Afbeelding door redacteur
Key Takeaways
- De t-toets is een statistische toets die kan worden gebruikt om te bepalen of er een significant verschil is tussen de gemiddelden van twee onafhankelijke gegevensmonsters.
- We illustreren hoe een t-toets kan worden toegepast met behulp van de iris-dataset en de Scipy-bibliotheek van Python.
De t-toets is een statistische toets die kan worden gebruikt om te bepalen of er een significant verschil is tussen de gemiddelden van twee onafhankelijke gegevensmonsters. In deze zelfstudie illustreren we de eenvoudigste versie van de t-toets, waarbij we aannemen dat de twee steekproeven gelijke varianties hebben. Andere geavanceerde versies van de t-toets zijn de Welch's t-toets, die een aanpassing is van de t-toets, en betrouwbaarder is wanneer de twee steekproeven ongelijke varianties en mogelijk ongelijke steekproeven hebben.
De t-statistiek of t-waarde wordt als volgt berekend:
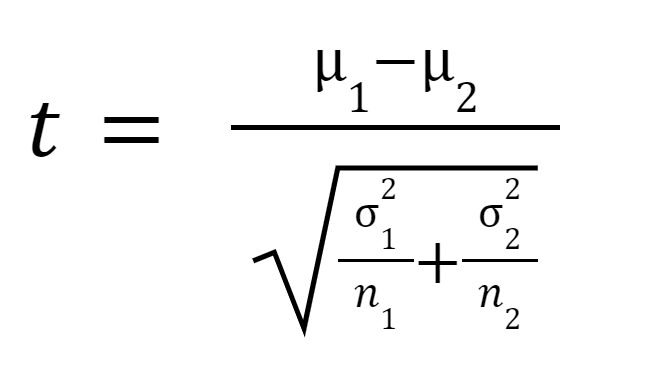
WAAR
is het gemiddelde van monster 1,
is het gemiddelde van monster 2,
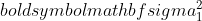 is de variantie van steekproef 1,
is de variantie van steekproef 1, 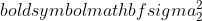 is de variantie van steekproef 2,
is de variantie van steekproef 2, 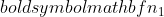 is de steekproefomvang van steekproef 1, en
is de steekproefomvang van steekproef 1, en 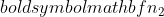 is de steekproefomvang van steekproef 2.
is de steekproefomvang van steekproef 2.
Om het gebruik van de t-toets te illustreren, laten we een eenvoudig voorbeeld zien met behulp van de iris-dataset. Stel dat we twee onafhankelijke monsters observeren, bijvoorbeeld de lengte van de bloemkelk, en we overwegen of de twee monsters zijn getrokken uit dezelfde populatie (bijvoorbeeld dezelfde bloemsoort of twee soorten met vergelijkbare kelkbladkenmerken) of twee verschillende populaties.
De t-toets kwantificeert het verschil tussen de rekenkundige gemiddelden van de twee steekproeven. De p-waarde kwantificeert de waarschijnlijkheid van het verkrijgen van de waargenomen resultaten, ervan uitgaande dat de nulhypothese (dat de steekproeven zijn getrokken uit populaties met dezelfde populatiegemiddelden) waar is. Een p-waarde groter dan een gekozen drempelwaarde (bijv. 5% of 0.05) geeft aan dat het niet zo onwaarschijnlijk is dat onze waarneming door toeval is ontstaan. Daarom accepteren we de nulhypothese van gelijke populatiegemiddelden. Als de p-waarde kleiner is dan onze drempel, dan hebben we bewijs tegen de nulhypothese van gelijke populatiegemiddelden.
T-testinvoer
De invoer of parameters die nodig zijn voor het uitvoeren van een t-toets zijn:
- Twee arrays a en b met de gegevens voor monster 1 en monster 2
T-Test-uitgangen
De t-toets geeft het volgende terug:
- De berekende t-statistieken
- De p-waarde
Importeer benodigde bibliotheken
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Iris-gegevensset laden
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Bereken de steekproefgemiddelden en steekproefvarianties
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Implementeer t-toets
stats.ttest_ind(a_1, b_1, equal_var = False)
uitgang
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
uitgang
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
uitgang
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Waarnemingen
We zien dat het gebruik van "true" of "false" voor de parameter "equal-var" de resultaten van de t-toets niet zo veel verandert. We zien ook dat het verwisselen van de volgorde van de steekproefarrays a_1 en b_1 een negatieve t-toetswaarde oplevert, maar de grootte van de t-toetswaarde niet verandert, zoals verwacht. Aangezien de berekende p-waarde veel groter is dan de drempelwaarde van 0.05, kunnen we de nulhypothese verwerpen dat het verschil tussen de gemiddelden van steekproef 1 en steekproef 2 significant is. Dit toont aan dat de kelklengtes voor monster 1 en monster 2 uit dezelfde populatiegegevens zijn getrokken.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Bereken de steekproefgemiddelden en steekproefvarianties
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Implementeer t-toets
stats.ttest_ind(a_1, b_1, equal_var = False)
uitgang
stats.ttest_ind(a_1, b_1, equal_var = False)Waarnemingen
We zien dat het gebruik van steekproeven met ongelijke grootte de t-statistieken en p-waarde niet significant verandert.
