Dykk inn i dyp læring (D2L.ai) er en åpen kildekode lærebok som gjør dyp læring tilgjengelig for alle. Den har interaktive Jupyter-notatbøker med selvstendig kode i PyTorch, JAX, TensorFlow og MXNet, i tillegg til virkelige eksempler, utstillingsfigurer og matematikk. Så langt har D2L blitt tatt i bruk av mer enn 400 universiteter rundt om i verden, som University of Cambridge, Stanford University, Massachusetts Institute of Technology, Carnegie Mellon University og Tsinghua University. Dette verket er også gjort tilgjengelig på kinesisk, japansk, koreansk, portugisisk, tyrkisk og vietnamesisk, med planer om å lansere spansk og andre språk.
Det er en utfordrende bestrebelse å ha en nettbok som kontinuerlig holdes oppdatert, skrevet av flere forfattere og tilgjengelig på flere språk. I dette innlegget presenterer vi en løsning som D2L.ai brukte for å møte denne utfordringen ved å bruke Active Custom Translation (ACT) funksjon of Amazon Oversett og bygge en flerspråklig automatisk oversettelsespipeline.
Vi viser hvordan du bruker AWS-administrasjonskonsoll og Amazon Translate offentlig API å levere automatisk maskinbatch-oversettelse, og analysere oversettelsene mellom to språkpar: engelsk og kinesisk, og engelsk og spansk. Vi anbefaler også beste fremgangsmåter når du bruker Amazon Translate i denne automatiske oversettelsespipelinen for å sikre oversettelseskvalitet og effektivitet.
Løsningsoversikt
Vi bygde automatiske oversettelsespipelines for flere språk ved å bruke ACT-funksjonen i Amazon Translate. ACT lar deg tilpasse oversettelsesutdata på farten ved å gi skreddersydde oversettelseseksempler i form av parallelle data. Parallelle data består av en samling teksteksempler på et kildespråk og ønskede oversettelser på ett eller flere målspråk. Under oversettelse velger ACT automatisk de mest relevante segmentene fra parallelldataene og oppdaterer oversettelsesmodellen med en gang basert på disse segmentparene. Dette resulterer i oversettelser som bedre samsvarer med stilen og innholdet i parallelldataene.
Arkitekturen inneholder flere underrørledninger; hver sub-pipeline håndterer ett språk oversettelse som engelsk til kinesisk, engelsk til spansk, og så videre. Flere translasjonsunderrørledninger kan behandles parallelt. I hver sub-pipeline bygger vi først parallelle data i Amazon Translate ved å bruke høykvalitetsdatasettet med tailed oversettelseseksempler fra de menneskelig oversatte D2L-bøkene. Deretter genererer vi den tilpassede maskinoversettelsesutgangen på farten under kjøring, som oppnår bedre kvalitet og nøyaktighet.
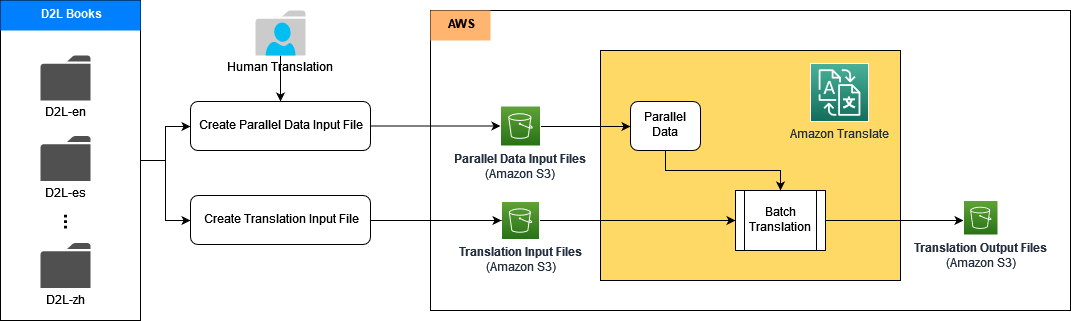
I de følgende delene viser vi hvordan du bygger hver oversettelsespipeline ved hjelp av Amazon Translate med ACT, sammen med Amazon SageMaker og Amazon enkel lagringstjeneste (Amazon S3).
