Voor moderne bedrijven die te maken hebben met enorme hoeveelheden documenten, zoals contracten, facturen, cv's en rapporten, is het efficiënt verwerken en ophalen van relevante gegevens van cruciaal belang voor het behouden van een concurrentievoordeel. Traditionele methoden voor het opslaan en zoeken naar documenten kunnen echter tijdrovend zijn en resulteren vaak in een grote inspanning om een specifiek document te vinden, vooral als ze handschrift bevatten. Wat als er een manier was om documenten op een intelligente manier te verwerken en ze met hoge nauwkeurigheid doorzoekbaar te maken?
Dit wordt mogelijk gemaakt met Amazon T-extract, de Intelligent Document Processing-service van AWS, gekoppeld aan de snelle zoekmogelijkheden van OpenSearch. In dit bericht nemen we u mee op een reis om snel een oplossing voor het indexeren van documenten te bouwen en te implementeren waarmee uw organisatie inzichten beter kan benutten en uit documenten kan halen.
Of u nu bij Human Resources op zoek bent naar specifieke clausules in werknemerscontracten, of als financieel analist een berg facturen doorzoekt om betalingsgegevens te extraheren, deze oplossing is op maat gemaakt om u in staat te stellen met ongekende snelheid en nauwkeurigheid toegang te krijgen tot de informatie die u nodig heeft.
Met de voorgestelde oplossing worden uw documenten automatisch opgenomen, wordt hun inhoud geparseerd en vervolgens geïndexeerd in een zeer responsieve en schaalbare OpenSearch-index.
We bespreken hoe technologieën zoals Amazon Textract, AWS Lambda, Amazon eenvoudige opslagservice (Amazon S3), en Amazon OpenSearch-service kan worden geïntegreerd in een workflow die documenten naadloos verwerkt. Vervolgens duiken we in het indexeren van deze gegevens in OpenSearch en demonstreren we de zoekmogelijkheden die binnen handbereik beschikbaar komen.
Of uw organisatie nu de eerste stappen zet in het digitale transformatietijdperk of een gevestigde reus is die het ophalen van informatie een boost wil geven, deze gids is uw kompas bij het navigeren door de mogelijkheden die AWS Intelligent Document Processing en OpenSearch bieden.
De uitvoering gebruikt in dit bericht maakt gebruik van de Amazon Textract IDP CDK-constructies – AWS Cloud Development Kit (CDK)-componenten om de infrastructuur voor Intelligent Document Processing (IDP)-workflows te definiëren, waarmee u gebruikscasus-specifieke, aanpasbare IDP-workflows kunt bouwen. De IDP CDK-constructies en -voorbeelden zijn een verzameling componenten om de definitie van IDP-processen op AWS mogelijk te maken en ernaar te publiceren GitHub. De belangrijkste gebruikte concepten zijn de AWS Cloudontwikkelingskit (CDK) constructies, het werkelijke CDK-stapels en AWS Stap Functies. De workshop Gebruik machine learning om documenten op grote schaal te automatiseren en verwerken is een goed startpunt om meer te leren over het aanpassen van workflows en het gebruiken van de andere voorbeeldworkflows als basis voor uw eigen workflows.
Overzicht oplossingen
In deze oplossing richten we ons op het indexeren van documenten in een OpenSearch-index voor het snel zoeken en ophalen van informatie en documenten. Documenten in PDF-, TIFF-, JPEG- of PNG-formaat worden in een Amazon Simple Storage Service geplaatst (Amazon S3) bucket en vervolgens geïndexeerd in OpenSearch met behulp van deze Step Functions-workflow.
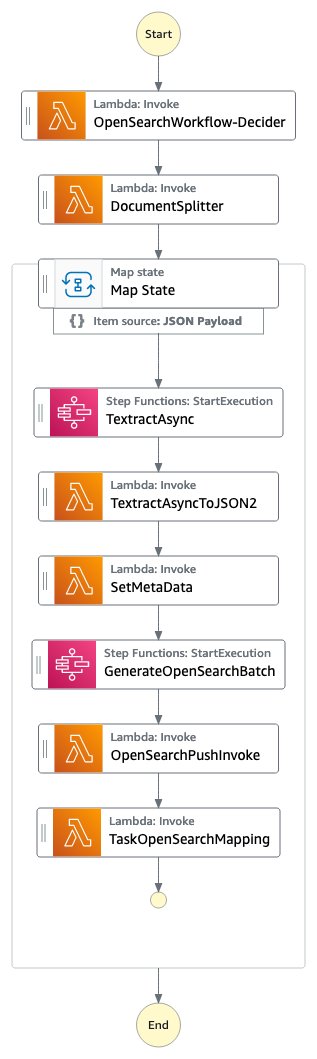
Figuur 1: De Step Functions OpenSearch-workflow
De OpenSearchWorkflow-Beslisser bekijkt het document en verifieert dat het document een van de ondersteunde mime-typen is (PDF, TIFF, PNG of JPEG). Het bestaat uit één AWS Lambda functie.
De Documentsplitter genereert maximaal 2500 pagina's uit documenten. Dit betekent dat, ook al ondersteunt Amazon Textract documenten van maximaal 3000 pagina's, je documenten met veel meer pagina's kunt doorgeven en dat het proces nog steeds prima werkt en de pagina's in OpenSearch plaatst en de juiste paginanummers aanmaakt. De Documentsplitter is geïmplementeerd als een AWS Lambda-functie.
De Kaart staat verwerkt elk deel parallel.
De TextractAsync taak roept Amazon Textract aan met behulp van de asynchroon Application Programming Interface (API) volgt 'best practices' met Amazon Simple Notification Service (Amazon SNS) meldingen en Uitvoerconfiguratie om de Amazon Textract JSON-uitvoer op te slaan in een Amazon S3-bucket van een klant. Het bestaat uit twee Amazon Lambda-functies: één om het document ter verwerking in te dienen en één om geactiveerd te worden bij de Amazon SNS-melding.
Omdat de TextractAsync-taak kan meerdere gepagineerde uitvoerbestanden produceren, de TextractAsyncToJSON2 proces combineert ze in één JSON-bestand.
De Step Functions-context is verrijkt met informatie die ook doorzoekbaar moet zijn in de OpenSearch-index in de SetMetaData stap. De voorbeeldimplementatie voegt toe ORIGIN_FILE_NAME, START_PAGE_NUMBER en ORIGIN_FILE_URI. U kunt alle informatie toevoegen om de zoekervaring te verrijken, zoals informatie uit andere backend-systemen, specifieke ID's of classificatie-informatie.
De GenereerOpenSearchBatch neemt de gegenereerde Amazon Textract-uitvoer JSON, combineert deze met de informatie uit de context die is ingesteld door SetMetaData en bereidt een bestand voor dat is geoptimaliseerd voor batchimport in OpenSearch.
In het OpenSearchPushInvoke, wordt dit batch-importbestand naar de OpenSearch-index gestuurd en beschikbaar voor zoeken. Deze AWS Lambda-functie is verbonden met de aws-lambda-opensearch construeren uit de AWS-oplossingen bibliotheek met behulp van de m6g.large.search-instanties, OpenSearch versie 2.7, en configureerde de Amazon Elastic Block Service (Amazon EBS) volumegrootte naar General Purpose 2 (GP2) met 200 GB. U kunt de OpenSearch-configuratie aanpassen aan uw wensen.
De uiteindelijke TaakOpenSearchMapping stap wist de context, die anders de context zou kunnen overschrijden Stap Functies Quotum of Maximale invoer- of uitvoergrootte voor een taak, status of uitvoering.
