Cliente 360 (C360) fornece uma visão completa e unificada das interações e do comportamento de um cliente em todos os pontos de contato e canais. Essa visualização é usada para identificar padrões e tendências no comportamento do cliente, que podem informar decisões baseadas em dados para melhorar os resultados de negócios. Por exemplo, você pode usar o C360 para segmentar e criar campanhas de marketing com maior probabilidade de repercutir em grupos específicos de clientes.
Em 2022, a AWS encomendou um estudo conduzido pelo American Productivity and Quality Center (APQC) para quantificar o Valor comercial do Customer 360. A figura a seguir mostra algumas das métricas derivadas do estudo. As organizações que usam o C360 alcançaram uma redução de 43.9% na duração do ciclo de vendas, um aumento de 22.8% no valor da vida do cliente, um tempo de lançamento no mercado 25.3% mais rápido e uma melhoria de 19.1% na classificação do Net Promoter Score (NPS).

Sem o C360, as empresas enfrentam oportunidades perdidas, relatórios imprecisos e experiências desarticuladas dos clientes, levando à rotatividade de clientes. No entanto, construir uma solução C360 pode ser complicado. A Pesquisa de marketing do Gartner descobriram que apenas 14% das organizações implementaram com sucesso uma solução C360, devido à falta de consenso sobre o que significa uma visão de 360 graus, aos desafios com a qualidade dos dados e à falta de uma estrutura de governação multifuncional para os dados dos clientes.
Nesta postagem, discutimos como você pode usar serviços AWS desenvolvidos especificamente para criar uma estratégia de dados ponta a ponta para o C360 para unificar e controlar os dados do cliente que abordam esses desafios. Nós o estruturamos em cinco pilares que impulsionam o C360: coleta de dados, unificação, análise, ativação e governança de dados, juntamente com uma arquitetura de solução que você pode usar para sua implementação.
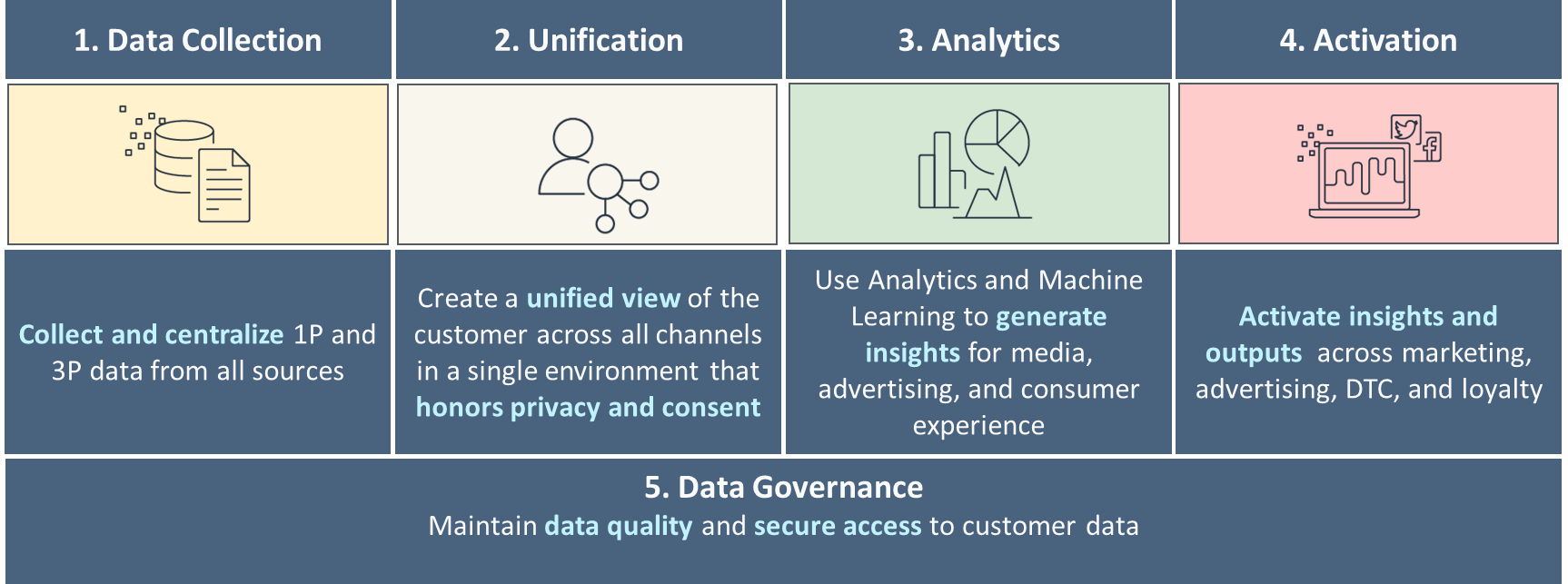
Os cinco pilares de um C360 maduro
Ao embarcar na criação de um C360, você trabalha com vários casos de uso, tipos de dados de clientes e usuários e aplicativos que exigem ferramentas diferentes. Construir um C360 nos conjuntos de dados certos, adicionar novos conjuntos de dados ao longo do tempo e, ao mesmo tempo, manter a qualidade dos dados e mantê-los seguros, requer uma estratégia de dados de ponta a ponta para os dados do seu cliente. Você também precisa fornecer ferramentas que facilitem para suas equipes a criação de produtos que amadureçam seu C360.
