Veel klanten hebben een ACID-transactie (atomisch, consistent, geïsoleerd, duurzaam) datameer nodig dat change data capture (CDC) uit operationele gegevensbronnen kan loggen. Ook is er vraag naar het samenvoegen van real-time data tot batchdata. Het Delta Lake-framework biedt deze twee mogelijkheden. In dit bericht bespreken we hoe om te gaan met UPSERT's (updates en inserts) van de operationele gegevens met behulp van native geïntegreerde Delta Lake met AWS lijm, en bevraag het Delta Lake met behulp van Amazone Athene.
We onderzoeken een hypothetische verzekeringsorganisatie die commerciële polissen uitgeeft aan kleine en middelgrote bedrijven. De verzekeringsprijzen variëren op basis van verschillende criteria, zoals waar het bedrijf zich bevindt, het type bedrijf, aardbevings- of overstromingsdekking, enzovoort. Deze organisatie is van plan een data-analytisch platform te bouwen en de verzekeringspolisgegevens zijn een van de inputs voor dit platform. Omdat het bedrijf groeit, worden er elke maand honderden en duizenden nieuwe verzekeringen afgesloten en verlengd. Daarom moeten al deze operationele gegevens in bijna realtime naar Delta Lake worden gestuurd, zodat de organisatie verschillende analyses kan uitvoeren en machine learning (ML)-modellen kan bouwen om hun klanten op een efficiëntere en kosteneffectievere manier van dienst te zijn.
Overzicht oplossingen
De gegevens kunnen afkomstig zijn uit elke bron, maar meestal willen klanten operationele gegevens naar datameren brengen om gegevensanalyses uit te voeren. Een van de oplossingen is om de relationele gegevens te brengen door te gebruiken AWS-databasemigratieservice (AWS-DMS). AWS DMS-taken kunnen worden geconfigureerd om zowel de volledige belasting als lopende wijzigingen (CDC) te kopiëren. De volledige belasting en CDC-belasting kunnen in de onbewerkte en gecureerde (Delta Lake) opslaglagen in het datameer worden gebracht. Om het simpel te houden, sluiten we in dit bericht af van de gegevensbronnen en opnamelaag; de aanname is dat de gegevens al naar de onbewerkte bucket zijn gekopieerd in de vorm van CSV-bestanden. Een AWS Glue ETL-taak voert de noodzakelijke transformatie uit en kopieert de gegevens naar de Delta Lake-laag. De Delta Lake-laag zorgt voor ACID-conformiteit van de brongegevens.
Het volgende diagram illustreert de oplossingsarchitectuur.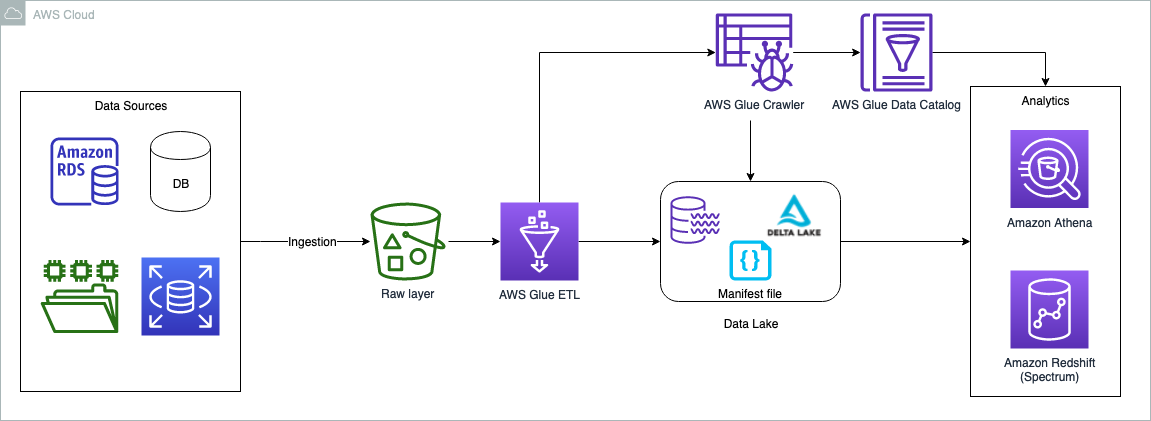
De use case die we in dit bericht gebruiken, gaat over een commerciële verzekeringsmaatschappij. We gebruiken een eenvoudige dataset die de volgende kolommen bevat:
- Beleid – Polisnummer, ingevoerd als tekst
- houdbaarheid – Datum waarop de polis afloopt
- Locatie – Type locatie (Stedelijk of Landelijk)
- Land - Naam van de staat waar het onroerend goed zich bevindt
- Regio – Geografische regio waar het onroerend goed zich bevindt
- Verzekerde waarde - Eigendoms-waarde
- Soort bedrijf – Zakelijk gebruikstype voor onroerend goed, zoals landbouw of detailhandel
- Aardbeving – Is aardbevingsdekking inbegrepen (J of N)
- Straler – Is overstromingsdekking inbegrepen (J of N)
De dataset bevat een steekproef van 25 verzekeringspolissen. In het geval van een productiedataset kan deze miljoenen records bevatten.
