Door Amazon beheerde workflows voor Apache Airflow (Amazon MWAA) is een beheerde orkestratieservice voor Apache-luchtstroom waarmee u op grote schaal datapipelines in de cloud kunt opzetten en exploiteren. Apache Airflow is een open source-tool die wordt gebruikt voor het programmatisch schrijven, plannen en monitoren van reeksen processen en taken, ook wel workflows. Met Amazon MWAA kun je Apache Airflow en Python gebruiken om workflows te creëren zonder dat je de onderliggende infrastructuur hoeft te beheren op schaalbaarheid, beschikbaarheid en beveiliging.
Door meerdere AWS-accounts te gebruiken, kunnen organisaties hun werklasten effectief schalen en hun complexiteit beheren naarmate ze groeien. Deze aanpak biedt een robuust mechanisme om de potentiële impact van verstoringen of storingen te beperken, en ervoor te zorgen dat kritieke werklasten operationeel blijven. Bovendien maakt het kostenoptimalisatie mogelijk door middelen af te stemmen op specifieke gebruiksscenario's, waardoor ervoor wordt gezorgd dat de uitgaven goed onder controle blijven. Door werklasten te isoleren met specifieke beveiligingsvereisten of nalevingsbehoeften kunnen organisaties het hoogste niveau van gegevensprivacy en -beveiliging handhaven. Bovendien kunt u dankzij de mogelijkheid om meerdere AWS-accounts op een gestructureerde manier te organiseren uw bedrijfsprocessen en middelen afstemmen op uw unieke operationele, regelgevende en budgettaire vereisten. Deze aanpak bevordert de efficiëntie, flexibiliteit en schaalbaarheid, waardoor grote ondernemingen aan hun veranderende behoeften kunnen voldoen en hun doelen kunnen bereiken.
In dit bericht wordt gedemonstreerd hoe u een end-to-end extractie-, transformatie- en laadpijplijn (ETL) kunt orkestreren met behulp van Amazon eenvoudige opslagservice (Amazone S3), AWS lijm en Amazon Redshift Serverloos met Amazon MWAA.
Overzicht oplossingen
Voor dit bericht beschouwen we een gebruiksscenario waarbij een data-engineeringteam een ETL-proces wil bouwen en de beste ervaring aan hun eindgebruikers wil bieden wanneer ze de nieuwste gegevens willen opvragen nadat nieuwe onbewerkte bestanden zijn toegevoegd aan Amazon S3 in de centrale account (Account A in het volgende architectuurdiagram). Het data-engineeringteam wil de onbewerkte gegevens scheiden in een eigen AWS-account (account B in het diagram) voor meer veiligheid en controle. Ze willen de gegevensverwerkings- en transformatiewerkzaamheden ook in hun eigen account (Account B) uitvoeren om de taken te verdelen en onbedoelde wijzigingen in de ruwe brongegevens in het centrale account (Account A) te voorkomen. Met deze aanpak kan het team de ruwe gegevens uit account A verwerken naar account B, die speciaal is bedoeld voor gegevensverwerkingstaken. Dit zorgt ervoor dat de onbewerkte en verwerkte gegevens, indien nodig, veilig gescheiden kunnen worden bewaard over meerdere accounts, voor verbeterd gegevensbeheer en beveiliging.
Onze oplossing maakt gebruik van een end-to-end ETL-pijplijn, georkestreerd door Amazon MWAA, die zoekt naar nieuwe incrementele bestanden op een Amazon S3-locatie in Account A, waar de onbewerkte gegevens aanwezig zijn. Dit wordt gedaan door AWS Glue ETL-taken aan te roepen en naar data-objecten in een Redshift Serverless cluster in Account B te schrijven. De pijplijn begint dan te lopen opgeslagen procedures en SQL-opdrachten op Redshift Serverless. Zodra de query's zijn uitgevoerd, wordt een LOSSEN bewerking wordt aangeroepen vanuit het Redshift-datawarehouse naar de S3-bucket in account A.
Omdat beveiliging belangrijk is, behandelt dit bericht ook hoe je een Airflow-verbinding configureert met behulp van AWS-geheimenmanager om te voorkomen dat databasereferenties worden opgeslagen binnen Airflow-verbindingen en variabelen.
Het volgende diagram illustreert het architecturale overzicht van de componenten die betrokken zijn bij de orkestratie van de workflow.
