Amazon roodverschuiving is een snel, volledig beheerd datawarehouse op petabyte-schaal dat de flexibiliteit biedt om ingerichte of serverloze rekenkracht te gebruiken voor uw analytische werklasten. Met Amazon Redshift Serverloos en Query-editor v2, kunt u met slechts een paar klikken grote datasets laden en opvragen en alleen betalen voor wat u gebruikt. Met de ontkoppelde reken- en opslagarchitectuur van Amazon Redshift kunt u zeer schaalbare, veerkrachtige en kosteneffectieve workloads bouwen. Veel klanten migreren hun datawarehousing-workloads naar Amazon Redshift en profiteren van de rijke mogelijkheden die het biedt, zoals de volgende:
- Amazon Redshift kan naadloos worden geïntegreerd met bredere data, analyses en AI of machine learning (ML) diensten op AWS, zodat u het juiste gereedschap voor de juiste klus kunt kiezen. Moderne analytics is veel breder dan op SQL gebaseerde datawarehousing. Met Amazon Redshift kun je bouwen architectuur aan het meer en voer elke vorm van analyse uit, zoals interactieve analyse, operationele analyses, big data verwerking, visuele gegevensvoorbereiding, voorspellende analyses, machine learningEn nog veel meer.
- U hoeft zich geen zorgen te maken over workloads zoals ETL (extract, transform en load), dashboards, ad-hocquery's, enzovoort die elkaar verstoren. U kunt workloads isoleren door gegevens te delen, terwijl u dezelfde onderliggende datasets gebruikt.
- Wanneer gebruikers op piekmomenten veel query's uitvoeren, kan de rekenkracht binnen enkele seconden naadloos worden geschaald om consistente prestaties bij hoge gelijktijdigheid te bieden. U krijgt 1 uur gratis gelijktijdigheidsschaalcapaciteit voor 24 uur gebruik. Dit gratis tegoed voldoet aan de gelijktijdigheidsvraag van 97% van het Amazon Redshift-klantenbestand.
- Amazon Redshift is eenvoudig te gebruiken met zelfafstemmende en zelfoptimaliserende mogelijkheden. U krijgt sneller inzicht zonder dat u kostbare tijd hoeft te besteden aan het beheren van uw datawarehouse.
- Fouttolerantie is ingebouwd. Alle gegevens die naar Amazon Redshift worden geschreven, worden automatisch en continu gerepliceerd Amazon eenvoudige opslagservice (Amazone S3). Eventuele hardwarestoringen worden automatisch vervangen.
- Amazon Redshift is eenvoudig om mee te communiceren. U hebt toegang tot gegevens met traditionele, cloud-native, containergebaseerde, serverloze webservices of gebeurtenisgestuurde applicaties. U kunt ook uw favoriete business intelligence (BI) en SQL-tools gebruiken om gegevens in Amazon Redshift te openen, analyseren en visualiseren.
- Amazon RedshiftML maakt het voor datawetenschappers eenvoudig om ML-modellen te creëren, trainen en implementeren met behulp van vertrouwde SQL. U kunt ook voorspellingen uitvoeren met behulp van SQL.
- Amazon Redshift biedt uitgebreide gegevensbeveiliging zonder extra kosten. U kunt end-to-end gegevensversleuteling instellen, firewallregels configureren, gedetailleerde beveiligingscontroles op rij- en kolomniveau definiëren voor gevoelige gegevens, en meer.
In dit bericht laten we zien hoe u een datawarehouse van Microsoft Azure Synapse naar Redshift Serverless kunt migreren met behulp van AWS Schema Conversie Tool (AWS SCT) en AWS SCT-gegevensextractiemiddelen. AWS SCT maakt heterogene databasemigraties voorspelbaar door de brondatabasecode en opslagobjecten automatisch te converteren naar een formaat dat compatibel is met de doeldatabase. Alle objecten die niet automatisch kunnen worden geconverteerd, worden duidelijk gemarkeerd, zodat ze handmatig kunnen worden geconverteerd om de migratie te voltooien. AWS SCT kan ook uw applicatiecode scannen op ingebedde SQL-instructies en deze converteren.
Overzicht oplossingen
AWS SCT gebruikt een serviceaccount om verbinding te maken met uw Azure Synapse Analytics. Eerst maken we een Redshift-database waarnaar Azure Synapse-gegevens worden gemigreerd. Vervolgens maken we een S3-bucket. Vervolgens gebruiken we AWS SCT om Azure Synapse-schema's te converteren en toe te passen op Amazon Redshift. Ten slotte gebruiken we voor het migreren van gegevens AWS SCT-gegevensextractieagenten, die gegevens uit Azure Synapse extraheren, deze naar een S3-bucket uploaden en naar Amazon Redshift kopiëren.
Het volgende diagram illustreert onze oplossingsarchitectuur.

