Desbloquear respostas precisas e perspicazes a partir de grandes quantidades de texto é um recurso interessante possibilitado por grandes modelos de linguagem (LLMs). Ao construir aplicações LLM, muitas vezes é necessário conectar e consultar fontes de dados externas para fornecer contexto relevante ao modelo. Uma abordagem popular é usar a Geração Aumentada de Recuperação (RAG) para criar sistemas de perguntas e respostas que compreendem informações complexas e fornecem respostas naturais às consultas. O RAG permite que os modelos acessem vastas bases de conhecimento e forneçam diálogos semelhantes aos humanos para aplicações como chatbots e assistentes de pesquisa empresarial.
Nesta postagem, exploramos como aproveitar o poder do LhamaIndex, Lhama 2-70B-Chat e LangChain para criar aplicativos poderosos de perguntas e respostas. Com essas tecnologias de última geração, você pode incorporar corpora de texto, indexar conhecimento crítico e gerar texto que responda às perguntas dos usuários com precisão e clareza.
Lhama 2-70B-Chat
Llama 2-70B-Chat é um LLM poderoso que compete com os principais modelos. Ele é pré-treinado em dois trilhões de tokens de texto e planejado pela Meta para ser usado para assistência por chat aos usuários. Os dados de pré-treinamento são provenientes de dados disponíveis publicamente e são concluídos em setembro de 2022, e os dados de ajuste fino são concluídos em julho de 2023. Para obter mais detalhes sobre o processo de treinamento do modelo, considerações de segurança, aprendizados e usos pretendidos, consulte o artigo Lhama 2: Base aberta e modelos de bate-papo ajustados. Os modelos Llama 2 estão disponíveis em JumpStart do Amazon SageMaker para uma implantação rápida e direta.
LhamaIndex
LhamaIndex é uma estrutura de dados que permite a construção de aplicativos LLM. Ele fornece ferramentas que oferecem conectores de dados para assimilar seus dados existentes com diversas fontes e formatos (PDFs, documentos, APIs, SQL e muito mais). Quer você tenha dados armazenados em bancos de dados ou em PDFs, o LlamaIndex facilita o uso desses dados para LLMs. Como demonstramos nesta postagem, as APIs LlamaIndex facilitam o acesso aos dados e permitem que você crie aplicativos e fluxos de trabalho LLM personalizados e poderosos.
Se você está experimentando e construindo LLMs, provavelmente está familiarizado com LangChain, que oferece uma estrutura robusta, simplificando o desenvolvimento e a implantação de aplicativos baseados em LLM. Semelhante ao LangChain, o LlamaIndex oferece uma série de ferramentas, incluindo conectores de dados, índices de dados, mecanismos e agentes de dados, bem como integrações de aplicativos, como ferramentas e observabilidade, rastreamento e avaliação. LlamaIndex se concentra em preencher a lacuna entre os dados e LLMs poderosos, agilizando tarefas de dados com recursos fáceis de usar. O LlamaIndex foi projetado e otimizado especificamente para a construção de aplicativos de busca e recuperação, como o RAG, porque fornece uma interface simples para consultar LLMs e recuperar documentos relevantes.
Visão geral da solução
Neste post, demonstramos como criar uma aplicação baseada em RAG usando LlamaIndex e um LLM. O diagrama a seguir mostra a arquitetura passo a passo desta solução descrita nas seções a seguir.
