Dette innlegget er skrevet sammen med Andries Engelbrecht og Scott Teal fra Snowflake.
Bedrifter er i stadig utvikling, og dataledere utfordres hver dag til å møte nye krav. For mange bedrifter og store organisasjoner er det ikke mulig å ha én prosesseringsmotor eller verktøy for å håndtere de ulike forretningskravene. De forstår at en tilnærming som passer alle ikke lenger fungerer, og anerkjenner verdien av å ta i bruk skalerbare, fleksible verktøy og åpne dataformater for å støtte interoperabilitet i en moderne dataarkitektur for å akselerere leveringen av nye løsninger.
Kunder bruker AWS og Snowflake til å utvikle spesialbygde dataarkitekturer som gir ytelsen som kreves for moderne analyse og kunstig intelligens (AI). Implementering av disse løsningene krever datadeling mellom spesialbygde datalagre. Dette er grunnen til at Snowflake og AWS leverer forbedret støtte for Apache Iceberg for å muliggjøre og lette datainteroperabilitet mellom datatjenester.
Apache Iceberg er et åpen kildekode-tabellformat som gir pålitelighet, enkelhet og høy ytelse for store datasett med transaksjonsintegritet mellom ulike prosesseringsmotorer. I dette innlegget diskuterer vi følgende:
- Fordeler med Iceberg-tabeller for datainnsjøer
- To arkitektoniske mønstre for å dele Iceberg-bord mellom AWS og Snowflake:
- Administrer dine Iceberg-bord med AWS Lim Datakatalog
- Administrer Iceberg-bordene dine med Snowflake
- Prosessen med å konvertere eksisterende datainnsjøtabeller til isfjelltabeller uten å kopiere dataene
Nå som du har en forståelse på høyt nivå av emnene, la oss dykke ned i hvert av dem i detalj.
Fordeler med Apache Iceberg
Apache Iceberg er et distribuert, fellesskapsdrevet, Apache 2.0-lisensiert, 100 % åpen kildekode-datatabellformat som hjelper til med å forenkle databehandling på store datasett som er lagret i datainnsjøer. Dataingeniører bruker Apache Iceberg fordi det er raskt, effektivt og pålitelig i alle skalaer og holder oversikt over hvordan datasett endres over tid. Apache Iceberg tilbyr integrasjoner med populære databehandlingsrammer som Apache Spark, Apache Flink, Apache Hive, Presto og mer.
Iceberg-tabeller opprettholder metadata for å abstrahere store samlinger av filer, og gir dataadministrasjonsfunksjoner inkludert tidsreiser, tilbakerulling, datakomprimering og full skjemautvikling, noe som reduserer administrasjonskostnader. Opprinnelig utviklet hos Netflix før den ble hentet fra Apache Software Foundation, var Apache Iceberg en blank-slate-design for å løse vanlige datainnsjøutfordringer som Brukererfaring, pålitelighet og ytelse, og støttes nå av et robust fellesskap av utviklere som fokuserer på kontinuerlig å forbedre og legge til nye funksjoner til prosjektet, betjene reelle brukerbehov og gi dem valgmuligheter.
Transaksjonsdatainnsjøer bygget på AWS og Snowflake
Snowflake gir ulike integrasjoner for Iceberg-bord med flere lagringsmuligheter, inkludert Amazon S3, og flere katalogalternativer, inkludert AWS Lim Data Catalog og Snowflake. AWS tilbyr integrasjoner for ulike AWS-tjenester med Iceberg-tabeller også, inkludert AWS Glue Data Catalog for sporing av tabellmetadata. Å kombinere Snowflake og AWS gir deg flere alternativer for å bygge ut en transaksjonsdatainnsjø for analytiske og andre brukstilfeller som datadeling og samarbeid. Ved å legge til et metadatalag i datainnsjøer får du en bedre brukeropplevelse, forenklet administrasjon og forbedret ytelse og pålitelighet på svært store datasett.
