Esta postagem foi co-escrita com Chaoyang He, Al Nevarez e Salman Avestimehr do FedML.
Muitas organizações estão implementando aprendizado de máquina (ML) para aprimorar a tomada de decisões de negócios por meio da automação e do uso de grandes conjuntos de dados distribuídos. Com maior acesso aos dados, o ML tem o potencial de fornecer insights e oportunidades de negócios incomparáveis. No entanto, a partilha de informações confidenciais brutas e não higienizadas em diferentes locais representa riscos significativos de segurança e privacidade, especialmente em setores regulamentados, como o da saúde.
Para resolver esse problema, a aprendizagem federada (FL) é uma técnica de treinamento de ML descentralizada e colaborativa que oferece privacidade de dados, mantendo a precisão e a fidelidade. Ao contrário do treinamento tradicional de ML, o treinamento de FL ocorre em um local isolado do cliente, usando uma sessão segura independente. O cliente compartilha apenas os parâmetros do modelo de saída com um servidor centralizado, conhecido como coordenador de treinamento ou servidor de agregação, e não os dados reais usados para treinar o modelo. Essa abordagem alivia muitas preocupações com a privacidade dos dados, ao mesmo tempo que permite uma colaboração eficaz no treinamento do modelo.
Embora a FL seja um passo para alcançar melhor privacidade e segurança dos dados, não é uma solução garantida. Redes inseguras sem controle de acesso e criptografia ainda podem expor informações confidenciais aos invasores. Além disso, informações treinadas localmente podem expor dados privados se reconstruídas por meio de um ataque de inferência. Para mitigar esses riscos, o modelo FL utiliza algoritmos de treinamento personalizados e mascaramento e parametrização eficazes antes de compartilhar informações com o coordenador de treinamento. Fortes controles de rede em locais locais e centralizados podem reduzir ainda mais os riscos de inferência e exfiltração.
Neste post, compartilhamos uma abordagem FL usando FedML, Serviço Amazon Elastic Kubernetes (Amazon EKS) e Amazon Sage Maker para melhorar os resultados dos pacientes e, ao mesmo tempo, abordar questões de privacidade e segurança de dados.
A necessidade de aprendizagem federada em saúde
A saúde depende fortemente de fontes de dados distribuídas para fazer previsões e avaliações precisas sobre o atendimento ao paciente. Limitar as fontes de dados disponíveis para proteger a privacidade afeta negativamente a precisão dos resultados e, em última análise, a qualidade do atendimento ao paciente. Portanto, o ML cria desafios para os clientes da AWS que precisam garantir privacidade e segurança em entidades distribuídas sem comprometer os resultados dos pacientes.
As organizações de saúde devem navegar por regulamentações de conformidade rigorosas, como a Lei de Portabilidade e Responsabilidade de Seguros de Saúde (HIPAA) nos Estados Unidos, ao implementar soluções FL. Garantir a privacidade, segurança e conformidade dos dados torna-se ainda mais crítico na área da saúde, exigindo criptografia robusta, controles de acesso, mecanismos de auditoria e protocolos de comunicação seguros. Além disso, os conjuntos de dados de saúde geralmente contêm tipos de dados complexos e heterogêneos, tornando a padronização e a interoperabilidade dos dados um desafio em ambientes de FL.
Visão geral do caso de uso
O caso de uso descrito nesta postagem é de dados de doenças cardíacas em diferentes organizações, nas quais um modelo de ML executará algoritmos de classificação para prever doenças cardíacas no paciente. Como esses dados estão presentes em todas as organizações, usamos o aprendizado federado para agrupar as descobertas.
A Conjunto de dados de doenças cardíacas do Repositório de Aprendizado de Máquina da Universidade da Califórnia em Irvine é um conjunto de dados amplamente utilizado para pesquisas cardiovasculares e modelagem preditiva. É composto por 303 amostras, cada uma representando um paciente, e contém uma combinação de atributos clínicos e demográficos, bem como a presença ou ausência de doença cardíaca.
Este conjunto de dados multivariado possui 76 atributos nas informações do paciente, dos quais 14 atributos são mais comumente usados para desenvolver e avaliar algoritmos de ML para prever a presença de doenças cardíacas com base nos atributos fornecidos.
