No cenário em evolução da produção, o poder transformador da IA e da aprendizagem automática (ML) é evidente, impulsionando uma revolução digital que agiliza as operações e aumenta a produtividade. No entanto, este progresso introduz desafios únicos para as empresas que navegam em soluções baseadas em dados. As instalações industriais lidam com vastos volumes de dados não estruturados, provenientes de sensores, sistemas de telemetria e equipamentos dispersos pelas linhas de produção. Os dados em tempo real são essenciais para aplicações como manutenção preditiva e detecção de anomalias, mas o desenvolvimento de modelos de ML personalizados para cada caso de uso industrial com esses dados de série temporal exige tempo e recursos consideráveis dos cientistas de dados, dificultando a adoção generalizada.
IA generativa usando grandes modelos de base pré-treinados (FMs), como Claude pode gerar rapidamente uma variedade de conteúdo, desde texto de conversação até código de computador com base em prompts de texto simples, conhecidos como aviso de tiro zero. Isso elimina a necessidade de os cientistas de dados desenvolverem manualmente modelos de ML específicos para cada caso de uso e, portanto, democratiza o acesso à IA, beneficiando até mesmo os pequenos fabricantes. Os trabalhadores ganham produtividade por meio de insights gerados por IA, os engenheiros podem detectar anomalias proativamente, os gerentes da cadeia de suprimentos otimizam os estoques e a liderança da fábrica toma decisões informadas e baseadas em dados.
No entanto, os FMs independentes enfrentam limitações no tratamento de dados industriais complexos com restrições de tamanho de contexto (normalmente menos de 200,000 tokens), o que coloca desafios. Para resolver isso, você pode usar a capacidade do FM de gerar código em resposta a consultas de linguagem natural (NLQs). Agentes como Pandas AI entra em ação, executando esse código em dados de séries temporais de alta resolução e lidando com erros usando FMs. PandasAI é uma biblioteca Python que adiciona recursos generativos de IA ao pandas, a popular ferramenta de análise e manipulação de dados.
No entanto, NLQs complexos, como processamento de dados de séries temporais, agregação multinível e operações de tabelas dinâmicas ou conjuntas, podem gerar precisão de script Python inconsistente com um prompt zero-shot.
Para aumentar a precisão da geração de código, propomos a construção dinâmica avisos multi-shot para NLQ. Os prompts multi-shot fornecem contexto adicional ao FM, mostrando vários exemplos de saídas desejadas para prompts semelhantes, aumentando a precisão e a consistência. Nesta postagem, prompts multi-shot são recuperados de uma incorporação contendo código Python executado com sucesso em um tipo de dados semelhante (por exemplo, dados de série temporal de alta resolução de dispositivos da Internet das Coisas). O prompt multi-shot construído dinamicamente fornece o contexto mais relevante para o FM e aumenta a capacidade do FM em cálculos matemáticos avançados, processamento de dados de séries temporais e compreensão de acrônimos de dados. Essa resposta aprimorada facilita o envolvimento dos trabalhadores empresariais e das equipes operacionais com os dados, obtendo insights sem a necessidade de extensas habilidades em ciência de dados.
Além da análise de dados de séries temporais, os FMs são valiosos em diversas aplicações industriais. As equipes de manutenção avaliam a integridade dos ativos, capturam imagens para Reconhecimento da Amazôniaresumos de funcionalidade baseados em funções e análise de causa raiz de anomalias usando pesquisas inteligentes com Geração Aumentada de Recuperação (RAG). Para simplificar esses fluxos de trabalho, a AWS introduziu Rocha Amazônica, permitindo que você crie e dimensione aplicativos generativos de IA com FMs pré-treinados de última geração, como Cláudio v2. Com Bases de conhecimento para Amazon Bedrock, você pode simplificar o processo de desenvolvimento do RAG para fornecer uma análise mais precisa da causa raiz da anomalia para os trabalhadores da fábrica. Nossa postagem apresenta um assistente inteligente para casos de uso industrial desenvolvido pela Amazon Bedrock, abordando desafios de NLQ, gerando resumos de peças a partir de imagens e aprimorando respostas de FM para diagnóstico de equipamentos por meio da abordagem RAG.
Visão geral da solução
O diagrama a seguir ilustra a arquitetura da solução.

O fluxo de trabalho inclui três casos de uso distintos:
Caso de uso 1: NLQ com dados de série temporal
O fluxo de trabalho para NLQ com dados de série temporal consiste nas seguintes etapas:
- Usamos um sistema de monitoramento de condições com recursos de ML para detecção de anomalias, como Amazon Monitron, para monitorar a saúde dos equipamentos industriais. O Amazon Monitron é capaz de detectar possíveis falhas de equipamentos a partir de medições de vibração e temperatura do equipamento.
- Coletamos dados de série temporal processando Amazon Monitron dados através Fluxos de dados do Amazon Kinesis e Amazon Data Firehose, convertendo-o em um formato CSV tabular e salvando-o em um Serviço de armazenamento simples da Amazon (Amazon S3).
- O usuário final pode começar a conversar com seus dados de série temporal no Amazon S3 enviando uma consulta em linguagem natural ao aplicativo Streamlit.
- O aplicativo Streamlit encaminha as consultas do usuário para o Modelo de incorporação de texto Amazon Bedrock Titan para incorporar esta consulta e realiza uma pesquisa de similaridade dentro de um Serviço Amazon OpenSearch índice, que contém NLQs anteriores e códigos de exemplo.
- Após a pesquisa de similaridade, os principais exemplos semelhantes, incluindo perguntas NLQ, esquema de dados e códigos Python, são inseridos em um prompt personalizado.
- PandasAI envia este prompt personalizado para o modelo Amazon Bedrock Claude v2.
- O aplicativo usa o agente PandasAI para interagir com o modelo Amazon Bedrock Claude v2, gerando código Python para análise de dados do Amazon Monitron e respostas NLQ.
