Introdução
A Retrieval Augmented-Generation (RAG) conquistou o mundo pela Storm desde o seu início. RAG é o que é necessário para que os Large Language Models (LLMs) forneçam ou gerem respostas precisas e factuais. Resolvemos a factualidade dos LLMs por RAG, onde tentamos dar ao LLM um contexto que seja contextualmente semelhante à consulta do usuário para que o LLM funcione com este contexto e gere uma resposta factualmente correta. Fazemos isso representando nossos dados e consultas do usuário na forma de incorporações vetoriais e realizando uma similaridade de cosseno. Mas o problema é que todas as abordagens tradicionais representam os dados numa única incorporação, o que pode não ser ideal para o bem. sistemas de recuperação. Neste guia, veremos o ColBERT, que realiza a recuperação com melhor precisão do que os modelos tradicionais de bi-codificador.
Objetivos de aprendizagem
- Entenda como a recuperação no RAG funciona em alto nível.
- Entenda as limitações de incorporação única na recuperação.
- Melhore o contexto de recuperação com incorporações de token do ColBERT.
- Saiba como a interação tardia do ColBERT melhora a recuperação.
- Saiba como trabalhar com ColBERT para uma recuperação precisa.
Este artigo foi publicado como parte do Blogatona de Ciência de Dados.
Conteúdo
O que é RAG?
Os LLMs, embora sejam capazes de gerar texto significativo e gramaticalmente correto, esses LLMs sofrem de um problema chamado alucinação. Alucinação em LLMs é o conceito onde os LLMs geram respostas erradas com segurança, ou seja, eles inventam respostas erradas de uma forma que nos faz acreditar que são verdadeiras. Este tem sido um grande problema desde a introdução dos LLMs. Essas alucinações levam a respostas incorretas e factualmente erradas. Conseqüentemente, a Geração Aumentada de Recuperação foi introduzida.
No RAG, pegamos uma lista de documentos/pedaços de documentos e codificamos esses documentos textuais em uma representação numérica chamada incorporação vetorial, onde uma única incorporação vetorial representa um único pedaço de documento e os armazena em um banco de dados chamado loja de vetores. Os modelos necessários para codificar esses pedaços em embeddings são chamados de modelos de codificação ou bi-codificadores. Esses codificadores são treinados em um grande corpus de dados, tornando-os poderosos o suficiente para codificar os pedaços de documentos em uma única representação de incorporação vetorial.
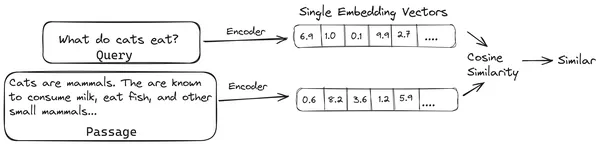
Agora, quando um usuário faz uma consulta ao LLM, fornecemos essa consulta ao mesmo codificador para produzir uma incorporação de vetor único. Essa incorporação é então usada para calcular a pontuação de similaridade com várias outras incorporações vetoriais dos pedaços do documento para obter o pedaço mais relevante do documento. O pedaço mais relevante ou uma lista dos pedaços mais relevantes junto com a consulta do usuário são fornecidos ao LLM. O LLM então recebe essas informações contextuais extras e gera uma resposta alinhada com o contexto recebido da consulta do usuário. Isso garante que o conteúdo gerado pelo LLM seja factual e algo que possa ser rastreado, se necessário.
O problema com os bi-codificadores tradicionais
O problema com modelos de codificadores tradicionais como o all-miniLM, OpenAI modelo de incorporação e outros modelos de codificador é que eles compactam o texto inteiro em uma única representação de incorporação vetorial. Essas representações de incorporação de vetor único são úteis porque ajudam na recuperação rápida e eficiente de documentos semelhantes. Porém, o problema está na contextualidade entre a consulta e o documento. A incorporação de um único vetor pode não ser suficiente para armazenar as informações contextuais de um pedaço de documento, criando assim um gargalo de informações.
Imagine que 500 palavras estão sendo compactadas em um único vetor de tamanho 782. Pode não ser suficiente representar tal pedaço com a incorporação de um único vetor, fornecendo assim resultados abaixo da média na recuperação na maioria dos casos. A representação vetorial única também pode falhar em casos de consultas ou documentos complexos. Uma dessas soluções seria representar o pedaço do documento ou uma consulta como uma lista de vetores de incorporação em vez de um único vetor de incorporação, é aqui que entra o ColBERT.
O que é ColBERT?
