
Introductie
Welkom bij onze uitgebreide gegevensanalyse blog die diep in de wereld van Netflix duikt. Als een van de toonaangevende streamingplatforms ter wereld heeft Netflix een revolutie teweeggebracht in de manier waarop we entertainment consumeren. Met zijn enorme bibliotheek met films en tv-programma's biedt het een overvloed aan keuzes voor kijkers over de hele wereld.
Het wereldwijde bereik van Netflix
Netflix heeft een opmerkelijke groei doorgemaakt en zijn aanwezigheid uitgebreid tot een dominante kracht in de streaming-industrie. Hier zijn enkele opmerkelijke statistieken die de wereldwijde impact ervan aantonen:
- Gebruikersbasis: Aan het begin van het tweede kwartaal van 2022 had Netflix ongeveer vergaard 222 miljoen internationale abonnees, verspreid over meer dan 190 landen (exclusief China, de Krim, Noord-Korea, Rusland en Syrië). Deze indrukwekkende cijfers onderstrepen de brede acceptatie en populariteit van het platform onder kijkers over de hele wereld.
- Internationale uitbreiding: Met zijn beschikbaarheid in meer dan 190 landen heeft Netflix met succes een wereldwijde aanwezigheid opgebouwd. Het bedrijf heeft aanzienlijke inspanningen geleverd om zijn inhoud te lokaliseren door ondertiteling en nasynchronisatie in verschillende talen aan te bieden, waardoor de toegankelijkheid voor een divers publiek wordt gegarandeerd.
In deze blog gaan we op een spannende reis om de intrigerende patronen, trends en inzichten te verkennen die verborgen zijn in het contentlandschap van Netflix. Maak gebruik van de kracht van Python en gegevensanalyse bibliotheken, duiken we in de uitgebreide collectie van het aanbod van Netflix om waardevolle informatie te ontdekken die licht werpt op inhoudtoevoegingen, duurverdelingen, genre-correlaties en zelfs de meest gebruikte woorden in titels en beschrijvingen.
Via gedetailleerde codefragmenten en visualisaties, pellen we de lagen van het content-ecosysteem van Netflix af om een nieuw perspectief te bieden op hoe het platform is geëvolueerd. Door releasepatronen, seizoenstrends en publieksvoorkeuren te analyseren, proberen we de inhoudsdynamiek binnen het enorme universum van Netflix beter te begrijpen.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Data voorbereiding
De gegevens die in deze casestudy worden gebruikt, zijn afkomstig van Kaggle, een populair platform voor liefhebbers van datawetenschap en machine learning. De dataset, getiteld “Netflix-films en tv-programma's”, is openbaar beschikbaar op Kaggle en biedt waardevolle informatie over de films en tv-programma's op het Netflix-streamingplatform.
De dataset bestaat uit een tabelindeling met verschillende kolommen die de verschillende aspecten van elke film of tv-show beschrijven. Hier is een tabel met een samenvatting van de kolommen en hun beschrijvingen:
| Kolomnaam | Omschrijving |
|---|---|
| show_id | Unieke ID voor elke film / tv-show |
| type dan: | Identifier - Een film of tv-programma |
| titel | Titel van de film/tv-show |
| directeur | Regisseur van de film |
| gegoten | Acteurs betrokken bij de film/show |
| Land | Land waar de film/show is geproduceerd |
| Datum toegevoegd | Datum waarop het op Netflix is toegevoegd |
| jaar van uitgave | Werkelijk releasejaar van de film / show |
| waardering | TV-classificatie van de film / show |
| duur | Totale duur - in minuten of aantal seizoenen |
In deze sectie zullen we gegevensvoorbereidingstaken uitvoeren op de Netflix-dataset om ervoor te zorgen dat deze schoon en geschikt is voor analyse. We behandelen ontbrekende waarden en duplicaten en voeren indien nodig conversies van gegevenstypen uit. Laten we in de code duiken en elke stap verkennen.
Bibliotheken importeren
Om te beginnen importeren we de benodigde bibliotheken voor data-analyse en visualisatie. Deze bibliotheken omvatten panda's, numpy en matplotlib. pyplot en seaborn. Ze bieden essentiële functies en hulpmiddelen om de gegevens effectief te manipuleren en te visualiseren.
# Importing necessary libraries for data analysis and visualization
import pandas as pd # pandas for data manipulation and analysis
import numpy as np # numpy for numerical operations
import matplotlib.pyplot as plt # matplotlib for data visualization
import seaborn as sns # seaborn for enhanced data visualizationDe gegevensset laden
Vervolgens laden we de Netflix-dataset met behulp van de functie pd.read_csv(). De dataset wordt opgeslagen in het bestand 'netflix.csv'. Laten we eens kijken naar de eerste vijf records van de dataset om de structuur ervan te begrijpen.