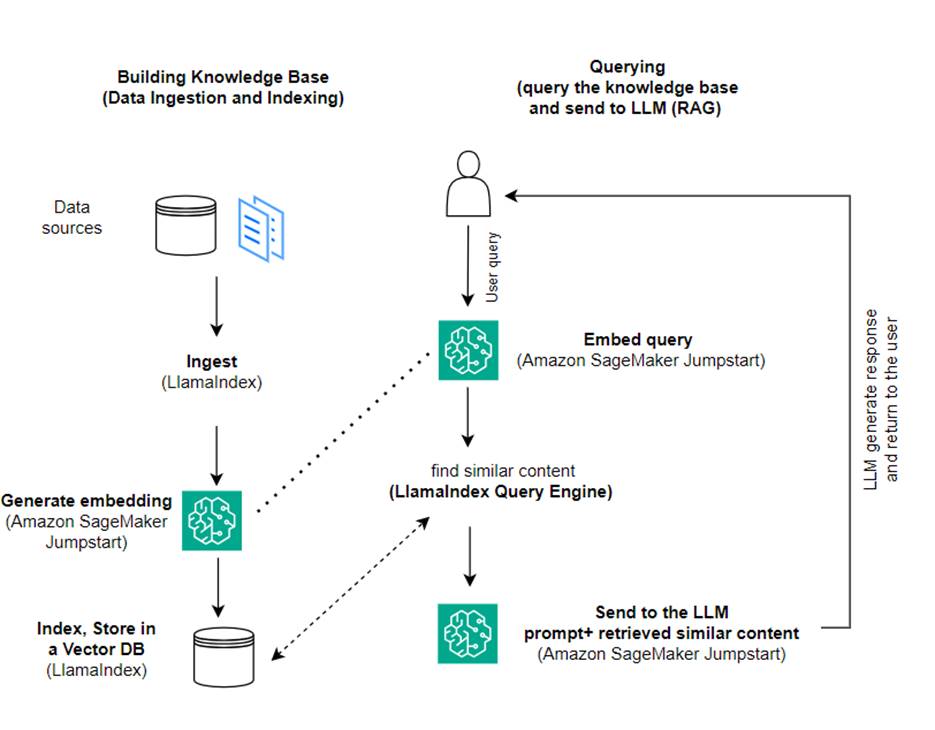
O RAG combina a recuperação de informações com a geração de linguagem natural para produzir respostas mais perspicazes. Quando solicitado, o RAG primeiro pesquisa corpora de texto para recuperar os exemplos mais relevantes para a entrada. Durante a geração de respostas, o modelo considera esses exemplos para aumentar suas capacidades. Ao incorporar passagens relevantes recuperadas, as respostas RAG tendem a ser mais factuais, coerentes e consistentes com o contexto em comparação com modelos generativos básicos. Essa estrutura de recuperação e geração aproveita os pontos fortes da recuperação e da geração, ajudando a resolver problemas como repetição e falta de contexto que podem surgir de modelos conversacionais autoregressivos puros. RAG apresenta uma abordagem eficaz para construir agentes de conversação e assistentes de IA com respostas contextualizadas e de alta qualidade.
A construção da solução consiste nas seguintes etapas:
- Estabelecer Estúdio Amazon SageMaker como o ambiente de desenvolvimento e instale as dependências necessárias.
- Implante um modelo de incorporação do hub Amazon SageMaker JumpStart.
- Baixe comunicados de imprensa para usar como nossa base de conhecimento externa.
- Crie um índice a partir dos comunicados à imprensa para poder consultar e adicionar contexto adicional ao prompt.
- Consulte a base de conhecimento.
- Crie um aplicativo de perguntas e respostas usando agentes LlamaIndex e LangChain.
Todo o código deste post está disponível no GitHub repo.
Pré-requisitos
Para este exemplo, você precisa de uma conta AWS com um domínio SageMaker e Gerenciamento de acesso e identidade da AWS (IAM). Para obter instruções de configuração da conta, consulte Criar uma conta da AWS. Se você ainda não possui um domínio SageMaker, consulte Domínio Amazon SageMaker visão geral para criar um. Nesta postagem, usamos o AmazonSageMakerFullAccess papel. Não é recomendado usar essa credencial em um ambiente de produção. Em vez disso, você deve criar e usar uma função com permissões de privilégio mínimo. Você também pode explorar como usar Gerenciador de funções do Amazon SageMaker para criar e gerenciar funções IAM baseadas em personas para necessidades comuns de aprendizado de máquina diretamente por meio do console SageMaker.
Além disso, você precisa de acesso a um mínimo dos seguintes tamanhos de instância:
- ml.g5.2xgrande para uso do endpoint ao implantar o Abraçando o rosto GPT-J modelo de incorporação de texto
- ml.g5.48xgrande para uso do endpoint ao implantar o endpoint do modelo Llama 2-Chat
Para aumentar sua cota, consulte Solicitando um aumento de cota.
Implante um modelo de incorporação GPT-J usando SageMaker JumpStart
Esta seção oferece duas opções ao implantar modelos SageMaker JumpStart. Você pode usar uma implantação baseada em código usando o código fornecido ou usar a interface do usuário (IU) do SageMaker JumpStart.