Deze walkthrough omvat de volgende stappen:
- Creëer een Redshift serverloos datawarehouse.
- Maak de S3-bucket en -map.
- Converteer het Azure Synapse-schema en pas het toe op Amazon Redshift met behulp van AWS SCT:
- Maak verbinding met de Azure Synapse-bron.
- Maak verbinding met het Amazon Redshift-doel.
- Converteer het Azure Synapse-schema naar een Redshift-database.
- Analyseer het assessmentrapport en behandel de actiepunten.
- Pas het geconverteerde schema toe op de doel Redshift-database.
- Migreer gegevens van Azure Synapse naar Amazon Redshift met behulp van AWS SCT-gegevensextractieagenten:
- Genereer vertrouwen en sleutelopslag (deze stap is optioneel).
- Installeer en configureer de gegevensextractieagent.
- Start de gegevensextractieagent.
- Registreer de gegevensextractieagent.
- Voeg virtuele partities toe voor grote tabellen (deze stap is optioneel).
- Maak een lokale gegevensmigratietaak.
- Start de lokale gegevensmigratietaak.
- Bekijk gegevens in Amazon Redshift.
Voorwaarden
Voordat u aan deze walkthrough begint, moet u over de volgende vereisten beschikken:
- Een werkstation met AWS SCT, Amazon Corretto 11en Redshift-stuurprogramma's.
- Een databasegebruikersaccount dat AWS SCT kan gebruiken om verbinding te maken met uw bron-Azure Synapse Analytics-database.
- Verleen VIEW DEFINITION en VIEW DATABASE STATE aan elk schema dat u probeert te converteren naar de databasegebruiker die voor de migratie wordt gebruikt.
Creëer een Redshift serverloos datawarehouse
In deze stap creëren we een Redshift Serverless datawarehouse met een werkgroep en naamruimte. A werkgroep is een verzameling computerbronnen en a namespace is een verzameling databaseobjecten en gebruikers. Om werklasten te isoleren en verschillende bronnen in Redshift Serverless te beheren, kunt u naamruimten en werkgroepen creëren en opslag- en computerbronnen afzonderlijk beheren.
Volg deze stappen om een Redshift Serverless datawarehouse met een werkgroep en naamruimte te maken:
- Kies op de Amazon Redshift-console de AWS-regio die u wilt gebruiken.
- Kies in het navigatievenster Roodverschuiving Serverloos.
- Kies Werkgroep maken.

- Voor Werkgroep naamVoer een naam in die de computerresources beschrijft.