- Depois que o modelo Amazon Bedrock Claude v2 retorna o código Python, o PandasAI executa a consulta Python nos dados do Amazon Monitron carregados do aplicativo, coletando saídas de código e abordando quaisquer novas tentativas necessárias para execuções com falha.
- O aplicativo Streamlit coleta a resposta via PandasAI e fornece a saída aos usuários. Se a saída for satisfatória, o usuário pode marcá-la como útil, salvando o código Python gerado por NLQ e Claude no OpenSearch Service.
Caso de uso 2: geração resumida de peças com defeito
Nosso caso de uso de geração de resumo consiste nas seguintes etapas:
- Após o usuário saber qual ativo industrial apresenta comportamento anômalo, ele poderá fazer upload de imagens da peça com defeito para identificar se há algo fisicamente errado com esta peça de acordo com sua especificação técnica e condição de funcionamento.
- O usuário pode usar o API DetectText de reconhecimento da Amazon para extrair dados de texto dessas imagens.
- Os dados de texto extraídos são incluídos no prompt do modelo Amazon Bedrock Claude v2, permitindo que o modelo gere um resumo de 200 palavras da peça com defeito. O usuário pode usar essas informações para realizar inspeções adicionais da peça.
Caso de uso 3: diagnóstico de causa raiz
Nosso caso de uso de diagnóstico de causa raiz consiste nas seguintes etapas:
- O usuário obtém dados corporativos em vários formatos de documento (PDF, TXT e assim por diante) relacionados a ativos com defeito e os carrega em um bucket S3.
- Uma base de conhecimento desses arquivos é gerada no Amazon Bedrock com um modelo de embeddings de texto Titan e um armazenamento de vetores padrão do OpenSearch Service.
- O usuário coloca questões relacionadas ao diagnóstico da causa raiz do mau funcionamento do equipamento. As respostas são geradas por meio da base de conhecimento Amazon Bedrock com uma abordagem RAG.
Pré-requisitos
Para acompanhar esta postagem, você deve atender aos seguintes pré-requisitos:
Implante a infraestrutura da solução
Para configurar os recursos da solução, conclua as etapas a seguir:
- Implante o Formação da Nuvem AWS modelo opensearchsagemaker.yml, que cria uma coleção e um índice do OpenSearch Service, Amazon Sage Maker instância de notebook e bucket S3. Você pode nomear esta pilha do AWS CloudFormation como:
genai-sagemaker. - Abra a instância do notebook SageMaker no JupyterLab. Você encontrará o seguinte GitHub repo já baixado nesta instância: desbloqueando o potencial da IA generativa em operações industriais.
- Execute o notebook no seguinte diretório neste repositório: desbloqueando o potencial de IA generativa em operações industriais/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Este notebook carregará o índice do OpenSearch Service usando o notebook SageMaker para armazenar pares de valores-chave do 23 exemplos NLQ existentes.
- Carregar documentos da pasta de dados ativopartdoc no repositório GitHub para o bucket S3 listado nas saídas da pilha do CloudFormation.

A seguir, você cria a base de conhecimento para os documentos no Amazon S3.
- No console do Amazon Bedrock, escolha Base de conhecimento no painel de navegação.
- Escolha Criar base de conhecimento.
- Escolha Nome da base de conhecimento, Insira o nome.
- Escolha Função de tempo de execução, selecione Criar e usar uma nova função de serviço.
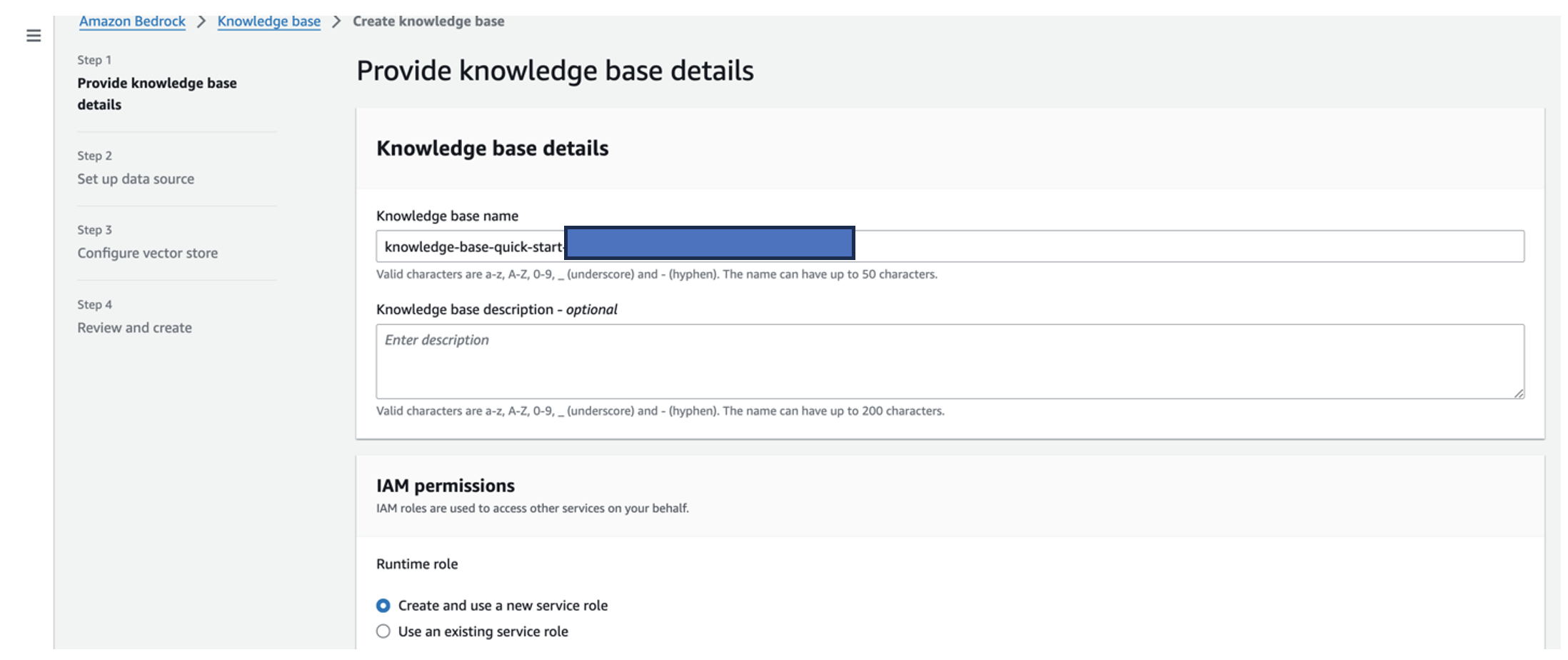
- Escolha Nome da fonte de dados, insira o nome da sua fonte de dados.
