Grunnmodeller (FM) er modeller for store maskinlæring (ML) som er trent på et bredt spekter av umerkede og generaliserte datasett. FM-er, som navnet antyder, gir grunnlaget for å bygge mer spesialiserte nedstrømsapplikasjoner, og er unike i sin tilpasningsevne. De kan utføre et bredt spekter av forskjellige oppgaver, som naturlig språkbehandling, klassifisering av bilder, forutsig trender, analysere følelser og svare på spørsmål. Denne skalaen og generell tilpasningsevne er det som gjør FM-er forskjellig fra tradisjonelle ML-modeller. FM-er er multimodale; de jobber med forskjellige datatyper som tekst, video, lyd og bilder. Store språkmodeller (LLM) er en type FM og er forhåndsopplært på enorme mengder tekstdata og har vanligvis applikasjonsbruk som tekstgenerering, intelligente chatbots eller oppsummering.
Streaming av data letter den konstante flyten av mangfoldig og oppdatert informasjon, og forbedrer modellenes evne til å tilpasse og generere mer nøyaktige, kontekstuelt relevante utdata. Denne dynamiske integrasjonen av strømmedata muliggjør generativ AI applikasjoner for å reagere raskt på endrede forhold, forbedre deres tilpasningsevne og generelle ytelse i ulike oppgaver.
For bedre å forstå dette, se for deg en chatbot som hjelper reisende med å bestille reisen. I dette scenariet trenger chatboten sanntidstilgang til flyselskapets beholdning, flystatus, hotellbeholdning, siste prisendringer og mer. Disse dataene kommer vanligvis fra tredjeparter, og utviklere må finne en måte å innta disse dataene og behandle dataendringene etter hvert som de skjer.
Batchbehandling passer ikke best i dette scenariet. Når data endres raskt, kan behandling av dem i en batch resultere i at foreldede data blir brukt av chatboten, og gir unøyaktig informasjon til kunden, noe som påvirker den generelle kundeopplevelsen. Strømbehandling kan imidlertid gjøre det mulig for chatboten å få tilgang til sanntidsdata og tilpasse seg endringer i tilgjengelighet og pris, noe som gir den beste veiledningen til kunden og forbedrer kundeopplevelsen.
Et annet eksempel er en AI-drevet observerbarhets- og overvåkingsløsning der FM-er overvåker sanntids interne beregninger av et system og produserer varsler. Når modellen finner en anomali eller unormal metrisk verdi, bør den umiddelbart gi et varsel og varsle operatøren. Verdien av slike viktige data avtar imidlertid betydelig over tid. Disse varslene bør ideelt sett mottas innen sekunder eller til og med mens det skjer. Hvis operatører mottar disse varslene minutter eller timer etter at de skjedde, er ikke en slik innsikt mulig og har potensielt mistet sin verdi. Du kan finne lignende brukssaker i andre bransjer som detaljhandel, bilproduksjon, energi og finansnæringen.
I dette innlegget diskuterer vi hvorfor datastrømming er en avgjørende komponent i generative AI-applikasjoner på grunn av sanntidsnaturen. Vi diskuterer verdien av AWS datastrømmetjenester som f.eks Amazon administrerte strømming for Apache Kafka (Amazon MSK), Amazon Kinesis datastrømmer, Amazon Managed Service for Apache Flinkog Amazon Kinesis Data Firehose i å bygge generative AI-applikasjoner.
Innlæring i kontekst
LLM-er er trent med punkt-i-tidsdata og har ingen iboende evne til å få tilgang til ferske data på inferenstidspunkt. Etter hvert som nye data dukker opp, må du kontinuerlig finjustere eller videreutdanne modellen. Dette er ikke bare en kostbar operasjon, men også svært begrensende i praksis fordi hastigheten på ny datagenerering langt erstatter hastigheten på finjustering. I tillegg mangler LLM-er kontekstuell forståelse og stoler utelukkende på treningsdataene deres, og er derfor utsatt for hallusinasjoner. Dette betyr at de kan generere en flytende, sammenhengende og syntaktisk lyd, men faktisk feil respons. De er også blottet for relevans, personalisering og kontekst.