Recomendamos construir sua estratégia de dados em torno dos cinco pilares do C360, conforme mostrado na figura a seguir. Isto começa com a recolha de dados básicos, unificando e ligando dados de vários canais relacionados com clientes únicos, e avança para análises básicas a avançadas para a tomada de decisões e envolvimento personalizado através de vários canais. À medida que você amadurece em cada um desses pilares, você progride no sentido de responder aos sinais dos clientes em tempo real.
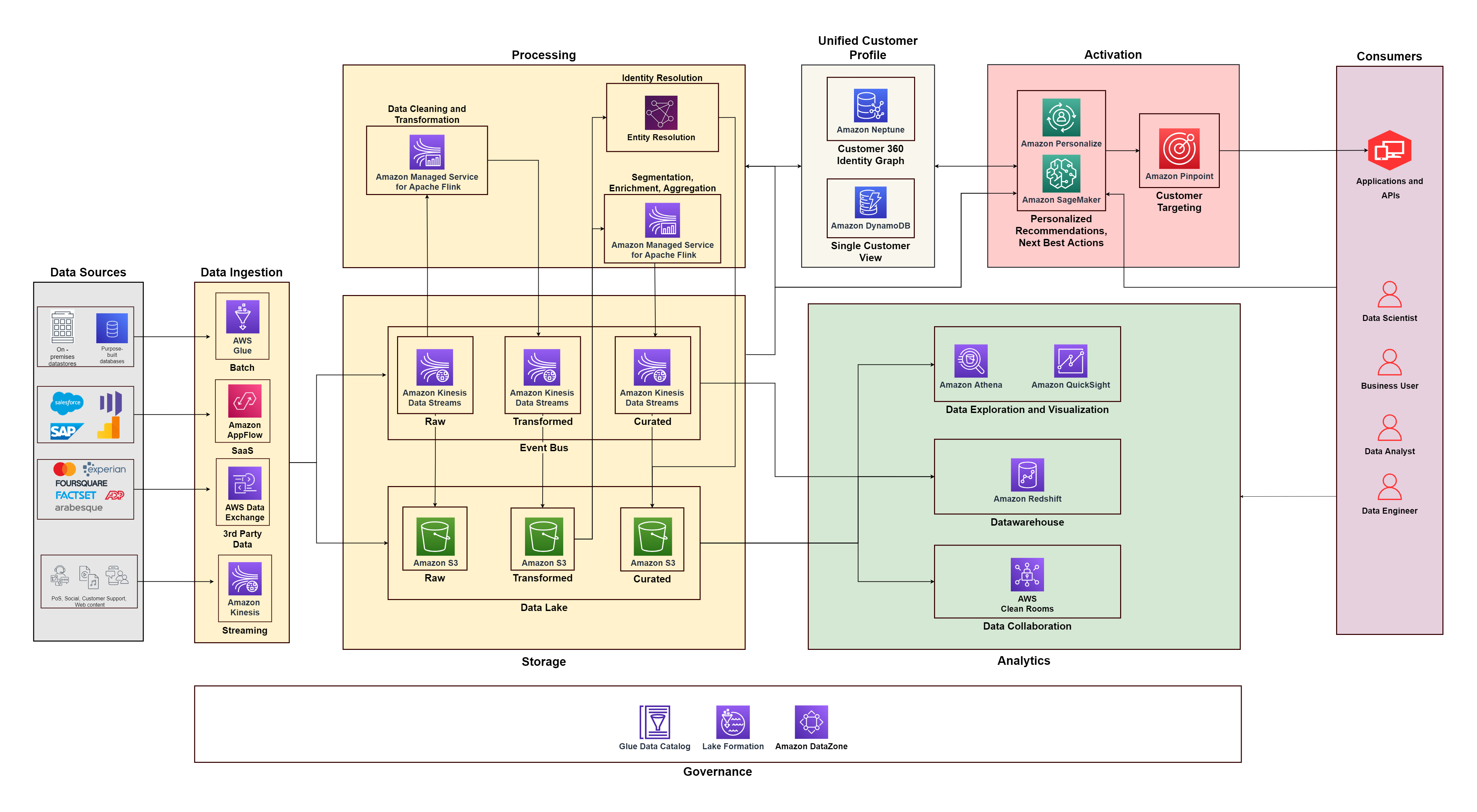
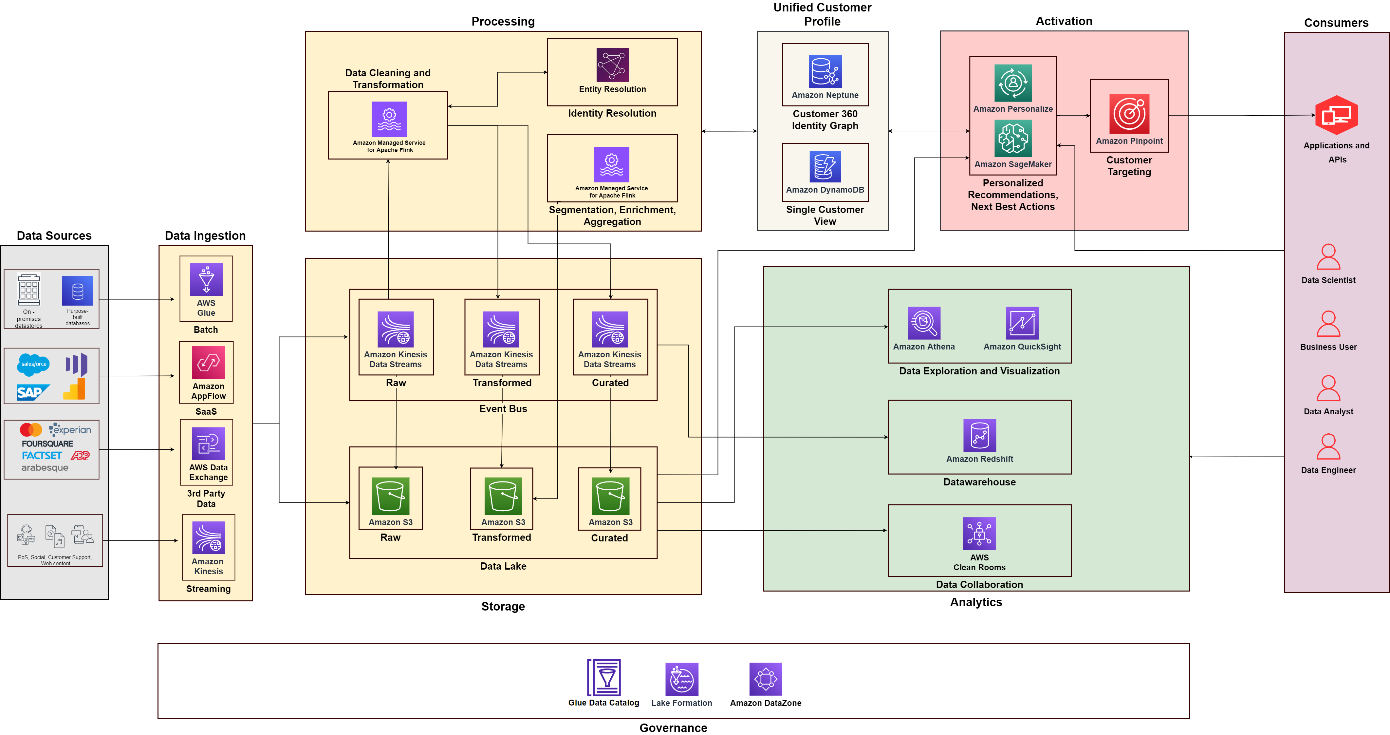
