Parte 1 desta série de duas partes descreveu como construir um serviço de pseudonimização que converte atributos de dados de texto simples em um pseudônimo ou vice-versa. Um serviço centralizado de pseudonimização fornece uma arquitetura única e universalmente reconhecida para geração de pseudônimos. Consequentemente, uma organização pode alcançar um processo padrão para lidar com dados confidenciais em todas as plataformas. Além disso, isso elimina qualquer complexidade e conhecimento necessários para compreender e implementar vários requisitos de conformidade das equipes de desenvolvimento e dos usuários analíticos, permitindo que eles se concentrem nos resultados de seus negócios.
Seguir uma abordagem baseada em serviços dissociados significa que, como organização, você é imparcial quanto ao uso de quaisquer tecnologias específicas para resolver seus problemas de negócios. Não importa qual tecnologia seja preferida pelas equipes individuais, elas podem chamar o serviço de pseudonimização para pseudonimizar dados confidenciais.
Nesta postagem, nos concentramos nos padrões comuns de consumo de extração, transformação e carregamento (ETL) que podem usar o serviço de pseudonimização. Discutimos como usar o serviço de pseudonimização em seus trabalhos de ETL em Amazon EMR (usando Amazon EMR no EC2) para casos de uso de streaming e lote. Além disso, você pode encontrar um Amazona atena e Cola AWS padrão de consumo baseado no GitHub repo da solução.
Visão geral da solução
O diagrama a seguir descreve a arquitetura da solução.

A conta à direita hospeda o serviço de pseudonimização, que você pode implantar usando as instruções fornecidas na Parte 1 desta série.
A conta à esquerda é aquela que você configurou como parte desta postagem, representando a plataforma ETL baseada no Amazon EMR usando o serviço de pseudonimização.
Você pode implantar o serviço de pseudonimização e a plataforma ETL na mesma conta.
O Amazon EMR permite que você crie, opere e dimensione estruturas de big data, como o Apache Spark, de maneira rápida e econômica.
Nesta solução, mostramos como consumir o serviço de pseudonimização em Amazon EMR com Apache Spark para casos de uso em lote e streaming. O aplicativo em lote lê dados de um Serviço de armazenamento simples da Amazon (Amazon S3), e o aplicativo de streaming consome registros de Fluxos de dados do Amazon Kinesis.
Código PySpark usado em trabalhos em lote e streaming
Ambos os aplicativos usam uma função utilitária comum que faz chamadas HTTP POST no API Gateway que está vinculado à pseudonimização AWS Lambda função. As chamadas da API REST são feitas por partição Spark usando o Spark RDD mapPartições função. O corpo da solicitação POST contém a lista de valores exclusivos para uma determinada coluna de entrada. A resposta da solicitação POST contém os valores pseudonimizados correspondentes. O código troca os valores confidenciais pelos pseudonimizados para um determinado conjunto de dados. O resultado é salvo no Amazon S3 e o Cola AWS Catálogo de dados, usando Apache Iceberg formato de tabela.
Iceberg é um formato de tabela aberta que oferece suporte a transações ACID, evolução de esquema e consultas de viagem no tempo. Você pode usar esses recursos para implementar o direito a ser esquecido soluções (ou eliminação de dados) usando instruções SQL ou interfaces de programação. Iceberg é compatível com Amazon EMR a partir da versão 6.5.0, AWS Glue e Athena. Os padrões de lote e streaming usam Iceberg como formato de destino. Para obter uma visão geral de como construir um data lake compatível com ACID usando Iceberg, consulte Crie um data lake em evolução, compatível com ACID e de alto desempenho usando o Apache Iceberg no Amazon EMR.
Pré-requisitos
Você deve ter os seguintes pré-requisitos:
- An Conta da AWS.
- An Gerenciamento de acesso e identidade da AWS principal (IAM) com privilégios para implantar o Formação da Nuvem AWS pilha e recursos relacionados.
- A Interface de linha de comando da AWS (AWS CLI) instalado na máquina de desenvolvimento ou implantação que você usará para executar os scripts fornecidos.
- Um bucket S3 na mesma conta e região da AWS onde a solução será implantada.
- Python3 instalado na máquina local onde os comandos são executados.
- PyYAMLName instalado usando pip.
- Um terminal bash para executar scripts bash que implantam pilhas CloudFormation.
- Um bucket S3 adicional contendo o conjunto de dados de entrada em arquivos Parquet (somente para aplicativos em lote). Copie o amostra de conjunto de dados para o balde S3.
- Uma cópia do repositório de código mais recente na máquina local usando
git cloneou a opção de download.
Abra um novo terminal bash e navegue até a pasta raiz do repositório clonado.
O código-fonte dos padrões propostos pode ser encontrado no repositório clonado. Ele usa os seguintes parâmetros:
- ARTEFACT_S3_BUCKET – O bucket S3 onde o código de infraestrutura será armazenado. O bucket deve ser criado na mesma conta e região onde a solução reside.
- AWS_REGION – A região onde a solução será implantada.
- AWS_PROFILE – O perfil nomeado que será aplicado ao Comando AWS CLI. Deve conter credenciais para um principal do IAM com privilégios para implantar a pilha CloudFormation de recursos relacionados.
- SUBNET_ID – O ID da sub-rede onde o cluster do EMR será ativado. A sub-rede é pré-existente e, para fins de demonstração, usamos o ID de sub-rede padrão da VPC padrão.
- EP_URL – O URL do terminal do serviço de pseudonimização. Recupere isso da solução implantada como Parte 1 desta série.
- API_SECRET - A Gateway de API da Amazon chave que será armazenado em Gerenciador de segredos da AWS. A chave de API é gerada a partir da implantação descrita em Parte 1 desta série.
- S3_INPUT_PATH – O URI do S3 apontando para a pasta que contém o conjunto de dados de entrada como arquivos Parquet.
