Amazon RedshiftML stelt data-analisten, ontwikkelaars en datawetenschappers in staat machine learning-modellen (ML) te trainen met behulp van SQL. In eerdere berichten hebben we gedemonstreerd hoe u de automatische modeltrainingsmogelijkheid van Redshift ML kunt gebruiken om te trainen classificatie en regressie modellen. Met Redshift ML kunt u een model maken met behulp van SQL en uw algoritme specificeren, zoals XGBoost. U kunt Redshift ML gebruiken om de gegevensvoorbereiding, voorverwerking en selectie van uw probleemtype te automatiseren (raadpleeg voor meer informatie Maak, train en implementeer machine learning-modellen in Amazon Redshift met behulp van SQL met Amazon Redshift ML). Je kunt ook een eerder getraind model meenemen Amazon Sage Maker in Amazon roodverschuiving via Redshift ML voor lokale gevolgtrekking. Voor lokale gevolgtrekkingen op modellen die in SageMaker zijn gemaakt, moet het ML-modeltype worden ondersteund door Redshift ML. Echter, gevolgtrekking op afstand is beschikbaar voor modeltypen die niet standaard beschikbaar zijn in Redshift ML.
Na verloop van tijd worden ML-modellen oud, en zelfs als er niets drastisch gebeurt, stapelen kleine veranderingen zich op. Veelvoorkomende redenen waarom ML-modellen moeten worden omgeschoold of gecontroleerd, zijn onder meer:
- Gegevensdrift – Omdat uw gegevens in de loop van de tijd zijn veranderd, kan de voorspellingsnauwkeurigheid van uw ML-modellen afnemen in vergelijking met de nauwkeurigheid die tijdens het testen werd getoond
- Begrip drift – Het ML-algoritme dat aanvankelijk werd gebruikt, moet mogelijk worden gewijzigd vanwege verschillende bedrijfsomgevingen en andere veranderende behoeften
Mogelijk moet u het model regelmatig vernieuwen, het proces automatiseren en de verbeterde nauwkeurigheid van uw model opnieuw evalueren. Op het moment van schrijven ondersteunt Amazon Redshift geen versiebeheer van ML-modellen. In dit bericht laten we zien hoe u de Bring Your Own Model (BYOM)-functionaliteit van Redshift ML kunt gebruiken om versiebeheer van Redshift ML-modellen te implementeren.
We gebruiken lokale inferentie om modelversiebeheer te implementeren als onderdeel van het operationeel maken van ML-modellen. We gaan ervan uit dat u een goed inzicht heeft in uw gegevens en het probleemtype dat het meest van toepassing is op uw gebruiksscenario, en dat u modellen hebt gemaakt en geïmplementeerd voor productie.
Overzicht oplossingen
In dit bericht gebruiken we Redshift ML om een regressiemodel te bouwen dat het aantal mensen voorspelt dat op een bepaald uur van de dag gebruik mag maken van de fietsdeelservice van de stad Toronto. Het model houdt rekening met verschillende aspecten, waaronder vakanties en weersomstandigheden, en omdat we een numerieke uitkomst moeten voorspellen, hebben we een regressiemodel gebruikt. We gebruiken datadrift als reden om het model opnieuw te trainen en gebruiken modelversiebeheer als onderdeel van de oplossing.
Nadat een model is gevalideerd en regelmatig wordt gebruikt voor het uitvoeren van voorspellingen, kunt u versies van de modellen maken. Hiervoor moet u het model opnieuw trainen met behulp van een bijgewerkte trainingsset en mogelijk een ander algoritme. Versiebeheer dient twee hoofddoelen:
- U kunt eerdere versies van een model raadplegen voor probleemoplossing of auditdoeleinden. Hierdoor kunt u ervoor zorgen dat uw model nog steeds een hoge nauwkeurigheid behoudt voordat u overschakelt naar een nieuwere modelversie.
- U kunt gevolgtrekkingsquery's blijven uitvoeren op de huidige versie van een model tijdens het modeltrainingsproces van de nieuwe versie.
Op het moment dat we dit schrijven beschikt Redshift ML niet over native versiebeheermogelijkheden, maar je kunt nog steeds versiebeheer realiseren door een paar eenvoudige SQL-technieken te implementeren met behulp van de BYOM-mogelijkheid. BYOM is geïntroduceerd om vooraf getrainde SageMaker-modellen te ondersteunen om uw gevolgtrekkingsquery's uit te voeren in Amazon Redshift. In dit bericht gebruiken we dezelfde BYOM-techniek om een versie te maken van een bestaand model dat is gebouwd met Redshift ML.
De volgende afbeelding illustreert deze workflow.