# Loading the dataset from a CSV file
df = pd.read_csv('netflix.csv') # Displaying the first few rows of the dataset
df.head()Beschrijvende statistieken
Het is cruciaal om de algemene kenmerken van de dataset te begrijpen beschrijvende statistieken. We kunnen inzicht krijgen in de numerieke attributen zoals aantal, gemiddelde, standaarddeviatie, minimum, maximum en kwartielen.
# Computing descriptive statistics for the dataset
df.describe()Beknopte samenvatting
Om een beknopte samenvatting van de dataset te krijgen, gebruiken we de functie df.info(). Het biedt informatie over het aantal niet-null-waarden en de gegevenstypen van elke kolom. Deze samenvatting helpt bij het identificeren van ontbrekende waarden en mogelijke problemen met gegevenstypen.
# Obtaining information about the dataset
df.info()Omgaan met ontbrekende waarden
Ontbrekende waarden kunnen nauwkeurige analyse in de weg staan. Deze dataset verkent de ontbrekende waarden in elke kolom met behulp van df. isnull().sum(). We streven ernaar de kolommen met ontbrekende waarden te identificeren en het percentage ontbrekende gegevens in elke kolom te bepalen.
# Checking for missing values in the dataset
df.isnull().sum()Om met ontbrekende waarden om te gaan, gebruiken we verschillende strategieën voor verschillende kolommen. Laten we elke stap doornemen:
duplicaten
Duplicaten kunnen analyseresultaten vervormen, dus het is essentieel om ze aan te pakken. We identificeren en verwijderen dubbele records met behulp van df.duplicate().sum().
# Checking for duplicate rows in the dataset
df.duplicated().sum()Omgaan met ontbrekende waarden in specifieke kolommen
Voor de kolommen 'regisseur' en 'cast' vervangen we ontbrekende waarden door 'Geen gegevens' om de gegevensintegriteit te behouden en vertekening in de analyse te voorkomen.
# Replacing missing values in the 'director' column with 'No Data'
df['director'].replace(np.nan, 'No Data', inplace=True) # Replacing missing values in the 'cast' column with 'No Data'
df['cast'].replace(np.nan, 'No Data', inplace=True)In de kolom 'land' vullen we ontbrekende waarden in met de modus (meest voorkomende waarde) om consistentie te garanderen en gegevensverlies te minimaliseren.
# Filling missing values in the 'country' column with the mode value
df['country'] = df['country'].fillna(df['country'].mode()[0])Voor de kolom 'rating' vullen we ontbrekende waarden in op basis van het 'type' van de show. We kennen de 'classificatie'-modus toe aan films en tv-programma's afzonderlijk.
# Finding the mode rating for movies and TV shows
movie_rating = df.loc[df['type'] == 'Movie', 'rating'].mode()[0]
tv_rating = df.loc[df['type'] == 'TV Show', 'rating'].mode()[0] # Filling missing rating values based on the type of content
df['rating'] = df.apply(lambda x: movie_rating if x['type'] == 'Movie' and pd.isna(x['rating']) else tv_rating if x['type'] == 'TV Show' and pd.isna(x['rating']) else x['rating'], axis=1)Voor de kolom 'duur' vullen we ontbrekende waarden in op basis van het 'type' van de show. We wijzen de modus 'duur' afzonderlijk toe aan films en tv-programma's.
# Finding the mode duration for movies and TV shows
movie_duration_mode = df.loc[df['type'] == 'Movie', 'duration'].mode()[0]
tv_duration_mode = df.loc[df['type'] == 'TV Show', 'duration'].mode()[0] # Filling missing duration values based on the type of content
df['duration'] = df.apply(lambda x: movie_duration_mode if x['type'] == 'Movie' and pd.isna(x['duration']) else tv_duration_mode if x['type'] == 'TV Show' and pd.isna(x['duration']) else x['duration'], axis=1)Resterende ontbrekende waarden laten vallen
Na het afhandelen van ontbrekende waarden in specifieke kolommen, laten we alle resterende rijen met ontbrekende waarden vallen om te zorgen voor een schone dataset voor analyse.
# Dropping rows with missing values
df.dropna(inplace=True)Datum afhandeling
We converteren de kolom 'date_added' naar datetime-indeling met behulp van pd.to_datetime() om verdere analyse mogelijk te maken op basis van datumgerelateerde attributen.
# Converting the 'date_added' column to datetime format
df["date_added"] = pd.to_datetime(df['date_added'])Aanvullende gegevenstransformaties
We halen aanvullende attributen uit de kolom 'date_added' om onze analysemogelijkheden te verbeteren. We verwijderen de maand- en jaarwaarden om trends te analyseren op basis van deze tijdsaspecten.