Estrutura FedML
Há uma grande variedade de estruturas de FL, mas decidimos usar a Estrutura FedML para este caso de uso porque é de código aberto e suporta vários paradigmas de FL. FedML fornece uma biblioteca popular de código aberto, plataforma MLOps e ecossistema de aplicativos para FL. Estes facilitam o desenvolvimento e a implantação de soluções de FL. Ele fornece um conjunto abrangente de ferramentas, bibliotecas e algoritmos que permitem que pesquisadores e profissionais implementem e experimentem algoritmos de FL em um ambiente distribuído. O FedML aborda os desafios de privacidade de dados, comunicação e agregação de modelos em FL, oferecendo uma interface amigável e componentes personalizáveis. Com o seu foco na colaboração e partilha de conhecimento, a FedML pretende acelerar a adoção da FL e impulsionar a inovação neste campo emergente. A estrutura FedML é independente de modelo, incluindo suporte recentemente adicionado para grandes modelos de linguagem (LLMs). Para obter mais informações, consulte Liberando FedLLM: construa seus próprios modelos de linguagem em dados proprietários usando a plataforma FedML.
Polvo FedML
A hierarquia e a heterogeneidade do sistema são um desafio importante em casos de uso de FL da vida real, onde diferentes silos de dados podem ter infraestruturas diferentes com CPU e GPUs. Nesses cenários, você pode usar Polvo FedML.
FedML Octopus é a plataforma de nível industrial de FL entre silos para treinamento entre organizações e contas. Juntamente com o FedML MLOps, ele permite que desenvolvedores ou organizações conduzam colaboração aberta de qualquer lugar e em qualquer escala, de maneira segura. O FedML Octopus executa um paradigma de treinamento distribuído dentro de cada silo de dados e usa treinamentos síncronos ou assíncronos.
MLOps FedML
FedML MLOps permite o desenvolvimento local de código que pode posteriormente ser implantado em qualquer lugar usando estruturas FedML. Antes de iniciar o treinamento, você deve criar uma conta FedML, bem como criar e fazer upload dos pacotes de servidor e cliente no FedML Octopus. Para mais detalhes, consulte passos e Apresentando o FedML Octopus: escalando o aprendizado federado para a produção com MLOps simplificados.
Visão geral da solução
Implementamos o FedML em vários clusters EKS integrados ao SageMaker para rastreamento de experimentos. Nós usamos Esquemas Amazon EKS para Terraform para implantar a infraestrutura necessária. O EKS Blueprints ajuda a compor clusters EKS completos que são totalmente inicializados com o software operacional necessário para implantar e operar cargas de trabalho. Com EKS Blueprints, a configuração para o estado desejado do ambiente EKS, como o plano de controle, nós de trabalho e complementos do Kubernetes, é descrita como um blueprint de infraestrutura como código (IaC). Depois que um blueprint é configurado, ele pode ser usado para criar ambientes consistentes em várias contas e regiões da AWS usando automação de implantação contínua.
O conteúdo compartilhado nesta postagem reflete situações e experiências da vida real, mas é importante observar que a implantação dessas situações em diferentes locais pode variar. Embora utilizemos uma única conta da AWS com VPCs separadas, é crucial compreender que as circunstâncias e configurações individuais podem ser diferentes. Portanto, as informações fornecidas devem ser utilizadas como um guia geral e podem exigir adaptações com base em requisitos específicos e condições locais.
O diagrama a seguir ilustra nossa arquitetura de solução.