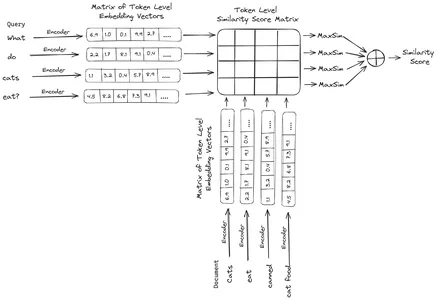
ColBERT (Contextual Late Interactions BERT) é um bi-codificador que representa texto em uma representação de incorporação multivetorial. Ele recebe uma consulta ou um pedaço de um documento/um documento pequeno e cria incorporações de vetores no nível do token. Ou seja, cada token obtém sua própria incorporação de vetor e a consulta/documento é codificada em uma lista de incorporações de vetor em nível de token. Os embeddings em nível de token são gerados a partir de um pré-treinado BERT modelo daí o nome BERT.
Eles são então armazenados no banco de dados vetorial. Agora, quando uma consulta chega, uma lista de embeddings em nível de token é criada para ela e, em seguida, uma multiplicação de matrizes é realizada entre a consulta do usuário e cada documento, resultando em uma matriz contendo pontuações de similaridade. A similaridade geral é obtida calculando a soma da similaridade máxima entre os tokens do documento para cada token de consulta. A fórmula para isso pode ser vista na foto abaixo:
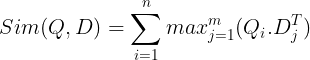
Aqui na equação acima, vemos que fazemos um produto escalar entre a Matriz de Tokens de Consulta (contendo N embeddings de vetor de nível de token) e a Matriz de Transposição de Tokens de Documento (contendo M embeddings de vetor de nível de token) e, em seguida, tomamos a similaridade máxima cruze os tokens do documento para cada token de consulta. Depois pegamos a soma de todas essas semelhanças máximas, o que nos dá a pontuação final de semelhança entre o documento e a consulta. A razão pela qual isso produz uma recuperação eficaz e precisa é que aqui estamos tendo uma interação em nível de token, o que dá espaço para uma compreensão mais contextual entre a consulta e o documento.
Por que o nome ColBERT?
Como estamos computando a lista de vetores incorporados antes de si mesmo e apenas executando esta operação MaxSim (máxima similaridade) durante a inferência do modelo, chamando-a de etapa de interação tardia, e como estamos obtendo mais informações contextuais por meio de interações em nível de token, ela é chamada de contextual interações tardias. Daí o nome Interações Contextuais Tardias BERT ou ColBERT. Esses cálculos podem ser realizados em paralelo, portanto, podem ser calculados de forma eficiente. Por fim, uma preocupação é o espaço, ou seja, é necessário muito espaço para armazenar esta lista de embeddings vetoriais em nível de token. Este problema foi resolvido no ColBERTv2, onde os embeddings são comprimidos através da técnica chamada compressão residual, otimizando assim o espaço utilizado.
ColBERT prático com exemplo
Nesta seção, colocaremos a mão na massa com o ColBERT e até verificaremos seu desempenho em relação a um modelo de incorporação regular.
Etapa 1: baixar bibliotecas
Começaremos baixando a seguinte biblioteca:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Esta biblioteca nos permite trabalhar com métodos de recuperação de última geração (SOTA), como ColBERT, de uma forma fácil de usar. Ele fornece opções para criar índices sobre os conjuntos de dados, consultá-los e até mesmo nos permitir treinar um modelo ColBERT em nossos dados.
- LangChain: Esta biblioteca nos permitirá trabalhar com modelos de incorporação de código aberto para que possamos testar quão bem os outros modelos de incorporação funcionam quando comparados ao ColBERT.
- langchain_openai: Instala o LangChain dependências para OpenAI. Trabalharemos até com o modelo OpenAI Embedding para verificar seu desempenho em relação ao ColBERT.
- CromaDB: Esta biblioteca nos permitirá criar um armazenamento de vetores em nosso ambiente para que possamos salvar os embeddings que criamos em nossos dados e posteriormente realizar uma pesquisa semântica entre a consulta e os embeddings armazenados.
- einops: Esta biblioteca é necessária para multiplicações eficientes de matrizes tensores.
- transformadores de frases e os votos de tiktok biblioteca são necessárias para que os modelos de incorporação de código aberto funcionem corretamente.
Etapa 2: Baixe o modelo pré-treinado
Na próxima etapa, faremos o download do modelo ColBERT pré-treinado. Para isso, o código será
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Primeiro importamos a classe RAGPretrainedModel da biblioteca RAGatouille.
