Door Dan Yu, Harry Foster en Tom Fitzpatrick
Welkom in het tijdperk van EDA 4.0, waar we getuige zijn van een revolutionaire transformatie in elektronische ontwerpautomatisering, aangedreven door de kracht van kunstmatige intelligentie. De geschiedenis van EDA kan worden afgebakend in verschillende periodes die worden gekenmerkt door aanzienlijke technologische vooruitgang die hebben geleid tot snellere ontwerpherhalingen, verbeterde productiviteit en de ontwikkeling van ingewikkelde elektronische systemen.
Met name de komst van EDA 1.0 werd ingeluid door de introductie van SPICE (simulatieprogramma met nadruk op geïntegreerde schakelingen) aan de University of California, Berkeley, in de vroege jaren zeventig, wat een revolutie teweegbracht in het ontwerpen van schakelingen.
In de jaren tachtig en begin jaren negentig ontstond EDA 1980 als resultaat van de ontwikkeling van efficiënte plaats-en-route-algoritmen. Deze periode, ook wel bekend als het RTL-tijdperk, was getuige van een overgang van ontwerp op poortniveau naar abstracties op hoger niveau, waarbij RTL-ontwerp circuitbeschrijvingen op registeroverdrachtsniveau mogelijk maakte, waardoor de simulatieprestaties werden verbeterd. Deze periode was getuige van een belangrijke mijlpaal met de introductie van logische synthese.
De opkomst van system-on-chip (SoC)-ontwerpen eind jaren negentig en begin jaren 1990 was een cruciaal moment dat leidde tot EDA 2000. Dit tijdperk was getuige van de opkomst van een IP-ontwikkelingseconomie in combinatie met methodologieën voor hergebruik van ontwerpen. EDA-tools en -standaarden zijn ontwikkeld om het ontwerp, de verificatie en validatie van SoC's te ondersteunen, waardoor ingenieurs de escalerende complexiteit van SoC-klasse ontwerpen kunnen beheren.
In veel opzichten komt EDA 4.0 overeen met de bredere trends van de industriële revolutie 4.0, die de manier waarop bedrijven hun producten produceren, verbeteren en distribueren snel verandert, deels geleid door de digitalisering van de productiesector. EDA 4.0 is geëvolueerd om het ontwerp van intelligente en verbonden apparaten te vergemakkelijken, waarbij het potentieel van cloud computing en kunstmatige intelligentie (AI) en machine learning (ML) wordt benut.


EDA-tools bevatten nu machine learning, virtual prototyping, een digitale tweeling en ontwerpmethodologieën op systeemniveau om versnelde verificatie, geautomatiseerde verificatieworkflows en verhoogde verificatienauwkeurigheid naar EDA-producten te brengen. Het EDA 4.0-tijdperk belooft geoptimaliseerde productprestaties, kortere time-to-market en gestroomlijnde ontwikkelings- en productieprocessen.
In dit artikel gaan we dieper in op de state-of-the-art implementatie van ML-oplossingen die specifiek zijn toegesneden op functionele verificatie. We onderzoeken de uitdagingen die ML kan aangaan en presenteren nieuwe technieken en algoritmen die relevant zijn in dit domein.
Onderwerpen van ML in functionele verificatie
Tabel 1 vat de onderwerpen en subonderwerpen samen die van toepassing zijn op functionele verificatie wanneer alle functionele verificatieonderwerpen worden opgenomen in het algemene perspectief van verificatie van programmeercodes. Cursieve tekst geeft subonderwerpen aan die onontgonnen waren in andere publicaties over algemeen onderzoek.
Tabel 1: Onderwerpen van ML-toepassingen in functionele verificatie.

