Volksgezondheidsorganisaties beschikken over een schat aan gegevens over verschillende soorten ziekten, gezondheidstrends en risicofactoren. Hun personeel gebruikt al lang statistische modellen en regressieanalyses om belangrijke beslissingen te nemen, zoals het richten op populaties met de hoogste risicofactoren voor een ziekte met therapieën, of het voorspellen van de voortgang van zorgwekkende uitbraken.
Wanneer er bedreigingen voor de volksgezondheid ontstaan, neemt de datasnelheid toe, kunnen inkomende datasets groter worden en wordt databeheer een grotere uitdaging. Dit maakt het moeilijker om gegevens holistisch te analyseren en er inzichten uit te halen. En wanneer tijd van essentieel belang is, zijn snelheid en behendigheid bij het analyseren van gegevens en het daaruit halen van inzichten belangrijke belemmeringen voor het vormen van snelle en robuuste gezondheidsreacties.
Typische vragen waarmee volksgezondheidsorganisaties in tijden van stress worden geconfronteerd, zijn onder meer:
- Zal er op een bepaalde locatie voldoende therapie aanwezig zijn?
- Welke risicofactoren bepalen de gezondheidsresultaten?
- Welke bevolkingsgroepen hebben een hoger risico op herinfectie?
Omdat het beantwoorden van deze vragen inzicht vereist in complexe relaties tussen veel verschillende factoren - vaak veranderende en dynamische - is machine learning (ML) een krachtige tool die we tot onze beschikking hebben, die kan worden ingezet om deze complexe kwantitatieve problemen te analyseren, te voorspellen en op te lossen. We zien ML steeds vaker worden toegepast om moeilijke gezondheidsproblemen aan te pakken, zoals hersentumoren classificeren met beeldanalyse en het voorspellen van de behoefte aan geestelijke gezondheid programma's voor vroegtijdige interventie in te zetten.
Maar wat gebeurt er als volksgezondheidsorganisaties een tekort hebben aan de vaardigheden die nodig zijn om ML op deze vragen toe te passen? De toepassing van ML op volksgezondheidsproblemen wordt belemmerd en volksgezondheidsorganisaties verliezen het vermogen om krachtige kwantitatieve instrumenten toe te passen om hun uitdagingen aan te pakken.
Hoe kunnen we deze knelpunten dan wegnemen? Het antwoord is om ML te democratiseren en een groter aantal gezondheidswerkers met diepgaande domeinexpertise in staat te stellen het te gebruiken en toe te passen op de vragen die ze willen oplossen.
Amazon SageMaker-canvas is een ML-tool zonder code die professionals in de volksgezondheid, zoals epidemiologen, informatici en biostatistici, in staat stelt ML toe te passen op hun vragen, zonder dat een achtergrond in datawetenschap of ML-expertise vereist is. Ze kunnen hun tijd aan de gegevens besteden, hun domeinexpertise toepassen, snel hypothesen testen en inzichten kwantificeren. Canvas helpt de volksgezondheid rechtvaardiger te maken door ML te democratiseren, gezondheidsexperts in staat te stellen grote datasets te evalueren en hen te voorzien van geavanceerde inzichten met behulp van ML.
In dit bericht laten we zien hoe deskundigen op het gebied van volksgezondheid de komende 30 dagen de beschikbare vraag naar een bepaald geneesmiddel kunnen voorspellen met behulp van Canvas. Canvas biedt je een visuele interface waarmee je zelf nauwkeurige ML-voorspellingen kunt genereren zonder dat je enige ML-ervaring nodig hebt of een enkele regel code hoeft te schrijven.
Overzicht oplossingen
Stel dat we werken aan gegevens die we hebben verzameld van staten in de VS. We kunnen een hypothese vormen dat een bepaalde gemeente of locatie de komende weken niet over voldoende therapieën beschikt. Hoe kunnen we dit snel en met een hoge mate van nauwkeurigheid testen?
Voor dit bericht gebruiken we een openbaar beschikbare dataset van het Amerikaanse ministerie van Volksgezondheid en Human Services, die door de staat geaggregeerde tijdreeksgegevens bevat met betrekking tot COVID-19, inclusief ziekenhuisgebruik, beschikbaarheid van bepaalde therapieën en nog veel meer. De dataset (COVID-19 Gerapporteerde patiëntimpact en ziekenhuiscapaciteit door State Timeseries (RAW)) kan worden gedownload van healthdata.gov en heeft 135 kolommen en meer dan 60,000 rijen. De dataset wordt periodiek bijgewerkt.
In de volgende secties laten we zien hoe u verkennende gegevensanalyse en -voorbereiding kunt uitvoeren, het ML-prognosemodel kunt bouwen en voorspellingen kunt genereren met Canvas.