In de volgende secties doorlopen we de stappen om de Delta Lake UPSERT-bewerkingen uit te voeren. Wij gebruiken de AWS-beheerconsole om alle stappen uit te voeren. U kunt deze stappen echter ook automatiseren met tools zoals AWS CloudFormatie AWS Cloud-ontwikkelingskit (AWS CDK), Terraforms, enzovoort.
Voorwaarden
Deze functie is gericht op architecten, ingenieurs, ontwikkelaars en datawetenschappers die analytische oplossingen op AWS bouwen, ontwerpen en bouwen. We verwachten een basiskennis van de console, AWS Glue, Amazon eenvoudige opslagservice (Amazon S3) en Athena. Bovendien kan de persona creëren AWS Identiteits- en toegangsbeheer (IAM)-beleid en -rollen, maakt en voert AWS Glue-taken en -crawlers uit en kan werken met de Athena-query-editor.
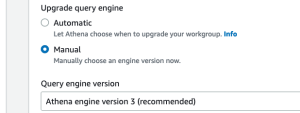
Gebruik Athena-query-engine versie 3 om delta lake-tabellen te doorzoeken, verderop in de sectie "Query the full load using Athena".
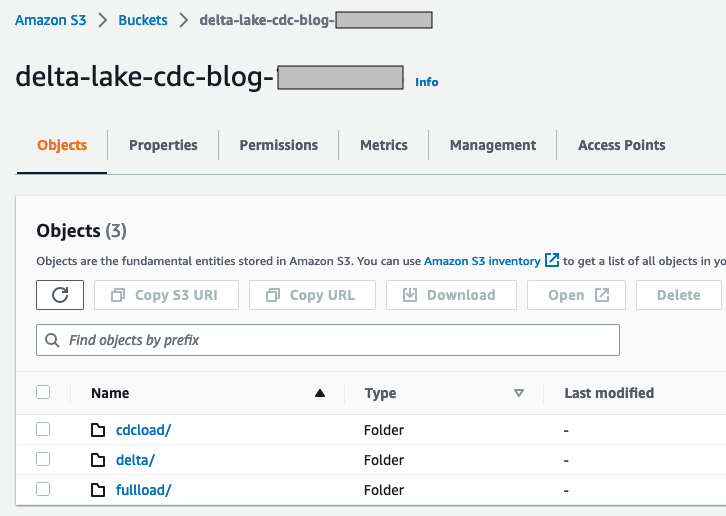
Stel een S3-bucket in voor volledige en CDC-gegevensfeeds
Voer de volgende stappen uit om uw S3-bucket in te stellen:
- Log in op uw AWS-account en kies een regio die het dichtst bij u in de buurt is.
- Maak op de Amazon S3-console een nieuwe bucket. Zorg ervoor dat de naam uniek is (bijvoorbeeld
delta-lake-cdc-blog-<some random number>). - Maak de volgende mappen aan:
- $bucket_name/volladen – Deze map wordt gebruikt voor een eenmalige volledige belasting van de stroomopwaartse gegevensbron
- $bucket_name/cdcload – Deze map wordt gebruikt voor het kopiëren van de stroomopwaartse gegevenswijzigingen
- $bucket_name/delta - Deze map bevat de gegevensbestanden van Delta Lake
- Kopieer de voorbeeldgegevensset en sla deze op in een bestand met de naam
full-load.csvnaar uw lokale machine. - Upload het bestand met behulp van de Amazon S3-console naar de map
$bucket_name/fullload.
