Introductie
De data-integratietechnieken ETL (Extract, Transform, Load) en ELT-pijplijnen (Extract, Load, Transform) worden beide gebruikt om gegevens van het ene systeem naar het andere over te dragen.
De informatie wordt uit een of meer gegevensbronnen gehaald, getransformeerd in een formaat dat compatibel is met het doelsysteem en vervolgens in het doelsysteem geladen als onderdeel van het ETL-proces. Een ETL-tool of -platform dat het proces organiseert, doet deze taak vaak. Om aan de behoeften van het doelsysteem te voldoen, moeten gegevens tijdens de transformatiefase worden opgeschoond, gevalideerd, geïntegreerd en verbeterd.
De ELT-pijplijn daarentegen houdt in dat gegevens uit een of meer gegevensbronnen worden verwijderd, naar het bestemmingssysteem worden gebracht en daar worden gewijzigd. Hiervoor kunnen databasebeheeroplossingen worden gebruikt die grote hoeveelheden gegevens kunnen verwerken, zoals SQL of Apache Spark. Deze methode is voordelig wanneer de gegevensbron in het oorspronkelijke formaat moet worden bewaard en het doelsysteem de vereiste transformaties kan uitvoeren.
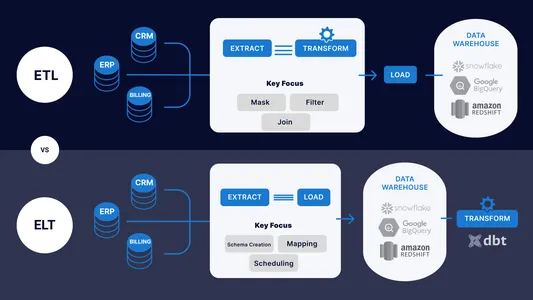
ETL- en ELT-pijplijnen integreer gegevens uit verschillende systemen, waaronder databases, applicaties en bestanden, om een consistent en uniform beeld van de gegevens te genereren voor analyse, rapportage en besluitvorming.
leerdoelen
Aan het einde van dit artikel leert u de verschillen tussen ETL- en ELT-pijplijnen, hun voor- en nadelen, en hun toepassing in verschillende gevallen, zoals datawarehousing, business intelligence, data-integratie, enz. Men zou ook leren over enkele methoden voor het ontwerpen van succesvolle ETL/ELT-pijplijnen, hoe tools zoals Talend, Apache Nifi, Apache Spark, enz. kunnen worden gebruikt, en welke strategieën voor monitoring en probleemoplossing kunnen worden gebruikt voor ETL- en ELT-pijplijnen.
Inhoudsopgave
Verschillen tussen ETL- en ELT-pijpleidingen
| ETL (EXTRACTIE, TRANSFORMATIE EN LADEN) | ELT (EXTRACTIE, LADING EN TRANSFORMATIE) |
| De informatie wordt eerst uit bronsystemen geëxtraheerd, omgezet in een formaat dat het doelsysteem kan gebruiken en vervolgens in het doelsysteem geplaatst. | De informatie wordt eerst in het bestemmingssysteem geladen voordat de nodige wijzigingen in de gegevens daar worden aangebracht. |
| ETL-pijplijnen kunnen nuttiger zijn wanneer gegevens moeten worden getransformeerd naar een indeling die het doelsysteem niet standaard ondersteunt. Dit leidt tot een lange conversietijd en meer hardware. | ELT werkt door het werk op te splitsen in kleinere batches en parallelle verwerking te gebruiken, waardoor het sneller werkt. |
| De schaalbaarheid van ETL kan worden beperkt omdat gegevens worden gewijzigd voordat deze in een doelsysteem worden ingevoerd. | Ze zijn beter schaalbaar omdat het gaat om het laden van gegevens in een doelsysteem, dat vervolgens wordt getransformeerd met behulp van gedistribueerde computertools zoals Hadoop of Spark. |
| Ze zijn doorgaans eenvoudiger te onderhouden omdat het meer controle biedt over de consistentie en kwaliteit van gegevens, wat de kans op fouten kan verkleinen en het onderhoud van pijpleidingen in de loop van de tijd eenvoudiger kan maken. | Tijdens het gebruik van ELT-pijplijnen kan het een grotere uitdaging zijn om problemen op te sporen en de pijplijn te onderhouden, omdat gegevens in het doelsysteem worden geladen voordat ze worden getransformeerd. |
| Het maakt gebruik van goedkopere dan eigen ETL-systemen, zoals Hadoop en Spark, die de verwerkingskosten helpen verlagen. | Ze zijn duurder in termen van kosten omdat het open-sourcetechnologieën gebruikt. |
Concluderend, de keuze tussen ETL- en ELT-pijplijnen is gebaseerd op de specifieke eisen van het data-integratieproject, zoals de kenmerken van de bron- en doelsystemen, het volume en de complexiteit van de data, en de vereisten voor prestaties en schaalbaarheid.