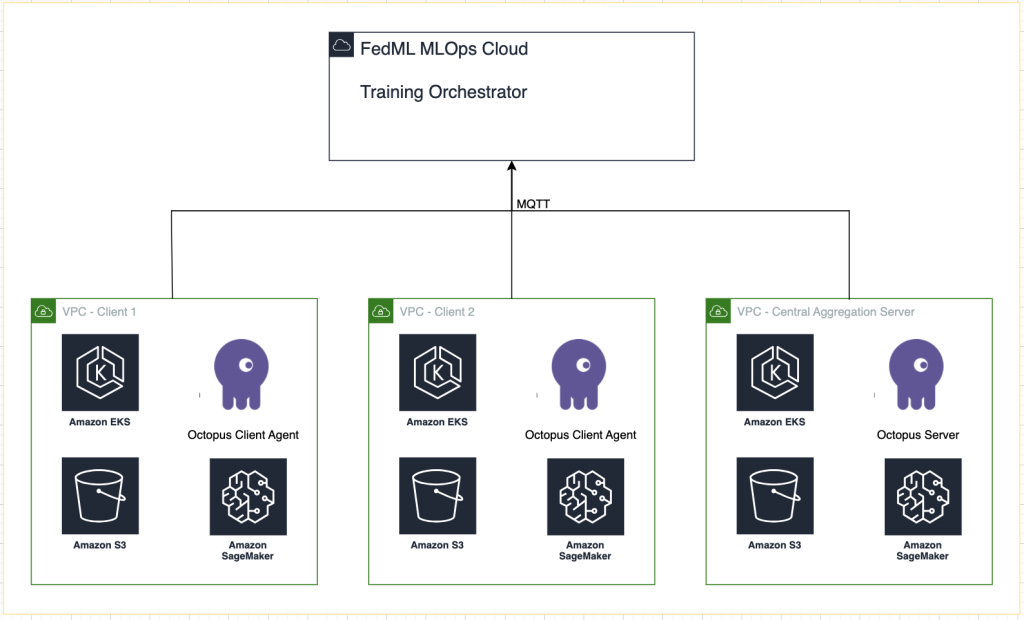
Além do rastreamento fornecido pelo FedML MLOps para cada execução de treinamento, usamos Experimentos Amazon SageMaker para acompanhar o desempenho de cada modelo de cliente e do modelo centralizado (agregador).
SageMaker Experiments é um recurso do SageMaker que permite criar, gerenciar, analisar e comparar seus experimentos de ML. Ao registrar detalhes, parâmetros e resultados do experimento, os pesquisadores podem reproduzir e validar com precisão seu trabalho. Permite a comparação e análise eficazes de diferentes abordagens, levando a uma tomada de decisão informada. Além disso, o rastreamento de experimentos facilita a melhoria iterativa, fornecendo insights sobre a progressão dos modelos e permitindo que os pesquisadores aprendam com as iterações anteriores, acelerando, em última análise, o desenvolvimento de soluções mais eficazes.
Enviamos o seguinte para o SageMaker Experiments para cada execução:
- Métricas de avaliação do modelo – Perda de treinamento e área sob a curva (AUC)
- Hiperparâmetros – Época, taxa de aprendizagem, tamanho do lote, otimizador e redução de peso
Pré-requisitos
Para acompanhar este post, você deve ter os seguintes pré-requisitos:
Implante a solução
Para começar, clone o repositório que hospeda o código de exemplo localmente:
Em seguida, implemente a infraestrutura do caso de uso usando os seguintes comandos:
O modelo Terraform pode levar de 20 a 30 minutos para ser totalmente implantado. Após a implantação, siga as etapas nas próximas seções para executar o aplicativo FL.
Crie um pacote de implantação MLOps
Como parte da documentação do FedML, precisamos criar os pacotes de cliente e servidor, que a plataforma MLOps distribuirá ao servidor e aos clientes para iniciar o treinamento.
Para criar esses pacotes, execute o seguinte script encontrado no diretório raiz:
Isso criará os respectivos pacotes no seguinte diretório raiz do projeto:
Carregue os pacotes para a plataforma FedML MLOps
Conclua as etapas a seguir para fazer upload dos pacotes:
- Na interface do FedML, escolha As minhas aplicações no painel de navegação.
- Escolha Nova aplicação.
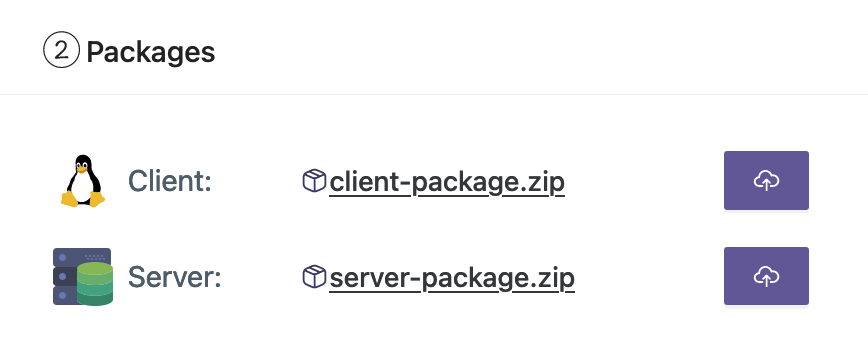
- Faça upload dos pacotes de cliente e servidor de sua estação de trabalho.
