
Afbeelding door auteur
In de afgelopen paar maanden Grote taalmodellen (LLM's) hebben veel aandacht gekregen en hebben de interesse gewekt van ontwikkelaars over de hele wereld. Deze modellen hebben spannende vooruitzichten gecreëerd, vooral voor ontwikkelaars die werken aan chatbots, persoonlijke assistenten en het maken van inhoud. De mogelijkheden die LLM's met zich meebrengen, hebben een golf van enthousiasme aangewakkerd bij de ontwikkelaar | KI | NLP-gemeenschap.
Large Language Models (LLM's) verwijzen naar machine learning-modellen die in staat zijn om tekst te produceren die sterk lijkt op menselijke taal en om prompts op een natuurlijke manier te begrijpen. Deze modellen worden getraind met behulp van uitgebreide datasets bestaande uit boeken, artikelen, websites en andere bronnen. Door statistische patronen binnen de gegevens te analyseren, voorspellen LLM's de meest waarschijnlijke woorden of zinsdelen die op een bepaalde invoer zouden moeten volgen.
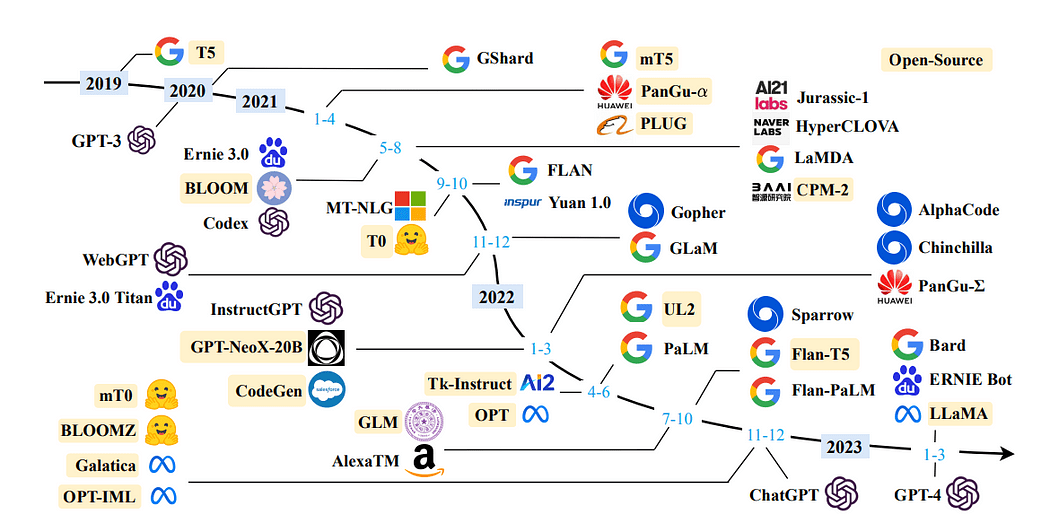
Een tijdlijn van LLM's in de afgelopen jaren: Een overzicht van grote taalmodellen
Door gebruik te maken van Large Language Models (LLM's), kunnen we domeinspecifieke gegevens opnemen om vragen effectief te beantwoorden. Dit wordt vooral voordelig bij het omgaan met informatie die niet toegankelijk was voor het model tijdens de initiële training, zoals de interne documentatie van een bedrijf of een kennisopslagplaats.
De architectuur die hiervoor wordt gebruikt, staat bekend als Generatie van ophaalaugmentatie of, minder vaak, Generatieve vraag beantwoorden.
LangChain is een indrukwekkend en vrij beschikbaar raamwerk dat zorgvuldig is ontworpen om ontwikkelaars in staat te stellen applicaties te maken die worden gevoed door de kracht van taalmodellen, met name grote taalmodellen (LLM's).
LangChain zorgt voor een revolutie in het ontwikkelingsproces van een breed scala aan applicaties, waaronder chatbots, Generative Question-Answering (GQA) en samenvattingen. Door naadloos chaining door componenten uit meerdere modules samen te voegen, maakt LangChain het mogelijk om uitzonderlijke applicaties te creëren die zijn toegesneden op de kracht van LLM's.
Lees verder: Officiële documentatie
Afbeelding door auteur
In dit artikel zal ik het proces demonstreren van het maken van uw eigen Document Assistant vanaf de basis, met behulp van LLaMA 7b en Langchain, een open-sourcebibliotheek die speciaal is ontwikkeld voor naadloze integratie met LLM's.
Hier is een overzicht van de structuur van de blog, met een overzicht van de specifieke secties die een gedetailleerd overzicht van het proces geven:
Setting up the virtual environment and creating file structureGetting LLM on your local machineIntegrating LLM with LangChain and customizing PromptTemplateDocument Retrieval and Answer GenerationBuilding application using Streamlit
Het opzetten van een virtuele omgeving biedt een gecontroleerde en geïsoleerde omgeving voor het uitvoeren van de toepassing, waarbij ervoor wordt gezorgd dat de afhankelijkheden gescheiden zijn van andere systeembrede pakketten. Deze aanpak vereenvoudigt het beheer van afhankelijkheden en helpt de consistentie in verschillende omgevingen te behouden.
Om de virtuele omgeving voor deze applicatie in te stellen, zal ik het pip-bestand in mijn GitHub-repository leveren. Laten we eerst de benodigde bestandsstructuur maken zoals weergegeven in de afbeelding. Als alternatief kunt u eenvoudig de repository klonen om de vereiste bestanden te verkrijgen.
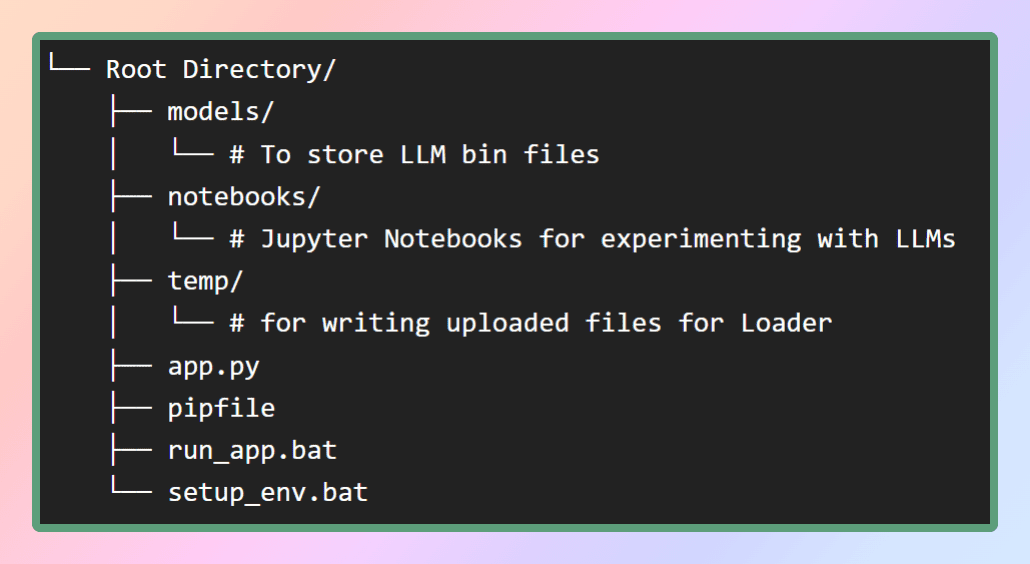
Afbeelding op auteur: bestandsstructuur
In de map van de modellen slaan we de LLM's op die we zullen downloaden, terwijl het pip-bestand zich in de hoofdmap bevindt.
