Dit bericht is geschreven in samenwerking met Claudia Chitu en Spyridon Dosis van ACAST.
Opgericht in 2014, Acast is 's werelds toonaangevende onafhankelijke podcastbedrijf, dat podcastmakers en podcast-adverteerders naar een hoger niveau tilt voor de ultieme luisterervaring. Door te pleiten voor een onafhankelijk en open ecosysteem voor podcasting, wil Acast podcasting voeden met de tools en het genereren van inkomsten die nodig zijn om te floreren.
Het bedrijf gebruikt AWS Cloud-services om datagestuurde producten te bouwen en best practices op het gebied van engineering te schalen. Om een duurzaam dataplatform te garanderen te midden van de groei- en winstgevendheidsfasen, hebben hun technische teams een gedecentraliseerde aanpak aangenomen data mesh-architectuur.
In dit bericht bespreken we hoe Acast de uitdaging van gekoppelde afhankelijkheden tussen teams die op grote schaal met data werken, heeft overwonnen door het concept van een datamesh te gebruiken.
Het probleem
Met een versnelde groei en expansie kwam Acast een uitdaging tegen die wereldwijd weerklank vindt. Acast bevond zich met diverse bedrijfseenheden en een enorme hoeveelheid gegevens die door de hele organisatie werd gegenereerd. De bestaande monolithische en gecentraliseerde architectuur had moeite om aan de groeiende eisen van dataconsumenten te voldoen. Data-ingenieurs vonden het steeds moeilijker om de data-infrastructuur te onderhouden en te schalen, wat resulteerde in datatoegang, datasilo's en inefficiënties in databeheer. Een belangrijke doelstelling was het verbeteren van de end-to-end gebruikerservaring, uitgaande van de zakelijke behoeften.
Acast moest deze uitdagingen aangaan om een operationele schaal te bereiken, wat neerkomt op een wereldwijd maximum van het aantal mensen dat onafhankelijk kan opereren en waarde kan leveren. In dit geval probeerde Acast de uitdaging van deze monolietstructuur en de hoge time-to-value voor productteams, technische teams en eindgebruikers aan te pakken. Het is de moeite waard te vermelden dat ze ook andere product- en technologieteams hebben, inclusief operationele of zakelijke teams, zonder AWS-accounts.
Acast heeft een variabel aantal productteams, die voortdurend evolueren door bestaande teams samen te voegen, op te splitsen, nieuwe mensen toe te voegen of eenvoudigweg nieuwe teams te creëren. In de afgelopen twee jaar hebben ze tussen de 2 en 10 teams gehad, elk bestaande uit 20 tot 4 personen. Elk team bezit minimaal twee AWS-accounts, maximaal 10 accounts, afhankelijk van het eigendom. Het merendeel van de gegevens die door deze accounts worden geproduceerd, wordt downstream gebruikt voor business intelligence (BI)-doeleinden en in Amazone Athene, elke dag door honderden zakelijke gebruikers.
De oplossing die Acast heeft geïmplementeerd is een data mesh, ontworpen op AWS. De oplossing weerspiegelt de organisatiestructuur in plaats van een expliciete architecturale beslissing. Volgens de Inverse Conway Manoeuvre vertoont de technologiearchitectuur van Acast isomorfisme met de zakelijke architectuur. In dit geval kunnen de zakelijke gebruikers via de data mesh-architectuur sneller inzicht krijgen en direct weten wie de domeinspecifieke eigenaren zijn, waardoor de samenwerking wordt versneld. Dit zal verder worden gedetailleerd wanneer we de AWS Identity and Access Management (IAM)-rollen bespreken die worden gebruikt in onze AWS-certificering, omdat een van de rollen is toegewezen aan de businessgroep.
Parameters van succes
Acast slaagde erin een nieuw team- en domeingeoriënteerd dataproduct en de bijbehorende infrastructuur en opzet op te starten en op te schalen, wat resulteerde in minder wrijving bij het verzamelen van inzichten en gelukkiger gebruikers en consumenten.