- Em seguida, chamamos .from_pretrained() e damos o nome do modelo, ou seja, “colbert-ir/colbertv2.0”.
A execução do código acima instanciará um modelo ColBERT RAG. Agora vamos baixar uma página da Wikipédia e realizar a recuperação dela. Para isso o código será:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])O RAGatouille vem com uma função útil chamada get_wikipedia_page que pega uma string e obtém a página correspondente da Wikipedia. Aqui baixamos o conteúdo da Wikipedia sobre Elon Musk e o armazenamos no documento variável. Vamos imprimir a quantidade de palavras presentes no documento e as primeiras linhas do documento.
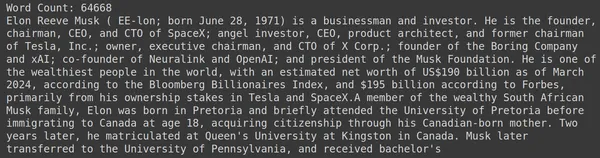
Aqui podemos ver a saída na foto. Podemos ver que há um total de 64,668 palavras na página da Wikipedia de Elon Musk.
Etapa 3: Indexação
Agora criaremos um índice neste documento.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Aqui chamamos .index() do RAG para indexar nosso documento. Para isso, passamos o seguinte:
- coleção: Esta é uma lista de documentos que queremos indexar. Aqui temos apenas um documento, portanto, uma lista de um único documento.
- document_ids: Cada documento espera um ID de documento exclusivo. Aqui passamos o nome elon_musk porque o documento é sobre Elon Musk.
- document_metadados: Cada documento possui seus metadados. Novamente, esta é uma lista de dicionários, onde cada dicionário contém metadados de um par de valores-chave para um documento específico.
- nome_índice: O nome do índice que estamos criando. Vamos chamá-lo de Elon2.
- tamanho máximo do documento: Isso é semelhante ao tamanho do pedaço. Especificamos quanto deve custar cada pedaço de documento. Aqui estamos atribuindo um valor de 256. Se não especificarmos nenhum valor, 256 será considerado o tamanho padrão do bloco.
- documentos_divididos: É um valor booleano, onde True indica que queremos dividir nosso documento de acordo com o tamanho do pedaço fornecido e False indica que queremos armazenar o documento inteiro como um único pedaço.
A execução do código acima dividirá nosso documento em tamanhos de 256 por bloco e, em seguida, incorporará-os por meio do modelo ColBERT, que produzirá uma lista de embeddings de vetores em nível de token para cada bloco e, finalmente, os armazenará em um índice. Esta etapa levará um pouco de tempo para ser executada e pode ser acelerada se você tiver uma GPU. Finalmente, ele cria um diretório onde nosso índice está armazenado. Aqui o diretório será “.ragatouille/colbert/indexes/Elon2”
Etapa 4: consulta geral
Agora, começaremos a busca. Para isso, o código será
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Aqui, primeiro, chamamos o método .search() do objeto RAG
- Para isso, damos as variáveis que incluem o nome da consulta, k (número de documentos a serem recuperados) e o nome do índice a ser pesquisado
- Aqui fornecemos a consulta “Quais empresas Elon Musk encontrou?”. O resultado obtido estará em uma lista em formato de dicionário, que contém as chaves como conteúdo, pontuação, classificação, document_id, passage_id e document_metadata
- Portanto, trabalhamos com o código abaixo para imprimir os documentos recuperados de maneira organizada
- Aqui percorremos a lista de dicionários e imprimimos o conteúdo dos documentos
A execução do código produzirá os seguintes resultados:
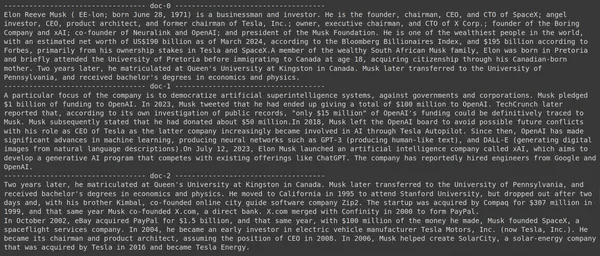
Na foto podemos ver que o primeiro e o último documento abrangem integralmente as diferentes empresas fundadas por Elon Musk. O ColBERT conseguiu recuperar corretamente os pedaços relevantes necessários para responder à consulta.