# Extracting month, month name, and year from the 'date_added' column
df['month_added'] = df['date_added'].dt.month
df['month_name_added'] = df['date_added'].dt.month_name()
df['year_added'] = df['date_added'].dt.yearGegevenstransformatie: Cast, Country, Listed In en Director
Om categorische attributen effectiever te analyseren, transformeren we ze in afzonderlijke dataframes, waardoor ze op een meer ontspannen manier kunnen worden verkend en geanalyseerd.
Voor de kolommen 'cast', 'country', 'listed_in' en 'director' hebben we de waarden gesplitst op basis van het kommascheidingsteken en afzonderlijke rijen gemaakt voor elke waarde. Deze transformatie stelt ons in staat om de gegevens op een meer gedetailleerd niveau te analyseren.
# Splitting and expanding the 'cast' column
df_cast = df['cast'].str.split(',', expand=True).stack()
df_cast = df_cast.reset_index(level=1, drop=True).to_frame('cast')
df_cast['show_id'] = df['show_id'] # Splitting and expanding the 'country' column
df_country = df['country'].str.split(',', expand=True).stack()
df_country = df_country.reset_index(level=1, drop=True).to_frame('country')
df_country['show_id'] = df['show_id'] # Splitting and expanding the 'listed_in' column
df_listed_in = df['listed_in'].str.split(',', expand=True).stack()
df_listed_in = df_listed_in.reset_index(level=1, drop=True).to_frame('listed_in')
df_listed_in['show_id'] = df['show_id'] # Splitting and expanding the 'director' column
df_director = df['director'].str.split(',', expand=True).stack()
df_director = df_director.reset_index(level=1, drop=True).to_frame('director')
df_director['show_id'] = df['show_id']Na het voltooien van deze stappen voor gegevensvoorbereiding hebben we een schone en getransformeerde dataset klaar voor verdere analyse. Deze initiële gegevensmanipulaties vormden de basis voor het verkennen van de Netflix-dataset en het blootleggen van inzichten in de datagestuurde strategieën van het streamingplatform.
Verkennende gegevensanalyse
Distributie van inhoudstypen
Om de distributie van inhoud in de Netflix-bibliotheek te bepalen, kunnen we de procentuele distributie van inhoudstypen (films en tv-programma's) berekenen met behulp van de volgende code:
# Calculate the percentage distribution of content types
x = df.groupby(['type'])['type'].count()
y = len(df)
r = ((x/y) * 100).round(2) # Create a DataFrame to store the percentage distribution
mf_ratio = pd.DataFrame(r)
mf_ratio.rename({'type': '%'}, axis=1, inplace=True) # Plot the 3D-effect pie chart
plt.figure(figsize=(12, 8))
colors = ['#b20710', '#221f1f']
explode = (0.1, 0)
plt.pie(mf_ratio['%'], labels=mf_ratio.index, autopct='%1.1f%%', colors=colors, explode=explode, shadow=True, startangle=90, textprops={'color': 'white'}) plt.legend(loc='upper right')
plt.title('Distribution of Content Types')
plt.show()
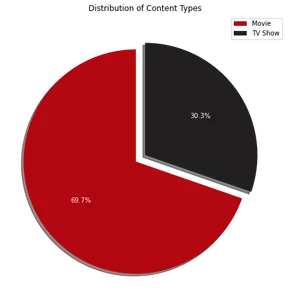
De cirkeldiagramvisualisatie laat zien dat ongeveer 70% van de inhoud op Netflix uit film bestaat, terwijl de overige 30% uit tv-programma's bestaat. Om vervolgens de top 10 landen te identificeren waar Netflix populair is, kunnen we de volgende code gebruiken:
Top 10 landen waar Netflix populair is
Om vervolgens de top 10 landen te identificeren waar Netflix populair is, kunnen we de volgende code gebruiken:
# Remove white spaces from 'country' column
df_country['country'] = df_country['country'].str.rstrip() # Find value counts
country_counts = df_country['country'].value_counts() # Select the top 10 countries
top_10_countries = country_counts.head(10) # Plot the top 10 countries
plt.figure(figsize=(16, 10))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_countries) - 1)
bar_plot = sns.barplot(x=top_10_countries.index, y=top_10_countries.values, palette=colors) plt.xlabel('Country')
plt.ylabel('Number of Titles')
plt.title('Top 10 Countries Where Netflix is Popular') # Add count values on top of each bar
for index, value in enumerate(top_10_countries.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()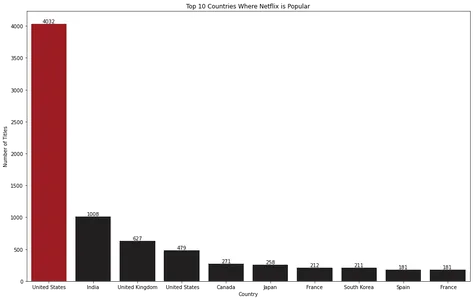
De visualisatie van het staafdiagram laat zien dat de Verenigde Staten het topland is waar Netflix populair is.
