met Kennisbanken voor Amazon Bedrock, kunt u funderingsmodellen (FM's) veilig aansluiten Amazonebodem naar uw bedrijfsgegevens voor Retrieval Augmented Generation (RAG). Toegang tot aanvullende gegevens helpt het model relevantere, contextspecifieke en nauwkeurigere antwoorden te genereren zonder de FM's opnieuw te hoeven trainen.
In dit bericht bespreken we twee nieuwe functies van Knowledge Bases voor Amazon Bedrock die specifiek zijn voor de RetrieveAndGenerate API: het maximale aantal resultaten configureren en aangepaste prompts maken met een kennisbankpromptsjabloon. Deze kunt u nu als zoekopties naast het zoektype kiezen.
Overzicht en voordelen van nieuwe functies
De optie voor het maximale aantal resultaten geeft u controle over het aantal zoekresultaten dat uit de vectoropslag moet worden opgehaald en aan de FM moet worden doorgegeven om het antwoord te genereren. Hierdoor kunt u de hoeveelheid achtergrondinformatie aanpassen die moet worden gegenereerd, waardoor u meer context krijgt voor complexe vragen of minder voor eenvoudigere vragen. Hiermee kunt u maximaal 100 resultaten ophalen. Deze optie helpt de waarschijnlijkheid van een relevante context te vergroten, waardoor de nauwkeurigheid wordt verbeterd en de hallucinatie van de gegenereerde reactie wordt verminderd.
Met de aangepaste kennisbank-promptsjabloon kunt u de standaardpromptsjabloon vervangen door uw eigen prompt om de prompt aan te passen die naar het model wordt verzonden voor het genereren van antwoorden. Hierdoor kunt u de toon, het uitvoerformaat en het gedrag van de FM aanpassen wanneer deze reageert op de vraag van een gebruiker. Met deze optie kunt u de terminologie verfijnen zodat deze beter aansluit bij uw branche of domein (zoals de gezondheidszorg of de juridische sector). Bovendien kunt u aangepaste instructies en voorbeelden toevoegen die zijn afgestemd op uw specifieke workflows.
In de volgende secties leggen we uit hoe u deze functies kunt gebruiken met de AWS-beheerconsole of SDK.
Voorwaarden
Om deze voorbeelden te volgen, moet u over een bestaande kennisbank beschikken. Voor instructies om er een te maken, zie Creëer een kennisbank.
Configureer het maximale aantal resultaten met behulp van de console
Voer de volgende stappen uit om de optie voor het maximale aantal resultaten te gebruiken via de console:
- Kies op de Amazon Bedrock-console Kennisbanken in het linkernavigatievenster.
- Selecteer de kennisbank die u heeft gemaakt.
- Kies Kennisbank testen.
- Kies het configuratiepictogram.
- Kies Gegevensbron synchroniseren voordat u uw kennisbank gaat testen.

- Onder Configuratiesvoor Zoektype, selecteert u een zoektype op basis van uw gebruiksscenario.
Voor dit bericht gebruiken we hybride zoeken omdat het semantisch en tekstzoeken combineert voor een grotere nauwkeurigheid. Zie voor meer informatie over hybride zoeken Knowledge Bases voor Amazon Bedrock ondersteunt nu hybride zoeken.
- Uitvouwen Maximaal aantal bronfragmenten en stel uw maximale aantal resultaten in.

Om de waarde van de nieuwe functie aan te tonen, laten we voorbeelden zien van hoe u de nauwkeurigheid van het gegenereerde antwoord kunt vergroten. We gebruikten Amazon 10K-document voor 2023 als brongegevens voor het creëren van de kennisbank. We gebruiken de volgende vraag om te experimenteren: "In welk jaar is de jaarlijkse omzet van Amazon gestegen van $245 miljard naar $434 miljard?"
Het juiste antwoord op deze vraag is: “De jaarlijkse omzet van Amazon is gestegen van 245 miljard dollar in 2019 naar 434 miljard dollar in 2022”, gebaseerd op de documenten in de kennisbank. We gebruikten Claude v2 als FM om het uiteindelijke antwoord te genereren op basis van de contextuele informatie uit de kennisbank. Claude 3 Sonnet en Claude 3 Haiku worden ook ondersteund als FM-generatie.
We hebben nog een query uitgevoerd om de vergelijking van het ophalen met verschillende configuraties aan te tonen. We gebruikten dezelfde invoerquery (“In welk jaar is de jaarlijkse omzet van Amazon gestegen van 245 miljard dollar naar 434 miljard dollar?”) en stelden het maximale aantal resultaten in op 5.
Zoals te zien is in de volgende schermafbeelding, was het gegenereerde antwoord: 'Sorry, ik kan u niet helpen met dit verzoek.'

