Amazon Titan Beeldgenerator G1 is een geavanceerd tekst-naar-beeldmodel, beschikbaar via Amazonebodem, dat aanwijzingen kan begrijpen die meerdere objecten in verschillende contexten beschrijven en deze relevante details vastlegt in de afbeeldingen die het genereert. Het is beschikbaar in de AWS-regio's US East (N. Virginia) en US West (Oregon) en kan geavanceerde beeldbewerkingstaken uitvoeren, zoals slim bijsnijden, in-painting en achtergrondwijzigingen. Gebruikers willen het model echter graag aanpassen aan unieke kenmerken in aangepaste datasets waarop het model nog niet is getraind. Aangepaste datasets kunnen zeer bedrijfseigen gegevens bevatten die consistent zijn met uw merkrichtlijnen of specifieke stijlen, zoals een eerdere campagne. Om deze gebruiksscenario's aan te pakken en volledig gepersonaliseerde afbeeldingen te genereren, kunt u Amazon Titan Image Generator verfijnen met uw eigen gegevens aangepaste modellen voor Amazon Bedrock.
Van het genereren van afbeeldingen tot het bewerken ervan, tekst-naar-afbeelding-modellen hebben brede toepassingen in verschillende sectoren. Ze kunnen de creativiteit van medewerkers vergroten en de mogelijkheid bieden om nieuwe mogelijkheden eenvoudigweg met tekstuele beschrijvingen voor te stellen. Het kan bijvoorbeeld het ontwerp en de vloerplanning voor architecten ondersteunen en snellere innovatie mogelijk maken door de mogelijkheid te bieden om verschillende ontwerpen te visualiseren zonder het handmatige proces om ze te maken. Op dezelfde manier kan het helpen bij het ontwerp in verschillende sectoren, zoals productie, modeontwerp in de detailhandel en gameontwerp, door het genereren van afbeeldingen en illustraties te stroomlijnen. Tekst-naar-beeldmodellen verbeteren ook uw klantervaring door gepersonaliseerde advertenties en interactieve en meeslepende visuele chatbots mogelijk te maken in media- en entertainmentgebruiksscenario's.
In dit bericht begeleiden we je bij het verfijnen van het Amazon Titan Image Generator-model om twee nieuwe categorieën te leren: Ron de hond en Smila de kat, onze favoriete huisdieren. We bespreken hoe u uw gegevens kunt voorbereiden op de taak voor het verfijnen van het model en hoe u een taak voor het aanpassen van modellen kunt maken in Amazon Bedrock. Ten slotte laten we u zien hoe u uw verfijnde model kunt testen en implementeren Ingerichte doorvoer.
 |
 |
| Ron de hond | Smila de kat |
Het evalueren van de modelmogelijkheden voordat een taak wordt verfijnd
