2023 foi um ano agitado para Serviço Amazon OpenSearch! Saiba mais sobre os lançamentos que o OpenSearch Service lançou no primeiro semestre de 2023.
No segundo semestre de 2023, o OpenSearch Service adicionou o suporte de dois novos Opensearch versões: 2.9 e 2.11 Essas duas versões introduzem novos recursos no espaço de busca, espaço de busca de aprendizado de máquina (ML), migrações e no lado operacional do serviço.
Com o lançamento da integração zero-ETL com Serviço de armazenamento simples da Amazon (Amazon S3), você pode analisar seus dados armazenados em seu data lake usando o OpenSearch Service para criar painéis e consultar os dados sem a necessidade de movê-los do Amazon S3.
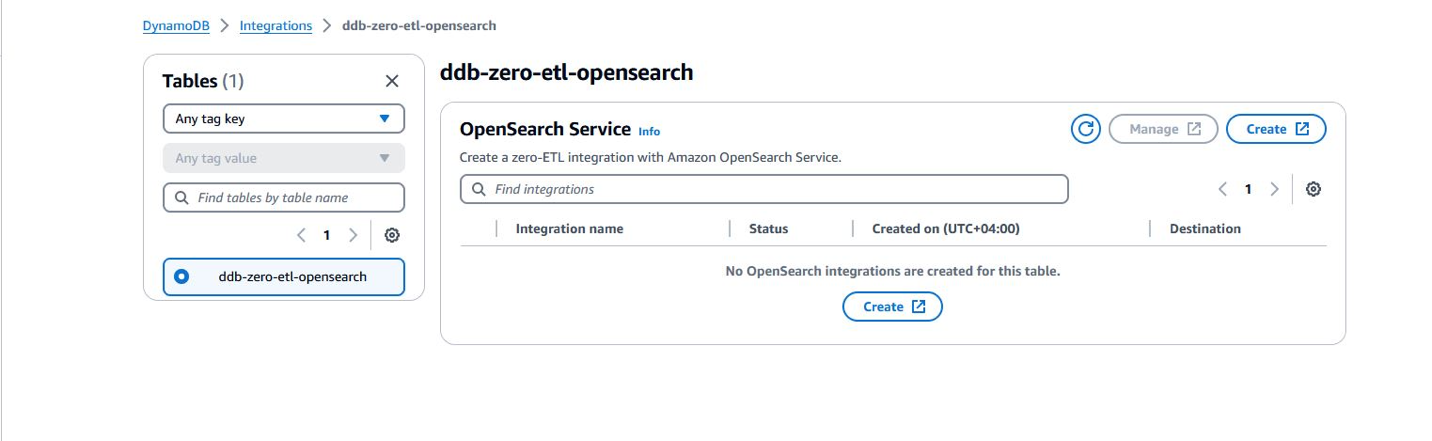
O OpenSearch Service também anunciou uma nova integração zero-ETL com Amazon DynamoDB através do plugin DynamoDB para Ingestão do Amazon OpenSearch. O OpenSearch Ingestion cuida da inicialização e transmite continuamente os dados da sua origem do DynamoDB.
OpenSearch Serverless anunciou a disponibilidade geral do Mecanismo vetorial para Amazon OpenSearch Serverless junto com outros recursos para aprimorar sua experiência com coleções de séries temporais, gerenciar seus custos para ambientes de desenvolvimento e dimensionar rapidamente seus recursos para atender às demandas de sua carga de trabalho.
Nesta postagem, discutimos os novos lançamentos do OpenSearch Service para capacitar seus negócios com pesquisa, observabilidade, análise de segurança e migrações.
Crie soluções econômicas com o OpenSearch Service
Com a integração ETL zero para Amazon S3, o OpenSearch Service agora permite consultar seus dados no local, economizando custos de armazenamento. A movimentação de dados é uma operação cara porque você precisa replicar dados em diferentes armazenamentos de dados. Isso aumenta o volume de dados e aumenta os custos. A movimentação de dados também adiciona a sobrecarga de gerenciamento de pipelines para migrar os dados de uma origem para um novo destino.
O OpenSearch Service também adicionou novos tipos de instância para nós de dados – Im4gn e OR1 – para ajudá-lo a otimizar ainda mais o custo de infraestrutura. Com unidades de estado sólido (SSD) de memória não volátil (NVMe) máxima de 30 TB, a instância Im4gn oferece armazenamento denso e melhor desempenho. As instâncias OR1 usam replicação de segmento e armazenamento com suporte remoto para aumentar significativamente a taxa de transferência para cargas de trabalho com muita indexação.
Zero-ETL do DynamoDB para o serviço OpenSearch
Em novembro de 2023, o DynamoDB e o OpenSearch Ingestion introduziram uma integração ETL zero para o OpenSearch Service. Os domínios do OpenSearch Service e as coleções OpenSearch Serverless fornecem recursos de pesquisa avançados, como pesquisa de texto completo e vetorial, em seus dados do DynamoDB. Com alguns cliques no Console de gerenciamento da AWS, agora você pode carregar e sincronizar perfeitamente seus dados do DynamoDB para o OpenSearch Service, eliminando a necessidade de escrever código personalizado para extrair, transformar e carregar os dados.