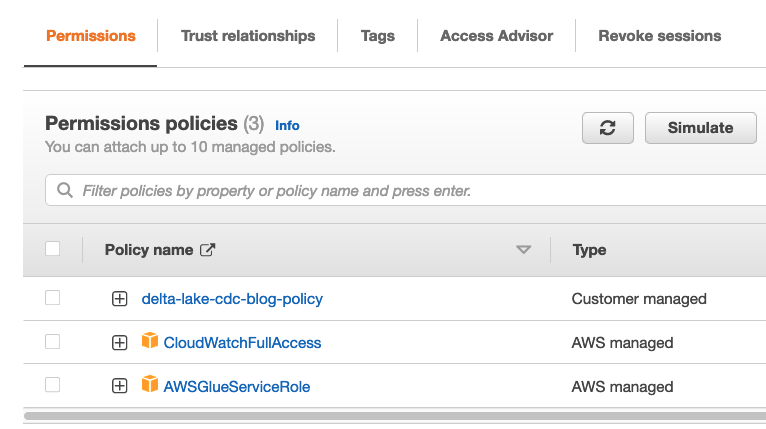
Stel een IAM-beleid en -rol in
In deze sectie maken we een IAM-beleid voor de toegang tot de S3-bucket en een rol voor het uitvoeren van AWS Glue-taken, en gebruiken we dezelfde rol ook voor het opvragen van het Delta Lake met behulp van Athena.
- Kies op de IAM-console Beleid in het navigatievenster.
- Kies Maak beleid.
- kies JSON tab en plak de volgende beleidscode. Vervang de
{bucket_name}die u in de eerdere stap hebt gemaakt.
- Geef het beleid een naam
delta-lake-cdc-blog-policyen selecteer Maak beleid. - Kies op de IAM-console rollen in het navigatievenster.
- Kies Rol creëren.
- Selecteer AWS Glue als uw vertrouwde entiteit en kies Volgende.
- Selecteer het beleid dat u zojuist hebt gemaakt en met twee extra door AWS beheerde beleidsregels:
delta-lake-cdc-blog-policyAWSGlueServiceRoleCloudWatchFullAccess
- Kies Volgende.
- Geef de rol een naam (bijvoorbeeld
delta-lake-cdc-blog-role).
Stel AWS Glue-taken in
In deze sectie hebben we twee AWS Glue-taken ingesteld: een voor volledige belasting en een voor de CDC-belasting. Laten we beginnen met de taak met volledige lading.
- Op de AWS Glue-console, onder Gegevensintegratie en ETL in het navigatievenster, kies Vacatures. AWS Glue Studio wordt geopend in een nieuw tabblad.
- kies Spark-scripteditor En kies creëren.
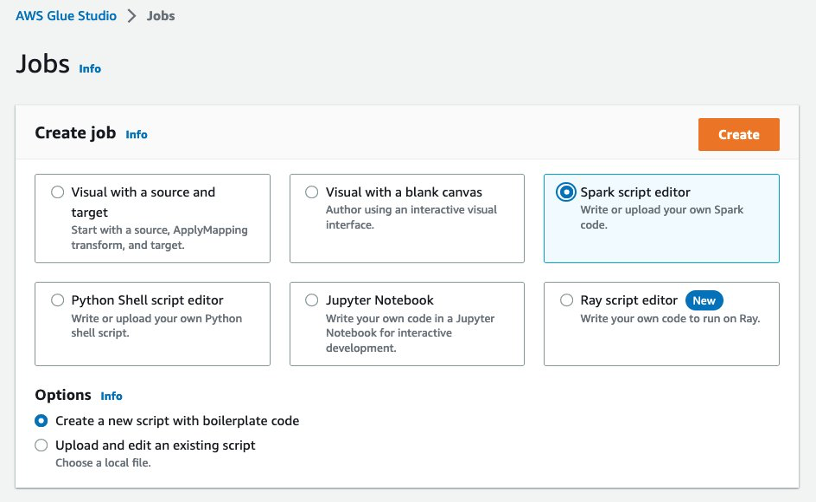
- Vervang de code in de scripteditor door het volgende codefragment
- Navigeer naar de Details van de baan Tab.
- Geef een naam op voor de taak (bijvoorbeeld
Full-Load-Job). - Voor IAM-rol¸ kies de rol
delta-lake-cdc-blog-roledie u eerder hebt gemaakt. - Voor Type werknemerKiezen G 2X.
- Voor Job bladwijzer, kiezen onbruikbaar maken.