Voors en tegens van ETL- en ELT-pijpleidingen
In eenvoudige en duidelijke taal zijn de voor- en nadelen van ETL- en ELT-pijplijnen voor verschillende use-cases als volgt:
Voordelen van ETL
- Wanneer informatie moet worden geconverteerd naar een indeling die het doelsysteem niet standaard ondersteunt, is ETL nuttig.
- ETL kan gegevens uit vele bronnen combineren tot één beeld voor evaluatie en besluitvorming.
- ETL-pijplijnen kunnen efficiënter worden gemaakt door batch- en parallelle verwerking te gebruiken.
Beperkingen van ETL
- ETL kan arbeidsintensief zijn en veel hardwarebronnen vergen, vooral voor geavanceerde transformaties en aanzienlijke datavolumes.
- Om de transformatielogica te creëren en toe te passen, kan ETL gespecialiseerde talenten nodig hebben.
- Vanaf het moment dat informatie wordt verzameld tot het moment dat deze beschikbaar is voor analyse, kunnen ETL-processen vertragingen veroorzaken.
Voordelen van ELT
- Wanneer het doelsysteem de gegevens in zijn eigen formaat kan verwerken en transformeren, kan ELT efficiënter en sneller worden uitgevoerd.
- Wanneer gegevens in hun oorspronkelijke vorm moeten worden bewaard en alleen moeten worden gewijzigd voor analyse en rapportage, is ELT nuttig.
- ELT kan gebruikmaken van de flexibiliteit en rekencapaciteit van moderne databasebeheersystemen.
Beperkingen van ELT
- Voordat ELT transformaties uitvoert, heeft het mogelijk veel opslagruimte nodig om de gegevens te bewaren.
- Het schrijven van gecompliceerde SQL-query's kan gedetailleerde informatie vereisen voor gegevenstransformaties met behulp van ELT.
- Het doelsysteem kan door ELT complexer worden, waardoor onderhoud moeilijker wordt.
Toepassing van ETL-pijpleidingen
Toepassingen voor datawarehousing en data-analyse worden vaak gebruikt ETL-pijplijnen. In eenvoudige en begrijpelijke taal zijn de volgende voorbeelden van gebruiksscenario's voor ETL-pijplijnen:
- Data opslagplaats: In een datawarehouse combineert ETL gegevens uit verschillende bronnen tot een uniform beeld. De gegevens worden opgeschoond, in een standaardformaat gezet en gecontroleerd om kwaliteit en consistentie te garanderen. ETL laadt regelmatig gegevens in het datawarehouse om de gegevens actueel te houden.
- Bedrijfsintelligentie: ETL haalt informatie uit transactiesystemen en laadt deze in een datawarehouse of datamart in business intelligence-toepassingen. Om rapportage en analyse mogelijk te maken, wordt de informatie getransformeerd en geconsolideerd. Het verzamelen, verwerken en laden van de gegevens in het rapportagesysteem is geautomatiseerd en gepland met behulp van ETL.
- Gegevens integratie: Om informatie uit verschillende bronnen te combineren in één systeem, wordt ETL gebruikt. Een voorbeeld is datafusie uit vele databases, spreadsheets en bestanden. ETL wordt gebruikt om ervoor te zorgen dat gegevens nauwkeurig en uniform zijn en om de gegevens om te zetten in een indeling die het bestemmingssysteem kan gebruiken.
- Data migratie: Om informatie van het ene systeem naar het andere over te dragen, wordt ETL gebruikt in datamigratieprojecten. Het kan hierbij gaan om datatransfers van een verouderd systeem naar een nieuw systeem of het combineren van data uit verschillende systemen. ETL wordt tijdens het migratieproces gebruikt om de informatie te transformeren en te controleren.
Toepassing van ELT-leidingen
ELT-processen (Extract, Load, Transform) worden veel gebruikt bij gegevensverwerking en -analyse om grote hoeveelheden gegevens voor te bereiden voor later gebruik. Hieronder volgen enkele vereenvoudigde gebruiksgevallen:
- Data opslagplaats: ELT-pijplijnen worden vaak gebruikt in datawarehousing om gegevens uit verschillende bronnen te extraheren, waaronder databases, cloudopslag en online API's. Na te zijn getransformeerd, worden de gegevens in een databasesysteem geplaatst voor aanvullende analyse.
- Big Data-verwerking: Het analyseren van enorme hoeveelheden data, inclusief dergelijke datastromen of logbestanden, maakt met name gebruik van ELT-pijplijnen. De informatie wordt eerst opgehaald en in een gedistribueerde database geplaatst, zoals Hadoop, voordat deze wordt geparalleliseerd met behulp van onder andere Spark of Hive.