LLM-er har imidlertid kapasitet til å lære av dataene de mottar fra konteksten for å svare mer nøyaktig uten å endre modellvektene. Dette kalles læring i kontekst, og kan brukes til å produsere personlige svar eller gi et nøyaktig svar i sammenheng med organisasjonens retningslinjer.
For eksempel, i en chatbot, kan datahendelser vedrøre en beholdning av flyreiser og hoteller eller prisendringer som kontinuerlig tas inn i en strømmelagringsmotor. Videre blir datahendelser filtrert, beriket og transformert til et forbruksformat ved hjelp av en strømprosessor. Resultatet gjøres tilgjengelig for applikasjonen ved å spørre etter det siste øyeblikksbildet. Øyeblikksbildet oppdateres kontinuerlig gjennom strømbehandling; derfor gis de oppdaterte dataene i sammenheng med en brukerforespørsel til modellen. Dette gjør at modellen kan tilpasse seg de siste endringene i pris og tilgjengelighet. Følgende diagram illustrerer en grunnleggende arbeidsflyt for læring i kontekst.
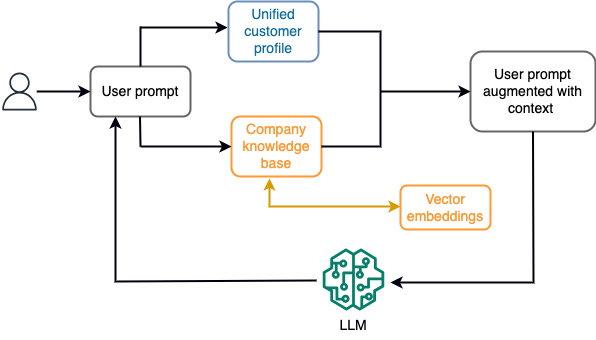
En ofte brukt tilnærming for læring i kontekst er å bruke en teknikk kalt Retrieval Augmented Generation (RAG). I RAG oppgir du relevant informasjon, for eksempel mest relevante retningslinjer og kunderegistre, sammen med brukerspørsmålet til ledeteksten. På denne måten genererer LLM et svar på brukerspørsmålet ved å bruke tilleggsinformasjon gitt som kontekst. For å lære mer om RAG, se Svar på spørsmål ved å bruke Retrieval Augmented Generation med grunnmodeller i Amazon SageMaker JumpStart.
En RAG-basert generativ AI-applikasjon kan bare produsere generiske svar basert på opplæringsdataene og de relevante dokumentene i kunnskapsbasen. Denne løsningen kommer til kort når det forventes et personlig tilpasset svar i nær sanntid fra applikasjonen. For eksempel forventes en reisechatbot å vurdere brukerens nåværende bestillinger, tilgjengelig hotell- og flybeholdning og mer. Dessuten er de relevante kundeopplysningene (ofte kjent som enhetlig kundeprofil) kan vanligvis endres. Hvis en batchprosess brukes for å oppdatere den generative AIs brukerprofildatabase, kan kunden motta misfornøyde svar basert på gamle data.
I dette innlegget diskuterer vi bruken av strømbehandling for å forbedre en RAG-løsning som brukes til å bygge spørsmålssvarsagenter med kontekst fra sanntidstilgang til enhetlige kundeprofiler og organisasjonskunnskapsbase.
