Introductie
ChatGPT
In het dynamische landschap van het moderne bedrijfsleven is het snijvlak van machine learning en operations (MLOps) een krachtige kracht gebleken, die traditionele benaderingen van verkoopconversie-optimalisatie opnieuw vormgeeft. Het artikel neemt u mee in de transformerende rol die MLOps-strategieën spelen bij het revolutioneren van het succes van verkoopconversies. Terwijl bedrijven streven naar verhoogde efficiëntie en verbeterde klantinteracties, staat de integratie van machine learning-technieken in de bedrijfsvoering centraal. Deze verkenning onthult innovatieve strategieën die gebruikmaken van MLOps om niet alleen verkoopprocessen te stroomlijnen, maar ook om ongekend succes te ontsluiten bij het omzetten van potentiële klanten in loyale klanten. Ga met ons mee op reis door de fijne kneepjes van MLops en ontdek hoe de strategische toepassing ervan het landschap van verkoopconversie opnieuw vormgeeft.
leerdoelen
- Belang van het verkoopoptimalisatiemodel
- Gegevens opschonen, datasets transformeren en datasets voorbewerken
- End-to-end fraudedetectie bouwen met Kedro en Deepcheck
- Model implementeren met behulp van gestroomlijnd en knuffelend gezicht
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat is het verkoopoptimalisatiemodel?
Een Verkoopoptimalisatiemodel is een end-to-end machine learning-model om de verkoop van producten te maximaliseren en de conversieratio te verbeteren. Het model gebruikt verschillende parameters als invoer, zoals vertoning, leeftijdsgroep, geslacht, klikfrequentie en kosten per klik. Nadat u dit heeft getraind, voorspelt het model het aantal mensen dat het product zal kopen na het zien van de advertentie.
Noodzakelijke vereisten
1) Kloon de repository
git clone https://github.com/ashishk831/Final-THC.git
cd Final-THC2) Creëer en activeer de virtuele omgeving
#create a virtual environment
python3 -m venv SOP
#Activate your virtual environment in your project folder
source SOP/bin/activate
pip install -r requirements.txt4)Installeer Kedro, Kedro-viz, Streamlit en Deepcheck
pip install streamlit
pip install Deepcheck
pip install Kedro
pip install Kedro-vizGegevensbeschrijving
Laten we een fundamentele data-analyse uitvoeren met behulp van Python-implementatie op een dataset van Kaggle. Om de dataset te downloaden, klikt u op hier.
import pandas as pd
import numpy as np
df = pd.read_csv('KAG_conversion_data.csv')
df.head()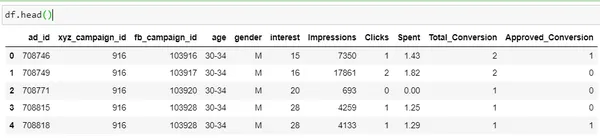
| Kolom | Omschrijving |
| advertentie_id | Een unieke ID voor elke advertentie |
| xyz_campagne_id | Een ID die is gekoppeld aan elke advertentiecampagne van het XYZ-bedrijf |
| fb_campagne_id | Een ID die is gekoppeld aan de manier waarop Facebook elke campagne bijhoudt |
| leeftijd | Leeftijd van de persoon aan wie de advertentie wordt getoond |
| geslacht | Het geslacht van de persoon die de advertentie wil ophitsen, wordt weergegeven |
| belang | een code die de categorie specificeert waartoe de interesse van de persoon behoort (interesses zijn zoals vermeld in het openbare Facebook-profiel van de persoon) |
| Impressies | het aantal keren dat de advertentie is weergegeven. |
| Clicks | Aantal klikken op die advertentie. |
| besteed | Bedrag dat bedrijf xyz aan Facebook heeft betaald om die advertentie te tonen |
| Totaal Conversie |
Totaal aantal mensen dat na het zien van de advertentie naar het product informeerde |
| aangenomen Conversie |
Totaal aantal mensen dat het product heeft gekocht na het zien van de advertentie |
Hier de "Goedgekeurde conversie' is de doelkolom. Ons
Het doel is om een model te ontwerpen dat de verkoop van het product zal vergroten zodra mensen het zien
de advertentie.