Om de virtuele omgeving te creëren en alle afhankelijkheden erin te installeren, kunnen we de pipenv installcommando vanuit dezelfde map of gewoon uitvoeren setup_env.bat batch-bestand, het zal alle afhankelijkheden van het pipfile. Dit zorgt ervoor dat alle benodigde pakketten en bibliotheken in de virtuele omgeving worden geïnstalleerd. Zodra de afhankelijkheden met succes zijn geïnstalleerd, kunnen we doorgaan naar de volgende stap, waarbij de gewenste modellen worden gedownload. Hier is de repo.
Wat is LLaMA?
LLaMA is een nieuw groot taalmodel ontworpen door Meta AI, het moederbedrijf van Facebook. Met een diverse verzameling modellen, variërend van 7 miljard tot 65 miljard parameters, onderscheidt LLaMA zich als een van de meest uitgebreide beschikbare taalmodellen. Op 24 februari 2023 bracht Meta het LLaMA-model uit voor het publiek, waarmee ze hun toewijding aan open wetenschap aantoonden.
Bron afbeelding: Lama
Gezien de opmerkelijke mogelijkheden van LLaMA, hebben we ervoor gekozen om dit krachtige taalmodel voor onze doeleinden te gebruiken. Concreet zullen we de kleinste versie van LLaMA gebruiken, bekend als LLaMA 7B. Zelfs bij deze kleinere omvang biedt LLaMA 7B aanzienlijke taalverwerkingsmogelijkheden, waardoor we onze gewenste resultaten efficiënt en effectief kunnen bereiken.
Officieel onderzoeksdocument :
LLaMA: Open and Efficient Foundation Language Models
Om de LLM op een lokale CPU uit te voeren, hebben we een lokaal model in GGML-indeling nodig. Dit kan op verschillende manieren worden bereikt, maar de eenvoudigste manier is om het bin-bestand rechtstreeks vanuit het Hugging Face Models-repository. In ons geval downloaden we het Llama 7B-model. Deze modellen zijn open-source en kunnen gratis worden gedownload.
Als u tijd en moeite wilt besparen, hoeft u zich geen zorgen te maken - ik heb u gedekt. Hier is de directe link om de modellen te downloaden ?. Download gewoon een willekeurige versie ervan en verplaats het bestand vervolgens naar de modellenmap in onze hoofdmap. Op deze manier heeft u het model gemakkelijk toegankelijk voor uw gebruik.
Wat is GGML? Waarom GGML? Hoe GGML? LLaMA CPP
GGML is een Tensor-bibliotheek voor machine learning, het is slechts een C++-bibliotheek waarmee u LLM's alleen op de CPU of CPU + GPU kunt uitvoeren. Het definieert een binair formaat voor het verspreiden van grote taalmodellen (LLM's). GGML maakt gebruik van een techniek genaamd kwantisering waarmee grote taalmodellen op consumentenhardware kunnen worden uitgevoerd.
Wat is nu kwantisatie?
LLM-gewichten zijn getallen met drijvende komma (decimaal). Net zoals er meer ruimte nodig is om een groot geheel getal (bijv. 1000) weer te geven in vergelijking met een klein geheel getal (bijv. 1), is er meer ruimte nodig om een uiterst nauwkeurig drijvend getal weer te geven (bijv. 0.0001) in vergelijking met een laag nauwkeurig drijvend getal (bijv. 0.1). Het proces van kwantiseren een groot taalmodel omvat het verminderen van de precisie waarmee gewichten worden weergegeven om de middelen te verminderen die nodig zijn om het model te gebruiken. GGML ondersteunt een aantal verschillende kwantiseringsstrategieën (bijv. 4-bits, 5-bits en 8-bits kwantisatie), die elk verschillende afwegingen tussen efficiëntie en prestaties bieden.
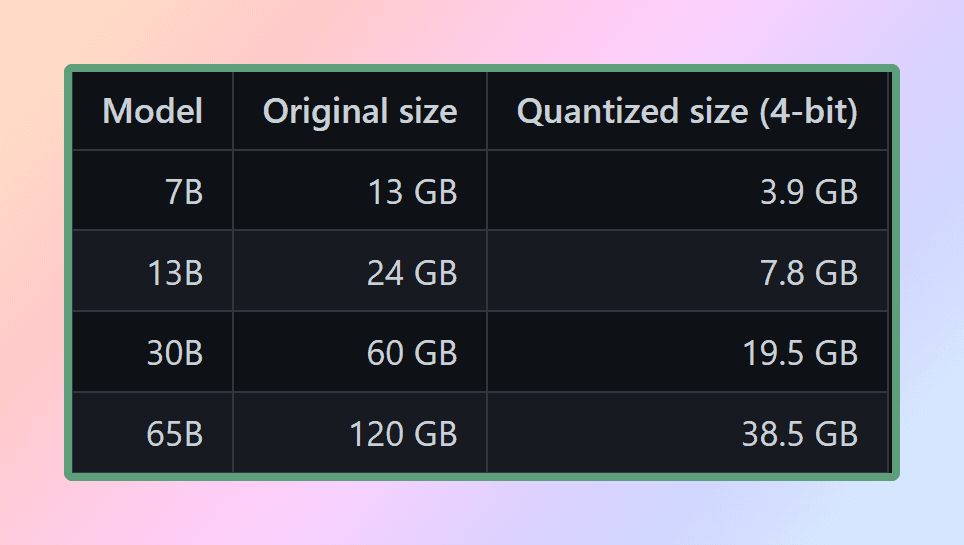
Gekwantiseerde grootte van lama
Om de modellen effectief te gebruiken, is het essentieel om rekening te houden met de geheugen- en schijfvereisten. Aangezien de modellen momenteel volledig in het geheugen worden geladen, hebt u voldoende schijfruimte nodig om ze op te slaan en voldoende RAM om ze tijdens de uitvoering te laden. Als het gaat om het 65B-model, is het zelfs na kwantisering aan te raden om minimaal 40 gigabyte RAM beschikbaar te hebben. Het is vermeldenswaard dat de geheugen- en schijfvereisten momenteel gelijk zijn.
Kwantisering speelt een cruciale rol bij het beheersen van deze behoefte aan hulpbronnen. Tenzij je toegang hebt tot uitzonderlijke rekenbronnen
Door de precisie van de parameters van het model te verminderen en het geheugengebruik te optimaliseren, kunnen de modellen met kwantisering worden gebruikt op meer bescheiden hardwareconfiguraties. Dit zorgt ervoor dat het uitvoeren van de modellen haalbaar en efficiënt blijft voor een breder scala aan opstellingen.