- Escolha URI S3, insira o caminho S3 do bucket onde você fez upload dos documentos de causa raiz.
- Escolha Próximo.
 O modelo de embeddings Titan é selecionado automaticamente.
O modelo de embeddings Titan é selecionado automaticamente. - Selecionar Crie rapidamente um novo armazenamento de vetores.
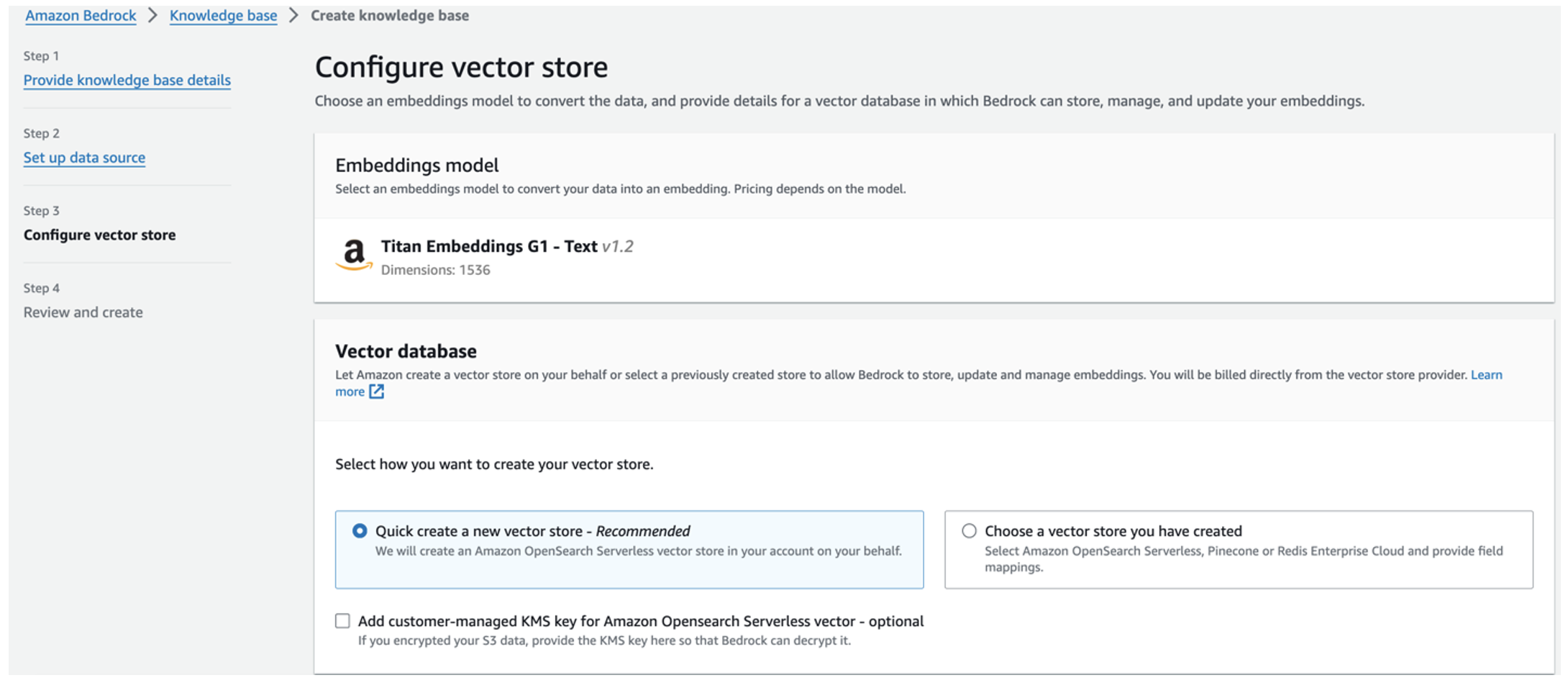
- Revise suas configurações e crie a base de conhecimento escolhendo Criar base de conhecimento.
- Depois que a base de conhecimento for criada com sucesso, escolha sincronização para sincronizar o bucket S3 com a base de conhecimento.