Nesten sanntids kundeprofiloppdateringer
Kundeposter er vanligvis distribuert på tvers av datalagre i en organisasjon. For at din generative AI-applikasjon skal gi en relevant, nøyaktig og oppdatert kundeprofil, er det avgjørende å bygge strømmedatapipelines som kan utføre identitetsoppløsning og profilaggregering på tvers av de distribuerte datalagrene. Strømmejobber tar stadig inn nye data for å synkronisere på tvers av systemer og kan utføre berikelse, transformasjoner, sammenføyninger og aggregering på tvers av tidsvinduer mer effektivt. Change data capture (CDC)-hendelser inneholder informasjon om kildeposten, oppdateringer og metadata som tid, kilde, klassifisering (sett inn, oppdater eller slett), og initiativtakeren til endringen.
Følgende diagram illustrerer et eksempel på en arbeidsflyt for CDC-streaming-inntak og -behandling for enhetlige kundeprofiler.

I denne delen diskuterer vi hovedkomponentene i et CDC-strømmemønster som kreves for å støtte RAG-baserte generative AI-applikasjoner.
CDC-streaminginntak
En CDC-replikator er en prosess som samler inn dataendringer fra et kildesystem (vanligvis ved å lese transaksjonslogger eller binlogger) og skriver CDC-hendelser med nøyaktig samme rekkefølge som de skjedde i en streaming datastrøm eller emne. Dette innebærer en loggbasert fangst med verktøy som f.eks AWS Database Migration Service (AWS DMS) eller open source-kontakter som Debezium for Apache Kafka connect. Apache Kafka Connect er en del av Apache Kafka-miljøet, slik at data kan tas inn fra ulike kilder og leveres til en rekke destinasjoner. Du kan kjøre Apache Kafka-kontakten på Amazon MSK Connect innen minutter uten å bekymre deg for konfigurasjon, oppsett og drift av en Apache Kafka-klynge. Du trenger bare å laste opp koblingens kompilerte kode til Amazon enkel lagringstjeneste (Amazon S3) og sett opp kontakten din med arbeidsbelastningens spesifikke konfigurasjon.
Det finnes også andre metoder for å fange dataendringer. For eksempel, Amazon DynamoDB gir en funksjon for å streame CDC-data til Amazon DynamoDB-strømmer eller Kinesis datastrømmer. Amazon S3 gir en trigger for å påkalle en AWS Lambda funksjon når et nytt dokument er lagret.
Streaming lagring
Streaminglagring fungerer som en mellombuffer for å lagre CDC-hendelser før de blir behandlet. Streaminglagring gir pålitelig lagring for streaming av data. Ved utforming er den svært tilgjengelig og motstandsdyktig mot maskinvare- eller nodefeil og opprettholder rekkefølgen på hendelsene slik de er skrevet. Streaminglagring kan lagre datahendelser enten permanent eller i en bestemt tidsperiode. Dette gjør at strømprosessorer kan lese fra deler av strømmen hvis det er en feil eller behov for re-prosessering. Kinesis Data Streams er en serverløs strømmedatatjeneste som gjør det enkelt å fange opp, behandle og lagre datastrømmer i stor skala. Amazon MSK er en fullstendig administrert, svært tilgjengelig og sikker tjeneste levert av AWS for å kjøre Apache Kafka.
Stream behandling
Strømbehandlingssystemer bør utformes for parallellitet for å håndtere høy datagjennomstrømning. De bør partisjonere inngangsstrømmen mellom flere oppgaver som kjører på flere beregningsnoder. Oppgaver skal kunne sende resultatet av en operasjon til den neste over nettverket, noe som gjør det mulig å behandle data parallelt mens de utfører operasjoner som sammenføyninger, filtrering, berikelse og aggregering. Strømbehandlingsapplikasjoner bør være i stand til å behandle hendelser med hensyn til hendelsestidspunktet for brukstilfeller der hendelser kan komme for sent eller korrekt beregning er avhengig av tidspunktet hendelser inntreffer i stedet for systemtiden. For mer informasjon, se Forestillinger om tid: hendelsestid og behandlingstid.
