Inhoudsopgave
In dit artikel gaan we uitzoeken hoe detecteer gezichten in realtime met behulp van OpenCV. Nadat we het gezicht van de webcamstream hebben gedetecteerd, gaan we de frames met het gezicht opslaan. Later zullen we deze frames (afbeeldingen) doorgeven aan onze maskerdetector-classificatie om erachter te komen of de persoon een masker draagt of niet.
We gaan ook kijken hoe je een aangepaste maskerdetector kunt maken met behulp van Tensorflow en Keras maar u kunt dat overslaan, aangezien ik het getrainde modelbestand hieronder zal bijvoegen dat u kunt downloaden en gebruiken. Hier is de lijst met subonderwerpen die we gaan behandelen:
- Wat is gezichtsdetectie?
- Methoden voor gezichtsdetectie
- Algoritme voor gezichtsherkenning
- Gezichtsherkenning
- Gezichtsdetectie met behulp van Python
- Gezichtsdetectie met behulp van OpenCV
- Maak een model om gezichten te herkennen die een masker dragen (optioneel)
- Realtime maskerdetectie uitvoeren
Wat is gezichtsherkenning?
Het doel van gezichtsdetectie is om te bepalen of er gezichten in de afbeelding of video zijn. Als er meerdere vlakken aanwezig zijn, wordt elk vlak omsloten door een selectiekader en weten we dus de locatie van de vlakken
Het primaire doel van algoritmen voor gezichtsdetectie is het nauwkeurig en efficiënt bepalen van de aanwezigheid en positie van gezichten in een afbeelding of video. De algoritmen analyseren de visuele inhoud van de gegevens en zoeken naar patronen en kenmerken die overeenkomen met gezichtskenmerken. Door gebruik te maken van verschillende technieken, zoals machine learning, beeldverwerking en patroonherkenning, proberen algoritmen voor gezichtsdetectie gezichten te onderscheiden van andere objecten of achtergrondelementen binnen de visuele gegevens.
Menselijke gezichten zijn moeilijk te modelleren omdat er veel variabelen zijn die kunnen veranderen, bijvoorbeeld gezichtsuitdrukking, oriëntatie, lichtomstandigheden en gedeeltelijke occlusies zoals zonnebrillen, sjaals, maskers, enz. Het resultaat van de detectie geeft de locatieparameters van het gezicht en het kan verschillende vormen vereist zijn, bijvoorbeeld een rechthoek die het centrale deel van het gezicht bedekt, oogcentra of oriëntatiepunten zoals ogen, neus- en mondhoeken, wenkbrauwen, neusgaten, enz.
Methoden voor gezichtsdetectie
Er zijn twee hoofdbenaderingen voor gezichtsdetectie:
- Feature Base-benadering
- Image Base-benadering
Feature Base-benadering
Objecten worden meestal herkend aan hun unieke eigenschappen. Er zijn veel kenmerken in een menselijk gezicht, die kunnen worden herkend tussen een gezicht en vele andere objecten. Het lokaliseert gezichten door structurele kenmerken zoals ogen, neus, mond enz. te extraheren en gebruikt deze vervolgens om een gezicht te detecteren. Doorgaans is een soort statistische classificator gekwalificeerd en vervolgens nuttig om onderscheid te maken tussen gezichts- en niet-gezichtsgebieden. Bovendien hebben menselijke gezichten bepaalde texturen die kunnen worden gebruikt om onderscheid te maken tussen een gezicht en andere objecten. Bovendien kan de rand van functies helpen om de objecten van het gezicht te detecteren. In de komende sectie zullen we een op functies gebaseerde aanpak implementeren door gebruik te maken van de OpenCV-zelfstudie.
