Amazon EPD op EKS biedt een implementatieoptie voor Amazon EMR waarmee organisaties open-source big data-frameworks kunnen uitvoeren op Amazon Elastic Kubernetes Service (Amazon EKS). Met EMR op EKS draaien Spark-applicaties op de Amazon EMR-runtime voor Apache Spark. Deze prestatie-geoptimaliseerde runtime aangeboden door Amazon EMR zorgt ervoor dat uw Spark-taken snel en kosteneffectief worden uitgevoerd. De EMR-runtime biedt tot 5.37 keer betere prestaties en 76.8% kostenbesparingen, in vergelijking met het gebruik van open-source Apache Spark op Amazon EKS.
Voortbouwend op het succes van Amazon EMR op EKS, hebben klanten taken uitgevoerd en beheerd met behulp van de emr-containers API, maken EMR virtuele clusters, en het verzenden van taken naar het EKS-cluster, hetzij via de AWS Command Line Interface (AWS CLI) of Apache-luchtstroom planner. Andere klanten met Spark-applicaties hebben echter gekozen Spark-operator of inheems vonk-indienen om Apache Spark-taken op Amazon EKS te definiëren en uit te voeren, maar zonder te profiteren van de prestatieverbeteringen van het uitvoeren van Spark op de geoptimaliseerde EMR-runtime. Als antwoord op deze behoefte hebben we vanaf EMR 6.10 een nieuwe functie geïntroduceerd waarmee u de geoptimaliseerde EMR-runtime kunt gebruiken bij het indienen en beheren van Spark-taken via Spark Operator of spark-submit. Dit betekent dat iedereen die Spark-workloads op EKS uitvoert, kan profiteren van de geoptimaliseerde runtime van EMR.
In dit bericht doorlopen we het proces van het instellen en uitvoeren van Spark-taken met zowel Spark Operator als spark-submit, geïntegreerd met de EMR-runtimefunctie. We bieden stapsgewijze instructies om u te helpen bij het opzetten van de infrastructuur en het indienen van een opdracht met beide methoden. Daarnaast kunt u gebruik maken van de Gegevens over EKS-blauwdruk om de volledige infrastructuur te implementeren met behulp van Terraform-sjablonen.
Infrastructuur overzicht
In dit bericht doorlopen we het proces van het implementeren van een uitgebreide oplossing met behulp van eksctl, Helm en AWS CLI. Onze implementatie omvat de volgende bronnen:
- Een VPC, EKS-cluster en beheerde knooppuntgroep, ingesteld met de
eksctltools - Essentiële door Amazon EKS beheerde add-ons, zoals de VPC CNI, CoreDNS en KubeProxy ingesteld met de
eksctltools - Cluster Autoscaler en Spark Operator add-ons, ingesteld met Helm
- De uitvoering van een Spark-taak AWS Identiteits- en toegangsbeheer (IAM) rol, IAM beleid voor Amazon eenvoudige opslagservice (Amazon S3) bucket-toegang, serviceaccount en op rollen gebaseerd toegangscontrole, ingesteld met behulp van de AWS CLI en
eksctl
Voorwaarden
Controleer of de volgende vereisten op uw computer zijn geïnstalleerd:
Stel AWS-referenties in
Voordat u doorgaat naar de volgende stap en de opdracht eksctl uitvoert, moet u uw lokale AWS-referentieprofiel instellen. Raadpleeg voor instructies Configuratie- en referentiebestandsinstellingen.
Implementeer de VPC, het EKS-cluster en beheerde add-ons
De volgende configuratie gebruikt us-west-1 als de standaardregio. Als u in een andere regio wilt draaien, werkt u het region en availabilityZones velden dienovereenkomstig. Controleer ook of dezelfde regio wordt gebruikt in de volgende stappen in het bericht.