- Você também pode ajustar os hiperparâmetros ou criar novos.

Acionar treinamento federado
Para executar o treinamento federado, conclua as etapas a seguir:
- Na interface do FedML, escolha Lista de projetos no painel de navegação.
- Escolha Crie um novo projeto.
- Insira um nome de grupo e um nome de projeto e escolha OK.

- Escolha o projeto recém-criado e escolha Criar nova corrida para acionar uma corrida de treinamento.
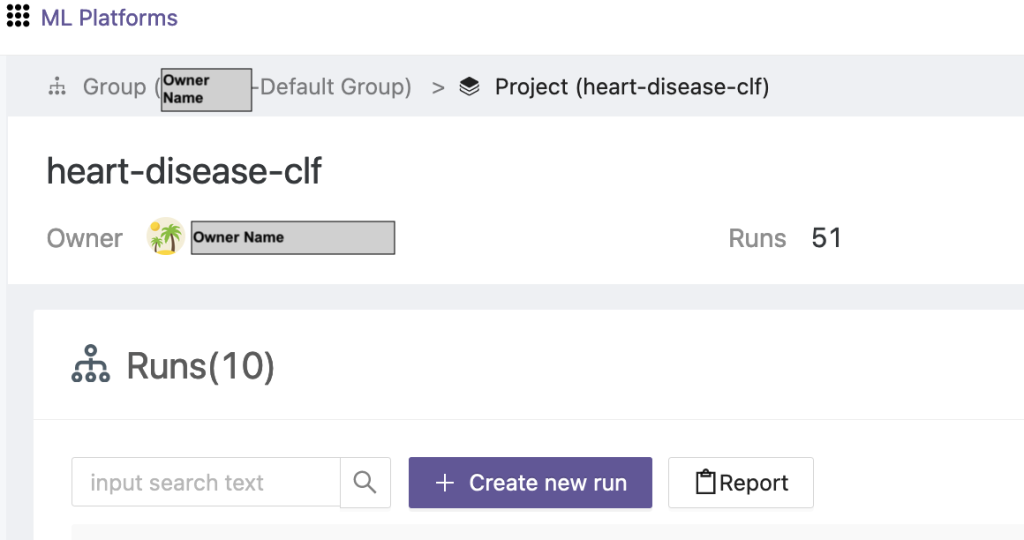
- Selecione os dispositivos do cliente de borda e o servidor agregador central para esta execução de treinamento.
- Escolha o aplicativo que você criou nas etapas anteriores.

- Atualize qualquer um dos hiperparâmetros ou use as configurações padrão.
- Escolha Início para começar a treinar.

- Escolha o estado de treinamento e aguarde a conclusão da execução do treinamento. Você também pode navegar até as guias disponíveis.
- Quando o treinamento estiver concluído, escolha o System para ver as durações do tempo de treinamento em seus servidores de borda e eventos de agregação.
Ver resultados e detalhes do experimento
Quando o treinamento for concluído, você poderá visualizar os resultados usando FedML e SageMaker.
Na interface do FedML, na página Modelos guia, você pode ver o agregador e o modelo do cliente. Você também pode baixar esses modelos no site.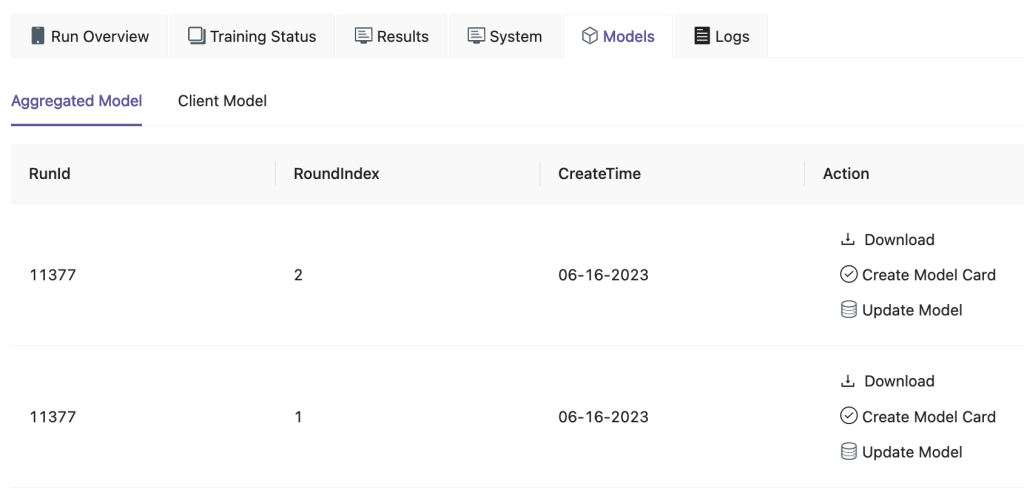
Você também pode fazer login em Estúdio Amazon SageMaker e escolha Experimentos no painel de navegação.
