Introdução
No passado, a IA Generativa conquistou o mercado e, como resultado, agora temos vários modelos com diferentes aplicações. A avaliação da Gen AI começou com a arquitetura Transformer, e desde então esta estratégia foi adotada em outras áreas. Vejamos um exemplo. Como sabemos, atualmente utilizamos o modelo VIT na área de difusão estável. Ao explorar mais o modelo, você verá que dois tipos de serviços estão disponíveis: serviços pagos e modelos de código aberto de uso gratuito. O usuário que quiser acessar os serviços extras pode utilizar serviços pagos como OpenAI, e para o modelo open source, temos o Hugging Face.
Você pode acessar o modelo e de acordo com sua tarefa, pode baixar o respectivo modelo nos serviços. Além disso, observe que podem ser aplicadas taxas para modelos de token de acordo com o respectivo serviço na versão paga. Da mesma forma, a AWS também fornece serviços como AWS Bedrock, que permite acesso a modelos LLM por meio de API. No final desta postagem do blog, vamos discutir os preços dos serviços.
Objetivos de aprendizagem
- Compreendendo IA generativa com difusão estável, modelos LLaMA 2 e Claude.
- Explorando os recursos e capacidades dos modelos Stable Diffusion, LLaMA 2 e Claude do AWS Bedrock.
- Explorando o AWS Bedrock e seus preços.
- Aprenda como aproveitar esses modelos para diversas tarefas, como geração de imagens, síntese de texto e geração de código.
Este artigo foi publicado como parte do Blogatona de Ciência de Dados.
Índice
O que é IA generativa?
IA generativa é um subconjunto de inteligência artificial (IA) desenvolvido para criar novo conteúdo com base nas solicitações do usuário, como imagens, texto ou código. Esses modelos são altamente treinados em grandes quantidades de dados, o que torna a produção de conteúdo ou resposta às solicitações dos usuários muito mais precisa e menos complexa em termos de tempo. A IA generativa tem muitas aplicações em diferentes domínios, como artes criativas, geração de conteúdo, aumento de dados e resolução de problemas.
Você pode consultar alguns dos meus blogs criados com modelos LLM, como chatbot (Gemini Pro) e Ajuste fino automatizado de modelos LLaMA 2 no Gradient AI Cloud. Eu também criei o Hugging Face BLOOM modelo da Meta para desenvolver o chatbot.
Principais recursos do GenAI
- Criação de conteúdo: Os modelos LLM podem gerar novo conteúdo usando as consultas fornecidas como entrada pelo usuário para gerar texto, imagens ou código.
- Afinação: Podemos fazer o ajuste fino facilmente, o que significa que podemos treinar o modelo em diferentes parâmetros para aumentar o desempenho dos modelos LLM e melhorar seu poder.
- Aprendizagem baseada em dados: Os modelos de IA generativos são treinados em grandes conjuntos de dados com parâmetros diferentes, permitindo-lhes aprender padrões de dados e tendências nos dados para gerar resultados precisos e significativos.
- Eficiência: Modelos generativos de IA fornecem resultados precisos; desta forma, economizam tempo e recursos em comparação com os métodos de criação manual.
- Versatilidade: Esses modelos são úteis em todos os campos. A IA generativa tem aplicações em diferentes domínios, incluindo artes criativas, geração de conteúdo, aumento de dados e resolução de problemas.
O que é o AWS Bedrock?
AWS Bedrock é uma plataforma fornecida pela Amazon Web Services (AWS). A AWS fornece uma variedade de serviços, então eles adicionaram recentemente o serviço de IA generativa Bedrock, que adicionou uma variedade de modelos de linguagem grandes (LLMs). Esses modelos são construídos para tarefas específicas em diferentes domínios. Temos vários modelos, como o modelo de geração de texto e o modelo de imagem, que podem ser perfeitamente integrados em softwares como o VSCode por cientistas de dados. Podemos usar LLMs para treinar e implantar diferentes tarefas de PNL, como geração de texto, resumo, tradução e muito mais.
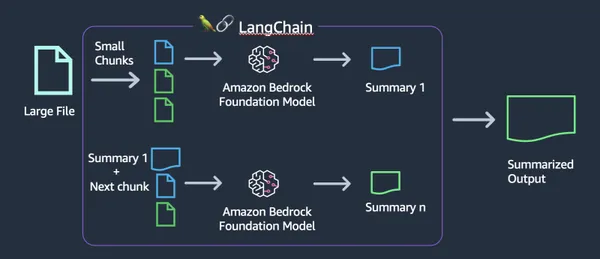
Principais recursos do AWS Bedrock
- Acesso a modelos pré-treinados: AWS Bedrock oferece muitos modelos LLM pré-treinados que os usuários podem utilizar facilmente sem a necessidade de criar ou treinar modelos do zero.
