Zoológico Digital fornece localização ponta a ponta e serviços de mídia para adaptar conteúdo original de TV e filmes a diferentes idiomas, regiões e culturas. Facilita a globalização para os melhores criadores de conteúdo do mundo. Com a confiança dos maiores nomes do entretenimento, a ZOO Digital oferece serviços de localização e mídia de alta qualidade em grande escala, incluindo dublagem, legendagem, script e conformidade.
Os fluxos de trabalho de localização típicos exigem a diarização manual do locutor, em que um fluxo de áudio é segmentado com base na identidade do locutor. Este processo demorado deve ser concluído antes que o conteúdo possa ser dublado para outro idioma. Com métodos manuais, um episódio de 30 minutos pode levar de 1 a 3 horas para ser localizado. Através da automação, a ZOO Digital pretende alcançar a localização em menos de 30 minutos.
Nesta postagem, discutimos a implantação de modelos escalonáveis de aprendizado de máquina (ML) para diarização de conteúdo de mídia usando Amazon Sage Maker, com foco no SussurroX modelo.
BACKGROUND
A visão da ZOO Digital é fornecer um retorno mais rápido do conteúdo localizado. Este objetivo é dificultado pela natureza manual intensiva do exercício, agravada pela pequena força de trabalho de pessoas qualificadas que podem localizar o conteúdo manualmente. A ZOO Digital trabalha com mais de 11,000 freelancers e localizou mais de 600 milhões de palavras somente em 2022. No entanto, a oferta de pessoas qualificadas está a ser superada pela crescente procura de conteúdos, exigindo automação para auxiliar nos fluxos de trabalho de localização.
Com o objetivo de acelerar a localização de fluxos de trabalho de conteúdo por meio de aprendizado de máquina, a ZOO Digital contratou o AWS Prototyping, um programa de investimento da AWS para construir cargas de trabalho em conjunto com os clientes. O compromisso se concentrou em fornecer uma solução funcional para o processo de localização, ao mesmo tempo em que fornecia treinamento prático aos desenvolvedores da ZOO Digital no SageMaker, Amazon Transcribe e Amazon Tradutor.
Desafio do cliente
Após a transcrição de um título (um filme ou episódio de uma série de TV), os locutores devem ser atribuídos a cada segmento da fala para que possam ser corretamente atribuídos aos dubladores escalados para interpretar os personagens. Este processo é chamado de diarização do locutor. A ZOO Digital enfrenta o desafio de diarizar conteúdo em grande escala e ao mesmo tempo ser economicamente viável.
Visão geral da solução
Neste protótipo, armazenamos os arquivos de mídia originais em um determinado Serviço de armazenamento simples da Amazon (Amazon S3) balde. Este bucket S3 foi configurado para emitir um evento quando novos arquivos forem detectados nele, acionando um AWS Lambda função. Para obter instruções sobre como configurar este gatilho, consulte o tutorial Usar um gatilho do Amazon S3 para invocar uma função do Lambda. Posteriormente, a função Lambda invocou o endpoint SageMaker para inferência usando o Cliente Boto3 SageMaker Runtime.
A SussurroX modelo, baseado em Sussurro da OpenAI, realiza transcrições e diarização de ativos de mídia. É construído sobre o Sussurro mais rápido reimplementação, oferecendo transcrição até quatro vezes mais rápida com melhor alinhamento de carimbo de data/hora em nível de palavra em comparação com o Whisper. Além disso, introduz a diarização do alto-falante, não presente no modelo Whisper original. WhisperX utiliza o modelo Whisper para transcrições, o Wav2Vec2 modelo para aprimorar o alinhamento do carimbo de data e hora (garantindo a sincronização do texto transcrito com carimbos de data e hora de áudio) e o nota de piano modelo para diarização. FFmpeg é usado para carregar áudio da mídia de origem, suportando vários formatos de mídia. A arquitetura do modelo transparente e modular permite flexibilidade, pois cada componente do modelo pode ser trocado conforme necessário no futuro. No entanto, é essencial observar que o WhisperX não possui recursos completos de gerenciamento e não é um produto de nível empresarial. Sem manutenção e suporte, pode não ser adequado para implantação em produção.
Nesta colaboração, implantamos e avaliamos o WhisperX no SageMaker, usando um endpoint de inferência assíncrona para hospedar o modelo. Os endpoints assíncronos do SageMaker suportam tamanhos de upload de até 1 GB e incorporam recursos de escalonamento automático que atenuam com eficiência os picos de tráfego e economizam custos fora dos horários de pico. Os endpoints assíncronos são particularmente adequados para processar arquivos grandes, como filmes e séries de TV em nosso caso de uso.
O diagrama a seguir ilustra os elementos centrais dos experimentos que conduzimos nesta colaboração.

Nas seções a seguir, nos aprofundamos nos detalhes da implantação do modelo WhisperX no SageMaker e avaliamos o desempenho da diarização.