Image Base-benadering
Over het algemeen vertrouwen beeldgebaseerde methoden op technieken uit statistische analyse en machine learning om de relevante kenmerken van gezichts- en niet-gezichtsbeelden te vinden. De geleerde kenmerken zijn in de vorm van distributiemodellen of discriminerende functies die vervolgens worden gebruikt voor gezichtsdetectie. Bij deze methode gebruiken we verschillende algoritmen zoals Neural-networks, HMM, SVM's, AdaBoost leren. In het komende gedeelte zullen we zien hoe we gezichten kunnen detecteren met MTCNN of Multi-Task Cascaded Convolutional Neural Network, een op afbeeldingen gebaseerde benadering van gezichtsdetectie
Algoritme voor gezichtsherkenning
Een van de populaire algoritmen die een op functies gebaseerde benadering gebruiken, is de Viola-Jones-algoritme en hier ga ik het kort bespreken. Als je er meer over wilt weten, raad ik je aan dit artikel door te nemen, Gezichtsdetectie met behulp van het Viola Jones-algoritme.
Viola Jones algoritme is vernoemd naar twee computer vision-onderzoekers die de methode in 2001 hebben voorgesteld, Paul Viola en Michael Jones in hun paper, "Rapid Object Detection using a Boosted Cascade of Simple Features". Ondanks dat het een verouderd framework is, is Viola-Jones behoorlijk krachtig, en de toepassing ervan is uitzonderlijk opmerkelijk gebleken bij real-time gezichtsdetectie. Dit algoritme is tergend langzaam om te trainen, maar kan met een indrukwekkende snelheid in realtime gezichten detecteren.
Gegeven een afbeelding (dit algoritme werkt op afbeeldingen in grijstinten), kijkt het algoritme naar veel kleinere subregio's en probeert het een gezicht te vinden door te zoeken naar specifieke kenmerken in elke subregio. Het moet veel verschillende posities en schalen controleren, omdat een afbeelding veel gezichten van verschillende afmetingen kan bevatten. Viola en Jones gebruikten Haar-achtige functies om gezichten in dit algoritme te detecteren.
Gezichtsherkenning
Gezichtsdetectie en gezichtsherkenning worden vaak door elkaar gebruikt, maar ze zijn behoorlijk verschillend. Gezichtsdetectie is in feite slechts een onderdeel van gezichtsherkenning.
Gezichtsherkenning is een methode om de identiteit van een persoon te identificeren of te verifiëren met behulp van zijn gezicht. Er zijn verschillende algoritmen die gezichtsherkenning kunnen uitvoeren, maar hun nauwkeurigheid kan variëren. Hier ga ik beschrijven hoe we gezichtsherkenning doen met behulp van diep leren.
In feite is hier een artikel, Face Recognition Python, dat laat zien hoe Face Recognition moet worden geïmplementeerd.
Gezichtsdetectie met behulp van Python
Zoals eerder vermeld, gaan we hier zien hoe we gezichten kunnen detecteren door een op afbeeldingen gebaseerde benadering te gebruiken. MTCNN of Multi-Task Cascaded Convolutional Neural Network is ongetwijfeld een van de meest populaire en meest nauwkeurige tools voor gezichtsdetectie die volgens dit principe werken. Het is dus gebaseerd op a diepgaand leren architectuur, het bestaat specifiek uit 3 neurale netwerken (P-Net, R-Net en O-Net) die in een cascade zijn verbonden.
Laten we dus eens kijken hoe we dit algoritme in Python kunnen gebruiken om gezichten in realtime te detecteren. Eerst moet u de MTCNN-bibliotheek installeren die een getraind model bevat dat gezichten kan detecteren.
pip install mtcnnLaten we nu kijken hoe we MTCNN kunnen gebruiken:
from mtcnn import MTCNN
import cv2
detector = MTCNN()
#Load a videopip TensorFlow
video_capture = cv2.VideoCapture(0) while (True): ret, frame = video_capture.read() frame = cv2.resize(frame, (600, 400)) boxes = detector.detect_faces(frame) if boxes: box = boxes[0]['box'] conf = boxes[0]['confidence'] x, y, w, h = box[0], box[1], box[2], box[3] if conf > 0.5: cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 255), 1) cv2.imshow("Frame", frame) if cv2.waitKey(25) & 0xFF == ord('q'): break video_capture.release()
cv2.destroyAllWindows()
Gezichtsdetectie met behulp van OpenCV
In deze sectie gaan we real-time optreden gezichtsdetectie met behulp van OpenCV van een livestream via onze webcam.