Etapa 5: consulta específica
Agora vamos dar um passo adiante e fazer uma pergunta específica.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])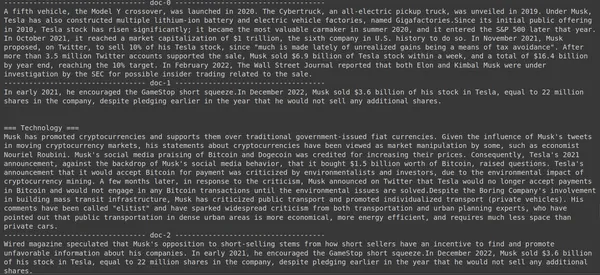
Aqui no código acima, estamos fazendo uma pergunta muito específica sobre quantas ações da Tesla Elon foram vendidas no mês de dezembro de 2022. Podemos ver o resultado aqui. O doc-1 contém a resposta à pergunta. Elon vendeu US$ 3.6 bilhões em ações da Tesla. Novamente, ColBERT conseguiu recuperar com sucesso o pedaço relevante para a consulta fornecida.
Etapa 6: Testando Outros Modelos
Vamos agora tentar a mesma pergunta com os outros modelos de incorporação, tanto de código aberto quanto fechados, aqui:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Começamos baixando o modelo primeiro por meio da classe AutoModel da biblioteca Transformers.
- Em seguida, armazenamos model_name e model_kwargs em suas respectivas variáveis.
- Agora para trabalhar com este modelo no LangChain, importamos o HuggingFaceEmbeddings do LangChain e forneça o nome do modelo e model_kwargs.
A execução deste código fará o download e carregará o modelo de incorporação Jina para que possamos trabalhar com ele
Etapa 7: criar incorporações
Agora, precisamos começar a dividir nosso documento e então criar embeddings a partir dele e armazená-los no armazenamento de vetores Chroma. Para isso, trabalhamos com o seguinte código:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- Começamos importando o Chroma e o RecursiveCharacterTextSplitter da biblioteca LangChain
- Em seguida, instanciamos um text_splitter chamando o .from_tiktoken_encoder do RecursiveCharacterTextSplitter e passando para ele chunk_size e chunk_overlap
- Aqui usaremos o mesmo chunk_size que fornecemos ao ColBERT
- Em seguida, chamamos o método .split_text() deste text_splitter e fornecemos a ele o documento que contém informações da Wikipedia sobre Elon Musk. Em seguida, ele divide o documento com base no tamanho do bloco fornecido e, finalmente, a lista de fragmentos do documento é armazenada na variável splits
- Finalmente, chamamos a função .from_texts() da classe Chroma para criar um armazenamento de vetores. Para esta função, fornecemos as divisões, o modelo de incorporação e o nome_da_coleção
- Agora, criamos um recuperador chamando a função .as_retriever() do objeto de armazenamento de vetor. Damos 3 para o valor k
A execução deste código pegará nosso documento, dividirá-o em documentos menores de tamanho 256 por pedaço e, em seguida, incorporará esses pedaços menores ao modelo de incorporação Jina e armazenará esses vetores de incorporação no armazenamento de vetores de croma.
Etapa 8: Criando um Retriever
Finalmente, criamos um recuperador a partir dele. Agora faremos uma pesquisa vetorial e verificaremos os resultados.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)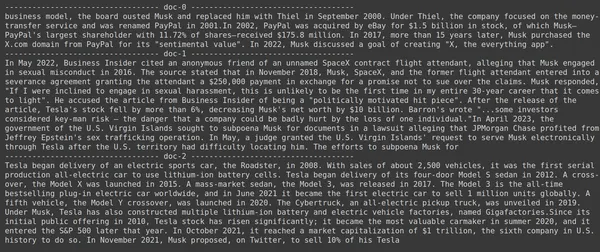
- Chamamos a função .get_relevent_documents() do objeto recuperador e fazemos a mesma consulta.
- Em seguida, imprimimos ordenadamente os 3 principais documentos recuperados.
- Na foto podemos ver que o Jina Embedder apesar de ser um modelo de incorporação popular, a recuperação para nossa consulta é ruim. Não foi possível obter os blocos de documentos corretos.
Podemos identificar claramente a diferença entre o Jina, o modelo de incorporação que representa cada pedaço como uma incorporação de vetor único, e o modelo ColBERT que representa cada pedaço como uma lista de vetores de incorporação em nível de token. O ColBERT tem um desempenho claramente superior neste caso.
Etapa 9: Testando o modelo de incorporação do OpenAI
Agora vamos tentar usar um modelo de incorporação de código fechado como o modelo OpenAI Embedding.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Aqui o código é muito semelhante ao que acabamos de escrever
- A única diferença é que passamos a chave da API OpenAI para definir a variável de ambiente.