Verkennende data-analyse en voorbereiding uitvoeren
Wanneer we een tijdreeksvoorspelling doen in Canvas, moeten we het aantal functies of kolommen verminderen op basis van de servicequota. In eerste instantie verminderen we het aantal kolommen tot de 12 die waarschijnlijk het meest relevant zijn. We hebben bijvoorbeeld de leeftijdsspecifieke kolommen weggelaten omdat we de totale vraag willen voorspellen. We hebben ook kolommen verwijderd waarvan de gegevens vergelijkbaar waren met andere kolommen die we bewaarden. In toekomstige iteraties is het redelijk om te experimenteren met het behouden van andere kolommen en het gebruik van functie-uitlegbaarheid in Canvas om het belang van deze functies te kwantificeren en die we willen behouden. We hernoemen ook de state kolom naar location.
Als we naar de dataset kijken, besluiten we ook om alle rijen voor 2020 te verwijderen, omdat er op dat moment beperkte therapieën beschikbaar waren. Hierdoor kunnen we de ruis verminderen en de kwaliteit van de gegevens verbeteren waar het ML-model van kan leren.
Het verminderen van het aantal kolommen kan op verschillende manieren. Je kunt de dataset bewerken in een spreadsheet of rechtstreeks in Canvas met behulp van de gebruikersinterface.
Je kunt gegevens in Canvas importeren vanuit verschillende bronnen, waaronder lokale bestanden van je computer, Amazon eenvoudige opslagservice (Amazon S3) emmers, Amazone Athene, Sneeuwvlok (Zie Bereid een trainings- en validatiedataset voor voor faciesclassificatie met behulp van Snowflake-integratie en train met Amazon SageMaker Canvas), En meer dan 40 aanvullende gegevensbronnen.
Nadat onze gegevens zijn geïmporteerd, kunnen we onze gegevens verkennen en visualiseren om er aanvullende inzichten in te krijgen, zoals met spreidingsdiagrammen of staafdiagrammen. We kijken ook naar de correlatie tussen verschillende functies om ervoor te zorgen dat we hebben geselecteerd wat volgens ons de beste zijn. De volgende schermafbeelding toont een voorbeeldvisualisatie.

Bouw het ML-prognosemodel
Nu zijn we klaar om ons model te maken, wat we met slechts een paar klikken kunnen doen. We kiezen de kolom met beschikbare therapieën als ons doelwit. Canvas identificeert ons probleem automatisch als een tijdreeksprognose op basis van de doelkolom die we zojuist hebben geselecteerd, en we kunnen de benodigde parameters configureren.
Wij configureren de item_id, de unieke identificator, als locatie omdat onze dataset wordt geleverd door locatie (Amerikaanse staten). Omdat we een tijdreeksprognose maken, moeten we een tijdstempel selecteren date in onze dataset. Ten slotte specificeren we hoeveel dagen in de toekomst we willen voorspellen (voor dit voorbeeld kiezen we 30 dagen). Canvas biedt ook de mogelijkheid om een vakantieschema op te nemen om de nauwkeurigheid te verbeteren. In dit geval gebruiken we Amerikaanse feestdagen omdat dit een op de VS gebaseerde dataset is.
Met Canvas kun je inzichten uit je gegevens halen voordat je een model bouwt door te kiezen Voorbeeldmodel. Dit bespaart u tijd en kosten door geen model te bouwen als de resultaten waarschijnlijk niet bevredigend zijn. Door een voorbeeld van ons model te bekijken, realiseren we ons dat de impact van sommige kolommen laag is, wat betekent dat de verwachte waarde van de kolom voor het model laag is. We verwijderen kolommen door ze te deselecteren in Canvas (rode pijlen in de volgende schermafbeelding) en zien een verbetering in een geschatte kwaliteitsstatistiek (groene pijl).

Als we verder gaan met het bouwen van ons model, hebben we twee opties, Snel gebouwd en Standaard gebouwd. Snel bouwen produceert een getraind model in minder dan 20 minuten, waarbij snelheid boven nauwkeurigheid gaat. Dit is geweldig om te experimenteren en is een grondiger model dan het voorbeeldmodel. Standaard build produceert een getraind model in minder dan 4 uur, waarbij nauwkeurigheid prioriteit krijgt boven latentie, waarbij een aantal modelconfiguraties wordt herhaald om automatisch het beste model te selecteren.
