Este é um post convidado co-escrito com Scott Gutterman do PGA TOUR.
A inteligência artificial generativa (IA generativa) permitiu novas possibilidades para a construção de sistemas inteligentes. Melhorias recentes em grandes modelos de linguagem (LLMs) baseados em IA generativa permitiram seu uso em uma variedade de aplicações relacionadas à recuperação de informações. Dadas as fontes de dados, os LLMs forneceram ferramentas que nos permitiriam construir um chatbot de perguntas e respostas em semanas, em vez do que poderia levar anos antes, e provavelmente com pior desempenho. Formulámos uma solução de Retrieval-Augmented-Generation (RAG) que permitiria ao PGA TOUR criar um protótipo para uma futura plataforma de envolvimento dos fãs que poderia tornar os seus dados acessíveis aos fãs de uma forma interactiva num formato conversacional.
O uso de dados estruturados para responder a perguntas requer uma maneira de extrair com eficácia dados relevantes para a consulta de um usuário. Formulamos uma abordagem de texto para SQL em que a consulta em linguagem natural do usuário é convertida em uma instrução SQL usando um LLM. O SQL é executado por Amazona atena para retornar os dados relevantes. Esses dados são novamente fornecidos a um LLM, que é solicitado a responder à consulta do usuário com base nos dados.
O uso de dados de texto requer um índice que possa ser usado para pesquisar e fornecer contexto relevante para um LLM responder a uma consulta do usuário. Para permitir a recuperação rápida de informações, usamos Amazona Kendra como índice desses documentos. Quando os usuários fazem perguntas, nosso assistente virtual pesquisa rapidamente no índice Amazon Kendra para encontrar informações relevantes. O Amazon Kendra usa processamento de linguagem natural (PNL) para entender as consultas dos usuários e encontrar os documentos mais relevantes. As informações relevantes são então fornecidas ao LLM para geração de resposta final. Nossa solução final é uma combinação dessas abordagens text-to-SQL e text-RAG.
Neste post destacamos como o Centro de inovação de IA generativa da AWS colaborou com o Serviços Profissionais AWS e PGA TOUR desenvolver um protótipo de assistente virtual usando Rocha Amazônica que poderia permitir que os torcedores extraíssem informações sobre qualquer evento, jogador, buraco ou nível de tacada de uma maneira interativa e contínua. O Amazon Bedrock é um serviço totalmente gerenciado que oferece uma variedade de modelos básicos (FMs) de alto desempenho de empresas líderes de IA, como AI21 Labs, Anthropic, Cohere, Meta, Stability AI e Amazon por meio de uma única API, juntamente com um amplo conjunto de recursos necessários para criar aplicativos generativos de IA com segurança, privacidade e IA responsável.
Desenvolvimento: Preparando os dados
Como acontece com qualquer projeto baseado em dados, o desempenho será tão bom quanto os dados. Processamos os dados para permitir que o LLM seja capaz de consultar e recuperar dados relevantes de maneira eficaz.
Para os dados tabulares de competição, nos concentramos em um subconjunto de dados relevantes para o maior número de consultas de usuários e rotulamos as colunas de forma intuitiva, de modo que fossem mais fáceis de serem compreendidas pelos LLMs. Também criamos algumas colunas auxiliares para ajudar o LLM a compreender conceitos com os quais, de outra forma, teria dificuldades. Por exemplo, se um jogador de golfe dá uma tacada a menos do par (como acertar no buraco em 3 tacadas em um par 4 ou em 4 tacadas em um par 5), isso é comumente chamado de passarinho. Se um usuário perguntar: “Quantos birdies o jogador X fez no ano passado?”, apenas ter a pontuação e o par na tabela não é suficiente. Como resultado, adicionamos colunas para indicar termos comuns de golfe, como bogey, birdie e eagle. Além disso, vinculamos os dados da Competição a uma coleção de vídeos separada, juntando uma coluna para um video_id, o que permitiria que nosso aplicativo extraísse o vídeo associado a uma cena específica nos dados da Competição. Também habilitamos a união de dados de texto aos dados tabulares, por exemplo, adicionando biografias de cada jogador como uma coluna de texto. As figuras a seguir mostram o procedimento passo a passo de como uma consulta é processada para o pipeline de texto para SQL. Os números indicam a série de etapas para responder a uma consulta.