Hoe gebruiken we het in Python als het een C++-bibliotheek is?
Dat is waar Python-bindingen in het spel komen. Binding verwijst naar het proces van het creëren van een brug of interface tussen twee talen voor ons python en C++. We zullen gebruiken llama-cpp-python dat is een Python-binding voor llama.cpp die fungeert als een gevolgtrekking van het LLaMA-model in pure C/C++. Het belangrijkste doel van llama.cpp is om het LLaMA-model uit te voeren met behulp van 4-bit integer kwantisering. Deze integratie stelt ons in staat om effectief gebruik te maken van het LLaMA-model, gebruikmakend van de voordelen van C/C++-implementatie en de voordelen van 4-bit integer-kwantisering

Ondersteunde modellen door lama.cpp: bron
Nu het GGML-model is voorbereid en al onze afhankelijkheden aanwezig zijn (dankzij het pipfile), is het tijd om aan onze reis met LangChain te beginnen. Maar voordat we in de opwindende wereld van LangChain duiken, laten we beginnen met het gebruikelijke "Hallo Wereld" ritueel — een traditie die we volgen wanneer we een nieuwe taal of een nieuw kader verkennen, LLM is tenslotte ook een taalmodel.

Afbeelding door auteur: interactie met LLM op CPU
Voila !!! We hebben met succes onze eerste LLM op de CPU uitgevoerd, volledig offline en op een volledig willekeurige manier (je kunt spelen met de hyper param temperatuur-).
Nu deze opwindende mijlpaal is bereikt, zijn we nu klaar om aan ons hoofddoel te beginnen: het beantwoorden van vragen van aangepaste tekst met behulp van het LangChain-framework.
In het laatste gedeelte hebben we LLM geïnitialiseerd met lama cpp. Laten we nu het LangChain-framework gebruiken om applicaties te ontwikkelen met behulp van LLM's. De primaire interface waarmee u met hen kunt communiceren, is via tekst. Als oversimplificatie zijn veel modellen dat wel tekst in, tekst uit. Daarom zijn veel van de interfaces in LangChain gecentreerd rond de tekst.
De opkomst van snelle engineering