- Controleer of de VPC dezelfde is als de VPC als de EC2-instantie met AWS SCT.
- Kies Volgende.
- Voor namespaceVoer een naam in die uw gegevensset beschrijft.
- In het Databasenaam en wachtwoord sectie, selecteer Pas beheerdersreferenties aan.
- Voor Gebruikersnaam beheerder, voer een gebruikersnaam naar keuze in (bijvoorbeeld
awsuser). - Voor Admin gebruikerswachtwoord, voer een wachtwoord naar keuze in (bijvoorbeeld
MyRedShiftPW2022).
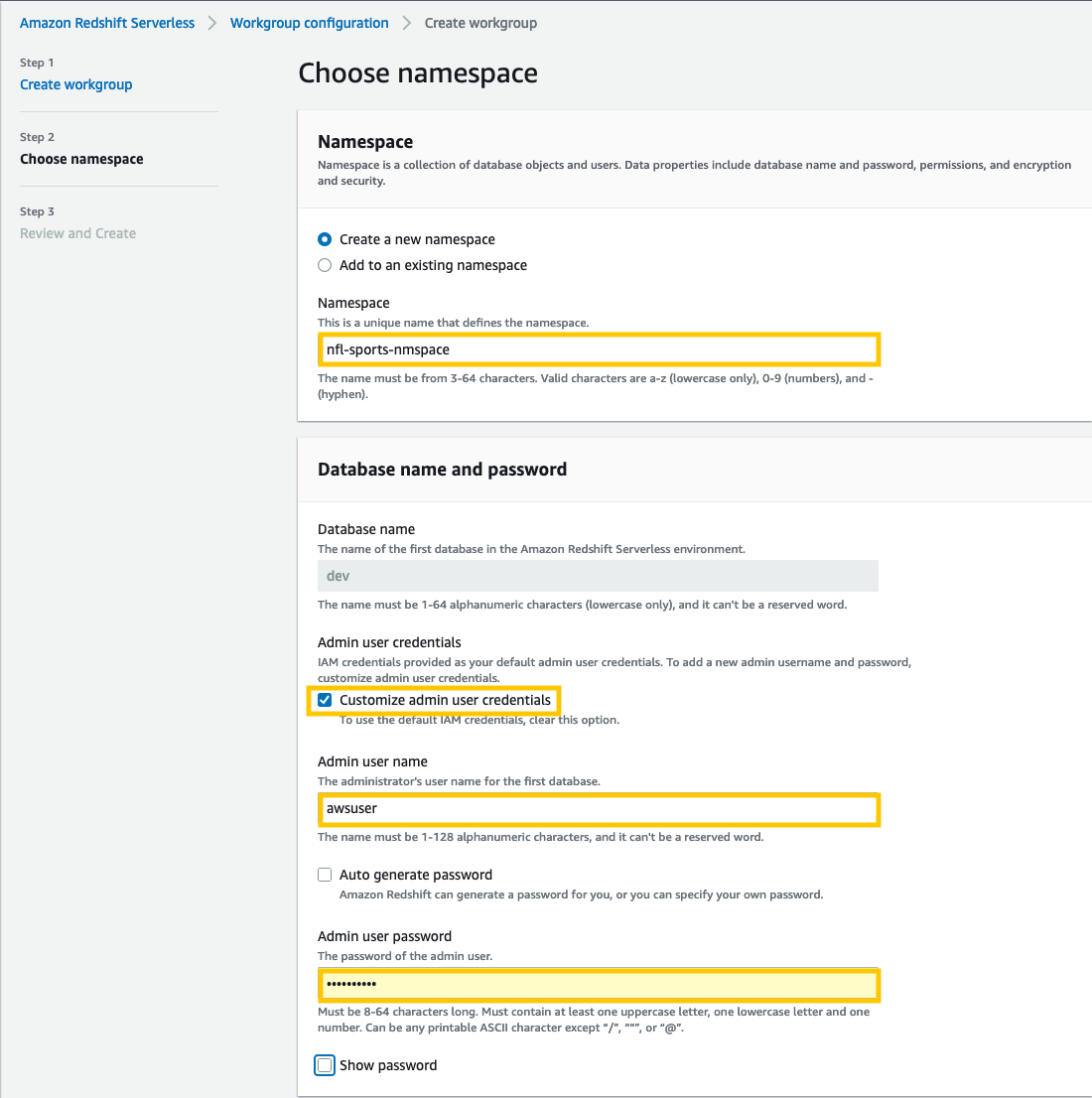
- Kies Volgende.
Houd er rekening mee dat gegevens in de Redshift Serverless-naamruimte standaard worden gecodeerd.
- In het Beoordeel en maak sectie, kies creëren.
Nu maak je een AWS Identiteits- en toegangsbeheer (IAM)-rol en stel deze in als standaard voor uw naamruimte. Houd er rekening mee dat er slechts één standaard IAM-rol kan zijn.
- Op het Redshift Serverless Dashboard, in het Naamruimten / Werkgroepen sectie, kies de naamruimte die u zojuist hebt gemaakt.
- Op de Beveiliging en codering tab, in de machtigingen sectie, kies IAM-rollen beheren.
- Kies IAM-rollen beheren En kies Maak een IAM-rol.
- In het Geef een Amazon S3-bucket op waartoe de IAM-rol toegang moet hebben sectie, kies een van de volgende methoden:
- Kies Geen extra Amazon S3-emmer om de aangemaakte IAM-rol alleen toegang te geven tot de S3-buckets met namen die het woord roodverschuiving bevatten.
- Kies Elke Amazon S3-emmer om de aangemaakte IAM-rol toegang te geven tot alle S3-buckets.
- Kies Specifieke Amazon S3-emmers om een of meer S3-buckets op te geven voor toegang tot de gemaakte IAM-rol. Kies dan één of meerdere S3 emmers uit de tabel.
- Kies IAM-rol als standaard aanmaken.
- Leg het eindpunt vast voor de Redshift Serverless-werkgroep die u zojuist hebt gemaakt.
- Op het Redshift Serverless Dashboard, in het Naamruimten / Werkgroepen sectie, kies de werkgroep die u zojuist hebt gemaakt.
- In het Algemene informatie sectie, kopieer het eindpunt.
Maak de S3-bucket en -map
Tijdens het datamigratieproces gebruikt AWS SCT Amazon S3 als verzamelplaats voor de geëxtraheerde gegevens. Volg deze stappen om een S3-bucket te maken:
- Kies op de Amazon S3-console Emmers in het navigatievenster.
- Kies Maak een bucket.
- Voor Bucketnaam, voert u een unieke DNS-compatibele naam in voor uw bucket (bijvoorbeeld
uniquename-as-rs).
Voor meer informatie over bucketnamen raadpleegt u Regels voor naamgeving van buckets.
- Voor AWS-regio, kies de regio waarin u de Redshift Serverless-werkgroep hebt gemaakt.
- Kies Maak een bucket.

