Afbeelding door auteur
In dit bericht zullen we het nieuwe, ultramoderne open-sourcemodel verkennen, genaamd Mixtral 8x7b. We zullen ook leren hoe we er toegang toe kunnen krijgen met behulp van de LLaMA C++-bibliotheek en hoe we grote taalmodellen kunnen uitvoeren met minder rekenkracht en geheugen.
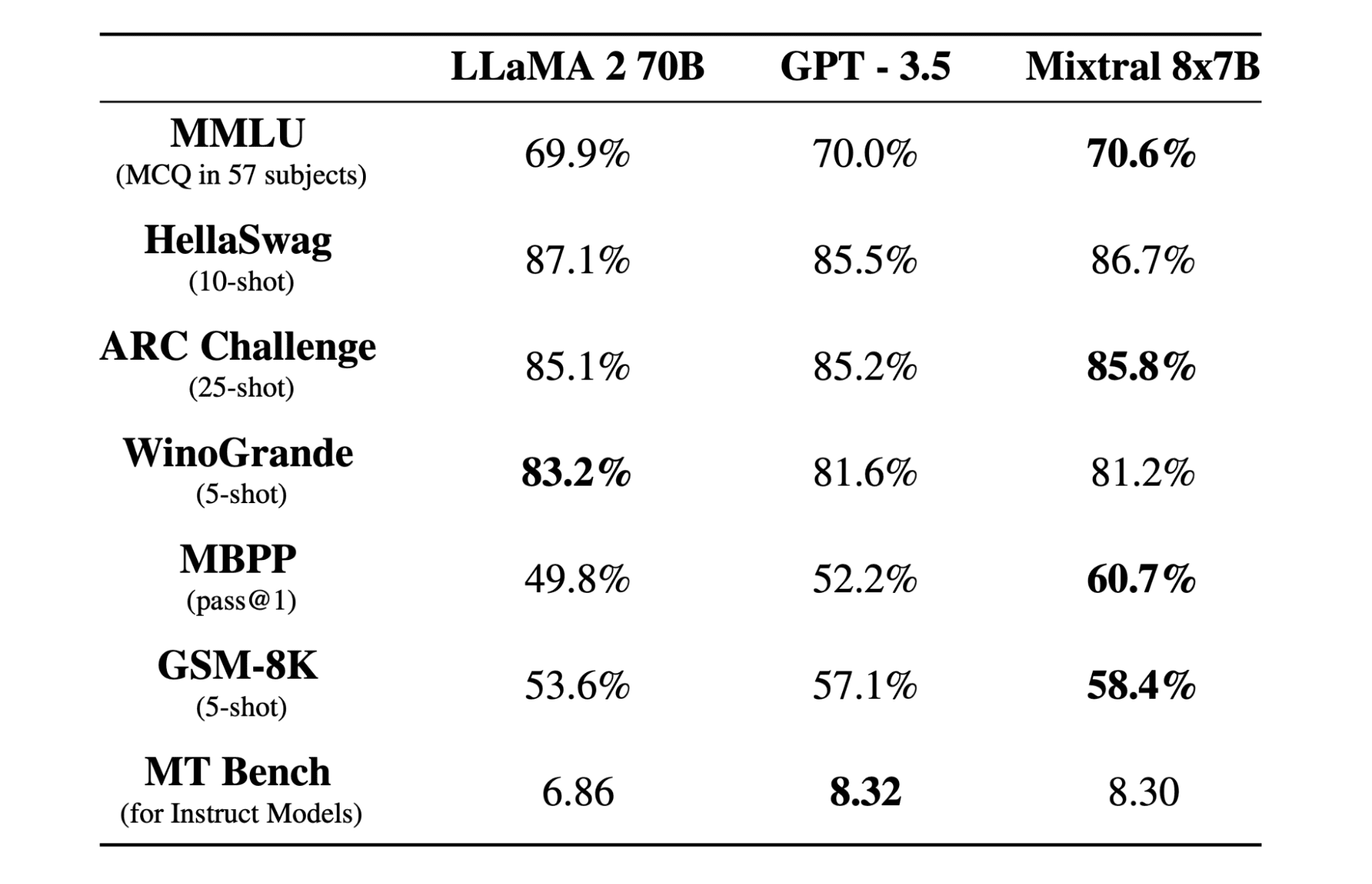
Mixtraal 8x7b is een hoogwaardig SMoE-model (Sparse Mix of Experts) met open gewichten, gemaakt door Mistral AI. Het is gelicentieerd onder Apache 2.0 en presteert beter dan Llama 2 70B op de meeste benchmarks, terwijl het 6x snellere gevolgtrekkingen heeft. Mixtral komt overeen met of verslaat GPT3.5 op de meeste standaard benchmarks en is het beste open-weight-model wat betreft kosten/prestaties.