Eerst experimenteren we met Snel bouwen om onze modelpreview te valideren. Omdat we tevreden zijn met het model, kiezen we vervolgens voor Standard build om Canvas te laten helpen bij het bouwen van het best mogelijke model voor onze dataset. Als het Quick build-model onbevredigende resultaten had opgeleverd, zouden we teruggaan en de invoergegevens aanpassen om een hoger niveau van nauwkeurigheid vast te leggen. Dit kunnen we bijvoorbeeld doen door kolommen of rijen toe te voegen of te verwijderen in onze originele dataset. Het Quick build-model ondersteunt snelle experimenten zonder dat u hoeft te vertrouwen op schaarse gegevenswetenschappelijke bronnen of hoeft te wachten tot een volledig model is voltooid.
Voorspellingen genereren
Nu het model gebouwd is, kunnen we de beschikbaarheid van therapieën voorspellen door location. Laten we eens kijken hoe onze geschatte voorhanden voorraad eruit ziet voor de komende 30 dagen, in dit geval voor Washington, DC.
Canvas voert probabilistische voorspellingen uit voor de therapeutische vraag, waardoor we zowel de mediaanwaarde als de boven- en ondergrenzen kunnen begrijpen. In de volgende schermafbeelding ziet u het einde van de historische gegevens (de gegevens uit de originele gegevensset). U ziet dan drie nieuwe lijnen: de mediaan (50e kwantiel) voorspeld in paars, de ondergrens (10e kwantiel) in lichtblauw en bovengrens (90e kwantiel) in donkerblauw.
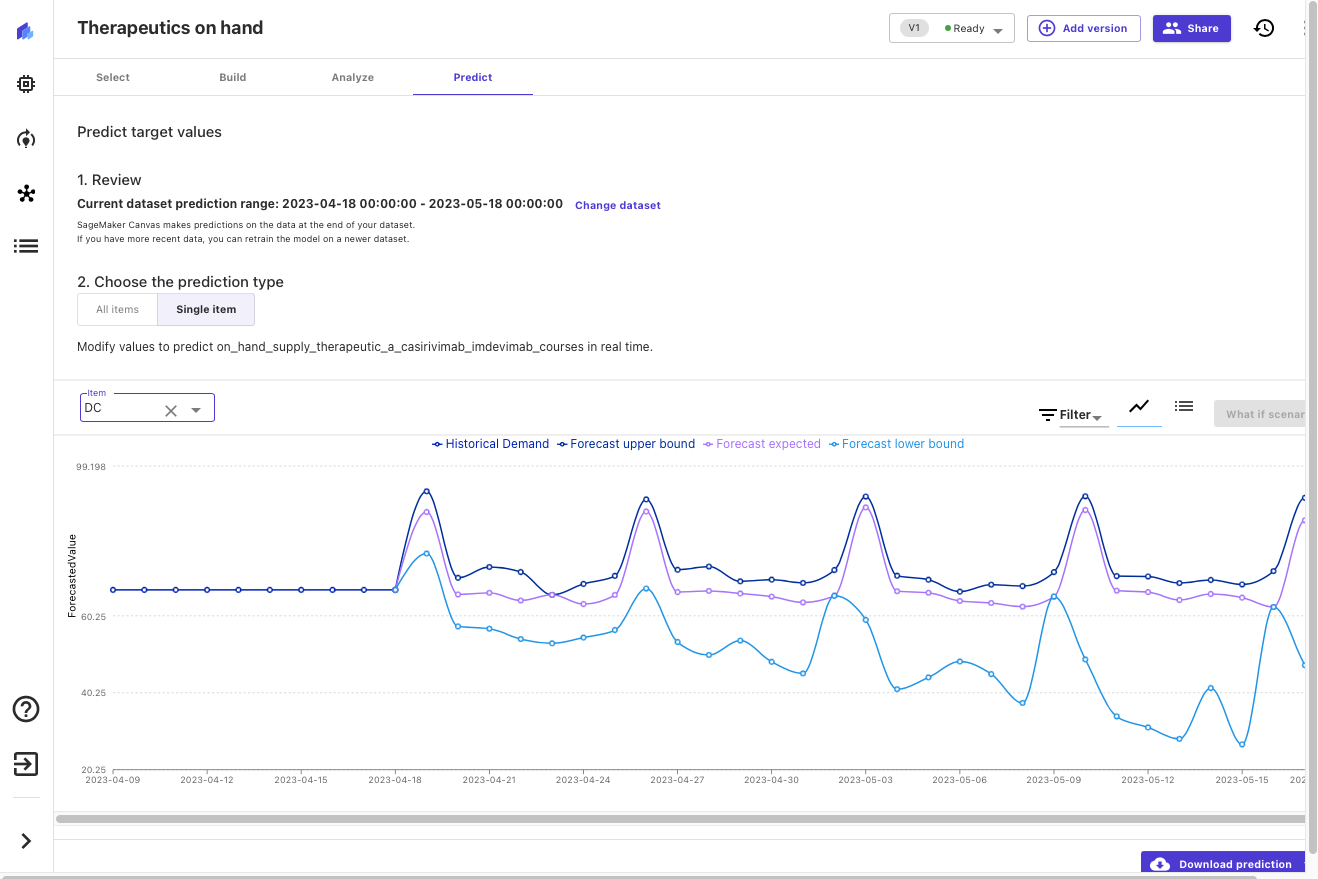
Het onderzoeken van boven- en ondergrenzen geeft inzicht in de waarschijnlijkheidsverdeling van de prognose en stelt ons in staat weloverwogen beslissingen te nemen over de gewenste niveaus van lokale inventarisatie voor dit geneesmiddel. We kunnen dit inzicht toevoegen aan andere gegevens (bijvoorbeeld prognoses van ziekteprogressie of therapeutische werkzaamheid en opname) om weloverwogen beslissingen te nemen over toekomstige bestellingen en voorraadniveaus.