- Em seguida, criamos uma instância do modelo OpenAI Embedding importando-o do LangChain.
- E ao criar o nome da coleção, damos um nome de coleção diferente, para que os embeddings do modelo OpenAI Embedding sejam armazenados em uma coleção diferente.
A execução deste código irá novamente pegar nossos documentos, dividi-los em documentos menores de tamanho 256 e, em seguida, incorporá-los em uma representação de incorporação de vetor único com o modelo de incorporação OpenAI e, finalmente, armazenar esses embeddings no Chroma Vector Store. Agora vamos tentar recuperar os documentos relevantes para a outra questão.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)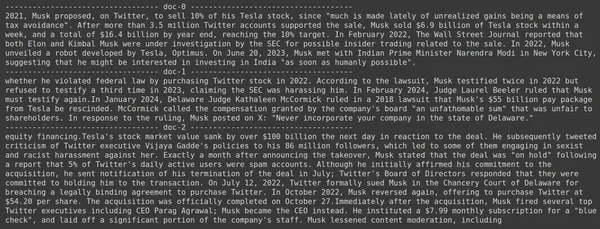
- Vemos que a resposta que esperamos não foi encontrada nos blocos recuperados.
- O primeiro contém informações sobre as ações da Tesla em 2022, mas não fala sobre a venda delas por Elon.
- O mesmo pode ser visto com os dois blocos de documentos restantes, onde a informação que contêm é sobre a Tesla e as suas ações, mas esta não é a informação que esperamos.
- Os pedaços recuperados acima não fornecerão o contexto para o LLM responder à consulta que fornecemos.
Mesmo aqui podemos ver uma diferença clara entre a representação de incorporação de vetor único e a representação de incorporação de vários vetores. As representações de incorporação múltipla capturam claramente as consultas complexas, o que resulta em recuperações mais precisas.
Conclusão
Concluindo, ColBERT demonstra um avanço significativo no desempenho de recuperação em relação aos modelos tradicionais de bi-codificador, representando o texto como incorporações multivetoriais no nível do token. Esta abordagem permite uma compreensão contextual mais matizada entre consultas e documentos, levando a resultados de recuperação mais precisos e atenuando o problema de alucinações comumente observadas em LLMs.
Principais lições
- O RAG aborda o problema das alucinações nos LLMs, fornecendo informações contextuais para geração de respostas factuais.
- Os bi-codificadores tradicionais sofrem com um gargalo de informações devido à compactação de textos inteiros em incorporações de vetor único, resultando em uma precisão de recuperação abaixo da média.
- ColBERT, com sua representação de incorporação em nível de token, facilita uma melhor compreensão contextual entre consultas e documentos, levando a um melhor desempenho de recuperação.
- A etapa de interação tardia no ColBERT, combinada com interações em nível de token, aumenta a precisão da recuperação ao considerar nuances contextuais.
- ColBERTv2 otimiza o espaço de armazenamento por meio de compactação residual, mantendo a eficácia da recuperação.
- Experimentos práticos demonstram a superioridade do ColBERT no desempenho de recuperação em comparação com modelos de incorporação tradicionais e de código aberto, como Jina e OpenAI Embedding.
Perguntas Frequentes
A. Os bi-codificadores tradicionais compactam textos inteiros em incorporações de vetor único, potencialmente perdendo informações contextuais. Isto limita a sua eficácia em tarefas de recuperação, especialmente com consultas ou documentos complexos.
A. ColBERT (Contextual Late Interactions BERT) é um modelo bi-codificador que representa texto usando incorporações de vetor em nível de token. Ele permite uma compreensão contextual mais sutil entre consultas e documentos, melhorando a precisão da recuperação.
R. ColBERT gera incorporações em nível de token para consultas e documentos, realiza multiplicação de matrizes para calcular pontuações de similaridade e, em seguida, seleciona as informações mais relevantes com base na similaridade máxima entre tokens. Isso permite uma recuperação eficaz com compreensão contextual.
R. O ColBERTv2 otimiza o espaço por meio do método de compactação residual, reduzindo os requisitos de armazenamento para incorporações em nível de token e, ao mesmo tempo, mantendo a precisão da recuperação.
R. Você pode usar bibliotecas como RAGatouille para trabalhar facilmente com ColBERT. Ao indexar documentos e consultas, você pode realizar tarefas de recuperação eficientes e gerar respostas precisas e alinhadas ao contexto.
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do Autor.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