- Afinação: os usuários podem ajustar modelos pré-treinados usando seus próprios conjuntos de dados para adaptá-los a casos de uso e domínios específicos.
- AMPLIAR: o AWS Bedrock é baseado na infraestrutura da AWS, fornecendo escalabilidade para lidar com grandes conjuntos de dados e cargas de trabalho de IA com uso intensivo de computação.
- API abrangente: Bedrock fornece uma API abrangente por meio da qual podemos nos comunicar facilmente com o modelo.
Como construir o AWS Bedrock?
Configurar o AWS Bedrock é simples, mas poderoso. Essa estrutura, baseada na Amazon Web Services (AWS), fornece uma base confiável para seus aplicativos. Vamos seguir as etapas simples para começar.
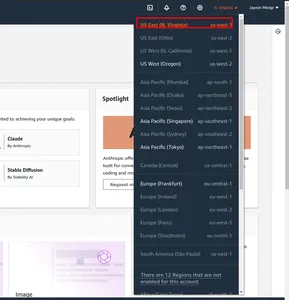
- Em primeiro lugar, navegue até o AWS Management Console. E mude de região. Marquei na caixa vermelha us-east-1.
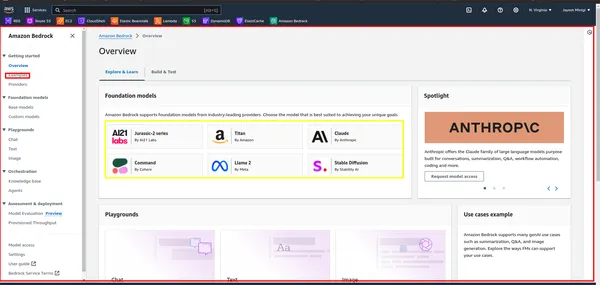
- Em seguida, pesquise “Bedrock” no AWS Management Console e clique nele. Em seguida, clique no botão “Começar”. Isso o levará ao painel do Bedrock, onde você pode acessar a interface do usuário.
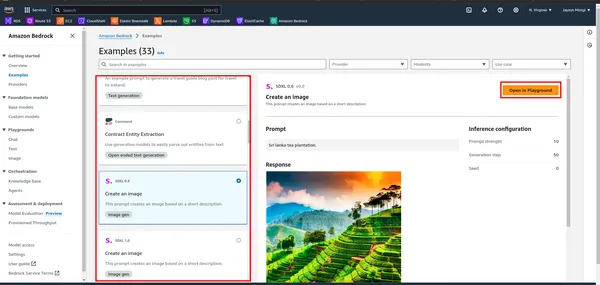
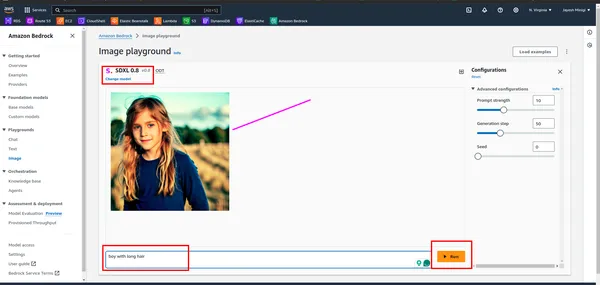
- Dentro do painel, você notará um retângulo amarelo contendo vários modelos de fundação, como LLaMA 2, Claude, etc. Clique no retângulo vermelho para ver exemplos e demonstrações desses modelos.
- Ao clicar no exemplo, você será direcionado para uma página onde encontrará um retângulo vermelho. Clique em qualquer uma dessas opções para fins de playground.
O que é difusão estável?
Difusão Estável é um modelo GenAI que gera imagens com base na entrada do usuário (texto). Os usuários fornecem prompts de texto e o Stable Diffusion produz imagens correspondentes, conforme demonstrado na parte prática. Foi lançado em 2022 e utiliza tecnologia de difusão e espaço latente para criar imagens de alta qualidade.