- Zet de Aantal nieuwe pogingen om 0.
- Onder Geavanceerde eigenschappen¸ behoud de standaardwaarden, maar geef het delta core JAR-bestandspad op Pad naar Python-bibliotheek en Afhankelijk JAR-pad.
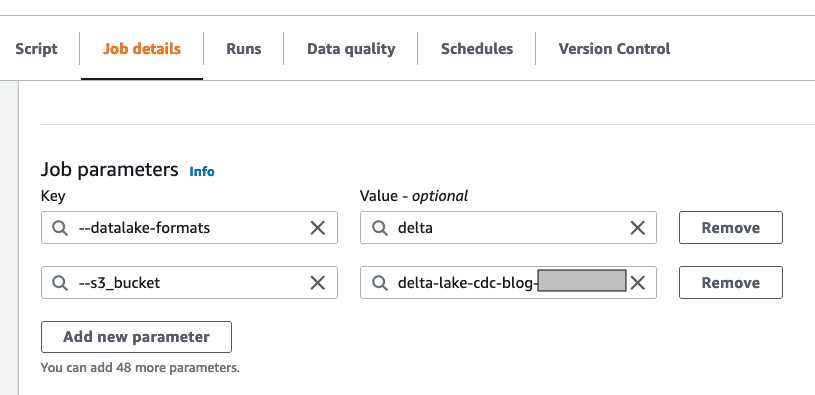
- Onder Taakparameters:
- Voeg de sleutel toe
--s3_bucketmet de eerder gemaakte bucketnaam als waarde. - Voeg de sleutel toe
--datalake-formatsen geef de waardedelta
- Voeg de sleutel toe
- Behoud de resterende standaardwaarden en kies Bespaar.
Laten we nu de CDC-laadtaak maken.
- Maak een tweede taak genaamd
CDC-Load-Job. - Volg de stappen op de Details van de baan tabblad zoals bij de vorige taak.
- Als alternatief kunt u de optie "Clone job" kiezen uit de Full-Load-Job, dit zal alle jobdetails van de full-load job bevatten.
- Voer in de scripteditor het volgende codefragment in voor de CDC-logica:
import sys
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from pyspark.sql.session import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.functions import expr ## For Delta lake
from delta.tables import DeltaTable ## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME','s3_bucket']) # Initialize Spark Session with Delta Lake
spark = SparkSession .builder .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") .getOrCreate() # Read the CDC load
cdc_df = spark.read.csv("s3://"+ args['s3_bucket']+"/cdcload")
cdc_df.show(5,True) # now read the full load (latest data) as delta table
delta_df = DeltaTable.forPath(spark, "s3://"+ args['s3_bucket']+"/delta/insurance/")
delta_df.toDF().show(5,True) # UPSERT process if matches on the condition the update else insert
# if there is no keyword then create a data set with Insert, Update and Delete flag and do it separately.
# for delete it has to run in loop with delete condition, this script do not handle deletes. final_df = delta_df.alias("prev_df").merge( source = cdc_df.alias("append_df"), #matching on primarykey
condition = expr("prev_df.policy_id = append_df._c1"))
.whenMatchedUpdate(set= { "prev_df.expiry_date" : col("append_df._c2"), "prev_df.location_name" : col("append_df._c3"), "prev_df.state_code" : col("append_df._c4"), "prev_df.region_name" : col("append_df._c5"), "prev_df.insured_value" : col("append_df._c6"), "prev_df.business_type" : col("append_df._c7"), "prev_df.earthquake_coverage" : col("append_df._c8"), "prev_df.flood_coverage" : col("append_df._c9")} )
.whenNotMatchedInsert(values =
#inserting a new row to Delta table