Baixe o modelo e seus componentes
WhisperX é um sistema que inclui vários modelos para transcrição, alinhamento forçado e diarização. Para uma operação tranquila do SageMaker sem a necessidade de buscar artefatos do modelo durante a inferência, é essencial fazer o download prévio de todos os artefatos do modelo. Esses artefatos são então carregados no contêiner de serviço do SageMaker durante a inicialização. Como esses modelos não são acessíveis diretamente, oferecemos descrições e exemplos de código da fonte do WhisperX, fornecendo instruções sobre como baixar o modelo e seus componentes.
WhisperX usa seis modelos:
A maioria desses modelos pode ser obtida em Abraçando o rosto usando a biblioteca huggingface_hub. Usamos o seguinte download_hf_model() função para recuperar esses artefatos do modelo. É necessário um token de acesso do Hugging Face, gerado após a aceitação dos contratos de usuário para os seguintes modelos pyannote:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
O modelo VAD é obtido do Amazon S3 e o modelo Wav2Vec2 é recuperado do módulo torchaudio.pipelines. Com base no código a seguir, podemos recuperar todos os artefatos dos modelos, incluindo aqueles do Hugging Face, e salvá-los no diretório de modelo local especificado:
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
Selecione o AWS Deep Learning Container apropriado para servir o modelo
Depois que os artefatos do modelo forem salvos usando o código de amostra anterior, você poderá escolher pré-construídos Contêineres de aprendizado profundo da AWS (DLCs) dos seguintes GitHub repo. Ao selecionar a imagem do Docker, considere as seguintes configurações: estrutura (Hugging Face), tarefa (inferência), versão do Python e hardware (por exemplo, GPU). Recomendamos usar a seguinte imagem: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Esta imagem possui todos os pacotes de sistema necessários pré-instalados, como ffmpeg. Lembre-se de substituir [REGION] pela região da AWS que você está usando.
Para outros pacotes Python necessários, crie um requirements.txt arquivo com uma lista de pacotes e suas versões. Esses pacotes serão instalados quando o AWS DLC for criado. A seguir estão os pacotes adicionais necessários para hospedar o modelo WhisperX no SageMaker:
Crie um script de inferência para carregar os modelos e executar a inferência
Em seguida, criamos um personalizado inference.py script para descrever como o modelo WhisperX e seus componentes são carregados no contêiner e como o processo de inferência deve ser executado. O script contém duas funções: model_fn e transform_fn. O model_fn A função é invocada para carregar os modelos de seus respectivos locais. Posteriormente, esses modelos são repassados ao transform_fn função durante a inferência, onde os processos de transcrição, alinhamento e diarização são realizados. A seguir está um exemplo de código para inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
Dentro do diretório do modelo, ao lado do requirements.txt arquivo, garanta a presença de inference.py em um subdiretório de código. O models diretório deve ser semelhante ao seguinte:
Crie um tarball dos modelos
Depois de criar os modelos e os diretórios de código, você poderá usar as linhas de comando a seguir para compactar o modelo em um tarball (arquivo .tar.gz) e carregá-lo no Amazon S3. No momento em que este artigo foi escrito, usando o modelo Large V2 de sussurro mais rápido, o tarball resultante representando o modelo SageMaker tinha 3 GB de tamanho. Para obter mais informações, consulte Padrões de hospedagem de modelo no Amazon SageMaker, Parte 2: Introdução à implantação de modelos em tempo real no SageMaker.
Crie um modelo SageMaker e implante um endpoint com um preditor assíncrono
Agora você pode criar o modelo SageMaker, a configuração do endpoint e o endpoint assíncrono com Preditor Assíncrono usando o modelo tarball criado na etapa anterior. Para obter instruções, consulte Criar um endpoint de inferência assíncrona.
Avalie o desempenho da diarização
Para avaliar o desempenho da diarização do modelo WhisperX em vários cenários, selecionamos três episódios de dois títulos em inglês: um título de drama composto por episódios de 30 minutos e um título de documentário composto por episódios de 45 minutos. Utilizamos o kit de ferramentas de métricas do pyannote, pyannote.metrics, para calcular o taxa de erro de diarização (DER). Na avaliação, transcrições transcritas manualmente e diarizadas fornecidas pelo ZOO serviram como base.
Definimos o DER da seguinte forma:
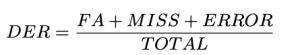
Total é a duração do vídeo de verdade. FA (Falso Alarme) é o comprimento dos segmentos que são considerados como discurso nas previsões, mas não na verdade. Senhorita é o comprimento dos segmentos que são considerados como discurso na verdade básica, mas não na previsão. erro, também chamada Confusão, é o comprimento dos segmentos atribuídos a diferentes falantes na previsão e na verdade básica. Todas as unidades são medidas em segundos. Os valores típicos para DER podem variar dependendo da aplicação específica, do conjunto de dados e da qualidade do sistema de diarização. Observe que o DER pode ser maior que 1.0. Um DER mais baixo é melhor.