Foundation-modellen worden getraind op grote hoeveelheden gegevens, dus het is mogelijk dat uw model out-of-the-box goed genoeg werkt. Daarom is het een goede gewoonte om te controleren of u uw model daadwerkelijk moet afstemmen op uw gebruiksscenario of dat snelle engineering voldoende is. Laten we proberen enkele afbeeldingen te genereren van Ron de hond en Smila de kat met het basismodel van Amazon Titan Image Generator, zoals weergegeven in de volgende schermafbeeldingen.
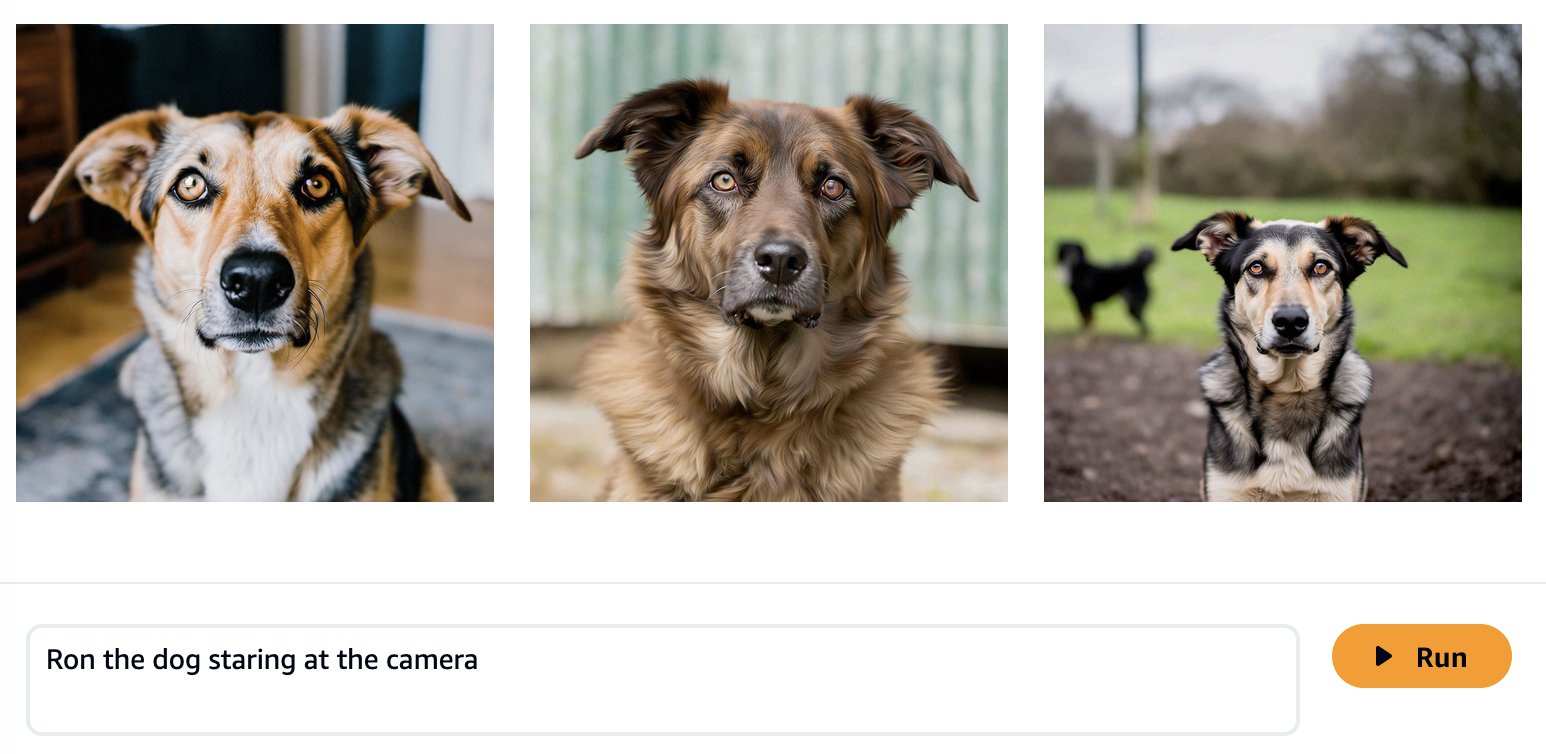

Zoals verwacht kent het kant-en-klare model Ron en Smila nog niet, en de gegenereerde resultaten tonen verschillende honden en katten. Met wat snelle techniek kunnen we meer details geven om het uiterlijk van onze favoriete huisdieren beter te benaderen.


Hoewel de gegenereerde afbeeldingen meer op Ron en Smila lijken, zien we dat het model niet in staat is de volledige gelijkenis ervan te reproduceren. Laten we nu beginnen met het verfijnen van de foto's van Ron en Smila om consistente, gepersonaliseerde resultaten te krijgen.
Verfijning van Amazon Titan Image Generator
Amazon Bedrock biedt u een serverloze ervaring voor het verfijnen van uw Amazon Titan Image Generator-model. U hoeft alleen uw gegevens voor te bereiden en uw hyperparameters te selecteren, en AWS zal het zware werk voor u doen.
Wanneer u het Amazon Titan Image Generator-model gebruikt om het model te verfijnen, wordt er een kopie van dit model gemaakt in het AWS-modelontwikkelingsaccount, eigendom van en beheerd door AWS, en wordt er een modelaanpassingstaak gemaakt. Deze taak heeft vervolgens toegang tot de fijnafstemmingsgegevens van een VPC en de gewichten van het Amazon Titan-model worden bijgewerkt. Het nieuwe model wordt vervolgens opgeslagen in een Amazon eenvoudige opslagservice (Amazon S3) in hetzelfde modelontwikkelingsaccount als het vooraf getrainde model. Het kan nu alleen door uw account worden gebruikt voor gevolgtrekkingen en wordt niet gedeeld met een ander AWS-account. Wanneer u inferentie uitvoert, krijgt u toegang tot dit model via a ingerichte capaciteit rekenkracht of direct, met behulp van batch-inferentie voor Amazon Bedrock. Onafhankelijk van de gekozen gevolgtrekkingsmodaliteit blijven uw gegevens in uw account en worden ze niet gekopieerd naar een AWS-account of gebruikt om het Amazon Titan Image Generator-model te verbeteren.
Het volgende diagram illustreert deze workflow.
