
Afbeelding door benzoix op Freepik
Wat is Panda eigenlijk en waarom is het zo beroemd? Zie Panda's als een Excel-blad, maar een Excel-blad van het volgende niveau met meer functies en flexibiliteit dan Excel.
Er zijn veel redenen om voor panda's te kiezen, sommige ook
- Open Source
- Makkelijk te leren
- Geweldige gemeenschap
- Gebouwd bovenop Numpy
- Gemakkelijk om gegevens erin te analyseren en voor te verwerken
- Ingebouwde gegevensvisualisatie
- Veel ingebouwde functies om te helpen bij verkennende gegevensanalyse
- Ingebouwde ondersteuning voor CSV, SQL, HTML, JSON, augurk, Excel, klembord en nog veel meer
- en veel meer
Als je Anaconda gebruikt, zul je er automatisch panda's in hebben, maar om de een of andere reden, als je het niet hebt, voer je gewoon deze opdracht uit
conda install pandas
Als je Anaconda niet gebruikt, installeer dan via pip by
pip install pandas
Importeren
Gebruik om panda's te importeren
import pandas as pd
import numpy as np
Het is beter om numpy met panda's te importeren om toegang te krijgen tot meer numpy-functies, wat ons helpt bij verkennende gegevensanalyse (EDA).
Panda's heeft twee belangrijke gegevensstructuren.
- -Series
- Gegevensframes
-Series
Beschouw Reeks als een enkele kolom in een Excel-blad. Je kunt het ook zien als een 1d Numpy-array. Het enige dat het onderscheidt van de 1d Numpy-array, is dat we indexnamen kunnen hebben.
De basissyntaxis om een panda-serie te maken is als volgt:
newSeries = pd.Series(data , index)
Gegevens kunnen van elk type zijn, van Python's woordenboek tot lijst of tuple. Het kan ook een numpy-array zijn.
Laten we een serie bouwen van Python List:
mylist = ['Ahmad','Machine Learning', 20, 'Pakistan']
labels = ['Name', 'Career', 'Age', 'Country']
newSeries = pd.Series(mylist,labels)
print(newSeries)
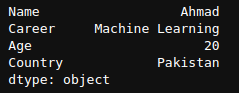
Uitvoer van newSeries.
Het is niet nodig om een index toe te voegen in een Panda Series. In dat geval zal de indexering automatisch vanaf 0 starten.
mylist = ['Ahmad','Machine Learning', 20, 'Pakistan']
newSeries = pd.Series(mylist)
print(newSeries)

Hier kunnen we zien dat de index begint bij 0 en doorgaat tot het einde van de reeks. Laten we nu eens kijken hoe we een serie kunnen maken met behulp van a Python-woordenboek,
myDict = {'Name': 'Ahmad', 'Career': 'Machine Learning', 'Age': 20, 'Country': 'Pakistan'}
mySeries = pd.Series(myDict)
print(mySeries)

Hier kunnen we zien dat we de indexwaarden niet expliciet hoeven door te geven, aangezien deze automatisch worden toegewezen vanuit de sleutels in het woordenboek.
Toegang tot gegevens uit Series
Het normale patroon om toegang te krijgen tot de gegevens van Panda's Series is
seriesName['IndexName']
Laten we het voorbeeld van mijnSerie nemen dat we eerder hebben gemaakt. Om de waarde van Naam, Leeftijd en Carrière te krijgen, hoeven we alleen maar te doen
print(mySeries['Name'])
print(mySeries['Age'])
print(mySeries['Career'])

Basisbewerkingen op Panda's-serie
Laten we twee nieuwe reeksen maken om er bewerkingen op uit te voeren
newSeries = pd.Series([10,20,30,40],index=['LONDON','NEWYORK','Washington','Manchester'])
newSeries1 = pd.Series([10,20,35,46],index=['LONDON','NEWYORK','Istanbul','Karachi'])
print(newSeries,newSeries1,sep='nn')
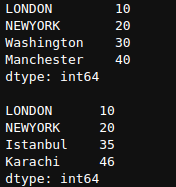
Basis rekenkundige bewerkingen omvatten +-*/ bewerkingen. Deze worden over-index gedaan, dus laten we ze uitvoeren.
newSeries + newSeries1