Strømprosesser produserer kontinuerlig resultater i form av datahendelser som må sendes til et målsystem. Et målsystem kan være et hvilket som helst system som kan integreres direkte med prosessen eller via strømmelagring som i mellomledd. Avhengig av rammeverket du velger for strømbehandling, vil du ha forskjellige alternativer for målsystemer avhengig av tilgjengelige synkekoblinger. Hvis du bestemmer deg for å skrive resultatene til en mellomliggende strømmelagring, kan du bygge en egen prosess som leser hendelser og bruker endringer på målsystemet, for eksempel å kjøre en Apache Kafka sink-kobling. Uavhengig av hvilket alternativ du velger, trenger CDC-data ekstra håndtering på grunn av sin natur. Fordi CDC-hendelser inneholder informasjon om oppdateringer eller slettinger, er det viktig at de smelter sammen i målsystemet i riktig rekkefølge. Hvis endringer brukes i feil rekkefølge, vil målsystemet være ute av synkronisering med kilden.
Apache Flash er et kraftig strømbehandlingsrammeverk kjent for sin lave latens og høye gjennomstrømningsevner. Den støtter prosessering av hendelsestid, semantikk for eksakt éngangsbehandling og høy feiltoleranse. I tillegg gir den innfødt støtte for CDC-data via en spesiell struktur kalt dynamiske tabeller. Dynamiske tabeller etterligner kildedatabasetabellene og gir en kolonnerepresentasjon av strømmedataene. Dataene i dynamiske tabeller endres med hver hendelse som behandles. Nye poster kan legges til, oppdateres eller slettes når som helst. Dynamiske tabeller abstraherer bort den ekstra logikken du trenger å implementere for hver postoperasjon (sett inn, oppdater, slett) separat. For mer informasjon, se Dynamiske tabeller.
Med Amazon Managed Service for Apache Flink, kan du kjøre Apache Flink-jobber og integrere med andre AWS-tjenester. Det er ingen servere og klynger å administrere, og det er ingen data- og lagringsinfrastruktur å sette opp.
AWS Lim er en fullstendig administrert ETL-tjeneste (extract, transform and load), noe som betyr at AWS håndterer infrastrukturtilførsel, skalering og vedlikehold for deg. Selv om det først og fremst er kjent for sine ETL-funksjoner, kan AWS Glue også brukes til Spark-streamingapplikasjoner. AWS Glue kan samhandle med strømmedatatjenester som Kinesis Data Streams og Amazon MSK for å behandle og transformere CDC-data. AWS Glue kan også sømløst integreres med andre AWS-tjenester som Lambda, AWS trinnfunksjoner, og DynamoDB, som gir deg et omfattende økosystem for å bygge og administrere databehandlingsrørledninger.
Samlet kundeprofil
Å overvinne foreningen av kundeprofilen på tvers av en rekke kildesystemer krever utvikling av robuste datapipelines. Du trenger datapipelines som kan bringe og synkronisere alle poster til ett datalager. Dette datalageret gir organisasjonen den helhetlige kunderegistreringsvisningen som er nødvendig for operasjonell effektivitet av RAG-baserte generative AI-applikasjoner. For å bygge et slikt datalager vil et ustrukturert datalager være best.
En identitetsgraf er en nyttig struktur for å lage en enhetlig kundeprofil fordi den konsoliderer og integrerer kundedata fra ulike kilder, sikrer datanøyaktighet og deduplisering, tilbyr sanntidsoppdateringer, kobler sammen innsikt på tvers av systemer, muliggjør personalisering, forbedrer kundeopplevelsen, og støtter overholdelse av regelverk. Denne enhetlige kundeprofilen gir den generative AI-applikasjonen mulighet til å forstå og engasjere seg effektivt med kunder, og overholde forskrifter for personvern, noe som til syvende og sist forbedrer kundeopplevelser og driver virksomhetsvekst. Du kan bygge din identitetsgrafløsning ved å bruke Amazon Neptun, en rask, pålitelig, fullstendig administrert grafdatabasetjeneste.
