelhante à de levantar uma Amazon CloudWatch alarme, como o monitoramento da violação de um limite durante um período específico. Para obter mais informações sobre como configurar alarmes, consulte Usando alarmes do Amazon CloudWatch. A execução dessas avaliações na função Lambda permite enviar avisos, por exemplo, publicando um aviso para um Serviço de notificação simples da Amazon (Amazon SNS) tópico.
limpar
Depois de terminar de usar esta solução, você deve limpar para evitar custos desnecessários:
- No SageMaker Canvas, encontre a implantação do endpoint do seu modelo e exclua-o.
- Saia do SageMaker Canvas para evitar cobranças por seu funcionamento inativo.
Resumo
Nesta postagem, mostramos como um especialista no domínio pode avaliar dados de entrada e criar um modelo de ML usando o SageMaker Canvas sem a necessidade de escrever código. Em seguida, mostramos como usar este modelo para realizar detecção de anomalias em tempo real usando SageMaker e Lambda por meio de um fluxo de trabalho simples. Essa combinação permite que especialistas do domínio usem seu conhecimento para criar modelos de ML poderosos sem treinamento adicional em ciência de dados e permite que especialistas em MLOps usem esses modelos e os disponibilizem para inferência de maneira flexível e eficiente.
Um nível gratuito de 2 meses está disponível para o SageMaker Canvas e, depois disso, você só paga pelo que usar. Comece a experimentar hoje e adicione ML para aproveitar ao máximo seus dados.
Sobre o autor
 Helge Aufderheide é um entusiasta de tornar os dados utilizáveis no mundo real, com forte foco em Automação, Análise e Aprendizado de Máquina em Aplicações Industriais, como Manufatura e Mobilidade.
Helge Aufderheide é um entusiasta de tornar os dados utilizáveis no mundo real, com forte foco em Automação, Análise e Aprendizado de Máquina em Aplicações Industriais, como Manufatura e Mobilidade.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/detect-anomalies-in-manufacturing-data-using-amazon-sagemaker-canvas/