Het succes van de implementatie betekende dat verschillende aspecten van de data-infrastructuur, het databeheer en de bedrijfsresultaten moesten worden beoordeeld. Ze classificeerden de statistieken en indicatoren in de volgende categorieën:
- Gebruiksgegevens – Een duidelijk inzicht in wie welke gegevensbron gebruikt, gematerialiseerd door het in kaart brengen van consumenten en producenten. Uit gesprekken met gebruikers bleek dat ze blijer waren met snellere toegang tot gegevens op een eenvoudiger manier, een meer gestructureerde gegevensorganisatie en een duidelijk overzicht van wie de producent is. Er is veel vooruitgang geboekt bij het bevorderen van hun datagedreven cultuur (datageletterdheid, het delen van data en samenwerking tussen bedrijfseenheden).
- Gegevensbeheer – Met hun serviceniveau-object dat aangeeft wanneer de gegevensbronnen beschikbaar zijn (onder andere details), weten teams wie ze op de hoogte moeten stellen en kunnen ze dit in een kortere tijd doen als er te late gegevens binnenkomen of andere problemen met de gegevens. Met de rol van datasteward is het eigenaarschap versterkt.
- Productiviteit van datateams – Via technische retrospectieven ontdekte Acast dat hun teams de autonomie waarderen om beslissingen te nemen met betrekking tot hun datadomeinen.
- Kosten- en hulpbronnenefficiëntie – Dit is een gebied waarop Acast een vermindering van het dupliceren van gegevens heeft waargenomen, en dus ook een kostenbesparing (in sommige accounts is de kopie van de gegevens voor 100% verwijderd), door gegevens tussen accounts te lezen en tegelijkertijd schaalbaarheid mogelijk te maken.
Overzicht datamesh
Een data mesh is een sociotechnische benadering om een gedecentraliseerde data-architectuur op te bouwen door gebruik te maken van een domeingericht, zelfbedieningsontwerp (in een softwareontwikkelingsperspectief), en ontleent de theorie van Eric Evans over domeingestuurd ontwerp en die van Manuel Pais en Matthew Skelton. theorie van teamtopologieën. Het is belangrijk om de context vast te stellen om te begrijpen wat data mesh is, omdat dit de basis vormt voor de technische details die volgen en u kan helpen begrijpen hoe de concepten die in dit bericht worden besproken passen in het bredere raamwerk van een data mesh.
Om samen te vatten voordat we dieper ingaan op de implementatie van Acast: het data mesh-concept is gebaseerd op de volgende principes:
- Het is domeingedreven, in tegenstelling tot pijpleidingen als een eersteklas zorg
- Het dient data als een product
- Het is een goed product waar gebruikers blij mee zijn (gegevens zijn betrouwbaar, documentatie is beschikbaar en gemakkelijk te gebruiken)
- Het biedt federatief computerbeheer en gedecentraliseerd eigendom: een zelfbedieningsdataplatform
Domeingestuurde architectuur
In de benadering van Acast om de operationele en analytische datasets te bezitten, zijn teams gestructureerd met eigendom op basis van domein, rechtstreeks lezen van de producent van de gegevens, via een API of programmatisch vanuit Amazon S3-opslag of met behulp van Athena als een SQL-query-engine. Enkele voorbeelden van de domeinen van Acast worden weergegeven in de volgende afbeelding.
