Este é um post convidado escrito por Axfood AB.
Nesta postagem, compartilhamos como a Axfood, um grande varejista de alimentos sueco, melhorou as operações e a escalabilidade de suas operações existentes de inteligência artificial (IA) e aprendizado de máquina (ML) por meio da prototipagem em estreita colaboração com especialistas da AWS e usando Amazon Sage Maker.
axfood é o segundo maior retalhista alimentar da Suécia, com mais de 13,000 funcionários e mais de 300 lojas. A Axfood possui uma estrutura com múltiplas equipes descentralizadas de ciência de dados com diferentes áreas de responsabilidade. Juntamente com uma equipe central de plataforma de dados, as equipes de ciência de dados trazem inovação e transformação digital para a organização por meio de soluções de IA e ML. A Axfood usa o Amazon SageMaker para cultivar seus dados usando ML e tem modelos em produção há muitos anos. Ultimamente, o nível de sofisticação e o grande número de modelos em produção têm aumentado exponencialmente. No entanto, embora o ritmo de inovação seja elevado, as diferentes equipas desenvolveram as suas próprias formas de trabalhar e estavam em busca de uma nova melhor prática de MLOps.
Nosso desafio
Para se manter competitiva em termos de serviços em nuvem e IA/ML, a Axfood optou por fazer parceria com a AWS e colabora com eles há muitos anos.
Durante uma de nossas sessões recorrentes de brainstorming com a AWS, estávamos discutindo a melhor forma de colaborar entre as equipes para aumentar o ritmo de inovação e a eficiência dos profissionais de ciência de dados e ML. Decidimos fazer um esforço conjunto para construir um protótipo com base nas melhores práticas para MLOps. O objetivo do protótipo era construir um modelo para todas as equipes de ciência de dados construirem modelos de ML escalonáveis e eficientes – a base para uma nova geração de plataformas de IA e ML para Axfood. O modelo deve unir e combinar práticas recomendadas de especialistas em ML da AWS e modelos de práticas recomendadas específicos da empresa – o melhor dos dois mundos.
Decidimos construir um protótipo a partir de um dos modelos de ML mais desenvolvidos atualmente na Axfood: previsão de vendas nas lojas. Mais especificamente, a previsão para frutas e legumes das próximas campanhas para lojas de varejo alimentar. A previsão diária precisa apoia o processo de encomendas para as lojas, aumentando a sustentabilidade ao minimizar o desperdício de alimentos como resultado da otimização das vendas, prevendo com precisão os níveis de stock necessários nas lojas. Este era o lugar perfeito para começar nosso protótipo – a Axfood não apenas ganharia uma nova plataforma de IA/ML, mas também teríamos a chance de avaliar nossos recursos de ML e aprender com os principais especialistas da AWS.
Nossa solução: um novo modelo de ML no Amazon SageMaker Studio
Construir um pipeline de ML completo projetado para um caso de negócios real pode ser desafiador. Neste caso, estamos desenvolvendo um modelo de previsão, portanto há duas etapas principais a serem concluídas:
- Treine o modelo para fazer previsões usando dados históricos.
- Aplique o modelo treinado para fazer previsões de eventos futuros.
No caso da Axfood, um pipeline que funciona bem para esse fim já foi configurado usando notebooks SageMaker e orquestrado pela plataforma de gerenciamento de fluxo de trabalho de terceiros, Airflow. No entanto, há muitos benefícios claros em modernizar nossa plataforma de ML e migrar para Estúdio Amazon SageMaker e Pipelines Amazon SageMaker. Mudar para o SageMaker Studio oferece muitos recursos predefinidos e prontos para uso:
- Monitorando a qualidade do modelo e dos dados, bem como a explicabilidade do modelo
- Ferramentas integradas de ambiente de desenvolvimento integrado (IDE), como depuração
- Monitoramento de custo/desempenho
- Estrutura de aceitação do modelo
- Registro do modelo
No entanto, o incentivo mais importante para a Axfood é a capacidade de criar modelos de projetos personalizados usando Projetos do Amazon SageMaker para ser usado como modelo para todas as equipes de ciência de dados e profissionais de ML. A equipe da Axfood já possuía um nível robusto e maduro de modelagem de ML, então o foco principal estava na construção da nova arquitetura.