Voer het volgende codefragment in de terminal in waar uw AWS-referenties zijn ingesteld. Zorg ervoor dat u de update uitvoert publicAccessCIDRs veld met uw IP voordat u de onderstaande opdracht uitvoert. Hiermee wordt een bestand met de naam gemaakt eks-cluster.yaml:
Gebruik de volgende opdracht om het EKS-cluster te maken: eksctl create cluster -f eks-cluster.yaml
Implementeer Cluster Autoscaler
Cluster Autoscaler is cruciaal voor het automatisch aanpassen van de grootte van uw Kubernetes-cluster op basis van de huidige resourcebehoeften, waardoor het gebruik van resources en de kosten worden geoptimaliseerd. Creëer een autoscaler-helm-values.yaml bestand en installeer de Cluster Autoscaler met behulp van Helm:
Je kunt ook instellen timmerman als clusterautomatische schaaller om automatisch de juiste rekenresources te starten om de toepassingen van uw EKS-cluster te verwerken. U kunt dit volgen blog over het instellen en configureren van Karpenter.
Spark-operator implementeren
Spark-operator is een open-source Kubernetes-operator die speciaal is ontworpen om Spark-applicaties die op Kubernetes draaien te beheren en te bewaken. Het stroomlijnt het proces van het implementeren en beheren van Spark-taken door een aangepaste Kubernetes-resource te bieden om Spark-applicaties te definiëren, configureren en uitvoeren, en om de levenscyclus van taken te beheren via Kubernetes API. Sommige klanten geven er de voorkeur aan Spark Operator te gebruiken om Spark-taken te beheren, omdat ze hiermee Spark-applicaties kunnen beheren, net als andere Kubernetes-resources.
Momenteel bouwen klanten hun open-source Spark-images en gebruiken ze S3a-committers als onderdeel van het indienen van vacatures met Spark Operator of spark-submit. Met de nieuwe optie voor het indienen van vacatures kunt u nu profiteren van de EMR-runtime in combinatie met EMRFS. Vanaf Amazon EMR 6.10 en voor elke aankomende versie van de EMR-runtime, zullen we de Spark Operator en zijn Helm-chart vrijgeven om de EMR-runtime te gebruiken.
In deze sectie laten we u zien hoe u een Spark Operator Helm-grafiek implementeert vanuit een Amazon Elastic Container-register (Amazon ECR)-opslagplaats en verzend taken met behulp van EMR-runtime-images, waarbij u profiteert van de prestatieverbeteringen die worden geboden door de EMR-runtime.
Installeer Spark Operator met Helm van Amazon ECR
De Spark Operator Helm-grafiek wordt opgeslagen in een ECR-repository. Om de Spark-operator te installeren, moet u eerst uw Helm-client verifiëren met de ECR-repository. De grafieken worden opgeslagen onder het volgende pad: ECR_URI/spark-operator.
Verifieer uw Helm-client en installeer de Spark-operator:
U kunt zich authenticeren bij andere EMR op door EKS ondersteunde regio's door de AWS-account-ID voor de overeenkomstige regio te verkrijgen. Voor meer informatie, zie hoe u een basisbeeld-URI selecteert.
Spark-operator installeren
U kunt nu Spark Operator installeren met de volgende opdracht:
Voer de volgende opdracht uit om te controleren of de operator correct is geïnstalleerd:
Stel de Spark-taakuitvoeringsrol en het serviceaccount in
In deze stap maken we een IAM-rol voor het uitvoeren van Spark-taken en een serviceaccount, die worden gebruikt in Spark Operator en spark-submit voorbeelden van het indienen van vacatures.