O diagrama a seguir ilustra a arquitetura funcional que combina os blocos de construção de um Plataforma de dados do cliente na AWS com componentes adicionais usados para projetar uma solução C360 completa. Isso está alinhado aos cinco pilares que discutimos neste post.
Pilar 1: Coleta de dados
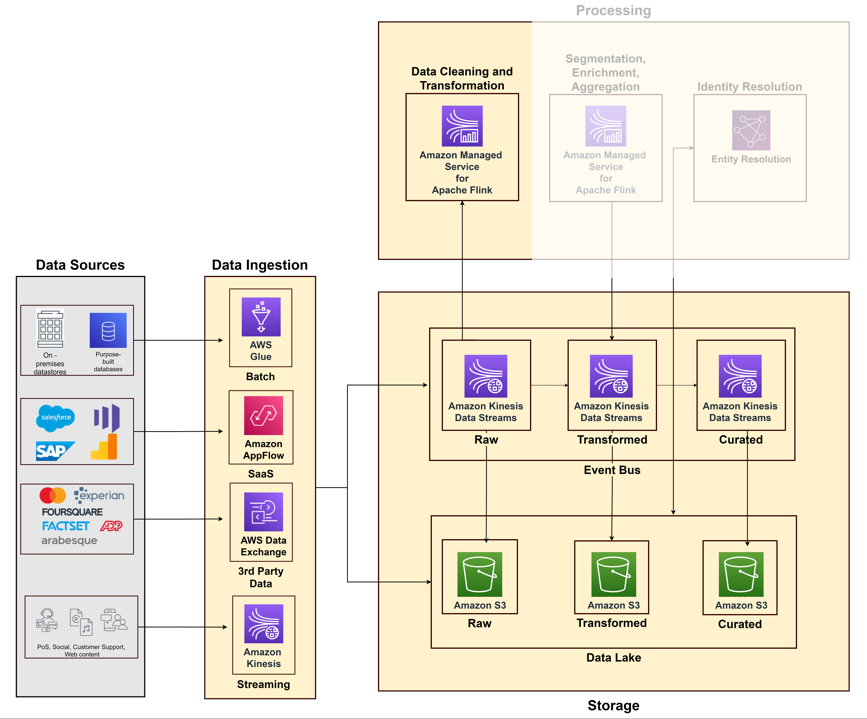
Ao começar a construir sua plataforma de dados de clientes, você precisa coletar dados de vários sistemas e pontos de contato, como sistemas de vendas, suporte ao cliente, mídias sociais e da web e mercados de dados. Pense no pilar de coleta de dados como uma combinação de recursos de ingestão, armazenamento e processamento.