Vervolgens stellen we de maximale resultaten in op 12 en stellen we dezelfde vraag. Het gegenereerde antwoord is: “Amazon’s jaarlijkse omzetstijging van 245 miljard dollar in 2019 naar 434 miljard dollar in 2022.”

Zoals in dit voorbeeld wordt getoond, kunnen we het juiste antwoord ophalen op basis van het aantal opgehaalde resultaten. Als u meer wilt weten over de bronvermelding die de uiteindelijke output vormt, kiest u Brondetails tonen om het gegenereerde antwoord te valideren op basis van de kennisbank.
Pas een kennisbankpromptsjabloon aan met behulp van de console
U kunt de standaardprompt ook aanpassen met uw eigen prompt op basis van de gebruikssituatie. Om dit op de console te doen, voert u de volgende stappen uit:
- Herhaal de stappen in de vorige sectie om te beginnen met het testen van uw kennisbank.
- Enable
Genereer reacties.

- Selecteer het model van uw keuze voor het genereren van antwoorden.
We gebruiken het Claude v2-model als voorbeeld in dit bericht. Het Claude 3 Sonnet- en Haiku-model is ook beschikbaar voor generatie.
- Kies Solliciteer verder gaan.

Nadat u het model hebt gekozen, wordt een nieuwe sectie genoemd Sjabloon voor kennisbankprompts verschijnt onder Configuraties.
- Kies Edit om de prompt aan te passen.
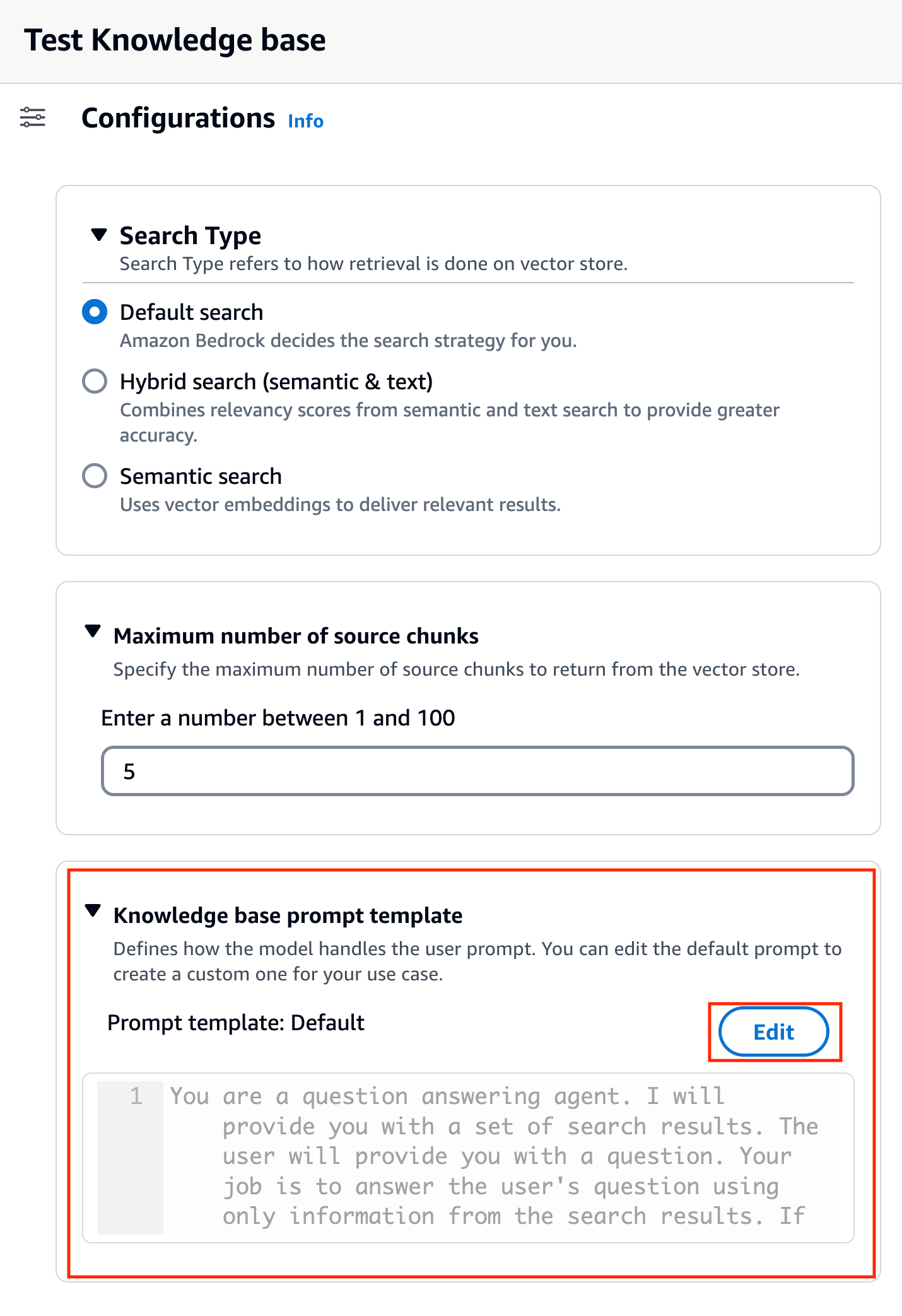
- Pas de promptsjabloon aan om aan te passen hoe u de opgehaalde resultaten wilt gebruiken en inhoud wilt genereren.
Voor dit bericht gaven we een paar voorbeelden voor het creëren van een “Financial Advisor AI-systeem” met behulp van financiële rapporten van Amazon met aangepaste aanwijzingen. Voor best practices op het gebied van snelle engineering raadpleegt u Snelle technische richtlijnen.
We passen nu de standaard promptsjabloon op verschillende manieren aan en observeren de reacties.
Laten we eerst een query proberen met de standaardprompt. We vragen ons af: “Wat waren de inkomsten van Amazon in 2019 en 2021?” Hieronder ziet u onze resultaten.