Consulta direta (ETL zero para dados do Amazon S3, em versão prévia)
O OpenSearch Service anunciou uma nova maneira de consultar logs operacionais no Amazon S3 e em data lakes baseados em S3 sem a necessidade de alternar entre ferramentas para analisar dados operacionais. Anteriormente, era necessário copiar dados do Amazon S3 para o OpenSearch Service para aproveitar as vantagens dos recursos avançados de análise e visualização do OpenSearch para compreender seus dados, identificar anomalias e detectar possíveis ameaças.
No entanto, a replicação contínua de dados entre serviços pode ser dispendiosa e requer trabalho operacional. Com o recurso de consulta direta do OpenSearch Service, você pode acessar dados de log operacional armazenados no Amazon S3, sem precisar mover os dados em si. Agora você pode realizar consultas e visualizações complexas em seus dados sem qualquer movimentação de dados.
Suporte de Im4gn com OpenSearch Service
As instâncias Im4gn são otimizadas para cargas de trabalho que gerenciam grandes conjuntos de dados e precisam de alta densidade de armazenamento por vCPU. As instâncias Im4gn vêm em tamanhos grandes a 16xlarge, com até 30 TB em tamanho de disco SSD NVMe. As instâncias Im4gn são construídas Sistema AWS Nitro SSDs, que oferecem acesso ao disco de alto rendimento e baixa latência para melhor desempenho. As instâncias do OpenSearch Service Im4gn suportam todas as versões do OpenSearch e do Elasticsearch versões 7.9 e superiores. Para mais detalhes, consulte Tipos de instância compatíveis no Amazon OpenSearch Service.
Apresentando OR1, uma família de instâncias otimizadas do OpenSearch para indexação de cargas de trabalho pesadas
Em novembro de 2023, o OpenSearch Service foi lançado OR1, a família de instâncias otimizadas do OpenSearch, que oferece uma melhoria de até 30% no preço-desempenho em relação às instâncias existentes em benchmarks internos e usa o Amazon S3 para fornecer 11 9s de durabilidade. Um domínio com instâncias OR1 usa Loja de blocos elásticos da Amazon (Amazon EBS) volumes para armazenamento primário, com dados copiados de forma síncrona para o Amazon S3 à medida que chegam. Instâncias OR1 usam OpenSearch's recurso de replicação de segmento para permitir que fragmentos de réplica leiam dados diretamente do Amazon S3, evitando o custo de recursos de indexação em fragmentos primários e de réplica. A família de instâncias OR1 também oferece suporte à recuperação automática de dados em caso de falha. Para obter mais informações sobre as opções de tipo de instância OR1, consulte Tipos de instância da geração atual no serviço OpenSearch.
Capacite seu negócio com recursos de análise de segurança
O plug-in Security Analytics no OpenSearch Service oferece suporte pronto para uso tipos de log pré-empacotados e fornece regras de detecção de segurança (regras SIGMA) para detectar possíveis incidentes de segurança.
No OpenSearch 2.9, o plug-in Security Analytics adicionou suporte para tipos de log de clientes e suporte nativo para Estrutura aberta do esquema de segurança cibernética (OCSF) formato de dados. Com este novo suporte, você pode construir detectores com dados OCSF armazenados em Lago de segurança amazônico para analisar descobertas de segurança e mitigar qualquer incidente potencial. O plugin Security Analytics também adicionou a possibilidade de criar seus próprios tipos de log personalizados e criar regras de detecção personalizadas.
Crie soluções de pesquisa baseadas em ML
Em 2023, o OpenSearch Service investiu na eliminação do trabalho pesado necessário para construir aplicativos de pesquisa de próxima geração. Com recursos como pipelines de pesquisa, processadores de pesquisa e conectores de IA/ML, o OpenSearch Service permitiu o rápido desenvolvimento de aplicativos de pesquisa alimentados por pesquisa neural, pesquisa híbrida e resultados personalizados. Além disso, melhorias no plugin kNN melhoraram o armazenamento e a recuperação de dados vetoriais. Plug-ins opcionais recém-lançados para OpenSearch Service permitem integração perfeita com analisadores de linguagem adicionais e Amazon Customize.
Pipelines de pesquisa
Pipelines de pesquisa fornecem novas maneiras de aprimorar as consultas de pesquisa e melhorar os resultados da pesquisa. Você define um pipeline de pesquisa e envia suas consultas para ele. Ao definir o pipeline de pesquisa, você especifica processadores que transformam e aumentam suas consultas e reclassificam seus resultados. Os processadores de consulta pré-construídos incluem conversão de data, agregação, manipulação de string e conversão de tipo de dados. O processador de resultados no pipeline de pesquisa intercepta e adapta os resultados dinamicamente antes de renderizá-los para a próxima fase. O processamento de solicitação e resposta do pipeline é executado no nó coordenador, portanto, não há processamento no nível do fragmento.
Plug-ins opcionais
O OpenSearch Service permite associar aplicativos pré-instalados plug-ins opcionais do OpenSearch para usar com seu domínio. Um pacote de plugin opcional é compatível com uma versão específica do OpenSearch e só pode ser associado a domínios com essa versão. Os plug-ins disponíveis estão listados no PACK página no console do OpenSearch Service. O plug-in opcional inclui o plug-in Amazon Personalize, que integra o OpenSearch Service ao Amazon Personalize e novos analisadores de linguagem, como Nori, Sudachi, STConvert e Pinyin.