Zoals je weet, zijn video's in feite opgebouwd uit frames, dit zijn stilstaande beelden. We voeren gezichtsdetectie uit voor elk frame in een video. Dus als het gaat om het detecteren van een gezicht in een stilstaand beeld en het detecteren van een gezicht in een real-time videostream, is er niet veel verschil tussen beide.
We zullen het Haar Cascade-algoritme gebruiken, ook wel bekend als het Voila-Jones-algoritme om gezichten te detecteren. Het is in feite een machine learning-objectdetectie-algoritme dat wordt gebruikt om objecten in een afbeelding of video te identificeren. In OpenCV hebben we verschillende getrainde Haar Cascade-modellen die worden opgeslagen als XML-bestanden. In plaats van het model helemaal opnieuw te maken en te trainen, gebruiken we dit bestand. We gaan het bestand "haarcascade_frontalface_alt2.xml" gebruiken in dit project. Laten we dit nu gaan coderen
De eerste stap is het vinden van het pad naar het bestand "haarcascade_frontalface_alt2.xml". We doen dit door de os-module van de Python-taal te gebruiken.
import os
cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"De volgende stap is het laden van onze classifier. Het pad naar het bovenstaande XML-bestand gaat als argument naar de methode CascadeClassifier() van OpenCV.
faceCascade = cv2.CascadeClassifier(cascPath)Na het laden van de classifier, laten we de webcam openen met deze eenvoudige OpenCV one-liner code
video_capture = cv2.VideoCapture(0)Vervolgens moeten we de frames uit de webcamstream halen, dit doen we met behulp van de read() functie. We gebruiken het in een oneindige lus om alle frames te krijgen tot het moment dat we de stream willen sluiten.
while True: # Capture frame-by-frame ret, frame = video_capture.read()De functie read() retourneert:
- Het werkelijk gelezen videoframe (één frame per lus)
- Een retourcode
De retourcode vertelt ons of we geen frames meer hebben, wat gebeurt als we uit een bestand lezen. Dit maakt niet uit bij het lezen van de webcam, aangezien we voor altijd kunnen opnemen, dus we zullen het negeren.
Om deze specifieke classificatie te laten werken, moeten we het frame omzetten in grijstinten.
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)Het faceCascade-object heeft een methode detectMultiScale(), die een frame(afbeelding) als argument ontvangt en de classificatie cascade over de afbeelding uitvoert. De term MultiScale geeft aan dat het algoritme subregio's van het beeld op meerdere schalen bekijkt om gezichten van verschillende groottes te detecteren.
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE)Laten we deze argumenten van deze functie eens doornemen:
- scaleFactor - Parameter die specificeert hoeveel de afbeeldingsgrootte wordt verkleind bij elke afbeeldingsschaal. Door de invoerafbeelding opnieuw te schalen, kunt u de grootte van een groter gezicht wijzigen in een kleiner gezicht, zodat het door het algoritme kan worden gedetecteerd. 1.05 is hiervoor een goed mogelijke waarde, wat betekent dat u een kleine stap gebruikt voor het wijzigen van de grootte, dwz de grootte met 5% verkleint, u vergroot de kans dat een overeenkomende grootte met het model voor detectie wordt gevonden.
- minNeighbors – Parameter die aangeeft hoeveel buren elke kandidaat-rechthoek moet hebben om deze te behouden. Deze parameter is van invloed op de kwaliteit van de gedetecteerde gezichten. Een hogere waarde resulteert in minder detecties maar met een hogere kwaliteit. 3~6 is er een goede waarde voor.
- vlaggen –Werkwijze
- minSize - Minimaal mogelijke objectgrootte. Objecten die kleiner zijn, worden genegeerd.