Ingestão de dados
Você precisa criar pipelines de ingestão com base em fatores como tipos de fontes de dados (armazenamentos de dados locais, arquivos, aplicativos SaaS, dados de terceiros) e fluxo de dados (fluxos ilimitados ou dados em lote). A AWS fornece diferentes serviços para a construção de pipelines de ingestão de dados:
- Cola AWS é um serviço de integração de dados sem servidor que ingere dados em lotes de bancos de dados locais e armazenamentos de dados na nuvem. Ele se conecta a mais de 70 fontes de dados e ajuda a criar pipelines de extração, transformação e carregamento (ETL) sem precisar gerenciar a infraestrutura de pipeline. Qualidade de dados do AWS Glue verifica e alerta sobre dados ruins, facilitando a detecção e correção de problemas antes que eles prejudiquem seus negócios.
- Fluxo de aplicativos da Amazon ingere dados de aplicativos de software como serviço (SaaS), como Google Analytics, Salesforce, SAP e Marketo, oferecendo flexibilidade para ingerir dados de mais de 50 aplicativos SaaS.
- Troca de dados da AWS torna mais fácil encontrar, assinar e usar dados de terceiros para análise. Você pode assinar produtos de dados que ajudam a enriquecer os perfis dos clientes, por exemplo, dados demográficos, dados de publicidade e dados dos mercados financeiros.
- Amazon Kinesis ingere eventos de streaming em tempo real de sistemas de ponto de venda, dados de fluxo de cliques de aplicativos móveis e sites e dados de mídia social. Você também pode considerar usar Amazon Managed Streaming para Apache Kafka (Amazon MSK) para streaming de eventos em tempo real.
O diagrama a seguir ilustra os diferentes pipelines para ingerir dados de vários sistemas de origem usando serviços da AWS.
Armazenamento de dados
Dados em lote estruturados, semiestruturados ou não estruturados são armazenados em um armazenamento de objetos porque são econômicos e duráveis. Serviço de armazenamento simples da Amazon (Amazon S3) é um serviço de armazenamento gerenciado com recursos de arquivamento que pode armazenar petabytes de dados com onze 9 de durabilidade. Os dados de streaming com necessidades de baixa latência são armazenados em Fluxos de dados do Amazon Kinesis para consumo em tempo real. Isso permite análises e ações imediatas para vários consumidores posteriores, como visto no caso central da Riot Games. Ônibus de evento de motim.
Processamento de dados
Os dados brutos costumam estar cheios de duplicatas e formatos irregulares. Você precisa processar isso para deixá-lo pronto para análise. Se você estiver consumindo dados em lote e dados de streaming, considere usar uma estrutura que possa lidar com ambos. Um padrão como o Arquitetura Kappa vê tudo como um fluxo, simplificando os pipelines de processamento. Considere usar Serviço gerenciado da Amazon para Apache Flink para lidar com o trabalho de processamento. Com o Managed Service for Apache Flink, você pode limpar e transformar os dados de streaming e direcioná-los para o destino apropriado com base nos requisitos de latência. Você também pode implementar o processamento de dados em lote usando Amazon EMR em estruturas de código aberto, como Apache Spark com desempenho 3.5 vezes melhor do que a versão autogerenciada. A decisão arquitetônica de usar um sistema de processamento em lote ou streaming dependerá de vários fatores; no entanto, se você deseja permitir análises em tempo real dos dados de seus clientes, recomendamos o uso de um padrão de arquitetura Kappa.
Pilar 2: Unificação
Para vincular os diversos dados que chegam de vários pontos de contato a um cliente único, você precisa construir uma solução de processamento de identidade que identifique logins anônimos, armazene informações úteis do cliente, vincule-os a dados externos para obter melhores insights e agrupe os clientes em domínios de interesse. Embora a solução de processamento de identidade ajude a construir o perfil unificado do cliente, recomendamos considerar isso como parte dos seus recursos de processamento de dados. O diagrama a seguir ilustra os componentes de tal solução.
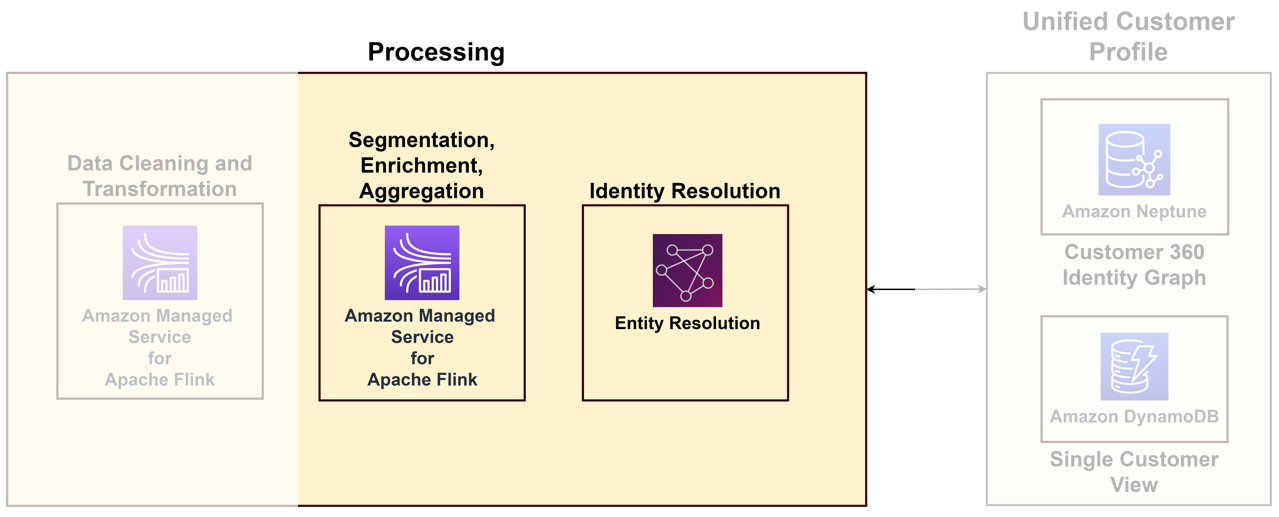
Os principais componentes são os seguintes:
- resolução de identidade – A resolução de identidade é uma solução de desduplicação, onde os registros são comparados para identificar um cliente único e clientes potenciais, vinculando vários identificadores, como cookies, identificadores de dispositivos, endereços IP, IDs de e-mail e IDs empresariais internos a uma pessoa conhecida ou perfil anônimo usando privacidade- métodos compatíveis. Isto pode ser conseguido usando Resolução de entidade AWS, que permite o uso de regras e técnicas de aprendizado de máquina (ML) para combinar registros e resolver identidades. Alternativamente, você pode construir gráficos de identidade utilização Amazon Netuno para uma visão única e unificada de seus clientes.