In het steeds evoluerende gebied van programmeren is een fascinerend paradigma ontstaan: Prompt. Prompting omvat het leveren van specifieke input aan een taalmodel om een gewenst antwoord uit te lokken. Deze innovatieve aanpak stelt ons in staat om de output van het model vorm te geven op basis van de input die we leveren.
Het is opmerkelijk hoe de nuances in de manier waarop we een prompt formuleren, een grote invloed kunnen hebben op de aard en inhoud van de reactie van het model. De uitkomst kan fundamenteel variëren op basis van de formulering, wat het belang benadrukt van zorgvuldige overweging bij het formuleren van aanwijzingen.
Om naadloze interactie met LLM's te bieden, biedt LangChain verschillende klassen en functies om het construeren van en werken met prompts eenvoudig te maken met behulp van een promptsjabloon. Het is een reproduceerbare manier om een prompt te genereren. Het bevat een tekenreeks de sjabloon, dat een set parameters van de eindgebruiker kan overnemen en een prompt genereert. Laten we een paar voorbeelden nemen.
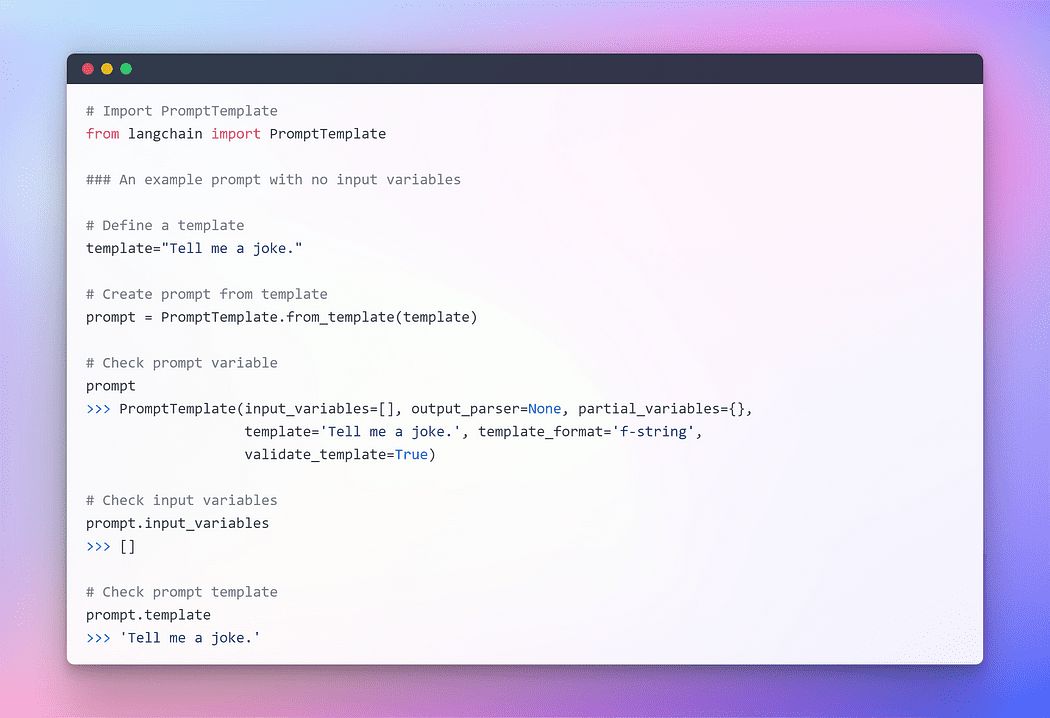
Afbeelding door auteur: Prompt zonder invoervariabelen
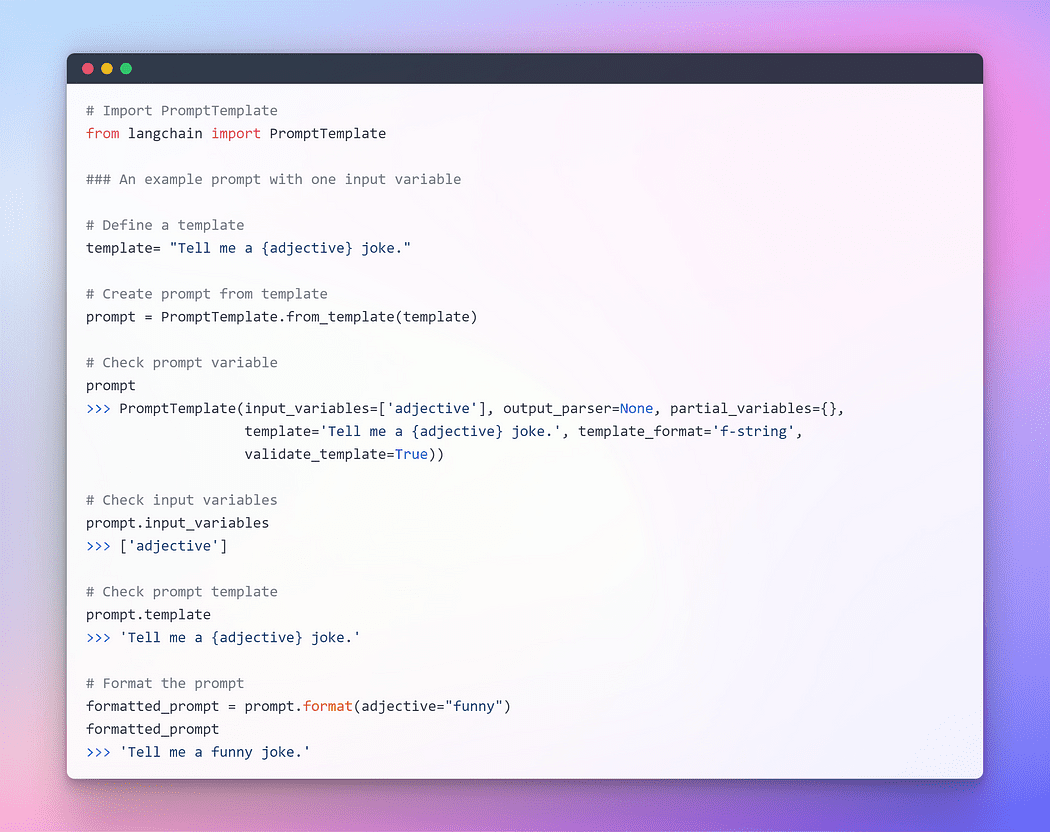
Afbeelding door auteur: Prompt met één invoervariabelen
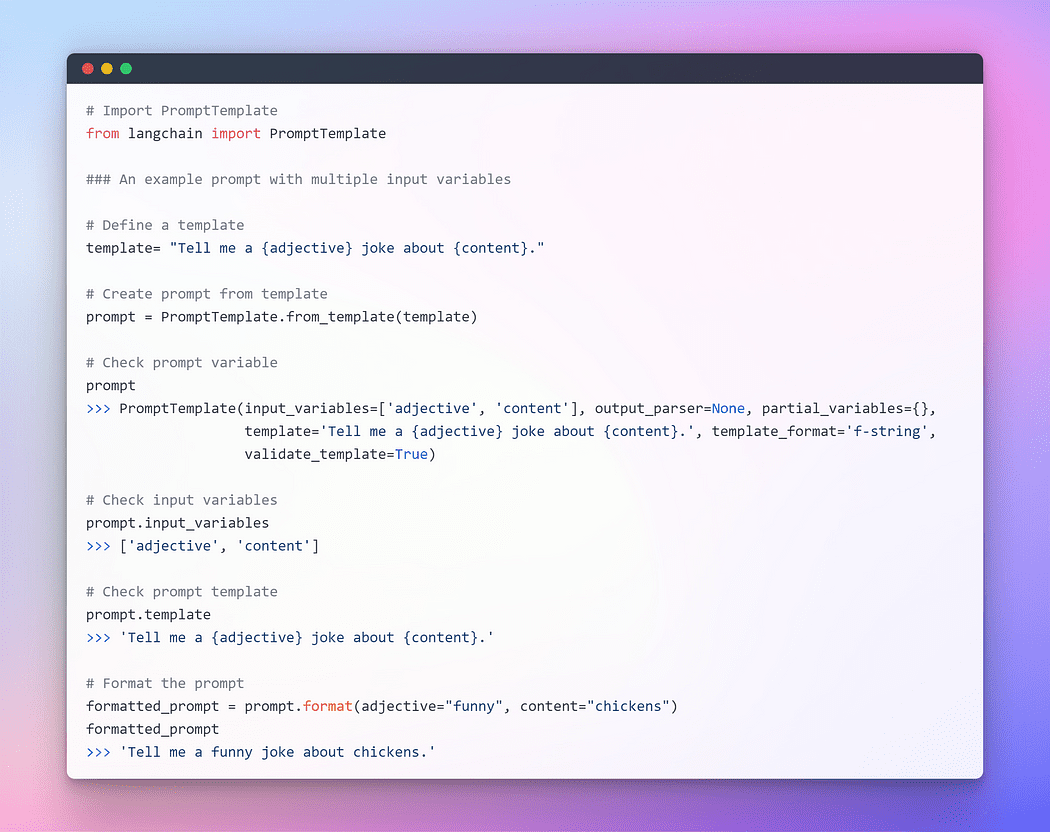
Afbeelding door auteur: Prompt met meerdere invoervariabelen
Ik hoop dat de voorgaande uitleg een beter begrip van het concept van aansporing heeft gegeven. Laten we nu verder gaan met het vragen van de LLM.
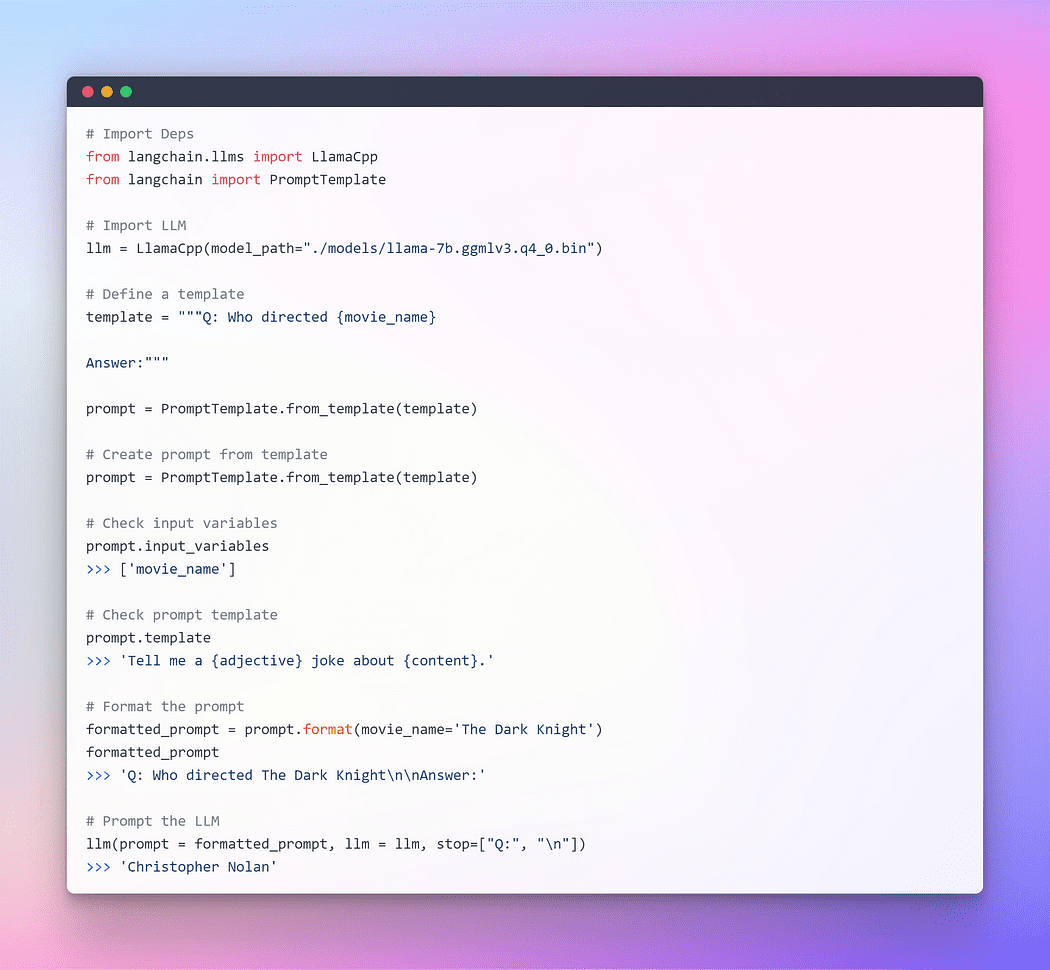
Afbeelding door auteur: vragen via Langchain LLM
Dit werkte prima, maar dit is niet het optimale gebruik van LangChain. Tot nu toe hebben we individuele componenten gebruikt. We hebben de prompt-sjabloon geformatteerd, vervolgens de llm genomen en vervolgens die parameters in llm doorgegeven om het antwoord te genereren. Het afzonderlijk gebruiken van een LLM is prima voor eenvoudige toepassingen, maar voor complexere toepassingen is het nodig om LLM's aan elkaar te koppelen, of met andere componenten.