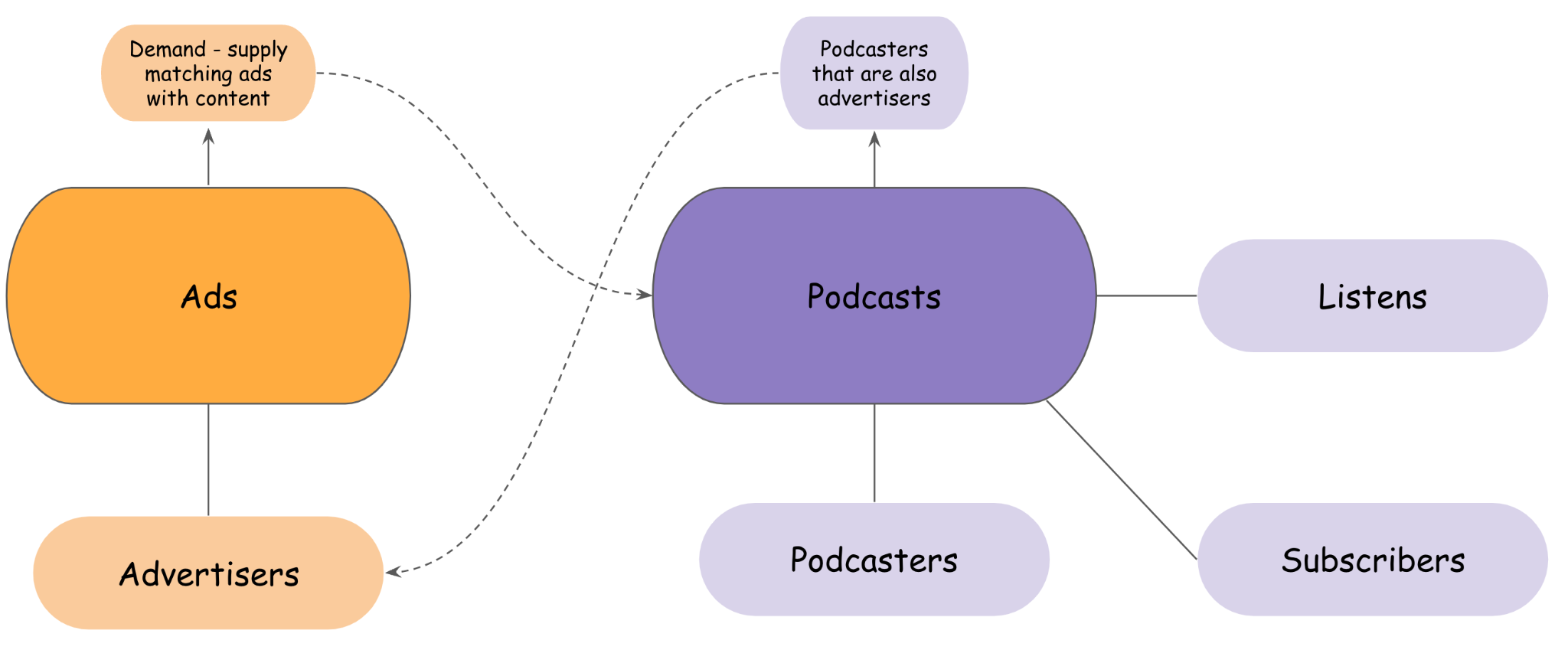
Zoals geïllustreerd in de voorgaande afbeelding zijn sommige domeinen losjes gekoppeld aan de operationele of analytische eindpunten van andere domeinen, met een ander eigenaarschap. Anderen zijn misschien sterker afhankelijk van het bedrijfsleven, zoals wordt verwacht (sommige podcasters kunnen ook adverteerders zijn, die sponsoradvertenties maken en campagnes voeren voor hun eigen shows, of advertenties afhandelen met behulp van de software as a service van Acast).
Gegevens als product
Het behandelen van data als een product omvat drie belangrijke componenten: de data zelf, de metadata en de bijbehorende code en infrastructuur. In deze aanpak worden teams die verantwoordelijk zijn voor het genereren van gegevens aangeduid als producenten. Deze producententeams beschikken over diepgaande kennis over hun consumenten en begrijpen hoe hun dataproduct wordt gebruikt. Eventuele door de dataproducenten geplande wijzigingen worden vooraf aan alle consumenten gecommuniceerd. Deze proactieve melding zorgt ervoor dat downstream-processen niet worden verstoord. Door consumenten vooraf op de hoogte te stellen, hebben ze voldoende tijd om zich voor te bereiden op en zich aan te passen aan de komende veranderingen, waardoor een soepele en ononderbroken workflow behouden blijft. De producenten voeren parallel een nieuwe versie van de initiële dataset uit, stellen de consumenten individueel op de hoogte en bespreken met hen het benodigde tijdsbestek om de nieuwe versie te gaan gebruiken. Wanneer alle consumenten de nieuwe versie gebruiken, maken de producenten de oorspronkelijke versie onbeschikbaar.