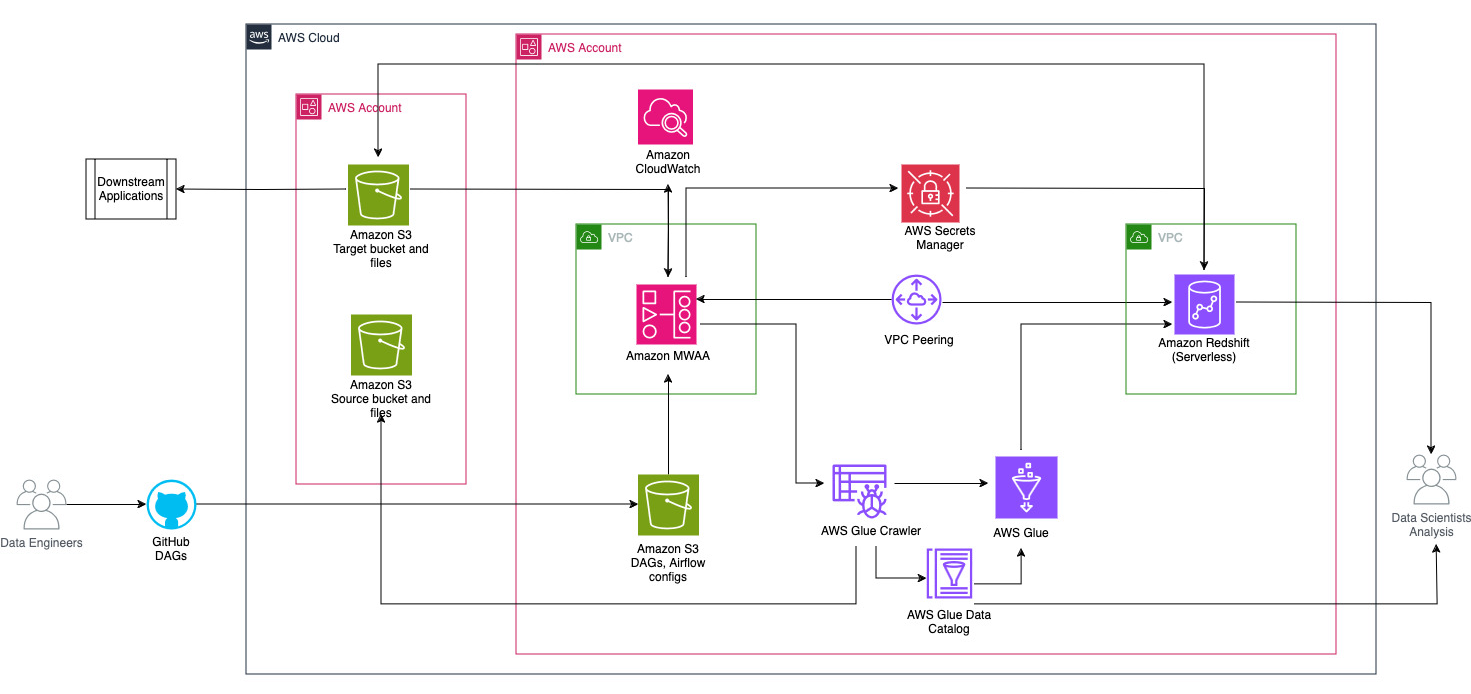
De workflow bestaat uit de volgende onderdelen:
- De bron- en doel-S3-buckets bevinden zich in een centraal account (Account A), terwijl Amazon MWAA, AWS Glue en Amazon Redshift zich in een ander account bevinden (Account B). Er is toegang tot meerdere accounts ingesteld tussen S3-buckets in Account A en bronnen in Account B om gegevens te kunnen laden en ontladen.
- In het tweede account wordt Amazon MWAA gehost in de ene VPC en Redshift Serverless in een andere VPC, die verbonden zijn via VPC-peering. Een Redshift Serverless-werkgroep is beveiligd binnen privé-subnetten verspreid over drie beschikbaarheidszones.
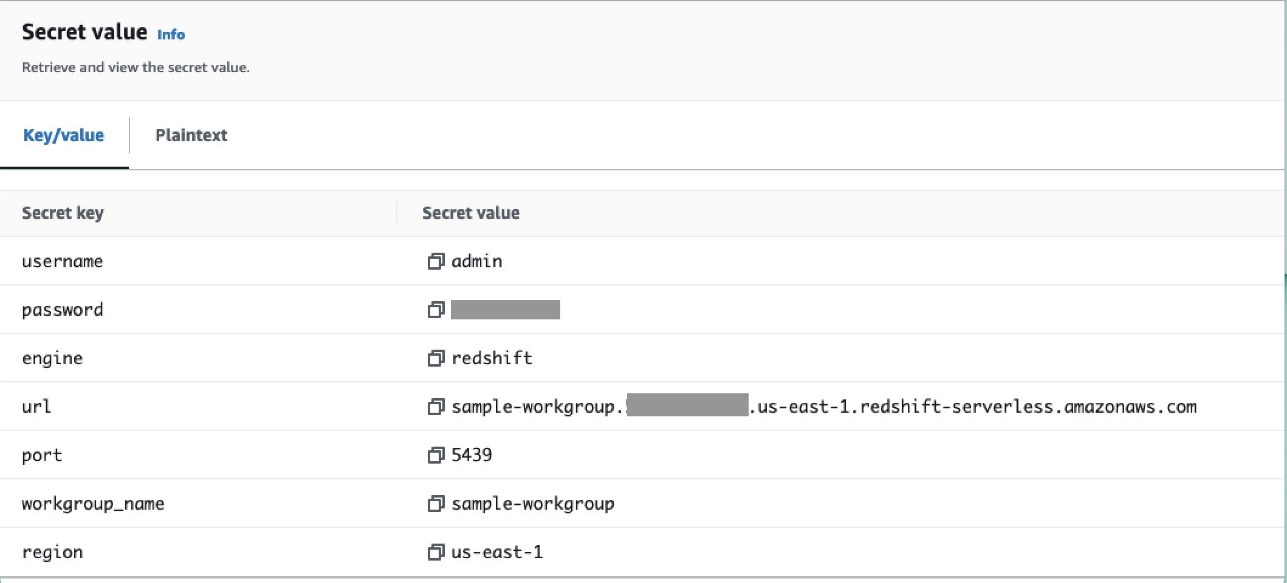
- Geheimen zoals gebruikersnaam, wachtwoord, DB-poort en AWS-regio voor Redshift Serverless worden opgeslagen in Secrets Manager.
- VPC-eindpunten worden gemaakt zodat Amazon S3 en Secrets Manager kunnen communiceren met andere bronnen.