LangChain biedt hiervoor de Chain-interface geketendtoepassingen. We definiëren een keten heel algemeen als een reeks oproepen naar componenten, die andere ketens kunnen omvatten. Met ketens kunnen we meerdere componenten combineren tot één samenhangende applicatie. We kunnen bijvoorbeeld een keten maken die gebruikersinvoer nodig heeft, deze formatteert met een promptsjabloon en vervolgens het geformatteerde antwoord doorgeeft aan een LLM. We kunnen complexere ketens bouwen door meerdere ketens met elkaar te combineren, of door ketens te combineren met andere componenten.
Laten we, om er een te begrijpen, een heel eenvoudige maken keten waarvoor gebruikersinvoer nodig is, formatteer de prompt ermee en stuur deze vervolgens naar de LLM met behulp van de bovenstaande individuele componenten die we al hebben gemaakt.
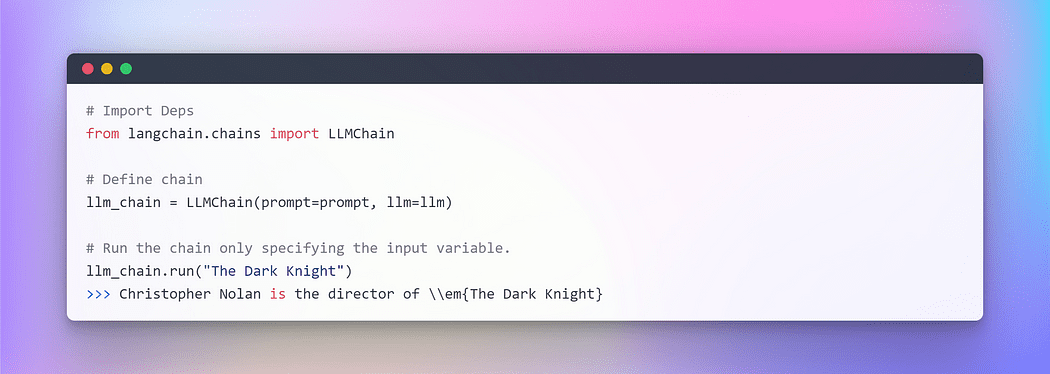
Afbeelding door auteur: Chaining in LangChain
Wanneer u met meerdere variabelen te maken heeft, heeft u de mogelijkheid om ze collectief in te voeren door een woordenboek te gebruiken. Dat concludeert dit deel. Laten we nu eens kijken naar het hoofdgedeelte waar we externe tekst zullen opnemen als een retriever voor het beantwoorden van vragen.
In tal van LLM-toepassingen is er behoefte aan gebruikersspecifieke gegevens die niet zijn opgenomen in de trainingsset van het model. LangChain biedt u de essentiële componenten om uw gegevens te laden, transformeren, op te slaan en op te vragen.
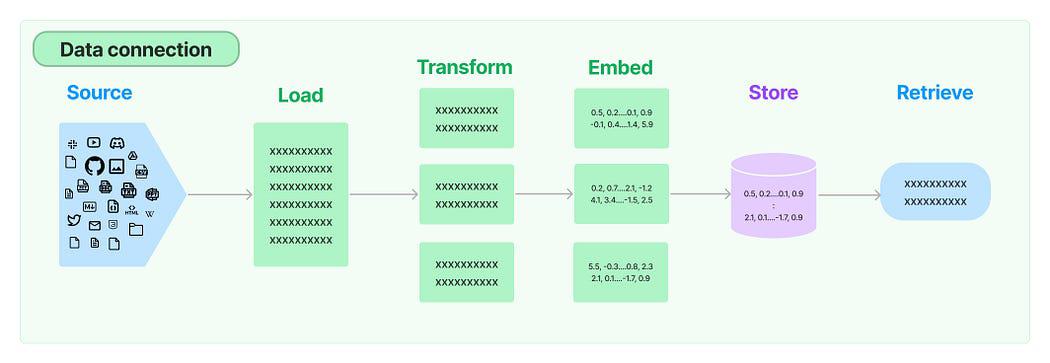
Gegevensverbinding in LangChain: bron
De vijf fasen zijn:
- Documentlader: Het wordt gebruikt voor het laden van gegevens als documenten.
- Documenttransformator: Het splitste het document op in kleinere stukken.
- Inbeddingen: Het transformeert de brokken in vectorrepresentaties, ook wel inbedding genoemd.
- Vectorwinkels: Het wordt gebruikt om de bovenstaande chunk-vectoren op te slaan in een vectordatabase.
- Retrievers: Het wordt gebruikt voor het ophalen van een set(s) vector(en) die het meest lijkt op een query in de vorm van een vector die is ingebed in dezelfde latente ruimte.