Gegevensschema's worden afgeleid van het algemeen overeengekomen formaat om bestanden tussen teams te delen, wat in het geval van Acast Parquet is. Gegevens kunnen worden gedeeld in bestanden, batchgebeurtenissen of streamgebeurtenissen, en meer. Elk team heeft zijn eigen AWS-account en fungeert als een onafhankelijke en autonome entiteit met zijn eigen infrastructuur. Voor orkestratie gebruiken ze de AWS Cloud-ontwikkelingskit (AWS CDK) voor infrastructuur als code (IaC) en AWS lijm Gegevenscatalogi voor metadatabeheer. Gebruikers kunnen ook verzoeken indienen bij producenten om de manier waarop de gegevens worden gepresenteerd te verbeteren of om de gegevens te verrijken met nieuwe datapunten om een hogere bedrijfswaarde te genereren.
Omdat elk team een AWS-account en een datacatalogus-ID van Athena bezit, is het eenvoudig om dit te zien door de lenzen van een gedistribueerd datameer bovenop Amazon S3, met een gemeenschappelijke catalogus die alle catalogi van alle accounts in kaart brengt.
Tegelijkertijd kan elk team ook andere catalogi aan hun eigen account toewijzen en hun eigen gegevens gebruiken, die ze samen met de gegevens van andere accounts produceren. Tenzij het gevoelige gegevens betreft, zijn de gegevens programmatisch of via het AWS-beheerconsole op een self-service manier zonder afhankelijk te zijn van de data-infrastructuuringenieurs. Dit is een domeinonafhankelijke, gedeelde manier om gegevens zelf te bedienen. De productontdekking gebeurt via de catalogusregistratie. Met behulp van slechts een paar standaarden waarover het bedrijf het eens was en die binnen het hele bedrijf werden toegepast, pakte Acast met het oog op interoperabiliteit de gefragmenteerde silo's en de wrijving aan om gegevens uit te wisselen of domein-agnostische gegevens te consumeren.
Met dit principe krijgen teams de zekerheid dat de gegevens veilig, betrouwbaar en nauwkeurig zijn, en dat passende toegangscontroles op elk domeinniveau worden beheerd. Bovendien worden op het centrale account rollen gedefinieerd voor verschillende soorten machtigingen en toegang, met behulp van AWS IAM Identiteitscentrum rechten. Alle datasets zijn vindbaar vanuit één centraal account. De volgende afbeelding illustreert hoe het is geïnstrumenteerd, waarbij twee IAM-rollen worden vervuld door twee soorten gebruikersgroepen (consumenten): één die toegang heeft tot een beperkte dataset, namelijk beperkte gegevens, en één die toegang heeft tot niet-beperkte gegevens. Er is ook een manier om een van deze rollen op zich te nemen, voor serviceaccounts, zoals die worden gebruikt voor gegevensverwerkingstaken in Door Amazon beheerde workflows voor Apache Airflow (Amazon MWAA), bijvoorbeeld.