Visão geral da solução
A nova estrutura de ML proposta pela Axfood está estruturada em torno de dois pipelines principais: o pipeline de construção de modelo e o pipeline de inferência em lote:
- Esses pipelines são versionados em dois repositórios Git separados: um repositório de construção e um repositório de implantação (inferência). Juntos, eles formam um pipeline robusto para a previsão de frutas e vegetais.
- Os pipelines são empacotados em um modelo de projeto personalizado usando projetos SageMaker em integração com um repositório Git de terceiros (Bitbucket) e pipelines Bitbucket para integração contínua e componentes de implantação contínua (CI/CD).
- O modelo de projeto SageMaker inclui o código inicial correspondente a cada etapa dos pipelines de construção e implantação (discutiremos essas etapas com mais detalhes posteriormente nesta postagem), bem como a definição do pipeline – a receita de como as etapas devem ser executadas.
- A automação da construção de novos projetos com base no modelo é simplificada por meio de Catálogo de serviços da AWS, onde é criado um portfólio, servindo de abstração para múltiplos produtos.
- Cada produto se traduz em um Formação da Nuvem AWS modelo, que é implantado quando um cientista de dados cria um novo projeto SageMaker com nosso modelo MLOps como base. Isto ativa um AWS Lambda função que cria um projeto Bitbucket com dois repositórios – construção de modelo e implantação de modelo – contendo o código inicial.
O diagrama a seguir ilustra a arquitetura da solução. O fluxo de trabalho A descreve o fluxo complexo entre os dois pipelines do modelo: construção e inferência. O fluxo de trabalho B mostra o fluxo para criar um novo projeto de ML.

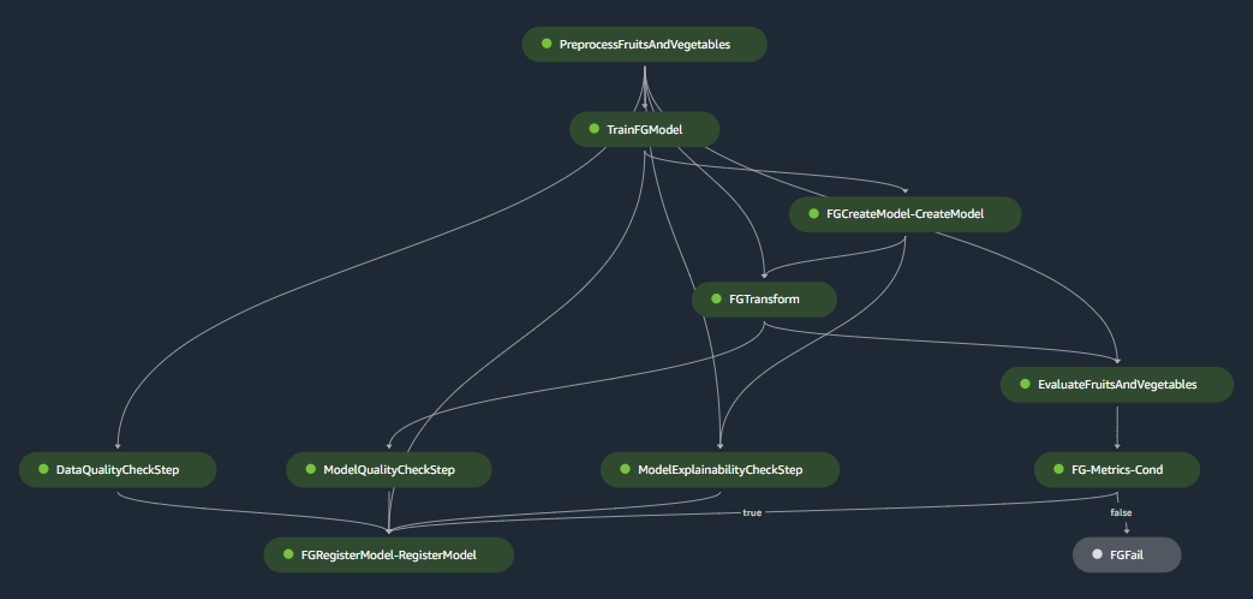
Pipeline de construção de modelo
O pipeline de construção do modelo orquestra o ciclo de vida do modelo, começando pelo pré-processamento, passando pelo treinamento e culminando no registro no registro do modelo:
- Pré-processando – Aqui, o SageMaker
ScriptProcessorclasse é empregada para engenharia de recursos, resultando no conjunto de dados no qual o modelo será treinado. - Treinamento e transformação em lote – Os contêineres personalizados de treinamento e inferência do SageMaker são aproveitados para treinar o modelo em dados históricos e criar previsões nos dados de avaliação usando um SageMaker Estimator e Transformer para as respectivas tarefas.