Uit de uitvoer blijkt dat het een reactie in vrije vorm genereert op basis van de opgehaalde kennis. De citaten zijn ook ter referentie vermeld.
Stel dat we extra instructies willen geven over hoe het gegenereerde antwoord moet worden opgemaakt, bijvoorbeeld door het te standaardiseren als JSON. We kunnen deze instructies als aparte stap toevoegen nadat we de informatie hebben opgehaald, als onderdeel van de promptsjabloon:
Het uiteindelijke antwoord heeft de vereiste structuur.

Door de prompt aan te passen, kunt u ook de taal van het gegenereerde antwoord wijzigen. In het volgende voorbeeld instrueren we het model om een antwoord in het Spaans te geven.

Na het verwijderen $output_format_instructions$ vanaf de standaardprompt wordt het citaat uit het gegenereerde antwoord verwijderd.
In de volgende secties leggen we uit hoe u deze functies kunt gebruiken met de SDK.
Configureer het maximale aantal resultaten met behulp van de SDK
Gebruik de volgende syntaxis om het maximale aantal resultaten met de SDK te wijzigen. Voor dit voorbeeld luidt de vraag: 'In welk jaar is de jaaromzet van Amazon gestegen van $245 miljard naar $434 miljard?' Het juiste antwoord is: “Amazon’s jaarlijkse omzet stijgt van 245 miljard dollar in 2019 naar 434 miljard dollar in 2022.”
Het 'numberOfResults'optie onder'retrievalConfiguration' kunt u het aantal resultaten selecteren dat u wilt ophalen. De uitvoer van de RetrieveAndGenerate API omvat het gegenereerde antwoord, brontoeschrijving en de opgehaalde tekstfragmenten.
Hieronder volgen de resultaten voor verschillende waarden van 'numberOfResults'parameters. Eerst gingen we zitten numberOfResults = 5.
Toen gingen we zitten numberOfResults = 12.
Pas de kennisbankpromptsjabloon aan met behulp van de SDK
Om de prompt aan te passen met behulp van de SDK, gebruiken we de volgende query met verschillende promptsjablonen. Voor dit voorbeeld luidt de vraag: 'Wat waren de inkomsten van Amazon in 2019 en 2021?'
Het volgende is de standaard promptsjabloon:
Het volgende is de aangepaste promptsjabloon:
Met de standaard promptsjabloon krijgen we het volgende antwoord:
![]()
Als u aanvullende instructies wilt geven over het uitvoerformaat van het genereren van antwoorden, zoals het standaardiseren van het antwoord in een specifiek formaat (zoals JSON), kunt u de bestaande prompt aanpassen door meer richtlijnen te geven. Met onze aangepaste promptsjabloon krijgen we het volgende antwoord.