Suporte para novos analisadores de linguagem
OpenSearch Service adicionou suporte para quatro novos plug-ins de analisador de linguagem: Nori (coreano), Sudachi (japonês), Pinyin (chinês) e STConvert Analysis (chinês). Eles estão disponíveis em todas as regiões da AWS como plug-ins opcionais que você pode associar a domínios que executam qualquer versão do OpenSearch. Você pode usar o PACK página no console do OpenSearch Service para associar esses plug-ins ao seu domínio ou usar a API Associate Package.
Recurso de pesquisa neural
Pesquisa neural está geralmente disponível com o OpenSearch Service versão 2.9 e posterior. A pesquisa neural permite a integração com modelos de ML hospedados remotamente usando a estrutura de serviço de modelo. Quando você usa uma consulta neural durante a pesquisa, a pesquisa neural converte o texto da consulta em incorporações vetoriais, usa a pesquisa vetorial para comparar a consulta e a incorporação do documento e retorna os resultados mais próximos. Durante a ingestão, a pesquisa neural transforma o texto do documento em incorporação vetorial e indexa o texto e suas incorporações vetoriais em um índice vetorial.
Integração com Amazon Personalize
O OpenSearch Service introduziu um plug-in opcional para integração com o Amazon Personalize nas versões 2.9 ou posteriores do OpenSearch. O plug-in OpenSearch Service para Amazon Personalize Search Ranking permite melhorar o envolvimento e a conversão do usuário final na pesquisa de sites e aplicativos, aproveitando os recursos de aprendizagem profunda oferecidos pelo Amazon Personalize. Como um plugin opcional, o o pacote é compatível com OpenSearch versão 2.9 ou posteriore só pode ser associado a domínios com essa versão.
Filtragem de consulta eficiente com k-NN FAISS do OpenSearch
O OpenSearch Service introduziu filtragem de consulta eficiente com k-NN FAISS do OpenSearch na versão 2.9 e posterior. OpenSearch filtros de consulta vetorial eficientes O recurso avalia de forma inteligente estratégias de filtragem ideais – pré-filtragem com vizinho mais próximo aproximado (ANN) ou filtragem com k-vizinho mais próximo exato (k-NN) – para determinar a melhor estratégia para fornecer consultas de pesquisa vetorial precisas e de baixa latência. Nas versões anteriores do OpenSearch, as consultas vetoriais no mecanismo FAISS usavam técnicas de pós-filtragem, o que permitia consultas filtradas em escala, mas potencialmente retornando menos do que o número “k” de resultados solicitado. Filtros de consulta vetorial eficientes fornecer baixa latência e resultados precisos, permitindo que você empregue pesquisa híbrida em técnicas vetoriais e lexicais.
Vetores quantizados em bytes no OpenSearch Service
Com o novo vetor quantizado em bytes introduzido com 2.9, você pode reduzir os requisitos de memória por um fator de 4 e reduzir significativamente a latência de pesquisa, com perda mínima de qualidade (recuperação). Com esse recurso, os floats usuais de 32 bits usados para vetores são quantizados ou convertidos em inteiros com sinal de 8 bits. Para muitas aplicações, os dados vetoriais flutuantes existentes podem ser quantizados com pouca perda de qualidade. Comparando benchmarks, você descobrirá que o uso de vetores de bytes em vez de flutuantes de 32 bits resulta em uma redução significativa no armazenamento e no uso de memória, ao mesmo tempo que melhora o rendimento da indexação e reduz a latência da consulta. Um interno referência mostrou que o uso de armazenamento foi reduzido em até 78% e o uso de RAM foi reduzido em até 59% (para o conjunto de dados glove-200-angular). Os valores de recuperação para conjuntos de dados angulares foram inferiores aos dos conjuntos de dados euclidianos.
Conectores AI/ML
OpenSearch 2.9 e versões posteriores suportam integrações com modelos de ML hospedado em serviços AWS ou plataformas de terceiros. Isso permite que administradores de sistema e cientistas de dados executem cargas de trabalho de ML fora do domínio do OpenSearch Service. Os conectores de ML vêm com um conjunto compatível de blueprints de ML – modelos que definem o conjunto de parâmetros que você precisa fornecer ao enviar solicitações de API para um conector específico. O OpenSearch Service fornece conectores para diversas plataformas, como Amazon SageMaker, Rocha Amazônica, OpenAI Chat GPT e Coerente.
Integrações do console do OpenSearch Service
OpenSearch 2.9 e versões posteriores adicionaram um novo recurso de integração no console. As integrações fornecem uma Formação da Nuvem AWS modelo para construir seu busca semântica caso de uso conectando-se aos seus modelos de ML hospedados no SageMaker ou Amazon Bedrock. O modelo CloudFormation gera o endpoint do modelo e registra o ID do modelo no domínio do OpenSearch Service que você fornece como entrada para o modelo.
Pesquisa híbrida e normalização de intervalo
A processador de normalização e consulta híbrida baseia-se nos dois recursos lançados no início de 2023—pesquisa neural e pipelines de pesquisa. Como as consultas lexicais e semânticas retornam pontuações de relevância em diferentes escalas, era difícil ajustar as consultas de pesquisa híbridas.