Eerst maken we een IAM-beleid dat zal worden gebruikt door de IAM-rollen voor serviceaccounts (IRSA). Met dit beleid kunnen de driver- en executor-pods toegang krijgen tot de AWS-services die in het beleid zijn gespecificeerd. Voer de volgende stappen uit:
- Maak als vereiste een S3-bucket (
aws s3api create-bucket --bucket <ENTER-S3-BUCKET> --create-bucket-configuration LocationConstraint=us-west-1 --region us-west-1) of gebruik een bestaande S3-bucket. Vervangen in de volgende code met de bucketnaam. - Maak een beleidsbestand dat lees- en schrijftoegang tot een S3-bucket toestaat:
- Maak het IAM-beleid met de volgende opdracht:
- Maak vervolgens het serviceaccount met de naam
emr-job-execution-sa-roleevenals de IAM-rollen. Het volgendeeksctlopdracht maakt een serviceaccount aan dat is afgestemd op de naamruimte en het serviceaccount dat is gedefinieerd om te worden gebruikt door de uitvoerder en het stuurprogramma. Zorg ervoor dat u vervangt met uw account-ID voordat u de opdracht uitvoert: - Maak een S3-bucketbeleid om alleen de uitvoerende rol create in stap 4 toe te staan om te schrijven en te lezen van de S3-bucket create in stap 1. Vervang met uw account-ID voordat u de opdracht uitvoert:
- Maak een Kubernetes-rol en rolbinding die vereist zijn voor het serviceaccount dat wordt gebruikt in de Spark-taakuitvoering:
- Pas de Kubernetes-rol en rolbindingsdefinitie toe met de volgende opdracht:
Tot nu toe hebben we de installatie van de infrastructuur voltooid, inclusief de Spark-taakuitvoeringsrollen. In de volgende stappen voeren we voorbeelden van Spark-taken uit met zowel Spark Operator als spark-submit met de EMR-looptijd.
Configureer de Spark Operator-taak met de EMR-runtime
In deze sectie presenteren we een voorbeeld van een Spark-taak die gegevens leest uit openbare datasets die zijn opgeslagen in S3-buckets, deze verwerkt en de resultaten naar uw eigen S3-bucket schrijft. Zorg ervoor dat u de S3-bucket in de volgende configuratie bijwerkt door te vervangen met de URI naar uw eigen S3-bucket waarnaar wordt verwezen stap 2 van de "Stel de Spark-taakuitvoeringsrol en het serviceaccount in" sectie. Merk ook op dat we gebruiken data-team-a als naamruimte en emr-job-execution-sa als een serviceaccount, dat we in de vorige stap hebben gemaakt. Deze zijn nodig om de Spark-taakpods in de speciale naamruimte uit te voeren, en de IAM-rol die aan het serviceaccount is gekoppeld, wordt gebruikt om toegang te krijgen tot de S3-bucket voor het lezen en schrijven van gegevens.
Let vooral op de image veld met de voor EMR geoptimaliseerde runtime Docker-image, die momenteel is ingesteld op emr-6.10.0. Je kunt dit wijzigen in een nieuwere versie wanneer deze wordt uitgebracht door het Amazon EMR-team. Zorg er bij het configureren van uw taken ook voor dat u de sparkConf en hadoopConf instellingen zoals gedefinieerd in het volgende manifest. Met deze configuraties kunt u profiteren van EMR-runtimeprestaties, AWS lijm Data Catalog-integratie en de voor EMRFS geoptimaliseerde connector.
- Maak het bestand (
emr-spark-operator-example.yaml) lokaal en werk de S3-bucketlocatie bij zodat u de taak kunt indienen als onderdeel van de volgende stap: - Voer de volgende opdracht uit om de taak naar het EKS-cluster te verzenden:
Het kan 4 tot 5 minuten duren voordat de taak is voltooid en u kunt het succesvolle bericht controleren in de logboeken van de driver pod.
- Controleer de taak door de volgende opdracht uit te voeren:
Schakel toegang tot de Spark-gebruikersinterface in
De gebruikersinterface van Spark is een belangrijk hulpmiddel voor data-engineers, omdat u hiermee de voortgang van taken kunt volgen, gedetailleerde taak- en fase-informatie kunt bekijken en het gebruik van resources kunt analyseren om knelpunten te identificeren en uw code te optimaliseren. Voor Spark-taken die op Kubernetes worden uitgevoerd, wordt de Spark-gebruikersinterface gehost op de driverpod en is de toegang beperkt tot het interne netwerk van Kubernetes. Om toegang te krijgen, moeten we het verkeer naar de pod doorsturen kubectl. De volgende stappen laten u zien hoe u het instelt.