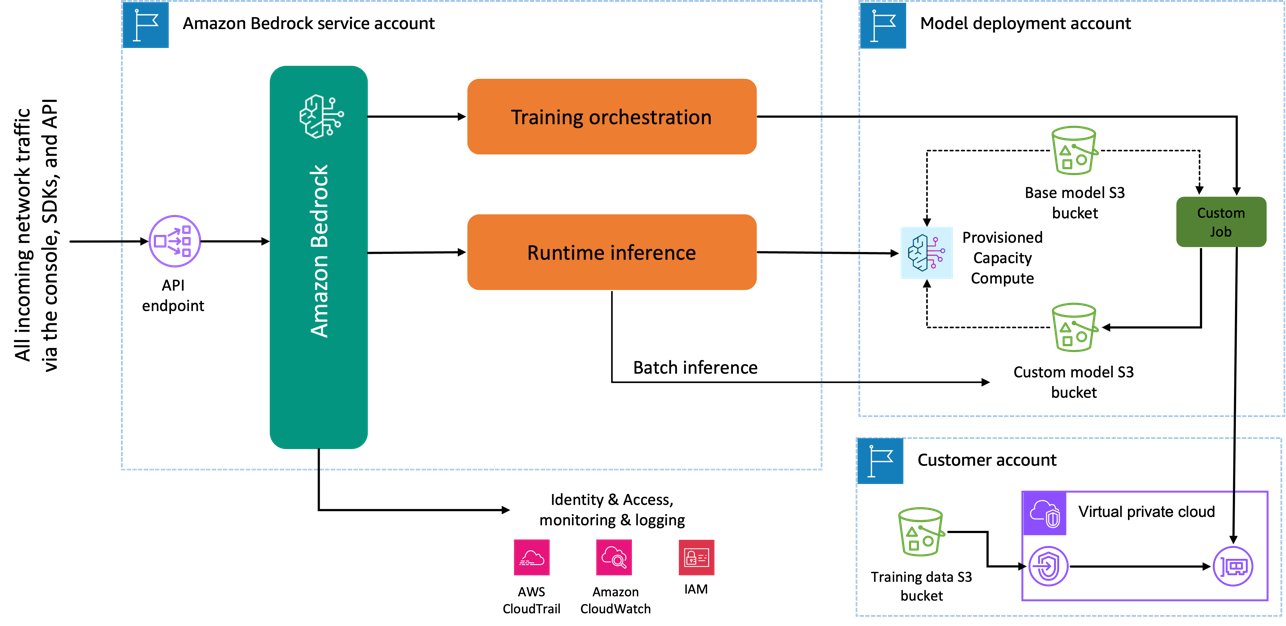
Gegevensprivacy en netwerkbeveiliging
Uw gegevens die worden gebruikt voor het afstemmen, inclusief aanwijzingen, evenals de aangepaste modellen, blijven privé in uw AWS-account. Ze worden niet gedeeld of gebruikt voor modeltraining of serviceverbeteringen, en worden niet gedeeld met externe modelaanbieders. Alle gegevens die voor de fijnafstemming worden gebruikt, worden zowel tijdens de overdracht als in rust gecodeerd. De gegevens blijven in dezelfde regio waar de API-aanroep wordt verwerkt. Je kan ook gebruiken AWS PrivéLink om een privéverbinding tot stand te brengen tussen het AWS-account waar uw gegevens zich bevinden en de VPC.
Data voorbereiding
Voordat u een modelaanpassingstaak kunt maken, moet u dit doen bereid uw trainingsgegevensset voor. Het formaat van uw trainingsgegevensset is afhankelijk van het type aanpassingstaak dat u maakt (verfijning of voortgezette pre-training) en de modaliteit van uw gegevens (tekst-naar-tekst, tekst-naar-afbeelding of afbeelding-naar-afbeelding). inbedden). Voor het Amazon Titan Image Generator-model moet u de afbeeldingen opgeven die u wilt gebruiken voor de verfijning en een bijschrift voor elke afbeelding. Amazon Bedrock verwacht dat je afbeeldingen worden opgeslagen op Amazon S3 en dat de afbeeldingen en bijschriften worden geleverd in een JSONL-indeling met meerdere JSON-regels.
Elke JSON-regel is een voorbeeld met een afbeeldingsreferentie, de S3-URI voor een afbeelding en een bijschrift met een tekstuele prompt voor de afbeelding. Uw afbeeldingen moeten de indeling JPEG of PNG hebben. De volgende code toont een voorbeeld van de indeling:
{"image-ref": "s3://bucket/pad/naar/image001.png", "caption": ""} {"image-ref": "s3://bucket/pad/naar/image002.png", "caption": ""} {"image-ref": "s3://bucket/pad/naar/image003.png", "caption": ""}
Omdat “Ron” en “Smila” namen zijn die ook in andere contexten kunnen worden gebruikt, zoals de naam van een persoon, voegen we de identificatiegegevens “Ron de hond” en “Smila de kat” toe bij het maken van de prompt om ons model te verfijnen . Hoewel het geen vereiste is voor de verfijningsworkflow, biedt deze aanvullende informatie meer contextuele duidelijkheid voor het model wanneer het wordt aangepast voor de nieuwe klassen en voorkomt het de verwarring van 'Ron de hond' met een persoon genaamd Ron en ' Smila de kat” met de stad Smila in Oekraïne. Met behulp van deze logica tonen de volgende afbeeldingen een voorbeeld van onze trainingsdataset.