O OpenSearch Service 2.11 agora oferece suporte a um processador de combinação e normalização para pesquisa híbrida. Agora você pode realizar consultas de pesquisa híbridas, combinando consultas de pesquisa vetorial k-NN baseadas em linguagem natural e lexical. O OpenSearch Service também permite que você ajuste seus resultados de pesquisa híbrida para máxima relevância usando múltiplas combinações de pontuação e técnicas de normalização.
Pesquisa multimodal com Amazon Bedrock
O OpenSearch Service 2.11 lança o suporte de pesquisa multimodal que permite pesquisar dados de texto e imagem usando modelos de incorporação multimodal. Para gerar embeddings de vetores, você precisa criar um pipeline de ingestão que contenha um processador text_image_embedding, que converte os binários de texto ou imagem em um campo de documento em incorporações de vetor. Você pode usar a cláusula de consulta neural, no API do plug-in k-NN or Consultar DSL consultas, para fazer uma combinação de pesquisas de texto e imagens. Você pode usar os novos recursos de integração do OpenSearch Service para iniciar rapidamente a pesquisa multimodal.
Recuperação neural esparsa
A pesquisa neural esparsa, um novo método eficiente de recuperação semântica, está disponível no OpenSearch Service 2.11. A pesquisa neural esparsa opera em dois modos: bi-codificador e somente documento. Com o modo bi-codificador, tanto os documentos quanto as consultas de pesquisa são passados por codificadores profundos. No modo somente documento, apenas os documentos passam por codificadores profundos, enquanto as consultas de pesquisa são tokenizadas. Um codificador esparso somente de documento gera um índice que tem 10.4% do tamanho de um índice de codificação denso. Para um bi-codificador, o tamanho do índice é 7.2% do tamanho de um índice de codificação denso. A pesquisa neural esparsa é habilitada por modelos de codificação esparsa que criam incorporações de vetores esparsos: um conjunto de <token: weight> pares que representam a entrada de texto e seu peso correspondente no vetor esparso. Para saber mais sobre os modelos pré-treinados para pesquisa neural esparsa, consulte Modelos de codificação esparsos.
A pesquisa neural esparsa reduz custos, melhora a relevância da pesquisa e tem menor latência. Você pode usar os novos recursos de integração do OpenSearch Service para iniciar rapidamente a pesquisa neural esparsa.
Atualizações de ingestão do OpenSearch
Ingestão do OpenSearch é um pipeline de ingestão totalmente gerenciado e escalonado automaticamente que entrega seus dados para domínios do OpenSearch Service e coleções do OpenSearch Serverless. Desde seu lançamento em 2023, o OpenSearch Ingestion continua adicionando novos recursos para facilitar a transformação e movimentação de seus dados de fontes suportadas para destinos downstream como OpenSearch Service, OpenSearch Serverless e Amazon S3.
Novos recursos de migração no OpenSearch Ingestion
Em novembro de 2023, o OpenSearch Ingestion anunciou o lançamento de novos recursos para oferecer suporte à migração de dados de domínios autogerenciados do Elasticsearch versão 7.x para as versões mais recentes do OpenSearch Service.
O OpenSearch Ingestion também oferece suporte à migração de dados de domínios gerenciados do OpenSearch Service que executam o OpenSearch versão 2.x para coleções do OpenSearch Serverless.
Saiba como você pode usar o OpenSearch Ingestion para migre seus dados para o OpenSearch Service.