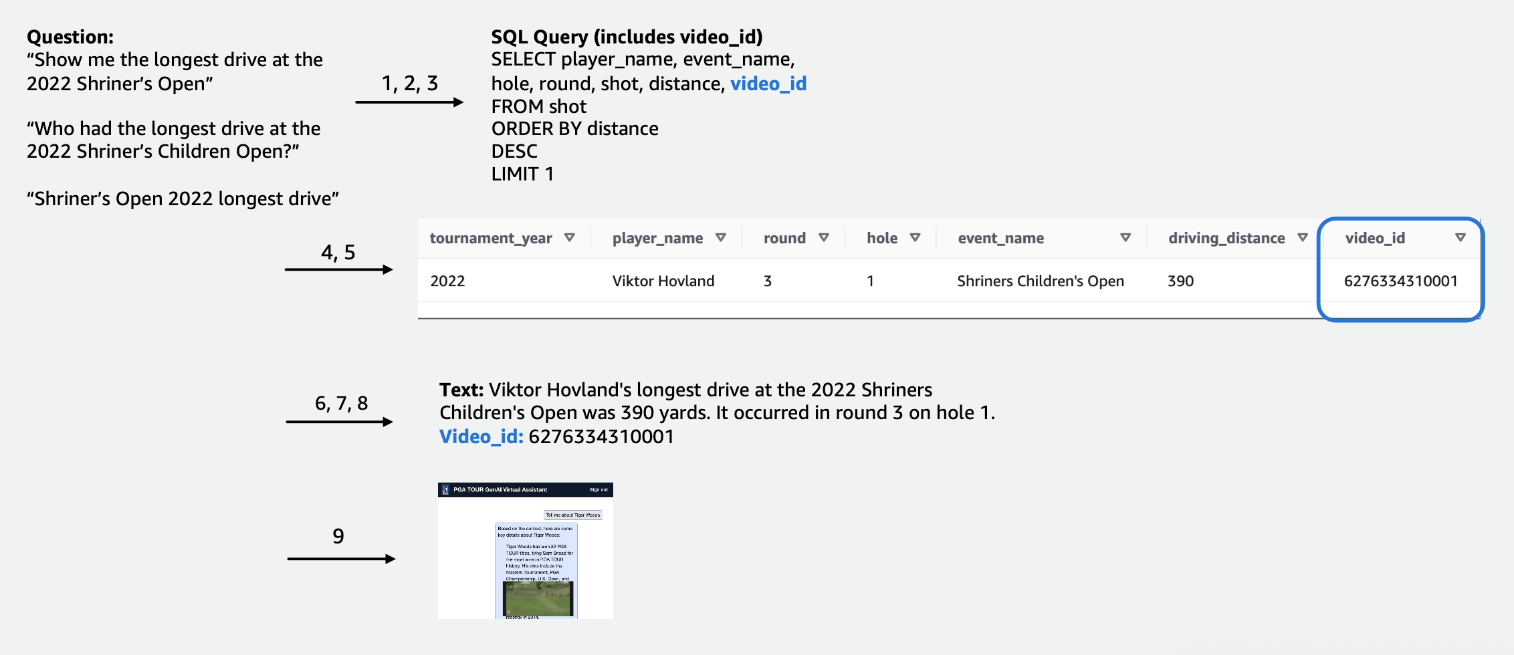
Na figura a seguir demonstramos nosso pipeline ponta a ponta. Nós usamos AWS Lambda como nossa função de orquestração responsável pela interação com diversas fontes de dados, LLMs e correção de erros com base na consulta do usuário. As etapas 1 a 8 são semelhantes às mostradas na figura a seguir. Existem pequenas alterações nos dados não estruturados, que discutiremos a seguir.