- Machine Learning: Gegevensverwerking voor machine learning-toepassingen kan worden gedaan via ELT-pijplijnen. Om dit te doen, moeten gegevens uit verschillende bronnen worden verzameld, opgeschoond en getransformeerd om klaar te zijn voor modellering, en vervolgens worden geladen in een raamwerk voor machine learning zoals TensorFlow of PyTorch.
- Bedrijfsintelligentie: Om zakelijke gebruikers dashboards en rapporten te bieden, kunnen ELT-pijplijnen gegevens uit verschillende bronnen verzamelen en transformeren, waaronder klantgegevens, verkoopgegevens en webanalyses.
Technieken voor het ontwerpen van efficiënte ETL- of ELT-pijpleidingen
Extractie, laden en transformeren, of ETL, pijplijnontwerp zorgt ervoor dat gegevensverwerkingstaken snel en nauwkeurig worden voltooid. Hieronder volgen enkele methoden voor het ontwerpen van succesvolle ETL/ELT-pijplijnen:
- Gegevenspartitionering: Gegevenspartitionering verdeelt grote datasets in beter beheersbare delen voor parallelle verwerking. Door de hoeveelheid gegevens die tegelijk moet worden verwerkt te beperken, kan partitionering de snelheid en efficiëntie van gegevensverwerking helpen verhogen.
- Data-opschoning: Het opschonen van gegevens omvat het lokaliseren en oplossen van gebreken of inconsistenties in de gegevens. Technieken voor het opschonen van gegevens kunnen hierbij betrokken zijn
- Het verwijderen van dubbele of irrelevante informatie
- Corrigeren van spelling- of grammaticale problemen
- Zorgen voor gegevensconsistentie tussen verschillende bronnen
- Gegevenstransformatie: Datatransformatie is het veranderen van het formaat of de organisatie van data. Variërende gegevenstypen, het combineren of samenvoegen van databases en het verzamelen of evalueren van informatie zijn enkele voorbeelden van procedures voor gegevenstransformatie.
- Incrementeel laden: Bij totaal laden worden alleen de gegevens verwerkt die zijn gewijzigd of toegevoegd sinds de vorige verwerkingsrun. Met name voor grote datasets kan incrementeel laden helpen om de hoeveelheid tijd en middelen die nodig zijn voor gegevensverwerking te verminderen.
- Taakplanning: Op basis van variabelen, waaronder beschikbare gegevens, verwerkingstijd en beschikbare middelen, omvat dit proces het opstellen van een efficiënt tijdschema voor het uitvoeren van ETL/ELT-processen. Een efficiënt programma kan de totale verwerkingstijd verkorten en een tijdige en correcte gegevensverwerking garanderen.
Softwareprogramma's genaamd ETL- en ELT-tools worden gebruikt voor gegevensintegratie, -verwerking en -transformatie. Het volgende is een vereenvoudigde vergelijking van enkele bekende ETL- en ELT-tools:
- Talen: Talend is een open-source data-integratie- en transformatieplatform dat een verscheidenheid aan connectoren en elementen voor datatransformatie biedt. Het biedt een eenvoudige gebruikersinterface en ondersteunt zowel slepen en neerzetten als programmeermethoden. Het biedt mogelijkheden die relevant zijn voor de ontwikkeling en controles van de informatiekwaliteit en ondersteunt batch- en real-time verwerking.
- Informatica: Een geavanceerde analytische integratie- en transformatieoperatie kan worden ondersteund door het commerciële ETL-product Informatica. Het biedt een visueel ontwikkelingsplatform en veel connectoren voor verschillende gegevensbronnen. Coherence biedt functies zoals gegevensbeheer, gegevensmanipulatie en gegevensintegriteit.
- Apache NiFi: Apache NiFi is een open-source ELT-tool voor gegevensstroombeheer genaamd Apache NiFi. Het bevat een reeks gegevensopname-, transformatie- en routeringsprocessors en biedt een webgebaseerde gebruikersinterface. Gegevensherkomst en afstammingskenmerken worden geleverd door Apache NiFi, dat ook real-time gegevensverwerking biedt.
- Apache Spark: ETL en ELT kunnen worden uitgevoerd met behulp van Apache Spark, een open en gedistribueerde computertechnologie. Het maakt bulk- en daadwerkelijke gegevensverwerking mogelijk en biedt snelle gegevensverwerking. Spark biedt machine learning, grafiekanalyse en uitzendfuncties en ondersteunt verschillende programmeertalen.