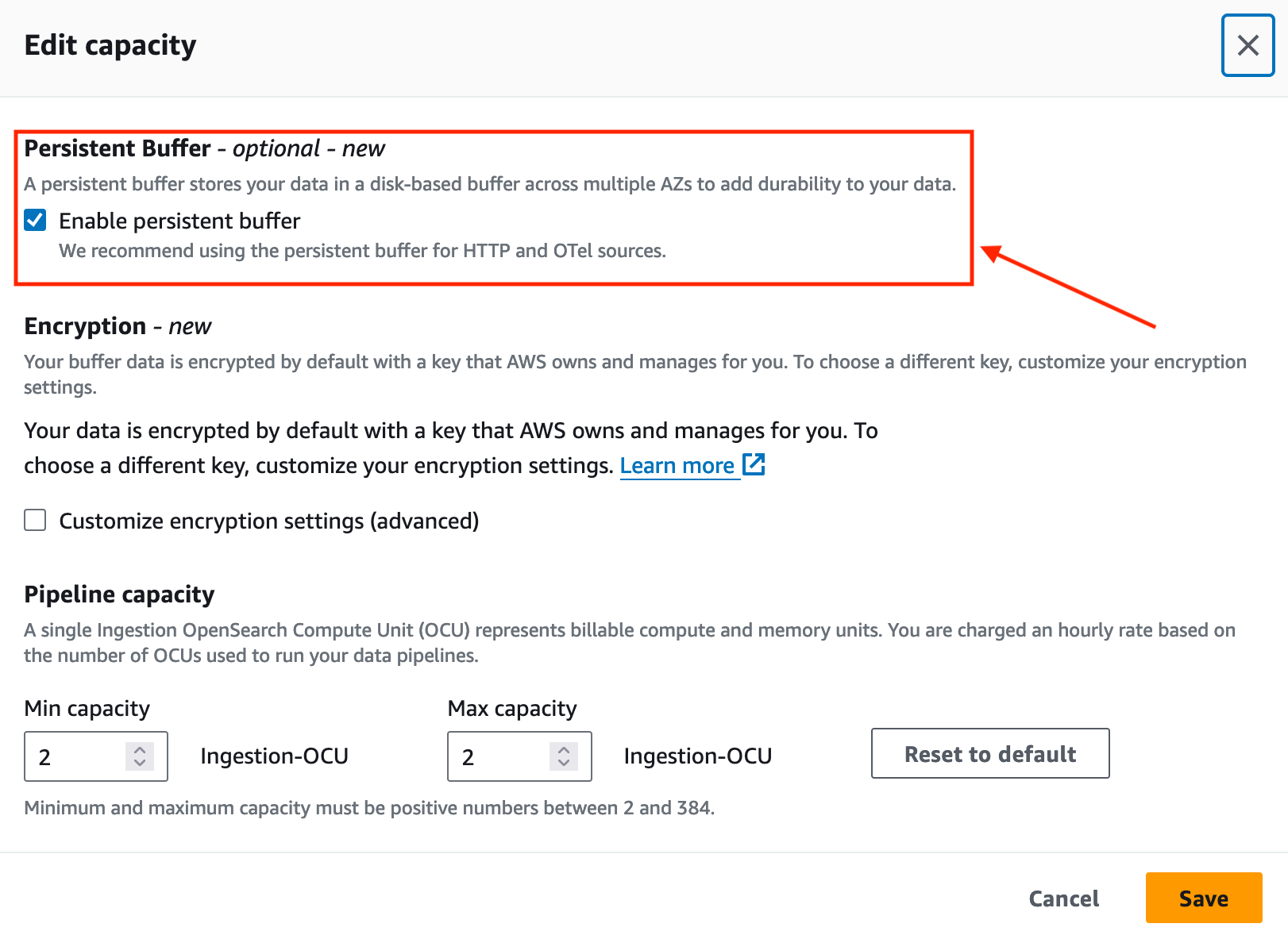
Melhore a durabilidade dos dados com o OpenSearch Ingestion
Em novembro de 2023, o OpenSearch Ingestion introduziu buffer persistente para fontes baseadas em push, como fontes HTTP (HTTP, Fluentd, FluentBit) e coletores OpenTelemetry.
Por padrão, o OpenSearch Ingestion usa buffer na memória. Com buffer persistente, o OpenSearch Ingestion armazena seus dados em um armazenamento baseado em disco que é mais resiliente. Se você tiver pipelines de ingestão existentes, poderá habilitar o buffer persistente para esses pipelines, conforme mostrado na captura de tela a seguir.
Suporte de novos plug-ins
No início de 2023, o OpenSearch Ingestion adicionou suporte para Amazon Managed Streaming para Apache Kafka (Amazon MSK). A ingestão do OpenSearch usa o Plug-in Kafka para transmitir dados do Amazon MSK para domínios gerenciados do OpenSearch Service ou coleções do OpenSearch Serverless. Para saber mais sobre como configurar o Amazon MSK como fonte de dados, consulte Usar um pipeline de ingestão do OpenSearch com Amazon Managed Streaming for Apache Kafka.
Atualizações sem servidor do OpenSearch
O OpenSearch Serverless continuou a aprimorar sua experiência sem servidor com o OpenSearch, introduzindo o suporte de uma nova coleção de pesquisa de vetor de tipo para armazenar embeddings e executar pesquisa de similaridade. O OpenSearch Serverless agora oferece suporte ao dimensionamento de réplicas de fragmentos para lidar com picos na taxa de transferência de consultas. E se você estiver usando uma coleta de série temporal, agora poderá configurar sua política personalizada de retenção de dados para atender aos seus requisitos de retenção de dados.
Mecanismo vetorial para OpenSearch sem servidor
Em novembro de 2023, lançamos o mecanismo de vetor para Amazon OpenSearch Serverless. O mecanismo vetorial simplifica a construção de experiências modernas de pesquisa aumentada por ML e aplicativos generativos de inteligência artificial (IA generativa), sem a necessidade de gerenciar a infraestrutura de banco de dados vetorial subjacente. Ele também permite executar pesquisa híbrida, combinando pesquisa vetorial e pesquisa de texto completo na mesma consulta, eliminando a necessidade de gerenciar e manter armazenamentos de dados separados ou uma pilha de aplicativos complexa.
Ambientes de desenvolvimento e teste de baixo custo OpenSearch Serverless
O OpenSearch Serverless agora oferece suporte a cargas de trabalho de desenvolvimento e teste, permitindo evitar a execução de uma réplica. A remoção de réplicas elimina a necessidade de ter OCUs redundantes em outra zona de disponibilidade apenas para fins de disponibilidade. Se você estiver usando o OpenSearch Serverless para desenvolvimento e teste, onde a disponibilidade não é uma preocupação, você pode diminuir o mínimo de OCUs de 4 para 2.
OpenSearch Serverless oferece suporte à exclusão automatizada de dados com base no tempo usando políticas de ciclo de vida de dados
Em dezembro de 2023, o OpenSearch Serverless anunciou suporte para gerenciamento de retenção de dados de coleções e índices de séries temporais. Com o novo recurso automatizado de exclusão de dados com base no tempo, você pode especificar por quanto tempo deseja reter os dados. OpenSearch Serverless gerencia automaticamente o ciclo de vida dos dados com base nesta configuração. Para saber mais, consulte Amazon OpenSearch Serverless agora oferece suporte à exclusão automatizada de dados com base no tempo.