Hier kunnen we zien dat, aangezien de Londen- en NEWYORK-index aanwezig zijn in beide series, de waarde van beide is toegevoegd en de uitvoer van rust NaN is (geen getal).
newSeries * newSeries1

newSeries / newSeries1

Element Wise operaties/uitzendingen
Als u bekend bent met Numpy, moet u op de hoogte zijn van het concept Broadcasting. Verwijzen naar deze link als u niet bekend bent met het concept uitzenden.
Nu we onze newSeries-serie gebruiken, zullen we operaties zien die worden uitgevoerd met behulp van het uitzendconcept.
newSeries + 5

Hier voegde het 5 toe aan elk afzonderlijk element in Series newSeries. Dit wordt ook wel elementgewijze bewerkingen genoemd. Evenzo voor andere bewerkingen zoals *, /, -, ** en ook andere operatoren. We zullen alleen ** operator zien, en je zou het ook voor andere operators moeten proberen.
newSeries ** 1/2

Hier nemen we de elementaire vierkantswortel van elk getal. Onthoud dat de vierkantswortel elk getal is dat tot de macht 1/2 wordt verheven.
Panda's DataFrame
Dataframe is inderdaad de meest gebruikte en belangrijke datastructuur van Panda's. Beschouw een dataframe als een Excel-blad.
De belangrijkste manieren om Data Frame te maken zijn
- Een CSV/Excel-bestand lezen
- Python-woordenboek
- ndarray
Laten we een voorbeeld nemen van het maken van een dataframe met behulp van een woordenboek.
We kunnen een dataframe maken door een woordenboek door te geven waarin elke waarde van het woordenboek een lijst is.
df1 = {"Name":["Ahmad","Ali",'Ismail',"John"],"Age": [20,21,19,17],"Height":[5.1,5.6,6.1,5.7]}
Om dit woordenboek om te zetten in een dataframe, hoeven we alleen maar de dataframe-functie op dit woordenboek aan te roepen.
df1 = pd.DataFrame(df1)
df1

df1
Waarden ophalen uit een kolom
Om waarden uit een kolom te halen, kunnen we deze syntaxis gebruiken
#df1['columnname']
#df1.columnname
Beide syntaxen zijn correct, maar we moeten voorzichtig zijn bij het kiezen van een. Als onze kolomnaam een spatie bevat, kunnen we zeker de 2e methode niet gebruiken. We moeten de eerste methode gebruiken. We kunnen de 2e methode alleen gebruiken als er geen spatie is in de kolomnaam.

df1.Naam
Hier kunnen we de waarden van de kolom zien, hun indexnummer, de naam van de kolom en het gegevenstype van de kolom.
df1['Age']

df1['Leeftijd']
We kunnen zien dat het gebruik van beide syntaxis de kolom van het dataframe retourneert waar we het kunnen analyseren.
Waarden van meerdere kolommen
Om waarden van meerdere kolommen in een gegevensframe te krijgen, geeft u de naam van kolommen door als een lijst.
df1[["Name","Age"]]

df1[["Naam", "Leeftijd"]]
We kunnen zien dat het het dataframe heeft geretourneerd met twee kolommen Naam en Leeftijd.
Laten we belangrijke functies van DataFrame verkennen door een dataset te gebruiken die bekend staat als 'Titanic'. Deze dataset is algemeen online beschikbaar, of u kunt deze downloaden op Kaggle.
Gegevens lezen
Pandas heeft goede ingebouwde ondersteuning voor het lezen van verschillende soorten gegevens, waaronder CSV, Fether, Excel, HTML, JSON, Pickle, SAS, SQL en nog veel meer.
De gebruikelijke syntaxis om gegevens te lezen is
# pd.read_fileExtensionName("File Path")
CSV
Om gegevens uit een CSV-bestand te lezen, hoeft u alleen maar de pandas read_csv-functie te gebruiken.
df = pd.read_csv('Path_To_CSVFile')
Omdat titanic ook beschikbaar is in CSV-formaat, zullen we het lezen met de functie read_csv. Wanneer u de dataset downloadt, heeft u twee bestanden met de namen train.csv en test.csv, die u zullen helpen bij het testen van machine learning-modellen, dus we zullen ons alleen concentreren op het train_csv-bestand.
df = pd.read_csv('train.csv')
Nu is df automatisch een dataframe. Laten we enkele van zijn functies verkennen.
hoofd()
Als u uw dataset normaal afdrukt, zal deze een volledige dataset tonen, die een miljoen rijen of kolommen kan hebben, wat moeilijk te zien en te analyseren is. df.head() functie stelt ons in staat om de eerste 'n' rijen van de dataset te zien (standaard 5) zodat we een ruwe schatting kunnen maken van onze dataset, en welke belangrijke functies daarop moeten worden toegepast.

