Een van de belangrijkste beslissingen die u moet nemen bij het oplossen van een data science-probleem, is welke machine learning algoritme te gebruiken.
Er zijn honderden machine learning-algoritmen om uit te kiezen, elk met zijn eigen voor- en nadelen. Sommige algoritmen werken mogelijk beter dan andere op specifieke soorten problemen of op specifieke datasets.
De "No Free Lunch" (NFL) stelling stelt dat er geen algoritme is dat het beste werkt voor elk probleem, met andere woorden, alle algoritmen hebben dezelfde prestaties wanneer hun prestaties worden gemiddeld over alle mogelijke problemen.
Verschillende machine learning-modellen
In dit artikel bespreken we de belangrijkste punten waarmee u rekening moet houden bij het kiezen van een model voor uw probleem en hoe u verschillende algoritmen voor machine learning kunt vergelijken.
De volgende lijst bevat 10 vragen die u uzelf kunt stellen bij het overwegen van een specifiek algoritme voor machine learning:
- Welk type problemen kan het algoritme oplossen? Kan het algoritme alleen regressie- of classificatieproblemen oplossen, of kan het beide oplossen? Kan het multi-class/multi-label problemen aan of alleen binaire classificatieproblemen?
- Heeft het algoritme aannames over de dataset? Sommige algoritmen gaan er bijvoorbeeld van uit dat de gegevens lineair scheidbaar zijn (bijvoorbeeld perceptron of lineaire SVM), terwijl andere ervan uitgaan dat de gegevens normaal verdeeld zijn (bijvoorbeeld Gaussiaanse mengmodellen).
- Zijn er garanties over de prestaties van het algoritme? Als het algoritme bijvoorbeeld een optimalisatieprobleem probeert op te lossen (zoals bij logistische regressie of neurale netwerken), vindt het dan gegarandeerd het globale optimum of alleen een lokaal optimum?
- Hoeveel gegevens zijn er nodig om het model effectief te trainen? Sommige algoritmen, zoals diepe neurale netwerken, zijn meer data-savvy dan andere.
- Heeft het algoritme de neiging om te overfitten? Zo ja, biedt het algoritme manieren om met overfitting om te gaan?
- Wat zijn de runtime- en geheugenvereisten van het algoritme, zowel tijdens de training als tijdens de voorspellingstijd?
- Welke stappen voor het voorbewerken van gegevens zijn nodig om de gegevens voor te bereiden op het algoritme?
- Hoeveel hyperparameters heeft het algoritme? Algoritmen met veel hyperparameters hebben meer tijd nodig om te trainen en af te stemmen.
- Kunnen de resultaten van het algoritme gemakkelijk worden geïnterpreteerd? In veel probleemdomeinen (zoals medische diagnostiek) willen we de voorspellingen van het model graag in menselijke termen kunnen verklaren. Sommige modellen kunnen gemakkelijk worden gevisualiseerd (zoals beslisbomen), terwijl andere zich meer als een zwarte doos gedragen (bijvoorbeeld neurale netwerken).
- Ondersteunt het algoritme online (incrementeel) leren, dwz kunnen we het trainen op aanvullende voorbeelden zonder het model helemaal opnieuw op te bouwen?
Laten we bijvoorbeeld twee van de meest populaire algoritmen nemen: Beslissingsbomen en neurale netwerkenen vergelijk ze volgens de bovenstaande criteria.
Beslissingsbomen
- Beslisbomen kunnen zowel classificatie- als regressieproblemen aan. Ze kunnen ook gemakkelijk problemen met meerdere klassen en meerdere labels aan.
- Beslisboomalgoritmen hebben geen specifieke aannames over de dataset.
- Een beslisboom wordt gebouwd met behulp van een hebzuchtig algoritme, dat niet gegarandeerd de optimale boom vindt (dwz de boom die het aantal tests minimaliseert dat nodig is om alle trainingsmonsters correct te classificeren). Een beslissingsboom kan echter 100% nauwkeurigheid bereiken op de trainingsset als we de knooppunten blijven uitbreiden totdat alle monsters in de bladknooppunten tot dezelfde klasse behoren. Dergelijke bomen zijn meestal geen goede voorspellers, omdat ze te veel passen bij de ruis in de trainingsset.