AWS tilbyr noen få andre administrerte og serverløse NoSQL-lagringstjenester for ustrukturerte nøkkelverdiobjekter. Amazon DocumentDB (med MongoDB-kompatibilitet) er en rask, skalerbar, svært tilgjengelig og fullt administrert virksomhet dokumentdatabase tjeneste som støtter innfødte JSON-arbeidsbelastninger. DynamoDB er en fullstendig administrert NoSQL-databasetjeneste som gir rask og forutsigbar ytelse med sømløs skalerbarhet.
Nesten sanntid oppdateringer av organisasjonskunnskapsbase
I likhet med kunderegistre er interne kunnskapsarkiver som firmapolicyer og organisasjonsdokumenter kuttet på tvers av lagringssystemer. Dette er vanligvis ustrukturerte data og oppdateres på en ikke-inkrementell måte. Bruken av ustrukturerte data for AI-applikasjoner er effektiv ved bruk av vektorinnbygginger, som er en teknikk for å representere høydimensjonale data som tekstfiler, bilder og lydfiler som flerdimensjonale numeriske.
AWS gir flere vektormotortjenester, Eksempel Amazon OpenSearch Serverless, Amazon Kendraog Amazon Aurora PostgreSQL-kompatibel utgave med pgvector-utvidelsen for lagring av vektorinnbygginger. Generative AI-applikasjoner kan forbedre brukeropplevelsen ved å transformere brukermeldingen til en vektor og bruke den til å spørre vektormotoren for å hente kontekstuelt relevant informasjon. Både forespørselen og vektordataene som hentes, sendes deretter til LLM for å motta et mer presist og personlig svar.
Følgende diagram illustrerer et eksempel på strømbehandlingsarbeidsflyt for vektorinnbygginger.
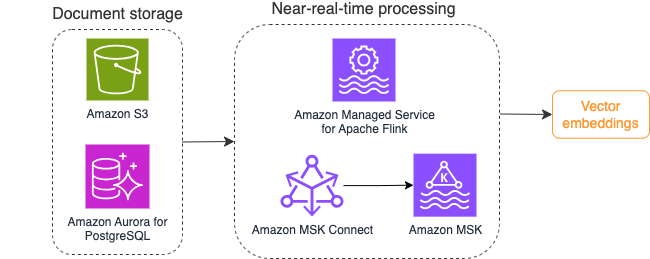
Kunnskapsbasens innhold må konverteres til vektorinnbygginger før det skrives til vektordatalageret. Amazonas grunnfjell or Amazon SageMaker kan hjelpe deg med å få tilgang til modellen du ønsker og avsløre et privat endepunkt for denne konverteringen. Videre kan du bruke biblioteker som LangChain for å integrere med disse endepunktene. Å bygge en batchprosess kan hjelpe deg med å konvertere kunnskapsbaseinnholdet ditt til vektordata og lagre det i en vektordatabase til å begynne med. Du må imidlertid stole på et intervall for å behandle dokumentene på nytt for å synkronisere vektordatabasen din med endringer i kunnskapsbasens innhold. Med et stort antall dokumenter kan denne prosessen være ineffektiv. Mellom disse intervallene vil dine generative AI-applikasjonsbrukere motta svar i henhold til det gamle innholdet, eller vil motta et unøyaktig svar fordi det nye innholdet ikke er vektorisert ennå.
Strømbehandling er en ideell løsning for disse utfordringene. Den produserer hendelser i henhold til eksisterende dokumenter i utgangspunktet og overvåker videre kildesystemet og oppretter en dokumentendringshendelse så snart de oppstår. Disse hendelsene kan lagres i strømmelagring og vente på å bli behandlet av en strømmejobb. En strømmejobb leser disse hendelsene, laster inn innholdet i dokumentet og transformerer innholdet til en rekke relaterte tokens av ord. Hvert token forvandles videre til vektordata via et API-kall til en innebygd FM. Resultatene sendes for lagring til vektorlageret via en synkeoperatør.