Os dados de texto requerem etapas de processamento exclusivas que fragmentam (ou segmentam) documentos longos em partes digeríveis pelo LLM, enquanto mantêm a coerência do tópico. Experimentamos diversas abordagens e estabelecemos um esquema de segmentação no nível da página que se alinhou bem com o formato dos Guias de Mídia. Utilizamos o Amazon Kendra, que é um serviço gerenciado que cuida da indexação de documentos, sem exigir especificação de embeddings, ao mesmo tempo que fornece uma API fácil de recuperação. A figura a seguir ilustra essa arquitetura.

O pipeline unificado e escalável que desenvolvemos permite que o PGA TOUR seja dimensionado para todo o seu histórico de dados, alguns dos quais remontam ao século XIX. Ele permite que aplicativos futuros que podem ser transmitidos ao vivo no contexto do curso criem experiências ricas em tempo real.
Desenvolvimento: Avaliando LLMs e desenvolvendo aplicações generativas de IA
Testamos e avaliamos cuidadosamente os LLMs próprios e de terceiros disponíveis no Amazon Bedrock para escolher o modelo mais adequado para nosso pipeline e caso de uso. Selecionamos Claude v2 e Claude Instant da Anthropic no Amazon Bedrock. Para nosso pipeline final de dados estruturados e não estruturados, observamos que Claude 2 da Anthropic no Amazon Bedrock gerou melhores resultados gerais para nosso pipeline de dados final.
A solicitação é um aspecto crítico para fazer com que os LLMs produzam o texto conforme desejado. Passamos um tempo considerável experimentando diferentes prompts para cada uma das tarefas. Por exemplo, para o pipeline de texto para SQL, tivemos vários prompts de fallback, com especificidade crescente e esquemas de tabela gradualmente simplificados. Se uma consulta SQL fosse inválida e resultasse em um erro do Athena, desenvolvemos um prompt de correção de erros que transmitiria o erro e o SQL incorreto ao LLM e solicitaria a correção. O prompt final no pipeline de texto para SQL solicita que o LLM pegue a saída do Athena, que pode ser fornecida em formato Markdown ou CSV, e forneça uma resposta ao usuário. Para o texto não estruturado, desenvolvemos prompts gerais para usar o contexto recuperado do Amazon Kendra para responder à pergunta do usuário. O prompt incluía instruções para usar apenas as informações recuperadas do Amazon Kendra e não confiar nos dados do pré-treinamento do LLM.
A latência costuma ser uma preocupação em aplicações generativas de IA, e também é o caso aqui. É especialmente uma preocupação para texto para SQL, que requer uma invocação LLM de geração SQL inicial, seguida por uma invocação LLM de geração de resposta. Se estivermos usando um LLM grande, como o Claude V2 da Anthropic, isso efetivamente dobra a latência de apenas uma invocação do LLM. Experimentamos diversas configurações de LLMs grandes e menores para avaliar o tempo de execução, bem como a correção. A tabela a seguir mostra um exemplo de uma pergunta que demonstra a latência, bem como as respostas geradas com Claude V2 e Claude Instant da Anthropic no Amazon Bedrock.

Protótipo
Em nossa aplicação, usamos uma função Lambda para orquestrar as escolhas imediatas e a comunicação entre Amazon Athena, Amazon Kendra e Amazon Bedrock. O assistente virtual possui uma interface conversacional, construída com React e Cloudscape Design System, que utiliza texto e vídeos para interagir com os usuários.