Top 10 acteurs op basis van het aantal films/tv-shows
Om de top 10 acteurs met het hoogste aantal optredens in films en tv-shows te identificeren, kunt u de volgende code gebruiken:
# Count the occurrences of each actor
cast_counts = df_cast['cast'].value_counts()[1:] # Select the top 10 actors
top_10_cast = cast_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_cast) - 1)
bar_plot = sns.barplot(x=top_10_cast.index, y=top_10_cast.values, palette=colors) plt.xlabel('Actor')
plt.ylabel('Number of Appearances')
plt.title('Top 10 Actors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_cast.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()
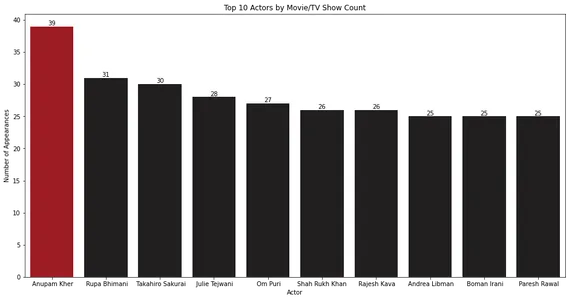
Het staafdiagram laat zien dat Anupam Kher het meest voorkomt in films en tv-shows.
Top 10 regisseurs op basis van het aantal films/tv-shows
Om de top 10 regisseurs te identificeren die het grootste aantal films of tv-shows hebben geregisseerd, kun je de volgende code gebruiken:
# Count the occurrences of each actor
director_counts = df_director['director'].value_counts()[1:] # Select the top 10 actors
top_10_directors = director_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_directors) - 1)
bar_plot = sns.barplot(x=top_10_directors.index, y=top_10_directors.values, palette=colors) plt.xlabel('Director')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Directors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_directors.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()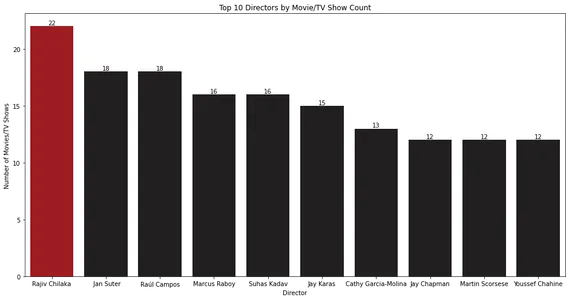
Het staafdiagram toont de top 10 regisseurs met de meeste films of tv-programma's. Rajiv Chilaka lijkt de meeste content in de Netflix-bibliotheek te hebben geregisseerd.
Top 10 categorieën op aantal films/tv-programma's
Om de distributie van inhoud in verschillende categorieën te analyseren, kunt u de volgende code gebruiken:
df_listed_in['listed_in'] = df_listed_in['listed_in'].str.strip() # Count the occurrences of each actor
listed_in_counts = df_listed_in['listed_in'].value_counts() # Select the top 10 actors
top_10_listed_in = listed_in_counts.head(10) plt.figure(figsize=(12, 8))
bar_plot = sns.barplot(x=top_10_listed_in.index, y=top_10_listed_in.values, palette=colors) # Customize the plot
plt.xlabel('Category')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Categories by Movie/TV Show Count')
plt.xticks(rotation=45) # Add count values on top of each bar
for index, value in enumerate(top_10_listed_in.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Show the plot
plt.show()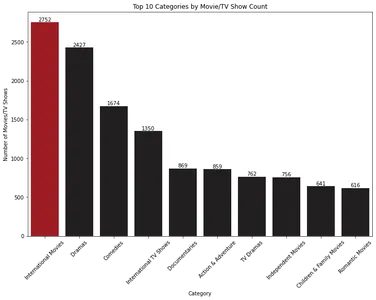
Het staafdiagram toont de top 10 categorieën van films en tv-programma's op basis van hun aantal. 'Internationale films' is de meest dominante categorie, gevolgd door 'Drama's'.