Voorwaarden
Om de samples te kunnen inzetten heb je een AWS-account nodig, de AWS Cloud Development Kit (AWS CDK), zijn een actuele Python-versie en Docker vereist. U heeft machtigingen nodig om AWS CloudFormation-sjablonen te implementeren, push naar de Amazon Elastic Container-register (Amazon ECR), creëren Amazon Identiteits- en toegangsbeheer (AWS IAM)-rollen, Amazon Lambda-functies, Amazon S3-buckets, Amazon Step Functions, Amazon OpenSearch-cluster en een Amazon Cognito gebruikerspool. Zorg ervoor dat uw AWS CLI-omgeving is ingesteld met de bijbehorende machtigingen.
Je kunt ook een spin-up maken AWS-Cloud9 instance met AWS CDK, Python en Docker vooraf geïnstalleerd om de implementatie te starten.
walkthrough
Deployment
- Nadat u de vereisten hebt ingesteld, moet u eerst de repository klonen:
- CD vervolgens naar de repositorymap en installeer de afhankelijkheden:
- Implementeer de OpenSearchWorkflow-stack:
De implementatie duurt ongeveer 25 minuten met de standaardconfiguratie-instellingen van de GitHub-voorbeelden en creëert een Step Functions-workflow, die wordt aangeroepen wanneer een document in een Amazon S3-bucket/voorvoegsel wordt geplaatst en vervolgens wordt verwerkt totdat de inhoud van het document is geïndexeerd in een OpenSearch-cluster.
Het volgende is een voorbeelduitvoer, inclusief nuttige links en informatie die is gegenereerd vanuitcdk deploy OpenSearchWorkflowopdracht:
Deze informatie is ook beschikbaar in de AWS CloudFormation Console.
Wanneer een nieuw document onder de OpenSearchWorkflow.DocumentUploadLocation, wordt voor dit document een nieuwe Step Functions-workflow gestart.
Om de status van dit document te controleren, gebruikt u de OpenSearchWorkflow.StepFunctionFlowLink biedt een link naar de lijst met StepFunction-uitvoeringen in de AWS Management Console, waarbij de status van de documentverwerking wordt weergegeven voor elk document dat naar Amazon S3 is geüpload. De tutorial Uitvoeringen bekijken en debuggen op de Step Functions-console biedt een overzicht van de componenten en weergaven in de AWS Console.
Testen
- Test eerst met een voorbeeldbestand.
- Nadat u de link naar de StepFunction-workflow hebt geselecteerd of de AWS Management Console hebt geopend en naar de Step Functions-servicepagina bent gegaan, kunt u de verschillende workflow-aanroepen bekijken.
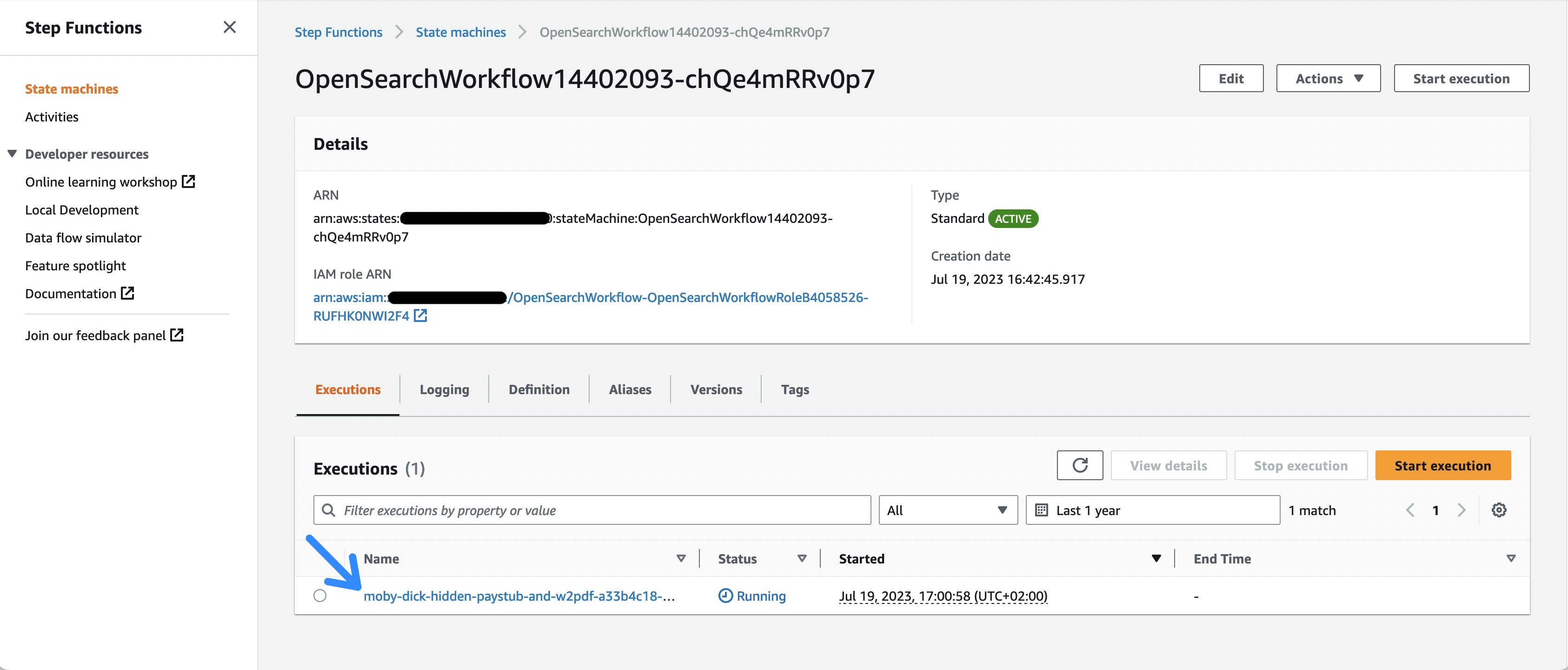
Figuur 2: De lijst met uitvoeringen van stapfuncties
- Bekijk de momenteel lopende voorbeelddocumentuitvoering, waar u de uitvoering van de afzonderlijke workflowtaken kunt volgen.