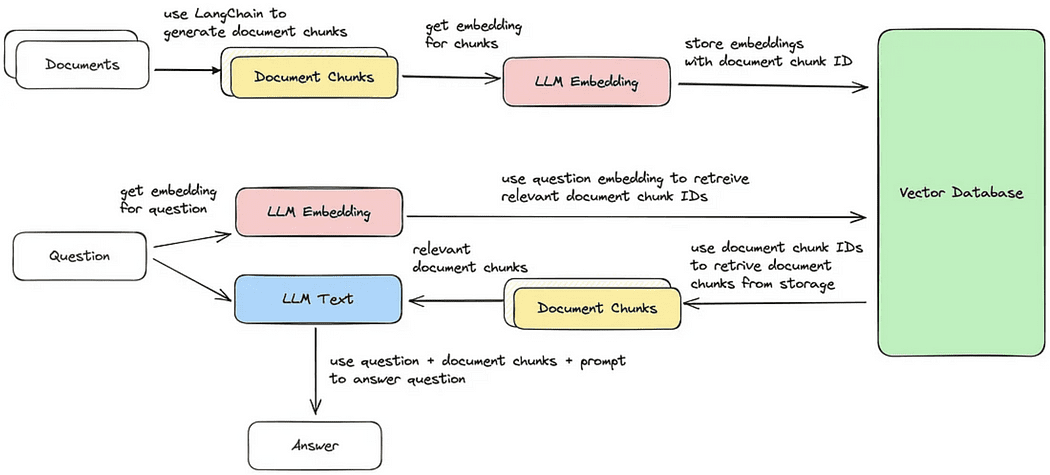
Cyclus voor het ophalen van documenten / het beantwoorden van vragen
Nu zullen we elk van de vijf stappen doorlopen om delen van documenten op te halen die het meest op de zoekopdracht lijken. Daarna kunnen we een antwoord genereren op basis van het opgehaalde vectorblok, zoals geïllustreerd in de meegeleverde afbeelding.
Voordat we echter verder gaan, moeten we een tekst voorbereiden voor het uitvoeren van de bovengenoemde taken. Voor deze fictieve test heb ik een tekst van Wikipedia gekopieerd met betrekking tot enkele populaire DC-superhelden. Hier is de tekst:

Afbeelding door auteur: onbewerkte tekst voor testen
Documenten laden en transformeren
Laten we om te beginnen een documentobject maken. In dit voorbeeld gebruiken we de tekstlader. Lang chain biedt echter ondersteuning voor meerdere documenten, dus afhankelijk van uw specifieke document kunt u verschillende laders gebruiken. Vervolgens gebruiken we de load methode om gegevens op te halen en als documenten te laden vanuit een vooraf geconfigureerde bron.
Zodra het document is geladen, kunnen we doorgaan met het transformatieproces door het op te splitsen in kleinere stukken. Om dit te bereiken, gebruiken we de TextSplitter. Standaard scheidt de splitter het document bij het scheidingsteken 'nn'. Als u het scheidingsteken echter instelt op null en een specifieke stukgrootte definieert, heeft elk stuk die gespecificeerde lengte. Bijgevolg is de resulterende lijstlengte gelijk aan de lengte van het document gedeeld door de blokgrootte. Samenvattend zal het er ongeveer zo uitzien: list length = length of doc / chunk size. Laten we praten.
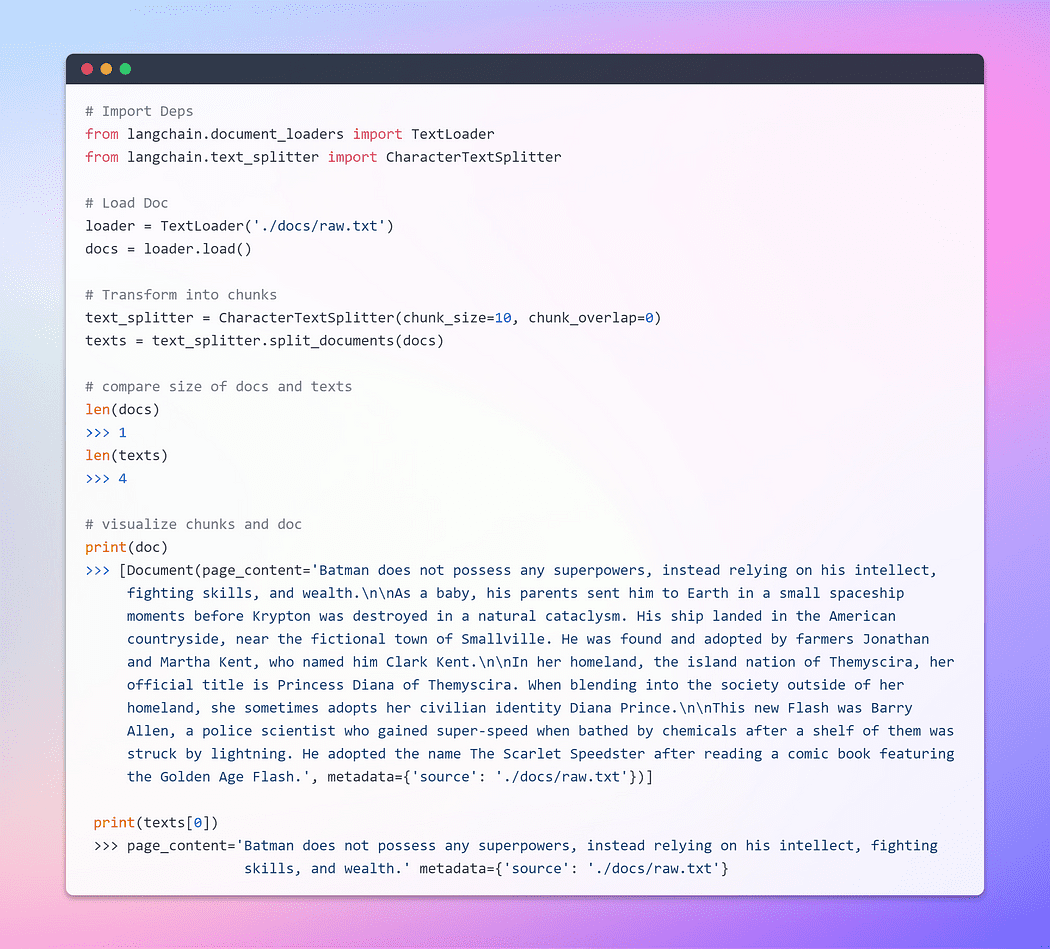
Afbeelding door auteur: Doc laden en transformeren
Onderdeel van de reis zijn de inbeddingen !!!
Dit is de belangrijkste stap. Inbeddingen genereren een gevectoriseerde weergave van tekstuele inhoud. Dit heeft praktische betekenis omdat het ons in staat stelt om tekst binnen een vectorruimte te conceptualiseren.
Woordinbedding is gewoon een vectorweergave van een woord, waarbij de vector reële getallen bevat. Aangezien talen doorgaans minstens tienduizenden woorden bevatten, kunnen eenvoudige binaire woordvectoren onpraktisch worden vanwege een groot aantal dimensies. Woordinbeddingen lossen dit probleem op door dichte representaties van woorden in een laag-dimensionale vectorruimte te bieden.
Als we het hebben over ophalen, verwijzen we naar het ophalen van een set vectoren die het meest lijkt op een query in de vorm van een vector die is ingebed in dezelfde latente ruimte.
De basisklasse Embeddings in LangChain biedt twee methoden: één voor het insluiten van documenten en één voor het insluiten van een query. De eerste neemt meerdere teksten als invoer, terwijl de laatste een enkele tekst gebruikt.