- Kies Emmers in het navigatievenster en navigeer naar de S3-bucket die u zojuist hebt gemaakt (
uniquename-as-rs). - Kies Maak een map.
- Voor Naam van de map, voer inkomend in.
- Kies Maak een map.
Converteer het Azure Synapse-schema en pas het toe op Amazon Redshift met behulp van AWS SCT
Om het Azure Synapse-schema naar het Amazon Redshift-formaat te converteren, gebruiken we AWS SCT. Begin door in te loggen op de EC2-instantie die u eerder hebt gemaakt en start AWS SCT.
Maak verbinding met de Azure Synapse-bron
Voer de volgende stappen uit om verbinding te maken met de Azure Synapse-bron:
- Op de Dien in menu, kies Maak een nieuw project.
- Kies een locatie om uw projectbestanden en gegevens op te slaan.
- Geef een betekenisvolle maar gedenkwaardige naam op voor uw project (bijvoorbeeld Azure Synapse naar Amazon Redshift).
- Als u verbinding wilt maken met het Azure Synapse-brondatawarehouse, kiest u bron toevoegen.
- Kies Azure Synaps En kies Volgende.
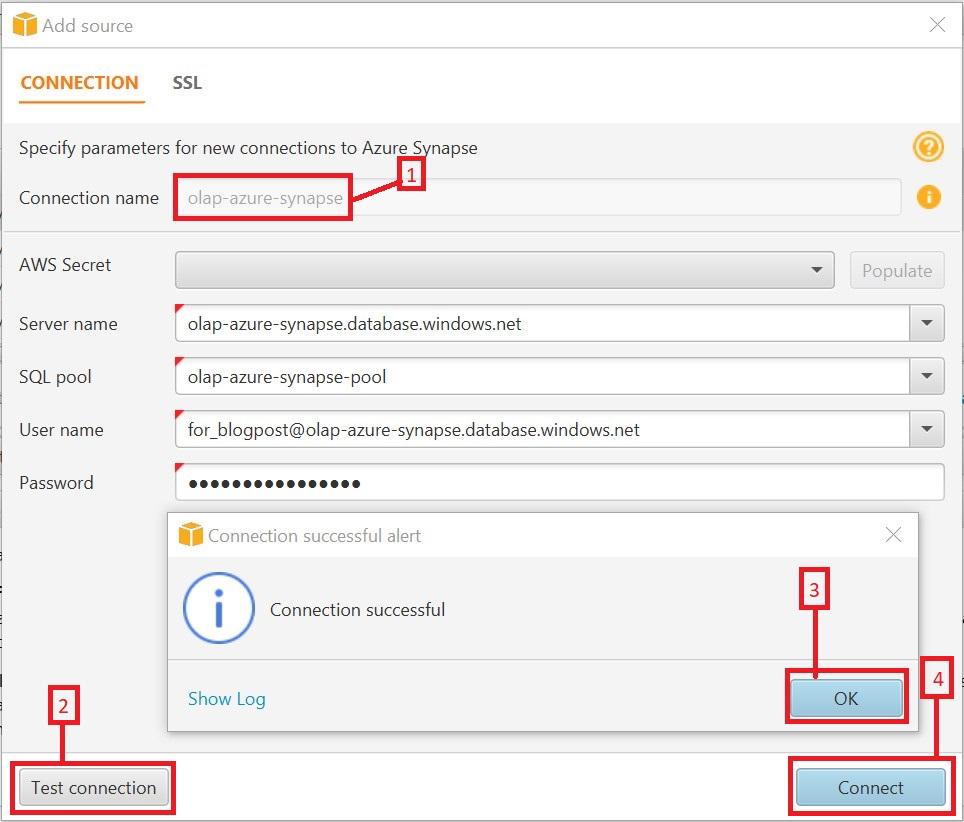
- Voor Verbindingsnaam, voer een naam in (bijvoorbeeld
olap-azure-synapse).
AWS SCT geeft deze naam weer in de objectboom in het linkerdeelvenster.
- Voor Server naamVoer uw Azure Synapse-servernaam in.
- Voor SQL-poolVoer de naam van uw Azure Synapse-pool in.
- Voer een gebruikersnaam en wachtwoord in.
- Kies Test verbinding om te verifiëren dat AWS SCT verbinding kan maken met uw bron-Azure Synapse-project.
- Wanneer de verbinding succesvol is gevalideerd, kiest u Ok en Verbinden.
Maak verbinding met het Amazon Redshift-doel
Volg deze stappen om verbinding te maken met Amazon Redshift:
- Kies in AWS SCT Target toevoegen.
- Kies Amazon roodverschuiving, kies dan Volgende.
- Voor VerbindingsnaamVoer een naam in om de Amazon Redshift-verbinding te beschrijven.
AWS SCT geeft deze naam weer in de objectboom in het rechterdeelvenster.
- Voor Server naam, voer het Redshift Serverless werkgroepeindpunt in dat u eerder hebt vastgelegd.
- Voor Server poort, voer 5439 in.
- Voor Database, voer dev in.
- Voor gebruikersnaamVoer de gebruikersnaam in die u hebt gekozen bij het maken van de Redshift Serverless-werkgroep.
- Voor WachtwoordVoer het wachtwoord in dat u hebt gekozen bij het maken van de Redshift Serverless-werkgroep.
- deselecteren Gebruik AWS-lijm.
- Kies Test verbinding om te verifiëren dat AWS SCT verbinding kan maken met uw doel-Redshift-werkgroep.
- Wanneer de test succesvol is, kiest u OK.
- Kies Verbinden om verbinding te maken met het Amazon Redshift-doelwit.
Als alternatief kunt u verbindingswaarden gebruiken die zijn opgeslagen in AWS-geheimenmanager.