Nosso assistente virtual pode responder a uma ampla gama de perguntas sobre eventos, jogadores, estatísticas, história do PGA TOUR e muito mais. Por exemplo, quando questionado sobre os percursos mais longos de Tony Finau no Shriners Children's Open (um dos eventos exclusivos do PGA TOUR), o assistente pode consultar dados estruturados para extrair seus dados de nível de tacada. Ele pode extrair a distância exata em jardas, o número redondo e o buraco durante o qual ele alcançou esse registro usando o pipeline de texto para SQL. O assistente então interpreta esses dados numéricos para gerar uma resposta final. A tabela a seguir contém alguns exemplos de respostas.
| Questão | Resposta |
| Qual foi o percurso mais longo atingido por Tony Finau no Shriners Children's Open? | O drive mais longo atingido por Tony Finau no Shriners Children's Open foi de 382 jardas, que ele acertou durante a primeira rodada no buraco número 4 em 2018. |
| Qual foi o percurso mais longo atingido por Collin Morikawa no Shriners Children's Open? | A corrida mais longa de Collin Morikawa no Shriners Childrens Open foi de 334 jardas. Isso ocorreu em 2019 durante a primeira rodada do buraco 15. |
| Alguém fez um ás no Shriners Children's Open de 2022? | Sim, Adam Hadwin fez um hole-in-one no buraco 14 durante a terceira rodada do Shriners Children's Open de 3 |
O vídeo explicativo a seguir destaca alguns exemplos de interação com o assistente virtual.
Nos testes iniciais, nosso assistente virtual PGA TOUR mostrou-se muito promissor na melhoria da experiência dos fãs. Ao combinar tecnologias de IA como texto para SQL, pesquisa semântica e geração de linguagem natural, o assistente fornece respostas informativas e envolventes. Os fãs têm a oportunidade de acessar facilmente dados e narrativas que antes eram difíceis de encontrar.
O que o futuro guarda?
À medida que continuamos o desenvolvimento, expandiremos a gama de perguntas que nosso assistente virtual pode responder. Isto exigirá testes extensivos, através da colaboração entre a AWS e o PGA TOUR. Com o tempo, pretendemos evoluir o assistente para uma experiência omnicanal personalizada, acessível através de interfaces web, móveis e de voz.
O estabelecimento de um assistente de IA generativo baseado na nuvem permite ao PGA TOUR apresentar a sua vasta fonte de dados a múltiplas partes interessadas internas e externas. À medida que o cenário da IA geradora de esportes evolui, ele permite a criação de novos conteúdos. Por exemplo, você pode usar IA e aprendizado de máquina (ML) para revelar o conteúdo que os fãs desejam ver enquanto assistem a um evento ou enquanto as equipes de produção procuram cenas de torneios anteriores que correspondam a um evento atual. Por exemplo, se Max Homa estiver se preparando para dar sua última tacada no PGA TOUR Championship de um local a 20 pés do pin, o PGA TOUR pode usar IA e ML para identificar e apresentar clipes dele, com comentários gerados por IA. tentando um tiro semelhante cinco vezes anteriormente. Esse tipo de acesso e dados permite que uma equipe de produção agregue imediatamente valor à transmissão ou permita que um fã personalize o tipo de dados que deseja ver.
“O PGA TOUR é líder do setor no uso de tecnologia de ponta para melhorar a experiência dos torcedores. A IA está na vanguarda da nossa pilha de tecnologia, permitindo-nos criar um ambiente mais envolvente e interativo para os fãs. Este é o início de nossa jornada de IA generativa em colaboração com o AWS Generative AI Innovation Center para uma experiência transformacional do cliente de ponta a ponta. Estamos trabalhando para aproveitar o Amazon Bedrock e nossos dados de propriedade para criar uma experiência interativa para os fãs do PGA TOUR encontrarem informações de interesse sobre um evento, jogador, estatísticas ou outro conteúdo de forma interativa.”
– Scott Gutterman, vice-presidente sênior de transmissão e propriedades digitais da PGA TOUR.
Conclusão
O projeto que discutimos nesta postagem exemplifica como fontes de dados estruturados e não estruturados podem ser fundidas usando IA para criar assistentes virtuais de próxima geração. Para as organizações desportivas, esta tecnologia permite um envolvimento mais envolvente dos adeptos e desbloqueia eficiências internas. A inteligência de dados que apresentamos ajuda as partes interessadas do PGA TOUR, como jogadores, treinadores, dirigentes, parceiros e mídia, a tomar decisões informadas com mais rapidez. Além dos esportes, nossa metodologia pode ser replicada em qualquer setor. Os mesmos princípios se aplicam aos assistentes de construção que envolvem clientes, funcionários, estudantes, pacientes e outros usuários finais. Com design e testes criteriosos, praticamente qualquer organização pode se beneficiar de um sistema de IA que contextualiza seus bancos de dados estruturados, documentos, imagens, vídeos e outros conteúdos.