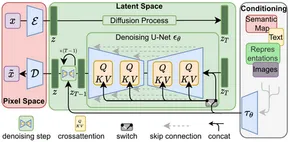
Após o início da arquitetura do transformador no processamento de linguagem natural (PNL), um progresso significativo foi feito. Na visão computacional, modelos como o Vision Transformer (ViT) tornaram-se predominantes. Embora arquiteturas tradicionais como o modelo codificador-decodificador fossem comuns, o Stable Diffusion adota uma arquitetura codificador-decodificador usando U-Net. Esta escolha arquitetônica contribui para sua eficácia na geração de imagens de alta qualidade.
A difusão estável opera adicionando progressivamente ruído gaussiano a uma imagem até que apenas o ruído aleatório permaneça - um processo conhecido como difusão direta. Posteriormente, esse ruído é revertido para recriar a imagem original usando um preditor de ruído.
No geral, a Difusão Estável representa um avanço notável na IA generativa, oferecendo recursos de geração de imagens eficientes e de alta qualidade.
Principais recursos da difusão estável
- Geração de Imagem: Stable Diffusion usa o modelo VIT para criar imagens do usuário (texto) como entradas.
- Versatilidade: Este modelo é versátil, portanto podemos utilizá-lo em seus respectivos campos. Podemos criar imagens, GiF, vídeos e animações.
- Eficiência: Os modelos de difusão estável utilizam espaço latente, exigindo menos poder de processamento em comparação com outros modelos de geração de imagens.
- Recursos de ajuste fino: os usuários podem ajustar a difusão estável para atender às suas necessidades específicas. Ao ajustar parâmetros como etapas de eliminação de ruído e níveis de ruído, os usuários podem personalizar a saída de acordo com suas preferências.
Algumas das imagens criadas usando o modelo de difusão estável


Como construir uma difusão estável?
Para construir o Stable Diffusion, você precisará seguir várias etapas, incluindo configurar seu ambiente de desenvolvimento, acessar o modelo e invocá-lo com os parâmetros apropriados.
Passo 1. Preparação do Ambiente
- Criação de Ambiente Virtual: Crie um ambiente virtual usando venv
conda create -p ./venv python=3.10 -y
- Ativação de Ambiente Virtual: Ative o ambiente virtual
conda activate ./venvEtapa 2. Instalando Pacotes de Requisitos
!pip install boto3
!pip install awscliEtapa 3: configurar a AWS CLI
- Primeiro, você precisa criar um usuário no IAM e conceder a ele as permissões necessárias, como acesso administrativo.
- Depois disso, siga os comandos abaixo para configurar a AWS CLI para que você possa acessar facilmente o modelo.
- Configurar credenciais da AWS: Depois de instalado, você precisa configurar suas credenciais da AWS. Abra um terminal ou prompt de comando e execute o seguinte comando:
aws configure- Depois de executar o comando acima, você verá uma interface de usuário semelhante a esta.
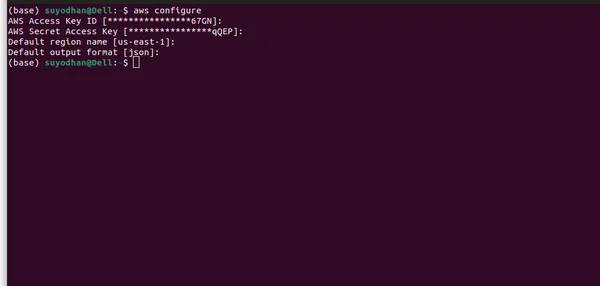
- Certifique-se de fornecer todas as informações necessárias e selecionar a região correta, pois o modelo LLM pode não estar disponível em todas as regiões. Além disso, especifiquei a região onde o modelo LLM está disponível no AWS Bedrock.
Passo 4: Importando as bibliotecas necessárias
- Importe os pacotes necessários.
import boto3
import json
import base64
import os
- Boto3 é uma biblioteca Python que fornece uma interface fácil de usar para interagir programaticamente com recursos da Amazon Web Services (AWS).
Etapa 5: Crie um cliente AWS Bedrock
bedrock = boto3.client(service_name="bedrock-runtime")
Etapa 6: definir parâmetros de carga útil
- Primeiro, observe a API no AWS Bedrock.