Converteer het Azure Synapse-schema naar een Redshift-datawarehouse
Nadat u de bron- en doelverbindingen hebt gemaakt, ziet u de bron-Azure Synapse-objectstructuur in het linkerdeelvenster en de doel-Amazon Redshift-objectstructuur in het rechterdeelvenster. Vervolgens maken we toewijzingsregels om het brondoelpaar voor de migratie van Azure Synapse naar Amazon Redshift te beschrijven.
Volg deze stappen om de Azure Synapse-gegevensset te converteren naar de Amazon Redshift-indeling:
- Kies (klik met de rechtermuisknop) in het linkerdeelvenster het schema dat u wilt converteren.
- Kies Schema converteren.
- Kies in het dialoogvenster Ja.
Wanneer de conversie is voltooid, ziet u een nieuw schema gemaakt in het deelvenster Amazon Redshift (rechterdeelvenster) met dezelfde naam als uw Azure Synapse-schema.

Het voorbeeldschema dat we gebruikten heeft drie tabellen; je kunt deze objecten in Amazon Redshift-formaat in het rechterdeelvenster zien. AWS SCT converteert alle Azure Synapse-code en gegevensobjecten naar de Amazon Redshift-indeling. U kunt AWS SCT ook gebruiken om externe SQL-scripts, applicatiecode of extra bestanden met ingebedde SQL te converteren.
Analyseer het assessmentrapport en pak de actiepunten aan
AWS SCT maakt een beoordelingsrapport om de complexiteit van de migratie te beoordelen. AWS SCT kan de meeste code- en databaseobjecten converteren, maar voor sommige objecten is mogelijk handmatige conversie vereist. AWS SCT markeert deze objecten in het blauw in het conversiestatistiekendiagram en creëert actie-items waaraan een complexiteit is verbonden.
Om het beoordelingsrapport te bekijken, schakelt u over van Hoofdweergave naar Beoordelingsrapport bekijken zoals weergegeven in de volgende schermafbeelding.

De Samengevat tabblad toont objecten die automatisch zijn geconverteerd en objecten die niet automatisch zijn geconverteerd. Groen staat voor automatisch geconverteerde objecten of objecten met eenvoudige actie-items. Blauw staat voor middelgrote en complexe actiepunten die handmatige tussenkomst vereisen.

De Actie-items op het tabblad worden de aanbevolen acties voor elk conversieprobleem weergegeven. Als u een actie-item uit de lijst kiest, markeert AWS SCT het object waarop het actie-item van toepassing is.

Het rapport bevat ook aanbevelingen voor het handmatig converteren van het schema-item. Nadat de beoordeling is uitgevoerd, laten gedetailleerde rapporten voor de database en het schema u bijvoorbeeld zien hoeveel moeite het kost om de aanbevelingen voor het converteren van actie-items te ontwerpen en te implementeren. Zie voor meer informatie over hoe u handmatige conversies afhandelt Handmatige conversies afhandelen in AWS SCT. AWS SCT voltooit sommige acties automatisch tijdens het converteren van het schema naar Amazon Redshift; objecten met dergelijke acties zijn gemarkeerd met een rood waarschuwingsbord.

U kunt het individuele object DDL evalueren en inspecteren door het in het rechterdeelvenster te selecteren, en u kunt het indien nodig ook bewerken. In het volgende voorbeeld wijzigt AWS SCT het gegevenstype ID-kolom van decimal(3,0) in Azure Synapse naar het gegevenstype smallint in Amazon Redshift.
Pas het geconverteerde schema toe op het doel-Redshift-datawarehouse
Om het geconverteerde schema op Amazon Redshift toe te passen, selecteert u het geconverteerde schema in het rechterdeelvenster, klikt u met de rechtermuisknop en kiest u Toepassen op databank.