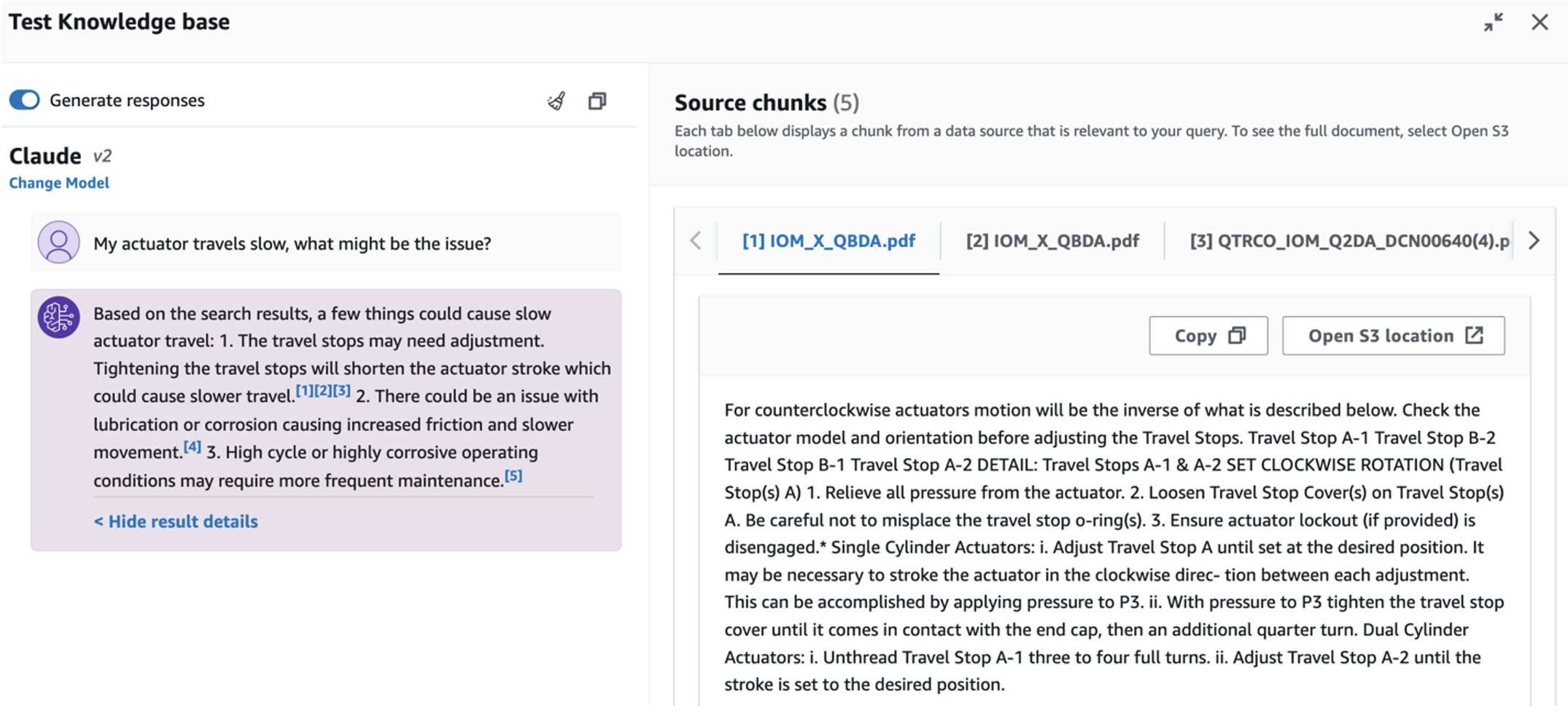
- Depois de configurar a base de conhecimento, você pode testar a abordagem RAG para diagnóstico de causa raiz fazendo perguntas como “Meu atuador se desloca lentamente, qual pode ser o problema?”
A próxima etapa é implantar o aplicativo com os pacotes de biblioteca necessários em seu PC ou em uma instância EC2 (Ubuntu Server 22.04 LTS).
- Configure suas credenciais da AWS com a AWS CLI em seu PC local. Para simplificar, você pode usar a mesma função de administrador usada para implantar a pilha do CloudFormation. Se você estiver usando o Amazon EC2, anexe uma função IAM adequada à instância.
- clone GitHub repo:
- Mude o diretório para
unlocking-the-potential-of-generative-ai-in-industrial-operations/srce execute osetup.shscript nesta pasta para instalar os pacotes necessários, incluindo LangChain e PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Execute o aplicativo Streamlit com o seguinte comando:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Forneça o ARN da coleção do OpenSearch Service que você criou no Amazon Bedrock na etapa anterior.
Converse com seu assistente de integridade de ativos
Após concluir a implantação ponta a ponta, você poderá acessar o aplicativo via localhost na porta 8501, que abre uma janela do navegador com a interface web. Se você implantou o aplicativo em uma instância do EC2, permitir acesso à porta 8501 por meio da regra de entrada do grupo de segurança. Você pode navegar para diferentes guias para vários casos de uso.
Explore o caso de uso 1
Para explorar o primeiro caso de uso, escolha Insight e gráfico de dados. Comece enviando seus dados de série temporal. Se você não tiver um arquivo de dados de série temporal existente para usar, poderá fazer upload do seguinte exemplo de arquivo CSV com dados anônimos do projeto Amazon Monitron. Se você já possui um projeto Amazon Monitron, consulte Gere insights acionáveis para gerenciamento de manutenção preditiva com Amazon Monitron e Amazon Kinesis para transmitir seus dados do Amazon Monitron para o Amazon S3 e usar seus dados com este aplicativo.
Quando o upload for concluído, insira uma consulta para iniciar uma conversa com seus dados. A barra lateral esquerda oferece vários exemplos de perguntas para sua conveniência. As capturas de tela a seguir ilustram a resposta e o código Python gerado pelo FM ao inserir uma pergunta como “Diga-me o número exclusivo de sensores para cada site mostrado como Aviso ou Alarme, respectivamente?” (uma pergunta de nível difícil) ou “Para sensores que mostram o sinal de temperatura como NÃO Saudável, você pode calcular a duração em dias para cada sensor que mostra um sinal de vibração anormal?” (uma pergunta de nível de desafio). O aplicativo responderá sua pergunta e também mostrará o script Python de análise de dados realizado para gerar tais resultados.


Se estiver satisfeito com a resposta, você pode marcá-la como Útil, salvando o código Python gerado por NLQ e Claude em um índice do OpenSearch Service.

Explore o caso de uso 2
Para explorar o segundo caso de uso, escolha o Resumo da imagem capturada guia no aplicativo Streamlit. Você pode fazer upload de uma imagem do seu ativo industrial e o aplicativo irá gerar um resumo de 200 palavras de suas especificações técnicas e condições de operação com base nas informações da imagem. A captura de tela a seguir mostra o resumo gerado a partir de uma imagem de um motor de correia. Para testar esse recurso, se você não tiver uma imagem adequada, poderá usar o seguinte imagem de exemplo.