- Meestal maken data-ingenieurs een Airflow Directed Acyclic Graph (DAG) en leggen hun wijzigingen vast in GitHub. Met GitHub-acties worden ze geïmplementeerd in een S3-bucket in account B (voor dit bericht uploaden we de bestanden rechtstreeks naar de S3-bucket). De S3-bucket slaat Airflow-gerelateerde bestanden op, zoals DAG-bestanden,
requirements.txtbestanden en plug-ins. AWS Glue ETL-scripts en assets worden opgeslagen in een andere S3-bucket. Deze scheiding helpt de organisatie in stand te houden en verwarring te voorkomen. - De Airflow DAG maakt gebruik van verschillende operators, sensoren, verbindingen, taken en regels om de datapijplijn naar behoefte uit te voeren.
- De Airflow-logboeken zijn ingelogd Amazon Cloud Watchen waarschuwingen kunnen worden geconfigureerd voor bewakingstaken. Voor meer informatie, zie Dashboards en alarmen monitoren op Amazon MWAA.
Voorwaarden
Omdat deze oplossing draait om het gebruik van Amazon MWAA om de ETL-pijplijn te orkestreren, moet je vooraf bepaalde fundamentele bronnen voor alle accounts instellen. Concreet moet u de S3-buckets en -mappen, AWS Glue-bronnen en Redshift Serverless-bronnen in hun respectievelijke accounts aanmaken voordat u de volledige workflow-integratie implementeert met behulp van Amazon MWAA.
Implementeer bronnen in Account A met behulp van AWS CloudFormation
Start in account A het meegeleverde AWS CloudFormatie stapel om de volgende bronnen te maken:
- De bron- en doel-S3-buckets en -mappen. Als best practice worden de invoer- en uitvoerbucketstructuren geformatteerd met partitie in hive-stijl as
s3://<bucket>/products/YYYY/MM/DD/. - Een voorbeeldgegevensset genaamd
products.csv, die we in dit bericht gebruiken.
![]()
Upload de AWS Glue-taak naar Amazon S3 in account B
Maak in Account B een Amazon S3-locatie aan met de naam aws-glue-assets-<account-id>-<region>/scripts (indien niet aanwezig). Vervang de parameters voor de account-ID en Regio in het sample_glue_job.py script en upload het AWS Glue-taakbestand naar de Amazon S3-locatie.
Implementeer bronnen in Account B met behulp van AWS CloudFormation
Start in Account B de meegeleverde CloudFormation-stacksjabloon om de volgende bronnen te maken:
- De S3-emmer
airflow-<username>-bucketom Airflow-gerelateerde bestanden op te slaan met de volgende structuur:- dags – De map voor DAG-bestanden.
- plugins – Het bestand voor eventuele aangepaste of community Airflow-plug-ins.
- eisen - The
requirements.txtbestand voor alle Python-pakketten. - scripts – Alle SQL-scripts die in de DAG worden gebruikt.
- gegevens – Alle datasets die in de DAG worden gebruikt.
- Een Redshift serverloze omgeving. De naam van de werkgroep en de naamruimte worden voorafgegaan door
sample. - Een AWS Glue-omgeving, die het volgende bevat:
- Een AWS-lijm crawler, waarmee de gegevens uit de S3-bronbucket worden gecrawld
sample-inp-bucket-etl-<username>op rekening A. - Een database genaamd
products_dbin de AWS Glue-gegevenscatalogus. - Een ELT baan Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
sample_glue_job. Deze taak kan bestanden lezen van deproductstabel in de gegevenscatalogus en laad gegevens in de roodverschuivingstabelproducts.
- Een AWS-lijm crawler, waarmee de gegevens uit de S3-bronbucket worden gecrawld
- Een VPC-gateway-eindpunt naar Amazon S3.
- Een Amazon MWAA-omgeving. Voor gedetailleerde stappen om een Amazon MWAA-omgeving te creëren met behulp van de Amazon MWAA-console, raadpleegt u Introductie van door Amazon beheerde workflows voor Apache Airflow (MWAA).
![]()
Creëer Amazon Redshift-bronnen
Maak twee tabellen en een opgeslagen procedure op een Redshift Serverless-werkgroep met behulp van de producten.sql bestand.
In dit voorbeeld maken we twee tabellen genaamd products en products_f. De naam van de opgeslagen procedure is sp_products.
Configureer luchtstroommachtigingen
Nadat de Amazon MWAA-omgeving met succes is aangemaakt, wordt de status weergegeven als Beschikbaar. Kiezen Open de luchtstroom-UI om de luchtstroomgebruikersinterface te bekijken. DAG's worden automatisch gesynchroniseerd vanuit de S3-bucket en zichtbaar in de gebruikersinterface. In dit stadium zijn er echter geen DAG's in de map S3.
Voeg het door de klant beheerde beleid toe AmazonMWAAFullConsoleAccess, waarmee Airflow-gebruikers toegangsrechten krijgen AWS Identiteits- en toegangsbeheer (IAM)-bronnen, en koppel dit beleid aan de Amazon MWAA-rol. Voor meer informatie, zie Toegang krijgen tot een Amazon MWAA-omgeving.
Het beleid dat aan de Amazon MWAA-rol is gekoppeld, heeft volledige toegang en mag alleen worden gebruikt voor testdoeleinden in een beveiligde testomgeving. Voor productie-implementaties volgt u het principe van de minste privileges.
Stel de omgeving in
In dit gedeelte worden de stappen beschreven voor het configureren van de omgeving. Het proces omvat de volgende stappen op hoog niveau:
- Update eventuele benodigde providers.