 |
 |
 |
| Ron de hond ligt op een wit hondenbed | Ron de hond zit op een tegelvloer | Ron de hond liggend op een autostoeltje |
 |
 |
 |
| Smila de kat liggend op een bank | Smila de kat die naar de camera staart terwijl hij op een bank ligt | Smila de kat ligt in een draagtas |
Wanneer we onze gegevens transformeren naar het formaat dat wordt verwacht door de aanpassingstaak, krijgen we de volgende voorbeeldstructuur:
{"afbeelding-ref": "/ron_01.jpg", "caption": "Ron de hond ligt op een wit hondenbed"} {"image-ref": "/ron_02.jpg", "caption": "Ron de hond zit op een tegelvloer"} {"image-ref": "/ron_03.jpg", "caption": "Ron de hond liggend op een autostoeltje"} {"image-ref": "/smila_01.jpg", "caption": "Smila de kat liggend op een bank"} {"image-ref": "/smila_02.jpg", "caption": "Smila de kat zit naast het raam naast een standbeeld van de kat"} {"image-ref": "/smila_03.jpg", "caption": "Smila de kat liggend op een reismand"}
Nadat we ons JSONL-bestand hebben gemaakt, moeten we het opslaan in een S3-bucket om onze aanpassingstaak te starten. De verfijningstaken van Amazon Titan Image Generator G1 werken met 5–10,000 afbeeldingen. Voor het voorbeeld dat in dit bericht wordt besproken, gebruiken we 60 afbeeldingen: 30 van Ron de hond en 30 van Smila de kat. Over het algemeen zal het aanbieden van meer varianten van de stijl of klasse die u probeert te leren de nauwkeurigheid van uw verfijnde model verbeteren. Hoe meer afbeeldingen u echter gebruikt voor de fijnafstelling, hoe langer het duurt voordat de fijnafstelling is voltooid. Het aantal gebruikte afbeeldingen heeft ook invloed op de prijs van uw verfijnde opdracht. Verwijzen naar Amazon Bedrock-prijzen voor meer informatie.
Verfijning van Amazon Titan Image Generator
Nu we onze trainingsgegevens gereed hebben, kunnen we aan een nieuwe maatwerkklus beginnen. Dit proces kan zowel via de Amazon Bedrock-console als via API's worden uitgevoerd. Om de Amazon Bedrock-console te gebruiken, voert u de volgende stappen uit:
- Kies op de Amazon Bedrock-console Aangepaste modellen in het navigatievenster.
- Op de Model aanpassen menu, kies Maak een verfijningstaak.