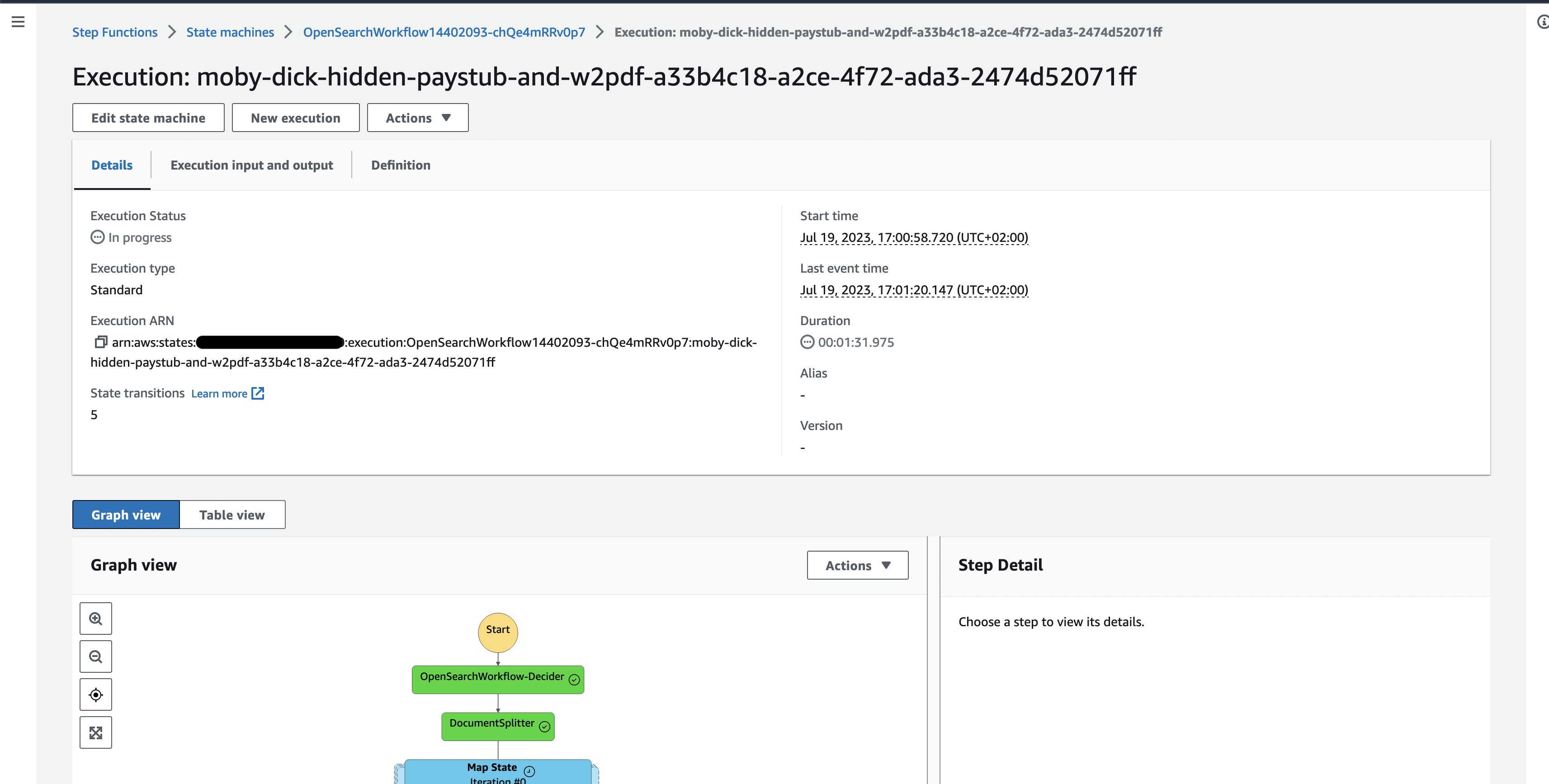
Figuur 3: Eén document Stap Functies workflowuitvoering
Ontdek
Zodra het proces is voltooid, kunnen we valideren dat het document is geïndexeerd in de OpenSearch-index.
- Om dit te doen, maken we eerst een Amazon Cognito-gebruiker aan. Amazon Cognito wordt gebruikt voor authenticatie van gebruikers tegen de OpenSearch-index. Selecteer de link in de uitvoer van de cdk-implementatie (of kijk naar de AWS CloudFormatie uitvoer in de AWS Management Console) genoemd OpenSearchWorkflow.CognitoUserPoolLink.
Figuur 4: De Cognito-gebruikerspool
- Selecteer vervolgens de Gebruiker maken knop, die u naar een pagina leidt waar u een gebruikersnaam en wachtwoord kunt invoeren voor toegang tot het OpenSearch Dashboard.
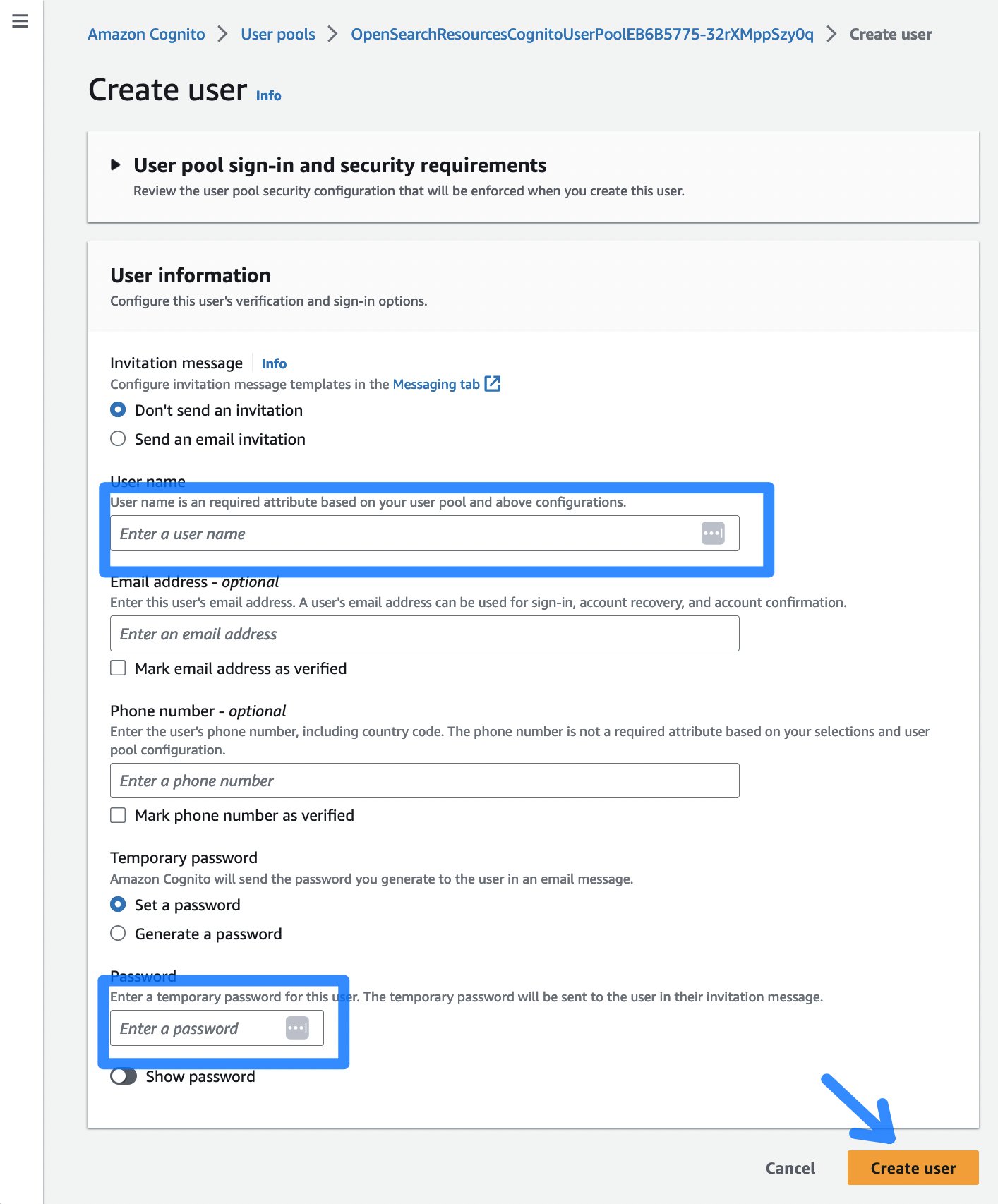
Figuur 5: Het dialoogvenster Cognito-gebruiker maken
- Na het kiezen Gebruiker maken, kunt u doorgaan naar het OpenSearch Dashboard door op te klikken OpenSearchWorkflow.OpenSearchDashboard van de uitvoer van de CDK-implementatie. Log in met de eerder aangemaakte gebruikersnaam en wachtwoord. De eerste keer dat u inlogt, moet u het wachtwoord wijzigen.
- Nadat u bent ingelogd op het OpenSearch Dashboard, selecteert u de Stapelbeheer sectie, gevolgd door Indexpatroons om een zoekindex te maken.