In de volgende secties laten we zien hoe u een versie van een bestaand model kunt maken en vervolgens een modelhertraining kunt uitvoeren.
Voorwaarden
Als voorwaarde voor het implementeren van het voorbeeld in dit bericht moet je een Roodverschuiving cluster or Amazon Redshift Serverloos eindpunt. Voor de voorbereidende stappen om aan de slag te gaan en uw omgeving in te stellen, raadpleegt u Maak, train en implementeer machine learning-modellen in Amazon Redshift met behulp van SQL met Amazon Redshift ML.
We gebruiken het regressiemodel dat in het bericht is gemaakt Bouw regressiemodellen met Amazon Redshift ML. We gaan ervan uit dat het al is geïmplementeerd en gebruiken dit model om nieuwe versies te maken en het model opnieuw te trainen.
Maak een versie van het bestaande model
De eerste stap is het creëren van een versie van het bestaande model (wat betekent dat ontwikkelingsveranderingen van het model worden opgeslagen), zodat de geschiedenis behouden blijft en het model later beschikbaar is voor vergelijking.
De volgende code is het algemene formaat van de syntaxis van de opdracht CREATE MODEL; in de volgende stap krijgt u de informatie die nodig is om deze opdracht te gebruiken om een nieuwe versie te maken:
Vervolgens verzamelen we de invoerparameters en passen we deze toe op de voorgaande CREATE MODEL-code op het model. We hebben de taaknaam en de gegevenstypen van de invoer- en uitvoerwaarden van het model nodig. We verzamelen deze door het uitvoeren van de show model commando op ons bestaande model. Voer de volgende opdracht uit in Amazon Redshift Query Editor v2:

Noteer de waarden voor AutoML-taaknaam, Functieparametertypen:En Doelkolom (trip_count) uit de modeluitvoer. We gebruiken deze waarden in de opdracht CREATE MODEL om de versie te maken.
Met de volgende instructie CREATE MODEL wordt een versie van het huidige model gemaakt met behulp van de waarden die zijn verzameld uit onze show model commando. We voegen de datum toe (de voorbeeldnotatie is JJJJMMDD) aan het einde van de model- en functienamen om bij te houden wanneer deze nieuwe versie is gemaakt.
Het kan enkele minuten duren voordat deze opdracht is voltooid. Wanneer het voltooid is, voert u de volgende opdracht uit:

In de uitvoer kunnen we het volgende waarnemen:
- AutoML-taaknaam is hetzelfde als de originele versie van het model
- Functie Naam toont de nieuwe naam, zoals verwacht
- Inferentie type shows
Local, wat aangeeft dat dit BYOM is met lokale gevolgtrekking
U kunt gevolgtrekkingsquery's uitvoeren met beide versies van het model om de gevolgtrekkingsuitvoer te valideren.
De volgende schermafbeelding toont de uitvoer van de modelinferentie met behulp van de originele versie.

De volgende schermafbeelding toont de uitvoer van modelinferentie met behulp van de versiekopie.