De variabele gezichten bevatten nu alle detecties voor de doelafbeelding. Detecties worden opgeslagen als pixelcoördinaten. Elke detectie wordt gedefinieerd door de coördinaten van de linkerbovenhoek en de breedte en hoogte van de rechthoek die het gedetecteerde gezicht omsluit.
Om het gedetecteerde gezicht te tonen, tekenen we er een rechthoek overheen. De rechthoek() van OpenCV tekent rechthoeken over afbeeldingen, en het moet de pixelcoördinaten van de linkerboven- en rechterbenedenhoek kennen. De coördinaten geven de rij en kolom met pixels in de afbeelding aan. We kunnen deze coördinaten gemakkelijk uit het variabele vlak halen.
for (x,y,w,h) in faces: cv2.rectangle(frame, (x, y), (x + w, y + h),(0,255,0), 2)rechthoek() accepteert de volgende argumenten:
- De originele afbeelding
- De coördinaten van het punt linksboven van de detectie
- De coördinaten van het punt rechtsonder van de detectie
- De kleur van de rechthoek (een tuple die de hoeveelheid rood, groen en blauw definieert (0-255)). In ons geval stellen we groen in, waarbij we de groene component op 255 houden en de rust op nul.
- De dikte van de rechthoekige lijnen
Vervolgens geven we alleen het resulterende frame weer en stellen we ook een manier in om deze oneindige lus te verlaten en de videofeed te sluiten. Door op de 'q'-toets te drukken, kunnen we het script hier afsluiten
cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): breakDe volgende twee regels zijn alleen om op te ruimen en de foto vrij te geven.
video_capture.release()
cv2.destroyAllWindows()Hier zijn de volledige code en uitvoer.
import cv2
import os
cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE) for (x,y,w,h) in faces: cv2.rectangle(frame, (x, y), (x + w, y + h),(0,255,0), 2) # Display the resulting frame cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()
Output:
Maak een model om gezichten te herkennen die een masker dragen
In deze sectie gaan we een classificatie maken die onderscheid kan maken tussen gezichten met maskers en zonder maskers. Voor het geval je dit deel wilt overslaan, hier is een link om het vooraf getrainde model te downloaden. Sla het op en ga verder naar het volgende gedeelte om te weten hoe u het kunt gebruiken om maskers te detecteren met behulp van OpenCV. Bekijk onze collectie van OpenCV-cursussen om u te helpen uw vaardigheden te ontwikkelen en beter te begrijpen.
Dus voor het maken van deze classificatie hebben we gegevens nodig in de vorm van afbeeldingen. Gelukkig hebben we een dataset met afbeeldingen van gezichten met en zonder masker. Aangezien deze afbeeldingen erg klein zijn, kunnen we een neuraal netwerk niet vanaf nul trainen. In plaats daarvan finetunen we een vooraf getraind netwerk genaamd MobileNetV2 dat is getraind op de Imagenet-dataset.
Laten we eerst alle benodigde bibliotheken importeren die we nodig zullen hebben.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import osDe volgende stap is om alle afbeeldingen te lezen en ze toe te wijzen aan een lijst. Hier krijgen we alle paden die aan deze afbeeldingen zijn gekoppeld en labelen ze dienovereenkomstig. Onthoud dat onze dataset zich in twee mappen bevindt, namelijk with_masks en without_masks. We kunnen dus gemakkelijk de labels krijgen door de mapnaam uit het pad te extraheren. We verwerken de afbeelding ook voor en verkleinen deze naar 224 x 224 dimensies.
imagePaths = list(paths.list_images('/content/drive/My Drive/dataset'))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths: # extract the class label from the filename label = imagePath.split(os.path.sep)[-2] # load the input image (224x224) and preprocess it image = load_img(imagePath, target_size=(224, 224)) image = img_to_array(image) image = preprocess_input(image) # update the data and labels lists, respectively data.append(image) labels.append(label)
# convert the data and labels to NumPy arrays
data = np.array(data, dtype="float32")
labels = np.array(labels)De volgende stap is het laden van het vooraf getrainde model en het aanpassen aan ons probleem. Dus we verwijderen gewoon de bovenste lagen van dit vooraf getrainde model en voegen een paar eigen lagen toe. Zoals je kunt zien heeft de laatste laag twee knooppunten omdat we maar twee uitgangen hebben. Dit wordt overdrachtsleren genoemd.