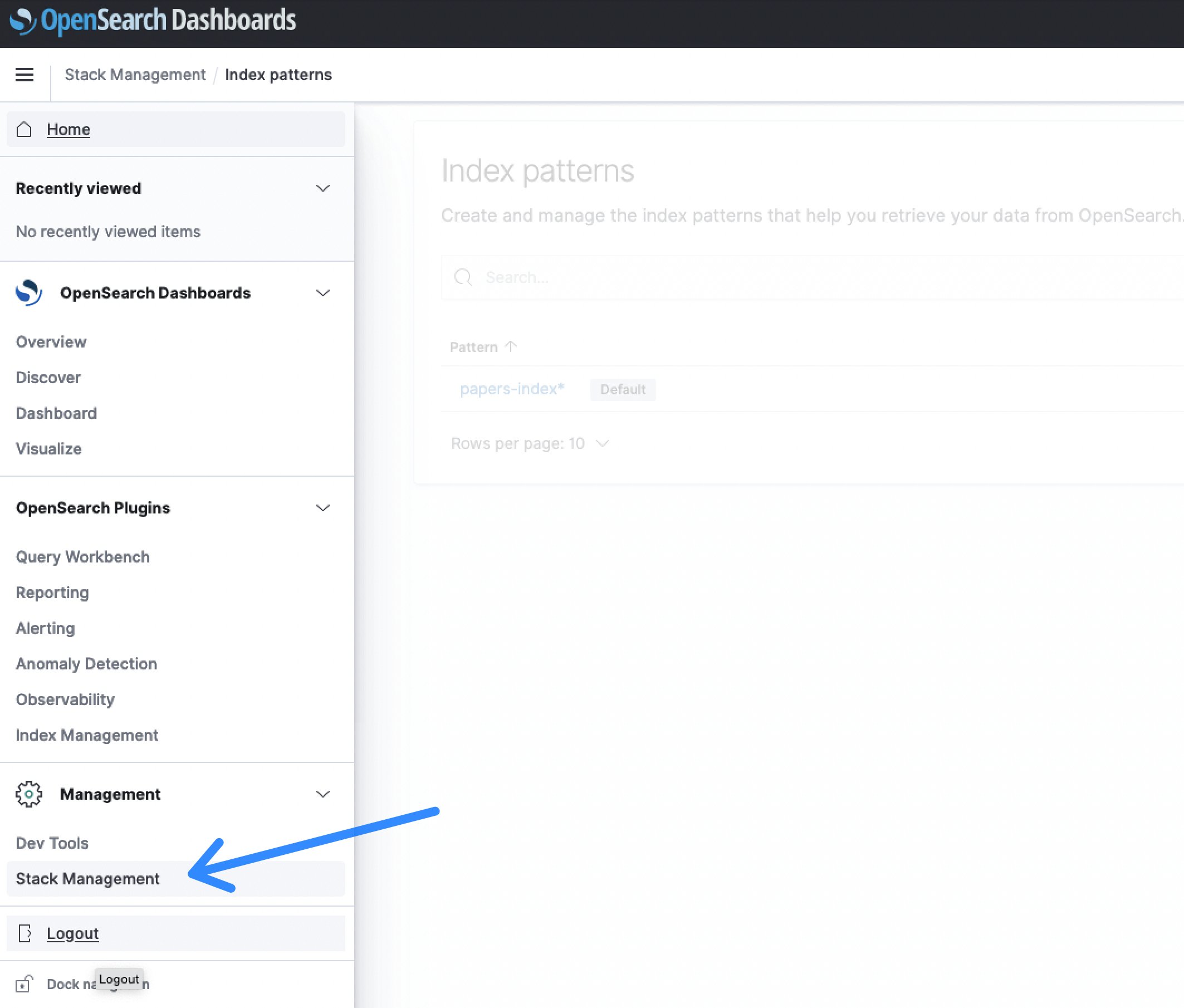
Figuur 6: OpenSearch Dashboards-stapelbeheer
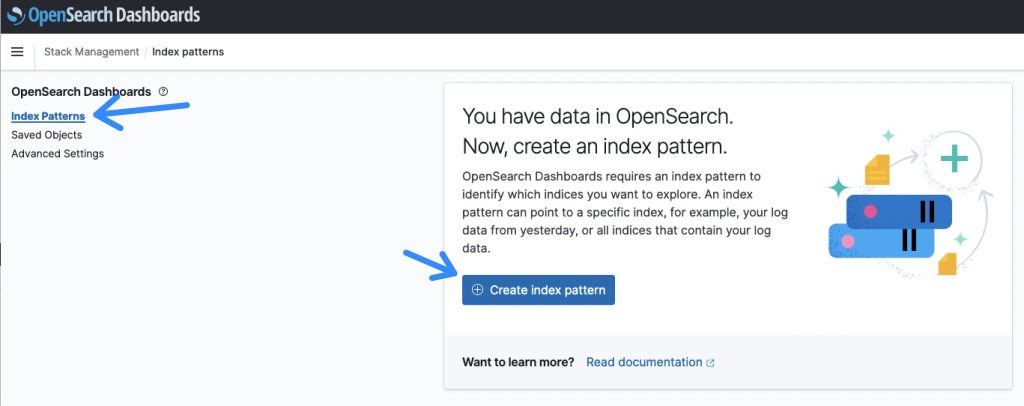
Figuur 7: Overzicht van OpenSearch-indexpatronen
- De standaardnaam voor de index is papieren-index en een indexpatroonnaam van papieren-index* zal dat evenaren.

Figuur 8: Definieer het OpenSearch-indexpatroon
- na het klikken op Volgende stapselecteer tijdstempel de Tijdveld en Indexpatroon maken.
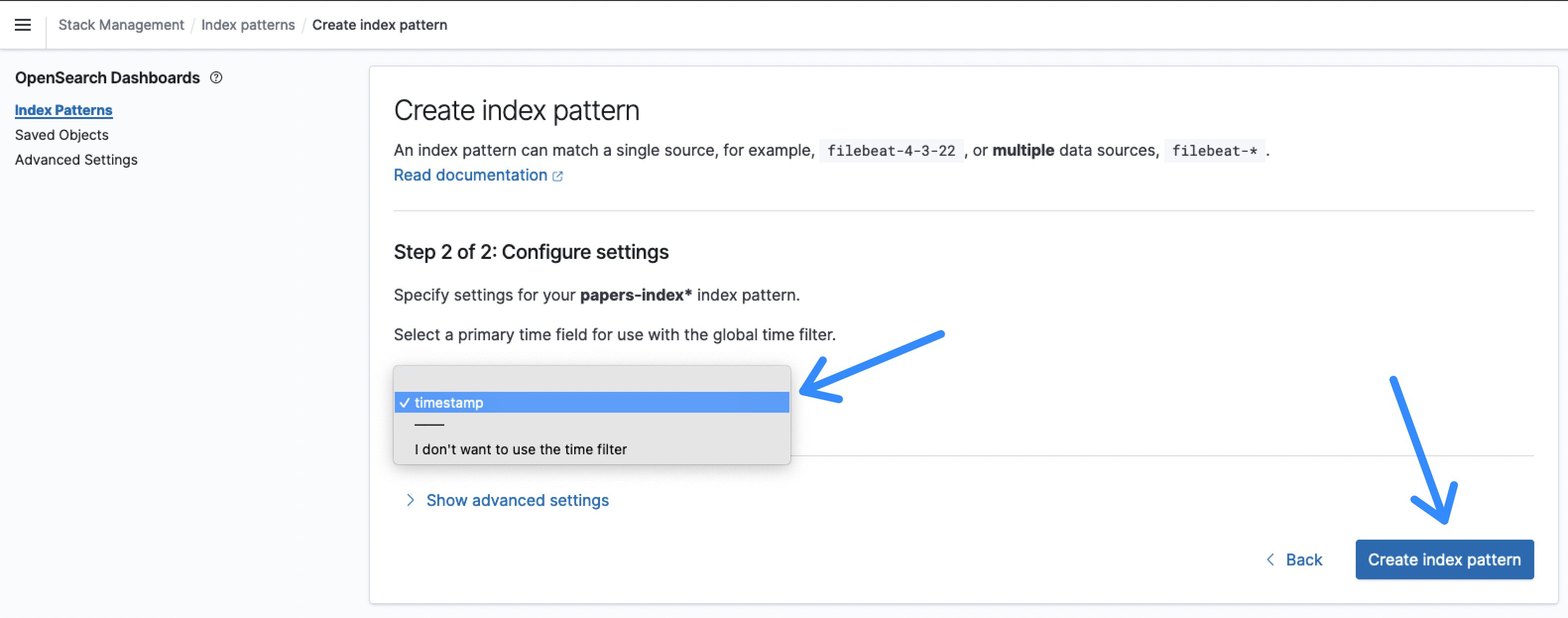
Figuur 9: OpenSearch-indexpatroontijdveld
- Selecteer nu in het menu Discover.