Zoals u kunt zien, zijn de gevolgtrekkingsuitgangen hetzelfde.
U hebt nu geleerd hoe u een versie van een eerder getraind Redshift ML-model kunt maken.
Train uw Redshift ML-model opnieuw
Nadat u een versie van een bestaand model hebt gemaakt, kunt u het bestaande model opnieuw trainen door eenvoudigweg een nieuw model te maken.
U kunt een nieuw model maken en trainen met dezelfde opdracht CREATE MODEL, maar met gebruik van andere invoerparameters, gegevenssets of probleemtypen, indien van toepassing. Voor dit bericht trainen we het model opnieuw op nieuwere datasets. Wij voegen toe _new aan de modelnaam, zodat deze voor identificatiedoeleinden vergelijkbaar is met het bestaande model.
In de volgende code gebruiken we de opdracht CREATE MODEL met een nieuwe gegevensset die beschikbaar is in de training_data tafel:
Voer de volgende opdracht uit om de status van het nieuwe model te controleren:
Vervang het bestaande Redshift ML-model door het opnieuw getrainde model
De laatste stap is het vervangen van het bestaande model door het opnieuw getrainde model. Dit doen we door de originele versie van het model te verwijderen en een model opnieuw te maken met behulp van de BYOM-techniek.
Controleer eerst uw opnieuw getrainde model om er zeker van te zijn dat de MSE/RMSE-scores stabiel blijven tussen modeltrainingsruns. Om de modellen te valideren, kunt u gevolgtrekkingen uitvoeren op basis van elk van de modelfuncties in uw dataset en de resultaten vergelijken. We gebruiken de gevolgtrekkingsquery's uit Bouw regressiemodellen met Amazon Redshift ML.
Na validatie kunt u uw model vervangen.
Begin met het verzamelen van de details van de predict_rental_count_new model.
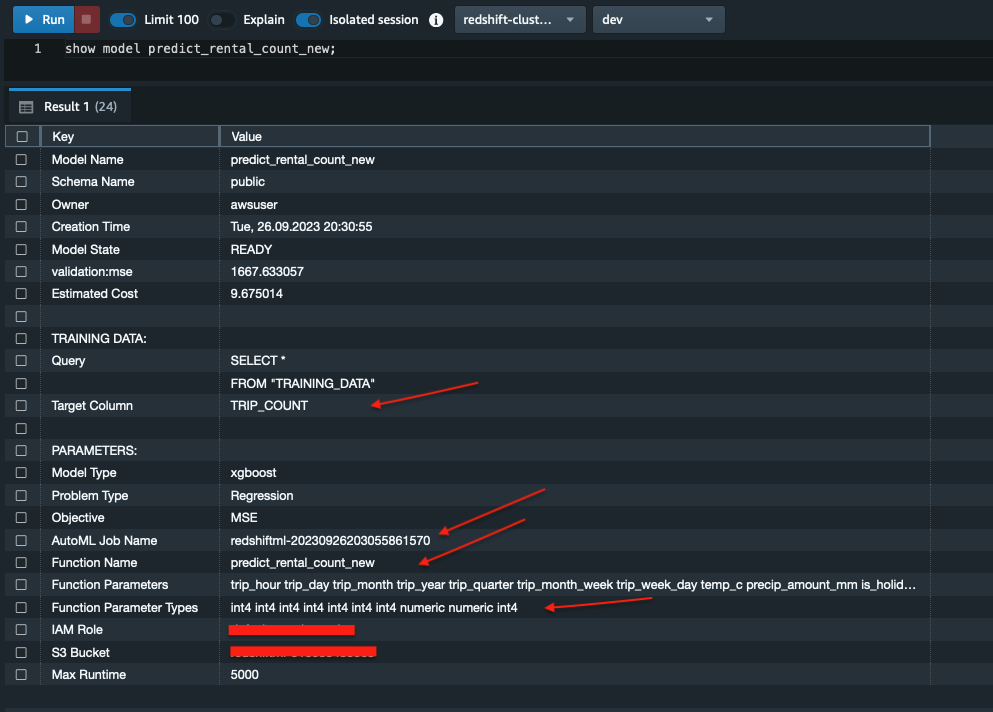
Merk op AutoML-taaknaam waarde, de Functieparametertypen: waarden, en de Doelkolom naam in de modeluitvoer.
Vervang het originele model door het originele model te verwijderen en vervolgens het model te maken met de originele model- en functienamen om ervoor te zorgen dat de bestaande verwijzingen naar het model en de functienamen werken:
Het maken van het model zou binnen een paar minuten voltooid moeten zijn. U kunt de status van het model controleren door de volgende opdracht uit te voeren:
Wanneer de modelstatus is ready, de nieuwere versie predict_rental_count van uw bestaande model beschikbaar is voor gevolgtrekking en de originele versie van het ML-model predict_rental_count_20230706 is indien nodig ter referentie beschikbaar.
Gelieve hiernaar te verwijzen GitHub-repository voor voorbeeldscripts om het versiebeheer van modellen te automatiseren.
Conclusie
In dit bericht hebben we laten zien hoe u de BYOM-functie van Redshift ML kunt gebruiken om modelversies te beheren. Hierdoor kunt u beschikken over een geschiedenis van uw modellen, zodat u modelscores in de loop van de tijd kunt vergelijken, kunt reageren op auditverzoeken en conclusies kunt trekken terwijl u een nieuw model traint.
Voor meer informatie over het bouwen van verschillende modellen met Redshift ML raadpleegt u Amazon RedshiftML.
Over de auteurs
 Rohit Bansal is een Analytics Specialist Solutions Architect bij AWS. Hij is gespecialiseerd in Amazon Redshift en werkt samen met klanten om analyseoplossingen van de volgende generatie te bouwen met behulp van andere AWS Analytics-services.
Rohit Bansal is een Analytics Specialist Solutions Architect bij AWS. Hij is gespecialiseerd in Amazon Redshift en werkt samen met klanten om analyseoplossingen van de volgende generatie te bouwen met behulp van andere AWS Analytics-services.
 Phil Bates is een Senior Analytics Specialist Solutions Architect bij AWS. Hij heeft meer dan 25 jaar ervaring met het implementeren van grootschalige datawarehouse-oplossingen. Hij is gepassioneerd om klanten te helpen tijdens hun cloudreis en de kracht van ML te gebruiken binnen hun datawarehouse.
Phil Bates is een Senior Analytics Specialist Solutions Architect bij AWS. Hij heeft meer dan 25 jaar ervaring met het implementeren van grootschalige datawarehouse-oplossingen. Hij is gepassioneerd om klanten te helpen tijdens hun cloudreis en de kracht van ML te gebruiken binnen hun datawarehouse.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/implement-model-versioning-with-amazon-redshift-ml/