Administrer Iceberg-bordet ditt med AWS Glue
Du kan bruke AWS Glue til å innta, katalogisere, transformere og administrere dataene på Amazon enkel lagringstjeneste (Amazon S3). AWS Glue er en serverløs dataintegrasjonstjeneste som lar deg visuelt lage, kjøre og overvåke ekstrahere, transformere og laste (ETL) rørledninger for å laste data inn i datainnsjøene dine i Iceberg-format. Med AWS Glue kan du oppdage og koble til mer enn 70 forskjellige datakilder og administrere dataene dine i en sentralisert datakatalog. Snowflake integreres med AWS Glue Data Catalog for å få tilgang til Iceberg-tabellkatalogen og filene på Amazon S3 for analytiske spørsmål. Dette forbedrer ytelsen og beregningskostnadene betydelig i forhold til eksterne bord på Snowflake, fordi de ekstra metadataene forbedrer beskjæringen i spørringsplaner.
Du kan bruke den samme integrasjonen til å dra nytte av datadelings- og samarbeidsmulighetene i Snowflake. Dette kan være veldig kraftig hvis du har data i Amazon S3 og trenger å aktivere Snowflake-datadeling med andre forretningsenheter, partnere, leverandører eller kunder.
Følgende arkitekturdiagram gir en oversikt over dette mønsteret på høyt nivå.
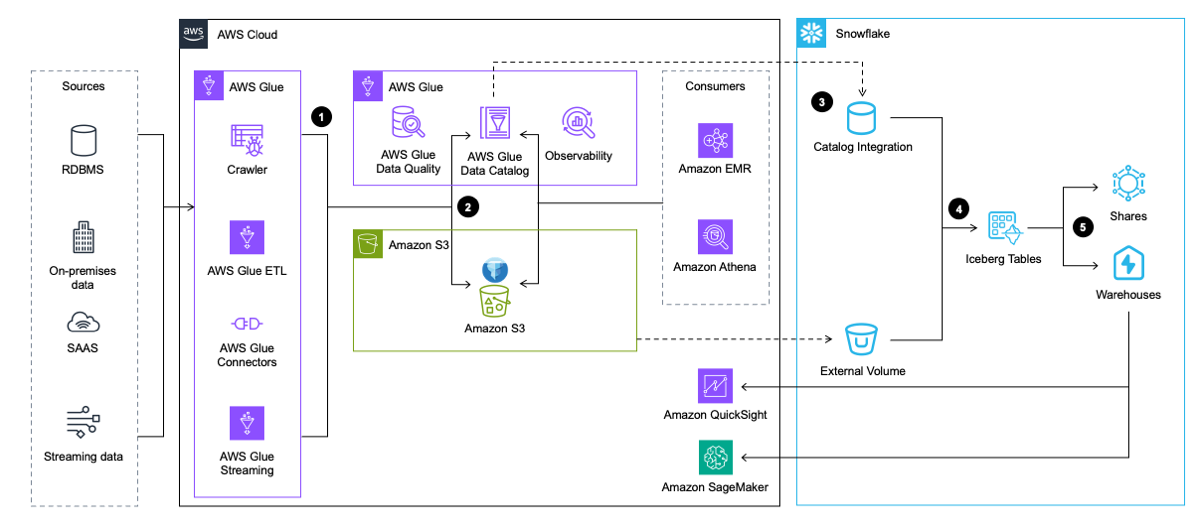
Arbeidsflyten inkluderer følgende trinn:
- AWS Glue trekker ut data fra applikasjoner, databaser og strømmekilder. AWS Glue transformerer den deretter og laster den inn i datasjøen i Amazon S3 i Iceberg-tabellformat, mens metadataene om Iceberg-tabellen settes inn og oppdateres i AWS Glue Data Catalog.
- AWS Glue-søkeroboten genererer og oppdaterer Iceberg-tabellmetadata og lagrer dem i AWS Glue Data Catalog for eksisterende Iceberg-tabeller på en S3-datainnsjø.
- Snowflake integreres med AWS Glue Data Catalog for å hente øyeblikksbildet.
- I tilfelle en spørring, bruker Snowflake øyeblikksbildeplasseringen fra AWS Glue Data Catalog til å lese Iceberg-tabelldata i Amazon S3.
- Snowflake kan søke på tvers av Iceberg- og Snowflake-tabellformatene. Du kan dele data for samarbeid med en eller flere kontoer i samme Snowflake-region. Du kan også bruke data i Snowflake for visualisering ved hjelp av Amazon QuickSight, eller bruk den til maskinlæring (ML) og kunstig intelligens (AI) formål med Amazon SageMaker.