Figuur 10: OpenSearch Discover
In de meeste gevallen moet u de tijdsduur aanpassen aan uw laatste inname. De standaardwaarde is 15 minuten en vaak was er de afgelopen 15 minuten geen activiteit. In dit voorbeeld is dit gewijzigd in 15 dagen om de inname te visualiseren.
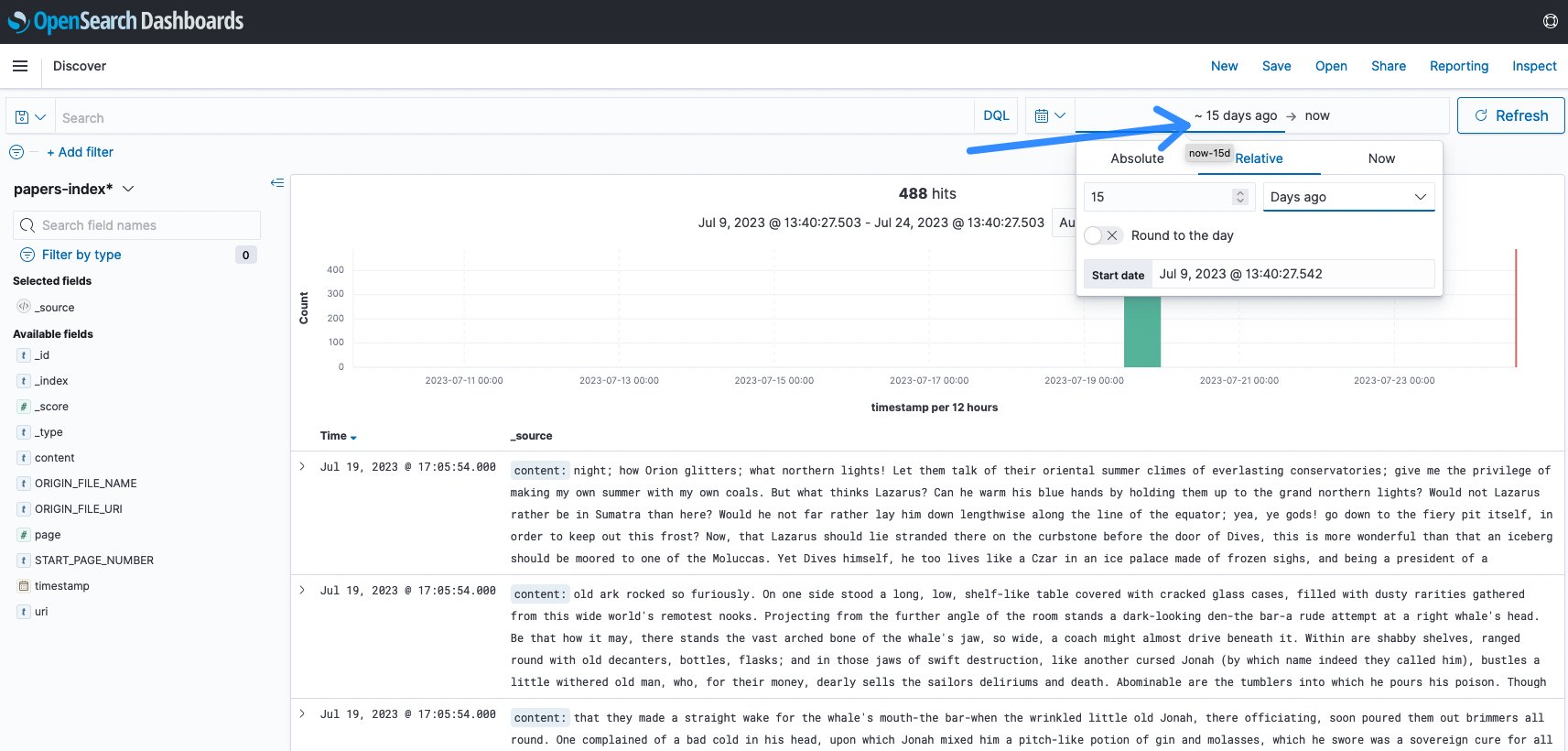
Figuur 11: Wijziging van de OpenSearch-tijdspanne
- Nu kunt u beginnen met zoeken. Een roman is geïndexeerd, u kunt zoeken op alle termen zoals noem mij Ismaël en bekijk de resultaten.
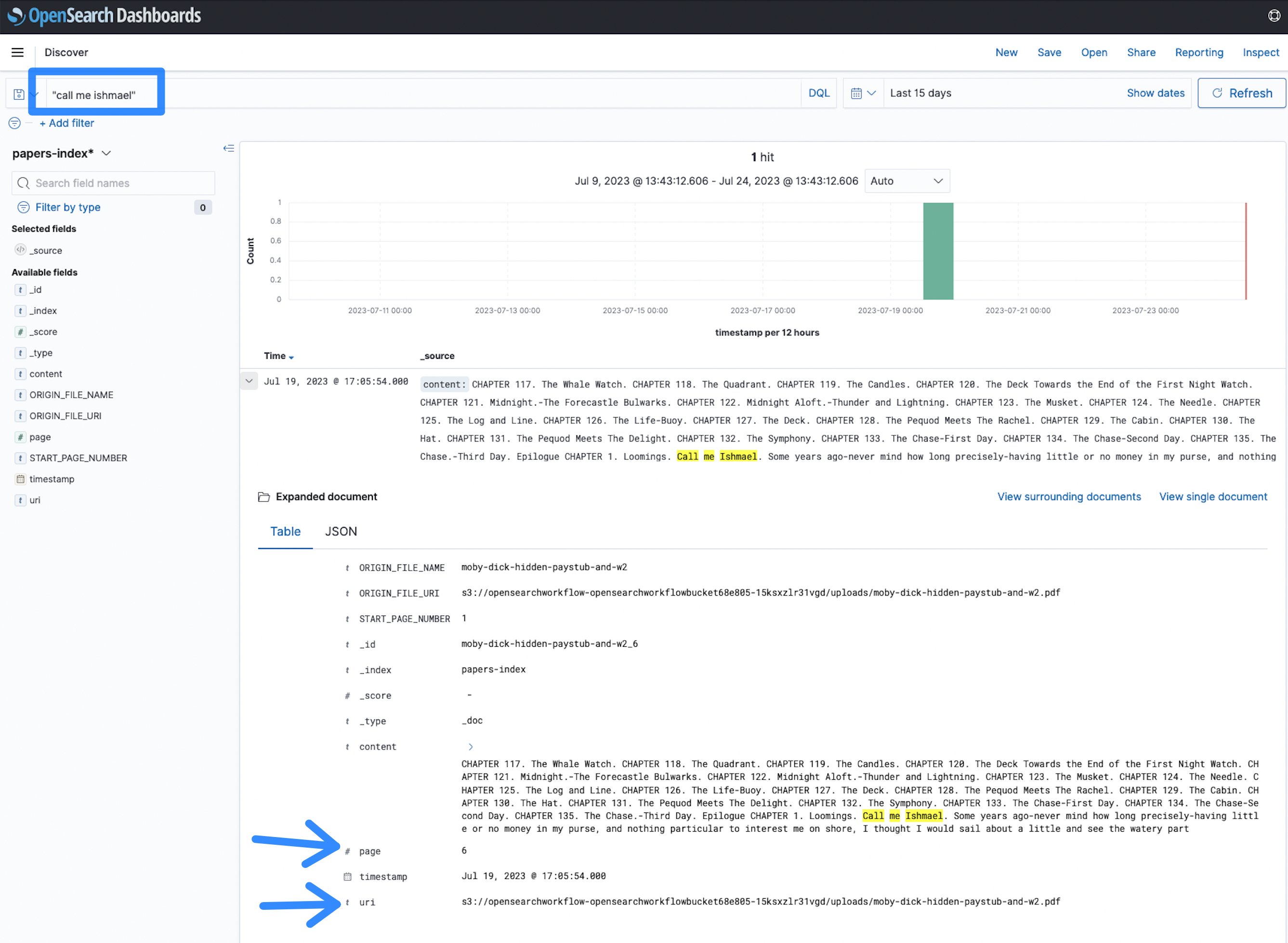
Figuur 12: OpenSearch-zoekterm
In dit geval is de term noem mij Ismaël verschijnt op pagina 6 van het document met de opgegeven Uniform Resource Identifier (URI), die verwijst naar de Amazon S3-locatie van het bestand. Dit maakt het sneller om documenten te identificeren en informatie te vinden in een groot corpus van PDF-, TIFF- of afbeeldingsdocumenten, vergeleken met het handmatig overslaan ervan.