- KINESIS_DATA_STREAM_NAME - O nome do stream de dados do Kinesis implantado com a pilha do CloudFormation.
- TAMANHO DO BATCH - O número de registros a serem enviados ao fluxo de dados por lote.
- THREADS_NUM - O número de threads paralelos usados na máquina local para fazer upload de dados no fluxo de dados. Mais threads correspondem a um volume maior de mensagens.
- EMR_CLUSTER_ID – O ID do cluster EMR onde o código será executado (o cluster EMR foi criado pela pilha do CloudFormation).
- STACK_NAME – O nome da pilha do CloudFormation, que é atribuído no script de implantação.
Etapas de implantação em lote
Conforme descrito nos pré-requisitos, antes de implantar a solução, carregue os arquivos Parquet do conjunto de dados de teste para Amazon S3. Em seguida, forneça o caminho S3 da pasta que contém os arquivos como parâmetro <S3_INPUT_PATH>.
Criamos os recursos da solução via AWS CloudFormation. Você pode implantar a solução executando o implantar_1.sh script, que está dentro do deployment_scripts pasta.
Depois que os pré-requisitos de implementação forem atendidos, insira o seguinte comando para implementar a solução:
sh ./deployment_scripts/deploy_1.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>
-i <S3_INPUT_PATH>A saída deve ser semelhante à captura de tela a seguir.

Os parâmetros necessários para o comando de limpeza são impressos no final da execução do deploy_1.sh roteiro. Certifique-se de anotar esses valores.
Teste a solução em lote
No modelo CloudFormation implantado usando o deploy_1.sh script, a etapa EMR contendo o Aplicativo em lote Spark é adicionado no final da configuração do cluster EMR.
Para verificar os resultados, verifique o bucket S3 identificado nas saídas da pilha do CloudFormation com a variável SparkOutputLocation.

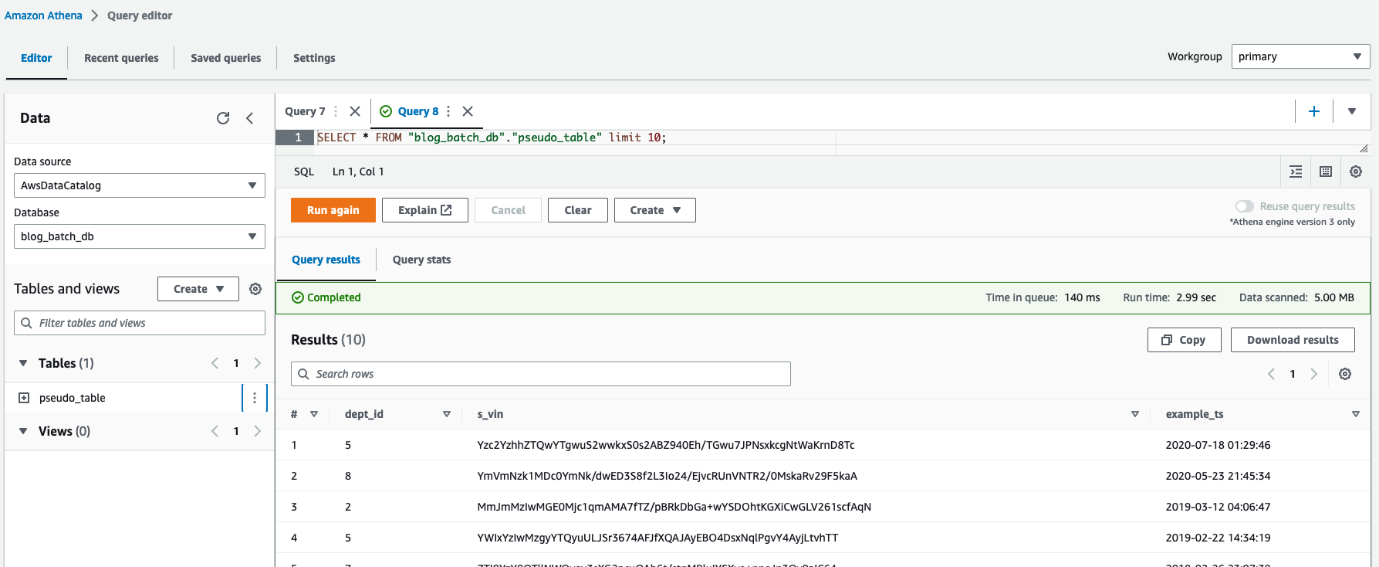
Você também pode usar o Athena para consultar a tabela pseudo_table no banco de dados blog_batch_db.
Limpar recursos em lote
Para destruir os recursos criados como parte deste exercício,
em um terminal bash, navegue até a pasta raiz do repositório clonado. Digite o comando de limpeza mostrado como saída da execução anterior implantar_1.sh script:
sh ./deployment_scripts/cleanup_1.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>A saída deve ser semelhante à captura de tela a seguir.

Etapas de implantação de streaming
Criamos os recursos da solução via AWS CloudFormation. Você pode implantar a solução executando o implantar_2.sh script, que está dentro do deployment_scripts pasta. O modelo de pilha do CloudFormation para esse padrão está disponível no GitHub repo.
Depois que os pré-requisitos de implementação forem atendidos, insira o seguinte comando para implementar a solução:
sh deployment_scripts/deploy_2.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>A saída deve ser semelhante à captura de tela a seguir.
Os parâmetros necessários para o comando de limpeza são impressos no final da saída do implantar_2.sh roteiro. Certifique-se de salvar esses valores para usar mais tarde.