A captura de tela a seguir mostra os experimentos registrados.
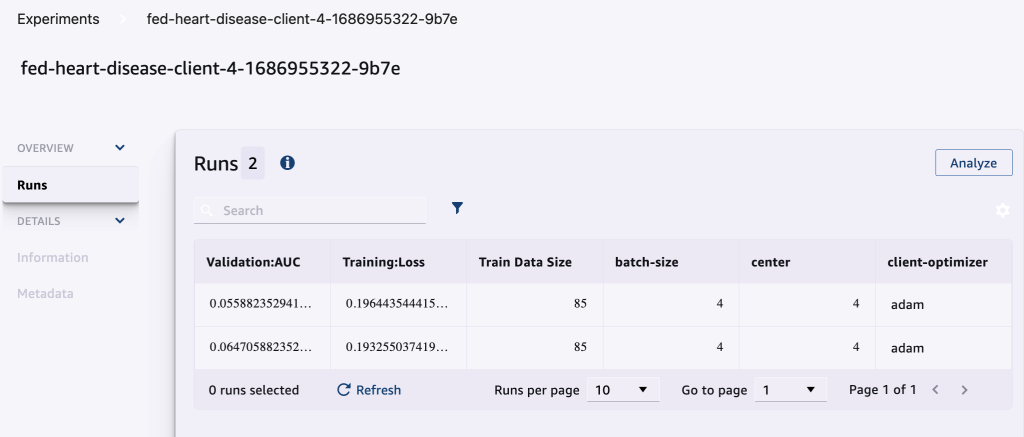
Código de acompanhamento da experiência
Nesta seção, exploramos o código que integra o rastreamento de experimentos do SageMaker com o treinamento da estrutura FL.
Em um editor de sua escolha, abra a seguinte pasta para ver as edições no código para injetar o código de rastreamento de experimentos do SageMaker como parte do treinamento:
Para acompanhar o treinamento, nós crie um experimento SageMaker com parâmetros e métricas registrados usando o log_parameter e log_metric comando conforme descrito no exemplo de código a seguir.
Uma entrada no config/fedml_config.yaml file declara o prefixo do experimento, que é referenciado no código para criar nomes exclusivos de experimentos: sm_experiment_name: "fed-heart-disease". Você pode atualizar isso para qualquer valor de sua escolha.
Por exemplo, consulte o código a seguir para o heart_disease_trainer.py, que é usado por cada cliente para treinar o modelo em seu próprio conjunto de dados:
Para cada execução do cliente, os detalhes do experimento são rastreados usando o seguinte código em heart_disease_trainer.py:
Da mesma forma, você pode usar o código em heart_disease_aggregator.py para executar um teste nos dados locais após atualizar os pesos do modelo. Os detalhes são registrados após cada comunicação executada com os clientes.
limpar
Quando terminar a solução, certifique-se de limpar os recursos usados para garantir a utilização eficiente dos recursos e o gerenciamento de custos, além de evitar despesas desnecessárias e desperdício de recursos. A organização ativa do ambiente, como a exclusão de instâncias não utilizadas, a interrupção de serviços desnecessários e a remoção de dados temporários, contribui para uma infraestrutura limpa e organizada. Você pode usar o seguinte código para limpar seus recursos:
Resumo
Ao usar o Amazon EKS como infraestrutura e o FedML como estrutura para FL, podemos fornecer um ambiente escalável e gerenciado para treinamento e implantação de modelos compartilhados, respeitando a privacidade dos dados. Com a natureza descentralizada da FL, as organizações podem colaborar de forma segura, desbloquear o potencial dos dados distribuídos e melhorar os modelos de ML sem comprometer a privacidade dos dados.