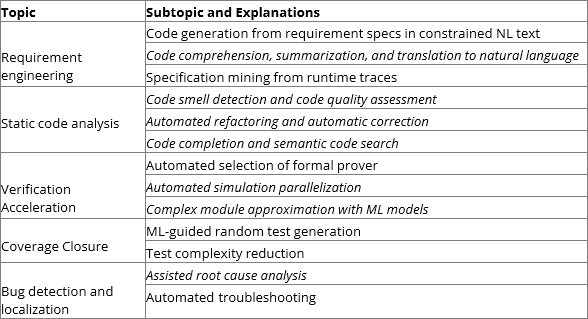
Vereiste engineering
Requirement engineering in functionele verificatie is het proces van het definiëren, documenteren en onderhouden van verificatievereisten, wat van cruciaal belang is om de uitstekende kwaliteit van het onderliggende IC-ontwerp te waarborgen.
Eisdefinitie omvat het vertalen van dubbelzinnige natuurlijke taal (NL) verificatiedoelstellingen in verificatiespecificaties met formaliteit en precisie. De kwaliteit van de vertaling bepaalt rechtstreeks de juistheid van de verificatie. Traditioneel is dit proces arbeidsintensief en neemt het aanzienlijke ontwerpcycli in beslag met verschillende iteraties van handmatige proefdrukken om de kwaliteit te waarborgen.
Er zijn twee groepen klassieke benaderingen voorgesteld om de vertaling te automatiseren. Een groep benaderingen is de introductie van beperkte natuurlijke taal (CNL) om het opstellen van de specificatie te formaliseren, gevolgd door een op sjablonen gebaseerde vertaalmachine. Deze aanpak vereist een aanzienlijke investering vooraf in de ontwikkeling van een krachtige CNL-syntaxis en een uitgebreid compiler-/sjabloonsysteem om ervoor te zorgen dat het krachtig genoeg is om aan de meeste eisen te voldoen die men tegenkomt bij functionele verificatie. Bovendien belast het ontwikkelaars met het leren van een extra taal, waardoor het idee niet algemeen geaccepteerd wordt.
De andere groep maakt gebruik van het klassieke natuurlijke taalproces (NLP) om NL-specificaties te ontleden en relevante sleutelelementen te extraheren om formele specificaties te formuleren.
De opmars van ML-vertaling in het NL-domein heeft volledig geautomatiseerde machinevertaling commercieel haalbaar gemaakt en overtreft soms de prestaties van gemiddelde menselijke vertalers. Het heeft de hoop gewekt om gebruik te maken van grootschalige getrainde NL-modellen met tot wel miljarden parameters om NL-specificaties direct te vertalen naar verificatiespecificaties in SystemVerilog Assertions (SVA), Property Specification Language (PSL) of andere talen. Er zijn verschillende pogingen waargenomen om een succesvolle end-to-end-vertaling uit te voeren, maar geen enkele is productiegereed gemaakt. De belangrijkste hindernis voor deze aanpak is de schaarste aan beschikbare trainingsdatasets die NL-specificaties koppelen aan hun formele vertaling. De meest uitgebreide datasets zijn slechts ongeveer 100 zinsparen. Het aantal verbleekt in vergelijking met hun NL-collega's, die routinematig in miljoenen of zelfs miljarden zinsparen voorkomen.
In tegenstelling tot het definiëren van vereisten, kijkt samenvatting naar de code en vertaalt deze naar een voor mensen begrijpelijke NL-samenvatting. Het helpt ontwikkelaars bij het lezen van minder ideaal onderhouden code of het begrijpen van complexe logica. Een ideaal geïmplementeerde codesamenvatting kan inline documentatie in codeblokken invoegen of afzonderlijke documentatie genereren. Met zijn hulp kan de onderhoudbaarheid en documentatie van de code aanzienlijk worden verbeterd.