Teste a solução de streaming
No modelo CloudFormation implantado usando o deploy_2.sh script, a etapa EMR contendo o Aplicativo de streaming Spark é adicionado no final da configuração do cluster EMR. Para testar o pipeline de ponta a ponta, você precisa enviar registros por push para o fluxo de dados implantado do Kinesis. Com os comandos a seguir em um terminal bash, você pode ativar um produtor do Kinesis que colocará registros continuamente no stream, até que o processo seja interrompido manualmente. Você pode controlar o volume de mensagens do produtor modificando o arquivo BATCH_SIZE e os votos de THREADS_NUM variáveis.


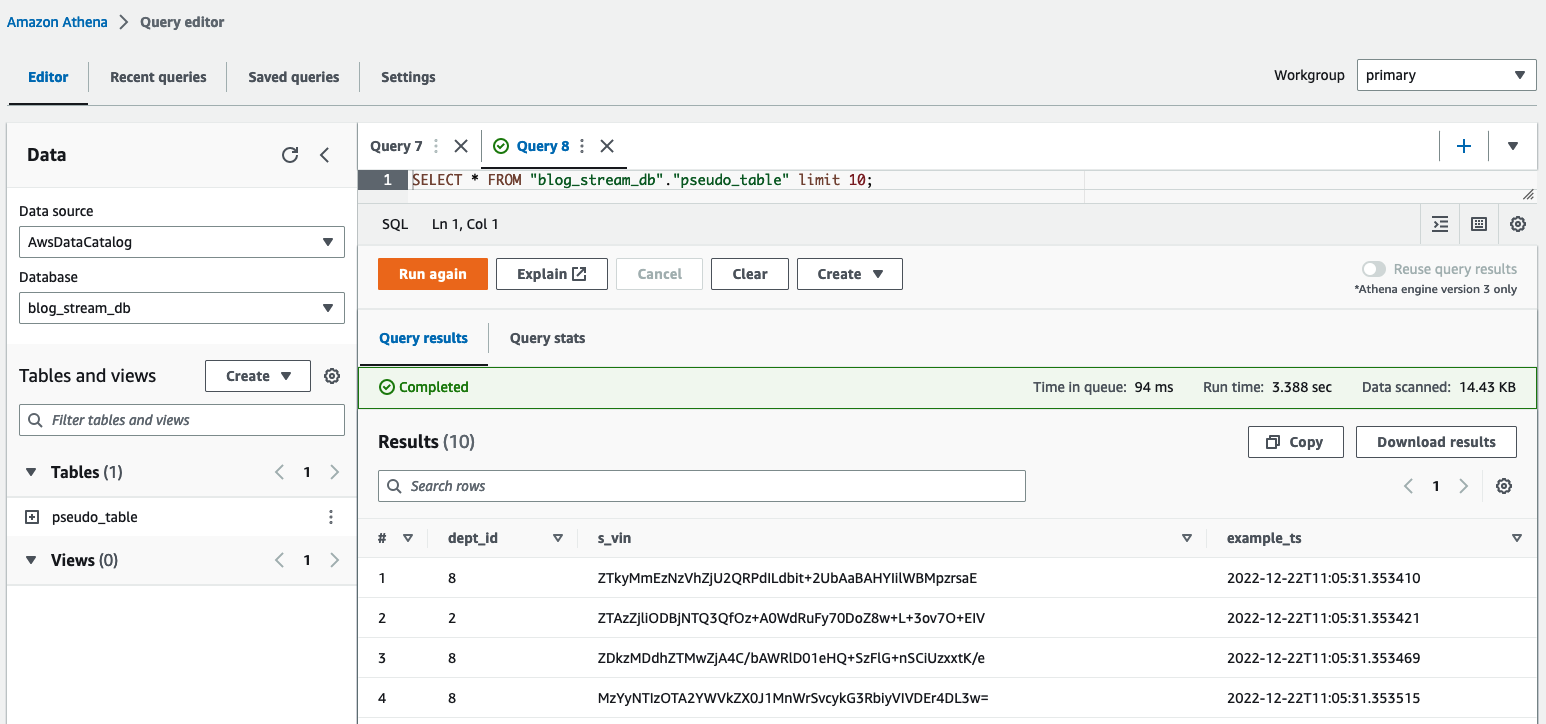
No editor de consultas do Athena, verifique os resultados consultando o table pseudo_table no banco de dados blog_stream_db.
Limpe os recursos de streaming
Para destruir os recursos criados como parte deste exercício, execute as seguintes etapas:
- Pare o produtor do Python Kinesis que foi iniciado em um terminal bash na seção anterior.
- Digite o seguinte comando:
sh ./deployment_scripts/cleanup_2.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>A saída deve ser semelhante à captura de tela a seguir.

Detalhes de desempenho
Os casos de uso podem diferir nos requisitos em relação ao tamanho dos dados, capacidade de computação e custo. Fornecemos alguns benchmarking e fatores que podem influenciar o desempenho; no entanto, recomendamos fortemente que você valide a solução em ambientes inferiores para ver se ela atende aos seus requisitos específicos.
Você pode influenciar o desempenho da solução proposta (que visa pseudonimizar um conjunto de dados usando Amazon EMR) pelo número máximo de chamadas paralelas para o serviço de pseudonimização e pelo tamanho da carga útil de cada chamada. Em termos de chamadas paralelas, os factores a considerar são a Limite de chamadas GetSecretValue do Secrets Manager (10.000 por segundo, limite rígido) e o paralelismo de simultaneidade padrão do Lambda (1,000 por padrão; pode ser aumentado por solicitação de cota). Você pode controlar o paralelismo máximo ajustando o número de executores, o número de partições que compõem o conjunto de dados e a configuração do cluster (número e tipo de nós). Em termos do tamanho da carga útil para cada chamada, os fatores a serem considerados são o Tamanho máximo da carga útil do API Gateway (6 MB) e o tempo de execução máximo da função Lambda (15 minutos). Você pode controlar o tamanho da carga útil e o tempo de execução da função Lambda ajustando o valor do tamanho do lote, que é um parâmetro do script PySpark que determina o número de itens a serem pseudonimizados por cada chamada de API. Para capturar a influência de todos esses fatores e avaliar o desempenho dos padrões de consumo usando o Amazon EMR, projetamos e monitoramos os seguintes cenários.