Como sempre, a AWS agradece seus comentários. Por favor, deixe suas idéias e perguntas na seção de comentários.
Sobre os autores
 Randy De Fauw é arquiteto de soluções principal sênior na AWS. Ele possui um MSEE pela Universidade de Michigan, onde trabalhou em visão computacional para veículos autônomos. Ele também possui MBA pela Colorado State University. Randy ocupou diversos cargos na área de tecnologia, desde engenharia de software até gerenciamento de produtos. Ele entrou no espaço de big data em 2013 e continua a explorar essa área. Ele está trabalhando ativamente em projetos na área de ML e fez apresentações em diversas conferências, incluindo Strata e GlueCon.
Randy De Fauw é arquiteto de soluções principal sênior na AWS. Ele possui um MSEE pela Universidade de Michigan, onde trabalhou em visão computacional para veículos autônomos. Ele também possui MBA pela Colorado State University. Randy ocupou diversos cargos na área de tecnologia, desde engenharia de software até gerenciamento de produtos. Ele entrou no espaço de big data em 2013 e continua a explorar essa área. Ele está trabalhando ativamente em projetos na área de ML e fez apresentações em diversas conferências, incluindo Strata e GlueCon.
 Arnab Sinha é arquiteto de soluções sênior da AWS, atuando como CTO de campo para ajudar as organizações a projetar e construir soluções escaláveis que apoiam resultados de negócios em migrações de data centers, transformação digital e modernização de aplicativos, big data e aprendizado de máquina. Ele apoiou clientes em diversos setores, incluindo energia, varejo, manufatura, saúde e ciências biológicas. Arnab possui todas as certificações AWS, incluindo a certificação de especialidade ML. Antes de ingressar na AWS, Arnab era líder de tecnologia e anteriormente ocupou cargos de liderança em arquitetura e engenharia.
Arnab Sinha é arquiteto de soluções sênior da AWS, atuando como CTO de campo para ajudar as organizações a projetar e construir soluções escaláveis que apoiam resultados de negócios em migrações de data centers, transformação digital e modernização de aplicativos, big data e aprendizado de máquina. Ele apoiou clientes em diversos setores, incluindo energia, varejo, manufatura, saúde e ciências biológicas. Arnab possui todas as certificações AWS, incluindo a certificação de especialidade ML. Antes de ingressar na AWS, Arnab era líder de tecnologia e anteriormente ocupou cargos de liderança em arquitetura e engenharia.
 Prachi Kulkarni é arquiteto de soluções sênior na AWS. Sua especialização é aprendizado de máquina e ela está trabalhando ativamente no design de soluções usando várias ofertas de AWS ML, big data e análises. Prachi tem experiência em vários domínios, incluindo saúde, benefícios, varejo e educação, e trabalhou em diversos cargos em engenharia e arquitetura de produtos, gerenciamento e sucesso de clientes.
Prachi Kulkarni é arquiteto de soluções sênior na AWS. Sua especialização é aprendizado de máquina e ela está trabalhando ativamente no design de soluções usando várias ofertas de AWS ML, big data e análises. Prachi tem experiência em vários domínios, incluindo saúde, benefícios, varejo e educação, e trabalhou em diversos cargos em engenharia e arquitetura de produtos, gerenciamento e sucesso de clientes.
 Domador Xerife é arquiteto de soluções principal na AWS, com experiência diversificada na área de tecnologia e serviços de consultoria empresarial, abrangendo mais de 17 anos como arquiteto de soluções. Com foco em infraestrutura, a experiência da Tamer abrange um amplo espectro de setores verticais da indústria, incluindo comercial, saúde, automotivo, setor público, manufatura, petróleo e gás, serviços de mídia e muito mais. Sua proficiência se estende a vários domínios, como arquitetura em nuvem, computação de ponta, redes, armazenamento, virtualização, produtividade empresarial e liderança técnica.
Domador Xerife é arquiteto de soluções principal na AWS, com experiência diversificada na área de tecnologia e serviços de consultoria empresarial, abrangendo mais de 17 anos como arquiteto de soluções. Com foco em infraestrutura, a experiência da Tamer abrange um amplo espectro de setores verticais da indústria, incluindo comercial, saúde, automotivo, setor público, manufatura, petróleo e gás, serviços de mídia e muito mais. Sua proficiência se estende a vários domínios, como arquitetura em nuvem, computação de ponta, redes, armazenamento, virtualização, produtividade empresarial e liderança técnica.