Er is geëxperimenteerd met de toepassing van ML op codesamenvatting in meer populaire computertalen, bijvoorbeeld Python en JavaScript. Verschillende groepen benaderingen hebben met wisselend succes geëxperimenteerd. Op Information Retrieval (IR) gebaseerde benaderingen richten zich op het toepassen van NLP op de broncode en het zoeken naar vergelijkbare code met bestaande samenvatting. Deze groep benaderingen leunt sterk op de kwaliteit van de bestaande code met samenvattingen. Het gebruik ervan is alleen mogelijk binnen een hechte organisatie waar veel bestaande coderepository's direct beschikbaar zijn. Op heuristiek gebaseerde benaderingen proberen in plaats daarvan specifieke regels te definiëren op basis van heuristieken die zijn geïdentificeerd in de definitie van een module. Een module met veel submodules van eenvoudige lees-/schrijfopdrachtregels kan bijvoorbeeld worden beschouwd als een geheugenmodule. Daarom kan een samenvatting worden samengesteld uit een vooraf gedefinieerd patroon voor de geheugenmodule.
Op het moment van schrijven is codesamenvatting in IC-ontwerpverificatie nog niet gerapporteerd in de literatuur. Het is redelijk om optimistisch te zijn dat het succes van andere talen kan worden gerealiseerd in het ontwerp en de verificatie van IC's, wat nog moet worden bevestigd door de onderzoeksgemeenschap. Met name de recente vooruitgang met meertalige modellen zou kunnen helpen bij het overdragen van geleerde kennis uit andere programmeertalen naar IC-ontwerp. Naast de algemene uitdagingen voor ML op het gebied van codesamenvatting, kan de intrinsieke temporele parallelliteit in IC-ontwerp en verificatiecode uitdagingen opleveren die ongebruikelijk zijn in andere programmeertalen.
Specificatiemining is een langdurig software-engineeringonderwerp geweest. Als alternatief voor het handmatig opstellen van specificaties, haalt het specificaties indirect uit de uitvoering van het ontwerp onder test (DUT). ML kan worden toegepast om terugkerende patronen uit simulatiesporen te ontginnen. Het kan helpen bij het automatiseren van op simulatie gebaseerde dekkingsafsluiting of formele verificatie. Aangenomen wordt dat vaak terugkerende patronen het verwachte gedrag van de DUT zouden kunnen zijn. Als alternatief kan een gebeurtenispatroon dat zelden voorkomt in de sporen als een anomalie worden beschouwd; daarom kan het worden gebruikt voor diagnostische en foutopsporingsdoeleinden.
ML is toegepast bij het ontdekken van patronen en het detecteren van afwijkingen in veel domeinen waar tijdelijke gegevens van een complex systeem beschikbaar zijn. Azeem et al. een algemene software-engineeringbenadering voorstellen waarbij ML wordt gebruikt om formele specificaties te ontdekken door protocolsporen te observeren en de mogelijke problematische implementatie van het protocol te vinden. Succesvolle experimenten hebben geleid tot interessante vervolgonderzoeksprojecten in specificatiemining met ML.
Statische code-analyse
Naarmate de kosten voor het oplossen van een bug exponentieel toenemen tijdens de fasen van IC-ontwikkeling, biedt statische code-analyse een aantrekkelijke optie om de codekwaliteit en onderhoudbaarheid in een vroeger stadium van de ontwerpontwikkeling te verbeteren.
Codegeur verwijst naar suboptimale ontwerppatronen in de broncode, die syntactisch en semantisch correct kunnen zijn, maar in strijd zijn met best practices en kunnen leiden tot slechte codeonderhoudbaarheid. Een specifiek voorbeeld is codeduplicatie, waarbij dezelfde functie meerdere keren wordt geïmplementeerd in een project of in de gehele codebasis. Bij sommige exemplaren kan een bepaalde bug in relatief korte tijd worden verholpen, terwijl dezelfde bug in andere exemplaren onopgemerkt blijft.