Migreer gegevens van Azure Synapse naar Amazon Redshift met behulp van AWS SCT-gegevensextractieagenten
AWS SCT-extractieagenten extraheren gegevens uit uw brondatabase en migreren deze naar de AWS Cloud. In deze sectie configureren we AWS SCT-extractieagenten om gegevens uit Azure Synapse te extraheren en naar Amazon Redshift te migreren. Voor dit bericht installeren we de AWS SCT-extractieagent op dezelfde Windows-instantie waarop AWS SCT is geïnstalleerd. Voor betere prestaties raden we u aan een afzonderlijk Linux-exemplaar te gebruiken om indien mogelijk extractieagentia te installeren. Voor zeer grote datasets ondersteunt AWS SCT het gebruik van meerdere data-extractieagenten die op verschillende instances draaien om de doorvoer te maximaliseren en de snelheid van datamigratie te verhogen.
Genereer vertrouwen en sleutelopslag (optioneel)
U kunt Secure Socket Layer (SSL)-gecodeerde communicatie gebruiken met AWS SCT-gegevensextractors. Wanneer u SSL gebruikt, blijven alle gegevens die tussen de applicaties worden doorgegeven privé en integraal. Om SSL-communicatie te gebruiken, moet u vertrouwen en sleutelopslag genereren met behulp van AWS SCT. U kunt deze stap overslaan als u geen SSL wilt gebruiken. We raden u aan SSL te gebruiken voor productieworkloads.
Volg deze stappen om vertrouwen en belangrijke winkels te genereren:
- Kies in AWS SCT Instellingen, Algemene instellingen en Security.
- Kies Genereer vertrouwen en sleutelopslag.

- Voer een naam en wachtwoord in voor de vertrouwens- en sleutelarchieven.
- Voer een locatie in om ze op te slaan.
- Kies Genereer, kies dan OK.

Installeer en configureer de gegevensextractieagent
In het installatiepakket voor AWS SCT vindt u een submap met de naam agents (aws-schema-conversion-tool-1.0.latest.zipagents). Zoek en installeer het uitvoerbare bestand met een naam als aws-schema-conversion-tool-extractor-xxxxxxxx.msi.

Volg tijdens het installatieproces deze stappen om AWS SCT Data Extractor te configureren:
- Voor ServicepoortVoer het poortnummer in waarop de agent luistert. Standaard is dit 8192.
- Voor Werkende mapVoer het pad in waar de AWS SCT-gegevensextractieagent de geëxtraheerde gegevens zal opslaan.
De werkmap kan zich op een andere computer bevinden dan de agent, en een enkele werkmap kan worden gedeeld door meerdere agenten op verschillende computers.
- Voor Voer Redshift JDBC-stuurprogrammabestand of -bestanden inVoer de locatie in waar u de Redshift JDBC-stuurprogramma's hebt gedownload.
- Voor Voeg het Amazon Redshift-stuurprogramma toe, ga naar binnen
YES. - Voor Schakel SSL-communicatie in, ga naar binnen
yes. InvoerenNohier als u geen SSL wilt gebruiken. - Kies Volgende.

- Voor VertrouwenswinkelpadVoer de opslaglocatie in die u hebt opgegeven bij het maken van de vertrouwens- en sleutelopslag.
- Voor Wachtwoord voor winkel vertrouwen, voer het wachtwoord in voor de trust store.
- Voor SSL-authenticatie voor client inschakelen, ga naar binnen
yes. - Voor Belangrijk winkelpadVoer de opslaglocatie in die u hebt opgegeven bij het maken van de vertrouwens- en sleutelopslag.
- Voor Wachtwoord voor sleutelopslag, voer het wachtwoord voor de sleutelopslag in.
- Kies Volgende.

Start de gegevensextractieagent
Gebruik de volgende procedure om extractiemiddelen te starten. Herhaal deze procedure op elke computer waarop een extractiemiddel is geïnstalleerd.
Extractiemiddelen fungeren als luisteraars. Wanneer u een agent start met deze procedure, begint de agent te luisteren naar instructies. In een latere sectie stuurt u de agenten instructies om gegevens uit uw datawarehouse te extraheren.
Om de extractieagent te starten, navigeert u naar de map AWS SCT Data Extractor Agent. Gebruik bijvoorbeeld in Microsoft Windows C:Program FilesAWS SCT Data Extractor AgentStartAgent.bat.
Op de computer waarop de extractieagent is geïnstalleerd, voert u vanaf een opdrachtprompt of terminalvenster de opdracht uit die voor uw besturingssysteem wordt vermeld. Om een agent te stoppen, voert u dezelfde opdracht uit, maar vervangt u start door stop. Om een agent opnieuw te starten, voert u hetzelfde bestand RestartAgent.bat uit.
Houd er rekening mee dat u beheerderstoegang moet hebben om deze opdrachten uit te voeren.