Desempenho do padrão de consumo em lote
Para avaliar o desempenho do padrão de consumo em lote, executamos o aplicativo de pseudonimização com três conjuntos de dados de entrada compostos por 1, 10 e 100 arquivos Parquet de 97.7 MB cada. Geramos os arquivos de entrada usando o dataset_generator.py script.
Os nós de capacidade do cluster eram 1 primário (m5.4xlarge) e 15 núcleos (m5d.8xlarge). Essa configuração de cluster permaneceu a mesma para todos os três cenários e permitiu que o aplicativo Spark usasse até 100 executores. O batch_size, que também era o mesmo para os três cenários, foi definido como 900 VINs por chamada de API e o tamanho máximo do VIN foi de 5 bytes.
A tabela a seguir captura as informações dos três cenários.
| ID de execução | Repartição | Tamanho do conjunto de dados | Número de Executores | Núcleos por Executor | Memória do Executor | Runtime |
| A | 800 | 9.53 GB | 100 | 4 | 4 GiB | 11 minutos, 10 segundos |
| B | 80 | 0.95 GB | 10 | 4 | 4 GiB | 8 minutos, 36 segundos |
| C | 8 | 0.09 GB | 1 | 4 | 4 GiB | 7 minutos, 56 segundos |
Como podemos ver, paralelizar adequadamente as chamadas ao nosso serviço de pseudonimização nos permite controlar o tempo de execução geral.
Nos exemplos a seguir, analisamos três métricas Lambda importantes para o serviço de pseudonimização: Invocations, ConcurrentExecutions e Duration.
O gráfico a seguir retrata o Invocations métrica, com a estatística SUM em laranja e RUNNING SUM Em azul.

Calculando a diferença entre o ponto inicial e final das invocações cumulativas, podemos extrair quantas invocações foram feitas durante cada execução.
| ID de execução | Tamanho do conjunto de dados | Total de invocações |
| A | 9.53 GB | 1.467.000 - 0 = 1.467.000 |
| B | 0.95 GB | 1.467.000 - 1.616.500 = 149.500 |
| C | 0.09 GB | 1.616.500 - 1.631.000 = 14.500 |
Como esperado, o número de invocações aumenta proporcionalmente em 10 com o tamanho do conjunto de dados.
O gráfico a seguir mostra o total ConcurrentExecutions métrica, com a estatística MAX Em azul.
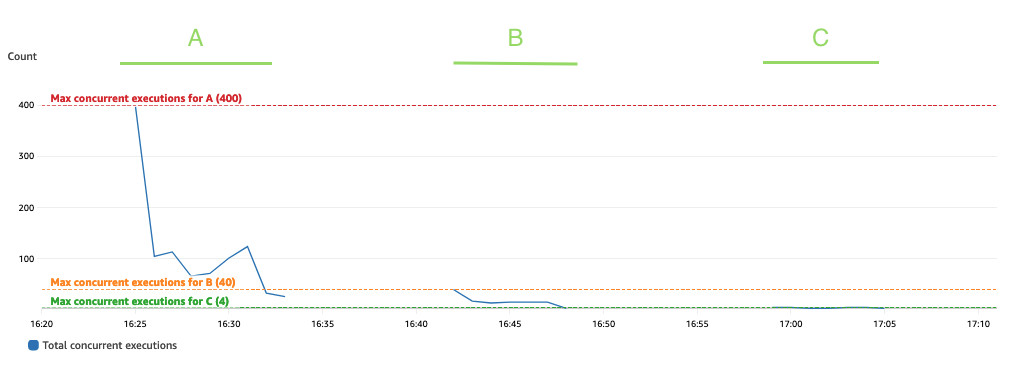
O aplicativo foi projetado de forma que o número máximo de execuções simultâneas de funções do Lambda seja determinado pela quantidade de tarefas do Spark (partições do conjunto de dados do Spark), que podem ser processadas em paralelo. Este número pode ser calculado como MIN (executores x executor_cores, partições do conjunto de dados Spark).
No teste, a execução A processou 800 partições, usando 100 executores com quatro núcleos cada. Isso faz com que 400 tarefas sejam processadas em paralelo, de modo que as execuções simultâneas da função Lambda não possam estar acima de 400. A mesma lógica foi aplicada para as execuções B e C. Podemos ver isso refletido no gráfico anterior, onde a quantidade de execuções simultâneas nunca ultrapassa o 400, 40 e 4 valores.
Para evitar limitação, certifique-se de que a quantidade de tarefas do Spark que podem ser processadas em paralelo não esteja acima do limite de simultaneidade da função Lambda. Se for esse o caso, você deve aumentar o limite de simultaneidade da função Lambda (se quiser manter o desempenho) ou reduzir a quantidade de partições ou o número de executores disponíveis (impactando o desempenho do aplicativo).
O gráfico a seguir descreve o Lambda Duration métrica, com a estatística AVG em laranja e MAX em verde.