Først legger vi kildedokumentene, referansedokumentene og det parallelle dataopplæringssettet i en S3-bøtte. Deretter bygger vi Jupyter-notatbøker i SageMaker for å kjøre oversettelsesprosessen ved å bruke Amazon Translates offentlige APIer.
Forutsetninger
For å følge trinnene i dette innlegget, sørg for at du har en AWS-konto med følgende:
- Tilgang til AWS identitets- og tilgangsadministrasjon (IAM) for rolle- og policykonfigurasjon
- Tilgang til Amazon Translate, SageMaker og Amazon S3
- En S3-bøtte for å lagre kildedokumenter, referansedokumenter, parallelle datadatasett og utdata fra oversettelse
Opprett en IAM-rolle og retningslinjer for Amazon Translate med ACT
Vår IAM-rolle må inneholde en tilpasset tillitspolicy for Amazon Translate:
Denne rollen må også ha en tillatelsespolicy som gir Amazon Translate lesetilgang til inndatamappen og undermappene i Amazon S3 som inneholder kildedokumentene, og lese-/skrivetilgang til utdata S3-bøtten og mappen som inneholder de oversatte dokumentene:
For å kjøre Jupyter-notatbøker i SageMaker for oversettelsesjobbene, må vi gi en integrert tillatelsespolicy til SageMaker-utførelsesrollen. Denne rollen overfører Amazon Translate-tjenesterollen til SageMaker som lar SageMaker-notatbøkene ha tilgang til kilden og oversatte dokumenter i de angitte S3-bøttene:
Forbered parallelle datatreningsprøver
De parallelle dataene i ACT må trenes opp av en inndatafil som består av en liste over teksteksempelpar, for eksempel et par kildespråk (engelsk) og målspråk (kinesisk). Inndatafilen kan være i TMX-, CSV- eller TSV-format. Følgende skjermbilde viser et eksempel på en CSV-inndatafil. Den første kolonnen er kildespråkdataene (på engelsk), og den andre kolonnen er målspråkdataene (på kinesisk). Følgende eksempel er hentet fra D2L-en-boken og D2L-zh-boken.

Utfør tilpasset parallell dataopplæring i Amazon Translate
Først setter vi opp S3-bøtten og mappene som vist i følgende skjermbilde. De source_data mappen inneholder kildedokumentene før oversettelsen; de genererte dokumentene etter batch-oversettelsen legges i utdatamappen. De ParallelData mappen inneholder den parallelle datainndatafilen som ble utarbeidet i forrige trinn.
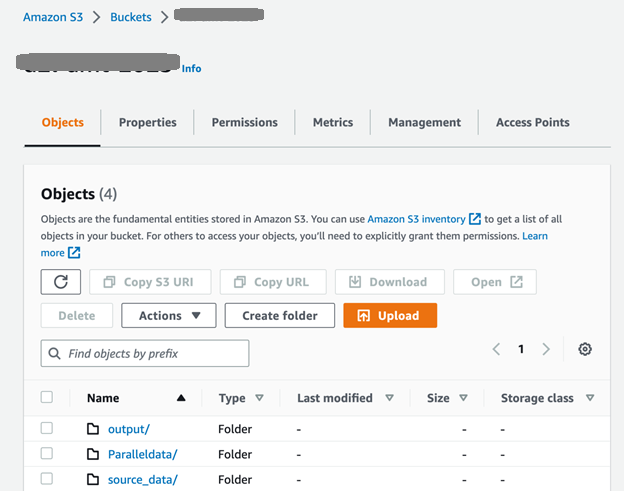
Etter å ha lastet opp inndatafilene til source_data mappen kan vi bruke CreateParallelData API for å kjøre en parallell dataopprettingsjobb i Amazon Translate:
For å oppdatere eksisterende parallelle data med nye opplæringsdatasett, kan vi bruke UpdateParallelData API:
S3_BUCKET = “YOUR-S3_BUCKET-NAME”
pd_name = “pd-d2l-short_test_sentence_enzh_all”
pd_description = “Parallel Data for English to Chinese”
pd_fn = “d2l_short_test_sentence_enzh_all.csv”
response_t = translate_client.update_parallel_data( Name=pd_name, # pd_name is the parallel data name Description=pd_description, # pd_description is the parallel data description ParallelDataConfig={ 'S3Uri': 's3://'+S3_BUCKET+'/Paralleldata/'+pd_fn, # S3_BUCKET is the S3 bucket name defined in the previous step 'Format': 'CSV' },
)
print(pd_name, ": ", response_t['Status'], " updated.")