Administrer Iceberg-bordet ditt med Snowflake
Et andre mønster gir også interoperabilitet på tvers av AWS og Snowflake, men implementerer datatekniske rørledninger for inntak og transformasjon til Snowflake. I dette mønsteret blir data lastet til Iceberg-tabeller av Snowflake gjennom integrasjoner med AWS-tjenester som AWS Glue eller gjennom andre kilder som Snowpipe. Snowflake skriver deretter data direkte til Amazon S3 i Iceberg-format for nedstrømstilgang av Snowflake og ulike AWS-tjenester, og Snowflake administrerer Iceberg-katalogen som sporer øyeblikksbilder på tvers av tabeller for AWS-tjenester å få tilgang til.
Som det forrige mønsteret kan du bruke Snowflake-administrerte Iceberg-tabeller med Snowflake-datadeling, men du kan også bruke S3 til å dele datasett i tilfeller der den ene parten ikke har tilgang til Snowflake.
Følgende arkitekturdiagram gir en oversikt over dette mønsteret med Snowflake-administrerte Iceberg-tabeller.
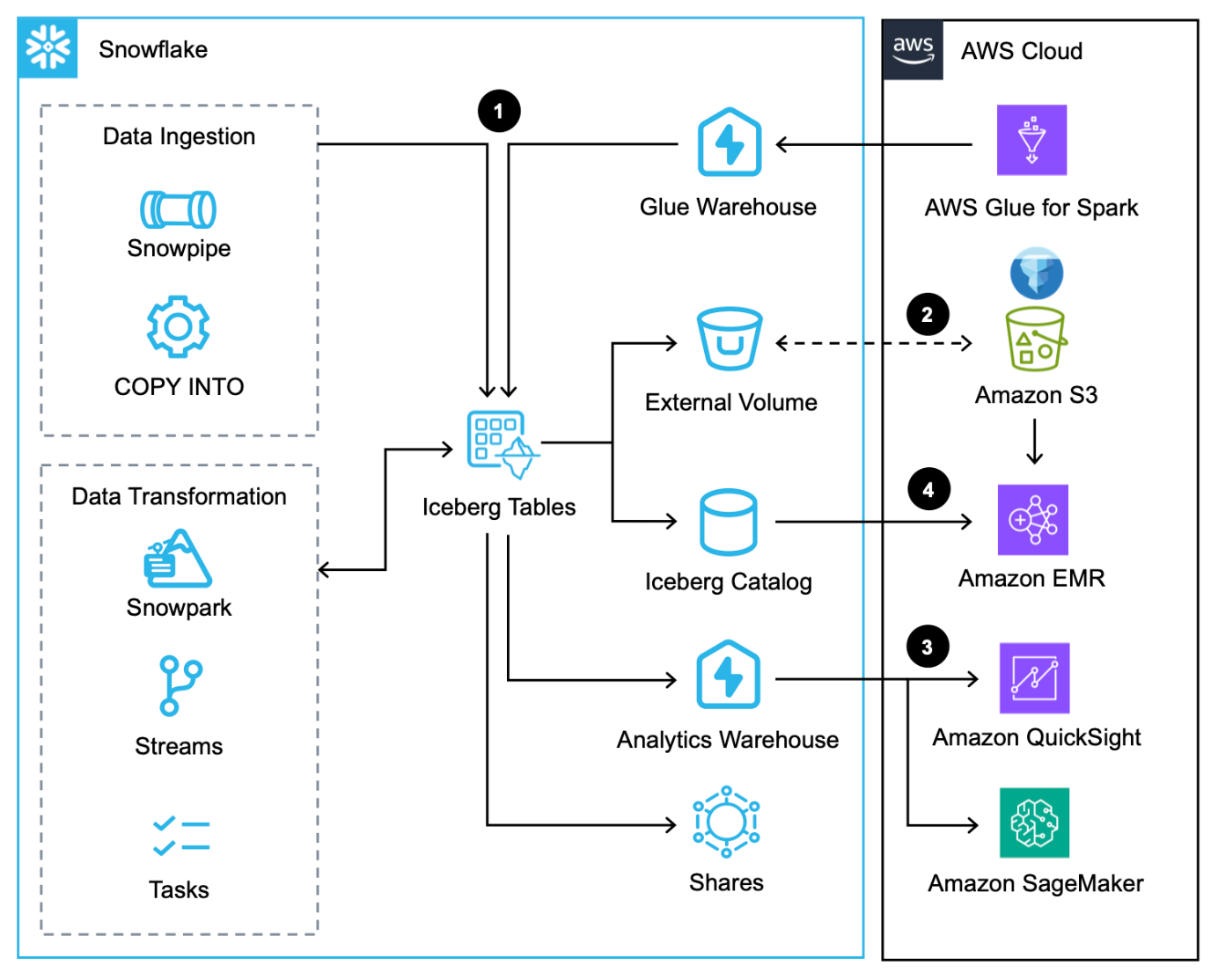
Denne arbeidsflyten består av følgende trinn:
- I tillegg til å laste inn data via COPY kommando, Snøpipeog den opprinnelige Snowflake-kontakten for AWS Glue, kan du integrere data via Snowflake Datadeling.