- Agregação de perfil – Depois de identificar um cliente de forma exclusiva, você pode construir aplicativos no serviço gerenciado para Apache Flink para consolidar todos os seus metadados, desde o nome até o histórico de interação. Em seguida, você transforma esses dados em um formato conciso. Em vez de mostrar todos os detalhes da transação, você pode oferecer um valor de gasto agregado e um link para o registro de gerenciamento de relacionamento com o cliente (CRM). Para interações de atendimento ao cliente, forneça uma pontuação CSAT média e um link para o sistema de call center para um mergulho mais profundo em seu histórico de comunicação.
- Enriquecimento de perfil – Depois de resolver um cliente para uma identidade única, aprimore seu perfil usando diversas fontes de dados. O enriquecimento normalmente envolve a adição de dados demográficos, comportamentais e de geolocalização. Você pode usar produtos de dados de terceiros do AWS Marketplace entregues por meio do AWS Data Exchange para obter insights sobre renda, padrões de consumo, pontuações de risco de crédito e muitas outras dimensões para refinar ainda mais a experiência do cliente.
- Segmentação de clientes – Depois de identificar e enriquecer exclusivamente o perfil de um cliente, você pode segmentá-lo com base em dados demográficos como idade, gastos, renda e localização usando aplicativos no Managed Service para Apache Flink. À medida que avança, você pode incorporar Serviços de IA para técnicas de segmentação mais precisas.
Depois de concluir o processamento e a segmentação de identidade, você precisará de um recurso de armazenamento para armazenar o perfil exclusivo do cliente e fornecer recursos de pesquisa e consulta para que os consumidores downstream possam usar os dados enriquecidos do cliente.
O diagrama a seguir ilustra o pilar de unificação para um perfil de cliente unificado e uma visão única do cliente para aplicativos downstream.
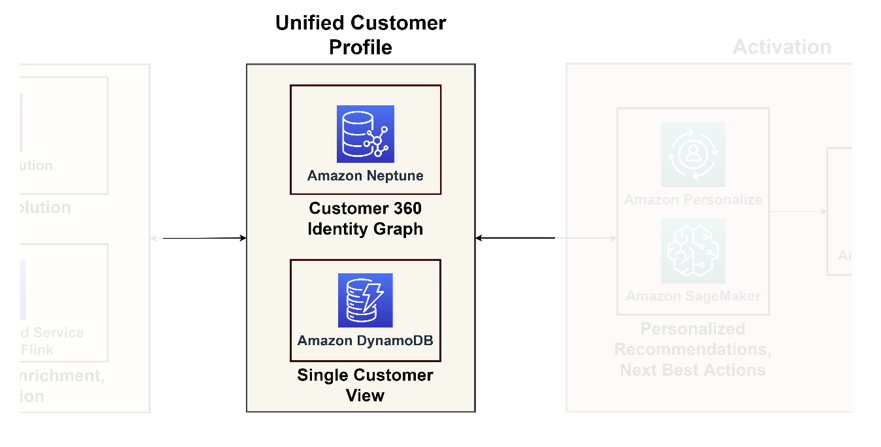
Perfil de cliente unificado
Os bancos de dados gráficos são excelentes na modelagem de interações e relacionamentos com clientes, oferecendo uma visão abrangente da jornada do cliente. Se você está lidando com bilhões de perfis e interações, pode considerar usar o Neptune, um serviço gerenciado de banco de dados gráfico na AWS. Organizações como Zeta e Activision usaram com sucesso o Neptune para armazenar e consultar bilhões de identificadores exclusivos por mês e milhões de consultas por segundo com tempo de resposta de milissegundos.