Implante com o SageMaker Python SDK
Você pode usar o SageMaker Python SDK para implantar os LLMs, conforme mostrado no código disponível no repositório. Conclua as seguintes etapas:
- Defina o tamanho da instância que será usada para implantação do modelo de embeddings usando
instance_type = "ml.g5.2xlarge" - Localize o ID do modelo a ser usado para incorporações. No SageMaker JumpStart, ele é identificado como
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - Recupere o contêiner do modelo pré-treinado e implante-o para inferência.
O SageMaker retornará o nome do endpoint do modelo e a seguinte mensagem quando o modelo de embeddings for implantado com sucesso:
Implante com SageMaker JumpStart no SageMaker Studio
Para implantar o modelo usando o SageMaker JumpStart no Studio, conclua as seguintes etapas:
- No console do SageMaker Studio, escolha JumpStart no painel de navegação.

- Procure e escolha o modelo GPT-J 6B Embedding FP16.
- Escolha Implantar e personalize a configuração de implantação.

- Para este exemplo, precisamos de uma instância ml.g5.2xlarge, que é a instância padrão sugerida pelo SageMaker JumpStart.
- Escolha Deploy novamente para criar o endpoint.
O endpoint levará aproximadamente 5 a 10 minutos para entrar em serviço.

Depois de implantar o modelo de embeddings, para usar a integração LangChain com APIs SageMaker, você precisa criar uma função para manipular entradas (texto bruto) e transformá-las em embeddings usando o modelo. Você faz isso criando uma classe chamada ContentHandler, que pega um JSON de dados de entrada e retorna um JSON de incorporações de texto: class ContentHandler(EmbeddingsContentHandler).
Passe o nome do endpoint do modelo para o ContentHandler função para converter o texto e retornar embeddings:
Você pode localizar o nome do endpoint na saída do SDK ou nos detalhes de implantação na UI do SageMaker JumpStart.
Você pode testar se o ContentHandler função e endpoint estão funcionando conforme esperado, inserindo algum texto bruto e executando o embeddings.embed_query(text) função. Você pode usar o exemplo fornecido text = "Hi! It's time for the beach" ou tente seu próprio texto.
Implante e teste o Llama 2-Chat usando o SageMaker JumpStart
Agora você pode implantar o modelo capaz de ter conversas interativas com seus usuários. Neste caso, escolhemos um dos modelos Llama 2-chat, que é identificado via
O modelo precisa ser implantado em um endpoint em tempo real usando predictor = my_model.deploy(). O SageMaker retornará o nome do endpoint do modelo, que você pode usar para o endpoint_name variável para referência posterior.
Você define um print_dialogue função para enviar entrada para o modelo de chat e receber sua resposta de saída. A carga inclui hiperparâmetros para o modelo, incluindo o seguinte:
- max_new_tokens – Refere-se ao número máximo de tokens que o modelo pode gerar em suas saídas.
- topo_p – Refere-se à probabilidade cumulativa dos tokens que podem ser retidos pelo modelo ao gerar seus resultados
- temperatura – Refere-se à aleatoriedade dos resultados gerados pelo modelo. Uma temperatura maior que 0 ou igual a 1 aumenta o nível de aleatoriedade, enquanto uma temperatura 0 gerará os tokens mais prováveis.
Você deve selecionar seus hiperparâmetros com base no seu caso de uso e testá-los adequadamente. Modelos como a família Llama exigem que você inclua um parâmetro adicional indicando que leu e aceitou o Contrato de Licença do Usuário Final (EULA):
Para testar o modelo, substitua a seção de conteúdo da carga de entrada: "content": "what is the recipe of mayonnaise?". Você pode usar seus próprios valores de texto e atualizar os hiperparâmetros para entendê-los melhor.
Semelhante à implantação do modelo de embeddings, você pode implantar o Llama-70B-Chat usando a UI do SageMaker JumpStart:
- No console do SageMaker Studio, escolha Acelerador no painel de navegação
- Pesquise e escolha o
Llama-2-70b-Chat model - Aceite o EULA e escolha Implantação, usando a instância padrão novamente
Semelhante ao modelo de incorporação, você pode usar a integração LangChain criando um modelo de manipulador de conteúdo para as entradas e saídas do seu modelo de chat. Neste caso, você define as entradas como aquelas provenientes de um usuário e indica que elas são regidas pelo system prompt. O system prompt informa o modelo sobre sua função em auxiliar o usuário em um caso de uso específico.