Registreer de gegevensextractieagent
Volg deze stappen om de gegevensextractieagent te registreren:
- Wijzig in AWS SCT de weergave in Weergave Gegevensmigratie kiezen Registreren.
- kies Roodverschuivingsgegevensagent, kies dan OK.

- Voor OmschrijvingVoer een naam in om de agent te identificeren.
- Voor HostnaamAls u de extractieagent op hetzelfde werkstation als AWS SCT hebt geïnstalleerd, voert u 0.0.0.0 in om de lokale host aan te geven. Voer anders de hostnaam in van de machine waarop de AWS SCT-extractieagent is geïnstalleerd. Het wordt aanbevolen om extractieagenten op Linux te installeren voor betere prestaties.
- Voor HavenVoer het nummer in dat u voor de luisterpoort hebt gebruikt (standaard 8192) bij het installeren van de AWS SCT-extractieagent.
- kies Gebruik SSL om de AWS SCT-verbinding met Data Extraction Agent te coderen.

- Als u SSL gebruikt, navigeert u naar de SSL Tab.
- Voor Vertrouw winkel, kies de truststore die u eerder hebt gemaakt.
- Voor Sleutelwinkel, kies de sleutelopslag die u eerder hebt gemaakt.
- Kies Test verbinding.
- Nadat de verbinding succesvol is gevalideerd, kiest u OK en Registreren.

Maak een lokale gegevensmigratietaak
Om gegevens van Azure Synapse Analytics naar Amazon Redshift te migreren, maakt, voert u en bewaakt u de lokale migratietaak vanuit AWS SCT. Bij deze stap wordt de gegevensextractieagent gebruikt om gegevens te migreren door een taak te maken.
Volg deze stappen om een lokale gegevensmigratietaak te maken:
- Kies in AWS SCT, onder de schemanaam in het linkerdeelvenster, (klik met de rechtermuisknop) de tabel die u wilt migreren (voor dit bericht gebruiken we de tabel
tbl_currency). - Kies Lokale taak maken.

- Kies uit de volgende migratiemodi:
- Extraheer de brongegevens en sla deze op een lokale pc of virtuele machine op waarop de agent draait.
- Extraheer de gegevens en upload deze naar een S3-bucket.
- Pak de gegevens uit, upload deze naar Amazon S3 en kopieer deze naar Amazon Redshift. (We kiezen deze optie voor dit bericht.)

- Op de Geavanceerd tabblad, geef de extractie- en kopieerinstellingen op.

- Op de Bronserver tabblad, zorg ervoor dat u de huidige verbindingseigenschappen gebruikt.

- Op de Amazon S3-instellingen tabblad, voor Amazon S3-bucketmap, geef de bucket- en mapnamen op van de S3-bucket die u eerder hebt gemaakt.
De AWS SCT-gegevensextractieagent uploadt de gegevens in die S3-buckets en -mappen voordat deze naar Amazon Redshift worden gekopieerd.
- Kies Taak testen.

- Wanneer de taak met succes is gevalideerd, kiest u OK, kies dan creëren.

Start de lokale gegevensmigratietaak
Om de taak te starten, kiest u Start or Herstart op de Taken Tab.

Eerst extraheert de gegevensextractieagent gegevens uit Azure Synapse. Vervolgens uploadt de agent gegevens naar Amazon S3 en start een kopieeropdracht om de gegevens naar Amazon Redshift te verplaatsen.
Op dit moment heeft AWS SCT met succes gegevens gemigreerd van de bron-Azure Synapse-tabel naar de Redshift-tabel.

Bekijk gegevens in Amazon Redshift
Nadat de gegevensmigratietaak is voltooid, kunt u verbinding maken met Amazon Redshift en de gegevens valideren. Voer de volgende stappen uit:
- Navigeer op de Amazon Redshift-console naar de Query Editor v2.
- Open de Redshift Serverless-werkgroep die u hebt gemaakt.
- Kies Gegevens opvragen.

- Voor Database, voer een naam in voor uw database.
- Voor authenticatieselecteer Federatieve gebruiker
- Kies Verbinding maken.

- Open een nieuwe editor door het plusteken te kiezen.
- Schrijf in de editor een query om te selecteren uit de schemanaam en de tabel- of weergavenaam die u wilt verifiëren.
U kunt de gegevens verkennen, ad-hocquery's uitvoeren en visualisaties, grafieken en weergaven maken.