- Avaliação – O modelo treinado passa por avaliação comparando as previsões geradas nos dados de avaliação com a verdade básica usando
ScriptProcessor. - Trabalhos de linha de base – O pipeline cria linhas de base com base nas estatísticas dos dados de entrada. Eles são essenciais para monitorar dados e qualidade do modelo, bem como atribuições de recursos.
- Registro do modelo – O modelo treinado é registrado para uso futuro. O modelo será aprovado por cientistas de dados designados para implantá-lo para uso na produção.
Para ambientes de produção, a ingestão de dados e os mecanismos de acionamento são gerenciados por meio de uma orquestração primária do Airflow. Enquanto isso, durante o desenvolvimento, o pipeline é ativado cada vez que um novo commit é introduzido no repositório Bitbucket de construção de modelo. A figura a seguir visualiza o pipeline de construção do modelo.
Pipeline de inferência em lote
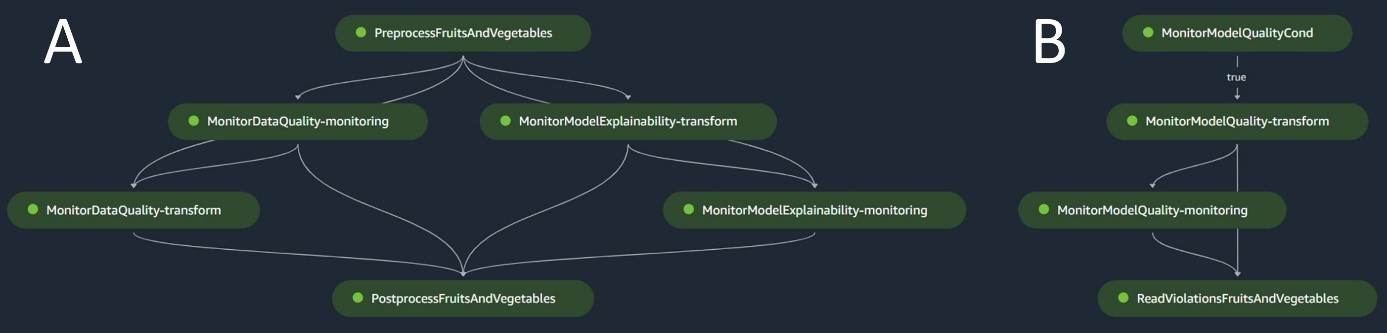
O pipeline de inferência em lote trata da fase de inferência, que consiste nas seguintes etapas:
- Pré-processando – Os dados são pré-processados usando
ScriptProcessor. - Transformação em lote – O modelo usa o contêiner de inferência personalizado com um SageMaker Transformer e gera previsões com base nos dados de entrada pré-processados. O modelo usado é o modelo treinado aprovado mais recente no registro de modelos.
- Pós-processamento – As previsões passam por uma série de etapas de pós-processamento usando
ScriptProcessor. - do Paciente – A vigilância contínua conclui as verificações de desvios relacionados à qualidade dos dados, qualidade do modelo e atribuição de recursos.
Se surgirem discrepâncias, uma lógica de negócios dentro do script de pós-processamento avalia se é necessário retreinar o modelo. O pipeline está programado para ser executado em intervalos regulares.
O diagrama a seguir ilustra o pipeline de inferência em lote. O fluxo de trabalho A corresponde ao pré-processamento, qualidade dos dados e verificações de desvios de atribuição de recursos, inferência e pós-processamento. O fluxo de trabalho B corresponde às verificações de desvios de qualidade do modelo. Esses pipelines são divididos porque a verificação de desvio de qualidade do modelo só será executada se novos dados reais estiverem disponíveis.
Monitor de modelo SageMaker
Com o Monitor de modelo do Amazon SageMaker integrados, os pipelines se beneficiam do monitoramento em tempo real do seguinte:
- Qualidade dos dados – Monitora qualquer desvio ou inconsistência nos dados
- Qualidade do modelo – Observa quaisquer flutuações no desempenho do modelo
- Atribuição de recursos – Verifica desvios nas atribuições de recursos
O monitoramento da qualidade do modelo requer acesso a dados reais. Embora a obtenção de dados reais possa às vezes ser um desafio, o uso do monitoramento de desvios de atribuição de dados ou recursos serve como um proxy competente para modelar a qualidade.