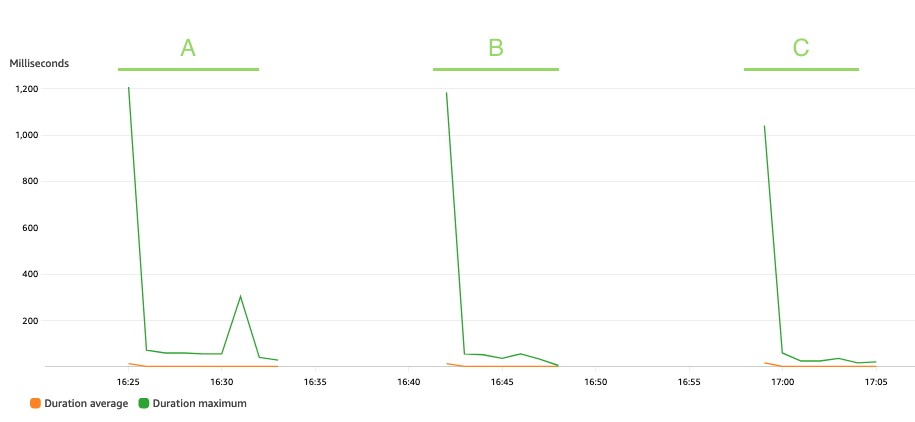
Como esperado, o tamanho do conjunto de dados não afeta a duração da execução da função de pseudonimização, que, além de algumas invocações iniciais que enfrentam inicializações a frio, permanece constante a uma média de 3 milissegundos ao longo dos três cenários. Isso porque o número máximo de registros incluídos em cada chamada de pseudonimização é constante (batch_size valor).
O Lambda é cobrado com base no número de invocações e no tempo que leva para o seu código ser executado (duração). Você pode usar a duração média e as métricas de invocações para estimar o custo do serviço de pseudonimização.
Desempenho do padrão de consumo de streaming
Para avaliar o desempenho do padrão de consumo de streaming, executamos o produtor.py script, que define um produtor de dados do Kinesis que envia registros em lotes para o fluxo de dados do Kinesis.
O aplicativo de streaming ficou em execução por 15 minutos e foi configurado com um batch_interval de 1 minuto, que é o intervalo de tempo em que os dados de streaming serão divididos em lotes. A tabela a seguir resume os fatores relevantes.
| Repartição | Nós de capacidade de cluster | Número de Executores | Memória do Executor | Janela de lote | Tamanho do batch | Tamanho do VIN |
| 17 |
1 Primário (m5.xlarge), 3 núcleos (m5.2xgrande) |
6 | 9 GiB | 60 segundos | 900 VINs/chamada API. | 5 Bytes/VIN |
Os gráficos a seguir representam as métricas do Kinesis Data Streams PutRecords (em azul) e GetRecords (em laranja) agregado ao período de 1 minuto e usando a estatística SUM. O primeiro gráfico mostra a métrica em bytes, com pico de 6.8 MB por minuto. O segundo gráfico mostra a métrica na contagem de registros com pico de 85,000 registros por minuto.
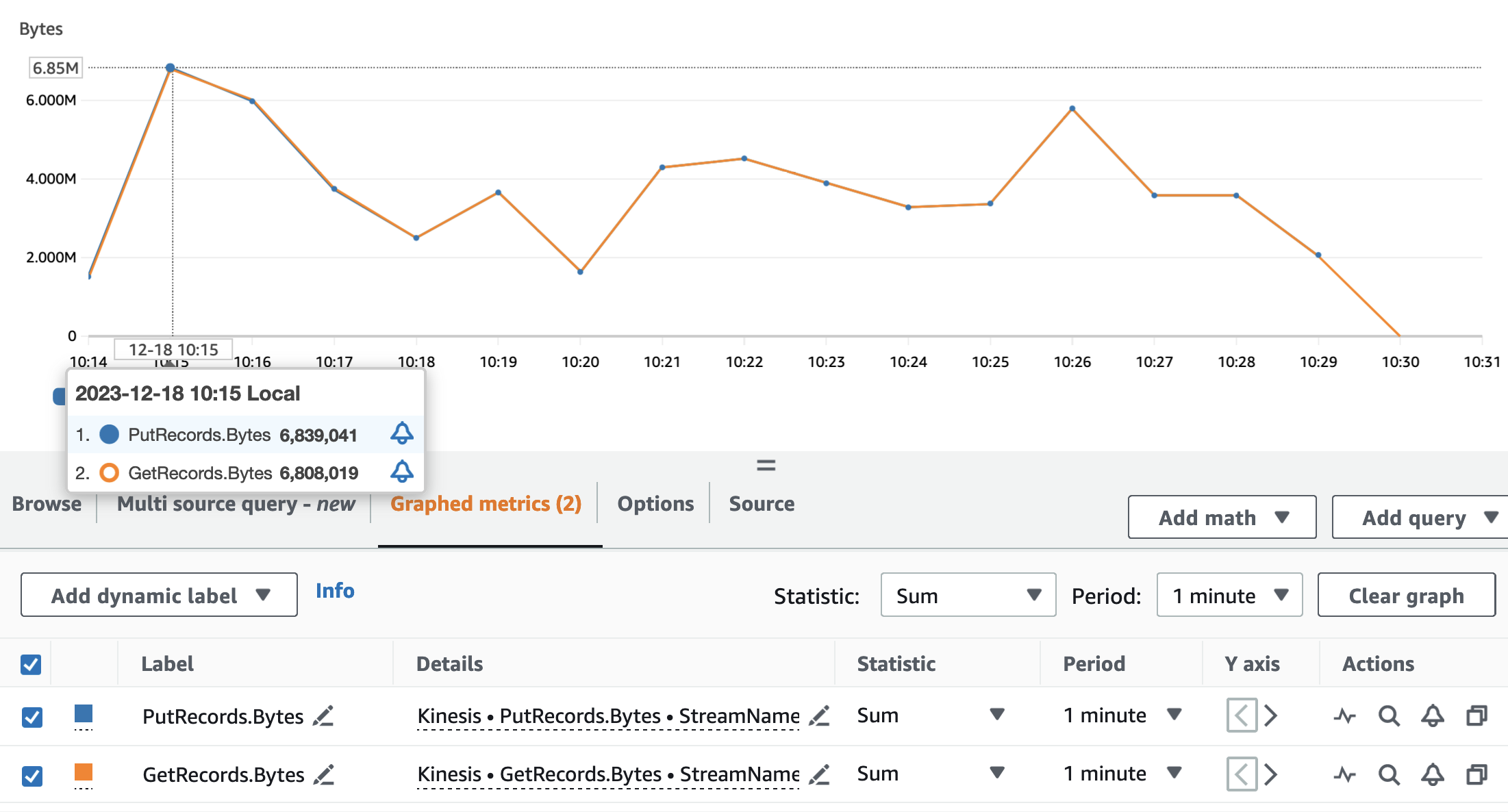

Podemos ver que as métricas GetRecords e PutRecords têm valores sobrepostos para quase toda a execução do aplicativo. Isso significa que o aplicativo de streaming conseguiu acompanhar a carga do stream.