Op schaal draaien
Om de omvang en duur van een indexeringsproces te schatten, werd de implementatie getest met 93,997 documenten en een totaal van 1,583,197 pagina's (gemiddeld 16.84 pagina's/document en het grootste bestand met 3755 pagina's), die allemaal werden geïndexeerd in OpenSearch. Het verwerken van alle bestanden en het indexeren ervan in OpenSearch duurde 5.5 uur in de regio VS-Oost (N. Virginia – us-east-1) met standaard Amazon Textract-servicequota. De onderstaande grafiek toont een eerste test om 18 uur, gevolgd door de hoofdinname om 00 uur en alles gedaan om 21 uur.
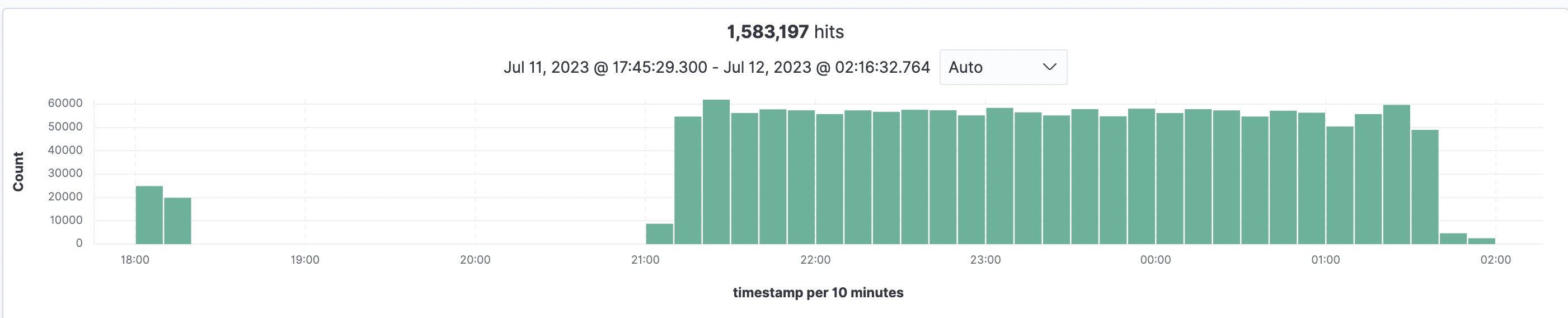
Figuur 13: Overzicht van OpenSearch-indexering
Voor de verwerking is de tcdk.SFExecutionsStartThrottle was ingesteld op een executions_concurrency_threshold=550, wat betekent dat de gelijktijdige documentverwerkingsworkflows zijn beperkt tot 550 en overtollige verzoeken in de wachtrij worden geplaatst bij een Amazon SQS Fist-In-First-Out (FIFO)-wachtrij, die vervolgens wordt leeggemaakt wanneer de huidige workflows zijn voltooid. De drempel van 550 is gebaseerd op het Textract Service-quotum van 600 in de regio us-east-1. Daarom zijn de wachtrijdiepte en de leeftijd van het oudste bericht statistieken die de moeite waard zijn om te monitoren.
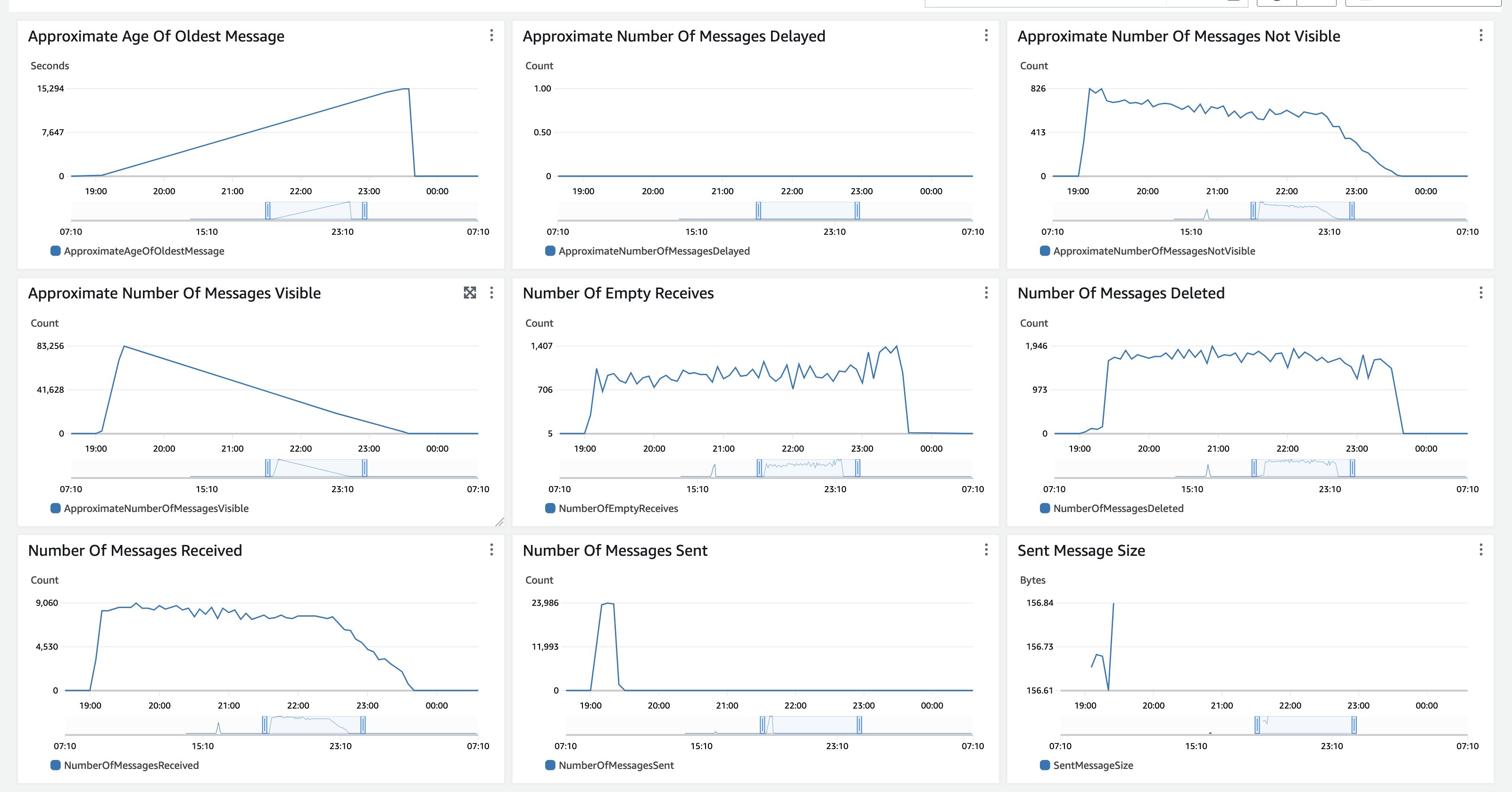
Figuur 14: Amazon SQS-monitoring
In deze test werden alle documenten in één keer naar Amazon S3 geüpload, daarom werden de Geschat aantal zichtbare berichten kent een steile stijging en vervolgens een langzame daling omdat er geen nieuwe documenten worden opgenomen. De Geschatte leeftijd van het oudste bericht neemt toe totdat alle berichten zijn verwerkt. De Amazon SQS BerichtBewaarPeriode is ingesteld op 14 dagen. Voor zeer langdurige verwerking van achterstanden die de verwerking van meer dan 14 dagen kunnen duren, begint