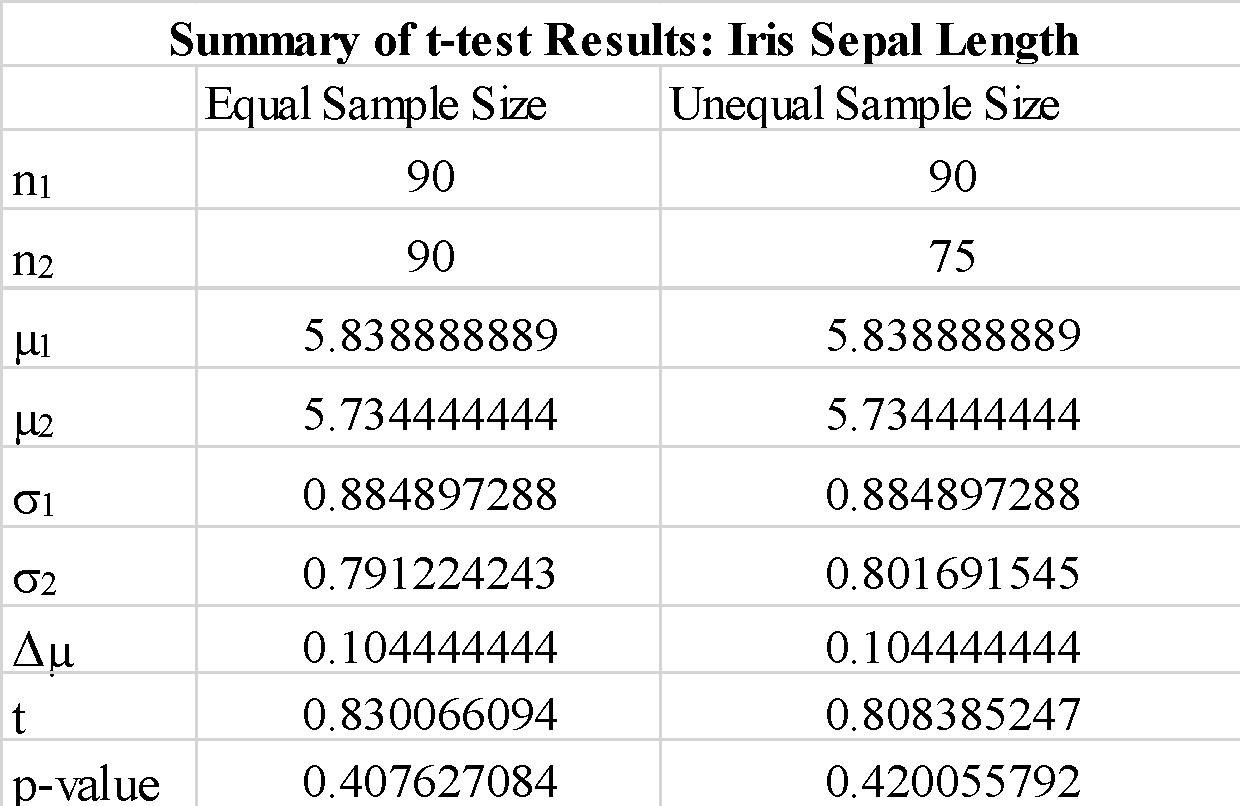
Samenvattend hebben we laten zien hoe een eenvoudige t-test kan worden geïmplementeerd met behulp van de scipy-bibliotheek in Python.
Benjamin O Tayo is een natuurkundige, opvoeder in gegevenswetenschappen en schrijver, evenals de eigenaar van DataScienceHub. Voorheen doceerde Benjamin Engineering en Natuurkunde aan U. of Central Oklahoma, Grand Canyon U., en Pittsburgh State U.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python