A seguir, analisamos as métricas Lambda relevantes para o serviço de pseudonimização: Invocations, ConcurrentExecutions e Duration.
O gráfico a seguir retrata o Invocations métrica, com a estatística SUM (em laranja) e RUNNING SUM Em azul.
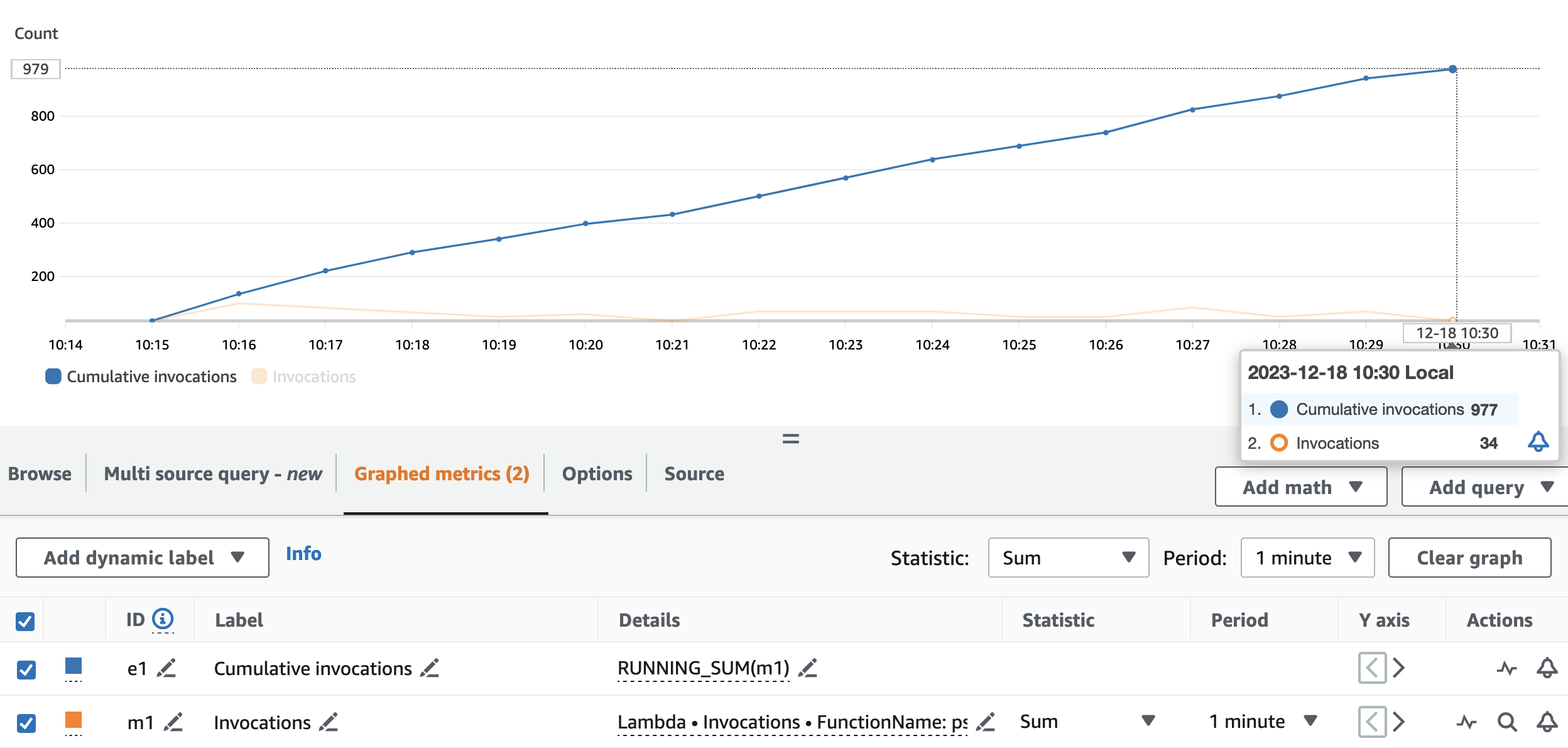
Calculando a diferença entre o ponto inicial e final das invocações cumulativas, podemos extrair quantas invocações foram feitas durante a execução. Especificamente, em 15 minutos, o aplicativo de streaming invocou a API de pseudonimização 977 vezes, o que equivale a cerca de 65 chamadas por minuto.
O gráfico a seguir mostra o total ConcurrentExecutions métrica, com a estatística MAX Em azul.