OpenSearch Serverless anunciou suporte para ampliação de réplicas em nível de fragmento
No lançamento, o OpenSearch Serverless suportava o aumento automático da capacidade em resposta ao aumento do tamanho dos dados. Com o novo escalonamento de réplica de shard recurso, o OpenSearch Serverless detecta automaticamente fragmentos sob coação devido a picos repentinos nas taxas de consulta e adiciona dinamicamente novas réplicas de fragmentos para lidar com o aumento da taxa de transferência de consultas, mantendo tempos de resposta rápidos. Esta abordagem revela-se mais económica do que simplesmente adicionar novas réplicas de índice.
Notificações de usuário da AWS para monitorar o uso da OCU
Com este lançamento, você pode configurar o sistema para enviar notificações quando a utilização da OCU estiver se aproximando ou atingir os limites máximos configurados para pesquisa ou ingestão. Com a nova integração do AWS User Notification, você pode configurar o sistema para enviar notificações sempre que o limite de capacidade for violado. O recurso de Notificação do Usuário elimina a necessidade de monitorar o serviço constantemente. Para mais informações, veja Monitoramento do Amazon OpenSearch Serverless usando AWS User Notifications.
Aprimore sua experiência com painéis OpenSearch
O OpenSearch 2.9 no OpenSearch Service introduziu novos recursos para facilitar a análise rápida de seus dados no OpenSearch Dashboards. Esses novos recursos incluem os novos painéis pré-configurados prontos para uso com integrações OpenSearch e a capacidade de criar alertas e detecção de anomalias a partir de uma visualização existente em seus painéis.
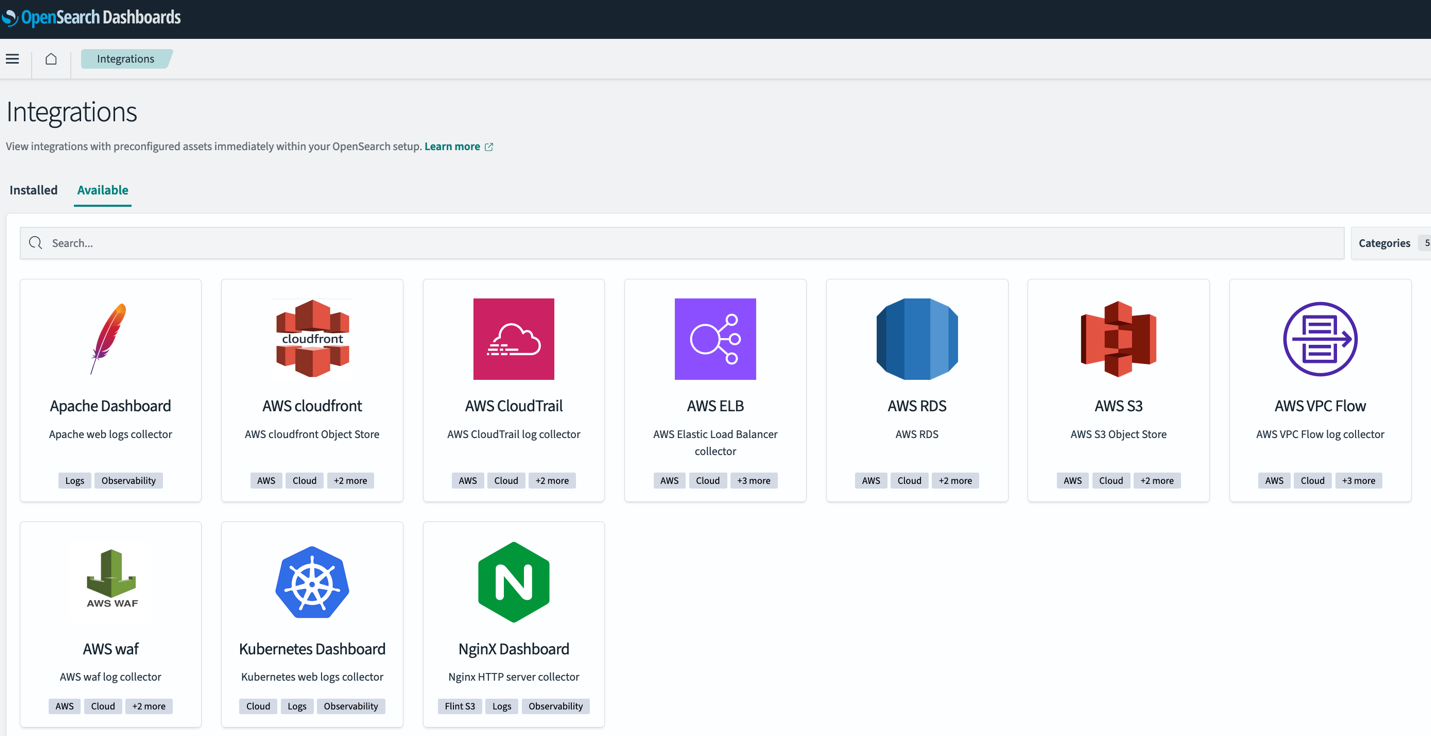
Integrações do painel OpenSearch
OpenSearch 2.9 adicionou suporte para integrações OpenSearch em OpenSearch Dashboards. As integrações do OpenSearch incluem painéis pré-configurados para que você possa começar a analisar rapidamente seus dados provenientes de fontes populares, como AWS CloudFront, AWS WAF, AWS CloudTrail e Nuvem virtual privada da Amazon (Amazon VPC).