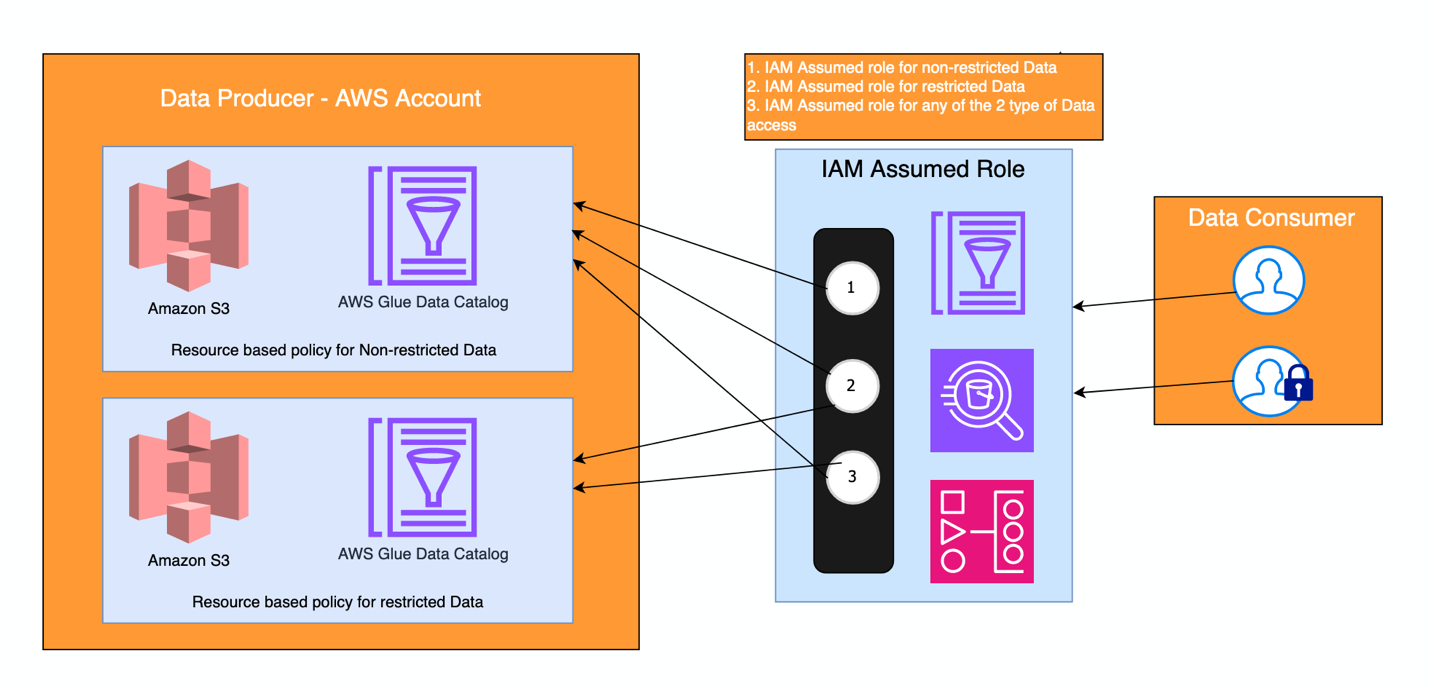
Hoe Acast oploste voor een hoge uitlijning en een losjes gekoppelde architectuur
Het volgende diagram toont een conceptuele architectuur van hoe de teams van Acast gegevens organiseren en met elkaar samenwerken.
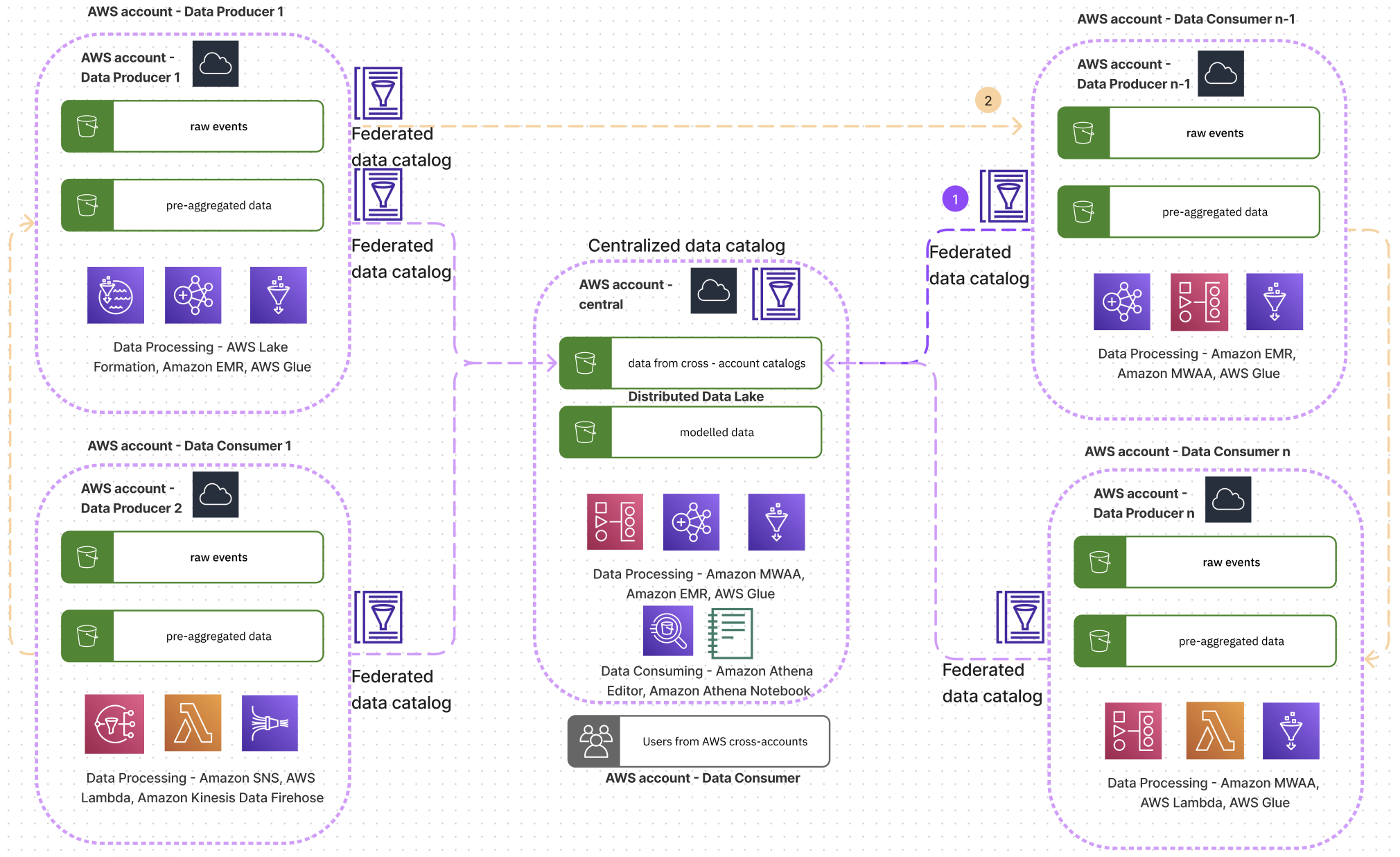
Acast gebruikte de Goed ontworpen raamwerk voor het centrale account om de praktijk van het uitvoeren van analytische workloads in de cloud te verbeteren. Door de lenzen van de tool kon Acast een betere monitoring realiseren, kosten optimalisatie, prestaties en beveiliging. Het hielp hen inzicht te krijgen in de gebieden waarop ze hun werklast konden verbeteren, hoe ze veelvoorkomende problemen konden aanpakken met geautomatiseerde oplossingen, en hoe ze het succes konden meten door KPI’s te definiëren. Het bespaarde hen tijd om de lessen te leren die anders langer zouden hebben geduurd om te vinden. Spyridon Dosis, Information Security Officer van Acast, zegt: “We zijn blij dat AWS altijd voorop loopt met het uitbrengen van tools die de configuratie, beoordeling en beoordeling van het instellen van meerdere accounts mogelijk maken. Voor ons is dit een groot pluspunt, omdat we in een decentrale organisatie werken.” Spyridon voegt ook toe: “Een heel belangrijk concept dat we waarderen zijn de standaardbeveiligingsinstellingen van AWS (bijvoorbeeld standaardcodering voor S3-buckets).”