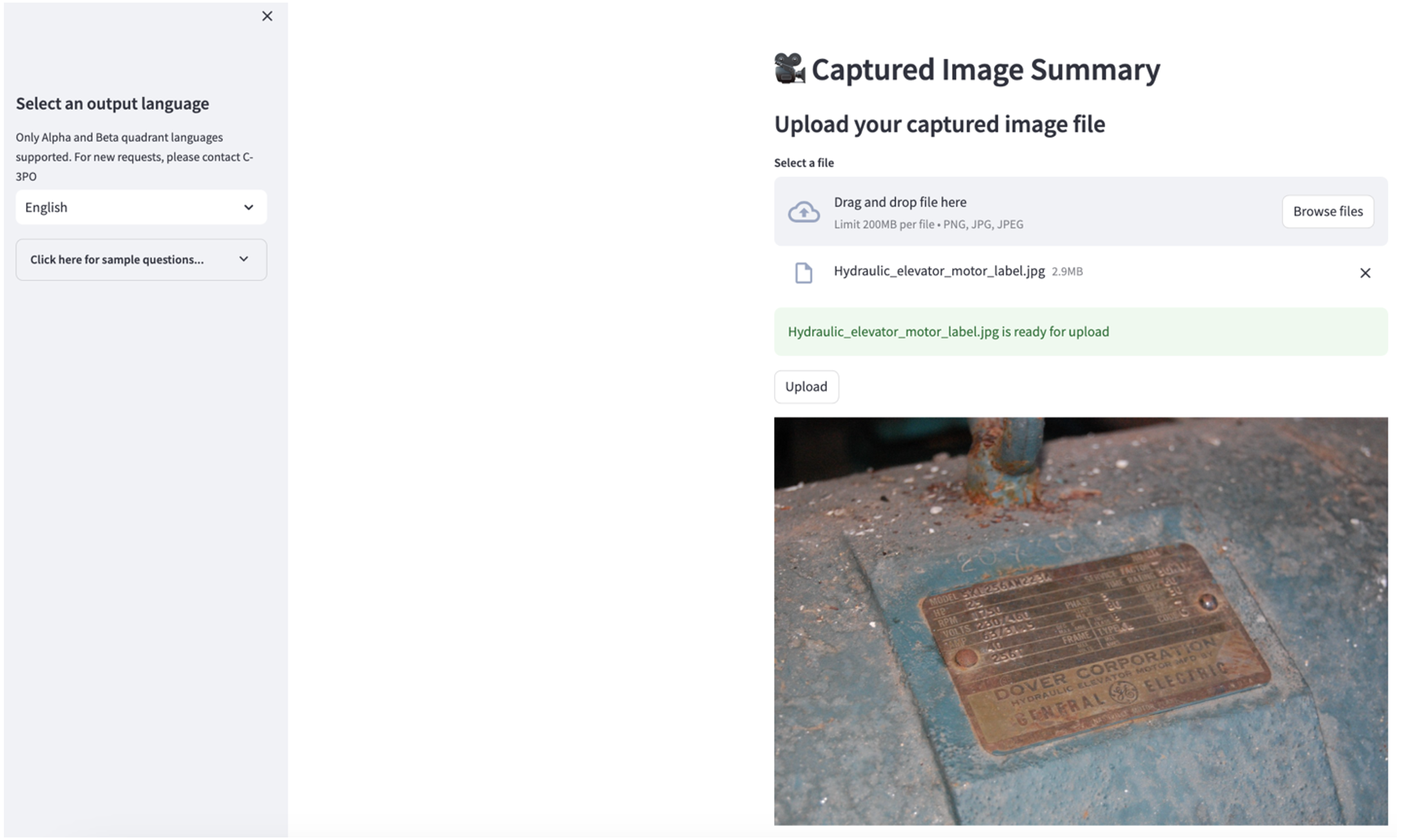
Etiqueta do motor do elevador hidráulico”por Clarence Risher está licenciado sob CC BY-SA 2.0.

Explore o caso de uso 3
Para explorar o terceiro caso de uso, escolha o Diagnóstico de causa raiz aba. Insira uma consulta relacionada ao seu ativo industrial quebrado, como “Meu atuador anda devagar, qual pode ser o problema?” Conforme ilustrado na captura de tela a seguir, o aplicativo entrega uma resposta com o trecho do documento de origem usado para gerar a resposta.