Modelontwikkeling met behulp van Kedro
Om dit project end-to-end op te bouwen, zullen we de Kedro-tool gebruiken. Kedro is een open-sourcetool die wordt gebruikt voor het bouwen van een productieklaar machine learning-model en biedt een aantal voordelen.
- Omgaat met complexiteit: Het biedt een structuur om gegevens te testen die na succesvol testen naar productie kunnen worden gepusht.
- normalisering: Het biedt een standaardsjabloon voor projecten. Zodat het voor anderen makkelijker te begrijpen is.
- Productieklaar: Code kan eenvoudig naar productie worden gepusht met verkennende code die u kunt overzetten naar reproduceerbare, onderhoudbare en modulaire experimenten.
Lees meer: Walkthrough van het Kedro-framework
Pijpleidingstructuur
Om een project in Kedro aan te maken, volgt u de onderstaande stappen.
#create project
kedro new
#create pipeline
kedro pipeline create <pipeline-name>
#Run kedro
kedro run
#Visualizing pipeline
kedro vizMet behulp van kedro zullen we de end-to-end modelpijplijn ontwerpen, die hieronder wordt weergegeven.
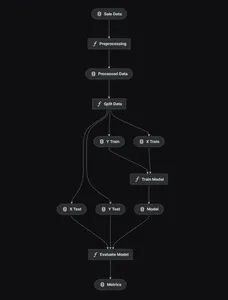
Data Preprocessing
- Controleer op ontbrekende waarden en handel deze af.
- Er worden twee nieuwe kolommen CTR en CPC gemaakt.
- Kolomvariabele omzetten in numeriek.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
def preprocessing(data: pd.DataFrame):
data.gender = data.gender.apply(lambda x: 1 if x=="M" else 0)
data['CTR'] = ((data['Clicks']/data['Impressions'])*100)
data['CPC'] = data['Spent']/data['Clicks']
data['CPC'] = data['CPC'].replace(np.nan,0)
encoder=LabelEncoder()
encoder.fit(data["age"])
data["age"]=encoder.transform(data["age"])
#data.Approved_Conversion = data.Approved_Conversion.apply(lambda x: 0 if x==0 else 1)
preprocessed_data = data.copy()
return preprocessed_dataGegevens splitsen
import pandas as pd
from sklearn.model_selection import train_test_split
def split_data(processed_data: pd.DataFrame):
X = processed_data[['ad_id', 'age', 'gender', 'interest', 'Spent',
'Total_Conversion','CTR', 'CPC']]
y = processed_data["Approved_Conversion"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1,
random_state=42)
return X_train, X_test, y_train, y_testHierboven is de dataset verdeeld in treindataset en testdataset voor modeltrainingsdoeleinden.
Model opleiding
from sklearn.ensemble import RandomForestRegressor
def train_model(X_train, y_train):
model = RandomForestRegressor(n_estimators = 50, random_state = 0, max_samples=0.75)
model.fit(X_train, y_train)
return model
We zullen de RandomForestRegressor-module gebruiken om het model te trainen. Alleen met RandomForestRegressor geven we andere parameters door, zoals n_estimators random_state en max_samples.
Evaluatie
import numpy as np
import logging
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, max_error
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
mae=mean_absolute_error(y_test, y_pred)
mse=mean_squared_error(y_test, y_pred)
rmse=np.sqrt(mse)
r2score=r2_score(y_test, y_pred)
me = max_error(y_test, y_pred)
print("MAE Of Model is: ",mae)
print("MSE Of Model is: ",mse)
print("RMSE Of Model is: ",rmse)
print("R2_Score Of Model is: ",r2score)
logger = logging.getLogger(__name__)
logger.info("Model has a coefficient R^2 of %.3f on test data.", r2score)
return {"r2_score": r2score, "mae": mae, "max_error": me}Zodra het model is getraind, wordt het geëvalueerd met behulp van een aantal belangrijke statistieken zoals MAE, MSE, RMSE en R2-score.