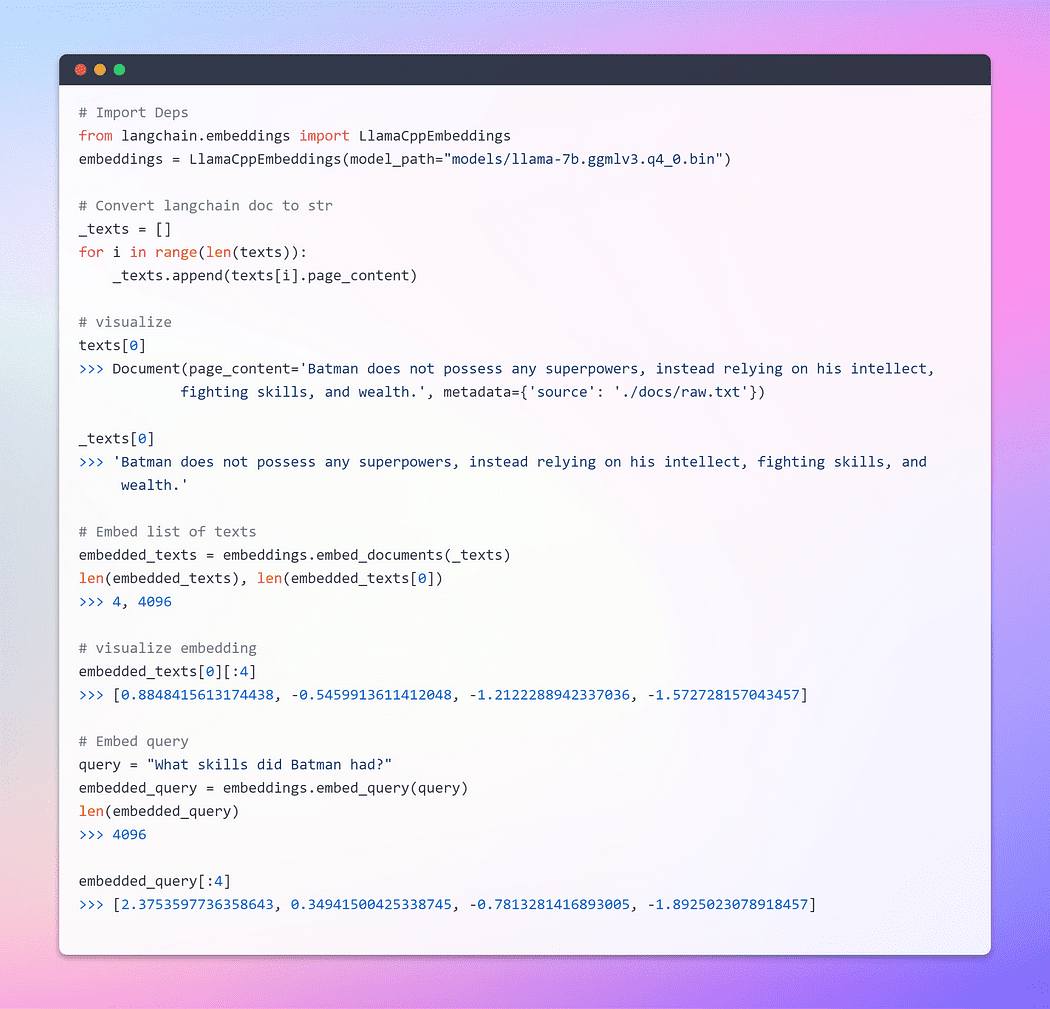
Afbeelding door auteur: inbeddingen
Voor een uitgebreid begrip van inbedding, raad ik ten zeerste aan om je te verdiepen in de basisprincipes, aangezien deze de kern vormen van hoe neurale netwerken omgaan met tekstuele gegevens. Ik heb dit onderwerp uitgebreid behandeld in een van mijn blogs met behulp van TensorFlow. Hier is de link.
Word Embeddings - Tekstrepresentatie voor neurale netwerken
Vectorwinkel maken en documenten ophalen
Een vectoropslag beheert efficiënt de opslag van ingebedde gegevens en vergemakkelijkt namens u vectorzoekoperaties. Het inbedden en opslaan van de resulterende inbeddingsvectoren is een gangbare methode voor het opslaan en doorzoeken van ongestructureerde gegevens. Tijdens de querytijd wordt de ongestructureerde query ook ingebed en worden de inbeddingsvectoren opgehaald die de grootste gelijkenis vertonen met de ingesloten query. Deze aanpak maakt het mogelijk om relevante informatie effectief op te halen uit de vectoropslag.
Hier zullen we Chroma gebruiken, een inbeddingsdatabase en vectoropslag die speciaal is ontworpen om de ontwikkeling van AI-toepassingen met inbedding te vereenvoudigen. Het biedt een uitgebreide reeks ingebouwde tools en functionaliteiten om uw eerste installatie te vergemakkelijken, die allemaal gemakkelijk op uw lokale computer kunnen worden geïnstalleerd door een eenvoudige pip install chromadb opdracht.

Afbeelding door auteur: vectorwinkel maken
Tot nu toe zijn we getuige geweest van het opmerkelijke vermogen van inbeddingen en vectoropslag in het ophalen van relevante stukken uit uitgebreide documentverzamelingen. Nu is het moment aangebroken om dit opgehaalde stuk als context naast onze vraag aan de LLM te presenteren. Met een beweging van zijn magische toverstaf zullen we de LLM smeken om een antwoord te genereren op basis van de informatie die we hem hebben verstrekt. Het belangrijkste onderdeel is de snelle structuur.
Het is echter cruciaal om het belang van een goed gestructureerde prompt te benadrukken. Door een goed opgestelde prompt te formuleren, kunnen we het potentieel voor de LLM om deel te nemen verminderen hallucinatie - waarin het feiten zou kunnen verzinnen wanneer het met onzekerheid wordt geconfronteerd.
Laten we, zonder het wachten nog langer te verlengen, nu doorgaan naar de laatste fase en kijken of onze LLM in staat is om een overtuigend antwoord te genereren. De tijd is gekomen om getuige te zijn van het hoogtepunt van onze inspanningen en het resultaat te onthullen. Hier zijn we Goooooo ?
