Pas vierentwintig uur nadat Google's Gemini publiekelijk werd vrijgegeven, merkte iemand dat chats publiekelijk werden weergegeven in de zoekresultaten van Google. Google reageerde snel op wat leek op een lek. De reden waarom dit gebeurde is nogal verrassend en niet zo sinister als het op het eerste gezicht lijkt.
@semiadhikarath tweeted:
“Een paar uur na de lancering van @Google Gemini hebben zoekmachines zoals Bing openbare gesprekken van Gemini geïndexeerd.”
Ze plaatsten een screenshot van de sitezoekopdracht op gemini.google.com/share/
Maar als je naar de schermafbeelding kijkt, zie je dat er een bericht is met de tekst: "We willen je hier graag een beschrijving laten zien, maar de site staat dit niet toe."
Op dinsdag 13 februari in de vroege ochtend begonnen de Google Gemini-chats uit de zoekresultaten van Google te verdwijnen. Google liet slechts drie zoekresultaten zien. Tegen de middag was het aantal gelekte Gemini-chats dat in de zoekresultaten werd weergegeven, geslonken tot slechts één zoekresultaat.
Hoe zijn Gemini-chatpagina's gemaakt?
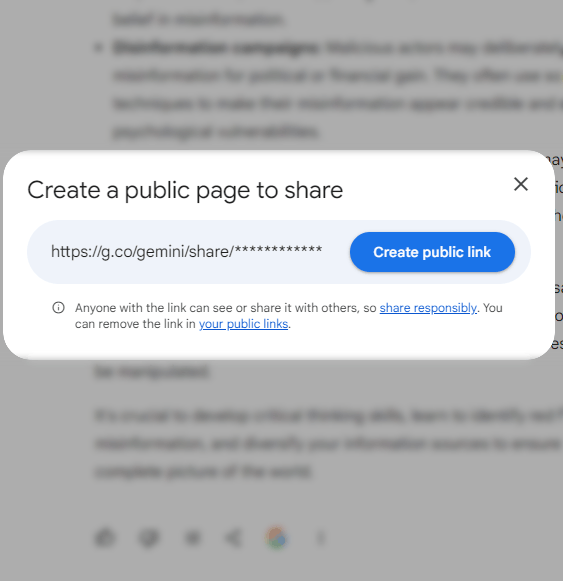
Gemini biedt een manier om een link te maken naar een publiekelijk zichtbare versie van een privéchat.
Google maakt niet automatisch webpagina's op basis van privéchats. Gebruikers maken de chatpagina's via een link onderaan elke chat.
Schermafbeelding van hoe u een gedeelde chatpagina maakt
Waarom zijn Gemini-chatpagina's geïndexeerd?
De voor de hand liggende reden waarom de chatpagina's werden gecrawld en geïndexeerd, is omdat Google vergat een robots.txt in de hoofdmap van het Gemini-subdomein (gemini.google.com) te plaatsen.
Een robots.txt-bestand is een document voor het controleren van de crawleractiviteit op websites. Een uitgever kan specifieke crawlers blokkeren door opdrachten te gebruiken die zijn gestandaardiseerd in het Robots.txt-protocol.
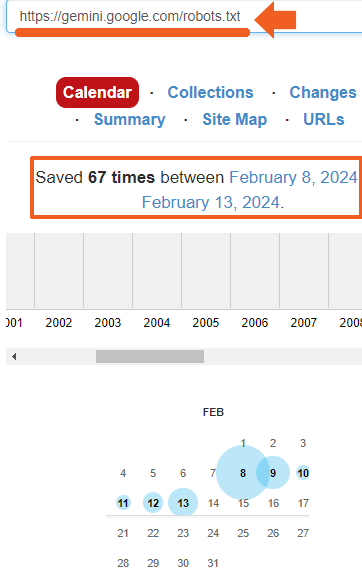
Ik controleerde de robots.txt om 4:19 uur op 13 februari en zag dat er een aanwezig was:

Vervolgens controleerde ik het internetarchief om te zien hoe lang het robots.txt-bestand al aanwezig was en ontdekte dat het daar stond sinds minstens 8 februari, de dag waarop de Gemini Apps werden aangekondigd.