 Hans Nesbitt é arquiteto de soluções sênior na AWS e mora no sul da Califórnia. Ele trabalha com clientes em todo o oeste dos EUA para criar arquiteturas de nuvem altamente escaláveis, flexíveis e resilientes. Nas horas vagas, gosta de ficar com a família, cozinhar e tocar violão.
Hans Nesbitt é arquiteto de soluções sênior na AWS e mora no sul da Califórnia. Ele trabalha com clientes em todo o oeste dos EUA para criar arquiteturas de nuvem altamente escaláveis, flexíveis e resilientes. Nas horas vagas, gosta de ficar com a família, cozinhar e tocar violão.
 Chaoyang Ele é cofundador e CTO da FedML, Inc., uma startup que trabalha para uma comunidade que constrói IA aberta e colaborativa em qualquer lugar e em qualquer escala. Sua pesquisa se concentra em algoritmos, sistemas e aplicativos de aprendizado de máquina distribuídos e federados. Ele recebeu seu PhD em Ciência da Computação pela University of Southern California.
Chaoyang Ele é cofundador e CTO da FedML, Inc., uma startup que trabalha para uma comunidade que constrói IA aberta e colaborativa em qualquer lugar e em qualquer escala. Sua pesquisa se concentra em algoritmos, sistemas e aplicativos de aprendizado de máquina distribuídos e federados. Ele recebeu seu PhD em Ciência da Computação pela University of Southern California.
 Al Nevarez é Diretor de Gestão de Produtos da FedML. Antes da FedML, ele foi gerente de produto de grupo no Google e gerente sênior de ciência de dados no LinkedIn. Ele possui diversas patentes relacionadas a produtos de dados e estudou engenharia na Universidade de Stanford.
Al Nevarez é Diretor de Gestão de Produtos da FedML. Antes da FedML, ele foi gerente de produto de grupo no Google e gerente sênior de ciência de dados no LinkedIn. Ele possui diversas patentes relacionadas a produtos de dados e estudou engenharia na Universidade de Stanford.
 Salman Avestimehr é cofundador e CEO da FedML. Ele foi professor reitor da USC, diretor do USC-Amazon Center on Trustworthy AI e Amazon Scholar em Alexa AI. Ele é especialista em aprendizado de máquina federado e descentralizado, teoria da informação, segurança e privacidade. Ele é Fellow do IEEE e recebeu seu PhD em EECS pela UC Berkeley.
Salman Avestimehr é cofundador e CEO da FedML. Ele foi professor reitor da USC, diretor do USC-Amazon Center on Trustworthy AI e Amazon Scholar em Alexa AI. Ele é especialista em aprendizado de máquina federado e descentralizado, teoria da informação, segurança e privacidade. Ele é Fellow do IEEE e recebeu seu PhD em EECS pela UC Berkeley.
 Samir Rapaz é um tecnólogo empresarial talentoso da AWS que trabalha em estreita colaboração com executivos de nível C dos clientes. Como ex-executivo C-suite que impulsionou transformações em diversas empresas da Fortune 100, Samir compartilha suas experiências inestimáveis para ajudar seus clientes a terem sucesso em sua própria jornada de transformação.
Samir Rapaz é um tecnólogo empresarial talentoso da AWS que trabalha em estreita colaboração com executivos de nível C dos clientes. Como ex-executivo C-suite que impulsionou transformações em diversas empresas da Fortune 100, Samir compartilha suas experiências inestimáveis para ajudar seus clientes a terem sucesso em sua própria jornada de transformação.
 Stephen Kraemer é consultor de conselho e CxO e ex-executivo da AWS. Stephen defende a cultura e a liderança como alicerces do sucesso. Ele afirma que a segurança e a inovação são os impulsionadores da transformação da nuvem, permitindo organizações altamente competitivas e orientadas por dados.
Stephen Kraemer é consultor de conselho e CxO e ex-executivo da AWS. Stephen defende a cultura e a liderança como alicerces do sucesso. Ele afirma que a segurança e a inovação são os impulsionadores da transformação da nuvem, permitindo organizações altamente competitivas e orientadas por dados.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/federated-learning-on-aws-using-fedml-amazon-eks-and-amazon-sagemaker/