Experimenttracker
Om de prestaties van het model te volgen en het beste model te selecteren, gebruiken we de experimenttracker. De functionaliteit van de experimenttracker is om alle informatie over het experiment op te slaan wanneer de applicatie wordt uitgevoerd. Om de experimenttracker in Kedro in te schakelen, kunnen we het bestand catalog.xml bijwerken. De parameter versiebeheer moet op True zijn ingesteld. Hieronder vindt u het voorbeeld
model:
type: pickle.PickleDataSet
filepath: data/06_models/model.pkl
backend: pickle
versioned: TrueDit helpt bij het volgen van het modelresultaat en het opslaan van de modelversie. Hier zullen we de experimenttracker gebruiken bij de evaluatiestap om de modelprestaties tijdens de ontwikkelingsfase te volgen.
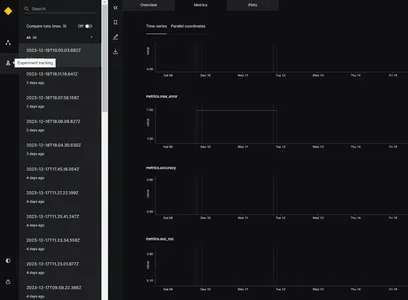
Wanneer het model wordt uitgevoerd, genereert het verschillende evaluatiestatistieken, zoals MAE, MSE, RMSE en R2-score voor verschillende tijdstempels, zoals weergegeven in de afbeelding. Op basis van bovenstaande evaluatiestatistieken kan het beste model worden geselecteerd.
Deepcheck: voor gegevens- en modelmonitoring
Wanneer het model in productie wordt ingezet, bestaat de kans dat de datakwaliteit in de loop van de tijd verandert en als gevolg van dit model kunnen de prestaties ook veranderen. Om dit probleem op te lossen, moeten we de gegevens in de productieomgeving monitoren. Hiervoor gebruiken we een open-source tool Deepcheck. Deepcheck heeft ingebouwde bibliotheken zoals Label-drift en Feature-Drift die eenvoudig kunnen worden geïntegreerd met modelcode.
- FeatureDrift: – Een drift betekent een verandering in de distributie van gegevens in de loop van de tijd, waardoor de prestaties van het model afnemen. FeatureDift betekent dat er een verandering heeft plaatsgevonden in een enkel kenmerk van de dataset.
- Labeldrift: – Labeldrift treedt op wanneer de grondwaarheid een dataset in de loop van de tijd labelt. Het komt vooral voor als gevolg van veranderingen in de etiketteringscriteria.
Integratie van modelvoorspelling en monitoring met Streamlit
Nu zullen we een gebruikersinterface bouwen om te communiceren met het model voor het maken van voorspellingen op basis van de gegeven invoerparameters om de conversieratio te controleren.
import streamlit as st
import pandas as pd
import joblib
import numpy as np
st.sidebar.header("Model Prediction or Report")
selected_report = st.sidebar.selectbox("Select from below", ["Model Prediction",
"Data Integrity","Feature Drift", "Label Drift"])
if selected_report=="Model Prediction":
st.header("Sales Optimization Model")
#def predict(ad_id, age, gender, interest, Impressions, Clicks, Spent,
#Total_Conversion, CTR, CPC):
def predict(ad_id, age, gender, interest, Spent, Total_Conversion, CTR, CPC):
if gender == 'Male':
gender = 0
else:
gender = 1
ad_id = int(ad_id)
age = int(age)
gender = int(gender)
interest = int(interest)
#Impressions = int(Impressions)
#Clicks = int(Clicks)
Spent = float(Spent)
Total_Conversion = int(Total_Conversion)
CTR = float(CTR*0.000001)
CPC = float(CPC)
input=np.array([[ad_id, age, gender, interest, Spent,
Total_Conversion, CTR, CPC]]).astype(np.float64)
model = joblib.load('model/model.pkl')
# Make prediction
prediction = model.predict(input)
prediction= np.round(prediction)