Hvis du bruker Amazon S3 for å lagre dokumentene dine, kan du bygge en hendelseskildearkitektur basert på S3-objektendringstriggere for Lambda. En Lambda-funksjon kan opprette en hendelse i ønsket format og skrive den til strømmelagringen din.
Du kan også bruke Apache Flink til å kjøre som en strømmejobb. Apache Flink gir den opprinnelige FileSystem-kildekoblingen, som kan oppdage eksisterende filer og lese innholdet i utgangspunktet. Etter det kan den kontinuerlig overvåke filsystemet ditt for nye filer og fange opp innholdet deres. Koblingen støtter lesing av et sett med filer fra distribuerte filsystemer som Amazon S3 eller HDFS med et format med ren tekst, Avro, CSV, Parkett og mer, og produserer en streaming-post. Som en fullstendig administrert tjeneste, fjerner Managed Service for Apache Flink den operative overheaden ved distribusjon og vedlikehold av Flink-jobber, slik at du kan fokusere på å bygge og skalere strømmeapplikasjonene dine. Med sømløs integrasjon i AWS-strømmetjenestene som Amazon MSK eller Kinesis Data Streams, gir den funksjoner som automatisk skalering, sikkerhet og robusthet, og gir pålitelige og effektive Flink-applikasjoner for håndtering av sanntidsstrømmedata.
Basert på dine DevOps-preferanser kan du velge mellom Kinesis Data Streams eller Amazon MSK for lagring av streamingpostene. Kinesis Data Streams forenkler kompleksiteten ved å bygge og administrere tilpassede streamingdataapplikasjoner, slik at du kan fokusere på å hente innsikt fra dataene dine i stedet for vedlikehold av infrastruktur. Kunder som bruker Apache Kafka velger ofte Amazon MSK på grunn av dets enkelhet, skalerbarhet og pålitelighet i å overvåke Apache Kafka-klynger i AWS-miljøet. Som en fullt administrert tjeneste tar Amazon MSK på seg operasjonelle kompleksiteten knyttet til distribusjon og vedlikehold av Apache Kafka-klynger, slik at du kan konsentrere deg om å konstruere og utvide strømmeapplikasjonene dine.
Fordi en RESTful API-integrasjon passer til denne prosessens natur, trenger du et rammeverk som støtter et stateful berikelsesmønster via RESTful API-kall for å spore feil og prøve på nytt for den mislykkede forespørselen. Apache Flink er igjen et rammeverk som kan utføre tilstandsfulle operasjoner i minnehastighet. For å forstå de beste måtene å foreta API-anrop via Apache Flink, se Vanlige mønstre for berikelse av strømmedata i Amazon Kinesis Data Analytics for Apache Flink.
Apache Flink gir native sink-kontakter for å skrive data til vektordatalagre som Amazon Aurora for PostgreSQL med pgvector eller Amazon OpenSearch-tjeneste med VectorDB. Alternativt kan du iscenesette Flink-jobbens utgang (vektoriserte data) i et MSK-emne eller en Kinesis-datastrøm. OpenSearch Service gir støtte for innfødt inntak fra Kinesis-datastrømmer eller MSK-emner. For mer informasjon, se Vi introduserer Amazon MSK som en kilde for Amazon OpenSearch Ingestion og Laster strømmedata fra Amazon Kinesis Data Streams.
Tilbakemeldingsanalyse og finjustering
Det er viktig for datadriftsledere og AI/ML-utviklere å få innsikt om ytelsen til den generative AI-applikasjonen og FM-ene som er i bruk. For å oppnå det, må du bygge datapipelines som beregner viktige nøkkelytelsesindikatorer (KPI) basert på tilbakemeldinger fra brukerne og en rekke applikasjonslogger og beregninger. Denne informasjonen er nyttig for interessenter for å få sanntidsinnsikt om ytelsen til FM, applikasjonen og generell brukertilfredshet om kvaliteten på støtten de mottar fra applikasjonen din. Du må også samle inn og lagre samtalehistorikken for ytterligere å finjustere FM-ene dine for å forbedre deres evne til å utføre domenespesifikke oppgaver.