Vi kan sjekke fremdriften i treningsjobben på Amazon Translate-konsollen. Når jobben er fullført, vises status for parallelldata som Aktiv og er klar til bruk.
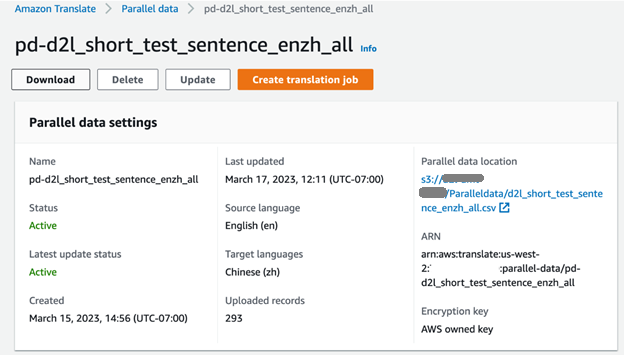
Kjør asynkronisert batch-oversettelse ved hjelp av parallelle data
Batch-oversettelsen kan utføres i en prosess der flere kildedokumenter automatisk oversettes til dokumenter på målspråk. Prosessen innebærer å laste opp kildedokumentene til inndatamappen til S3-bøtten, og deretter bruke StartTextTranslationJob API av Amazon Translate for å starte en asynkronisert oversettelsesjobb:
Vi valgte ut fem kildedokumenter på engelsk fra D2L-boken (D2L-en) for masseoversettelsen. På Amazon Translate-konsollen kan vi overvåke fremdriften for oversettelsesjobben. Når jobbstatusen endres til Terminado, kan vi finne de oversatte dokumentene på kinesisk (D2L-zh) i S3-bøtteutdatamappen.
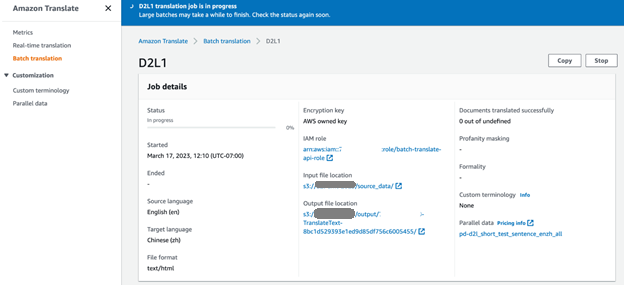
Vurder oversettelsens kvalitet
For å demonstrere effektiviteten til ACT-funksjonen i Amazon Translate, brukte vi også den tradisjonelle metoden Amazon Translate sanntidsoversettelse uten parallelle data for å behandle de samme dokumentene, og sammenlignet utdataene med batch-oversettelsesutdataene med ACT. Vi brukte poengsummen BLEU (BiLingual Evaluation Understudy) for å måle oversettelseskvaliteten mellom de to metodene. Den eneste måten å nøyaktig måle kvaliteten på maskinoversettelse er å få en ekspertgjennomgang og gradere kvaliteten. BLEU gir imidlertid et estimat for relativ kvalitetsforbedring mellom to produksjoner. En BLEU-score er vanligvis et tall mellom 0–1; den beregner likheten mellom maskinoversettelsen og den menneskelige referanseoversettelsen. Den høyere poengsummen representerer bedre kvalitet i naturlig språkforståelse (NLU).