Films en tv-programma's in de loop van de tijd toegevoegd
Om de toevoeging van films en tv-programma's in de loop van de tijd te analyseren, kunt u de volgende code gebruiken:
# Filter the DataFrame to include only Movies and TV Shows
df_movies = df[df['type'] == 'Movie']
df_tv_shows = df[df['type'] == 'TV Show'] # Group the data by year and count the number of Movies and TV Shows # added in each year
movies_count = df_movies['year_added'].value_counts().sort_index()
tv_shows_count = df_tv_shows['year_added'].value_counts().sort_index() # Create a line chart to visualize the trends over time
plt.figure(figsize=(16, 8))
plt.plot(movies_count.index, movies_count.values, color='#b20710', label='Movies', linewidth=2)
plt.plot(tv_shows_count.index, tv_shows_count.values, color='#221f1f', label='TV Shows', linewidth=2) # Fill the area under the line charts
plt.fill_between(movies_count.index, movies_count.values, color='#b20710')
plt.fill_between(tv_shows_count.index, tv_shows_count.values, color='#221f1f') # Customize the plot
plt.xlabel('Year')
plt.ylabel('Count')
plt.title('Movies & TV Shows Added Over Time')
plt.legend() # Show the plot
plt.show()
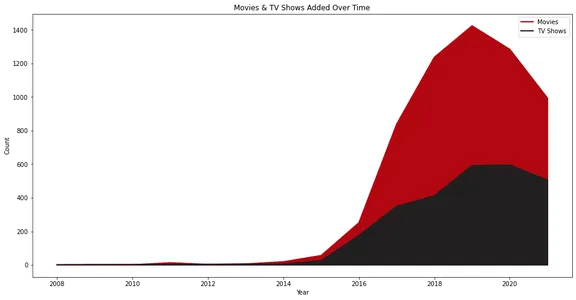
Het lijndiagram illustreert het aantal films en tv-programma's dat in de loop van de tijd aan Netflix is toegevoegd. Het geeft visueel de groei en trends in contenttoevoegingen weer, met aparte regels voor films en tv-shows.
Netflix zag zijn echte groei vanaf het jaar 2015, en we kunnen zien dat het in de loop der jaren meer films dan tv-programma's heeft toegevoegd.
Het is ook interessant dat de toevoeging van inhoud in 2020 is gedaald. Dit kan te wijten zijn aan de pandemische situatie.
Vervolgens onderzoeken we de verdeling van contenttoevoegingen over verschillende maanden. Deze analyse helpt ons patronen te identificeren en te begrijpen wanneer Netflix nieuwe inhoud introduceert.
Inhoud toegevoegd per maand
Om dit te onderzoeken, extraheren we de maand uit de kolom 'date_added' en tellen we het aantal keren dat elke maand voorkomt. Door deze gegevens als een staafdiagram te visualiseren, kunnen we snel de maanden identificeren met de hoogste inhoudstoevoegingen.
# Extract the month from the 'date_added' column
df['month_added'] = pd.to_datetime(df['date_added']).dt.month_name() # Define the order of the months
month_order = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'] # Count the number of shows added in each month
monthly_counts = df['month_added'].value_counts().loc[month_order] # Determine the maximum count
max_count = monthly_counts.max() # Set the color for the highest bar and the rest of the bars
colors = ['#b20710' if count == max_count else '#221f1f' for count in monthly_counts] # Create the bar chart
plt.figure(figsize=(16, 8))
bar_plot = sns.barplot(x=monthly_counts.index, y=monthly_counts.values, palette=colors) # Customize the plot
plt.xlabel('Month')
plt.ylabel('Count')
plt.title('Content Added by Month') # Add count values on top of each bar
for index, value in enumerate(monthly_counts.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()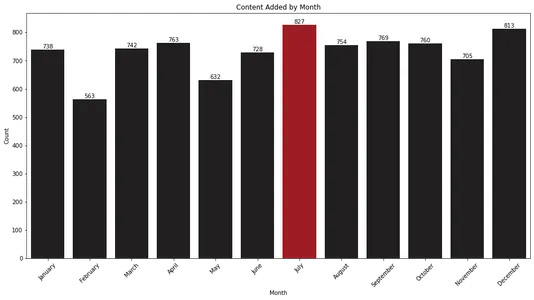
Het staafdiagram laat zien dat juli en december de maanden zijn waarin Netflix de meeste content aan zijn bibliotheek toevoegt. Deze informatie kan waardevol zijn voor kijkers die in deze maanden willen anticiperen op nieuwe releases.
Een ander cruciaal aspect van de inhoudsanalyse van Netflix is het begrijpen van de verdeling van beoordelingen. Door het aantal van elke beoordelingscategorie te onderzoeken, kunnen we de meest voorkomende soorten inhoud op het platform bepalen.