Especificamente, no caso de desvio na qualidade dos dados, o sistema observa o seguinte:
- Desvio de conceito – Isso se refere a mudanças na correlação entre entrada e saída, exigindo informações básicas
- Mudança de covariável – Aqui, a ênfase está nas alterações na distribuição das variáveis de entrada independentes
A funcionalidade de desvio de dados do SageMaker Model Monitor captura e examina meticulosamente os dados de entrada, implantando regras e verificações estatísticas. Alertas são gerados sempre que anomalias são detectadas.
Paralelamente ao uso de verificações de desvio de qualidade de dados como um proxy para monitorar a degradação do modelo, o sistema também monitora o desvio de atribuição de recursos usando a pontuação de ganho cumulativo descontado normalizado (NDCG). Essa pontuação é sensível às mudanças na ordem de classificação de atribuição de recursos, bem como às pontuações brutas de atribuição de recursos. Ao monitorar o desvio na atribuição de recursos individuais e sua importância relativa, é fácil detectar a degradação na qualidade do modelo.
Explicabilidade do modelo
A explicabilidade do modelo é uma parte essencial das implantações de ML, porque garante transparência nas previsões. Para uma compreensão detalhada, usamos Esclarecimento do Amazon SageMaker.
Ele oferece explicações de modelos globais e locais por meio de uma técnica de atribuição de recursos independente de modelo baseada no conceito de valor Shapley. Isso é usado para decodificar por que uma determinada previsão foi feita durante a inferência. Tais explicações, que são inerentemente contrastantes, podem variar com base em diferentes linhas de base. O SageMaker Clarify ajuda a determinar essa linha de base usando K-means ou K-prototypes no conjunto de dados de entrada, que é então adicionado ao pipeline de construção do modelo. Essa funcionalidade nos permite construir aplicativos generativos de IA no futuro para aumentar a compreensão de como o modelo funciona.
Industrialização: Do protótipo à produção
O projeto MLOps inclui um alto grau de automação e pode servir como modelo para casos de uso semelhantes:
- A infraestrutura pode ser totalmente reutilizada, enquanto o código inicial pode ser adaptado para cada tarefa, com a maioria das alterações limitadas à definição do pipeline e à lógica de negócios para pré-processamento, treinamento, inferência e pós-processamento.
- Os scripts de treinamento e inferência são hospedados usando contêineres personalizados do SageMaker, para que uma variedade de modelos possa ser acomodada sem alterações nos dados e no monitoramento do modelo ou nas etapas de explicabilidade do modelo, desde que os dados estejam em formato tabular.
Depois de terminar o trabalho no protótipo, passamos a ver como deveríamos utilizá-lo na produção. Para isso, sentimos a necessidade de fazer alguns ajustes adicionais no template MLOps:
- O código inicial original usado no protótipo do modelo incluía etapas de pré-processamento e pós-processamento executadas antes e depois das etapas principais de ML (treinamento e inferência). No entanto, ao ampliar para usar o modelo em vários casos de uso na produção, as etapas integradas de pré-processamento e pós-processamento podem levar à diminuição da generalidade e da reprodução do código.
- Para melhorar a generalidade e minimizar o código repetitivo, optamos por reduzir ainda mais os pipelines. Em vez de executar as etapas de pré-processamento e pós-processamento como parte do pipeline de ML, nós as executamos como parte da orquestração primária do Airflow antes e depois de acionar o pipeline de ML.
- Dessa forma, as tarefas de processamento específicas do caso de uso são abstraídas do modelo, e o que resta é um pipeline principal de ML executando tarefas gerais em vários casos de uso com repetição mínima de código. Os parâmetros que diferem entre os casos de uso são fornecidos como entrada para o pipeline de ML a partir da orquestração primária do Airflow.
O resultado: uma abordagem rápida e eficiente para construção e implantação de modelos
O protótipo em colaboração com a AWS resultou em um modelo MLOps seguindo as melhores práticas atuais que agora está disponível para uso por todas as equipes de ciência de dados da Axfood. Ao criar um novo projeto SageMaker no SageMaker Studio, os cientistas de dados podem iniciar novos projetos de ML de forma rápida e fazer uma transição perfeita para a produção, permitindo um gerenciamento de tempo mais eficiente. Isso é possível automatizando tarefas MLOps tediosas e repetitivas como parte do modelo.