- Toegang voor meerdere accounts instellen.
- Breng een VPC-peeringverbinding tot stand tussen de Amazon MWAA VPC en Amazon Redshift VPC.
- Configureer Secrets Manager voor integratie met Amazon MWAA.
- Definieer luchtstroomverbindingen.
Update de aanbieders
Volg de stappen in deze sectie als uw versie van Amazon MWAA lager is dan 2.8.1 (de nieuwste versie op het moment dat dit bericht werd geschreven).
Providers zijn pakketten die door de gemeenschap worden onderhouden en alle kernoperatoren, hooks en sensoren voor een bepaalde dienst bevatten. De Amazon-provider wordt gebruikt om te communiceren met AWS-services zoals Amazon S3, Amazon Redshift Serverless, AWS Glue en meer. Er zijn meer dan 200 modules binnen de Amazon-provider.
Hoewel de versie van Airflow die wordt ondersteund in Amazon MWAA 2.6.3 is, die wordt geleverd bij de door Amazon geleverde pakketversie 8.2.0, werd ondersteuning voor Amazon Redshift Serverless pas toegevoegd nadat Amazon pakketversie 8.4.0 had geleverd. Omdat de standaard gebundelde providerversie ouder is dan toen Redshift Serverless-ondersteuning werd geïntroduceerd, moet de providerversie worden geüpgraded om die functionaliteit te kunnen gebruiken.
De eerste stap is het bijwerken van het beperkingenbestand en requirements.txt bestand met de juiste versies. Verwijzen naar Nieuwere providerpakketten opgeven voor stappen om het Amazon-providerpakket bij te werken.
- Specificeer de vereisten als volgt:
- Werk de versie in het beperkingenbestand bij naar 8.4.0 of hoger.
- Voeg de beperkingen-3.11-updated.txt bestand naar de
/dagsmap.
Verwijzen naar Apache Airflow-versies op Amazon Managed Workflows voor Apache Airflow voor correcte versies van het beperkingenbestand, afhankelijk van de Airflow-versie.
- Navigeer naar de Amazon MWAA-omgeving en kies Edit.
- Onder DAG-code in Amazon S3voor Vereistenbestand, kies de nieuwste versie.
- Kies Bespaar.
Hierdoor wordt de omgeving bijgewerkt en worden er nieuwe providers van kracht.
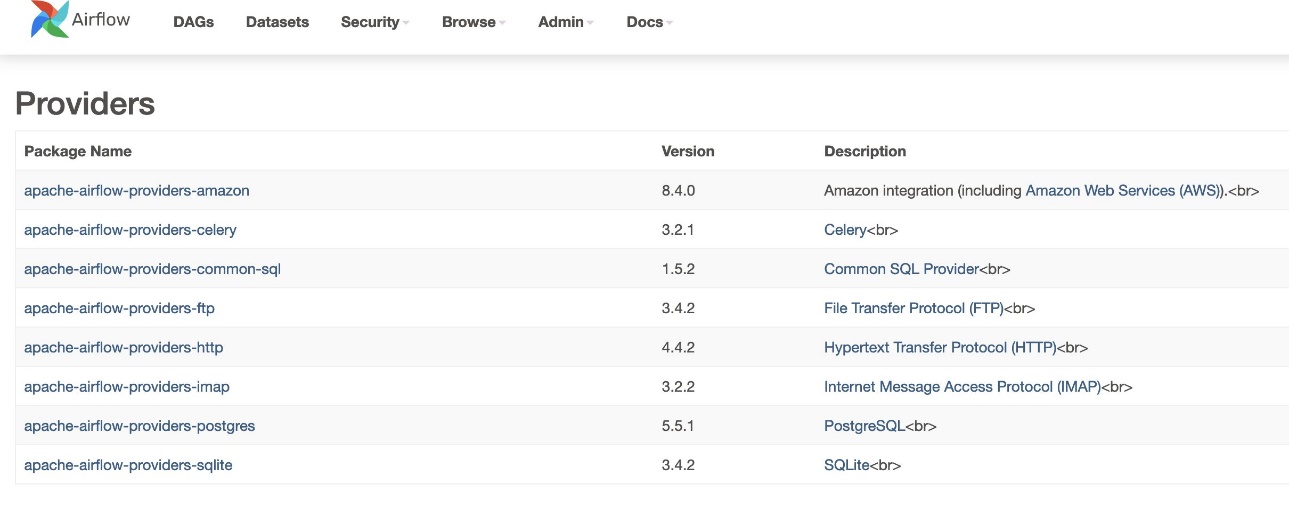
- Ga naar om de versie van de provider te verifiëren Providers onder de beheerder tafel.
De versie voor het Amazon-providerpakket zou 8.4.0 moeten zijn, zoals weergegeven in de volgende schermafbeelding. Als dit niet het geval is, is er een fout opgetreden tijdens het laden requirements.txt. Om eventuele fouten op te lossen, gaat u naar de CloudWatch-console en opent u het bestand requirements_install_ip Log in Streams loggen, waar fouten worden vermeld. Verwijzen naar Logboeken inschakelen op de Amazon MWAA-console voor meer details.