Alertas e anomalias em painéis OpenSearch
No OpenSearch Service 2.9, você pode criar um novo monitor de alertas diretamente do seu visualização de gráfico de linhas nos painéis do OpenSearch. Você também pode associar os monitores ou detectores existentes criados anteriormente no OpenSearch à visualização do painel.
Esse novo recurso ajuda a reduzir a alternância de contexto entre os painéis e os plug-ins de Alerta ou Detecção de Anomalias. Consulte o painel a seguir para adicionar um monitor de alerta para detectar quedas no volume médio de dados em seus serviços.

OpenSearch expande suporte a agregações geoespaciais
Com o OpenSearch versão 2.9, o OpenSearch Service adicionou o suporte de três tipos de geoforma agregação de dados por meio de API: limites geográficos, geo_hash e geo_tile.
O tipo de campo geoshape oferece a possibilidade de indexar dados de localização em diferentes formatos geográficos, como um ponto, um polígono ou uma cadeia de linhas. Com os novos tipos de agregação, você tem mais flexibilidade para agregar documentos de um índice usando agregações geoespaciais métricas e multi-bucket.
Atualizações operacionais do OpenSearch Service
O OpenSearch Service eliminou a necessidade de executar a implantação azul/verde ao alterar os nós gerenciados pelo domínio. Além disso, o serviço melhorou os eventos do Auto-Tune com o suporte de novas métricas do Auto-Tune para rastrear as alterações em seu domínio do OpenSearch Service.
O OpenSearch Service agora permite atualizar nós do gerenciador de domínio sem implantação azul/verde
No início do segundo semestre de 2, o OpenSearch Service permitiu que você modificasse o tipo de instância ou a contagem de instâncias de nós dedicados do gerenciador de cluster sem a necessidade de implantação azul/verde. Essa melhoria permite atualizações mais rápidas com o mínimo de interrupção nas operações do seu domínio, ao mesmo tempo que evita qualquer movimentação de dados.
Anteriormente, atualizar seus nós dedicados do gerenciador de cluster no OpenSearch Service significava usar uma implantação azul/verde para fazer a mudança. Embora as implantações azul/verde tenham como objetivo evitar qualquer interrupção em seus domínios, como a implantação utiliza recursos adicionais no domínio, é recomendável executá-las durante períodos de pouco tráfego. Agora você pode atualizar os tipos de instâncias do gerenciador de cluster ou contagens de instâncias sem exigir uma implantação azul/verde, para que essas atualizações possam ser concluídas mais rapidamente, evitando qualquer possível interrupção nas operações do seu domínio. Nos casos em que você modifica o tipo e a contagem da instância do gerenciador de domínio, o OpenSearch Service ainda usará uma implantação azul/verde para fazer a alteração. Você pode usar a opção de simulação para verificar se sua alteração requer uma implantação azul/verde.
Experiência aprimorada de ajuste automático
Em setembro de 2023, o OpenSearch Service adicionou novas métricas de Auto-Tune e eventos aprimorados de Auto-Tune que oferecem melhor visibilidade das otimizações de desempenho de domínio feitas pelo Auto-Tune.
Auto-Tune é um sistema de gerenciamento de recursos adaptável que atualiza automaticamente os recursos de domínio do OpenSearch Service para melhorar a eficiência e o desempenho. Por exemplo, o Auto-Tune otimiza configurações relacionadas à memória, como tamanhos de filas, tamanhos de cache e configurações de Java Virtual Machine (JVM) em seus nós.
Com este lançamento, agora você pode auditar o histórico das alterações, bem como acompanhá-las em tempo real a partir do Amazon CloudWatch console.
Além disso, o OpenSearch Service agora publica detalhes das alterações no Amazon Event Bridge quando as configurações do Auto-Tune são recomendadas ou aplicadas a um domínio do OpenSearch Service. Esses eventos de Auto-Tune também estarão visíveis no Notificações página no console do OpenSearch Service.
Acelere sua migração para o OpenSearch Service com a nova solução Migration Assistant
Em novembro de 2023, a equipe OpenSearch lançou uma nova solução de código aberto—Assistente de migração para Amazon OpenSearch Service. A solução oferece suporte à migração de dados de domínios autogerenciados Elasticsearch e OpenSearch para OpenSearch Service, suportando Elasticsearch 7.x (<=7.10), OpenSearch 1.x e OpenSearch 2.x como fontes de migração. A solução facilita a migração dos dados existentes e ativos entre a origem e o destino.
Conclusão
Nesta postagem, abordamos os novos lançamentos do OpenSearch Service para ajudá-lo a inovar seus negócios com pesquisa, observabilidade, análise de segurança e migrações. Fornecemos informações sobre quando usar cada novo recurso no OpenSearch Service, OpenSearch Ingestion e OpenSearch Serverless.
Saiba mais sobre OpenSearch Dashboards e plug-ins OpenSearch e o novo e emocionante assistente OpenSearch usando Playground OpenSearch.
Confira os recursos descritos nesta postagem e agradecemos por nos fornecer seus valiosos comentários.