u met het verwerken van een kleinere subset van representatieve documenten en bewaakt u de duur van de uitvoering om te schatten hoeveel documenten u kunt doorgeven voordat u de 14 dagen overschrijdt. De Amazon SQS CloudWatch-statistieken zien er vergelijkbaar uit voor een gebruiksscenario waarbij een grote achterstand aan documenten wordt verwerkt, die in één keer wordt opgenomen en vervolgens volledig wordt verwerkt. Als uw gebruiksscenario een gestage stroom documenten is, zijn beide statistieken, de Geschat aantal zichtbare berichten en Geschatte leeftijd van het oudste bericht zal meer lineair zijn. U kunt de drempelparameter ook gebruiken om een constante belasting te combineren met achterstandverwerking en capaciteit toe te wijzen op basis van uw verwerkingsbehoeften.
Een andere maatstaf die u moet controleren, is de gezondheid van het OpenSearch-cluster, die u moet instellen volgens de Operationele best practices voor Amazon OpenSearch Service. De standaardimplementatie maakt gebruik van m6g.large.search-instanties.
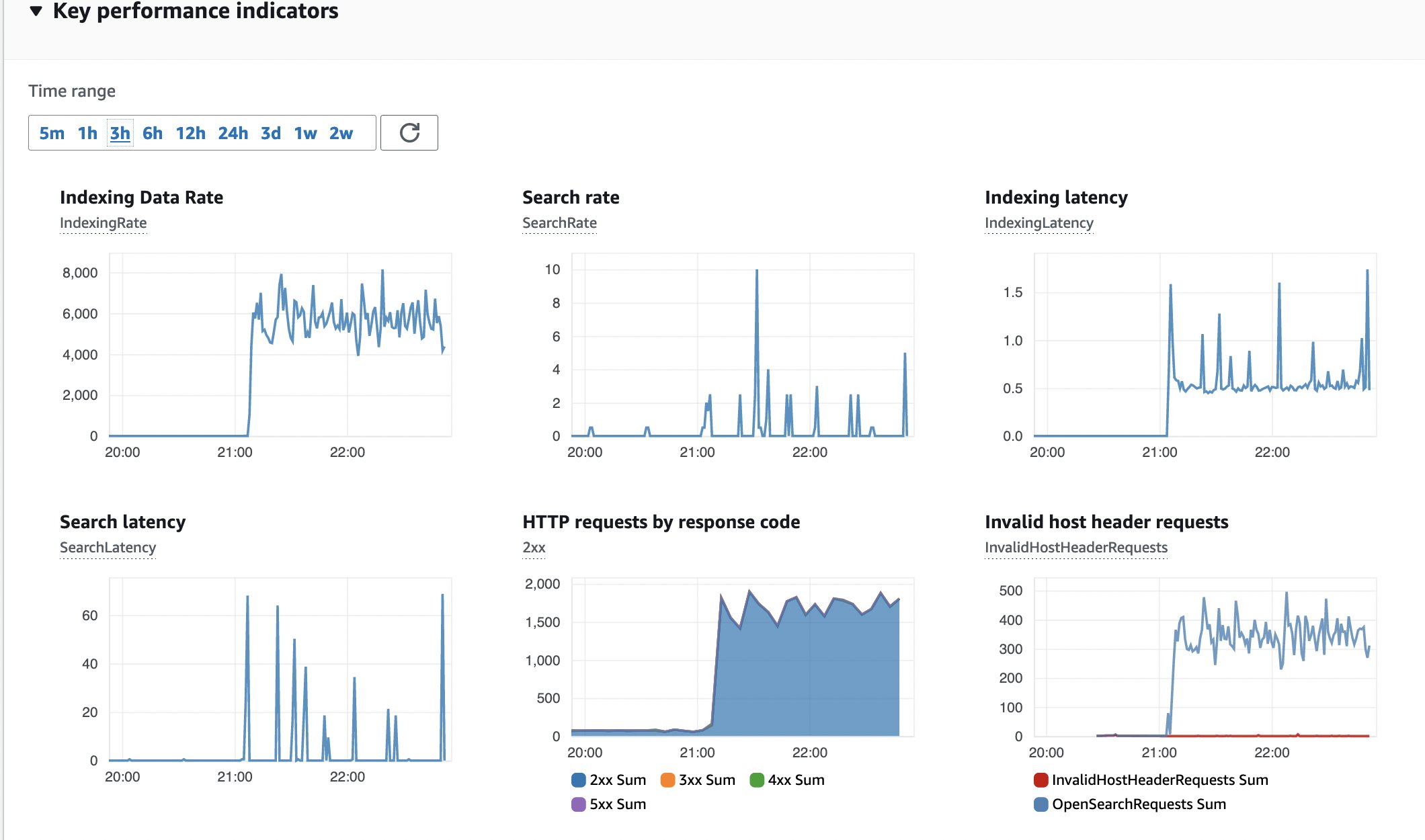
Figuur 15: OpenSearch-monitoring
Hier is een momentopname van de Key Performance Indicators (KPI) voor het OpenSearch-cluster. Geen fouten, constante datasnelheid en latentie bij het indexeren.
De workflowuitvoeringen van Stapfuncties tonen de verwerkingsstatus voor elk afzonderlijk document. Als je executies ziet in Mislukt staat en selecteer vervolgens de details. Een goede maatstaf om te monitoren is de AWS CloudWatch automatisch dashboard voor stapfuncties, die enkele van de Stap Functies CloudWatch-statistieken.
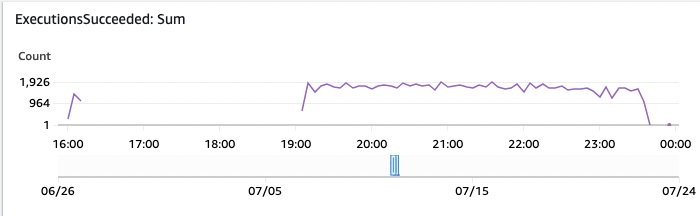
Afbeelding 16: Stapfuncties voor het monitoren van uitvoeringen zijn geslaagd
In deze AWS CloudWatch Dashboard-grafiek ziet u de succesvolle uitvoeringen van Step Functions in de loop van de tijd.