Voer de volgende opdracht uit om verkeer door te sturen naar de driver pod:
U zou tekst moeten zien die lijkt op het volgende:
Als u de naam van de driver pod niet hebt opgegeven bij het indienen van de SparkApplication, je kunt het krijgen met de volgende opdracht:
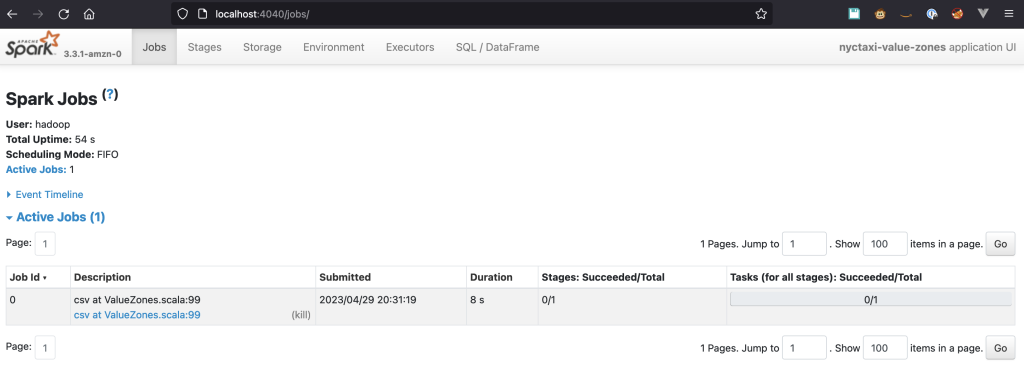
Open een browser en voer in http://localhost:4040 in de adresbalk. U zou nu verbinding moeten kunnen maken met de Spark-gebruikersinterface.
Spark-geschiedenisserver
Als u uw taak wilt verkennen nadat deze is uitgevoerd, kunt u deze bekijken via de Spark History Server. Het voorgaande SparkApplication definition heeft het gebeurtenislogboek ingeschakeld en slaat de gebeurtenissen op in een S3-bucket met het volgende pad: s3://YOUR-S3-BUCKET/. Raadpleeg voor instructies over het instellen van de Spark History Server en het verkennen van de logboeken De Spark-geschiedenisserver starten en de Spark-gebruikersinterface bekijken met behulp van Docker.
vonk-indienen
vonk-indienen is een opdrachtregelinterface voor het uitvoeren van Apache Spark-applicaties op een cluster of lokaal. Hiermee kunt u aanvragen indienen bij Spark-clusters. De tool maakt eenvoudige configuratie van applicatie-eigenschappen, resourcetoewijzing en aangepaste bibliotheken mogelijk, waardoor de implementatie en het beheer van Spark-taken wordt gestroomlijnd.
Beginnend met Amazon EMR 6.10, spark-submit wordt ondersteund als methode voor het indienen van vacatures. Deze methode ondersteunt momenteel alleen de clustermodus als indieningsmechanisme. Om vacatures in te dienen met behulp van de spark-submit methode hergebruiken we de IAM-rol voor het serviceaccount dat we eerder hebben ingesteld. We gebruiken ook de S3-bucket die wordt gebruikt voor de Spark Operator-methode. De stappen in deze sectie laten u zien hoe u taken configureert en verzendt met spark-submit en profiteer van EMR-runtime-verbeteringen.
- Om een taak in te dienen, moet u de Spark-versie gebruiken die overeenkomt met de versie die beschikbaar is in Amazon EMR. Voor Amazon EMR 6.10 moet u dat wel doen download de Spark 3.3-versie.
- Je moet er ook voor zorgen dat je Java geïnstalleerd in uw omgeving.
- Pak het bestand uit en navigeer naar de hoofdmap van de Spark-directory.
- Vervang in de volgende code de EKS-eindpunt alsmede de S3 emmer voer vervolgens het script uit:
De taak duurt ongeveer 7 minuten om te voltooien met twee uitvoerders van één kern en 1 G geheugen.
Aangepaste Kubernetes-planners gebruiken
Klanten die een groot aantal taken tegelijkertijd uitvoeren, kunnen uitdagingen tegenkomen met betrekking tot het bieden van eerlijke toegang tot rekencapaciteit die ze niet kunnen oplossen met de standaardplanning en het beheer van resourcegebruik dat Kubernetes biedt. Bovendien kunnen klanten die migreren van Amazon EMR naar Amazon Elastic Compute Cloud (Amazon EC2) en hun planning beheren met YARN-wachtrijen, deze niet omzetten naar Kubernetes-planningsmogelijkheden.