Afbeelding van Mixtraal van experts
Mixtral 8x7B maakt gebruik van een schaars mengsel van experts-netwerk met alleen een decoder. Dit omvat een feedforward-blok dat selecteert uit 8 groepen parameters, waarbij een routernetwerk twee van deze groepen voor elk token kiest, waarbij hun uitgangen op additieve wijze worden gecombineerd. Deze methode verbetert het aantal parameters van het model en beheert tegelijkertijd de kosten en latentie, waardoor het net zo efficiënt is als een model van 12.9 miljard, ondanks dat het in totaal 46.7 miljard parameters heeft.
Het Mixtral 8x7B-model blinkt uit in het verwerken van een brede context van 32k-tokens en ondersteunt meerdere talen, waaronder Engels, Frans, Italiaans, Duits en Spaans. Het demonstreert sterke prestaties bij het genereren van code en kan worden verfijnd tot een instructievolgend model, waardoor hoge scores worden behaald op benchmarks zoals MT-Bench.
LLaMA.cpp is een C/C++-bibliotheek die een krachtige interface biedt voor grote taalmodellen (LLM's) op basis van de LLM-architectuur van Facebook. Het is een lichtgewicht en efficiënte bibliotheek die voor een verscheidenheid aan taken kan worden gebruikt, waaronder het genereren van tekst, vertalen en het beantwoorden van vragen. LLaMA.cpp ondersteunt een breed scala aan LLM's, waaronder LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B en GPT4ALL. Het is compatibel met alle besturingssystemen en kan functioneren op zowel CPU's als GPU's.
In deze sectie gebruiken we de webapplicatie llama.cpp op Colab. Door een paar regels code te schrijven, kunt u de nieuwe, ultramoderne modelprestaties op uw pc of op Google Colab ervaren.
Ermee beginnen
Eerst zullen we de llama.cpp GitHub-repository downloaden met behulp van de onderstaande opdrachtregel:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitDaarna zullen we de map naar de repository wijzigen en de llama.cpp installeren met behulp van het `make` commando. We installeren de llama.cpp voor de NVidia GPU waarop CUDA is geïnstalleerd.
%cd llama.cpp
!make LLAMA_CUBLAS=1Download het model
We kunnen het model downloaden van de Hugging Face Hub door de juiste versie van het `.gguf`-modelbestand te selecteren. Meer informatie over de verschillende versies vindt u in TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
Afbeelding van TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
U kunt het commando `wget` gebruiken om het model in de huidige map te downloaden.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufExtern adres voor LLaMA-server
Wanneer we de LLaMA-server gebruiken, krijgt deze ons een localhost IP-adres, wat nutteloos is voor ons op Colab. We hebben de verbinding met de localhost-proxy nodig via de Colab-kernelproxypoort.
Nadat u de onderstaande code hebt uitgevoerd, krijgt u de globale hyperlink. We zullen deze link gebruiken om later toegang te krijgen tot onze webapp.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/De server uitvoeren
Om de LLaMA C++-server te kunnen gebruiken, moet u de serveropdracht opgeven met de locatie van het modelbestand en het juiste poortnummer. Het is belangrijk om ervoor te zorgen dat het poortnummer overeenkomt met het nummer dat we in de vorige stap voor de proxypoort hebben geïnitieerd.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
De chat-webapp is toegankelijk door in de vorige stap op de proxypoort-hyperlink te klikken, aangezien de server niet lokaal draait.
LLaMA C++ Webapp
Voordat we de chatbot gaan gebruiken, moeten we deze aanpassen. Vervang "LLaMA" door uw modelnaam in het promptgedeelte. Wijzig bovendien de gebruikersnaam en de botnaam om onderscheid te maken tussen de gegenereerde reacties.