- Voor Verfijnde modelnaam, voer een naam in voor uw nieuwe model.
- Voor Taak configuratie, voer een naam in voor de trainingstaak.
- Voor Invoergegevens, voer het S3-pad van de invoergegevens in.
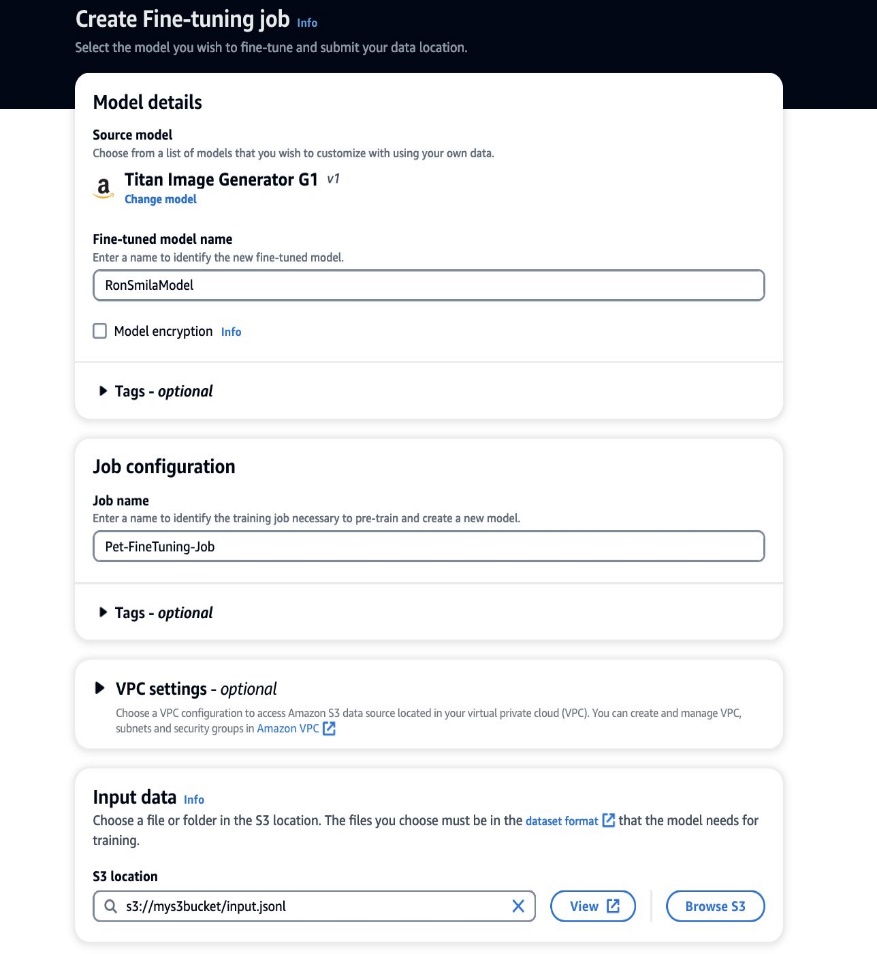
- In het Hyperparameters sectie, geef waarden op voor het volgende:
- Aantal stappen – Het aantal keren dat het model aan elke batch wordt blootgesteld.
- Seriegrootte – Het aantal verwerkte monsters voordat de modelparameters werden bijgewerkt.
- Leren tarief – De snelheid waarmee de modelparameters na elke batch worden bijgewerkt. De keuze van deze parameters hangt af van een bepaalde dataset. Als algemene richtlijn raden we u aan om te beginnen met het vaststellen van de batchgrootte op 8, de leersnelheid op 1e-5, en het aantal stappen in te stellen op basis van het aantal gebruikte afbeeldingen, zoals beschreven in de volgende tabel.
| Aantal geleverde afbeeldingen | 8 | 32 | 64 | 1,000 | 10,000 |
| Aanbevolen aantal stappen | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Als de resultaten van uw verfijning niet bevredigend zijn, kunt u overwegen het aantal stappen te verhogen als u geen enkel teken van de stijl in de gegenereerde afbeeldingen waarneemt, en het aantal stappen te verlagen als u de stijl wel in de gegenereerde afbeeldingen waarneemt, maar met artefacten of onscherpte. Als het verfijnde model er zelfs na 40,000 stappen niet in slaagt de unieke stijl in uw dataset te leren, kunt u overwegen de batchgrootte of de leersnelheid te vergroten.
- In het Gegevens uitvoeren sectie, voer het S3-uitvoerpad in waar de validatie-uitvoer, inclusief de periodiek geregistreerde validatieverlies- en nauwkeurigheidsstatistieken, worden opgeslagen.
- In het Toegang voor onderhoud sectie, genereer een nieuwe AWS Identiteits- en toegangsbeheer (IAM)-rol of kies een bestaande IAM-rol met de benodigde machtigingen voor toegang tot uw S3-buckets.
Met deze autorisatie kan Amazon Bedrock invoer- en validatiegegevenssets ophalen uit de door u aangewezen bucket en validatie-uitvoer naadloos opslaan in uw S3-bucket.
- Kies Model afstellen.