Para poder calcular o DER para uma mídia, é necessária uma diarização da verdade, bem como as saídas transcritas e diarizadas do WhisperX. Eles devem ser analisados e resultar em listas de tuplas contendo um rótulo de locutor, hora de início do segmento de fala e hora de término do segmento de fala para cada segmento de fala na mídia. Os rótulos dos alto-falantes não precisam corresponder entre o WhisperX e as diarizações de verdade. Os resultados são baseados principalmente no tempo dos segmentos. pyannote.metrics pega essas tuplas de diarizações verdadeiras e diarizações de saída (referidas na documentação pyannote.metrics como referência e hipótese) para calcular o DER. A tabela a seguir resume nossos resultados.
| Tipo de vídeo | DER | Correto | Senhorita | erro | Alarme falso |
| Drama | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| Documentário | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| Média | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
Estes resultados revelam uma diferença significativa de desempenho entre os títulos de drama e documentário, com o modelo alcançando resultados notavelmente melhores (usando DER como métrica agregada) para os episódios de drama em comparação com o título de documentário. Uma análise mais detalhada dos títulos fornece informações sobre os potenciais fatores que contribuem para esta lacuna de desempenho. Um fator-chave pode ser a presença frequente de música de fundo sobreposta à fala no título do documentário. Embora o pré-processamento de mídia para melhorar a precisão da diarização, como a remoção de ruído de fundo para isolar a fala, estivesse além do escopo deste protótipo, ele abre caminhos para trabalhos futuros que poderiam potencialmente melhorar o desempenho do WhisperX.
Conclusão
Nesta postagem, exploramos a parceria colaborativa entre AWS e ZOO Digital, empregando técnicas de aprendizado de máquina com SageMaker e o modelo WhisperX para aprimorar o fluxo de trabalho de diarização. A equipe da AWS desempenhou um papel fundamental auxiliando a ZOO na prototipagem, avaliação e compreensão da implantação eficaz de modelos de ML personalizados, projetados especificamente para diarização. Isso incluiu a incorporação de escalonamento automático para escalabilidade usando SageMaker.
Aproveitar a IA para diarização levará a economias substanciais em custos e tempo ao gerar conteúdo localizado para ZOO. Ao ajudar os transcritores a criar e identificar os oradores de forma rápida e precisa, esta tecnologia aborda a natureza tradicionalmente demorada e propensa a erros da tarefa. O processo convencional geralmente envolve múltiplas passagens pelo vídeo e etapas adicionais de controle de qualidade para minimizar erros. A adoção de IA para diarização permite uma abordagem mais direcionada e eficiente, aumentando assim a produtividade num prazo mais curto.
Descrevemos as principais etapas para implantar o modelo WhisperX no endpoint assíncrono SageMaker e incentivamos você a experimentá-lo usando o código fornecido. Para obter mais informações sobre os serviços e tecnologia da ZOO Digital, visite Site oficial do ZOO Digital. Para obter detalhes sobre a implantação do modelo OpenAI Whisper no SageMaker e várias opções de inferência, consulte Hospede o modelo Whisper no Amazon SageMaker: explorando opções de inferência. Sinta-se à vontade para compartilhar suas idéias nos comentários.
Sobre os autores
 Ying Hou, PhD, é arquiteto de prototipagem de aprendizado de máquina na AWS. Suas principais áreas de interesse abrangem Deep Learning, com foco em GenAI, Visão Computacional, PNL e previsão de dados de séries temporais. Nas horas vagas, ela adora passar momentos de qualidade com a família, mergulhando em romances e fazendo caminhadas nos parques nacionais do Reino Unido.
Ying Hou, PhD, é arquiteto de prototipagem de aprendizado de máquina na AWS. Suas principais áreas de interesse abrangem Deep Learning, com foco em GenAI, Visão Computacional, PNL e previsão de dados de séries temporais. Nas horas vagas, ela adora passar momentos de qualidade com a família, mergulhando em romances e fazendo caminhadas nos parques nacionais do Reino Unido.
 Ethan Cumberland é engenheiro de pesquisa de IA na ZOO Digital, onde trabalha no uso de IA e aprendizado de máquina como tecnologias assistivas para melhorar fluxos de trabalho em fala, idioma e localização. Ele tem experiência em engenharia de software e pesquisa no domínio de segurança e policiamento, com foco na extração de informações estruturadas da web e no aproveitamento de modelos de ML de código aberto para analisar e enriquecer os dados coletados.
Ethan Cumberland é engenheiro de pesquisa de IA na ZOO Digital, onde trabalha no uso de IA e aprendizado de máquina como tecnologias assistivas para melhorar fluxos de trabalho em fala, idioma e localização. Ele tem experiência em engenharia de software e pesquisa no domínio de segurança e policiamento, com foco na extração de informações estruturadas da web e no aproveitamento de modelos de ML de código aberto para analisar e enriquecer os dados coletados.
 Gaurav Kaila lidera a equipe de prototipagem da AWS para o Reino Unido e Irlanda. Sua equipe trabalha com clientes de diversos setores para idealizar e co-desenvolver cargas de trabalho críticas para os negócios, com o objetivo de acelerar a adoção dos serviços da AWS.
Gaurav Kaila lidera a equipe de prototipagem da AWS para o Reino Unido e Irlanda. Sua equipe trabalha com clientes de diversos setores para idealizar e co-desenvolver cargas de trabalho críticas para os negócios, com o objetivo de acelerar a adoção dos serviços da AWS.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