Esse manipulador de conteúdo é então passado ao invocar o modelo, além dos hiperparâmetros e atributos customizados mencionados acima (aceitação do EULA). Você analisa todos esses atributos usando o seguinte código:
Quando o endpoint estiver disponível, você poderá testar se ele está funcionando conforme o esperado. Você pode atualizar llm("what is amazon sagemaker?") com seu próprio texto. Você também precisa definir o específico ContentHandler para invocar o LLM usando LangChain, conforme mostrado no código e o seguinte trecho de código:
Use LlamaIndex para construir o RAG
Para continuar, instale o LlamaIndex para criar o aplicativo RAG. Você pode instalar o LlamaIndex usando o pip: pip install llama_index
Primeiro você precisa carregar seus dados (base de conhecimento) no LlamaIndex para indexação. Isso envolve algumas etapas:
- Escolha um carregador de dados:
LlamaIndex fornece vários conectores de dados disponíveis em LhamaHub para tipos de dados comuns como JSON, CSV e arquivos de texto, bem como outras fontes de dados, permitindo a ingestão de uma variedade de conjuntos de dados. Nesta postagem, usamos SimpleDirectoryReader para ingerir alguns arquivos PDF conforme mostrado no código. Nossa amostra de dados são dois comunicados de imprensa da Amazon em versão PDF no comunicados de imprensa pasta em nosso repositório de código. Depois de carregar os PDFs, você verá que eles foram convertidos em uma lista de 11 elementos.
Em vez de carregar os documentos diretamente, você também pode ocultar os Document objeto em Node objetos antes de enviá-los para o índice. A escolha entre enviar todo o Document objeto ao índice ou convertendo o Documento em Node objetos antes da indexação depende do seu caso de uso específico e da estrutura dos seus dados. A abordagem de nós geralmente é uma boa opção para documentos longos, nos quais você deseja quebrar e recuperar partes específicas de um documento, em vez de todo o documento. Para obter mais informações, consulte Documentos / Nós.
- Instancie o carregador e carregue os documentos:
Esta etapa inicializa a classe do carregador e qualquer configuração necessária, como ignorar arquivos ocultos. Para mais detalhes, consulte Leitor de Diretório Simples.
- Chame o carregador
load_datamétodo para analisar seus arquivos e dados de origem e convertê-los em objetos LlamaIndex Document, prontos para indexação e consulta. Você pode usar o código a seguir para concluir a ingestão de dados e a preparação para pesquisa de texto completo usando os recursos de indexação e recuperação do LlamaIndex:
- Construa o índice:
A principal característica do LlamaIndex é sua capacidade de construir índices organizados sobre dados, que são representados como documentos ou nós. A indexação facilita a consulta eficiente dos dados. Criamos nosso índice com o armazenamento de vetores na memória padrão e com nossa configuração definida. O LhamaIndex Configurações é um objeto de configuração que fornece recursos e configurações comumente usados para operações de indexação e consulta em um aplicativo LlamaIndex. Ele atua como um objeto singleton, de modo que permite definir configurações globais, ao mesmo tempo que permite substituir componentes específicos localmente, passando-os diretamente para as interfaces (como LLMs, modelos de incorporação) que os utilizam. Quando um componente específico não é fornecido explicitamente, a estrutura LlamaIndex volta às configurações definidas no arquivo Settings objeto como um padrão global. Para usar nossos modelos de incorporação e LLM com LangChain e configurar o Settings precisamos instalar llama_index.embeddings.langchain e llama_index.llms.langchain. Podemos configurar o Settings objeto como no código a seguir:
Por padrão, o VectorStoreIndex usa uma memória SimpleVectorStore que é inicializado como parte do contexto de armazenamento padrão. Em casos de uso da vida real, muitas vezes você precisa se conectar a armazenamentos de vetores externos, como Serviço Amazon OpenSearch. Para mais detalhes, consulte Mecanismo vetorial para Amazon OpenSearch Serverless.
Agora você pode fazer perguntas e respostas sobre seus documentos usando o query_engine do LlamaIndex. Para isso, passe o índice que você criou anteriormente para consultas e faça sua pergunta. O mecanismo de consulta é uma interface genérica para consultar dados. É necessária uma consulta em linguagem natural como entrada e retorna uma resposta rica. O mecanismo de consulta normalmente é construído sobre um ou mais índices utilização recuperadores.