- Snowflake skriver Iceberg-tabeller til Amazon S3 og oppdaterer metadata automatisk for hver transaksjon.
- Iceberg-tabeller i Amazon S3 spørres av Snowflake for analytiske og ML-arbeidsbelastninger ved hjelp av tjenester som QuickSight og SageMaker.
- Apache Spark-tjenester på AWS kan få tilgang til øyeblikksbilder fra Snowflake via en Snowflake Iceberg Catalog SDK og skanne Iceberg-tabellfilene direkte i Amazon S3.
Sammenligne løsninger
Disse to mønstrene fremhever alternativer som er tilgjengelige for datapersonas i dag for å maksimere datainteroperabiliteten mellom Snowflake og AWS ved å bruke Apache Iceberg. Men hvilket mønster er ideelt for ditt bruksområde? Hvis du allerede bruker AWS Glue Data Catalog og bare krever Snowflake for lesespørringer, kan det første mønsteret integrere Snowflake med AWS Glue og Amazon S3 for å spørre Iceberg-tabeller. Hvis du ikke allerede bruker AWS Glue Data Catalog og krever at Snowflake utfører lesing og skriving, er det andre mønsteret sannsynligvis en god løsning som gjør det mulig å lagre og få tilgang til data fra AWS.
Tatt i betraktning at lesing og skriving sannsynligvis vil fungere på en per-tabell-basis i stedet for hele dataarkitekturen, er det tilrådelig å bruke en kombinasjon av begge mønstrene.
Migrer eksisterende datainnsjøer til en transaksjonsdatainnsjø ved hjelp av Apache Iceberg
Du kan konvertere eksisterende parkett-, ORC- og Avro-baserte datainnsjøtabeller på Amazon S3 til Iceberg-format for å høste fordelene av transaksjonsintegritet samtidig som du forbedrer ytelsen og brukeropplevelsen. Det er flere alternativer for migrering av Iceberg-bord (STILLBILDE, MIGRERog LEGG TIL FILER) for å migrere eksisterende datainnsjøtabeller på plass til Iceberg-format, som er å foretrekke fremfor å omskrive alle de underliggende datafilene – en kostbar og tidkrevende innsats med store datasett. I denne delen fokuserer vi på ADD_FILES, fordi det er nyttig for tilpassede migreringer.
For ADD_FILES-alternativer kan du bruke AWS Glue til å generere Iceberg-metadata og statistikk for en eksisterende datainnsjøtabell og lage nye Iceberg-tabeller i AWS Glue Data Catalog for fremtidig bruk uten å måtte skrive om de underliggende dataene. For instruksjoner om generering av Iceberg-metadata og statistikk ved hjelp av AWS Glue, se Migrer en eksisterende datainnsjø til en transaksjonsdatainnsjø ved hjelp av Apache Iceberg or Konverter eksisterende Amazon S3-datainnsjøtabeller til Snowflake Unmanaged Iceberg-tabeller ved å bruke AWS Glue.