{ "prev_df.policy_id" : col("append_df._c1"), "prev_df.expiry_date" : col("append_df._c2"), "prev_df.location_name" : col("append_df._c3"), "prev_df.state_code" : col("append_df._c4"), "prev_df.region_name" : col("append_df._c5"), "prev_df.insured_value" : col("append_df._c6"), "prev_df.business_type" : col("append_df._c7"), "prev_df.earthquake_coverage" : col("append_df._c8"), "prev_df.flood_coverage" : col("append_df._c9")
})
.execute()
Voer de volledige laadtaak uit
Open op de AWS Glue-console full-load-job En kies lopen. Het duurt ongeveer 2 minuten om de taak te voltooien en de uitvoeringsstatus van de taak verandert in Langs. Ga naar $bucket_name en open de delta map, die de verzekeringsmap bevat. U kunt de Delta Lake-bestanden erin noteren. 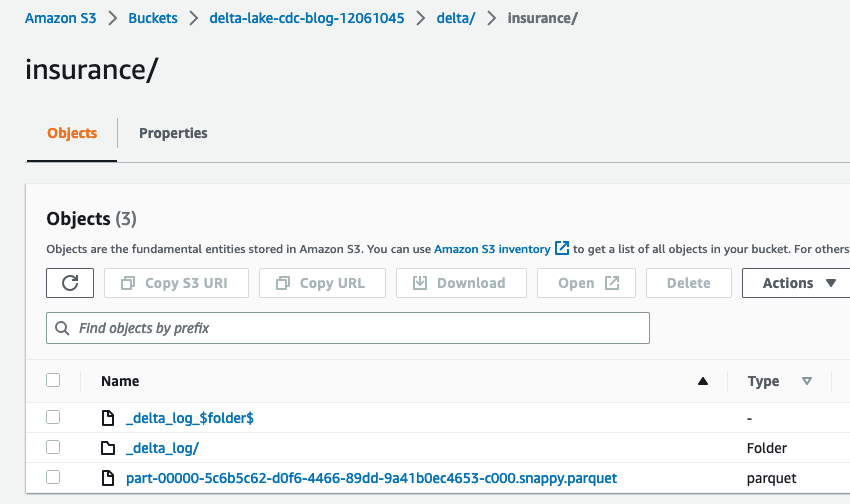
Maak en voer de AWS Glue-crawler uit
In deze stap maken we een AWS Glue-crawler met Delta Lake als gegevensbrontype. Nadat de crawler succesvol is uitgevoerd, inspecteren we de gegevens met behulp van Athena.
- Kies op de AWS Glue-console: crawlers in het navigatievenster.
- Kies Creëren van crawler.
- Geef een naam op (bijvoorbeeld
delta-lake-crawler) en kies Volgende. - Kies Een gegevensbron toevoegen En kies Delta meer als uw gegevensbron.
- Kopieer de URI van uw deltamap (bijvoorbeeld
s3://delta-lake-cdc-blog-123456789/delta/insurance) en voer de locatie van het Delta Lake-tabelpad in. - Behoud de standaardselectie Native tabellen makenen kies Een Delta Lake-gegevensbron toevoegen.
- Kies Volgende.
- Kies de IAM-rol die u eerder hebt gemaakt en kies vervolgens Volgende.
- Selecteer het
defaultdoeldatabase en biedendelta_voor het voorvoegsel van de tabelnaam. Als Needefaultdatabase bestaat, kunt u er een maken. - Kies Volgende.
- Kies Creëren van crawler.
- Voer de nieuw gemaakte crawler uit. Nadat de crawler is voltooid, wordt het
delta_insurancetafel is beschikbaar onderDatabases/Tables. - Open de tafel om het tafeloverzicht te bekijken.
U kunt negen kolommen en hun gegevenstypen observeren. 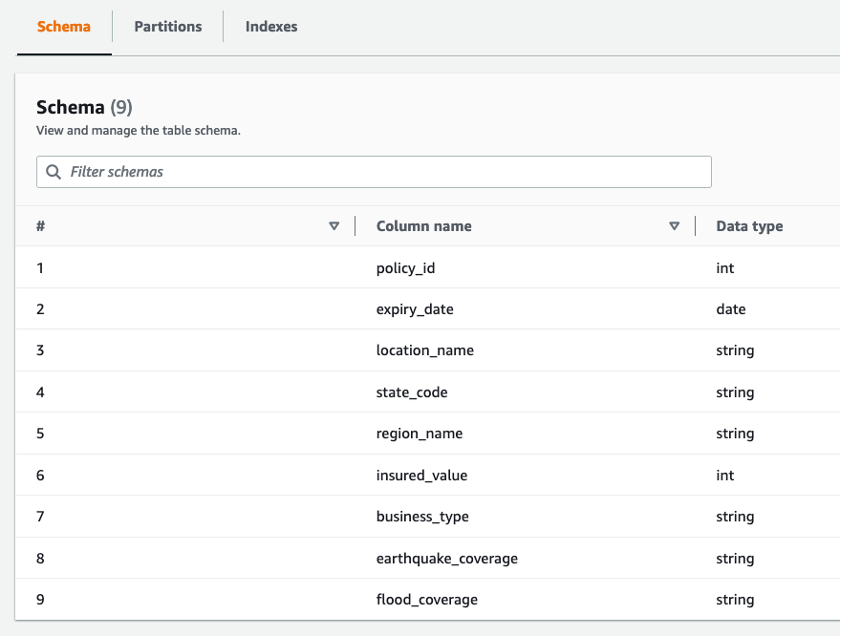
Vraag de volledige belasting op met behulp van Athena
In de eerdere stap hebben we de delta_insurance tabel door een crawler uit te voeren tegen de Delta Lake-locatie. In deze sectie vragen we de delta_insurance tafel met Athena. Houd er rekening mee dat als u Athena voor het eerst gebruikt, u de query-uitvoermap instelt om de Athena-queryresultaten op te slaan (bijvoorbeeld s3://<your-s3-bucket>/query-output/).