Het 'promptTemplate'optie in'generationConfiguration' kunt u de prompt aanpassen voor een betere controle over het genereren van antwoorden.
Conclusie
In dit bericht hebben we twee nieuwe functies geïntroduceerd in Knowledge Bases voor Amazon Bedrock: het aanpassen van het maximale aantal zoekresultaten en het aanpassen van de standaard promptsjabloon voor de RetrieveAndGenerate API. We hebben gedemonstreerd hoe u deze functies op de console en via SDK kunt configureren om de prestaties en nauwkeurigheid van de gegenereerde respons te verbeteren. Het verhogen van de maximale resultaten levert uitgebreidere informatie op, terwijl u door het aanpassen van de promptsjabloon de instructies voor het funderingsmodel kunt verfijnen, zodat deze beter aansluiten bij specifieke gebruiksscenario's. Deze verbeteringen bieden meer flexibiliteit en controle, waardoor u op maat gemaakte ervaringen kunt leveren voor op RAG gebaseerde toepassingen.
Raadpleeg het volgende voor aanvullende bronnen die u kunt implementeren in uw AWS-omgeving:
Over de auteurs
 Sandeep Singh is een Senior Genative AI Data Scientist bij Amazon Web Services en helpt bedrijven te innoveren met generatieve AI. Hij is gespecialiseerd in generatieve AI, kunstmatige intelligentie, machinaal leren en systeemontwerp. Hij heeft een passie voor het ontwikkelen van state-of-the-art AI/ML-aangedreven oplossingen om complexe zakelijke problemen voor diverse industrieën op te lossen, waarbij de efficiëntie en schaalbaarheid worden geoptimaliseerd.
Sandeep Singh is een Senior Genative AI Data Scientist bij Amazon Web Services en helpt bedrijven te innoveren met generatieve AI. Hij is gespecialiseerd in generatieve AI, kunstmatige intelligentie, machinaal leren en systeemontwerp. Hij heeft een passie voor het ontwikkelen van state-of-the-art AI/ML-aangedreven oplossingen om complexe zakelijke problemen voor diverse industrieën op te lossen, waarbij de efficiëntie en schaalbaarheid worden geoptimaliseerd.
 Suyin Wang is een AI/ML Specialist Solutions Architect bij AWS. Ze heeft een interdisciplinaire opleidingsachtergrond in Machine Learning, Financial Information Service en Economie, samen met jarenlange ervaring in het bouwen van Data Science- en Machine Learning-applicaties die echte zakelijke problemen hebben opgelost. Ze vindt het leuk om klanten te helpen de juiste zakelijke vragen te identificeren en de juiste AI/ML-oplossingen te bouwen. In haar vrije tijd houdt ze van zingen en koken.
Suyin Wang is een AI/ML Specialist Solutions Architect bij AWS. Ze heeft een interdisciplinaire opleidingsachtergrond in Machine Learning, Financial Information Service en Economie, samen met jarenlange ervaring in het bouwen van Data Science- en Machine Learning-applicaties die echte zakelijke problemen hebben opgelost. Ze vindt het leuk om klanten te helpen de juiste zakelijke vragen te identificeren en de juiste AI/ML-oplossingen te bouwen. In haar vrije tijd houdt ze van zingen en koken.
 sherry ding is een senior specialist in kunstmatige intelligentie (AI) en machine learning (ML) oplossingen bij Amazon Web Services (AWS). Ze heeft uitgebreide ervaring met machinaal leren en heeft een doctoraat in computerwetenschappen. Ze werkt voornamelijk met klanten uit de publieke sector aan verschillende AI/ML-gerelateerde zakelijke uitdagingen, en helpt hen hun machine learning-traject op de AWS Cloud te versnellen. Als ze geen klanten helpt, houdt ze van buitenactiviteiten.
sherry ding is een senior specialist in kunstmatige intelligentie (AI) en machine learning (ML) oplossingen bij Amazon Web Services (AWS). Ze heeft uitgebreide ervaring met machinaal leren en heeft een doctoraat in computerwetenschappen. Ze werkt voornamelijk met klanten uit de publieke sector aan verschillende AI/ML-gerelateerde zakelijke uitdagingen, en helpt hen hun machine learning-traject op de AWS Cloud te versnellen. Als ze geen klanten helpt, houdt ze van buitenactiviteiten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-custom-prompts-for-the-retrieveandgenerate-api-and-configuration-of-the-maximum-number-of-retrieved-results/