Denne brukssaken passer veldig bra i streaminganalysedomenet. Applikasjonen din skal lagre hver samtale i strømmelagring. Applikasjonen din kan spørre brukerne om deres vurdering av hvert svars nøyaktighet og deres generelle tilfredshet. Disse dataene kan være i et format med et binært valg eller en tekst i fri form. Disse dataene kan lagres i en Kinesis-datastrøm eller MSK-emne, og bli behandlet for å generere KPIer i sanntid. Du kan sette FM-er i arbeid for brukernes sentimentanalyse. FM-er kan analysere hvert svar og tildele en kategori for brukertilfredshet.
Apache Flinks arkitektur tillater kompleks dataaggregering over tidsvinduer. Den gir også støtte for SQL-spørring over strøm av datahendelser. Derfor, ved å bruke Apache Flink, kan du raskt analysere rå brukerinndata og generere KPIer i sanntid ved å skrive kjente SQL-spørringer. For mer informasjon, se Tabell API og SQL.
Med Amazon Managed Service for Apache Flink Studio, kan du bygge og kjøre Apache Flink-strømbehandlingsapplikasjoner ved å bruke standard SQL, Python og Scala i en interaktiv notatbok. Studio-notatbøker drives av Apache Zeppelin og bruker Apache Flink som strømbehandlingsmotor. Studio-notatbøker kombinerer sømløst disse teknologiene for å gjøre avansert analyse av datastrømmer tilgjengelig for utviklere av alle ferdighetssett. Med støtte for brukerdefinerte funksjoner (UDFs), tillater Apache Flink å bygge tilpassede operatører for å integrere med eksterne ressurser som FM-er for å utføre komplekse oppgaver som sentimentanalyse. Du kan bruke UDF-er til å beregne ulike beregninger eller berike rådata fra brukertilbakemeldinger med ytterligere innsikt, for eksempel brukersentiment. For å lære mer om dette mønsteret, se Proaktivt ta opp kundeproblemer i sanntid med GenAI, Flink, Apache Kafka og Kinesis.
Med Managed Service for Apache Flink Studio kan du distribuere Studio-notatboken din som en strømmejobb med ett klikk. Du kan bruke native sink-koblinger levert av Apache Flink for å sende utdataene til ditt valgte lager eller sette det i en Kinesis-datastrøm eller MSK-emne. Amazon RedShift og OpenSearch Service er begge ideelle for lagring av analytiske data. Begge motorene gir naturlig inntaksstøtte fra Kinesis Data Streams og Amazon MSK via en separat streaming-pipeline til en datainnsjø eller datavarehus for analyse.
Amazon Redshift bruker SQL til å analysere strukturerte og semistrukturerte data på tvers av datavarehus og datainnsjøer, ved å bruke AWS-designet maskinvare og maskinlæring for å levere den beste prisytelsen i skala. OpenSearch Service tilbyr visualiseringsfunksjoner drevet av OpenSearch Dashboards og Kibana (1.5 til 7.10 versjoner).
Du kan bruke resultatet av en slik analyse kombinert med brukerforespørselsdata for å finjustere FM når det er nødvendig. SageMaker er den enkleste måten å finjustere FM-ene dine på. Bruk av Amazon S3 med SageMaker gir en kraftig og sømløs integrasjon for finjustering av modellene dine. Amazon S3 fungerer som en skalerbar og holdbar objektlagringsløsning, som muliggjør enkel lagring og henting av store datasett, treningsdata og modellartefakter. SageMaker er en fullstendig administrert ML-tjeneste som forenkler hele ML-livssyklusen. Ved å bruke Amazon S3 som lagringsbackend for SageMaker, kan du dra nytte av skalerbarheten, påliteligheten og kostnadseffektiviteten til Amazon S3, samtidig som du integrerer den sømløst med SageMakers opplærings- og distribusjonsmuligheter. Denne kombinasjonen muliggjør effektiv dataadministrasjon, letter utvikling av samarbeidsmodeller og sørger for at ML-arbeidsflyter er strømlinjeformede og skalerbare, noe som til slutt forbedrer den generelle smidigheten og ytelsen til ML-prosessen. For mer informasjon, se Finjuster Falcon 7B og andre LLM-er på Amazon SageMaker med @remote decorator.