Rol van gegevensintegratie en gegevenskwaliteit
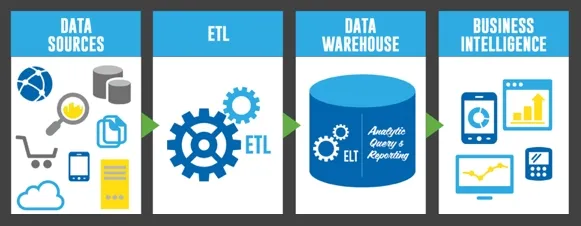
Het combineren van gegevens uit verschillende bronnen om een uniform beeld van de gegevens te geven, wordt data-integratie genoemd. Gegevens uit vele bronnen zijn verbonden met behulp van ETL (Extract, Transform, Load) en ELT (Extract, Load, Transform) pijplijnen om een datawarehouse of data lake te creëren.
De kwaliteit van de gegevens meet de nauwkeurigheid, volledigheid, consistentie en validiteit van de gegevens. Gegevenskwaliteit is essentieel bij het instellen van ETL- en ELT-pijplijnen om te garanderen dat de geïntegreerde gegevens veilig en praktisch zijn.
Met andere woorden, datakwaliteit is als controleren of de puzzelstukjes goed in elkaar passen en niet beschadigd zijn of ontbreken. Data-integratie daarentegen is als het samen doen van de delen van een puzzel om het hele plaatje te bekijken. De processen die de puzzelstukjes samenstellen en ervoor zorgen dat ze georiënteerd en in de juiste volgorde geplaatst worden, staan bekend als ETL- en ELT-pijplijnen.
Strategieën voor monitoring en probleemoplossing
Het is essentieel om problemen met ETL (Extract, Transform, Load) en ELT (Extract, Load, Transform) pijplijnen op te sporen en op te lossen om de effectieve en efficiënte werking van het data-integratieproces te garanderen. Hier zijn enkele methoden om dingen in de gaten te houden en problemen op te lossen:
- Problemen met vroegtijdige waarschuwing: Stel waarschuwingen en berichten in om meldingen te ontvangen wanneer een pijplijn faalt of problemen tegenkomt. Hierdoor kunt u problemen aanpakken zodra ze zich voordoen en ze oplossen voordat ze erger worden.
- Pijplijnprestaties bewaken: Het bewaken van de pijplijnprestaties omvat het bijhouden van parameters, waaronder de verwerkingstijd van gegevens, de snelheid van gegevensoverdracht en het gebruik van bronnen. Dit kan helpen bij het optimaliseren van pijpleidingen en het detecteren van obstakels.
- Pijplijnactiviteiten loggen: Log pijplijnbewerkingen om de ontwikkeling van gegevensintegratie te volgen en problemen of fouten te identificeren. Bovendien kunnen logboeken worden gebruikt voor nalevings- en auditdoeleinden.
- Voer regelmatig testen uit: Test regelmatig om ervoor te zorgen dat de pijpleiding naar behoren werkt. Dit kan u helpen bij het opsporen van problemen voordat ze dure downtime worden.
- Samenwerken met belanghebbenden: Werk samen met belanghebbenden: werk samen met belanghebbenden zoals datawetenschappers, ingenieurs en zakelijke gebruikers om problemen op te sporen en op te lossen. Je kunt vraagstukken oplossen en daardoor het informatiemanagementproces goed doorgronden.
Conclusie
De specifieke eisen en vereisten van een project zullen bepalen of ETL of ETL-pijplijn moet worden gebruikt. ETL werkt goed voor kleinschalige projecten die handmatig maatwerk en interventie in elke workflowfase vereisen. Aan de andere kant is een ETL-pijplijn beter geschikt voor enorme projecten met enorme hoeveelheden gegevens die automatisering en standaardisatie nodig hebben om correctheid en efficiëntie te garanderen.
Concluderend, ETL en ETL-pijplijn zijn twee verwante maar verschillende concepten. Een ETL-pijplijn is een geautomatiseerde workflow die het hele ETL-proces van begin tot eind bestuurt. ETL is een gegevensintegratieproces in drie fasen. De omvang, complexiteit en vraag naar maatwerk en automatisering van het project bepalen de beste optie.

Key Takeaways
- In eerste instantie hebben we een overzicht gezien van de verschillen tussen ETL- en ELT-pijplijnen, inclusief de volgorde van gegevensverwerking en implicaties voor de prestaties.
- En vervolgens inzicht krijgen in de voor- en nadelen van ETL- en ELT-pijplijnen voor verschillende gebruiksscenario's.
- De technieken voor het ontwerpen van een efficiënte ETL- of ELT-pijplijn omvatten ook gegevenspartitionering, gegevensopschoning en gegevenstransformatie.
- Vergelijking van populaire ETL- en ELT-tools, waaronder Talend, Informatica, Apache NiFi en Apache Spark.
- Inzicht in de rol van data-integratie en datakwaliteit in ETL- en ELT-pijplijnen.
- Strategieën voor het bewaken en oplossen van problemen met ETL- en ELT-pijplijnen en vergelijking van beide.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/03/difference-between-etl-and-elt-pipelines/