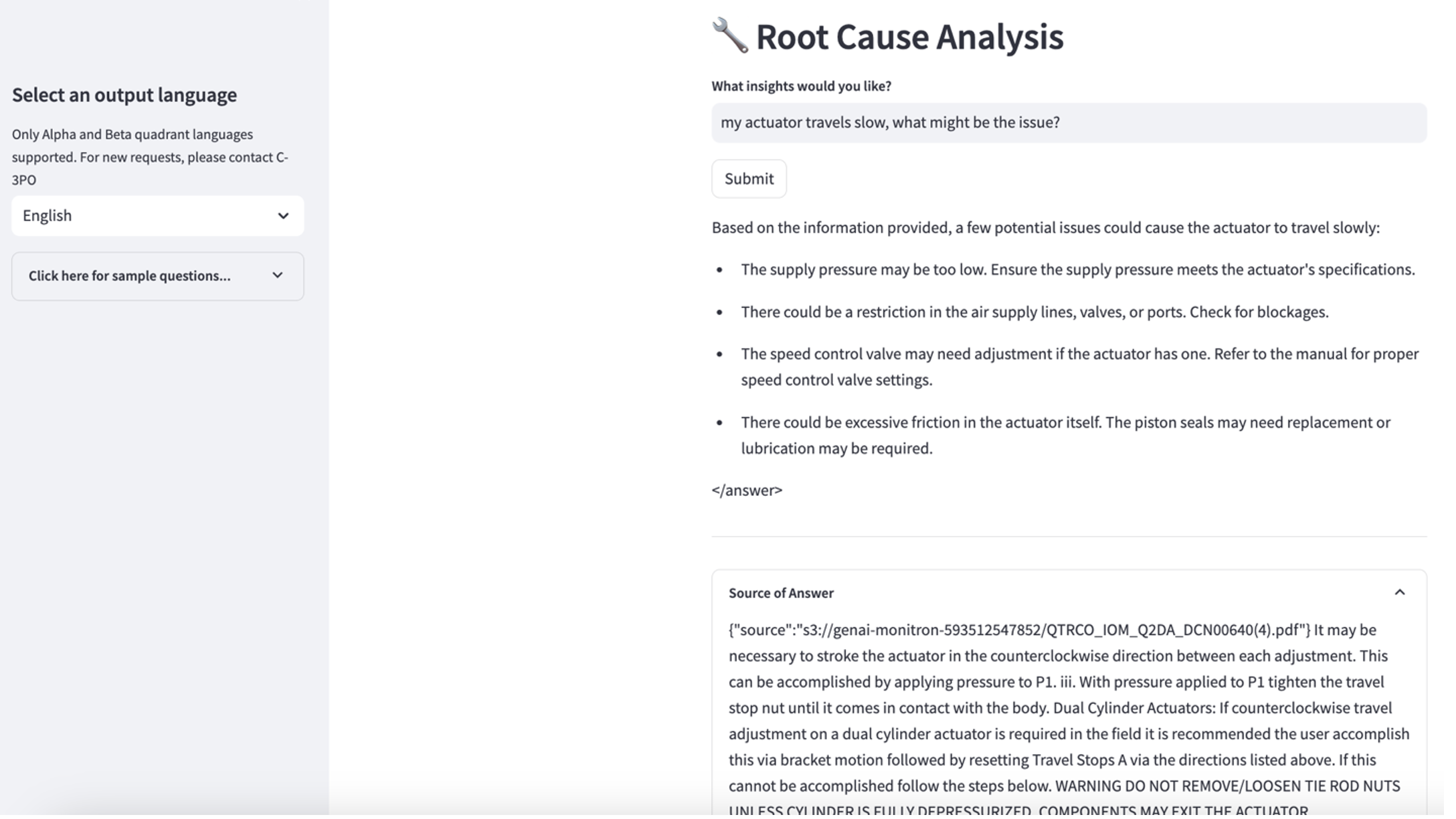
Caso de uso 1: detalhes do design
Nesta seção, discutimos os detalhes de design do fluxo de trabalho do aplicativo para o primeiro caso de uso.
Criação de prompt personalizado
A consulta em linguagem natural do usuário vem com diferentes níveis de dificuldade: fácil, difícil e desafiador.
Perguntas diretas podem incluir as seguintes solicitações:
- Selecione valores exclusivos
- Conte os números totais
- Classificar valores
Para essas questões, o PandasAI pode interagir diretamente com o FM para gerar scripts Python para processamento.
Perguntas difíceis requerem operação básica de agregação ou análise de série temporal, como a seguir:
- Selecione o valor primeiro e agrupe os resultados hierarquicamente
- Execute estatísticas após a seleção inicial do registro
- Contagem de carimbo de data/hora (por exemplo, mínimo e máximo)
Para perguntas difíceis, um modelo de prompt com instruções passo a passo detalhadas ajuda os FMs a fornecer respostas precisas.
As questões de nível de desafio precisam de cálculos matemáticos avançados e processamento de séries temporais, como os seguintes:
- Calcule a duração da anomalia para cada sensor
- Calcular sensores de anomalia para o local mensalmente
- Compare as leituras do sensor sob operação normal e condições anormais
Para essas perguntas, você pode usar vários disparos em um prompt personalizado para aumentar a precisão da resposta. Essas múltiplas tomadas mostram exemplos de processamento avançado de séries temporais e cálculos matemáticos, e fornecerão contexto para o FM realizar inferências relevantes em análises semelhantes. Inserir dinamicamente os exemplos mais relevantes de um banco de questões NLQ no prompt pode ser um desafio. Uma solução é construir embeddings a partir de amostras de perguntas NLQ existentes e salvá-los em um armazenamento de vetores como o OpenSearch Service. Quando uma pergunta é enviada para o aplicativo Streamlit, a pergunta será vetorizada por BedrockEmbeddings. Os N principais embeddings mais relevantes para essa questão são recuperados usando opensearch_vector_search.similarity_search e inserido no modelo de prompt como um prompt multi-shot.
O diagrama a seguir ilustra esse fluxo de trabalho.