- Beslissingsbomen kunnen goed werken, zelfs op kleine of middelgrote datasets.
- Beslissingsbomen kunnen gemakkelijk overfitten. We kunnen overfitting echter verminderen door boomsnoei toe te passen. We kunnen ook gebruiken ensemble methodes zoals willekeurige forests die de uitvoer van meerdere beslissingsbomen combineren. Deze methoden hebben minder last van overfitting.
- Het is tijd om een beslisboom op te bouwen O(n²p), waarbij n het aantal trainingsvoorbeelden is, en p is het aantal functies. De voorspellingstijd in beslissingsbomen hangt af van de hoogte van de boom, die meestal logaritmisch is n, aangezien de meeste beslisbomen redelijk evenwichtig zijn.
- Beslisbomen vereisen geen voorverwerking van gegevens. Ze kunnen naadloos omgaan met verschillende soorten functies, waaronder numerieke en categorische functies. Ze vereisen ook geen normalisatie van de gegevens.
- Beslissingsbomen hebben verschillende belangrijke hyperparameters die moeten worden afgestemd, vooral als u snoei gebruikt, zoals de maximale diepte van de boom en welke onzuiverheidsmaat moet worden gebruikt om te beslissen hoe de knooppunten moeten worden gesplitst.
- Beslissingsbomen zijn eenvoudig te begrijpen en te interpreteren, en we kunnen ze gemakkelijk visualiseren (tenzij de boom erg groot is).
- Beslissingsbomen kunnen niet eenvoudig worden aangepast om rekening te houden met nieuwe trainingsvoorbeelden, aangezien kleine veranderingen in de dataset grote veranderingen in de topologie van de boom kunnen veroorzaken.
Neurale netwerken
- Neurale netwerken zijn een van de meest algemene en flexibele machine learning-modellen die er bestaan. Ze kunnen bijna elk type probleem oplossen, inclusief classificatie, regressie, tijdreeksanalyse, automatische contentgeneratie, enz.
- Neurale netwerken hebben geen aannames over de gegevensset, maar de gegevens moeten worden genormaliseerd.
- Neurale netwerken worden getraind met behulp van gradiëntafdaling. Ze kunnen dus alleen een lokale optimale oplossing vinden. Er zijn echter verschillende technieken die kunnen worden gebruikt om te voorkomen dat je vast komt te zitten in lokale minima, zoals momentum en adaptieve leersnelheden.
- Diepe neurale netwerken hebben veel gegevens nodig om te trainen in de orde van miljoenen monsterpunten. Over het algemeen geldt dat hoe groter het netwerk is (hoe meer lagen en neuronen het heeft), hoe meer gegevens we nodig hebben om het te trainen.
- Netwerken die te groot zijn, kunnen alle trainingsvoorbeelden onthouden en niet goed generaliseren. Voor veel problemen kun je beginnen met een klein netwerk (bijvoorbeeld met slechts één of twee verborgen lagen) en de omvang ervan geleidelijk vergroten totdat je de trainingsset begint te overbelasten. U kunt ook toevoegen regularisatie om overbelasting tegen te gaan.
- De trainingstijd van een neuraal netwerk hangt van veel factoren af (de grootte van het netwerk, het aantal gradiëntafdalingen dat nodig is om het te trainen, enz.). De voorspellingstijd is echter erg snel, omdat we maar één keer vooruit over het netwerk hoeven te gaan om het label te krijgen.
- Neurale netwerken vereisen dat alle functies numeriek en genormaliseerd zijn.
- Neurale netwerken hebben veel hyperparameters die moeten worden afgestemd, zoals het aantal lagen, het aantal neuronen in elke laag, welke activeringsfunctie moet worden gebruikt, de leersnelheid, enz.
- De voorspellingen van neurale netwerken zijn moeilijk te interpreteren omdat ze gebaseerd zijn op de berekening van een groot aantal neuronen, die elk slechts een kleine bijdrage leveren aan de uiteindelijke voorspelling.