- Open de query-editor op de Athena-console.
- Behoud de standaardselecties voor Gegevensbron en Database.
- Voer de query uit
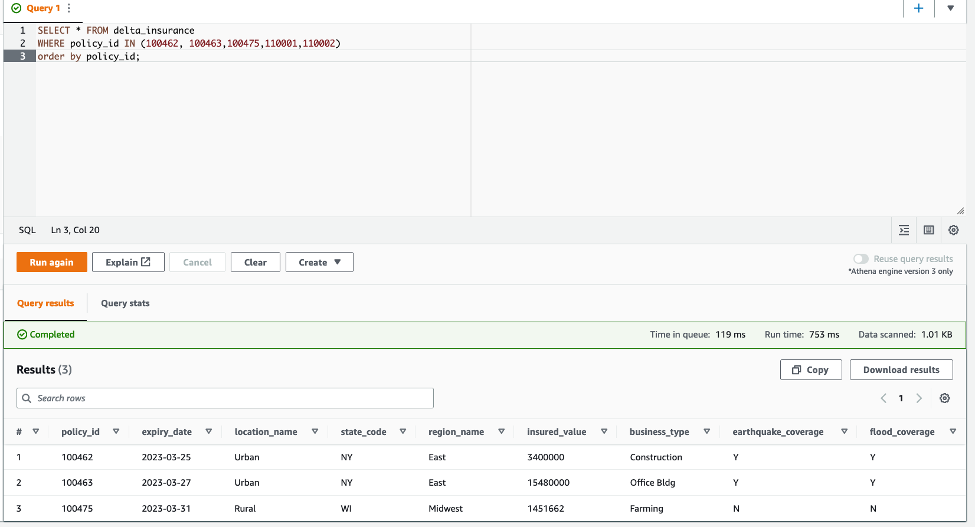
SELECT * FROM delta_insurance;. Deze query retourneert in totaal 25 rijen, hetzelfde als in de volledige gegevensfeed. - Voer voor de CDC-vergelijking de volgende query uit en sla de resultaten op een locatie op waar u deze resultaten later kunt vergelijken:
De volgende schermafbeelding toont het resultaat van de Athena-query.
Upload de CDC-datafeed en voer de CDC-taak uit
In deze rubriek actualiseren we drie verzekeringspolissen en voegen we twee nieuwe polissen in.
- Kopieer de volgende verzekeringspolisgegevens en sla deze lokaal op als
cdc-load.csv:
De eerste kolom in de CDC-feed beschrijft de UPSERT-bewerkingen. U is voor het bijwerken van een bestaand record, en I is voor het invoegen van een nieuw record.
- Upload het bestand cdc-load.csv naar het
$bucket_name/cdcload/map. - Voer op de AWS Glue-console uit
CDC-Load-Job. Deze baan zorgt ervoor dat het Deltameer dienovereenkomstig wordt bijgewerkt.