Detectie van klassieke codegeur is gebaseerd op gedefinieerde heuristische regels om patronen in de broncode te identificeren. In plaats van deze regels en statistieken handmatig te ontwikkelen in de statische code-analysetools, kan een op ML gebaseerde aanpak worden getraind op een grote hoeveelheid beschikbare broncode om codegeuren te identificeren. Onderzoek heeft aangetoond dat geurdetectie met ML kan leiden tot universele codegeurdetectie en aanzienlijk minder inspanningen voor patroonimplementatie. De resulterende geurscore kan vervolgens worden gebruikt voor beoordeling van de codekwaliteit en helpt ontwikkelaars de productkwaliteit consistent te verbeteren. Bovendien kan op ML gebaseerde coderefactoring nuttige tips geven voor het verbeteren van de codegeur of zelfs voor het bevorderen van enkele kandidaat-wijzigingen.
De toepassing van ML in functionele verificatie is nog niet zichtbaar, en de onbeschikbaarheid van grote trainingsdatasets heeft voorkomen dat bestaand onderzoek het potentieel van deze oplossing volledig benut.
Ontwikkelaars die aan IC-ontwerp werken, kunnen het meest productief zijn als ze over de juiste tools beschikken. Eenvoudige code-aanvulling is een standaardfunctie in de moderne Integrated Development Environment (IDE). Er werden echter meer geavanceerde technieken met betrekking tot diep leren voorgesteld, die snel volwassen worden. Het is nu mogelijk om ANN's te trainen met miljarden parameters uit vele grootschalige open-source code-opslagplaatsen om redelijke aanbevelingen te doen voor codefragmenten van de implementatie-intentie van ontwikkelaars of de context.
ML kan IC-ontwikkelaars ook helpen productief te blijven met semantische codezoekopdrachten, waarmee relevante code kan worden opgehaald door NL-query's. Omdat code meestal vol zit met verschillende afkortingen en technisch jargon, kunnen semantische zoekopdrachten effectiever zijn bij het vinden van relevante codefragmenten zonder de sleutelvariabele, functie of modulenamen correct te spellen. Hoewel vergelijkbaar met semantisch zoeken in veel bestaande zoekmachines, kan zoeken met semantische code helpen bij het vinden van verkorte en zeer technische code met vage concepten. De gemiddelde wederzijdse rangorde van het beste model kan al bruikbare scores van 70% behalen.
Hoewel in theorie dezelfde ML-technieken die worden toegepast op andere programmeertalen kunnen worden toegepast op IC-ontwerp, is er nog geen onderzoek gepubliceerd over hulp bij het coderen.
Verificatie versnelling
Recente onderzoeken geven aan dat functionele verificatie nog steeds de meest tijdrovende stap is in het ontwerp van IC's, en functionele en logische fouten zijn nog steeds de belangrijkste oorzaak van een respin. Elke verbetering in de snelheid van functionele verificatie zal een aanzienlijke invloed hebben op de kwaliteit en productiviteit van het IC-ontwerp. ML is gebruikt in zowel formele als op simulatie gebaseerde verificatie voor hun versnelling.
Formele verificatie maakt gebruik van formele wiskundige algoritmen om de juistheid van een ontwerp te bewijzen. Moderne formele verificatie-orkestratie maakt gebruik van formele algoritmen om zich te richten op ontwerpen van verschillende groottes, typen en complexiteiten. Ervaring en heuristiek kunnen ontwikkelaars helpen bij het selecteren van de meest geschikte algoritmen uit de bibliotheek voor een specifiek probleem.
Als statistische methode kan ML niet rechtstreeks formele verificatieproblemen aanpakken. Het is echter bewezen dat het zeer nuttig is bij formele orkestratie. Met zijn voorspelling van computerresources en de waarschijnlijkheid van het oplossen van een probleem, is het mogelijk om formele oplossers te plannen om deze bronnen het beste te gebruiken om de verificatietijd te verkorten door eerst de meest veelbelovende oplossers in te plannen met een lager rekenresourceverbruik. De Ada-boost op beslissingsboom gebaseerde classificatie kan de verhouding van opgeloste instanties van de basislijnorkestratie verbeteren van 95% tot 97%, met een gemiddelde snelheidstoename van 1.85. Een ander experiment was in staat om de benodigde middelen voor formele verificatie te voorspellen met een gemiddelde fout van 32%. Het past iteratief feature engineering toe om zorgvuldig features uit DUT, eigenschappen en formele beperkingen te selecteren, die vervolgens worden gebruikt om een meervoudig lineair regressiemodel te trainen voor voorspelling van resourcevereisten.