df.head ()
Nu kunnen we onze kolommen in de dataset zien, en hun waarden voor de eerste 5 rijen. Omdat we geen waarde hebben doorgegeven, worden de eerste 5 rijen weergegeven.
staart()
Net als bij de kopfunctie hebben we een staartfunctie die als laatste wordt weergegeven n waarden.
df.tail(3)

df.staart (3)
We kunnen de laatste 3 rijen van onze dataset zien, als we df.tail(3) zijn gepasseerd.
vorm()
De shape() is een andere belangrijke functie om de vorm van de dataset te analyseren, wat erg handig is bij het maken van onze machine learning-modellen, en we willen dat onze dimensies exact zijn.
df.shape()
![]()
![]() df.vorm()
df.vorm()
Hier kunnen we zien dat onze uitvoer (891,12) is, wat gelijk is aan 891 rijen en 12 kolommen, wat betekent dat we in totaal 12 kenmerken of 12 kolommen en 891 rijen of 891 voorbeelden hebben.
Toen we eerder de functie df.tail() gebruikten, was het indexnummer van onze laatste kolom 890 omdat onze index begon bij 0, niet bij 1. Als het indexnummer begon bij 1, dan zouden we een indexnummer hebben van de laatste kolom als 891.
is niets()
Dit is een andere belangrijke functie die wordt gebruikt om de null-waarden in een dataset te vinden. We kunnen in eerdere uitvoer zien dat sommige waarden NaN zijn, wat betekent "Geen getal", en we moeten omgaan met deze ontbrekende waarden om goede resultaten te krijgen. isnull() is een belangrijke functie om met deze null-waarden om te gaan.
df.isnull().head()
Ik gebruik de head-functie zodat we de eerste 5 voorbeelden kunnen zien, niet de hele dataset.

df.isnull().head()
Hier kunnen we zien dat sommige waarden in de kolommen "Cabine" waar zijn. Waar betekent dat de waarde NaN is of ontbreekt. We kunnen zien dat dit onduidelijk is om te zien en te begrijpen, dus we kunnen de functie sum() gebruiken om meer gedetailleerde informatie te krijgen.
som()
De somfunctie wordt gebruikt om alle waarden in een dataframe op te tellen. Onthoud dat True 1 betekent en False 0, dus om alle True-waarden te krijgen die worden geretourneerd door de functie isnull(), kunnen we de functie sum() gebruiken. Laten we het bekijken.
df.isnull().sum()

df.isnull().sum()
Hier kunnen we zien dat alleen ontbrekende waarden in de kolommen "Leeftijd", "Cabine" & "Ingescheept" staan.
info ()
De info-functie is ook een veelgebruikte panda-functie, die "een beknopte samenvatting van een DataFrame afdrukt".

df.info()
Hier kunnen we zien dat het ons vertelt hoeveel niet-null entiteiten we hebben, zoals in het geval van Age, we hebben 714 Non-Null float64 type entiteiten. Het vertelt ons ook over het geheugengebruik, in dit geval 83.6 KB.
beschrijven()
Beschrijven is ook een superhandige functie om de gegevens te analyseren. Het vertelt ons over de beschrijvende statistieken van een dataframe, inclusief de statistieken die de centrale tendens, spreiding en vorm van de distributie van een dataset samenvatten, exclusief waarden.
df.describe()