In het architectuurdiagram kunnen we zien dat elk team een dataproducent kan zijn, behalve het team dat eigenaar is van het centrale account, dat dient als het centrale dataplatform en de logica uit meerdere domeinen modelleert om het volledige bedrijfsplaatje te schetsen. Alle andere teams kunnen dataproducenten of dataconsumenten zijn. Ze kunnen verbinding maken met het centrale account en datasets ontdekken via de cross-account AWS Glue Data Catalog, deze analyseren in de Athena-queryeditor of met Athena-notebooks, of de catalogus toewijzen aan hun eigen AWS-account. Toegang tot de centrale Athena-catalogus wordt geïmplementeerd met IAM Identity Center, met rollen voor open data en beperkte datatoegang.
Voor niet-gevoelige gegevens (open data) gebruikt Acast een sjabloon waarbij de gegevenssets standaard openstaan voor de hele organisatie om uit te lezen, waarbij een voorwaarde wordt gebruikt om de door de organisatie toegewezen ID-parameter op te geven, zoals weergegeven in het volgende codefragment:
Bij het omgaan met gevoelige gegevens, zoals financiële gegevens, gebruiken de teams een collaboratief datasteward-model. De datasteward werkt samen met de aanvrager om de rechtvaardiging van de toegang voor het beoogde gebruiksscenario te evalueren. Samen bepalen ze de juiste toegangsmethoden om aan de behoefte te voldoen en tegelijkertijd de veiligheid te behouden. Dit kunnen IAM-rollen, serviceaccounts of specifieke AWS-services zijn. Met deze aanpak kunnen zakelijke gebruikers buiten de technologieorganisatie (wat betekent dat ze geen AWS-account hebben) zelfstandig toegang krijgen tot de informatie die ze nodig hebben en deze analyseren. Door via IAM-beleid toegang te verlenen tot AWS Glue-bronnen en S3-buckets, biedt Acast zelfbedieningsmogelijkheden terwijl gevoelige gegevens nog steeds worden beheerd via menselijke beoordeling. De rol van datasteward is waardevol geweest voor het begrijpen van gebruiksscenario's, het beoordelen van beveiligingsrisico's en uiteindelijk het faciliteren van toegang die het bedrijf versnelt door middel van analytische inzichten.
Voor het gebruik van Acast waren gedetailleerde toegangscontroles op rij- of kolomniveau niet nodig, dus de aanpak voldeed. Andere organisaties hebben mogelijk echter een fijnmaziger beheer van gevoelige gegevensvelden nodig. In die gevallen zijn oplossingen zoals AWS Lake-formatie zou de benodigde machtigingen kunnen implementeren, terwijl het toch een zelfbedieningsmodel voor gegevenstoegang biedt. Voor meer informatie, zie Ontwerp een data mesh-architectuur met behulp van AWS Lake Formation en AWS Glue.
Tegelijkertijd kunnen teams rechtstreeks van andere producenten lezen, van Amazon S3 of via een API, waardoor de afhankelijkheid tot een minimum wordt beperkt, wat de snelheid van ontwikkeling en levering verbetert. Daarom kan een account tegelijkertijd een producent en een consument zijn. Elk team is autonoom en verantwoordelijk voor zijn eigen tech-stack.
Aanvullende lessen
Wat heeft Acast geleerd? Tot nu toe hebben we besproken dat het architecturale ontwerp een effect is van de organisatiestructuur. Omdat de technologieorganisatie uit meerdere cross-functionele teams bestaat en het eenvoudig is om een nieuw team op te starten, volgens de gemeenschappelijke principes van data mesh, heeft Acast geleerd dat dit niet altijd vlekkeloos verloopt. Om een volledig nieuw account in AWS op te zetten, doorlopen teams dezelfde reis, maar iets anders, rekening houdend met hun eigen specifieke kenmerken.
Dit kan voor bepaalde fricties zorgen, en het is moeilijk om alle dataproducerende teams een hoge mate van volwassenheid als dataproducent te laten bereiken. Dit kan worden verklaard door de verschillende datacompetenties in deze cross-functionele teams en niet door specifieke datateams.