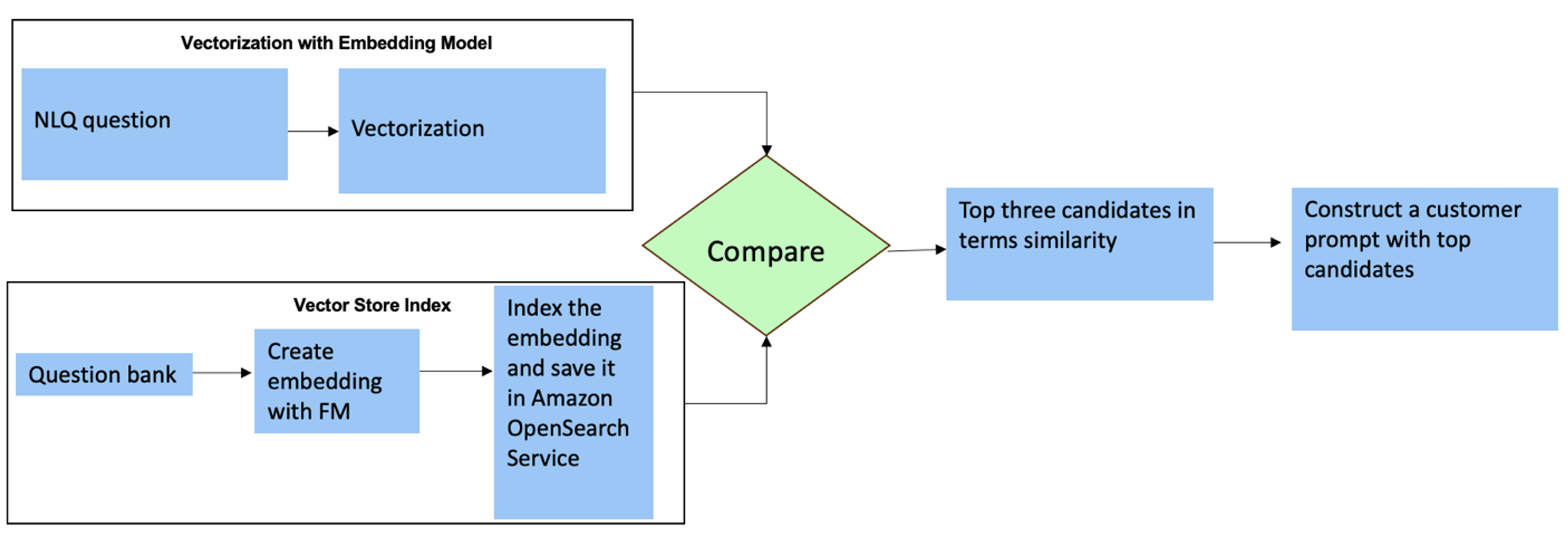
A camada de incorporação é construída usando três ferramentas principais:
- Modelo de incorporações – Usamos Amazon Titan Embeddings disponíveis no Amazon Bedrock (amazon.titan-embed-text-v1) para gerar representações numéricas de documentos textuais.
- Loja de vetores – Para nosso armazenamento de vetores, utilizamos OpenSearch Service através do framework LangChain, agilizando o armazenamento de embeddings gerados a partir de exemplos de NLQ neste notebook.
- Índice – O índice do OpenSearch Service desempenha um papel fundamental na comparação de incorporações de entrada com incorporações de documentos e na facilitação da recuperação de documentos relevantes. Como os códigos de exemplo do Python foram salvos como um arquivo JSON, eles foram indexados no OpenSearch Service como vetores por meio de um OpenSearchVevtorSearch.fromtexts Chamada API.
Coleta contínua de exemplos auditados por humanos via Streamlit
No início do desenvolvimento do aplicativo, começamos com apenas 23 exemplos salvos no índice do OpenSearch Service como embeddings. À medida que o aplicativo entra em operação em campo, os usuários começam a inserir seus NLQs por meio do aplicativo. No entanto, devido aos exemplos limitados disponíveis no modelo, alguns NLQs podem não encontrar instruções semelhantes. Para enriquecer continuamente esses embeddings e oferecer prompts de usuário mais relevantes, você pode usar o aplicativo Streamlit para coletar exemplos auditados por humanos.
Dentro do aplicativo, a função a seguir atende a esse propósito. Quando os usuários finais consideram o resultado útil e selecionam Útil, o aplicativo segue estas etapas:
- Use o método de retorno de chamada do PandasAI para coletar o script Python.
- Reformate o script Python, a pergunta de entrada e os metadados CSV em uma string.
- Verifique se este exemplo de NLQ já existe no índice atual do OpenSearch Service usando opensearch_vector_search.similarity_search_with_score.
- Se não houver um exemplo semelhante, este NLQ será adicionado ao índice do OpenSearch Service usando opensearch_vector_search.add_texts.
Caso um usuário selecione Não ajuda, nenhuma ação será tomada. Este processo iterativo garante que o sistema melhore continuamente, incorporando exemplos fornecidos pelos usuários.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Ao incorporar a auditoria humana, a quantidade de exemplos no OpenSearch Service disponíveis para incorporação imediata aumenta à medida que o aplicativo ganha uso. Esse conjunto de dados de incorporação expandido resulta em maior precisão de pesquisa ao longo do tempo. Especificamente, para NLQs desafiadores, a precisão da resposta do FM atinge aproximadamente 90% ao inserir dinamicamente exemplos semelhantes para construir prompts personalizados para cada pergunta de NLQ. Isto representa um aumento notável de 28% em comparação com cenários sem avisos multi-shot.
Caso de uso 2: detalhes do design
No aplicativo Streamlit Resumo da imagem capturada guia, você pode fazer upload diretamente de um arquivo de imagem. Isso inicia a API do Amazon Rekognition (detectar_texto API), extraindo texto do rótulo da imagem detalhando as especificações da máquina. Posteriormente, os dados de texto extraídos são enviados ao modelo Amazon Bedrock Claude como contexto de um prompt, resultando em um resumo de 200 palavras.
Do ponto de vista da experiência do usuário, habilitar a funcionalidade de streaming para uma tarefa de resumo de texto é fundamental, permitindo que os usuários leiam o resumo gerado pelo FM em pedaços menores, em vez de esperar pela saída inteira. Amazon Bedrock facilita o streaming por meio de sua API (bedrock_runtime.invoke_model_with_response_stream).
Caso de uso 3: detalhes do design
Neste cenário, desenvolvemos uma aplicação chatbot focada na análise de causa raiz, empregando a abordagem RAG. Este chatbot baseia-se em vários documentos relacionados a equipamentos de rolamento para facilitar a análise da causa raiz. Este chatbot de análise de causa raiz baseado em RAG usa bases de conhecimento para gerar representações de texto vetorial ou incorporações. As bases de conhecimento do Amazon Bedrock são um recurso totalmente gerenciado que ajuda a implementar todo o fluxo de trabalho do RAG, desde a ingestão até a recuperação e o aumento imediato, sem precisar criar integrações personalizadas para fontes de dados ou gerenciar fluxos de dados e detalhes de implementação do RAG.