Sobre os autores
 Jon Handler é arquiteto de soluções principal sênior da Amazon Web Services com sede em Palo Alto, CA. Jon trabalha em estreita colaboração com o OpenSearch e o Amazon OpenSearch Service, fornecendo ajuda e orientação a uma ampla gama de clientes que têm cargas de trabalho de pesquisa e análise de log que desejam migrar para a Nuvem AWS. Antes de ingressar na AWS, a carreira de Jon como desenvolvedor de software incluiu 4 anos codificando um mecanismo de pesquisa de comércio eletrônico em grande escala. Jon é bacharel em artes pela Universidade da Pensilvânia, mestre em ciências e doutorado em ciência da computação e inteligência artificial pela Northwestern University.
Jon Handler é arquiteto de soluções principal sênior da Amazon Web Services com sede em Palo Alto, CA. Jon trabalha em estreita colaboração com o OpenSearch e o Amazon OpenSearch Service, fornecendo ajuda e orientação a uma ampla gama de clientes que têm cargas de trabalho de pesquisa e análise de log que desejam migrar para a Nuvem AWS. Antes de ingressar na AWS, a carreira de Jon como desenvolvedor de software incluiu 4 anos codificando um mecanismo de pesquisa de comércio eletrônico em grande escala. Jon é bacharel em artes pela Universidade da Pensilvânia, mestre em ciências e doutorado em ciência da computação e inteligência artificial pela Northwestern University.
 Hajer Bouafif é arquiteto de soluções especialista em análise na Amazon Web Services. Ela se concentra no Amazon OpenSearch Service e ajuda os clientes a projetar e criar cargas de trabalho analíticas bem arquitetadas em diversos setores. Hajer gosta de passar o tempo ao ar livre e descobrir novas culturas.
Hajer Bouafif é arquiteto de soluções especialista em análise na Amazon Web Services. Ela se concentra no Amazon OpenSearch Service e ajuda os clientes a projetar e criar cargas de trabalho analíticas bem arquitetadas em diversos setores. Hajer gosta de passar o tempo ao ar livre e descobrir novas culturas.
 Aruna Govindaraju é arquiteto de soluções especialista em Amazon OpenSearch e trabalhou com muitos mecanismos de pesquisa comerciais e de código aberto. Ela é apaixonada por pesquisa, relevância e experiência do usuário. Sua experiência em correlacionar sinais do usuário final com o comportamento do mecanismo de pesquisa ajudou muitos clientes a melhorar sua experiência de pesquisa.
Aruna Govindaraju é arquiteto de soluções especialista em Amazon OpenSearch e trabalhou com muitos mecanismos de pesquisa comerciais e de código aberto. Ela é apaixonada por pesquisa, relevância e experiência do usuário. Sua experiência em correlacionar sinais do usuário final com o comportamento do mecanismo de pesquisa ajudou muitos clientes a melhorar sua experiência de pesquisa.
 Prashant Agrawal é Arquiteto de Soluções Especialista em Pesquisa Sênior no Amazon OpenSearch Service. Ele trabalha em estreita colaboração com os clientes para ajudá-los a migrar suas cargas de trabalho para a nuvem e ajuda os clientes existentes a ajustar seus clusters para obter melhor desempenho e economizar custos. Antes de ingressar na AWS, ele ajudou vários clientes a usar o OpenSearch e o Elasticsearch para seus casos de uso de pesquisa e análise de log. Quando não está trabalhando, você pode encontrá-lo viajando e explorando novos lugares. Resumindo, ele gosta de fazer Comer → Viajar → Repetir.
Prashant Agrawal é Arquiteto de Soluções Especialista em Pesquisa Sênior no Amazon OpenSearch Service. Ele trabalha em estreita colaboração com os clientes para ajudá-los a migrar suas cargas de trabalho para a nuvem e ajuda os clientes existentes a ajustar seus clusters para obter melhor desempenho e economizar custos. Antes de ingressar na AWS, ele ajudou vários clientes a usar o OpenSearch e o Elasticsearch para seus casos de uso de pesquisa e análise de log. Quando não está trabalhando, você pode encontrá-lo viajando e explorando novos lugares. Resumindo, ele gosta de fazer Comer → Viajar → Repetir.
 Muçulmano Abu Taha é um arquiteto sênior de soluções especialistas em OpenSearch dedicado a orientar os clientes por meio de migrações contínuas de cargas de trabalho de pesquisa, ajustando clusters para desempenho máximo e garantindo economia. Com experiência como gerente técnico de contas (TAM), Muslim traz uma vasta experiência em ajudar clientes corporativos na adoção da nuvem e na otimização de seus diferentes conjuntos de cargas de trabalho. Muslim gosta de passar tempo com a família, viajar e explorar novos lugares.
Muçulmano Abu Taha é um arquiteto sênior de soluções especialistas em OpenSearch dedicado a orientar os clientes por meio de migrações contínuas de cargas de trabalho de pesquisa, ajustando clusters para desempenho máximo e garantindo economia. Com experiência como gerente técnico de contas (TAM), Muslim traz uma vasta experiência em ajudar clientes corporativos na adoção da nuvem e na otimização de seus diferentes conjuntos de cargas de trabalho. Muslim gosta de passar tempo com a família, viajar e explorar novos lugares.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/amazon-opensearch-h2-2023-in-review/