Verdeling van beoordelingen
We beginnen met het berekenen van het voorkomen van elke beoordelingscategorie en visualiseren deze met behulp van een staafdiagram. Deze visualisatie geeft een duidelijk overzicht van de verdeling van beoordelingen.
# Count the occurrences of each rating
rating_counts = df['rating'].value_counts() # Create a bar chart to visualize the ratings
plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(rating_counts) - 1)
sns.barplot(x=rating_counts.index, y=rating_counts.values, palette=colors) # Customize the plot
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('Distribution of Ratings') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()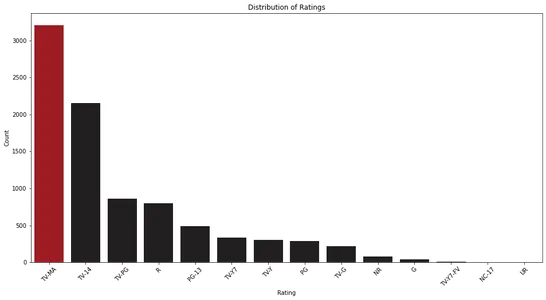
Bij analyse van het staafdiagram kunnen we de verdeling van beoordelingen op Netflix observeren. Het helpt ons de meest voorkomende beoordelingscategorieën en hun relatieve frequentie te identificeren.
Genrecorrelatie Heatmap
Genres spelen een belangrijke rol bij het categoriseren en organiseren van inhoud op Netflix. Het analyseren van de correlatie tussen genres kan interessante verbanden tussen verschillende soorten inhoud aan het licht brengen.
We maken een DataFrame voor genregegevens om genrecorrelatie te onderzoeken en vullen deze met nullen. Door elke rij in het oorspronkelijke DataFrame te herhalen, werken we de genregegevens DataFrame bij op basis van de vermelde genres. Vervolgens maken we een correlatiematrix met behulp van deze genregegevens en visualiseren deze als een heatmap.
# Extracting unique genres from the 'listed_in' column
genres = df['listed_in'].str.split(', ', expand=True).stack().unique() # Create a new DataFrame to store the genre data
genre_data = pd.DataFrame(index=genres, columns=genres, dtype=float) # Fill the genre data DataFrame with zeros
genre_data.fillna(0, inplace=True) # Iterate over each row in the original DataFrame and update the genre data DataFrame
for _, row in df.iterrows(): listed_in = row['listed_in'].split(', ') for genre1 in listed_in: for genre2 in listed_in: genre_data.at[genre1, genre2] += 1 # Create a correlation matrix using the genre data
correlation_matrix = genre_data.corr() # Create the heatmap
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm') # Customize the plot
plt.title('Genre Correlation Heatmap')
plt.xticks(rotation=90)
plt.yticks(rotation=0) # Show the plot
plt.show()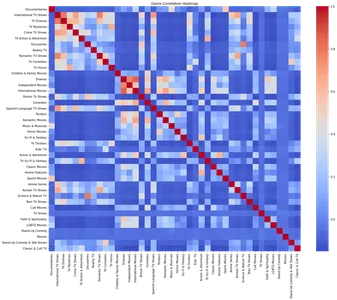
De heatmap toont de correlatie tussen verschillende genres. Door de heatmap te analyseren, kunnen we sterke positieve correlaties identificeren tussen specifieke genres, zoals tv-drama's en internationale tv-shows, romantische tv-shows en internationale tv-shows.
Verdeling van filmlengtes en aantal afleveringen van tv-shows
Inzicht in de duur van films en tv-programma's geeft inzicht in de lengte van de inhoud en helpt kijkers hun kijktijd te plannen. Door de verdeling van filmlengtes en tv-programmaduur te onderzoeken, kunnen we de inhoud die beschikbaar is op Netflix beter begrijpen.
Om dit te bereiken, halen we de filmduur en het aantal afleveringen van tv-programma's uit de kolom 'duur'. Vervolgens plotten we histogrammen en boxplots om de verdeling van filmlengtes en tv-programmaduur te visualiseren.
# Extract the movie lengths and TV show episode counts
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Plot the histogram
plt.figure(figsize=(10, 6))
plt.hist(movie_lengths, bins=10, color='#b20710', label='Movies')
plt.hist(tv_show_episodes, bins=10, color='#221f1f', label='TV Shows') # Customize the plot
plt.xlabel('Duration/Episode Count')
plt.ylabel('Frequency')
plt.title('Distribution of Movie Lengths and TV Show Episode Counts')
plt.legend() # Show the plot
plt.show()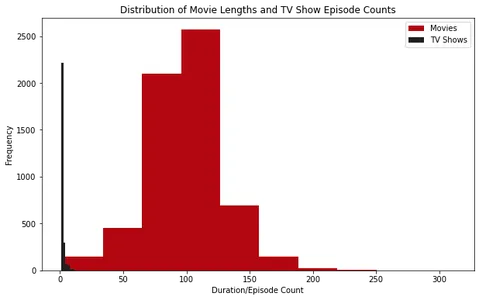
Als we de histogrammen analyseren, zien we dat de meeste films op Netflix een duur hebben van ongeveer 100 minuten. Aan de andere kant hebben de meeste tv-programma's op Netflix maar één seizoen.