Toegang voor meerdere accounts instellen
U moet beleid en rollen voor meerdere accounts instellen tussen account A en account B om toegang te krijgen tot de S3-buckets om gegevens te laden en te verwijderen. Voer de volgende stappen uit:
- Configureer in Account A het bucketbeleid voor bucket
sample-inp-bucket-etl-<username>om machtigingen te verlenen aan de AWS Glue- en Amazon MWAA-rollen in Account B voor objecten in bucketsample-inp-bucket-etl-<username>: - Configureer op dezelfde manier het bucketbeleid voor bucket
sample-opt-bucket-etl-<username>om machtigingen te verlenen aan Amazon MWAA-rollen in account B om objecten in deze bucket te plaatsen: - Maak in Account A een IAM-beleid met de naam
policy_for_roleA, waarmee de noodzakelijke Amazon S3-acties op de uitvoerbucket mogelijk zijn: - Maak een nieuwe IAM-rol met de naam
RoleAmet Account B als de rol van vertrouwde entiteit en voeg dit beleid toe aan de rol. Hierdoor kan Account B RoleA aannemen om de noodzakelijke Amazon S3-acties uit te voeren op de uitvoerbucket. - Maak in Account B een IAM-beleid met de naam
s3-cross-account-accessmet toestemming om toegang te krijgen tot objecten in de bucketsample-inp-bucket-etl-<username>, die op rekening A staat. - Voeg dit beleid toe aan de AWS Glue-rol en Amazon MWAA-rol:
- Maak in Account B het IAM-beleid aan
policy_for_roleBdoor Account A op te geven als een vertrouwde entiteit. Het volgende is het vertrouwensbeleid dat moet worden aangenomenRoleAop rekening A: - Maak een nieuwe IAM-rol met de naam
RoleBmet Amazon Redshift als het vertrouwde entiteitstype en voeg dit beleid toe aan de rol. Dit maakt het mogelijkRoleBaannemenRoleAin Account A en ook aan te nemen door Amazon Redshift. - hechten
RoleBnaar de Redshift Serverless-naamruimte, zodat Amazon Redshift objecten naar de S3-uitvoerbucket in Account A kan schrijven. - Voeg het beleid toe
policy_for_roleBaan de Amazon MWAA-rol, waardoor Amazon MWAA toegang krijgt tot de uitvoerbucket in account A.
Verwijzen naar Hoe geef ik via meerdere accounts toegang tot objecten die zich in Amazon S3-buckets bevinden? voor meer details over het instellen van toegang tussen accounts tot objecten in Amazon S3 van AWS Glue en Amazon MWAA. Verwijzen naar Hoe KOPIEER of ONTLAAD ik gegevens van Amazon Redshift naar een Amazon S3-bucket in een ander account? voor meer informatie over het instellen van rollen voor het overbrengen van gegevens van Amazon Redshift naar Amazon S3 van Amazon MWAA.
Stel VPC-peering in tussen de Amazon MWAA- en Amazon Redshift-VPC's
Omdat Amazon MWAA en Amazon Redshift zich in twee afzonderlijke VPC's bevinden, moet u VPC-peering daartussen instellen. U moet voor beide services een route toevoegen aan de routetabellen die aan de subnetten zijn gekoppeld. Verwijzen naar Werk met VPC-peeringverbindingen voor meer informatie over VPC-peering.

Zorg ervoor dat het CIDR-bereik van de Amazon MWAA VPC is toegestaan in de Redshift-beveiligingsgroep en dat het CIDR-bereik van de Amazon Redshift VPC is toegestaan in de Amazon MWAA-beveiligingsgroep, zoals weergegeven in de volgende schermafbeelding.

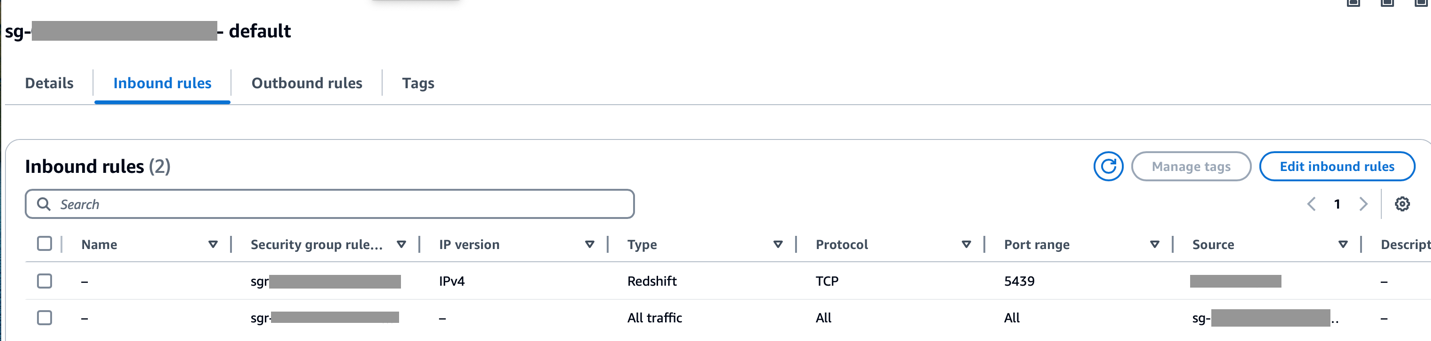
Als een van de voorgaande stappen onjuist is geconfigureerd, zult u waarschijnlijk een ‘Connection Timeout’-fout tegenkomen tijdens de DAG-uitvoering.
Configureer de Amazon MWAA-verbinding met Secrets Manager
Wanneer de Amazon MWAA-pijplijn is geconfigureerd om Secrets Manager te gebruiken, zal deze eerst zoeken naar verbindingen en variabelen in een alternatieve backend (zoals Secrets Manager). Als de alternatieve backend de benodigde waarde bevat, wordt deze geretourneerd. Anders zal het de metadatadatabase controleren op de waarde en die in plaats daarvan retourneren. Voor meer details, zie Een Apache Airflow-verbinding configureren met behulp van een AWS Secrets Manager-geheim.