Visão única do cliente
Embora os bancos de dados gráficos forneçam insights aprofundados, eles podem ser complexos para aplicações regulares. É prudente consolidar estes dados numa visão única do cliente, servindo como referência primária para aplicações a jusante, que vão desde plataformas de comércio eletrónico a sistemas CRM. Essa visão consolidada atua como um elo de ligação entre a plataforma de dados e os aplicativos centrados no cliente. Para tais fins, recomendamos o uso Amazon DynamoDB por sua adaptabilidade, escalabilidade e desempenho, resultando em um banco de dados de clientes atualizado e eficiente. Este banco de dados aceitará muitas consultas de gravação dos sistemas de ativação que aprendem novas informações sobre os clientes e os retornam.
Pilar 3: Análise
O pilar analítico define recursos que ajudam você a gerar insights sobre os dados de seus clientes. Sua estratégia analítica se aplica às necessidades organizacionais mais amplas, não apenas ao C360. Você pode usar os mesmos recursos para fornecer relatórios financeiros, medir o desempenho operacional ou até mesmo monetizar ativos de dados. Crie estratégias com base em como suas equipes exploram dados, executam análises, organizam dados para requisitos posteriores e visualizam dados em diferentes níveis. Planeje como você pode permitir que suas equipes usem ML para passar de análises descritivas para prescritivas.
A Arquitetura de dados moderna da AWS mostra uma maneira de construir uma plataforma de dados específica, segura e escalável na nuvem. Aprenda com isso para criar recursos de consulta em seu data lake e data warehouse.
O diagrama a seguir divide a capacidade analítica em exploração de dados, visualização, armazenamento de dados e colaboração de dados. Vamos descobrir qual o papel de cada um desses componentes no contexto do C360.

Exploração de dados
A exploração de dados ajuda a descobrir inconsistências, valores discrepantes ou erros. Ao identificá-los desde o início, suas equipes podem ter uma integração de dados mais limpa para o C360, o que, por sua vez, leva a análises e previsões mais precisas. Considere as personas que exploram os dados, suas habilidades técnicas e o tempo necessário para obter insights. Por exemplo, analistas de dados que sabem escrever SQL podem consultar diretamente os dados residentes no Amazon S3 usando Amazona atena. Os usuários interessados na exploração visual podem fazê-lo usando Produção de dados do AWS Glue. Cientistas ou engenheiros de dados podem usar Estúdio Amazon EMR or Estúdio Amazon SageMaker para explorar dados do notebook e para uma experiência de baixo código, você pode usar Gerenciador de dados do Amazon SageMaker. Como esses serviços consultam diretamente os buckets do S3, você pode explorar os dados à medida que eles chegam ao data lake, reduzindo o tempo de obtenção de insights.
Visualização
Transformar conjuntos de dados complexos em visuais intuitivos revela padrões ocultos nos dados e é crucial para casos de uso do C360. Com esse recurso, você pode criar relatórios para diferentes níveis atendendo a diversas necessidades: relatórios executivos que oferecem visões estratégicas, relatórios gerenciais destacando métricas operacionais e relatórios detalhados que abordam detalhes específicos. Essa clareza visual ajuda sua organização a tomar decisões informadas em todos os níveis, centralizando a perspectiva do cliente.
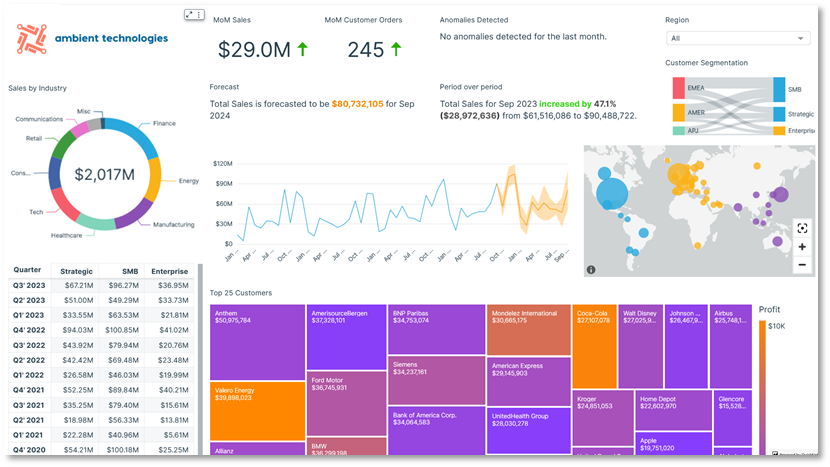
O diagrama a seguir mostra um exemplo de painel do C360 criado em AmazonQuickSight. QuickSight oferece recursos de visualização escalonáveis e sem servidor. Você pode se beneficiar de suas integrações de ML para obter insights automatizados, como previsão e detecção de anomalias ou consultas em linguagem natural com Amazon Q no QuickSight, conectividade direta de dados de várias fontes e preços de pagamento por sessão. Com o QuickSight, você pode incorporar painéis em sites e aplicativos externos, e as SPICE O mecanismo permite visualização de dados rápida e interativa em escala. A captura de tela a seguir mostra um exemplo de painel do C360 criado no QuickSight.