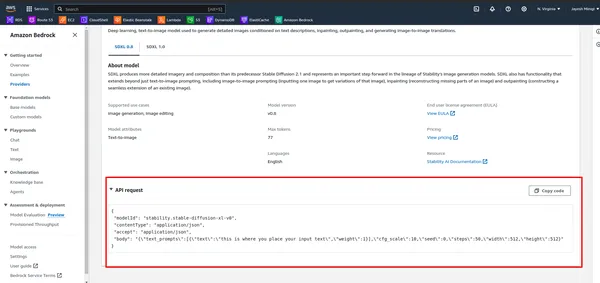
- Execute a célula abaixo.
# DEFINE THE USER QUERY
USER_QUERY="provide me an 4k hd image of a beach, also use a blue sky rainy season and
cinematic display"
payload_params = {
"text_prompts": [{"text": USER_QUERY, "weight": 1}],
"cfg_scale": 10,
"seed": 0,
"steps": 50,
"width": 512,
"height": 512
}
Etapa 7: definir o objeto Payload
model_id = "stability.stable-diffusion-xl-v0"
response = bedrock.invoke_model(
body= json.dumps(payload_params),
modelId=model_id,
accept="application/json",
contentType="application/json",
)
Etapa 8: envie uma solicitação para a API AWS Bedrock e obtenha o corpo da resposta
response_body = json.loads(response.get("body").read())

Etapa 9: extrair dados de imagem da resposta
artifact = response_body.get("artifacts")[0]
image_encoded = artifact.get("base64").encode("utf-8")
image_bytes = base64.b64decode(image_encoded)
Etapa 10: salve a imagem em um arquivo
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
file_name = f"{output_dir}/generated-img.png"
with open(file_name, "wb") as f:
f.write(image_bytes)

Etapa 11: crie um aplicativo Streamlit
- Primeiro instale o Streamlit. Para isso abra o terminal e passe por ele.
pip install streamlit
- Crie um script Python para o aplicativo Streamlit
import streamlit as st
import boto3
import json
import base64
import os
def generate_image(prompt_text):
prompt_template = [{"text": prompt_text, "weight": 1}]
bedrock = boto3.client(service_name="bedrock-runtime")
payload = {
"text_prompts": prompt_template,
"cfg_scale": 10,
"seed": 0,
"steps": 50,
"width": 512,
"height": 512
}
body = json.dumps(payload)
model_id = "stability.stable-diffusion-xl-v0"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json",
)
response_body = json.loads(response.get("body").read())
artifact = response_body.get("artifacts")[0]
image_encoded = artifact.get("base64").encode("utf-8")
image_bytes = base64.b64decode(image_encoded)
# Save image to a file in the output directory.
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
file_name = f"{output_dir}/generated-img.png"
with open(file_name, "wb") as f:
f.write(image_bytes)
return file_name
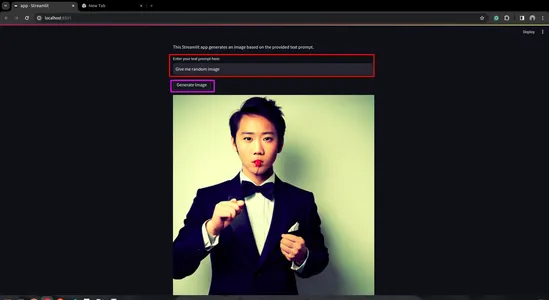
def main():
st.title("Generated Image")
st.write("This Streamlit app generates an image based on the provided text prompt.")
# Text input field for user prompt
prompt_text = st.text_input("Enter your text prompt here:")
if st.button("Generate Image") and prompt_text:
image_file = generate_image(prompt_text)
st.image(image_file, caption="Generated Image", use_column_width=True)
elif st.button("Generate Image") and not prompt_text:
st.error("Please enter a text prompt.")
if __name__ == "__main__":
main()
- Execute o aplicativo Streamlit
streamlit run app.py
O que é LLaMA 2?
LLaMA 2, ou Modelo de Linguagem Grande de Muitas Aplicações, pertence à categoria de Modelos de Linguagem Grande (LLM). O Facebook (Meta) desenvolveu este modelo para explorar um amplo espectro de aplicações de processamento de linguagem natural (PNL). Nas séries anteriores, o modelo 'LAMA' foi a face inicial do desenvolvimento, mas utilizou métodos ultrapassados.
Principais recursos do LLaMA 2
- Versatilidade: LLaMA 2 é um modelo poderoso capaz de realizar diversas tarefas com alta precisão e eficiência
- Compreensão contextual: Na aprendizagem sequência a sequência, exploramos fonemas, morfemas, lexemas, sintaxe e contexto. O LLaMA 2 permite uma melhor compreensão das nuances contextuais.