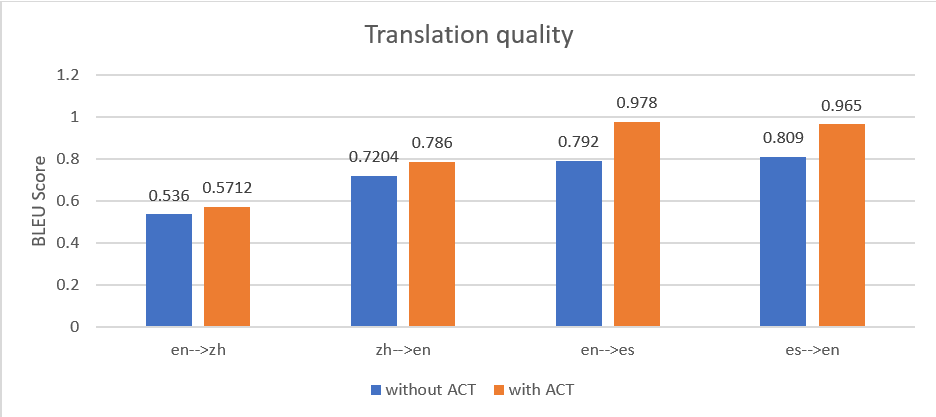
Vi har testet et sett med dokumenter i fire pipelines: engelsk til kinesisk (en til zh), kinesisk til engelsk (zh til en), engelsk til spansk (en til es), og spansk til engelsk (es til en). Følgende figur viser at oversettelsen med ACT ga en høyere gjennomsnittlig BLEU-score i alle oversettelsespipelinene.
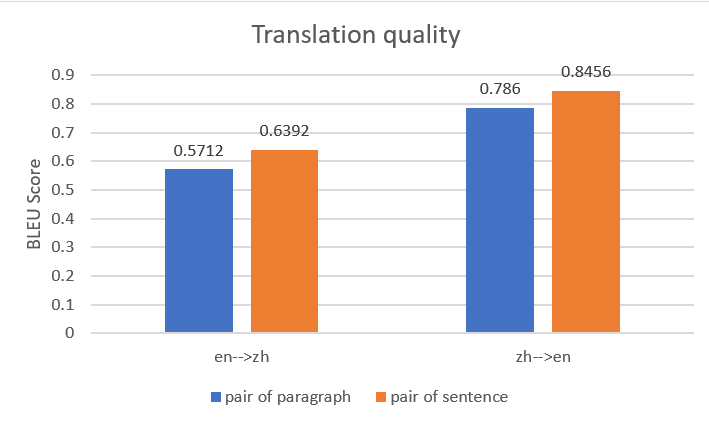
Vi observerte også at jo mer granulære de parallelle dataparene er, desto bedre er oversettelsesytelsen. For eksempel bruker vi følgende parallelle datainndatafil med par av avsnitt, som inneholder 10 oppføringer.

For det samme innholdet bruker vi følgende parallelle datainndatafil med setningspar og 16 oppføringer.

Vi brukte begge parallelle datainndatafiler for å konstruere to parallelle dataenheter i Amazon Translate, og opprettet deretter to batch-oversettelsesjobber med samme kildedokument. Følgende figur sammenligner utdataoversettelsene. Den viser at utdataene ved bruk av parallelle data med par av setninger overgikk den som brukte parallelle data med par av avsnitt, for både engelsk til kinesisk oversettelse og kinesisk til engelsk oversettelse.
Hvis du er interessert i å lære mer om disse benchmarkanalysene, se Automatisk maskinoversettelse og synkronisering for "Dyk inn i dyp læring".