Bovendien kunnen we, door de boxplots te onderzoeken, zien dat films die langer dan ongeveer 2.5 uur duren, als uitschieters worden beschouwd. Voor tv-programma's is het ongebruikelijk om die met meer dan vier seizoenen te vinden.
De trend van film-/tv-showlengtes door de jaren heen
We kunnen lijndiagrammen uitzetten om te begrijpen hoe filmlengtes en het aantal afleveringen van tv-programma's in de loop der jaren zijn geëvolueerd. Patronen of verschuivingen in de inhoudsduur identificeren door deze trends te analyseren.
We beginnen met het extraheren van de filmlengtes en het aantal afleveringen van tv-programma's uit de kolom 'duur'. Vervolgens maken we lijnplots om de veranderingen in filmlengtes en afleveringen van tv-programma's door de jaren heen te visualiseren.
import seaborn as sns
import matplotlib.pyplot as plt # Extract the movie lengths and TV show episodes from the 'duration' column
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Create line plots for movie lengths and TV show episodes
plt.figure(figsize=(16, 8)) plt.subplot(2, 1, 1)
sns.lineplot(data=df_movies, x='release_year', y=movie_lengths, color=colors[0])
plt.xlabel('Release Year')
plt.ylabel('Movie Length')
plt.title('Trend of Movie Lengths Over the Years') plt.subplot(2, 1, 2)
sns.lineplot(data=df_tv_shows, x='release_year', y=tv_show_episodes,color=colors[1])
plt.xlabel('Release Year')
plt.ylabel('TV Show Episodes')
plt.title('Trend of TV Show Episodes Over the Years') # Adjust the layout and spacing
plt.tight_layout() # Show the plots
plt.show()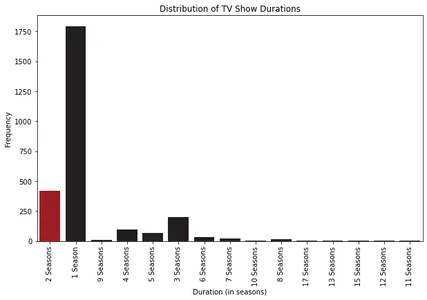
Bij het analyseren van de lijndiagrammen zien we spannende patronen. We kunnen zien dat de lengte van films aanvankelijk toenam tot ongeveer 1963-1964 en daarna geleidelijk afnam, tot een stabilisatie rond een gemiddelde van 100 minuten. Dit suggereert een verschuiving in de voorkeuren van het publiek in de loop van de tijd.
Wat betreft afleveringen van tv-programma's, hebben we een consistente trend opgemerkt sinds het begin van de jaren 2000, waarbij de meeste tv-programma's op Netflix één tot drie seizoenen hebben. Dit duidt op een voorkeur bij kijkers voor kortere series of beperkte serieformaten.
Meest voorkomende woorden in titels en beschrijvingen
Het analyseren van de meest voorkomende woorden die in titels en beschrijvingen worden gebruikt, kan inzicht geven in de thema's en contentfocus op Netflix. We kunnen woordwolken genereren om deze patronen te ontdekken op basis van de titels en beschrijvingen van de inhoud van Netflix.
from wordcloud import WordCloud # Concatenate all the titles into a single string
text = ' '.join(df['title']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show() # Concatenate all the titles into a single string
text = ' '.join(df['description']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show()
Als we de woordwolk voor titels onderzoeken, zien we dat termen als 'Liefde', 'Meisje', 'Man', 'Leven' en 'Wereld' vaak worden gebruikt, wat duidt op de aanwezigheid van romantiek, volwassen worden en drama genres in de inhoudsbibliotheek van Netflix.
Bij het analyseren van de woordwolk voor beschrijvingen, zien we dominante woorden zoals 'leven', 'vinden' en 'familie', die thema's suggereren van persoonlijke reizen, relaties en gezinsdynamiek die overheersend zijn in de inhoud van Netflix.
Duurdistributie voor films en tv-programma's
Door de duurverdeling voor films en tv-programma's te analyseren, krijgen we inzicht in de typische lengte van de inhoud die beschikbaar is op Netflix. We kunnen boxplots maken om deze verdelingen te visualiseren en uitschieters of standaardduren te identificeren.