- Aprendizagem por transferência: LLaMA 2 é um modelo robusto, que se beneficia de treinamento extensivo em um grande conjunto de dados. A aprendizagem por transferência facilita sua rápida adaptabilidade a tarefas específicas.
- Open-Source: Na Ciência de Dados, um aspecto fundamental é a comunidade. Os modelos de código aberto permitem que pesquisadores, desenvolvedores e comunidades os explorem, adaptem e integrem em seus projetos.
Casos de uso
- LLaMA 2 pode ajudar criando geração de texto tarefas, como escrita de histórias, criação de conteúdo, etc.
- Sabemos a importância do aprendizado zero-shot. Então, podemos usar o LLaMA 2 para responder perguntas tarefas, semelhantes ao ChatGPT. Ele fornece respostas relevantes e precisas.
- Para tradução de idiomas, no mercado, temos APIs, mas precisamos fazer assinatura. Mas LLaMA 2 oferece tradução de idiomas gratuitamente, tornando-o fácil de utilizar.
- O LLaMA 2 é fácil de usar e uma excelente opção para desenvolver chatbots.
Como construir o LLaMA 2
Para construir o LLaMA 2, você precisará seguir vários passos, incluindo configurar seu ambiente de desenvolvimento, acessar o modelo e invocá-lo com os parâmetros apropriados.
Etapa 1: importar bibliotecas
- Na primeira célula do notebook, importe as bibliotecas necessárias:
import boto3
import json
Etapa 2: definir o prompt e o cliente AWS Bedrock
- Na próxima célula, defina o prompt para geração do poema e crie um cliente para acesso à API AWS Bedrock:
prompt_data = """
Act as a Shakespeare and write a poem on Generative AI
"""
bedrock = boto3.client(service_name="bedrock-runtime")
Etapa 3: definir carga útil e modelo de invocação
- Primeiro, observe a API no AWS Bedrock.
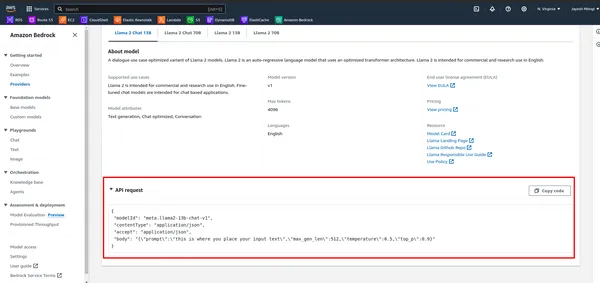
- Defina a carga útil com o prompt e outros parâmetros e, em seguida, invoque o modelo usando o cliente AWS Bedrock:
payload = {
"prompt": "[INST]" + prompt_data + "[/INST]",
"max_gen_len": 512,
"temperature": 0.5,
"top_p": 0.9
}
body = json.dumps(payload)
model_id = "meta.llama2-70b-chat-v1"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
response_text = response_body['generation']
print(response_text)
Etapa 4: execute o notebook
- Execute as células do notebook uma por uma pressionando Shift + Enter. A saída da última célula exibirá o poema gerado.