In tegenstelling tot formele verificatie kan verificatie op basis van simulatie meestal geen volledige juistheid in het ontwerp garanderen. In plaats daarvan wordt het ontwerp onder een testbank geplaatst met bepaalde willekeurige of vaste patrooninvoerstimuli, terwijl de uitvoer wordt vergeleken met de referentie-uitvoer om te verifiëren of het gedrag van het ontwerp wordt verwacht. Terwijl simulatie het brood en de boter is van functionele verificatie, kan op simulatie gebaseerde verificatie ook last hebben van lange verificatietijden. Het is niet ongebruikelijk dat de verificatie van een complex ontwerp weken in beslag neemt.
Een veelbelovend idee dat wordt besproken en waarmee wordt geëxperimenteerd, is het gebruik van ML om het gedrag van een complex systeem te modelleren en te voorspellen. De Universal Approximation Theorem bewijst dat een meerlaags perceptron (MLP), een feed-forward ANN met ten minste één verborgen laag, elke continue functie met willekeurige nauwkeurigheid kan benaderen. Terwijl is bewezen dat genormaliseerde terugkerende neurale netwerken (RNN's), een gespecialiseerde vorm van ANN, elk dynamisch systeem met geheugen benaderen. Geavanceerde ML-versnellerhardware heeft het mogelijk gemaakt dat ANN's het gedrag van sommige IC-ontwerpmodules kunnen modelleren om hun simulaties te versnellen. Aanzienlijke versnelling kan worden bereikt, afhankelijk van de mogelijkheden van AI-versnellers en de complexiteit van de ML-modellen.
Testgeneratie en afsluiting van de dekking
Naast handmatig gedefinieerde testpatronen, omvatten standaardtechnieken die worden gebruikt bij op simulatie gebaseerde verificatie onder meer willekeurige testgeneratie en op grafieken gebaseerde intelligente testbankautomatisering. Vanwege de "long tail" aard van dekkingsafsluiting kan zelfs een kleine efficiëntieverbetering gemakkelijk resulteren in een aanzienlijk kortere simulatietijd. Veel onderzoek naar de toepassing van ML op functionele verificatie heeft zich op dit gebied gericht.
Uitgebreide ML-onderzoeken hebben aangetoond dat ze het beter kunnen dan willekeurige testgeneratie. Het meeste onderzoek maakt gebruik van een "black box-model", ervan uitgaande dat een DUT een black box is waarvan de invoer kan worden gecontroleerd en de uitvoer kan worden gecontroleerd. Optioneel kunnen enkele testpunten worden waargenomen. Het onderzoek beoogt niet het gedrag van de TU Delft te begrijpen. In plaats daarvan wordt de focus besteed aan het verminderen van onnodige tests. Ze gebruiken verschillende ML-technieken om te leren van historische invoer-/uitvoer-/observatiegegevens om de willekeurige testgeneratoren af te stemmen of om tests te elimineren die waarschijnlijk niet bruikbaar zijn. In een recente ontwikkeling werd een op Reinforcement Learning (RL) gebaseerd model gebruikt om te leren van de uitvoer van een DUT en de meest waarschijnlijke tests voor een cachecontroller te voorspellen. Wanneer de beloning die aan het ML-model wordt gegeven de FIFO-dieptes zijn, kunnen de experimenten leren van historische resultaten en de volledige doel-FIFO-dieptes in verschillende iteraties bereiken, terwijl de op willekeurige tests gebaseerde benadering nog steeds moeite heeft om meer dan 1 te halen. Een ML-architectuur met een veel fijnere granulariteit vereist dat