Voer de volgende stappen uit:
- Configureer een VPC-eindpunt om Amazon MWAA en Secrets Manager te koppelen (
com.amazonaws.us-east-1.secretsmanager).
Hierdoor heeft Amazon MWAA toegang tot de inloggegevens die zijn opgeslagen in Secrets Manager.

- Om Amazon MWAA toestemming te geven voor toegang tot de geheime sleutels van Secrets Manager, voegt u het aangeroepen beleid toe
SecretsManagerReadWritevoor de IAM-rol van de omgeving. - Om de Secrets Manager-backend te maken als een Apache Airflow-configuratieoptie, gaat u naar de Airflow-configuratieopties, voegt u de volgende sleutel-waardeparen toe en slaat u uw instellingen op.
Hierdoor wordt Airflow geconfigureerd om te zoeken naar verbindingsreeksen en variabelen op de airflow/connections/* en airflow/variables/* paden:

- Om een Airflow-verbindings-URI-tekenreeks te genereren, gaat u naar AWS-cloudshell en ga een Python-shell binnen.
- Voer de volgende code uit om de verbindings-URI-tekenreeks te genereren:
De verbindingsreeks moet als volgt worden gegenereerd:
- Voeg de verbinding toe in Secrets Manager met behulp van de volgende opdracht in het AWS-opdrachtregelinterface (AWS CLI).
Dit kan ook gedaan worden vanuit de Secrets Manager-console. Dit wordt als platte tekst toegevoegd aan Secrets Manager.
Gebruik de verbinding airflow/connections/secrets_redshift_connection in de DAG. Wanneer de DAG wordt uitgevoerd, zal deze naar deze verbinding zoeken en de geheimen uit Secrets Manager ophalen. In het geval van RedshiftDataOperator, geef de secret_arn als parameter in plaats van verbindingsnaam.
U kunt ook geheimen toevoegen met behulp van de Secrets Manager-console als sleutel-waardeparen.
- Voeg nog een geheim toe in Secrets Manager en sla het op als
airflow/connections/redshift_conn_test.
Creëer een Airflow-verbinding via de metadatadatabase
U kunt ook verbindingen maken in de gebruikersinterface. In dit geval worden de verbindingsgegevens opgeslagen in een Airflow-metagegevensdatabase. Als de Amazon MWAA-omgeving niet is geconfigureerd om de Secrets Manager-backend te gebruiken, zal deze de metadatadatabase controleren op de waarde en deze retourneren. U kunt een Airflow-verbinding maken met behulp van de UI, AWS CLI of API. In deze sectie laten we zien hoe u een verbinding tot stand kunt brengen met behulp van de Airflow-gebruikersinterface.
- Voor Verbindings-ID, voer een naam in voor de verbinding.
- Voor Type verbinding, kiezen Amazon roodverschuiving.
- Voor gastheer, voer het Redshift-eindpunt in (zonder poort en database) voor Redshift Serverless.
- Voor Database, ga naar binnen
dev. - Voor Gebruiker, voer uw beheerdersgebruikersnaam in.
- Voor Wachtwoord, voer uw wachtwoord in.
- Voor Haven, gebruik poort 5439.
- Voor Extra, stel de
regionentimeoutparameters. - Test de verbinding en sla vervolgens uw instellingen op.

Maak en voer een DAG uit
In deze sectie beschrijven we hoe u een DAG kunt maken met behulp van verschillende componenten. Nadat u de DAG hebt gemaakt en uitgevoerd, kunt u de resultaten verifiëren door Redshift-tabellen op te vragen en de doel-S3-buckets te controleren.
Maak een DAG
In Airflow worden datapijplijnen in Python-code gedefinieerd als DAG's. We creëren een DAG die bestaat uit verschillende operators, sensoren, verbindingen, taken en regels:
- De DAG begint met het zoeken naar bronbestanden in de S3-bucket
sample-inp-bucket-etl-<username>onder Account A voor de huidige dagS3KeySensor. S3KeySensor wordt gebruikt om te wachten tot een of meerdere sleutels aanwezig zijn in een S3-bucket.- Onze S3-bucket is bijvoorbeeld gepartitioneerd als
s3://bucket/products/YYYY/MM/DD/, dus onze sensor moet controleren op mappen met de huidige datum. We hebben de huidige datum in de DAG afgeleid en doorgegevenS3KeySensor, dat zoekt naar nieuwe bestanden in de map van de huidige dag. - Wij hebben ook gezeten
wildcard_matchasTrue, waarmee zoekopdrachten mogelijk zijnbucket_keyte worden geïnterpreteerd als een Unix-jokertekenpatroon. Stel demodenaarreschedulezodat de sensortaak de werkruimte vrijmaakt wanneer niet aan de criteria wordt voldaan en deze op een later tijdstip opnieuw wordt gepland. Gebruik deze modus als best practice wanneerpoke_intervalis meer dan 1 minuut om te veel belasting van een planner te voorkomen.