Door de gedecentraliseerde oplossing te implementeren, heeft Acast de schaalbaarheidsuitdaging effectief aangepakt door hun teams aan te passen aan de veranderende bedrijfsbehoeften. Deze aanpak zorgt voor een hoge ontkoppeling en uitlijning. Bovendien versterkten ze het eigenaarschap, waardoor de tijd die nodig was om problemen te identificeren en op te lossen aanzienlijk werd verkort, omdat de upstream-bron gemakkelijk bekend en gemakkelijk toegankelijk is met gespecificeerde SLA's. Het aantal vragen over gegevensondersteuning is met meer dan 50% afgenomen, omdat zakelijke gebruikers sneller inzicht kunnen krijgen. Met name hebben ze met succes tientallen terabytes aan redundante opslag geëlimineerd die voorheen uitsluitend werden gekopieerd om aan downstream-verzoeken te voldoen. Deze prestatie werd mogelijk gemaakt door de implementatie van cross-account reading, wat leidde tot het wegvallen van de bijbehorende ontwikkelings- en onderhoudskosten voor deze pijpleidingen.
Conclusie
Acast gebruikte de Inverse Conway Manoeuvre-wet en maakte gebruik van AWS-diensten waarbij elk cross-functioneel productteam zijn eigen AWS-account heeft om een data mesh-architectuur te bouwen die schaalbaarheid, hoog eigendom en self-service dataverbruik mogelijk maakt. Dit heeft goed gewerkt voor het bedrijf, wat betreft de manier waarop data-eigendom en -activiteiten werden benaderd, om te voldoen aan hun technische principes, wat resulteerde in het feit dat de data mesh een effect was in plaats van een opzettelijke bedoeling. Voor andere organisaties kan de gewenste data mesh er anders uitzien en kan de aanpak andere lessen opleveren.
Tot slot, a moderne data-architectuur op AWS Hiermee kunt u op efficiënte wijze dataproducten en datamesh-infrastructuur bouwen tegen lage kosten, zonder dat dit ten koste gaat van de prestaties.
Hieronder volgen enkele voorbeelden van AWS-services die u kunt gebruiken om uw gewenste datamesh op AWS te ontwerpen:
Over de auteurs
 Claudia Chitu is een datastrateeg en een invloedrijke leider op het gebied van Analytics. Gericht op het afstemmen van data-initiatieven op de algemene strategische doelstellingen van de organisatie, gebruikt ze data als leidende kracht voor langetermijnplanning en duurzame groei.
Claudia Chitu is een datastrateeg en een invloedrijke leider op het gebied van Analytics. Gericht op het afstemmen van data-initiatieven op de algemene strategische doelstellingen van de organisatie, gebruikt ze data als leidende kracht voor langetermijnplanning en duurzame groei.
 Spyridon-dosis is een informatiebeveiligingsprofessional in Acast. Spyridon ondersteunt de organisatie bij het ontwerpen, implementeren en exploiteren van haar diensten op een veilige manier, waarbij de bedrijfs- en gebruikersgegevens worden beschermd.
Spyridon-dosis is een informatiebeveiligingsprofessional in Acast. Spyridon ondersteunt de organisatie bij het ontwerpen, implementeren en exploiteren van haar diensten op een veilige manier, waarbij de bedrijfs- en gebruikersgegevens worden beschermd.
 Srikant Das is een Acceleration Lab Solutions Architect bij Amazon Web Services. Hij heeft meer dan 13 jaar ervaring in Big Data-analyse en Data Engineering, waar hij graag betrouwbare, schaalbare en efficiënte oplossingen bouwt. Buiten zijn werk houdt hij van reizen en bloggen over zijn ervaringen op sociale media.
Srikant Das is een Acceleration Lab Solutions Architect bij Amazon Web Services. Hij heeft meer dan 13 jaar ervaring in Big Data-analyse en Data Engineering, waar hij graag betrouwbare, schaalbare en efficiënte oplossingen bouwt. Buiten zijn werk houdt hij van reizen en bloggen over zijn ervaringen op sociale media.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/design-a-data-mesh-on-aws-that-reflects-the-envisioned-organization/