Dette alternativet krever at du pauser datapipelines mens du konverterer filene til Iceberg-tabeller, som er en enkel prosess i AWS Glue fordi destinasjonen bare må endres til en Iceberg-tabell.
konklusjonen
I dette innlegget så du de to arkitekturmønstrene for implementering av Apache Iceberg i en datainnsjø for bedre interoperabilitet på tvers av AWS og Snowflake. Vi ga også veiledning om migrering av eksisterende datainnsjøtabeller til Iceberg-format.
Meld deg på AWS Dev Day 10. april å få hands-on ikke bare med Apache Iceberg, men også med streaming av datapipelines med Amazon Data Firehose og Snowpipe Streaming, og generative AI-applikasjoner med Strømbelyst i Snowflake og Amazonas grunnfjell.
Om forfatterne
 Andries Engelbrecht er Principal Partner Solutions Architect hos Snowflake og jobber med strategiske partnere. Han er aktivt engasjert med strategiske partnere som AWS som støtter produkt- og tjenesteintegrasjoner samt utvikling av felles løsninger med partnere. Andries har over 20 års erfaring innen data og analyse.
Andries Engelbrecht er Principal Partner Solutions Architect hos Snowflake og jobber med strategiske partnere. Han er aktivt engasjert med strategiske partnere som AWS som støtter produkt- og tjenesteintegrasjoner samt utvikling av felles løsninger med partnere. Andries har over 20 års erfaring innen data og analyse.
 Deenbandhu Prasad er senior analytiker hos AWS, og spesialiserer seg på big data-tjenester. Han brenner for å hjelpe kunder med å bygge moderne dataarkitekturer på AWS Cloud. Han har hjulpet kunder i alle størrelser med å implementere løsninger for dataadministrasjon, datavarehus og datainnsjø.
Deenbandhu Prasad er senior analytiker hos AWS, og spesialiserer seg på big data-tjenester. Han brenner for å hjelpe kunder med å bygge moderne dataarkitekturer på AWS Cloud. Han har hjulpet kunder i alle størrelser med å implementere løsninger for dataadministrasjon, datavarehus og datainnsjø.
 Brian Dolan begynte i Amazon som Military Relations Manager i 2012 etter sin første karriere som Naval Aviator. I 2014 begynte Brian på Amazon Web Services, hvor han hjalp kanadiske kunder fra startups til bedrifter med å utforske AWS Cloud. Senest var Brian medlem av det ikke-relasjonelle forretningsutviklingsteamet som Go-To-Market-spesialist for Amazon DynamoDB og Amazon Keyspaces før han begynte i Analytics Worldwide Specialist Organization i 2022 som Go-To-Market-spesialist for AWS Glue.
Brian Dolan begynte i Amazon som Military Relations Manager i 2012 etter sin første karriere som Naval Aviator. I 2014 begynte Brian på Amazon Web Services, hvor han hjalp kanadiske kunder fra startups til bedrifter med å utforske AWS Cloud. Senest var Brian medlem av det ikke-relasjonelle forretningsutviklingsteamet som Go-To-Market-spesialist for Amazon DynamoDB og Amazon Keyspaces før han begynte i Analytics Worldwide Specialist Organization i 2022 som Go-To-Market-spesialist for AWS Glue.
 Nidhi Gupta er Sr. Partner Solution Architect hos AWS. Hun bruker dagene på å jobbe med kunder og partnere, og løse arkitektoniske utfordringer. Hun er lidenskapelig opptatt av dataintegrasjon og orkestrering, serverløs og stor databehandling og maskinlæring. Nidhi har lang erfaring med å lede arkitekturdesign og produksjonsutgivelser og distribusjoner for dataarbeidsmengder.
Nidhi Gupta er Sr. Partner Solution Architect hos AWS. Hun bruker dagene på å jobbe med kunder og partnere, og løse arkitektoniske utfordringer. Hun er lidenskapelig opptatt av dataintegrasjon og orkestrering, serverløs og stor databehandling og maskinlæring. Nidhi har lang erfaring med å lede arkitekturdesign og produksjonsutgivelser og distribusjoner for dataarbeidsmengder.
 Scott Teal er en produktmarkedsføringsleder hos Snowflake og fokuserer på datainnsjøer, lagring og styring.
Scott Teal er en produktmarkedsføringsleder hos Snowflake og fokuserer på datainnsjøer, lagring og styring.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-your-data-lake-with-amazon-s3-aws-glue-and-snowflake/