- Onze S3-bucket is bijvoorbeeld gepartitioneerd als
- Nadat het bestand beschikbaar is in de S3-bucket, wordt de AWS Glue-crawler uitgevoerd met behulp van
GlueCrawlerOperatorom de S3-bronbucket te crawlensample-inp-bucket-etl-<username>onder Account A en werkt de metagegevens van de tabel bij onder deproducts_dbdatabase in de gegevenscatalogus. De crawler gebruikt de AWS Glue-rol en de Data Catalog-database die in de vorige stappen zijn gemaakt. - De DAG gebruikt
GlueCrawlerSensorwachten tot de crawler is voltooid. - Wanneer de crawlertaak voltooid is,
GlueJobOperatorwordt gebruikt om de AWS Glue-taak uit te voeren. De AWS Glue-scriptnaam (samen met de locatie) wordt samen met de AWS Glue IAM-rol doorgegeven aan de operator. Andere parameters zoalsGlueVersion,NumberofWorkersenWorkerTypeworden doorgegeven met behulp van decreate_job_kwargsparameter. - De DAG gebruikt
GlueJobSensorwachten tot de AWS Glue-taak is voltooid. Als het klaar is, de Redshift-stagingtabelproductswordt geladen met gegevens uit het S3-bestand. - Je kunt vanuit Airflow verbinding maken met Amazon Redshift via drie verschillende exploitanten:
PythonOperator.SQLExecuteQueryOperator, dat gebruikmaakt van een PostgreSQL-verbinding enredshift_defaultals standaardverbinding.RedshiftDataOperator, die gebruikmaakt van de Redshift Data API enaws_defaultals standaardverbinding.
In onze DAG gebruiken we SQLExecuteQueryOperator en RedshiftDataOperator om te laten zien hoe u deze operators kunt gebruiken. De opgeslagen Redshift-procedures worden uitgevoerd RedshiftDataOperator. De DAG voert ook SQL-opdrachten uit in Amazon Redshift om de gegevens uit de stagingtabel te verwijderen met behulp van SQLExecuteQueryOperator.
Omdat we onze Amazon MWAA-omgeving hebben geconfigureerd om naar verbindingen te zoeken in Secrets Manager, haalt de DAG, wanneer deze wordt uitgevoerd, de Redshift-verbindingsgegevens zoals gebruikersnaam, wachtwoord, host, poort en regio op uit Secrets Manager. Als de verbinding niet wordt gevonden in Secrets Manager, worden de waarden opgehaald uit de standaardverbindingen.
In SQLExecuteQueryOperator, geven we de verbindingsnaam door die we in Secrets Manager hebben gemaakt. Het zoekt airflow/connections/secrets_redshift_connection en haalt de geheimen op uit Secrets Manager. Als Secrets Manager niet is ingesteld, wordt de handmatig gemaakte verbinding (bijvoorbeeld redshift-conn-id) kan worden doorgegeven.
In RedshiftDataOperator, passeren we de secret_arn van de airflow/connections/redshift_conn_test verbinding gemaakt in Secrets Manager als een parameter.
- Als laatste taak,
RedshiftToS3Operatorwordt gebruikt om gegevens uit de Redshift-tabel naar een S3-bucket te ladensample-opt-bucket-etlop rekening B.airflow/connections/redshift_conn_testvan Secrets Manager wordt gebruikt voor het verwijderen van de gegevens. TriggerRuleis ingesteld opALL_DONE, waardoor de volgende stap kan worden uitgevoerd nadat alle upstream-taken zijn voltooid.- De afhankelijkheid van taken wordt gedefinieerd met behulp van de
chain()functie, die indien nodig parallelle uitvoering van taken mogelijk maakt. In ons geval willen we dat alle taken op volgorde worden uitgevoerd.
Het volgende is de volledige DAG-code. De dag_id moet overeenkomen met de DAG-scriptnaam, anders wordt deze niet gesynchroniseerd met de Airflow-gebruikersinterface.
Controleer de DAG-run
Nadat u het DAG-bestand hebt gemaakt (vervang de variabelen in het DAG-script) en het hebt geüpload naar het s3://sample-airflow-instance/dags map, wordt deze automatisch gesynchroniseerd met de Airflow-gebruikersinterface. Alle DAG's verschijnen op de DAG's tabblad. Schakel de ON optie om de DAG uitvoerbaar te maken. Omdat onze DAG is ingesteld op schedule="@once", moet u de taak handmatig uitvoeren door het run-pictogram hieronder te kiezen Acties. Wanneer de DAG voltooid is, wordt de status in het groen bijgewerkt, zoals weergegeven in de volgende schermafbeelding.
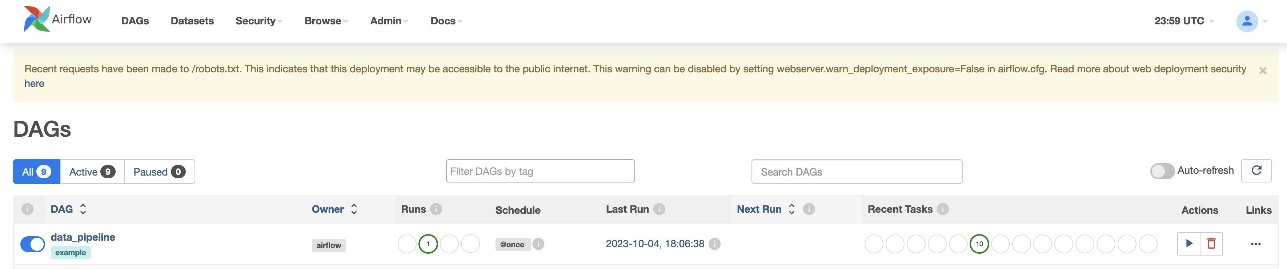
In het Kruisstukken sectie zijn er opties om de code, grafiek, raster, log en meer te bekijken. Kiezen Diagram om de DAG in een grafiekformaat te visualiseren. Zoals u in de volgende schermafbeelding kunt zien, duidt elke kleur van het knooppunt een specifieke operator aan, en geeft de kleur van de knooppuntomtrek een specifieke status aan.