df.describe ()
Hier kunnen we enkele belangrijke statistische analyses van elke kolom bekijken, inclusief het gemiddelde, de standaarddeviatie, de minimumwaarde en nog veel meer. Lees er meer over in zijn documentatie.
Dit is ook een van de belangrijke en veelgebruikte concepten, zowel in Numpy als in Panda's.
Zoals de naam al doet vermoeden, indexeren we met booleaanse variabelen, dwz True en False. Als de index True is, laat die rij dan zien, en als de Index False is, laat die rij dan niet zien.
Het helpt ons enorm wanneer we belangrijke functies uit onze dataset proberen te extraheren. Laten we een voorbeeld nemen waarbij we alleen de vermeldingen willen zien waar "Sex" "mannelijk" is. Laten we eens kijken hoe we dit gaan aanpakken.
df["Sex"]=="male"
Dit retourneert een reeks Booleaanse waarden True en False, waarbij True de rij is waarin "Sex" "mannelijk" is, anders False.
Om alleen de eerste 10 resultaten te zien, kan ik de head-functie gebruiken als
(df["Sex"]=="male").head(10)
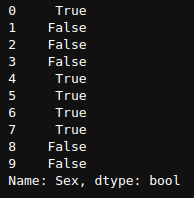
(df[“geslacht”]==”mannelijk”).head(10)
Om nu het volledige dataframe te zien met alleen die rijen waar "Sex" "male" is, moeten we df["Sex"]=="male" in dataframe doorgeven om alle resultaten te krijgen waar "Sex" "male" is ”.
df[df["Sex"]=="male"].head(5)

Hier kunnen we zien dat alle resultaten die we hebben die zijn waar Seks mannelijk is.
Laten we nu wat nuttige informatie afleiden met behulp van Booleaanse indexering.
Om rijen op basis van meerdere voorwaarden te krijgen, gebruiken we haakjes "()" en "&,|,!="-tekens tussen meerdere voorwaarden.
Laten we eens kijken wat het percentage is van alle mannelijke passagiers die het hebben overleefd.
df[(df["Sex"]=="male") & (df["Survived"]==1)]

Geef deze code even de tijd om te lezen en te begrijpen wat er gebeurt. We verzamelen alle rijen uit het dataframe waar df[“Sex”] == “male” en df[“Survived”]==1. De geretourneerde waarde is een dataframe met alle rijen mannelijke passagiers die het hebben overleefd.
Laten we eens kijken hoeveel procent van de mannelijke passagiers het heeft overleefd.
Nu is de formule voor het percentage mannelijke passagiers dat het heeft overleefd Totaal aantal mannelijke overlevenden / Totaal aantal mannelijke passagiers

In panda's kunnen we dit schrijven als
men = df[df['Sex']=='male']['Survived']
perc = sum(men) / len(men) * 100
Laten we deze code stap voor stap doorbreken.
df['Sex']=='male' zal een booleaanse reeks voorbeelden teruggeven waar sex mannelijk is.
df[df["Sex"]=="male"] geeft het volledige dataframe terug met alle voorbeelden waarin "Sex" "male" is.
men = df[df['Sex']=='male']['Survived'] geeft de kolom 'Survived' terug van het dataframe van alle passagiers die mannelijk zijn.
sum(men) somt alle mannen op die het hebben overleefd. Aangezien het een reeks van 0 en 1 is, zal len(men) het aantal totale mannen retourneren.
Zet deze nu in de bovenstaande formule en we zullen het percentage vinden van alle mannen die de Titanic hebben overleefd
![]()
![]()
18%!!!!!. Ja, slechts 18% van de mannen in onze dataset heeft de ramp met de Titanic overleefd.
Evenzo kunnen we het coderen voor vrouwen, wat ik niet zal doen, maar het is jouw taak, we ontdekken dat 74% van de vrouwelijke passagiers deze ramp heeft overleefd.
Dit brengt ons aan het einde van dit artikel. Nu zijn er natuurlijk tal van andere belangrijke functies in Panda's die erg belangrijk zijn, zoals groupby, toepassen, iloc, hernoemen, vervangen enz. Ik raad je aan om de "Python voor gegevensanalyse" boek van Wes, de maker van deze Panda's-bibliotheek.
Kijk ook eens deze spiekbrief door Dataquest voor snelle referentie.
Ahmad is geïnteresseerd in Machine Learning, Deep Learning en Computer Vision. Momenteel werkzaam als Jr. Machine Learning engineer bij Redbuffer.
- Coinsmart. Europa's beste Bitcoin- en crypto-uitwisseling.Klik Hier
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2020/06/introduction-pandas-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-pandas-for-data-science