voor elk dekkingspunt een ML-model wordt getraind. Een ternaire classificator wordt ook gebruikt om te helpen beslissen of een test moet worden gesimuleerd, weggegooid of gebruikt om een model verder te trainen. Support vector machine (SVM), random forest en deep neural network worden allemaal geëxperimenteerd op een CPU-ontwerp. Het kan 100% dekking sluiten met 3x tot 5x minder tests. Verdere experimenten met FSM- en niet-FSM-ontwerpen hebben reducties van 69% en 72% aangetoond in vergelijking met het genereren van gerichte sequenties. De meeste van deze resultaten lijden echter nog steeds onder de beperking van de statistische aard van ML. Een uitgebreider overzicht van op ML gebaseerde dekkingsgerichte testgeneratie (CDG) geeft een overzicht van verschillende ML-modellen en hun experimentresultaten. Genetische algoritmen van het Bayesiaanse netwerk en genetische programmeerbenaderingen, het Markov-model, datamining en inductieve logische programmering zijn allemaal experimenten met verschillende mate van succes.
In alle besproken benaderingen kan een ML-model een voorspelling doen op basis van het leren van historische gegevens die het heeft verzameld, maar heeft het minimale vermogen om de toekomst te voorspellen, dwz welke test een meer veelbelovende optie zou kunnen zijn om een ongedekt testdoel te halen. Aangezien dit soort informatie nog niet beschikbaar is, kunnen ze het beste de tests kiezen die het meest irrelevant zijn voor de historische tests. Een ander veelbelovend experiment onderzocht een andere aanpak, waarbij de DUT wordt beschouwd als een witte doos en de code wordt geanalyseerd en omgezet in een Control / Data Flow Graph (CDFG). Een op gradiënt gebaseerde zoekopdracht op een getraind Graph Neural Network (GNN) wordt gebruikt om tests te genereren voor een vooraf gedefinieerd testdoel. De experimenten op IBEX v1, v2 en TPU behaalden een nauwkeurigheid van 74%, 73% en 90% bij dekkingsvoorspelling wanneer getraind met 50% dekkingspunten. Verschillende aanvullende experimenten bevestigen ook dat de toegepaste gradiëntzoekmethode ongevoelig is voor de GNN-architectuur.
Opgemerkt wordt dat vanwege de onbeschikbaarheid van trainingsgegevens, de meeste van deze ML-benaderingen alleen leren van elk ontwerp zonder gebruik te maken van enige voorkennis van andere vergelijkbare ontwerpen.
Bug-analyse
Buganalyse heeft tot doel potentiële bugs te identificeren, de codeblokken die ze bevatten te lokaliseren en suggesties voor het oplossen te doen. Uit recente onderzoeken is gebleken dat de verificatie van een IC ongeveer evenveel tijd kost als aan het ontwerp en dat functionele bugs bijdragen aan ongeveer 50% van de respins voor een ASIC-ontwerp. Daarom is het van cruciaal belang dat deze bugs kunnen worden geïdentificeerd en verholpen in de vroege functionele verificatiefase. ML is gebruikt om ontwikkelaars te helpen bugs in ontwerpen op te sporen en bugs sneller te vinden.
Er moeten drie progressieve problemen worden opgelost om het opsporen van bugs bij functionele verificatie te versnellen, namelijk clustering van bugs op basis van hun hoofdoorzaken, classificatie van hoofdoorzaken en suggesties voor oplossingen. Het meeste onderzoek richt zich op de eerste twee, terwijl er nog geen onderzoeksresultaten over de derde beschikbaar zijn.