baseModel = MobileNetV2(weights="imagenet", include_top=False, input_shape=(224, 224, 3))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(7, 7))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(128, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(2, activation="softmax")(headModel) # place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers: layer.trainable = FalseNu moeten we de labels omzetten in one-hot codering. Daarna splitsten we de gegevens op in trainings- en testsets om ze te evalueren. De volgende stap is ook data-augmentatie, waarmee de diversiteit aan beschikbare data voor trainingsmodellen aanzienlijk wordt vergroot, zonder dat er daadwerkelijk nieuwe data worden verzameld. Data-augmentatietechnieken zoals bijsnijden, roteren, afschuiven en horizontaal spiegelen worden vaak gebruikt om grote neurale netwerken te trainen.
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.20, stratify=labels, random_state=42)
# construct the training image generator for data augmentation
aug = ImageDataGenerator( rotation_range=20, zoom_range=0.15, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15, horizontal_flip=True, fill_mode="nearest")De volgende stap is het compileren van het model en het trainen op de augmented data.
INIT_LR = 1e-4
EPOCHS = 20
BS = 32
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])
# train the head of the network
print("[INFO] training head...")
H = model.fit( aug.flow(trainX, trainY, batch_size=BS), steps_per_epoch=len(trainX) // BS, validation_data=(testX, testY), validation_steps=len(testX) // BS, epochs=EPOCHS)Nu ons model is getraind, laten we een grafiek plotten om de leercurve te zien. Ook bewaren we het model voor later gebruik. Hier is een link naar dit getrainde model.
N = EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")Output:
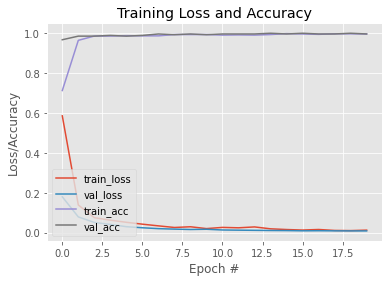
#To save the trained model
model.save('mask_recog_ver2.h5')Realtime maskerdetectie uitvoeren
Voordat u naar het volgende deel gaat, moet u ervoor zorgen dat u het bovenstaande model hiervan downloadt link en plaats het in dezelfde map als het python-script waarin u de onderstaande code gaat schrijven.
Nu ons model is getraind, kunnen we de code in het eerste gedeelte aanpassen zodat het gezichten kan detecteren en ons ook kan vertellen of de persoon een masker draagt of niet.
Om ons maskerdetectormodel te laten werken, heeft het afbeeldingen van gezichten nodig. Hiervoor zullen we de frames met gezichten detecteren met behulp van de methoden zoals getoond in de eerste sectie en ze vervolgens doorgeven aan ons model nadat ze zijn voorbewerkt. Dus laten we eerst alle bibliotheken importeren die we nodig hebben.
import cv2
import os
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
import numpy as npDe eerste paar regels zijn precies hetzelfde als het eerste deel. Het enige dat anders is, is dat we ons vooraf getrainde maskerdetectormodel hebben toegewezen aan het variabele model.
ascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
model = load_model("mask_recog1.h5") video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE)Vervolgens definiëren we enkele lijsten. De faces_list bevat alle gezichten die zijn gedetecteerd door het faceCascade-model en de preds-lijst wordt gebruikt om de voorspellingen van het maskerdetectormodel op te slaan.