Você pode ver que a solução RAG é capaz de recuperar a resposta correta dos documentos fornecidos:
Use ferramentas e agentes LangChain
Loader aula. O carregador foi projetado para carregar dados no LlamaIndex ou posteriormente como uma ferramenta em um Agente LangChain. Isso lhe dá mais poder e flexibilidade para usar isso como parte de seu aplicativo. Você começa definindo seu ferramenta da classe de agente LangChain. A função que você passa para sua ferramenta consulta o índice que você construiu sobre seus documentos usando LlamaIndex.
Em seguida, você seleciona o tipo certo de agente que gostaria de usar para sua implementação RAG. Neste caso, você usa o chat-zero-shot-react-description agente. Com este agente, o LLM utilizará a ferramenta disponível (neste cenário, o RAG sobre a base de conhecimento) para fornecer a resposta. Em seguida, você inicializa o agente passando sua ferramenta, LLM e tipo de agente:
Você pode ver o agente passando thoughts, actions e observation , utilize a ferramenta (nesse cenário, consultando seus documentos indexados); e retornar um resultado:
Você pode encontrar o código de implementação ponta a ponta no anexo GitHub repo.
limpar
Para evitar custos desnecessários, você pode limpar seus recursos por meio dos seguintes snippets de código ou da IU do Amazon JumpStart.
Para usar o Boto3 SDK, use o código a seguir para excluir o endpoint do modelo de incorporação de texto e o endpoint do modelo de geração de texto, bem como as configurações do endpoint:
Para usar o console do SageMaker, conclua as seguintes etapas:
- No console do SageMaker, em Inferência no painel de navegação, escolha Endpoints
- Procure os pontos de extremidade de incorporação e geração de texto.
- Na página de detalhes do endpoint, escolha Excluir.
- Escolha Excluir novamente para confirmar.
Conclusão
Para casos de uso focados em pesquisa e recuperação, o LlamaIndex oferece recursos flexíveis. É excelente em indexação e recuperação para LLMs, tornando-se uma ferramenta poderosa para exploração profunda de dados. LlamaIndex permite que você crie índices de dados organizados, use diversos LLMs, aumente os dados para melhor desempenho do LLM e consulte dados com linguagem natural.
Esta postagem demonstrou alguns conceitos e recursos importantes do LlamaIndex. Usamos GPT-J para incorporação e Llama 2-Chat como LLM para construir um aplicativo RAG, mas você pode usar qualquer modelo adequado. Você pode explorar a ampla gama de modelos disponíveis no SageMaker JumpStart.
Também mostramos como o LlamaIndex pode fornecer ferramentas poderosas e flexíveis para conectar, indexar, recuperar e integrar dados com outras estruturas como LangChain. Com integrações LlamaIndex e LangChain, você pode construir aplicativos LLM mais poderosos, versáteis e perspicazes.
Sobre os autores
 Dra.Romina Sharifpour é arquiteto sênior de soluções de aprendizado de máquina e inteligência artificial na Amazon Web Services (AWS). Ela passou mais de 10 anos liderando o design e a implementação de soluções inovadoras de ponta a ponta, possibilitadas pelos avanços em ML e IA. As áreas de interesse de Romina são processamento de linguagem natural, grandes modelos de linguagem e MLOps.
Dra.Romina Sharifpour é arquiteto sênior de soluções de aprendizado de máquina e inteligência artificial na Amazon Web Services (AWS). Ela passou mais de 10 anos liderando o design e a implementação de soluções inovadoras de ponta a ponta, possibilitadas pelos avanços em ML e IA. As áreas de interesse de Romina são processamento de linguagem natural, grandes modelos de linguagem e MLOps.
 Nicole Pinto é arquiteto de soluções especialista em AI/ML baseado em Sydney, Austrália. Sua experiência em serviços financeiros e de saúde lhe dá uma perspectiva única na solução dos problemas dos clientes. Ela é apaixonada por capacitar clientes por meio de aprendizado de máquina e capacitar a próxima geração de mulheres em STEM.
Nicole Pinto é arquiteto de soluções especialista em AI/ML baseado em Sydney, Austrália. Sua experiência em serviços financeiros e de saúde lhe dá uma perspectiva única na solução dos problemas dos clientes. Ela é apaixonada por capacitar clientes por meio de aprendizado de máquina e capacitar a próxima geração de mulheres em STEM.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