Etapa 5: crie um aplicativo Streamlit
- Crie um script Python: crie um novo script Python (por exemplo, lhama2_app.py) e abra-o em seu editor de código preferido
import streamlit as st
import boto3
import json
# Define AWS Bedrock client
bedrock = boto3.client(service_name="bedrock-runtime")
# Streamlit app layout
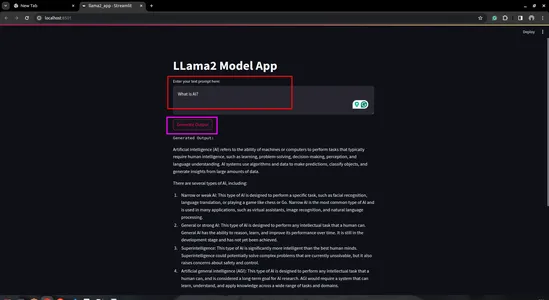
st.title('LLama2 Model App')
# Text input for user prompt
user_prompt = st.text_area('Enter your text prompt here:', '')
# Button to trigger model invocation
if st.button('Generate Output'):
payload = {
"prompt": user_prompt,
"max_gen_len": 512,
"temperature": 0.5,
"top_p": 0.9
}
body = json.dumps(payload)
model_id = "meta.llama2-70b-chat-v1"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
generation = response_body['generation']
st.text('Generated Output:')
st.write(generation)
- Execute o aplicativo Streamlit:
- Salve seu script Python e execute-o usando o comando Streamlit em seu terminal:
streamlit run llama2_app.py
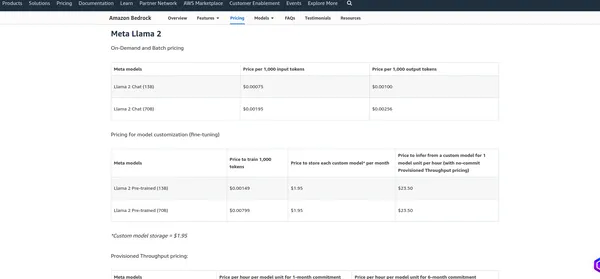
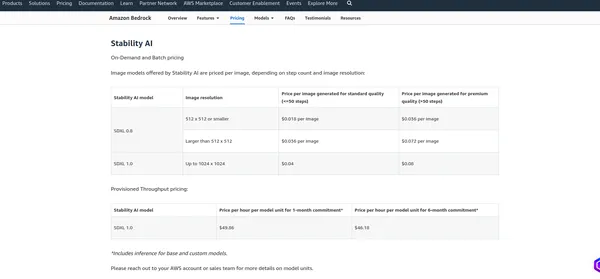
Preços do AWS Bedrock
A preços do AWS Bedrock depende de vários fatores e dos serviços que você usa, como hospedagem de modelo, solicitações de inferência, armazenamento e transferência de dados. A AWS normalmente cobra com base no uso, o que significa que você paga apenas pelo que usa. Recomendo verificar a página oficial de preços, pois a AWS pode alterar sua estrutura de preços. Posso fornecer as cobranças atuais, mas é melhor verificar as informações no Página oficial para obter os detalhes mais precisos.
Meta Lhama 2
IA de estabilidade
Conclusão
Este blog mergulhou no domínio da IA generativa, concentrando-se especificamente em dois modelos LLM poderosos: Difusão Estável e LLamV2. Também exploramos o AWS Bedrock como uma plataforma para a criação de APIs de modelo LLM. Usando essas APIs, demonstramos como escrever código para interagir com os modelos. Além disso, utilizamos o playground AWS Bedrock para praticar e avaliar os recursos dos modelos.
Inicialmente, destacamos a importância de selecionar a região correta no AWS Bedrock, pois esses modelos podem não estar disponíveis em todas as regiões. Seguindo em frente, fornecemos uma exploração prática de cada modelo LLM, começando com a criação de notebooks Jupyter e depois fazendo a transição para o desenvolvimento de aplicativos Streamlit.
Por fim, discutimos a estrutura de preços do AWS Bedrock, ressaltando a necessidade de compreender os custos associados e consultando a página oficial de preços para obter informações precisas.
Principais lições
- Stable Diffusion e LLAMV2 no AWS Bedrock oferecem acesso fácil a poderosos recursos de IA generativa.
- O AWS Bedrock oferece uma interface simples e documentação abrangente para integração perfeita.
- Esses modelos têm diferentes recursos principais e casos de uso em vários domínios.
- Lembre-se de escolher a região certa para acesso aos modelos desejados no AWS Bedrock.
- A implementação prática de modelos generativos de IA, como Stable Diffusion e LLAMv2, oferece eficiência no AWS Bedrock.
Perguntas Frequentes
R. A IA generativa é um subconjunto de inteligência artificial focado na criação de novos conteúdos, como imagens, texto ou código, em vez de apenas analisar dados existentes.
A. Difusão Estável é um modelo generativo de IA que produz imagens fotorrealistas a partir de prompts de texto e imagem usando tecnologia de difusão e espaço latente.
R. O AWS Bedrock fornece APIs para gerenciamento, treinamento e implantação de modelos, permitindo que os usuários acessem grandes modelos de linguagem, como LLAMv2, para diversas aplicações.
R. Você pode acessar modelos LLM no AWS Bedrock usando as APIs fornecidas, como invocar o modelo com parâmetros específicos e receber a saída gerada.
R. O Stable Diffusion pode gerar imagens de alta qualidade a partir de prompts de texto, operar com eficiência usando espaço latente e ser acessível a uma ampla gama de usuários.
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do Autor.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/02/building-end-to-end-generative-ai-models-with-aws-bedrock/