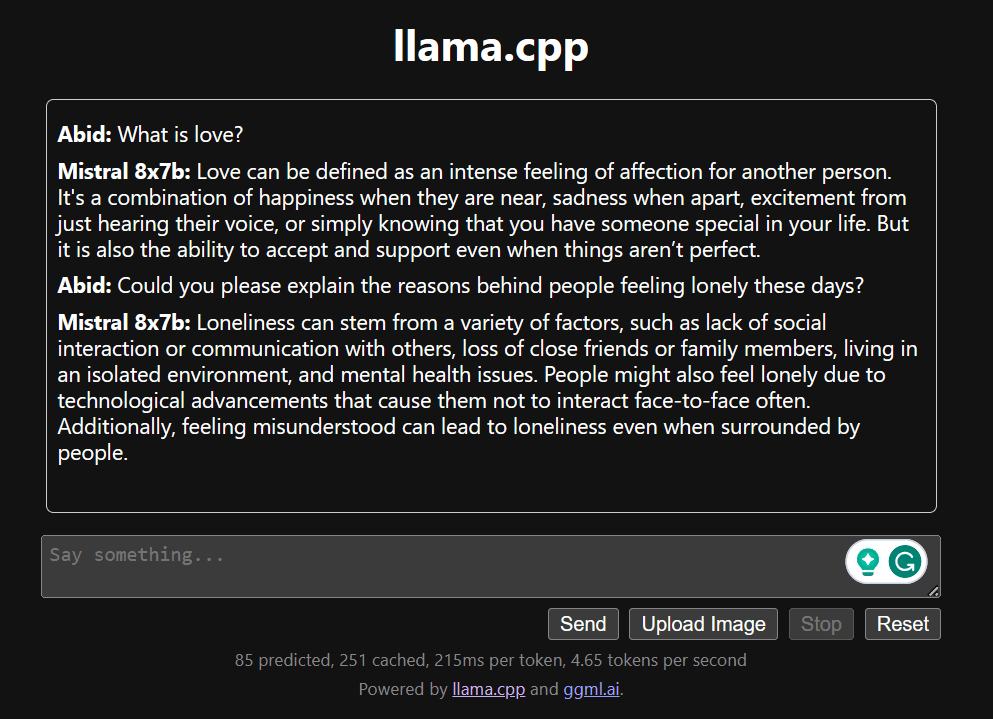
Begin met chatten door naar beneden te scrollen en in het chatgedeelte te typen. Stel gerust technische vragen die andere open source-modellen niet goed hebben kunnen beantwoorden.
Als u problemen ondervindt met de app, kunt u proberen deze zelf uit te voeren met behulp van mijn Google Colab: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
Deze tutorial biedt een uitgebreide handleiding over het uitvoeren van het geavanceerde open-sourcemodel, Mixtral 8x7b, op Google Colab met behulp van de LLaMA C++-bibliotheek. Vergeleken met andere modellen levert Mixtral 8x7b superieure prestaties en efficiëntie, waardoor het een uitstekende oplossing is voor degenen die willen experimenteren met grote taalmodellen maar niet over uitgebreide computerbronnen beschikken. U kunt het eenvoudig op uw laptop of op een gratis cloudcomputer uitvoeren. Het is gebruiksvriendelijk en u kunt uw chat-app zelfs inzetten zodat anderen deze kunnen gebruiken en ermee kunnen experimenteren.
Ik hoop dat je deze eenvoudige oplossing voor het grote model nuttig vond. Ik ben altijd op zoek naar eenvoudige en betere opties. Als je een nog betere oplossing hebt, laat het me dan weten, dan zal ik het de volgende keer bespreken.
Abid Ali Awan (@1abidaliawan) is een gecertificeerde datawetenschapper-professional die dol is op het bouwen van machine learning-modellen. Momenteel richt hij zich op het creëren van content en het schrijven van technische blogs over machine learning en data science-technologieën. Abid heeft een Master in Technologie Management en een Bachelor in Telecommunicatie Engineering. Zijn visie is om een AI-product te bouwen met behulp van een grafisch neuraal netwerk voor studenten die worstelen met een psychische aandoening.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free