De volgende schermafbeelding is de weergave van de bron-Azure Synapse-gegevensset die we in dit bericht hebben gebruikt.

Opruimen
Volg de stappen in deze sectie om alle AWS-bronnen op te ruimen die u als onderdeel van dit bericht hebt gemaakt.
Stop de EC2-instantie
Volg deze stappen om de EC2-instantie te stoppen:
- Kies op de Amazon EC2-console in het navigatievenster Gevallen.
- Selecteer het exemplaar dat u hebt gemaakt.
- Kies Instantie staat, kies dan Beëindig instantie.
- Kies Beëindigen wanneer om bevestiging wordt gevraagd.
Verwijder de Redshift Serverless-werkgroep en naamruimte
Volg deze stappen om de Redshift Serverless-werkgroep en naamruimte te verwijderen:
- Op het Redshift Serverless Dashboard, in het Naamruimten / Werkgroepen sectie, kies de werkruimte die u hebt gemaakt
- Op de Acties menu, kies Werkgroep verwijderen.
- kies Verwijder de bijbehorende naamruimte.
- deselecteren Maak een definitieve momentopname.
- Voer verwijderen in het bevestigingstekstvak in en kies Verwijder.
Verwijder de S3-bucket
Volg deze stappen om de S3-bucket te verwijderen:
- Kies op de Amazon S3-console Emmers in het navigatievenster.
- Kies de bucket die je hebt gemaakt.
- Kies Verwijder.
- Om de verwijdering te bevestigen, voert u de naam van de bucket in.
- Kies Emmer verwijderen.
Conclusie
Het migreren van een datawarehouse kan een uitdagend, complex en toch lonend project zijn. AWS SCT vermindert de complexiteit van datawarehouse-migraties. In dit bericht wordt besproken hoe een gegevensmigratietaak gegevens van Azure Synapse naar Amazon Redshift extraheert, downloadt en migreert. De oplossing die we presenteerden voert een eenmalige migratie van databaseobjecten en gegevens uit. Gegevenswijzigingen die in Azure Synapse worden aangebracht wanneer de migratie wordt uitgevoerd, worden niet weerspiegeld in Amazon Redshift. Wanneer de gegevensmigratie bezig is, zet u uw ETL-taken naar Azure Synapse in de wacht of voert u de ETL-taken opnieuw uit door na de migratie naar Amazon Redshift te verwijzen. Overweeg het gebruik van de best practices voor AWS SCT.
Starten, download en installeer AWS SCT, log in op de AWS-beheerconsole, bekijk Redshift Serverless en begin met migreren!
Over de auteurs
 Ahmed Shehat is een Senior Analytics Specialist Solutions Architect bij AWS in Toronto. Hij heeft meer dan twintig jaar ervaring met het helpen van klanten bij het moderniseren van hun dataplatforms. Ahmed is gepassioneerd om klanten te helpen bij het bouwen van efficiënte, performante en schaalbare analytische oplossingen.
Ahmed Shehat is een Senior Analytics Specialist Solutions Architect bij AWS in Toronto. Hij heeft meer dan twintig jaar ervaring met het helpen van klanten bij het moderniseren van hun dataplatforms. Ahmed is gepassioneerd om klanten te helpen bij het bouwen van efficiënte, performante en schaalbare analytische oplossingen.
 Jagadische Kumar is een Senior Analytics Specialist Solutions Architect bij AWS gericht op Amazon Redshift. Hij heeft een grote passie voor data-architectuur en helpt klanten bij het bouwen van analytische oplossingen op schaal op AWS.
Jagadische Kumar is een Senior Analytics Specialist Solutions Architect bij AWS gericht op Amazon Redshift. Hij heeft een grote passie voor data-architectuur en helpt klanten bij het bouwen van analytische oplossingen op schaal op AWS.
 Anusha Challa is een Senior Analytics Specialist Solution Architect bij AWS gericht op Amazon Redshift. Ze heeft veel klanten geholpen bij het bouwen van grootschalige datawarehouse-oplossingen in de cloud en op locatie. Anusha heeft een passie voor data-analyse en datawetenschap en zorgt ervoor dat klanten succes kunnen behalen met hun grootschalige dataprojecten.
Anusha Challa is een Senior Analytics Specialist Solution Architect bij AWS gericht op Amazon Redshift. Ze heeft veel klanten geholpen bij het bouwen van grootschalige datawarehouse-oplossingen in de cloud en op locatie. Anusha heeft een passie voor data-analyse en datawetenschap en zorgt ervoor dat klanten succes kunnen behalen met hun grootschalige dataprojecten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/migrate-microsoft-azure-synapse-analytics-to-amazon-redshift-using-aws-sct/