Med en filsystemsink-kobling kan Apache Flink-jobber levere data til Amazon S3 i åpne format (som JSON, Avro, Parquet og flere) filer som dataobjekter. Hvis du foretrekker å administrere datainnsjøen din ved å bruke et transaksjonsdatainnsjø-rammeverk (som Apache Hudi, Apache Iceberg eller Delta Lake), gir alle disse rammeverkene en tilpasset kobling for Apache Flink. For flere detaljer, se Lag en kilde-til-data-pipeline med lav latens ved hjelp av Amazon MSK Connect, Apache Flink og Apache Hudi.
Oppsummering
For en generativ AI-applikasjon basert på en RAG-modell, må du vurdere å bygge to datalagringssystemer, og du må bygge dataoperasjoner som holder dem oppdatert med alle kildesystemene. Tradisjonelle batchjobber er ikke tilstrekkelig til å behandle størrelsen og mangfoldet av dataene du trenger for å integrere med din generative AI-applikasjon. Forsinkelser i behandlingen av endringene i kildesystemer resulterer i en unøyaktig respons og reduserer effektiviteten til din generative AI-applikasjon. Datastrømming lar deg innta data fra en rekke databaser på tvers av ulike systemer. Den lar deg også transformere, berike, slå sammen og samle data på tvers av mange kilder effektivt i nesten sanntid. Datastrømming gir en forenklet dataarkitektur for å samle inn og transformere brukernes sanntidsreaksjoner eller kommentarer på applikasjonssvarene, og hjelper deg med å levere og lagre resultatene i en datainnsjø for modellfinjustering. Datastrømming hjelper deg også med å optimalisere datapipelines ved å behandle bare endringshendelsene, slik at du kan svare på dataendringer raskere og mer effektivt.
Lær mer om AWS datastrømmetjenester og kom i gang med å bygge din egen datastrømningsløsning.
Om forfatterne
 Ali Alemi er en Streaming Specialist Solutions Architect hos AWS. Ali gir råd til AWS-kunder med arkitektonisk beste praksis og hjelper dem med å designe sanntidsanalysedatasystemer som er pålitelige, sikre, effektive og kostnadseffektive. Han jobber baklengs fra kundens brukstilfeller og designer dataløsninger for å løse deres forretningsproblemer. Før han begynte i AWS, støttet Ali flere offentlige kunder og AWS-konsulentpartnere i deres applikasjonsmoderniseringsreise og migrering til skyen.
Ali Alemi er en Streaming Specialist Solutions Architect hos AWS. Ali gir råd til AWS-kunder med arkitektonisk beste praksis og hjelper dem med å designe sanntidsanalysedatasystemer som er pålitelige, sikre, effektive og kostnadseffektive. Han jobber baklengs fra kundens brukstilfeller og designer dataløsninger for å løse deres forretningsproblemer. Før han begynte i AWS, støttet Ali flere offentlige kunder og AWS-konsulentpartnere i deres applikasjonsmoderniseringsreise og migrering til skyen.
 Imtiaz (Taz) sa er verdensomspennende teknisk leder for Analytics ved AWS. Han liker å engasjere seg i samfunnet om alt som har med data og analyser å gjøre. Han kan nås via Linkedin.
Imtiaz (Taz) sa er verdensomspennende teknisk leder for Analytics ved AWS. Han liker å engasjere seg i samfunnet om alt som har med data og analyser å gjøre. Han kan nås via Linkedin.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