Om dit probleem op te lossen, kunt u aangepaste planners gebruiken, zoals Apache Yunikorn or Vulkaan.Spark Operator ondersteunt deze planners van nature, en hiermee kunt u Spark-applicaties plannen op basis van factoren zoals prioriteit, resourcevereisten en eerlijkheidsbeleid, terwijl Spark Operator de implementatie en het beheer van applicaties vereenvoudigt. Om Yunikorn in te stellen met bendeplanning en deze te gebruiken in Spark-applicaties die zijn ingediend via Spark Operator, raadpleegt u Vonkoperator met YuniKorn.
Opruimen
Verwijder alle AWS-bronnen die tijdens deze implementatie zijn gemaakt om ongewenste kosten van uw AWS-account te voorkomen:
Conclusie
In dit bericht hebben we de EMR-runtime-functie geïntroduceerd voor Spark Operator en spark-submit, en onderzocht de voordelen van het gebruik van deze functie op een EKS-cluster. Met de geoptimaliseerde EMR-runtime kunt u de prestaties van uw Spark-applicaties aanzienlijk verbeteren en tegelijkertijd de kosten optimaliseren. We hebben de implementatie van het cluster gedemonstreerd met behulp van de eksctl tool, , kunt u ook de Gegevens over EKS-blauwdrukken voor het implementeren van een productieklare EKS die u kunt gebruiken voor EMR op EKS en gebruik kunt maken van deze nieuwe implementatiemethoden naast de EMR op EKS API-taakverzendingsmethode. Door uw applicaties op de geoptimaliseerde EMR-runtime uit te voeren, kunt u uw Spark-applicatieworkflows verder verbeteren en innovatie in uw dataverwerkingspijplijnen stimuleren.
Over de auteurs
 Lotfi Mohib is een Senior Solutions Architect die werkt voor het team van de publieke sector met Amazon Web Services. Hij helpt klanten in de publieke sector in EMEA hun ideeën te realiseren, nieuwe diensten te bouwen en te innoveren voor burgers. In zijn vrije tijd houdt Lotfi van fietsen en hardlopen.
Lotfi Mohib is een Senior Solutions Architect die werkt voor het team van de publieke sector met Amazon Web Services. Hij helpt klanten in de publieke sector in EMEA hun ideeën te realiseren, nieuwe diensten te bouwen en te innoveren voor burgers. In zijn vrije tijd houdt Lotfi van fietsen en hardlopen.
 Var Bonthu is een toegewijde technologieprofessional en Worldwide Tech Leader for Data on EKS, gespecialiseerd in het assisteren van AWS-klanten, variërend van strategische accounts tot diverse organisaties. Hij is gepassioneerd door open-sourcetechnologieën, data-analyse, AI/ML en Kubernetes, en heeft een uitgebreide achtergrond in ontwikkeling, DevOps en architectuur. Vara's primaire focus ligt op het bouwen van zeer schaalbare data- en AI/ML-oplossingen op Kubernetes-platforms, om klanten te helpen het volledige potentieel van geavanceerde technologie te benutten voor hun datagestuurde bezigheden.
Var Bonthu is een toegewijde technologieprofessional en Worldwide Tech Leader for Data on EKS, gespecialiseerd in het assisteren van AWS-klanten, variërend van strategische accounts tot diverse organisaties. Hij is gepassioneerd door open-sourcetechnologieën, data-analyse, AI/ML en Kubernetes, en heeft een uitgebreide achtergrond in ontwikkeling, DevOps en architectuur. Vara's primaire focus ligt op het bouwen van zeer schaalbare data- en AI/ML-oplossingen op Kubernetes-platforms, om klanten te helpen het volledige potentieel van geavanceerde technologie te benutten voor hun datagestuurde bezigheden.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/introducing-amazon-emr-on-eks-job-submission-with-spark-operator-and-spark-submit/