De wijzigingsgegevens zijn als volgt:
- 100462 – Vervaldatum verandert naar 12-31-2024
- 100463 – Verzekerde waarde wijzigt naar 1 miljoen
- 100475 – Dit beleid valt nu onder een nieuw overstromingsgebied
- 110001 en 110002 - Nieuw beleid toegevoegd aan de tabel
- Voer de query opnieuw uit:
Zoals te zien is in de volgende schermafbeelding, worden de wijzigingen in de CDC-datafeed weergegeven in de Athena-queryresultaten.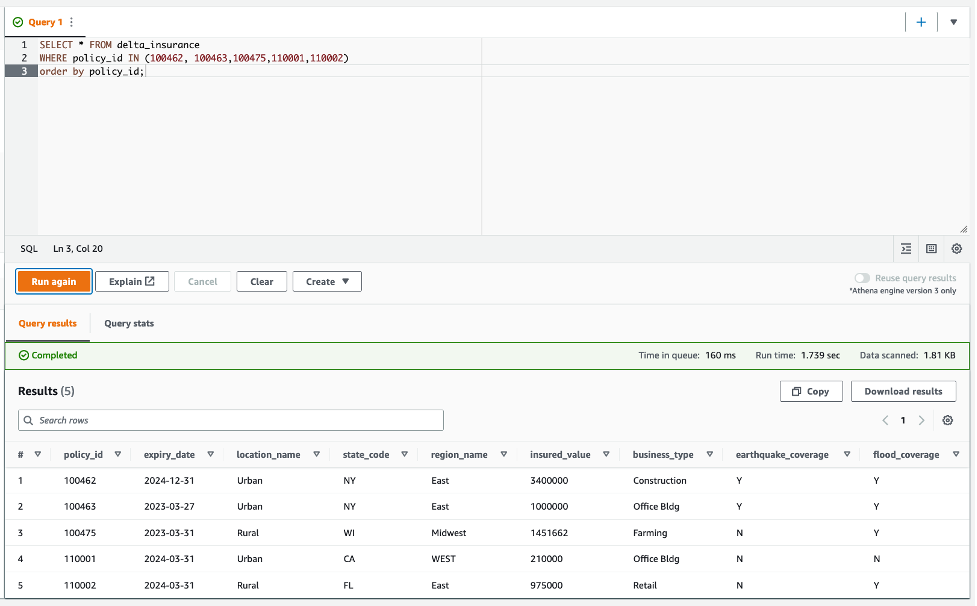
Opruimen
In deze oplossing hebben we alle beheerde services gebruikt en er zijn geen kosten als AWS Glue-taken niet worden uitgevoerd. Als u de taken echter wilt opschonen, kunt u de twee AWS Glue-taken, de AWS Glue-tabel en de S3-bucket verwijderen.
Conclusie
Organisaties zijn voortdurend op zoek naar hoogwaardige, kosteneffectieve en schaalbare analytische oplossingen om de waarde van hun operationele gegevensbronnen in bijna realtime te extraheren. Het analytische platform moet klaar zijn om wijzigingen in de operationele gegevens te ontvangen zodra deze zich voordoen. Typische data lake-oplossingen worden geconfronteerd met uitdagingen om de veranderingen in brongegevens aan te kunnen; het Delta Lake-raamwerk kan deze kloof dichten. Dit bericht liet zien hoe je datalakes bouwt voor UPSERT-bewerkingen met behulp van AWS Glue en native Delta Lake-tabellen, en hoe je AWS Glue-tabellen opvraagt vanuit Athena. U kunt uw grootschalige UPSERT-gegevensbewerkingen implementeren met AWS Glue, Delta Lake en analyses uitvoeren met Amazon Athena.
Referenties
Over de auteurs
 Praveen Allam is een oplossingsarchitect bij AWS. Hij helpt klanten bij het ontwerpen van schaalbare, voordeligere enterprise-grade applicaties met behulp van de AWS Cloud. Hij bouwt oplossingen om organisaties te helpen datagedreven beslissingen te nemen.
Praveen Allam is een oplossingsarchitect bij AWS. Hij helpt klanten bij het ontwerpen van schaalbare, voordeligere enterprise-grade applicaties met behulp van de AWS Cloud. Hij bouwt oplossingen om organisaties te helpen datagedreven beslissingen te nemen.
 Vivek Singh is Senior Solutions Architect bij het AWS Data Lab-team. Hij helpt klanten hun datareis op het AWS-ecosysteem te deblokkeren. Zijn interessegebieden zijn datapijplijnautomatisering, datakwaliteit en databeheer, datalakes en lakehouse-architecturen.
Vivek Singh is Senior Solutions Architect bij het AWS Data Lab-team. Hij helpt klanten hun datareis op het AWS-ecosysteem te deblokkeren. Zijn interessegebieden zijn datapijplijnautomatisering, datakwaliteit en databeheer, datalakes en lakehouse-architecturen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/handle-upsert-data-operations-using-open-source-delta-lake-and-aws-glue/