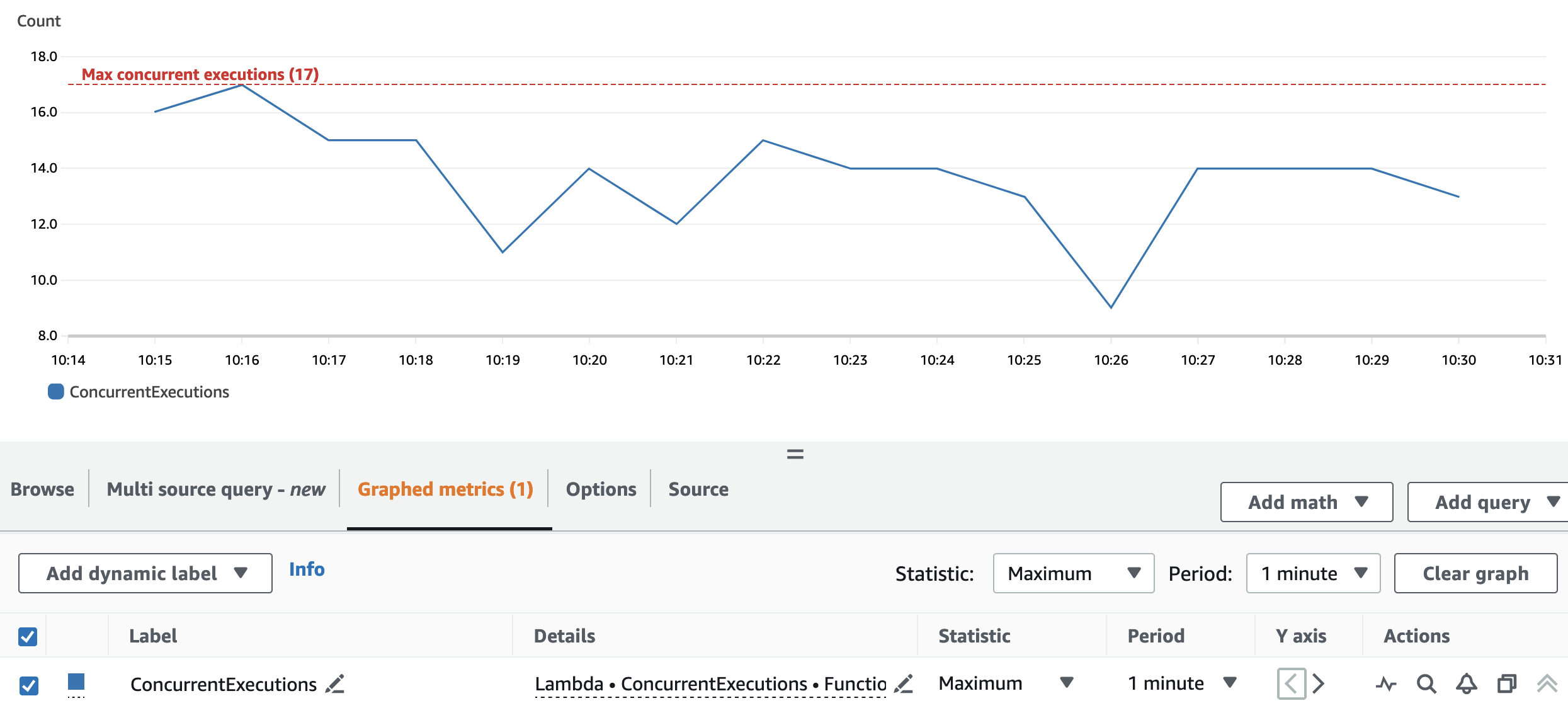
A repartição e a configuração do cluster permitem que o aplicativo processe todas as partições Spark RDD em paralelo. Como resultado, as execuções simultâneas da função Lambda são sempre iguais ou inferiores ao número de repartição, que é 17.
Para evitar limitação, certifique-se de que a quantidade de tarefas do Spark que podem ser processadas em paralelo não esteja acima do limite de simultaneidade da função Lambda. Para este aspecto, são válidas as mesmas sugestões do caso de uso em lote.
O gráfico a seguir descreve o Lambda Duration métrica, com a estatística AVG em azul e MAX em laranja.
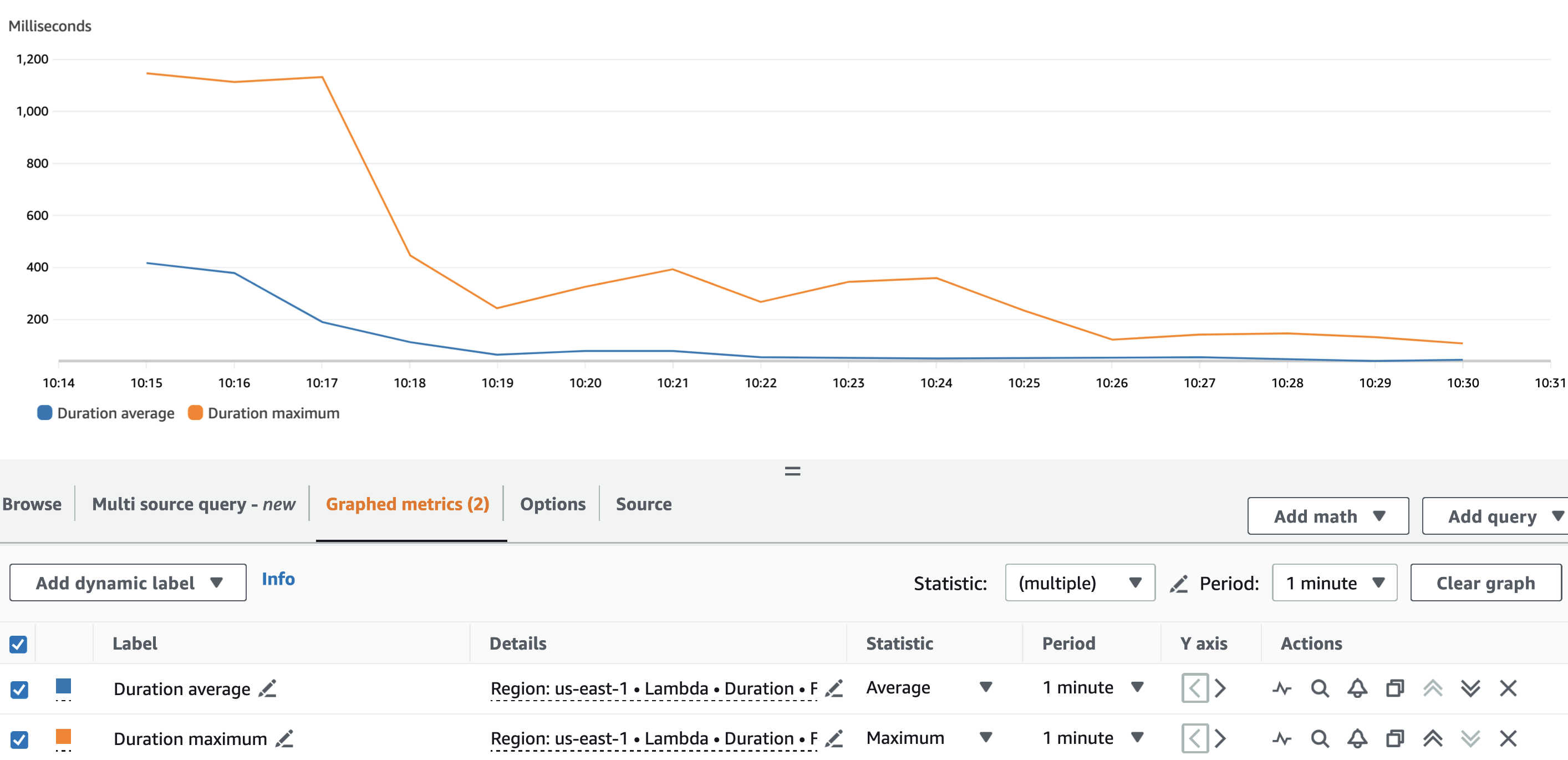
Como esperado, além da inicialização a frio da função Lambda, a duração média da função de pseudonimização foi mais ou menos constante durante toda a execução. Isso porque o batch_size O valor, que define o número de VINs a serem pseudonimizados por chamada, foi definido e permaneceu constante em 900.