faces_list=[]
preds=[]Omdat de variabele gezichten de coördinaten van de linkerbovenhoek en de hoogte en breedte van de rechthoek die de gezichten omvat, kunnen we die ook gebruiken om een frame van het gezicht te krijgen en dat frame vervolgens voorbewerken zodat het voor voorspelling in het model kan worden ingevoerd . De voorverwerkingsstappen zijn dezelfde als die worden gevolgd bij het trainen van het model in het tweede gedeelte. Het model is bijvoorbeeld getraind op RGB-afbeeldingen, dus we zetten de afbeelding hier om in RGB
for (x, y, w, h) in faces: face_frame = frame[y:y+h,x:x+w] face_frame = cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB) face_frame = cv2.resize(face_frame, (224, 224)) face_frame = img_to_array(face_frame) face_frame = np.expand_dims(face_frame, axis=0) face_frame = preprocess_input(face_frame) faces_list.append(face_frame) if len(faces_list)>0: preds = model.predict(faces_list) for pred in preds: #mask contain probabily of wearing a mask and vice versa (mask, withoutMask) = pred Nadat we de voorspellingen hebben ontvangen, tekenen we een rechthoek over het gezicht en plaatsen we een label volgens de voorspellingen.
label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (x, y- 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (x, y), (x + w, y + h),color, 2)De rest van de stappen zijn hetzelfde als het eerste deel.
cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()Hier is de volledige code en uitvoer:
import cv2
import os
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
import numpy as np cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
model = load_model("mask_recog1.h5") video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE) faces_list=[] preds=[] for (x, y, w, h) in faces: face_frame = frame[y:y+h,x:x+w] face_frame = cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB) face_frame = cv2.resize(face_frame, (224, 224)) face_frame = img_to_array(face_frame) face_frame = np.expand_dims(face_frame, axis=0) face_frame = preprocess_input(face_frame) faces_list.append(face_frame) if len(faces_list)>0: preds = model.predict(faces_list) for pred in preds: (mask, withoutMask) = pred label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (x, y- 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (x, y), (x + w, y + h),color, 2) # Display the resulting frame cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()
Output:
Dit brengt ons aan het einde van dit artikel, waar we hebben geleerd hoe we gezichten in realtime kunnen detecteren en ook een model hebben ontworpen dat gezichten met maskers kan detecteren. Met dit model konden we de gezichtsdetector ombouwen tot maskerdetector.
bijwerken: Ik heb een ander model getraind dat afbeeldingen kan classificeren in het dragen van een masker, het niet dragen van een masker en het niet correct dragen van een masker. Hier is een link van de Kaggle notitieboek van dit model. U kunt het aanpassen en ook het model van daaruit downloaden en gebruiken in plaats van het model dat we in dit artikel hebben getraind. Hoewel dit model niet zo efficiënt is als het model dat we hier hebben getraind, heeft het een extra functie om niet correct gedragen maskers te detecteren.
Als u dit model gebruikt, moet u enkele kleine wijzigingen in de code aanbrengen. Vervang de vorige regels door deze regels.
#Here are some minor changes in opencv code
for (box, pred) in zip(locs, preds): # unpack the bounding box and predictions (startX, startY, endX, endY) = box (mask, withoutMask,notproper) = pred # determine the class label and color we'll use to draw # the bounding box and text if (mask > withoutMask and mask>notproper): label = "Without Mask" elif ( withoutMask > notproper and withoutMask > mask): label = "Mask" else: label = "Wear Mask Properly" if label == "Mask": color = (0, 255, 0) elif label=="Without Mask": color = (0, 0, 255) else: color = (255, 140, 0) # include the probability in the label label = "{}: {:.2f}%".format(label, max(mask, withoutMask, notproper) * 100) # display the label and bounding box rectangle on the output # frame cv2.putText(frame, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2)Je kunt ook bijscholen met Great Learning's PGP Kunstmatige Intelligentie en Machine Learning Cursus. De cursus biedt mentorschap van marktleiders, en je krijgt ook de kans om te werken aan real-time brancherelevante projecten.
Verder lezen
- Realtime objectdetectie met behulp van TensorFlow
- YOLO-objectdetectie met behulp van OpenCV
- Objectdetectie in Pytorch | Wat is objectdetectie?
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.mygreatlearning.com/blog/real-time-face-detection/