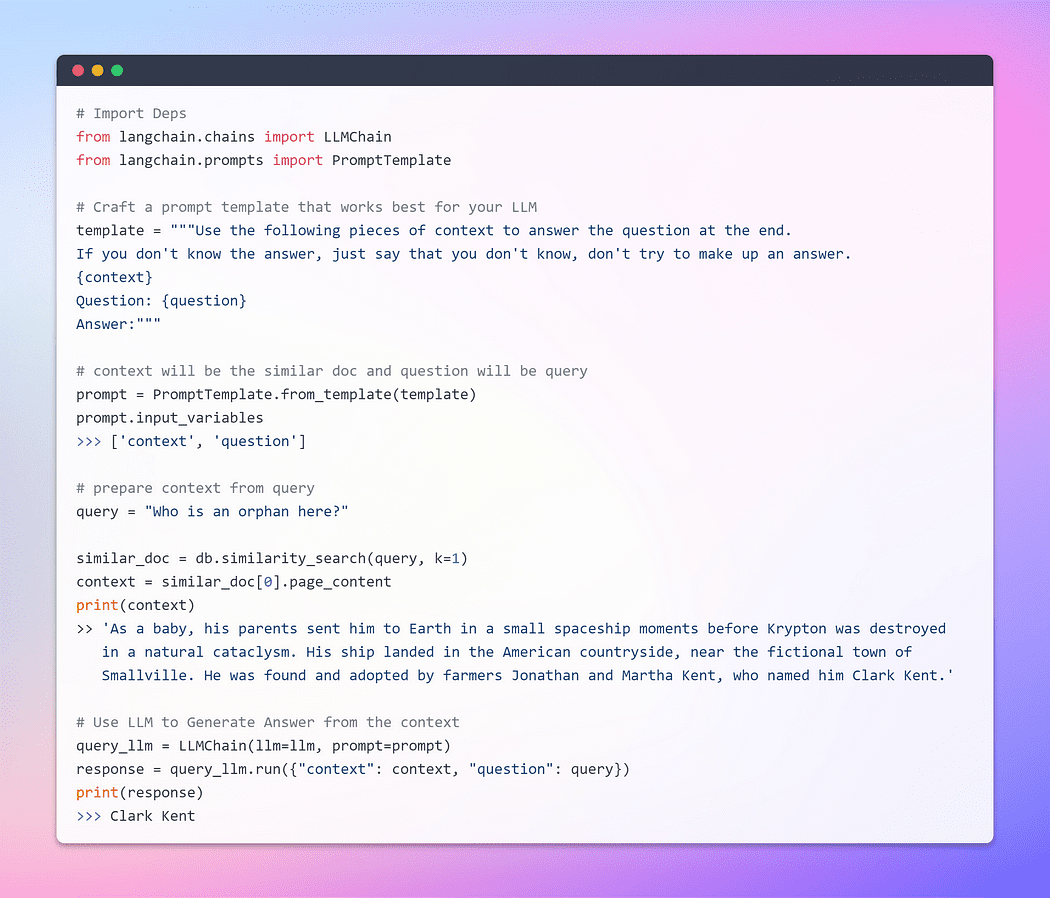
Afbeelding door auteur: Q / A met de Doc
Dit is het moment waarop we hebben gewacht! We hebben het volbracht! We hebben zojuist onze eigen vraag-antwoordbot gebouwd met behulp van de LLM die lokaal draait.
Dit gedeelte is volledig optioneel, aangezien het niet dient als een uitgebreide gids voor Streamlit. Ik zal niet diep ingaan op dit deel; in plaats daarvan zal ik een basistoepassing presenteren waarmee gebruikers elk tekstdocument kunnen uploaden. Ze hebben dan de mogelijkheid om vragen te stellen via tekstinvoer. Achter de schermen blijft de functionaliteit consistent met wat we in het vorige gedeelte hebben behandeld.
Er is echter een voorbehoud als het gaat om het uploaden van bestanden in Streamlit. Om mogelijke fouten door onvoldoende geheugen te voorkomen, vooral gezien de geheugenintensieve aard van LLM's, lees ik het document en schrijf ik het naar de tijdelijke map in onze bestandsstructuur, met de naam raw.txt. Op deze manier zal Textloader het in de toekomst naadloos verwerken, ongeacht de oorspronkelijke naam van het document.
Momenteel is de app ontworpen voor tekstbestanden, maar u kunt deze aanpassen voor pdf's, csv's of andere indelingen. Het onderliggende concept blijft hetzelfde, aangezien LLM's in de eerste plaats zijn ontworpen voor tekstinvoer en -uitvoer. Bovendien kunt u experimenteren met verschillende LLM's die worden ondersteund door de Llama C++-bindingen.
Zonder verder in ingewikkelde details te duiken, presenteer ik de code voor de app. Voel je vrij om het aan te passen aan je specifieke gebruikssituatie.
Zo ziet de gestreamlit-app eruit.
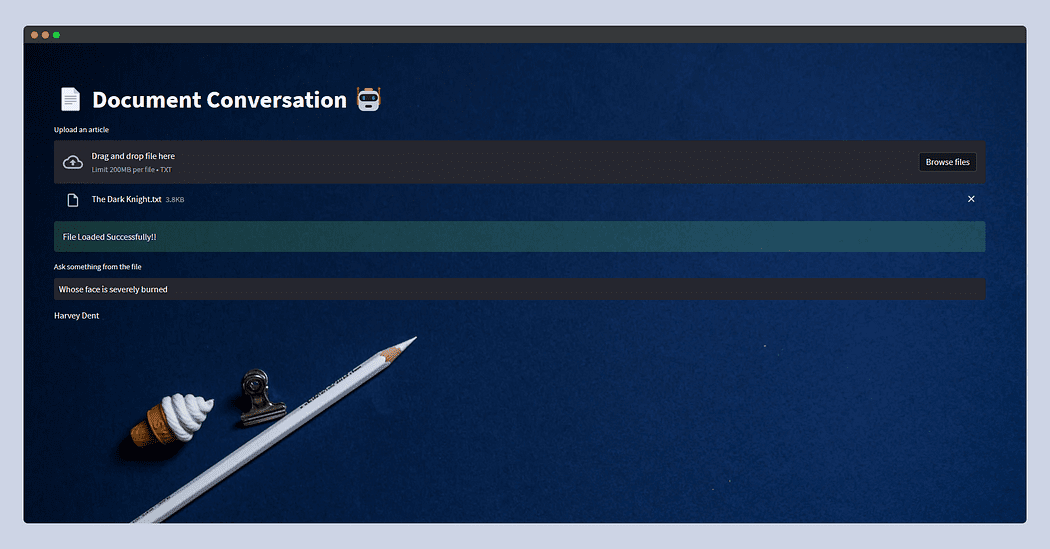
Deze keer voedde ik de plot van De donkere ridder gekopieerd van Wiki en zojuist gevraagd Wiens gezicht is ernstig verbrand? en de LLM antwoordde - Harvey Dent.
Oké, oké, oké! Daarmee komen we aan het einde van deze blog.
Ik hoop dat je genoten hebt van dit artikel! en vond het informatief en boeiend. Jij kan Volg mij Afaque Umer For meer dergelijke artikelen.
Ik zal proberen meer naar voren te brengen Machine learning/Data science-concepten en zal proberen mooi klinkende termen en concepten op te splitsen in eenvoudigere termen.
Afaque Umer is een gepassioneerde Machine Learning Engineer. Hij houdt ervan nieuwe uitdagingen aan te gaan met behulp van de nieuwste technologie om efficiënte oplossingen te vinden. Laten we samen de grenzen van AI verleggen!
ORIGINELE. Met toestemming opnieuw gepost.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- ChartPrime. Verhoog uw handelsspel met ChartPrime. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/08/langchain-streamlit-llama-bringing-conversational-ai-local-machine.html?utm_source=rss&utm_medium=rss&utm_campaign=langchain-streamlit-llama-bringing-conversational-ai-to-your-local-machine