- Neurale netwerken kunnen zich gemakkelijk aanpassen om extra trainingsvoorbeelden op te nemen, omdat ze een incrementeel leeralgoritme gebruiken (stochastische gradiëntafdaling).
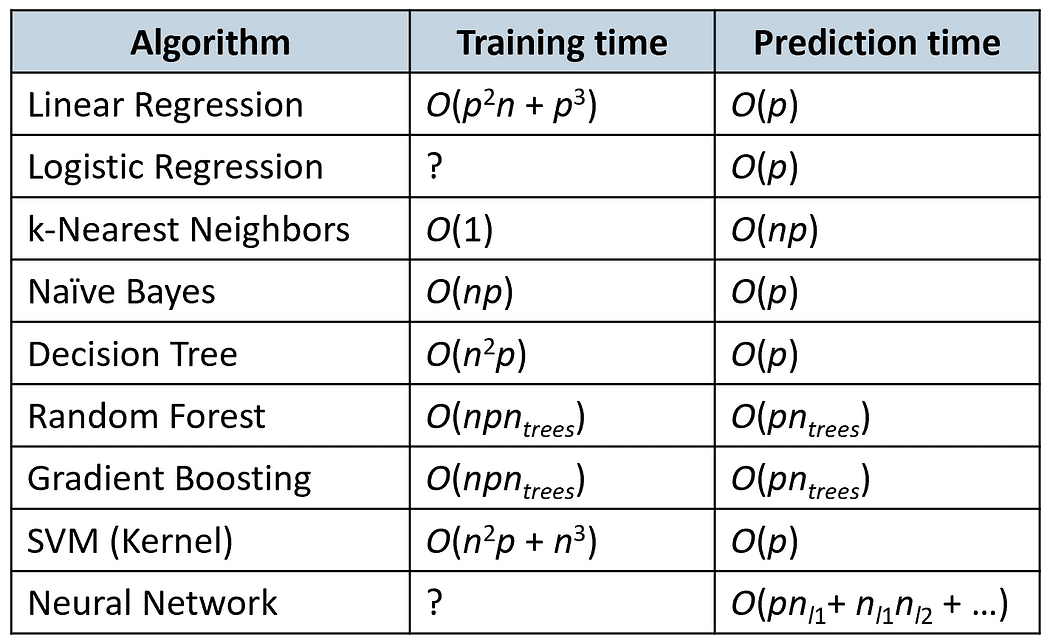
De volgende tabel vergelijkt de trainings- en voorspellingstijden van enkele populaire algoritmen (n is het aantal trainingsvoorbeelden en p is het aantal functies).
Volgens een onderzoek dat in 2016 werd uitgevoerd, waren de meest gebruikte algoritmen door winnaars van de Kaggle-wedstrijd gradiëntverhogende algoritmen (XGBoost) en neurale netwerken (zie dit artikel).
Van de 29 winnaars van de Kaggle-wedstrijd in 2015 gebruikten er 8 XGBoost, 9 gebruikten diepe neurale netwerken en 11 gebruikten een combinatie van beide.
XGBoost werd voornamelijk gebruikt bij problemen die te maken hadden met gestructureerde gegevens (bijv. relationele tabellen), terwijl neurale netwerken succesvoller waren in het omgaan met ongestructureerde problemen (bijv. problemen met beeld, stem of tekst).
Het zou interessant zijn om na te gaan of dit vandaag de dag nog steeds het geval is of dat de trends zijn veranderd (kan iemand de uitdaging aan?)
Bedankt voor het lezen!
Dr Roi Yehoshua is een onderwijsprofessor aan de Northeastern University in Boston, waar hij lessen geeft die deel uitmaken van de masteropleiding Data Science. Zijn onderzoek naar multi-robotsystemen en versterkend leren is gepubliceerd in toonaangevende tijdschriften en conferenties op het gebied van AI. Hij is ook een topschrijver op het sociale platform Medium, waar hij regelmatig artikelen publiceert over Data Science en Machine Learning.
ORIGINELE. Met toestemming opnieuw gepost.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/07/ml-algorithm-choose.html?utm_source=rss&utm_medium=rss&utm_campaign=unlock-the-secrets-to-choosing-the-perfect-machine-learning-algorithm