Semi-gestructureerde simulatielogbestanden kunnen worden gebruikt voor buganalyse. Het extraheert 616 verschillende functies uit metadata en berichtregels uit logbestanden van geheime ontwerpen. Het experiment met clustering behaalde een Adjusted Mutual Information (AMI) van 0.543 met K-means en agglomeratieve clustering en 0.593 met DBSCAN, zelfs na reductie van kenmerkdimensionaliteit, verre van ideale clustering wanneer AMI 1.0 bereikt. Verschillende classificatie-algoritmen werden ook getest om hun nauwkeurigheid te bepalen bij het oplossen van probleem 2. Alle algoritmen, inclusief random forest, Support Vector Classification (SVC), beslissingsboom, logistische regressie, K-neighbours en naïeve Bayes, worden vergeleken op hun vermogen om onderliggende oorzaken voorspellen. De beste score werd behaald door willekeurig bos met een voorspellingsnauwkeurigheid van 90.7% en 0.913 F1-scores. Een andere benadering stelt voor om een gelabelde dataset van code commit te gebruiken om een gradiënt boosting model te trainen, waarbij meer dan 100 features over auteurs, revisies, codes en projecten werden getest totdat er 36 werden geselecteerd voor het algoritme. De experimenten laten zien dat het mogelijk is om te voorspellen welke commits de meeste kans hebben om code met fouten te bevatten en mogelijk de tijd voor het handmatig opsporen van bugs aanzienlijk te verminderen.
Vanwege de relatieve eenvoud van de toegepaste ML-technieken zijn ze echter niet in staat om ML-modellen te trainen die rekening kunnen houden met rijke semantiek in code of kunnen leren van historische bugfixes. Daarom kunnen ze niet uitleggen waarom en hoe de bugs optreden, noch voorstellen om de code te herzien om bugs automatisch of semi-automatisch te elimineren.
Opkomende ML-technieken en -modellen die van toepassing zijn op functionele verificatie
De afgelopen jaren zijn er aanzienlijke doorbraken geweest in ML-technieken, modellen en algoritmen. Uit ons onderzoek is gebleken dat zeer weinig van deze opkomende technieken worden overgenomen door onderzoek naar functionele verificatie, en we zijn optimistisch dat groot succes mogelijk zal zijn als ze eenmaal worden gebruikt om uitdagende problemen bij functionele verificatie aan te pakken.
Op transformatoren gebaseerde grootschalige NL-modellen met miljarden parameters, getraind op de enorme hoeveelheden tekstcorpus, bereikten bijna-menselijke of bovenmenselijke prestaties in verschillende NL-taken, bijvoorbeeld het beantwoorden van vragen, machinevertaling, tekstclassificatie, abstracte samenvatting en anderen. De toepassing van deze onderzoeksresultaten in code-analyse heeft ook het grote potentieel en de veelzijdigheid van deze modellen aangetoond. Het is aangetoond dat deze modellen echt een groot corpus aan trainingsgegevens kunnen opnemen, de geleerde kennis kunnen structureren en gemakkelijk toegankelijk kunnen zijn. Deze mogelijkheid speelt een belangrijke rol bij de analyse van statische code, het opstellen van vereisten en het coderen van verschillende populaire programmeertalen. Gegeven voldoende trainingsgegevens, is het redelijk om aan te nemen dat deze technieken ML-modellen kunnen trainen voor verschillende functionele verificatietaken.
Tot voor kort was het moeilijk om ML toe te passen op grafische gegevens vanwege de complexiteit van hun structuur. De vooruitgang van Graph Neural Network (GNN) heeft een nieuwe kans voor functionele verificatie beloofd. Een van die benaderingen zet een ontwerp om in een code-/gegevensstroomgrafiek, die vervolgens verder wordt gebruikt om een GNN te trainen om te helpen bij het voorspellen van de dekkingsafsluiting van een test. Dit soort white box-benadering belooft eerder niet-beschikbaar inzicht in de besturing en gegevensstroom in een ontwerp, dat gerichte tests kan genereren om potentiële gaten in de dekking op te vullen. Grafieken kunnen rijke relationele, structurele en semantische informatie vertegenwoordigen die men tegenkomt bij verificatie. De rijke informatie van het trainen van een ML-model op grafieken kan veel nieuwe mogelijke functionele verificatietaken opleveren, bijvoorbeeld het opsporen van bugs en het sluiten van dekking.