Se você estiver interessado em implementar funcionalidades semelhantes, considere usar Agentes da Amazon Bedrock e Bases de conhecimento para Amazon Bedrock como uma solução alternativa totalmente gerenciada pela AWS. Esta abordagem poderia investigar melhor o fornecimento de automação inteligente e habilidades de pesquisa de dados por meio de agentes personalizáveis. Esses agentes poderiam potencialmente transformar as interações do usuário com os aplicativos para que sejam mais naturais, eficientes e eficazes.
Sobre os autores
 Scott Gutterman é o vice-presidente sênior de operações digitais do PGA TOUR. Ele é responsável pelas operações digitais gerais do TOUR, pelo desenvolvimento de produtos e está conduzindo sua estratégia GenAI.
Scott Gutterman é o vice-presidente sênior de operações digitais do PGA TOUR. Ele é responsável pelas operações digitais gerais do TOUR, pelo desenvolvimento de produtos e está conduzindo sua estratégia GenAI.
 Ahsan Ali é Cientista Aplicado no Amazon Generative AI Innovation Center, onde trabalha com clientes de diferentes domínios para resolver seus problemas urgentes e caros usando IA Generativa.
Ahsan Ali é Cientista Aplicado no Amazon Generative AI Innovation Center, onde trabalha com clientes de diferentes domínios para resolver seus problemas urgentes e caros usando IA Generativa.
 Tahin Syed é cientista aplicado no Amazon Generative AI Innovation Center, onde trabalha com clientes para ajudar a obter resultados de negócios com soluções de IA generativa. Fora do trabalho, ele gosta de experimentar novas comidas, viajar e ensinar taekwondo.
Tahin Syed é cientista aplicado no Amazon Generative AI Innovation Center, onde trabalha com clientes para ajudar a obter resultados de negócios com soluções de IA generativa. Fora do trabalho, ele gosta de experimentar novas comidas, viajar e ensinar taekwondo.
 Grace Lang é engenheiro associado de dados e ML da AWS Professional Services. Motivada pela paixão por superar desafios difíceis, Grace ajuda os clientes a atingir seus objetivos desenvolvendo soluções baseadas em aprendizado de máquina.
Grace Lang é engenheiro associado de dados e ML da AWS Professional Services. Motivada pela paixão por superar desafios difíceis, Grace ajuda os clientes a atingir seus objetivos desenvolvendo soluções baseadas em aprendizado de máquina.
 Jae Lee é Gerente Sênior de Engajamento na vertical de M&A da ProServe. Ela lidera e entrega compromissos complexos, exibe fortes conjuntos de habilidades para resolução de problemas, gerencia as expectativas das partes interessadas e faz a curadoria de apresentações de nível executivo. Ela gosta de trabalhar em projetos focados em esportes, IA generativa e experiência do cliente.
Jae Lee é Gerente Sênior de Engajamento na vertical de M&A da ProServe. Ela lidera e entrega compromissos complexos, exibe fortes conjuntos de habilidades para resolução de problemas, gerencia as expectativas das partes interessadas e faz a curadoria de apresentações de nível executivo. Ela gosta de trabalhar em projetos focados em esportes, IA generativa e experiência do cliente.
 Karn Chahar é consultor de segurança da equipe de entrega compartilhada da AWS. Ele é um entusiasta da tecnologia que gosta de trabalhar com os clientes para solucionar seus desafios de segurança e melhorar sua postura de segurança na nuvem.
Karn Chahar é consultor de segurança da equipe de entrega compartilhada da AWS. Ele é um entusiasta da tecnologia que gosta de trabalhar com os clientes para solucionar seus desafios de segurança e melhorar sua postura de segurança na nuvem.