Rydd opp
For å unngå gjentakende kostnader i fremtiden, anbefaler vi at du rydder opp i ressursene du opprettet:
- På Amazon Translate-konsollen velger du parallelldataene du opprettet og velger Delete. Alternativt kan du bruke SlettParallelData API eller AWS kommandolinjegrensesnitt (AWS CLI) slette-parallelle-data kommando for å slette parallelldata.
- Slett S3-bøtten brukes til å være vert for kilde- og referansedokumenter, oversatte dokumenter og parallelle datainndatafiler.
- Slett IAM-rollen og policyen. For instruksjoner, se Sletting av roller eller forekomstprofiler og Sletter IAM-policyer.
konklusjonen
Med denne løsningen tar vi sikte på å redusere arbeidsmengden til menneskelige oversettere med 80 %, samtidig som vi opprettholder oversettelseskvaliteten og støtter flere språk. Du kan bruke denne løsningen til å forbedre oversettelseskvaliteten og effektiviteten. Vi jobber med å ytterligere forbedre løsningsarkitekturen og oversettelseskvaliteten for andre språk.
Din tilbakemelding er alltid velkommen; legg igjen dine tanker og spørsmål i kommentarfeltet.
Om forfatterne
 Yunfei Bai er Senior Solutions Architect hos AWS. Med bakgrunn innen AI/ML, datavitenskap og analyse hjelper Yunfei kundene med å ta i bruk AWS-tjenester for å levere forretningsresultater. Han designer AI/ML og dataanalyseløsninger som overvinner komplekse tekniske utfordringer og driver strategiske mål. Yunfei har en doktorgrad i elektronikk og elektroteknikk. Utenom jobben liker Yunfei å lese og musikk.
Yunfei Bai er Senior Solutions Architect hos AWS. Med bakgrunn innen AI/ML, datavitenskap og analyse hjelper Yunfei kundene med å ta i bruk AWS-tjenester for å levere forretningsresultater. Han designer AI/ML og dataanalyseløsninger som overvinner komplekse tekniske utfordringer og driver strategiske mål. Yunfei har en doktorgrad i elektronikk og elektroteknikk. Utenom jobben liker Yunfei å lese og musikk.
 Rachel Hu er anvendt vitenskapsmann ved AWS Machine Learning University (MLU). Hun har ledet noen få kursdesign, inkludert ML Operations (MLOps) og Accelerator Computer Vision. Rachel er en AWS senior foredragsholder og har talt på toppkonferanser inkludert AWS re:Invent, NVIDIA GTC, KDD og MLOps Summit. Før hun begynte i AWS, jobbet Rachel som maskinlæringsingeniør og bygde modeller for naturlig språkbehandling. Utenom jobben liker hun yoga, ultimat frisbee, lesing og reise.
Rachel Hu er anvendt vitenskapsmann ved AWS Machine Learning University (MLU). Hun har ledet noen få kursdesign, inkludert ML Operations (MLOps) og Accelerator Computer Vision. Rachel er en AWS senior foredragsholder og har talt på toppkonferanser inkludert AWS re:Invent, NVIDIA GTC, KDD og MLOps Summit. Før hun begynte i AWS, jobbet Rachel som maskinlæringsingeniør og bygde modeller for naturlig språkbehandling. Utenom jobben liker hun yoga, ultimat frisbee, lesing og reise.
 Watson Srivathsan er hovedproduktsjef for Amazon Translate, AWS sin naturlige språkbehandlingstjeneste. I helgene vil du finne ham utforske utendørs i Pacific Northwest.
Watson Srivathsan er hovedproduktsjef for Amazon Translate, AWS sin naturlige språkbehandlingstjeneste. I helgene vil du finne ham utforske utendørs i Pacific Northwest.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- EVM Finans. Unified Interface for desentralisert økonomi. Tilgang her.
- Quantum Media Group. IR/PR forsterket. Tilgang her.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/build-a-multilingual-automatic-translation-pipeline-with-amazon-translate-active-custom-translation/