Armazém de dados
Os data warehouses são eficientes na consolidação de dados estruturados de diversas fontes e no atendimento de consultas analíticas de um grande número de usuários simultâneos. Os data warehouses podem fornecer uma visão unificada e consistente de uma grande quantidade de dados de clientes para casos de uso do C360. Amazon RedShift atende a essa necessidade lidando habilmente com grandes volumes de dados e diversas cargas de trabalho. Ele fornece forte consistência entre conjuntos de dados, permitindo que as organizações obtenham insights confiáveis e abrangentes sobre seus clientes, o que é essencial para uma tomada de decisão informada. O Amazon Redshift oferece insights em tempo real e recursos de análise preditiva para analisar dados de terabytes a petabytes. Com Amazon RedshiftML, você pode incorporar o ML aos dados armazenados no data warehouse com sobrecarga mínima de desenvolvimento. Sem servidor Amazon Redshift simplifica a criação de aplicativos e facilita para as empresas a incorporação de recursos avançados de análise de dados.
Colaboração de dados
Você pode com segurança colaborar e analisar conjuntos de dados coletivos de seus parceiros sem compartilhar ou copiar os dados subjacentes uns dos outros usando Salas limpas da AWS. Você pode reunir dados díspares de canais de engajamento e conjuntos de dados de parceiros para formar uma visão de 360 graus de seus clientes. O AWS Clean Rooms pode aprimorar o C360, permitindo casos de uso como otimização de marketing entre canais, segmentação avançada de clientes e personalização compatível com privacidade. Ao mesclar conjuntos de dados com segurança, oferece insights mais ricos e privacidade de dados robusta, atendendo às necessidades de negócios e aos padrões regulatórios.
Pilar 4: Ativação
O valor dos dados diminui à medida que envelhecem, levando a custos de oportunidade mais elevados ao longo do tempo. Em uma pesquisa conduzido pela Intersystems, 75% das organizações pesquisadas acreditam que dados inoportunos inibiram oportunidades de negócios. Em outra pesquisa, 58% de organizações (de 560 entrevistados do conselho consultivo e leitores da HBR) afirmaram ter visto um aumento na retenção e fidelidade de clientes usando análises de clientes em tempo real.
Você pode atingir a maturidade no C360 ao desenvolver a capacidade de agir em tempo real com base em todos os insights adquiridos nos pilares anteriores que discutimos. Por exemplo, neste nível de maturidade, você pode agir de acordo com o sentimento do cliente com base no contexto derivado automaticamente com um perfil de cliente enriquecido e canais integrados. Para isso, você precisa implementar uma tomada de decisão prescritiva sobre como abordar o sentimento do cliente. Para fazer isso em grande escala, você precisa usar serviços de IA/ML para tomada de decisões. O diagrama a seguir ilustra a arquitetura para ativar insights usando ML para análises prescritivas e serviços de IA para direcionamento e segmentação.
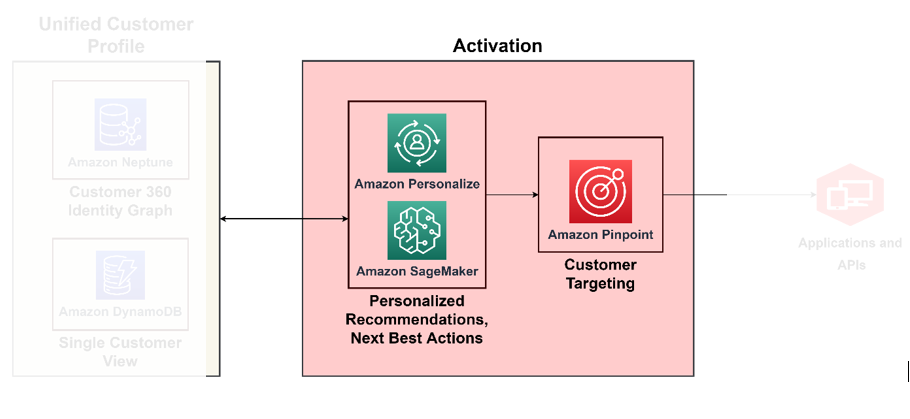
Use ML como mecanismo de tomada de decisão
Com o ML, você pode melhorar a experiência geral do cliente: você pode criar modelos preditivos de comportamento do cliente, projetar ofertas hiperpersonalizadas e atingir o cliente certo com o incentivo certo. Você pode construí-los usando Amazon Sage Maker, que apresenta um conjunto de serviços gerenciados mapeados para o ciclo de vida da ciência de dados, incluindo organização de dados, treinamento de modelo, hospedagem de modelo, inferência de modelo, detecção de desvio de modelo e armazenamento de recursos. SageMaker permite que você crie e operacionalize seus modelos de ML, infundindo-os de volta em seus aplicativos para produzir o insight certo para a pessoa certa, no momento certo.
Amazon Customize oferece suporte a recomendações contextuais, por meio das quais você pode melhorar a relevância das recomendações gerando-as dentro de um contexto — por exemplo, tipo de dispositivo, local ou hora do dia. Sua equipe pode começar sem qualquer experiência anterior em ML, usando APIs para criar recursos sofisticados de personalização com apenas alguns cliques. Para mais informações, veja Personalize suas recomendações promovendo itens específicos usando regras de negócios com o Amazon Personalize.
Ative canais de marketing, publicidade, direto ao consumidor e fidelidade
Agora que você sabe quem são seus clientes e quem contatar, você pode criar soluções para executar campanhas de segmentação em grande escala. Com Amazon identificar, você pode personalizar e segmentar as comunicações para envolver os clientes em vários canais. Por exemplo, você pode usar o Amazon Pinpoint para crie experiências envolventes para o cliente por meio de vários canais de comunicação, como e-mail, SMS, notificações push e notificações no aplicativo.