Screenshot uit internetarchief
Dat betekent dat de voor de hand liggende reden waarom de chatpagina's werden gecrawld niet de juiste reden is, maar gewoon de meest voor de hand liggende reden.
Hoewel het Google Gemini-subdomein een robots.txt had die webcrawlers van zowel Bing als Google blokkeerde, hoe kwamen ze er uiteindelijk toe om die pagina's te crawlen en te indexeren?
Twee manieren waarop privéchatpagina's worden ontdekt en geïndexeerd
- Mogelijk is er ergens een openbare link.
- Minder waarschijnlijk, maar misschien wel mogelijk, is dat ze zijn ontdekt via de browsergeschiedenis die is gekoppeld aan cookies.
Het is waarschijnlijker dat er openbare links zijn.
Ik vroeg Bill Hartzer (@bhartzer) erover en hij ontdekte a openbare link voor een van de geïndexeerde pagina's:

Nu weten we dus dat het zeer waarschijnlijk is dat een openbare link ervoor heeft gezorgd dat deze Gemini Chat-pagina's zijn gecrawld en geïndexeerd.
Bill Hartzer maakte deze observatie:
“Ook al wordt de Gemini-URL geblokkeerd in het robots.txt-bestand, er is een link naar de Gemini-URL in een blogcommentaar, zodat de Gemini-URL wordt geïndexeerd.
Dit laat alleen maar zien dat Google nog steeds URL's indexeert die zijn geblokkeerd voor crawlen in het robots.txt-bestand.
Als Google er echt zeker van wilde zijn dat de Gemini-URL niet wordt geïndexeerd, zouden ze het crawlen van het robots.txt-bestand TOESTAAN en een noindex-metatag aan de pagina's toevoegen. Misschien moet Google hier zijn eigen advies volgen?”
Waarom begonnen chatpagina's uit de zoekresultaten te verdwijnen?
Maar als er een openbare link is, waarom is Google dan helemaal begonnen met het schrappen van chatpagina's? Heeft Google een interne regel gemaakt voor de zoekcrawler om webpagina's uit de map /share/ uit te sluiten van de zoekindex, zelfs als ze openbaar zijn gelinkt?
Inzicht in hoe Bing en Google Search inhoud indexeren
Dit is het echt interessante deel voor alle zoekgeeks die geïnteresseerd zijn in hoe Google en Bing inhoud indexeren.
De zoekindex van Microsoft Bing reageerde anders op de Gemini-inhoud dan de zoekfunctie van Google. Terwijl Google in de vroege ochtend van 13 februari nog drie zoekresultaten liet zien, liet Bing slechts één resultaat zien van het subdomein. Er was een schijnbaar willekeurige kwaliteit aan wat er werd geïndexeerd en hoeveel ervan.
Waarom lekten Gemini-chatpagina's?
Hier zijn de bekende feiten:
- Google heeft sinds 8 februari een robots.txt in gebruik.
- Zowel Google als Bing indexeerden pagina's van het subdomein gemini.google.com.
- Zowel Google als Bing hebben mogelijk links naar de chats ontdekt en deze vervolgens geïndexeerd.
- De zoekmachines indexeerden de inhoud ongeacht de robots.txt en begonnen deze vervolgens te dumpen.
Dat brengt ons terug bij de vraag waarom deze pagina’s uit de zoekresultaten van zowel Google als Bing verdwenen. Ik vermoed dat de Google Gemini-chatpagina's webpagina's van lage kwaliteit zijn die niet de moeite waard zijn om te laten zien voor wat in wezen longtail-zoekopdrachten zijn (site:gemini.google.com/share/). Er is eigenlijk geen bruikbare reden om deze pagina's in de zoekresultaten weer te geven.
Content die door Robots.txt wordt geblokkeerd, kan nog steeds worden ontdekt, gecrawld en in de zoekindex terechtkomen en als de pagina’s nuttig zijn, kunnen ze ook ranken, tenzij ze niet nuttig zijn. Ik denk dat dit het geval kan zijn.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.searchenginejournal.com/google-gemini-leak/508126/