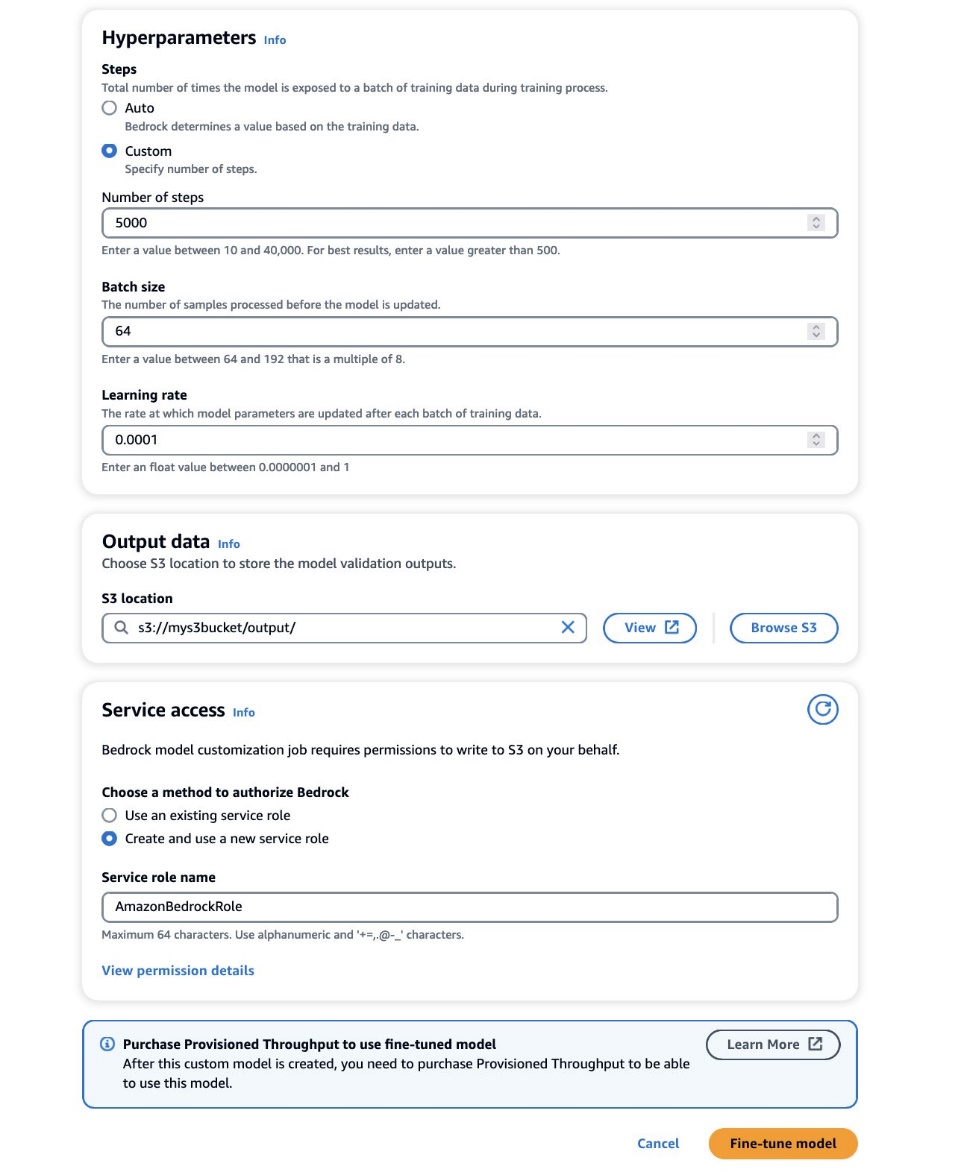
Als de juiste configuraties zijn ingesteld, traint Amazon Bedrock nu uw aangepaste model.
Implementeer de verfijnde Amazon Titan Image Generator met ingerichte doorvoer
Nadat u een aangepast model hebt gemaakt, kunt u met Provisioned Throughput een vooraf bepaalde, vaste verwerkingscapaciteit aan het aangepaste model toewijzen. Deze toewijzing biedt een consistent prestatieniveau en capaciteit voor het verwerken van werklasten, wat resulteert in betere prestaties bij productiewerklasten. Het tweede voordeel van Provisioned Throughput is kostenbeheersing, omdat standaard op tokens gebaseerde prijzen met on-demand inferentiemodus op grote schaal moeilijk te voorspellen kunnen zijn.
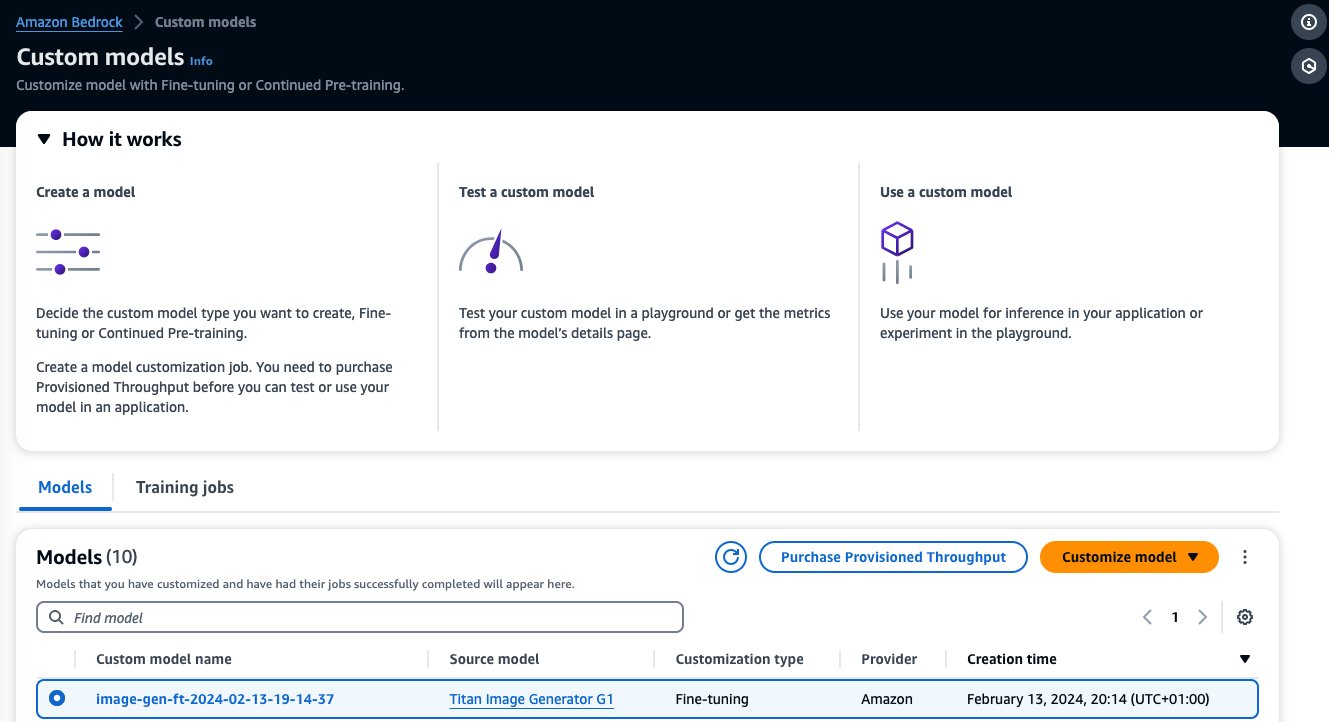
Wanneer de fijnafstemming van uw model is voltooid, verschijnt dit model op de Aangepaste modellen' pagina op de Amazon Bedrock-console.