Além disso, várias novas funcionalidades foram adicionadas de forma automatizada à nossa configuração de ML. Esses ganhos incluem:
- Monitoramento de modelo – Podemos realizar verificações de desvios para a qualidade do modelo e dos dados, bem como para a explicabilidade do modelo
- Modelo e linhagem de dados – Agora é possível rastrear exatamente quais dados foram usados para qual modelo
- Registro do modelo – Isso nos ajuda a catalogar modelos para produção e gerenciar versões de modelos
Conclusão
Nesta postagem, discutimos como a Axfood melhorou as operações e a escalabilidade de nossas operações existentes de IA e ML em colaboração com especialistas da AWS e usando o SageMaker e seus produtos relacionados.
Essas melhorias ajudarão as equipes de ciência de dados da Axfood a construir fluxos de trabalho de ML de maneira mais padronizada e simplificarão bastante a análise e o monitoramento de modelos em produção, garantindo a qualidade dos modelos de ML construídos e mantidos por nossas equipes.
Por favor, deixe qualquer comentário ou pergunta na seção de comentários.
Sobre os autores
 Dr.Björn Blomqvist é o chefe de estratégia de IA da Axfood AB. Antes de ingressar na Axfood AB, ele liderou uma equipe de cientistas de dados na Dagab, parte da Axfood, construindo soluções inovadoras de aprendizado de máquina com a missão de fornecer alimentos bons e sustentáveis para pessoas em toda a Suécia. Nascido e criado no norte da Suécia, nas horas vagas Björn se aventura em montanhas nevadas e mar aberto.
Dr.Björn Blomqvist é o chefe de estratégia de IA da Axfood AB. Antes de ingressar na Axfood AB, ele liderou uma equipe de cientistas de dados na Dagab, parte da Axfood, construindo soluções inovadoras de aprendizado de máquina com a missão de fornecer alimentos bons e sustentáveis para pessoas em toda a Suécia. Nascido e criado no norte da Suécia, nas horas vagas Björn se aventura em montanhas nevadas e mar aberto.
 Oskar Klang é Cientista de Dados Sênior no departamento de análise da Dagab, onde gosta de trabalhar com tudo relacionado a análise e aprendizado de máquina, por exemplo, otimização de operações da cadeia de suprimentos, construção de modelos de previsão e, mais recentemente, aplicações GenAI. Ele está empenhado em construir pipelines de aprendizado de máquina mais simplificados, aumentando a eficiência e a escalabilidade.
Oskar Klang é Cientista de Dados Sênior no departamento de análise da Dagab, onde gosta de trabalhar com tudo relacionado a análise e aprendizado de máquina, por exemplo, otimização de operações da cadeia de suprimentos, construção de modelos de previsão e, mais recentemente, aplicações GenAI. Ele está empenhado em construir pipelines de aprendizado de máquina mais simplificados, aumentando a eficiência e a escalabilidade.
 Pavel Maslov é engenheiro sênior de DevOps e ML na equipe de plataformas analíticas. Pavel possui ampla experiência no desenvolvimento de frameworks, infraestrutura e ferramentas nas áreas de DevOps e ML/AI na plataforma AWS. Pavel tem sido um dos principais participantes na construção da capacidade fundamental de ML na Axfood.
Pavel Maslov é engenheiro sênior de DevOps e ML na equipe de plataformas analíticas. Pavel possui ampla experiência no desenvolvimento de frameworks, infraestrutura e ferramentas nas áreas de DevOps e ML/AI na plataforma AWS. Pavel tem sido um dos principais participantes na construção da capacidade fundamental de ML na Axfood.
 Joaquim Berg é o líder da equipe e proprietário do produto Analytic Platforms, com sede em Estocolmo, Suécia. Ele lidera uma equipe de engenheiros DevOps/MLOps finais de plataforma de dados, fornecendo plataformas de dados e ML para as equipes de ciência de dados. Joakim tem muitos anos de experiência liderando equipes seniores de desenvolvimento e arquitetura de diferentes setores.
Joaquim Berg é o líder da equipe e proprietário do produto Analytic Platforms, com sede em Estocolmo, Suécia. Ele lidera uma equipe de engenheiros DevOps/MLOps finais de plataforma de dados, fornecendo plataformas de dados e ML para as equipes de ciência de dados. Joakim tem muitos anos de experiência liderando equipes seniores de desenvolvimento e arquitetura de diferentes setores.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/how-axfood-enables-accelerated-machine-learning-throughout-the-organization-using-amazon-sagemaker/