 Mike Amjadi é engenheiro de dados e ML do AWS ProServe focado em permitir que os clientes maximizem o valor dos dados. Ele é especialista em projetar, construir e otimizar pipelines de dados seguindo princípios bem arquitetados. Mike é apaixonado por usar tecnologia para resolver problemas e está comprometido em entregar os melhores resultados para nossos clientes.
Mike Amjadi é engenheiro de dados e ML do AWS ProServe focado em permitir que os clientes maximizem o valor dos dados. Ele é especialista em projetar, construir e otimizar pipelines de dados seguindo princípios bem arquitetados. Mike é apaixonado por usar tecnologia para resolver problemas e está comprometido em entregar os melhores resultados para nossos clientes.
 Vrushali Sawant é engenheiro front-end da Proserve. Ela é altamente qualificada na criação de sites responsivos. Ela adora trabalhar com clientes, entendendo seus requisitos e fornecendo-lhes soluções UI/UX escaláveis e fáceis de adotar.
Vrushali Sawant é engenheiro front-end da Proserve. Ela é altamente qualificada na criação de sites responsivos. Ela adora trabalhar com clientes, entendendo seus requisitos e fornecendo-lhes soluções UI/UX escaláveis e fáceis de adotar.
 Neelam Patel é gerente de soluções de clientes na AWS, liderando as principais iniciativas de IA generativa e modernização da nuvem. Neelam trabalha com os principais executivos e proprietários de tecnologia para enfrentar os desafios de transformação da nuvem e ajuda os clientes a maximizar os benefícios da adoção da nuvem. Ela possui MBA pela Warwick Business School, Reino Unido, e bacharelado em Engenharia da Computação, Índia.
Neelam Patel é gerente de soluções de clientes na AWS, liderando as principais iniciativas de IA generativa e modernização da nuvem. Neelam trabalha com os principais executivos e proprietários de tecnologia para enfrentar os desafios de transformação da nuvem e ajuda os clientes a maximizar os benefícios da adoção da nuvem. Ela possui MBA pela Warwick Business School, Reino Unido, e bacharelado em Engenharia da Computação, Índia.
 Murali Baktha é arquiteto global de soluções de golfe na AWS e lidera iniciativas importantes que envolvem IA generativa, análise de dados e tecnologias de nuvem de ponta. Murali trabalha com os principais executivos e proprietários de tecnologia para compreender os desafios de negócios dos clientes e projetar soluções para enfrentar esses desafios. Ele tem MBA em Finanças pela UConn e doutorado pela Iowa State University.
Murali Baktha é arquiteto global de soluções de golfe na AWS e lidera iniciativas importantes que envolvem IA generativa, análise de dados e tecnologias de nuvem de ponta. Murali trabalha com os principais executivos e proprietários de tecnologia para compreender os desafios de negócios dos clientes e projetar soluções para enfrentar esses desafios. Ele tem MBA em Finanças pela UConn e doutorado pela Iowa State University.
 Mehdi Noor é gerente de ciências aplicadas no Generative Ai Innovation Center. Com uma paixão por unir tecnologia e inovação, ele auxilia os clientes da AWS a liberar o potencial da IA generativa, transformando desafios potenciais em oportunidades para experimentação e inovação rápidas, concentrando-se em usos escaláveis, mensuráveis e impactantes de tecnologias avançadas de IA e simplificando o caminho. para a produção.
Mehdi Noor é gerente de ciências aplicadas no Generative Ai Innovation Center. Com uma paixão por unir tecnologia e inovação, ele auxilia os clientes da AWS a liberar o potencial da IA generativa, transformando desafios potenciais em oportunidades para experimentação e inovação rápidas, concentrando-se em usos escaláveis, mensuráveis e impactantes de tecnologias avançadas de IA e simplificando o caminho. para a produção.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/the-journey-of-pga-tours-generative-ai-virtual-assistant-from-concept-to-development-to-prototype/