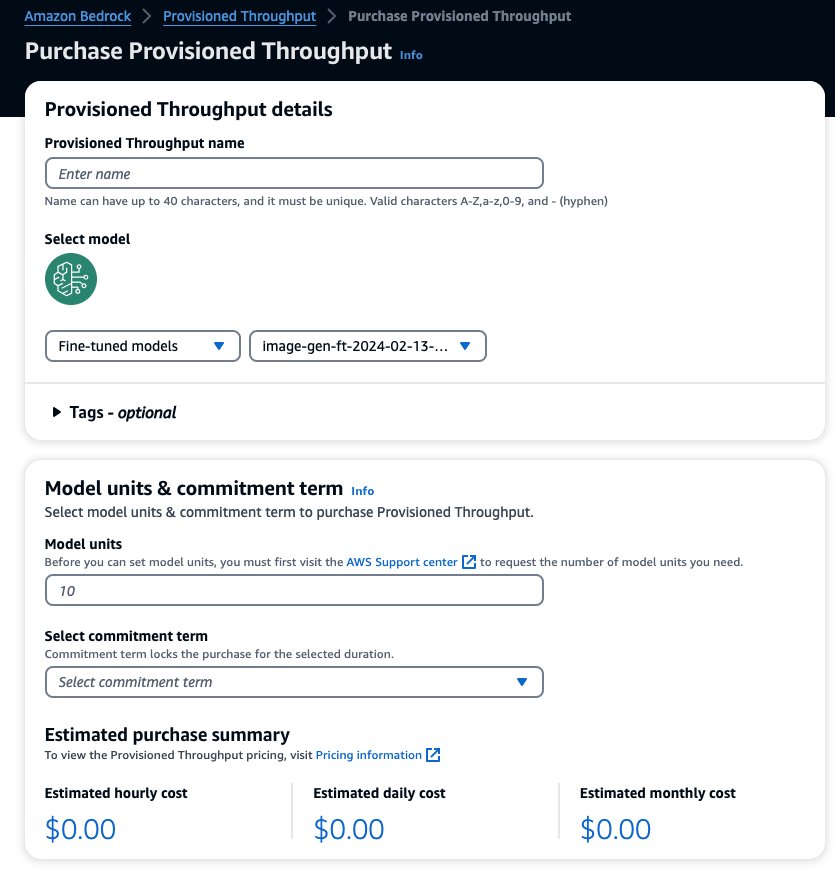
Om ingerichte doorvoer aan te schaffen, selecteert u het aangepaste model dat u zojuist hebt verfijnd en kiest u dit Aankoop ingerichte doorvoer.
Hiermee wordt het geselecteerde model vooraf ingevuld waarvoor u ingerichte doorvoer wilt aanschaffen. Om uw verfijnde model te testen voordat u het implementeert, stelt u modeleenheden in op de waarde 1 en stelt u de verplichtingstermijn in op Geen toewijding. Hierdoor kunt u snel beginnen met het testen van uw modellen met uw aangepaste aanwijzingen en controleren of de training voldoende is. Bovendien kunt u, wanneer er nieuwe, verfijnde modellen en nieuwe versies beschikbaar zijn, de ingerichte doorvoer bijwerken, zolang u deze bijwerkt met andere versies van hetzelfde model.