Conclusie
EDA 4.0 transformeert elektronische ontwerpautomatisering door de kracht van kunstmatige intelligentie en levert verschillende sleuteltechnologieën die ingenieurs zullen helpen de revolutionaire veranderingen van Industry 4.0 te realiseren. In dit artikel geven we een uitgebreid overzicht van de mogelijke bijdragen van machine learning bij het aanpakken van verschillende aspecten van functionele verificatie. Het artikel belicht de typische toepassingen van ML in functionele verificatie en vat de state-of-the-art prestaties op dit gebied samen.
Ondanks de toepassing van diverse ML-technieken, berust het huidige onderzoek echter voornamelijk op basis-ML-methoden en wordt het beperkt door de beschikbaarheid van trainingsgegevens. Deze situatie doet denken aan de vroege stadia van ML-toepassingen in andere geavanceerde domeinen, wat aangeeft dat ML-toepassingen in functionele verificatie zich nog in de beginfase bevinden. Er blijft een aanzienlijk onbenut potentieel voor het gebruik van geavanceerde technieken en modellen om de mogelijkheden van ML volledig te benutten. Bovendien is het gebruik van semantische, relationele en structurele informatie in de huidige ML-toepassingen nog steeds niet volledig gerealiseerd.
Voor een meer gedetailleerde verkenning van dit onderwerp, nodigen wij u uit om onze white paper getiteld te raadplegen Een overzicht van toepassingen voor machinaal leren in functionele verificatie. In deze whitepaper gaan we dieper in op het onderwerp, bieden we inzichten vanuit een industrieel perspectief en bespreken we de dringende uitdaging die de beperkte beschikbaarheid van gegevens met zich meebrengt. Het volledige artikel bevat ook uitgebreide verwijzingen naar het fascinerende onderzoek en de geschriften die een groot deel van dit artikel informeren.
Harry Foster is Chief Scientist Verification voor Siemens Digital Industries Software; en is de mede-oprichter en uitvoerend redacteur van de Verification Academy. Foster was de algemene voorzitter van de Design Automation Conference 2021 en is momenteel voorzitter van het verleden. Hij heeft meerdere patenten in verificatie en is co-auteur van zes boeken over verificatie. Foster is de ontvanger van de Accellera Technical Excellence Award voor zijn bijdragen aan de ontwikkeling van industriestandaarden en was de oorspronkelijke maker van de Accellera Open Verification Library (OVL)-standaard. Daarnaast is Foster de ontvanger van de ACM Distinguished Service Award 2022 en de IEEE CEDA Outstanding Service Award 2022.
Tom Fitzpatrick is een Strategic Verification Architect bij Siemens Digital Industries Software (Siemens EDA), waar hij werkt aan de ontwikkeling van geavanceerde verificatiemethodologieën, talen en standaarden. Hij heeft een belangrijke bijdrage geleverd aan verschillende industriestandaarden die het functionele verificatielandschap de afgelopen 25 jaar drastisch hebben verbeterd, waaronder Verilog 1364, SystemVerilog 1800 en UVM 1800.2. Hij is een van de oprichters en huidig vicevoorzitter van de Accellera Portable Stimulus Working Group en is momenteel voorzitter van de IEEE 1800 en Accellera UVM-AMS Working Groups. Fitzpatrick is al lang lid van de DVCon US Steering Committee en is de algemene voorzitter van DVConUS 2024. Hij is ook lid van het Design Automation Conference Executive Committee. Fitzpatrick heeft master- en bachelordiploma's in Electrical Engineering en Computer Science van MIT.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://semiengineering.com/welcome-to-eda-4-0-and-the-ai-driven-revolution/