A taxa de ingestão do fluxo de dados do Kinesis e a taxa de consumo do nosso aplicativo de streaming são fatores que influenciam o número de chamadas de API feitas no serviço de pseudonimização e, portanto, o custo relacionado.
O gráfico a seguir descreve o Lambda Invocations métrica, com a estatística SUM em laranja e o Kinesis Data Streams GetRecords.Records métrica, com a estatística SUM Em azul. Podemos ver que há correlação entre a quantidade de registros recuperados do stream por minuto e a quantidade de invocações de funções Lambda, impactando assim o custo da execução do streaming.

Além do batch_interval, podemos controlar a taxa de consumo do aplicativo de streaming usando Propriedades de streaming do Spark como spark.streaming.receiver.maxRate e spark.streaming.blockInterval. Para mais detalhes, consulte Integração Spark Streaming + Kinesis e Guia de programação de streaming do Spark.
Conclusão
Pode ser difícil navegar pelas regras e regulamentos das leis de privacidade de dados. A pseudonimização de atributos PII é um dos muitos pontos a serem considerados ao lidar com dados confidenciais.
Nesta série de duas partes, exploramos como você pode criar e consumir um serviço de pseudonimização usando vários serviços da AWS com recursos para ajudá-lo a construir uma plataforma de dados robusta. Em Parte 1, construímos a base mostrando como construir um serviço de pseudonimização. Nesta postagem, apresentamos os vários padrões para consumir o serviço de pseudonimização de maneira econômica e com bom desempenho. Confira a GitHub repositório para padrões de consumo adicionais.
Sobre os autores
 Edvin Hallvaxhiu é arquiteto de segurança global sênior da AWS Professional Services e é apaixonado por segurança cibernética e automação. Ele ajuda os clientes a criar soluções seguras e compatíveis na nuvem. Fora do trabalho, gosta de viajar e praticar esportes.
Edvin Hallvaxhiu é arquiteto de segurança global sênior da AWS Professional Services e é apaixonado por segurança cibernética e automação. Ele ajuda os clientes a criar soluções seguras e compatíveis na nuvem. Fora do trabalho, gosta de viajar e praticar esportes.
 Rahul Shaurya é arquiteto principal de Big Data da AWS Professional Services. Ele ajuda e trabalha em estreita colaboração com clientes na criação de plataformas de dados e aplicativos analíticos na AWS. Fora do trabalho, Rahul adora fazer longas caminhadas com seu cachorro Barney.
Rahul Shaurya é arquiteto principal de Big Data da AWS Professional Services. Ele ajuda e trabalha em estreita colaboração com clientes na criação de plataformas de dados e aplicativos analíticos na AWS. Fora do trabalho, Rahul adora fazer longas caminhadas com seu cachorro Barney.
 Andrea Montanari é arquiteto sênior de Big Data na AWS Professional Services. Ele apoia ativamente clientes e parceiros na construção de soluções analíticas em escala na AWS.
Andrea Montanari é arquiteto sênior de Big Data na AWS Professional Services. Ele apoia ativamente clientes e parceiros na construção de soluções analíticas em escala na AWS.
 Maria Guerra é um arquiteto de big data com serviços profissionais da AWS. Maria tem experiência em análise de dados e engenharia mecânica. Ela ajuda os clientes a arquitetar e desenvolver cargas de trabalho relacionadas a dados na nuvem.
Maria Guerra é um arquiteto de big data com serviços profissionais da AWS. Maria tem experiência em análise de dados e engenharia mecânica. Ela ajuda os clientes a arquitetar e desenvolver cargas de trabalho relacionadas a dados na nuvem.
 Pushpraj Singh é arquiteto de dados sênior da AWS Professional Services. Ele é apaixonado por engenharia de dados e DevOps. Ele ajuda os clientes a criar aplicativos orientados a dados em escala.
Pushpraj Singh é arquiteto de dados sênior da AWS Professional Services. Ele é apaixonado por engenharia de dados e DevOps. Ele ajuda os clientes a criar aplicativos orientados a dados em escala.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/build-a-pseudonymization-service-on-aws-to-protect-sensitive-data-part-2/