Controleer de resultaten
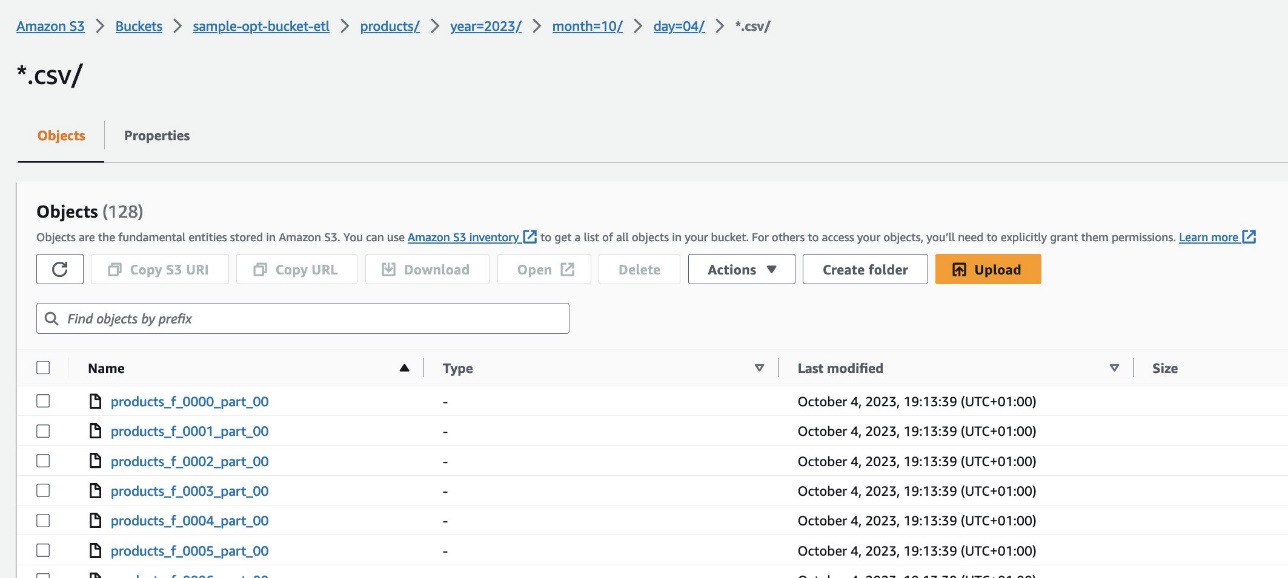
Navigeer op de Amazon Redshift-console naar de Query-editor v2 en selecteer de gegevens in het products_f tafel. De tabel moet worden geladen en hetzelfde aantal records bevatten als S3-bestanden.

Navigeer op de Amazon S3-console naar de S3-bucket s3://sample-opt-bucket-etl op rekening B. De product_f bestanden moeten worden gemaakt onder de mapstructuur s3://sample-opt-bucket-etl/products/YYYY/MM/DD/.
Opruimen
Ruim de bronnen op die zijn gemaakt als onderdeel van dit bericht om te voorkomen dat er doorlopende kosten in rekening worden gebracht:
- Verwijder de CloudFormation-stacks en S3-bucket die u als vereisten hebt gemaakt.
- Verwijder de VPC's en VPC-peeringverbindingen, het beleid en de rollen voor meerdere accounts en de geheimen in Secrets Manager.
Conclusie
Met Amazon MWAA kun je complexe workflows bouwen met Airflow en Python zonder clusters, knooppunten of andere operationele overhead te beheren die doorgaans gepaard gaat met het implementeren en schalen van Airflow in productie. In dit bericht hebben we laten zien hoe Amazon MWAA een geautomatiseerde manier biedt om gegevens op te nemen, te transformeren, te analyseren en te distribueren tussen verschillende accounts en services binnen AWS. Raadpleeg het volgende voor meer voorbeelden van andere AWS-operators GitHub-repository; we moedigen u aan om meer te leren door enkele van deze voorbeelden uit te proberen.
Over de auteurs

Radhika Jakkula is een Big Data Prototyping Solutions Architect bij AWS. Ze helpt klanten bij het bouwen van prototypen met behulp van AWS-analyseservices en speciaal gebouwde databases. Ze is een specialist in het beoordelen van een breed scala aan vereisten en het toepassen van relevante AWS-services, big data-tools en raamwerken om een robuuste architectuur te creëren.
 Sidhanth Muralidhar is een Principal Technical Account Manager bij AWS. Hij werkt met grote zakelijke klanten die hun workloads op AWS draaien. Hij heeft een passie voor het werken met klanten en het helpen van hen bij het ontwerpen van workloads op het gebied van kosten, betrouwbaarheid, prestaties en operationele uitmuntendheid op schaal in hun cloudtraject. Daarnaast heeft hij een grote interesse in data-analyse.
Sidhanth Muralidhar is een Principal Technical Account Manager bij AWS. Hij werkt met grote zakelijke klanten die hun workloads op AWS draaien. Hij heeft een passie voor het werken met klanten en het helpen van hen bij het ontwerpen van workloads op het gebied van kosten, betrouwbaarheid, prestaties en operationele uitmuntendheid op schaal in hun cloudtraject. Daarnaast heeft hij een grote interesse in data-analyse.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/orchestrate-an-end-to-end-etl-pipeline-using-amazon-s3-aws-glue-and-amazon-redshift-serverless-with-amazon-mwaa/