Pilar 5: Governança de dados
Estabelecer a governança correta que equilibre controle e acesso dá aos usuários confiança e confiança nos dados. Imagine oferecer promoções de produtos que um cliente não precisa ou bombardear os clientes errados com notificações. A má qualidade dos dados pode levar a tais situações e, em última análise, resultar na rotatividade de clientes. Você precisa construir processos que validem a qualidade dos dados e tomem ações corretivas. Qualidade de dados do AWS Glue pode ajudá-lo a criar soluções que validem a qualidade dos dados em repouso e em trânsito, com base em regras predefinidas.
Para configurar uma estrutura de governança multifuncional para dados de clientes, você precisa de capacidade para governar e compartilhar dados em toda a sua organização. Com Zona de dados da Amazon, administradores e administradores de dados podem gerenciar e governar o acesso aos dados, e consumidores como engenheiros de dados, cientistas de dados, gerentes de produtos, analistas e outros usuários corporativos podem descobrir, usar e colaborar com esses dados para gerar insights. Ele agiliza o acesso aos dados, permitindo encontrar e usar dados do cliente, promove a colaboração da equipe com ativos de dados compartilhados e fornece análises personalizadas por meio de um aplicativo da web ou API em um portal. Formação AWS Lake garante que os dados sejam acessados com segurança, garantindo que as pessoas certas vejam os dados certos pelos motivos certos, o que é crucial para uma governança multifuncional eficaz em qualquer organização. Os metadados de negócios são armazenados e gerenciados pelo Amazon DataZone, que é sustentado por metadados técnicos e informações de esquema, registrados no Catálogo de dados do AWS Glue. Esses metadados técnicos também são usados por outros serviços de governança, como Lake Formation e Amazon DataZone, e serviços de análise, como Amazon Redshift, Athena e AWS Glue.

Juntando tudo
Usando o diagrama a seguir como referência, você pode criar projetos e equipes para construir e operar diferentes capacidades. Por exemplo, você pode ter uma equipe de integração de dados focada no pilar de coleta de dados – você pode então alinhar funções funcionais, como arquitetos e engenheiros de dados. Você pode desenvolver suas práticas de análise e ciência de dados para se concentrar nos pilares de análise e ativação, respectivamente. Depois, você pode criar uma equipe especializada para processamento de identidade do cliente e para construir a visão unificada do cliente. Você pode estabelecer uma equipe de governança de dados com administradores de dados de diferentes funções, administradores de segurança e formuladores de políticas de governança de dados para projetar e automatizar políticas.
Conclusão
Construir uma capacidade C360 robusta é fundamental para que sua organização obtenha insights sobre sua base de clientes. Os serviços de bancos de dados, análises e IA/ML da AWS podem ajudar a agilizar esse processo, fornecendo escalabilidade e eficiência. Seguindo os cinco pilares para orientar seu pensamento, você pode construir uma estratégia de dados ponta a ponta que defina a visão C360 em toda a organização, garanta que os dados sejam precisos e estabeleça governança multifuncional para os dados do cliente. Você pode categorizar e priorizar os produtos e recursos que precisa construir dentro de cada pilar, selecionar a ferramenta certa para o trabalho e desenvolver as habilidades necessárias em suas equipes.
Visite a Histórias de clientes da AWS para dados para saber como a AWS está transformando as jornadas dos clientes, desde as maiores empresas do mundo até startups em crescimento.
Sobre os autores
 Ismail Makhlouf é arquiteto de soluções especialista sênior para análise de dados na AWS. Ismail se concentra na arquitetura de soluções para organizações em todo o seu patrimônio de análise de dados ponta a ponta, incluindo streaming em lote e em tempo real, big data, armazenamento de dados e cargas de trabalho de data lake. Ele trabalha principalmente com organizações de varejo, comércio eletrônico, FinTech, HealthTech e viagens para atingir seus objetivos de negócios com plataformas de dados bem arquitetadas.
Ismail Makhlouf é arquiteto de soluções especialista sênior para análise de dados na AWS. Ismail se concentra na arquitetura de soluções para organizações em todo o seu patrimônio de análise de dados ponta a ponta, incluindo streaming em lote e em tempo real, big data, armazenamento de dados e cargas de trabalho de data lake. Ele trabalha principalmente com organizações de varejo, comércio eletrônico, FinTech, HealthTech e viagens para atingir seus objetivos de negócios com plataformas de dados bem arquitetadas.
 Sandipan Bhaumik (Sandy) é arquiteto de soluções especialista em análise sênior na AWS. Ele ajuda os clientes a modernizarem suas plataformas de dados na nuvem para realizar análises com segurança em escala, reduzir a sobrecarga operacional e otimizar o uso para obter economia e sustentabilidade.
Sandipan Bhaumik (Sandy) é arquiteto de soluções especialista em análise sênior na AWS. Ele ajuda os clientes a modernizarem suas plataformas de dados na nuvem para realizar análises com segurança em escala, reduzir a sobrecarga operacional e otimizar o uso para obter economia e sustentabilidade.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/create-an-end-to-end-data-strategy-for-customer-360-on-aws/