Quando estiver satisfeito com a resposta da base de conhecimento do Amazon Bedrock, você poderá integrar a resposta da causa raiz da base de conhecimento ao aplicativo Streamlit.
limpar
Para economizar custos, exclua os recursos que você criou nesta postagem:
- Exclua a base de conhecimento do Amazon Bedrock.
- Exclua o índice do OpenSearch Service.
- Exclua a pilha genai-sagemaker CloudFormation.
- Pare a instância do EC2 se você usou uma instância do EC2 para executar o aplicativo Streamlit.
Conclusão
As aplicações de IA generativa já transformaram vários processos de negócios, aumentando a produtividade e os conjuntos de habilidades dos trabalhadores. No entanto, as limitações dos FMs no tratamento da análise de dados de séries temporais impediram a sua plena utilização pelos clientes industriais. Esta restrição impediu a aplicação de IA generativa ao tipo de dados predominante processado diariamente.
Nesta postagem, apresentamos uma solução generativa de aplicativos de IA projetada para aliviar esse desafio para usuários industriais. Este aplicativo usa um agente de código aberto, PandasAI, para fortalecer a capacidade de análise de série temporal de um FM. Em vez de enviar dados de séries temporais diretamente para FMs, o aplicativo emprega PandasAI para gerar código Python para a análise de dados de séries temporais não estruturados. Para aumentar a precisão da geração de código Python, foi implementado um fluxo de trabalho personalizado de geração de prompts com auditoria humana.
Capacitados com insights sobre a saúde de seus ativos, os trabalhadores industriais podem aproveitar totalmente o potencial da IA generativa em vários casos de uso, incluindo diagnóstico de causa raiz e planejamento de substituição de peças. Com as bases de conhecimento do Amazon Bedrock, a solução RAG é simples para os desenvolvedores criarem e gerenciarem.
A trajetória do gerenciamento e das operações de dados empresariais está inequivocamente caminhando para uma integração mais profunda com a IA generativa para obter insights abrangentes sobre a saúde operacional. Essa mudança, liderada pela Amazon Bedrock, é significativamente amplificada pela crescente robustez e potencial de LLMs como Amazona Bedrock Claude 3 para elevar ainda mais as soluções. Para saber mais, acesse consulte o Documentação do Amazon Bedrocke coloque a mão na massa com o Oficina Amazon Bedrock.
Sobre os autores
 Júlia Hu é arquiteto sênior de soluções de IA/ML na Amazon Web Services. Ela é especializada em IA Generativa, Ciência de Dados Aplicada e arquitetura IoT. Atualmente ela faz parte da equipe Amazon Q e é membro/mentora ativa na Comunidade de Campo Técnico de Machine Learning. Ela trabalha com clientes, desde start-ups até empresas, para desenvolver soluções de IA generativas AWSome. Ela é particularmente apaixonada por aproveitar grandes modelos de linguagem para análise avançada de dados e explorar aplicações práticas que abordam desafios do mundo real.
Júlia Hu é arquiteto sênior de soluções de IA/ML na Amazon Web Services. Ela é especializada em IA Generativa, Ciência de Dados Aplicada e arquitetura IoT. Atualmente ela faz parte da equipe Amazon Q e é membro/mentora ativa na Comunidade de Campo Técnico de Machine Learning. Ela trabalha com clientes, desde start-ups até empresas, para desenvolver soluções de IA generativas AWSome. Ela é particularmente apaixonada por aproveitar grandes modelos de linguagem para análise avançada de dados e explorar aplicações práticas que abordam desafios do mundo real.
 Sudeesh Sasidharan é arquiteto de soluções sênior na AWS, dentro da equipe de energia. Sudeesh adora experimentar novas tecnologias e construir soluções inovadoras que resolvam desafios de negócios complexos. Quando ele não está projetando soluções ou mexendo nas tecnologias mais recentes, você pode encontrá-lo na quadra de tênis trabalhando no backhand.
Sudeesh Sasidharan é arquiteto de soluções sênior na AWS, dentro da equipe de energia. Sudeesh adora experimentar novas tecnologias e construir soluções inovadoras que resolvam desafios de negócios complexos. Quando ele não está projetando soluções ou mexendo nas tecnologias mais recentes, você pode encontrá-lo na quadra de tênis trabalhando no backhand.
 Neil Desai é um executivo de tecnologia com mais de 20 anos de experiência em inteligência artificial (IA), ciência de dados, engenharia de software e arquitetura empresarial. Na AWS, ele lidera uma equipe mundial de arquitetos de soluções especialistas em serviços de IA que ajudam os clientes a criar soluções inovadoras baseadas em IA generativa, compartilhar práticas recomendadas com os clientes e impulsionar o roteiro de produtos. Em suas funções anteriores na Vestas, Honeywell e Quest Diagnostics, Neil ocupou cargos de liderança no desenvolvimento e lançamento de produtos e serviços inovadores que ajudaram empresas a melhorar suas operações, reduzir custos e aumentar receitas. Ele é apaixonado por usar tecnologia para resolver problemas do mundo real e é um pensador estratégico com histórico comprovado de sucesso.
Neil Desai é um executivo de tecnologia com mais de 20 anos de experiência em inteligência artificial (IA), ciência de dados, engenharia de software e arquitetura empresarial. Na AWS, ele lidera uma equipe mundial de arquitetos de soluções especialistas em serviços de IA que ajudam os clientes a criar soluções inovadoras baseadas em IA generativa, compartilhar práticas recomendadas com os clientes e impulsionar o roteiro de produtos. Em suas funções anteriores na Vestas, Honeywell e Quest Diagnostics, Neil ocupou cargos de liderança no desenvolvimento e lançamento de produtos e serviços inovadores que ajudaram empresas a melhorar suas operações, reduzir custos e aumentar receitas. Ele é apaixonado por usar tecnologia para resolver problemas do mundo real e é um pensador estratégico com histórico comprovado de sucesso.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