Resultaten verfijnen
Voor onze taak om het model op Ron de hond en Smila de kat aan te passen, hebben experimenten aangetoond dat de beste hyperparameters 5,000 stappen waren met een batchgrootte van 8 en een leersnelheid van 1e-5.
Hieronder volgen enkele voorbeelden van de afbeeldingen die door het aangepaste model zijn gegenereerd.
 |
 |
 |
| Ron de hond met een superheldencape | Ron de hond op de maan | Ron de hond in een zwembad met zonnebril |
 |
 |
 |
| Smila de kat in de sneeuw | Smila de kat in zwart-wit starend naar de camera | Smila de kat met een kerstmuts |
Conclusie
In dit bericht hebben we besproken wanneer u fijnafstemming moet gebruiken in plaats van uw aanwijzingen te ontwerpen voor het genereren van afbeeldingen van betere kwaliteit. We hebben laten zien hoe je het Amazon Titan Image Generator-model kunt verfijnen en het aangepaste model op Amazon Bedrock kunt implementeren. We hebben ook algemene richtlijnen gegeven over hoe u uw gegevens kunt voorbereiden op fijnafstemming en hoe u optimale hyperparameters kunt instellen voor nauwkeurigere modelaanpassing.
Als volgende stap kunt u het volgende aanpassen voorbeeld aan uw gebruiksscenario om hyper-gepersonaliseerde afbeeldingen te genereren met behulp van Amazon Titan Image Generator.
Over de auteurs
 Maira Ladeira Tanke is een senior generatieve AI-datawetenschapper bij AWS. Met een achtergrond in machine learning heeft ze meer dan 10 jaar ervaring met het ontwerpen en bouwen van AI-applicaties met klanten uit verschillende sectoren. Als technisch leider helpt ze klanten hun bedrijfswaarde te versnellen door middel van generatieve AI-oplossingen op Amazon Bedrock. In haar vrije tijd houdt Maira van reizen, spelen met haar kat Smila en tijd doorbrengen met haar familie op een warme plek.
Maira Ladeira Tanke is een senior generatieve AI-datawetenschapper bij AWS. Met een achtergrond in machine learning heeft ze meer dan 10 jaar ervaring met het ontwerpen en bouwen van AI-applicaties met klanten uit verschillende sectoren. Als technisch leider helpt ze klanten hun bedrijfswaarde te versnellen door middel van generatieve AI-oplossingen op Amazon Bedrock. In haar vrije tijd houdt Maira van reizen, spelen met haar kat Smila en tijd doorbrengen met haar familie op een warme plek.
 Dani Mitchel is een AI/ML Specialist Solutions Architect bij Amazon Web Services. Hij richt zich op gebruiksscenario's voor computervisie en helpt klanten in EMEA hun ML-traject te versnellen.
Dani Mitchel is een AI/ML Specialist Solutions Architect bij Amazon Web Services. Hij richt zich op gebruiksscenario's voor computervisie en helpt klanten in EMEA hun ML-traject te versnellen.
 Bharathi Srinivasan is een Data Scientist bij AWS Professional Services, waar ze graag coole dingen bouwt op Amazon Bedrock. Ze heeft een passie voor het genereren van bedrijfswaarde uit machine learning-toepassingen, met een focus op verantwoorde AI. Naast het bouwen van nieuwe AI-ervaringen voor klanten, houdt Bharathi ervan om sciencefiction te schrijven en zichzelf uit te dagen met duursporten.
Bharathi Srinivasan is een Data Scientist bij AWS Professional Services, waar ze graag coole dingen bouwt op Amazon Bedrock. Ze heeft een passie voor het genereren van bedrijfswaarde uit machine learning-toepassingen, met een focus op verantwoorde AI. Naast het bouwen van nieuwe AI-ervaringen voor klanten, houdt Bharathi ervan om sciencefiction te schrijven en zichzelf uit te dagen met duursporten.
 Achin Jain is een toegepast wetenschapper bij het Amazon Artificial General Intelligence (AGI)-team. Hij heeft expertise op het gebied van tekst-naar-afbeelding-modellen en richt zich op het bouwen van de Amazon Titan Image Generator.
Achin Jain is een toegepast wetenschapper bij het Amazon Artificial General Intelligence (AGI)-team. Hij heeft expertise op het gebied van tekst-naar-afbeelding-modellen en richt zich op het bouwen van de Amazon Titan Image Generator.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