# Extracting and converting the duration for movies
df_movies['duration'] = df_movies['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for movie duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_movies, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for Movies')
plt.show() # Extracting and converting the duration for TV shows
df_tv_shows['duration'] = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for TV show duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_tv_shows, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for TV Shows')
plt.show()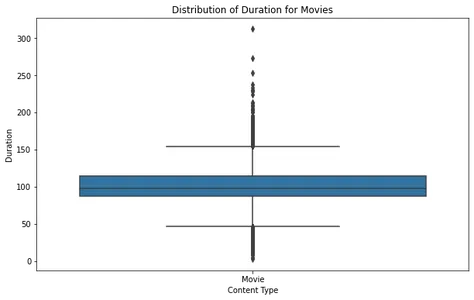
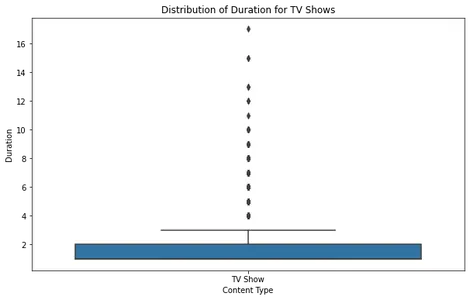
Als we de plot van de filmdoos analyseren, kunnen we zien dat de meeste films binnen een redelijk tijdsduurbereik vallen, met enkele uitschieters van meer dan ongeveer 2.5 uur. Dit suggereert dat de meeste films op Netflix zijn ontworpen om binnen een standaard kijktijd te passen.
Voor tv-shows laat de boxplot zien dat de meeste shows één tot vier seizoenen hebben, met zeer weinig uitschieters die een langere duur hebben. Dit sluit aan bij de eerdere trends, wat aangeeft dat Netflix zich richt op kortere serieformaten.
Conclusie
Met behulp van dit artikel hebben we kunnen leren over-
- Aantal: Uit onze analyse bleek dat Netflix meer films dan tv-programma's had toegevoegd, in overeenstemming met de verwachting dat films hun inhoudsbibliotheek domineren.
- Toevoeging van inhoud: juli kwam naar voren als de maand waarin Netflix de meeste inhoud toevoegt, op de voet gevolgd door december, wat duidt op een strategische benadering van het vrijgeven van inhoud.
- Genrecorrelatie: er werden sterke positieve associaties waargenomen tussen verschillende genres, zoals tv-drama's en internationale tv-shows, romantische en internationale tv-shows en onafhankelijke films en drama's. Deze correlaties bieden inzicht in de voorkeuren van kijkers en onderlinge verbanden tussen inhoud.
- Filmduur: de analyse van de filmduur wees op een piek rond de jaren 1960, gevolgd door een stabilisatie rond 100 minuten, wat wijst op een trend in filmduur in de loop van de tijd.
- Afleveringen van tv-programma's: De meeste tv-programma's op Netflix hebben één seizoen, wat suggereert dat kijkers de voorkeur geven aan kortere series.
- Algemene thema's: Woorden als liefde, leven, familie en avontuur kwamen vaak voor in titels en beschrijvingen, waarmee terugkerende thema's in Netflix-inhoud werden vastgelegd.
- Beoordelingsdistributie: de verdeling van beoordelingen over de jaren heen biedt inzicht in het evoluerende inhoudslandschap en de ontvangst van het publiek.
- Gegevensgestuurde inzichten: Ons data-analysetraject toonde de kracht van data bij het ontrafelen van de mysteries van het contentlandschap van Netflix, wat waardevolle inzichten opleverde voor kijkers en contentmakers.
- Blijvende relevantie: naarmate de streaming-industrie evolueert, wordt het begrijpen van deze patronen en trends steeds belangrijker voor het navigeren door het dynamische landschap van Netflix en zijn enorme bibliotheek.
- Veel plezier met streamen: we hopen dat deze blog een verhelderende en vermakelijke reis door de wereld van Netflix is geweest, en we moedigen je aan om de boeiende verhalen binnen het steeds veranderende inhoudsaanbod te ontdekken. Laat de gegevens je streamingavonturen begeleiden!
Officiële documentatie en bronnen
Hieronder vindt u de officiële links naar de bibliotheken die in onze analyse zijn gebruikt. U kunt deze links raadplegen voor meer informatie over de methoden en functionaliteiten van deze bibliotheken:
- Panda's: https://pandas.pydata.org/
- NumPy: https://numpy.org/
- matplotlib: https://matplotlib.org/
- SciPy: https://scipy.org/
- Zeegeboren: https://seaborn.pydata.org/
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/06/netflix-case-study-eda-unveiling-data-driven-strategies-for-streaming/