Conclusie
No-code ML-tools stellen volksgezondheidsexperts in staat om ML snel en effectief toe te passen op bedreigingen voor de volksgezondheid. Deze democratisering van ML maakt volksgezondheidsorganisaties wendbaarder en efficiënter in hun missie om de volksgezondheid te beschermen. Ad-hocanalyses die belangrijke trends of omslagpunten in volksgezondheidsproblemen kunnen identificeren, kunnen nu rechtstreeks door specialisten worden uitgevoerd, zonder dat ze hoeven te concurreren om beperkte ML-expertbronnen en de reactietijden en besluitvorming vertragen.
In dit bericht hebben we laten zien hoe iemand zonder enige kennis van ML Canvas kan gebruiken om de voorhanden voorraad van een bepaald therapeutisch middel te voorspellen. Deze analyse kan worden uitgevoerd door elke analist in het veld, dankzij de kracht van cloudtechnologieën en no-code ML. Hierdoor worden capaciteiten breed gedistribueerd en kunnen volksgezondheidsinstanties sneller reageren en efficiënter gebruik maken van gecentraliseerde en veldkantoormiddelen om betere resultaten op het gebied van volksgezondheid te behalen.
Wat zijn enkele van de vragen die u mogelijk stelt, en hoe kunnen low-code/no-code-tools u helpen deze te beantwoorden? Als je meer wilt weten over Canvas, ga dan naar Amazon SageMaker-canvas en begin ML toe te passen op uw eigen kwantitatieve gezondheidsvragen.
Over de auteurs
 Hendrik Balle is een Sr. Solutions Architect bij AWS die de Amerikaanse publieke sector ondersteunt. Hij werkt nauw samen met klanten aan uiteenlopende onderwerpen, van machine learning tot beveiliging en governance op grote schaal. In zijn vrije tijd houdt hij van wielrennen, motorrijden, of je kunt hem zien werken aan weer een ander project voor het verbeteren van je huis.
Hendrik Balle is een Sr. Solutions Architect bij AWS die de Amerikaanse publieke sector ondersteunt. Hij werkt nauw samen met klanten aan uiteenlopende onderwerpen, van machine learning tot beveiliging en governance op grote schaal. In zijn vrije tijd houdt hij van wielrennen, motorrijden, of je kunt hem zien werken aan weer een ander project voor het verbeteren van je huis.
 Dan Sinnreich leads Ga naar Market-productbeheer voor Amazon SageMaker Canvas en Amazon Forecast. Hij richt zich op het democratiseren van low-code/no-code machine learning en het toepassen ervan om bedrijfsresultaten te verbeteren. Voorafgaand aan AWS bouwde Dan enterprise SaaS-platforms en tijdreeksrisicomodellen die door institutionele beleggers worden gebruikt om risico's te beheren en portefeuilles samen te stellen. Buiten zijn werk speelt hij hockey, duikt, reist en leest hij sciencefiction.
Dan Sinnreich leads Ga naar Market-productbeheer voor Amazon SageMaker Canvas en Amazon Forecast. Hij richt zich op het democratiseren van low-code/no-code machine learning en het toepassen ervan om bedrijfsresultaten te verbeteren. Voorafgaand aan AWS bouwde Dan enterprise SaaS-platforms en tijdreeksrisicomodellen die door institutionele beleggers worden gebruikt om risico's te beheren en portefeuilles samen te stellen. Buiten zijn werk speelt hij hockey, duikt, reist en leest hij sciencefiction.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/capture-public-health-insights-more-quickly-with-no-code-machine-learning-using-amazon-sagemaker-canvas/