# Return the predicted value for Approved_Conversion
return prediction
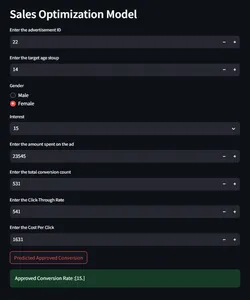
ad_id = st.number_input('Enter the advertisement ID',min_value = 0)
age = st.number_input('Enter the target age stoup',min_value = 0)
gender = st.radio("Gender",('Male','Female'))
interest = st.selectbox('Interest', [2, 7, 10, 15, 16, 18, 19, 20, 21, 22, 23,
24, 25,
26, 27, 28, 29, 30, 31, 32, 36, 63, 64, 65, 66, 100, 101, 102,
103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114])
#Impressions = st.number_input('Enter the number of impressions',min_value = 0)
#Clicks = st.number_input('Enter the number of clicks',min_value = 0)
Spent = st.number_input('Enter the amount spent on the ad',min_value = 0)
Total_Conversion = st.number_input('Enter the total conversion count',
min_value = 0)
CTR = st.number_input('Enter the Click-Through Rate',min_value = 0)
CPC = st.number_input('Enter the Cost Per Click',min_value = 0)
if st.button("Predicted Approved Conversion"):
output = predict(ad_id, age, gender, interest, Spent, Total_Conversion,
CTR, CPC)
st.success("Approved Conversion Rate :{}".format(output))
else:
st.header("Sales Model Monitoring Report")
report_file_name = "report/"+ selected_report.replace(" ", "") + ".html"
HtmlFile = open(report_file_name, 'r', encoding='utf-8')
source_code = HtmlFile.read()
st.components.v1.html(source_code, width=1200, height=1500, scrolling=True)
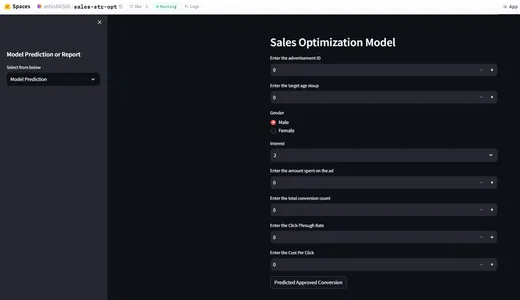
Implementatie met HuggingFace
Nu we een end-to-end verkoopoptimalisatiemodel hebben gebouwd, zullen we het model inzetten met behulp van HuggingFace. In Huggingface moeten we het README.md-bestand configureren voor modelimplementatie. Knuffelgezicht zorgt voor CI/CD. Elke keer dat er een wijziging in het bestand plaatsvindt, worden de wijzigingen gevolgd en wordt de app opnieuw geïmplementeerd. Hieronder vindt u de readme.md-bestandsconfiguratie.
title: {{Sale-str-opt}}
emoji: {{Sale-str-opt}}
colorFrom: {{colorFrom}}
colorTo: {{colorTo}}
sdk: {{sdk}}
sdk_version: {{sdkVersion}}
app_file: app.py
pinned: falseHuggingFace-appdemo
Voor cloudversie klik hier.
Conclusie
- Machine learning-apps kunnen het testconversiepercentage op een onbekende markt weergeven, zodat bedrijven de vraag naar producten kunnen kennen.
- Met behulp van het Sale-optimalisatiemodel kunnen bedrijven zich op de juiste doelgroep richten.
- Deze applicatie helpt de bedrijfsinkomsten te vergroten.
- Het in realtime monitoren van gegevens kan ook helpen bij het volgen van modelwijzigingen en veranderingen in gebruikersgedrag.
Veelgestelde Vragen / FAQ
A. Het doel van het verkoopoptimalisatiemodel is het voorspellen van het aantal klanten dat het product zal kopen na het zien van de advertentie.
A. Het monitoren van de gegevens helpt bij het volgen van het dataset- en modelgedrag.
A. Ja, Huggingface is gratis te gebruiken met basisfunctie 2 vCPU, 16 GB RAM.
A. Er zijn geen strikte regels voor het selecteren van rapporten in de modelmonitoringfase. Deepcheck heeft veel ingebouwde bibliotheken, zoals modeldrift en distributiedrift.
A. Streamlit helpt bij lokale implementatie, wat helpt bij het oplossen van fouten tijdens de ontwikkelingsfase.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/01/mlops-strategies-for-sales-conversion-success/