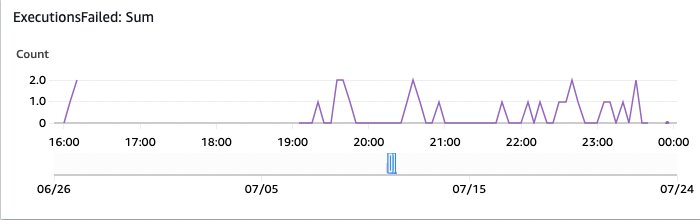
Afbeelding 17: Uitvoeringen van OpenSearch-monitoring zijn mislukt
En deze toont de mislukte executies. Deze zijn de moeite waard om te onderzoeken via het AWS Console Step Functions-overzicht.
De volgende schermafbeelding toont een voorbeeld van een mislukte uitvoering omdat het oorspronkelijke bestand de grootte 0 heeft, wat logisch is omdat het bestand geen inhoud heeft en niet kon worden verwerkt. Het is belangrijk om mislukte processen te filteren en fouten te visualiseren, zodat u terug kunt gaan naar het brondocument en de hoofdoorzaak kunt valideren.
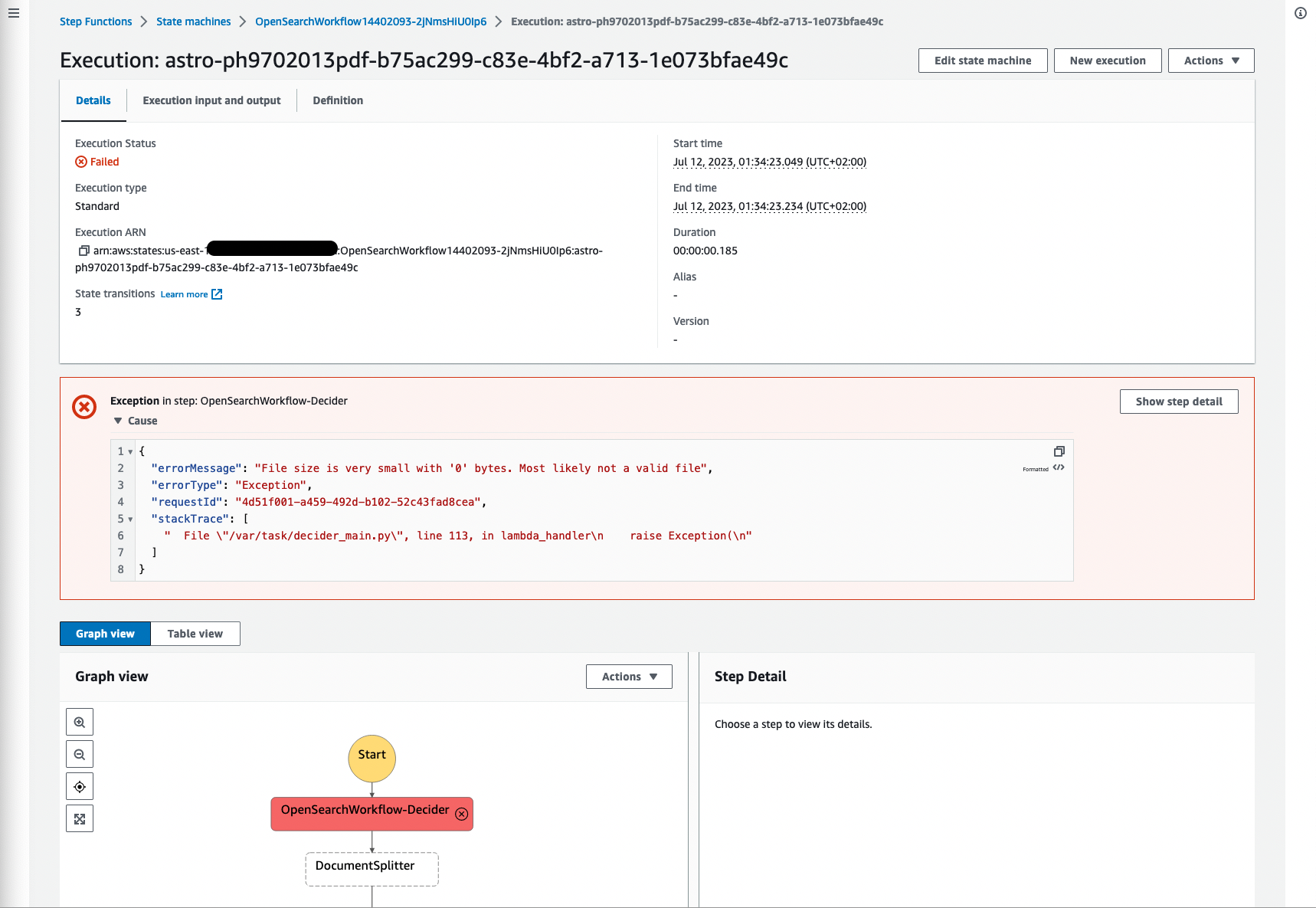
Afbeelding 18: Stapfuncties mislukte workflow
Andere fouten kunnen documenten zijn die niet van het mime-type zijn: application/pdf, image/png, image/jpeg of image/tiff, omdat andere documenttypen niet worden ondersteund door Amazon Textract.
Kosten
De totale kosten voor het verwerken van 1,583,278 pagina's werden verdeeld over de AWS-services die voor de implementatie werden gebruikt. De volgende lijst dient als geschatte cijfers, omdat uw werkelijke kosten en verwerkingsduur variëren afhankelijk van de grootte van de documenten, het aantal pagina's per document, de informatiedichtheid in de documenten en de AWS-regio. Amazon DynamoDB verbruikte $0.55, Amazon S3 $3.33, OpenSearch Service $14.71, Step Functions $17.92, AWS Lambda $28.95 en Amazon Textract $1,849.97. Houd er ook rekening mee dat het geïmplementeerde Amazon OpenSearch Service-cluster per uur wordt gefactureerd en hogere kosten met zich meebrengt als het gedurende een bepaalde periode wordt gebruikt.
wijzigingen
Hoogstwaarschijnlijk wilt u de implementatie aanpassen en aanpassen aan uw gebruiksscenario en documenten. De workshop Gebruik machine learning om documenten op grote schaal te automatiseren en verwerken biedt een goed overzicht van hoe u de daadwerkelijke workflows kunt manipuleren, de stroom kunt wijzigen en nieuwe componenten kunt toevoegen. Om aangepaste velden aan de OpenSearch-index toe te voegen, kijkt u naar de SetMetaData taak in de workflow met behulp van de set-manifest-metadata-opensearch AWS Lambda-functie om metadata aan de context toe te voegen, die als veld aan de OpenSearch-index wordt toegevoegd. Alle metadata-informatie wordt onderdeel van de index.
Schoonmaken
Verwijder de voorbeeldresources als u ze niet langer nodig heeft, om toekomstige kosten te voorkomen met behulp van de volgende opdracht:
in dezelfde omgeving als de cdk deploy commando. Houd er rekening mee dat hierdoor alles wordt verwijderd, inclusief het OpenSearch-cluster en alle documenten en de Amazon S3-bucket. Als je die informatie wilt behouden, maak dan een back-up van je Amazon S3-bucket en maak een indexmomentopname van uw OpenSearch-cluster. Als u veel bestanden heeft verwerkt, moet u mogelijk eerst de Amazon S3-bucket leegmaken met behulp van de AWS Management Console (dat wil zeggen, nadat u een back-up hebt gemaakt of deze met een andere bucket hebt gesynchroniseerd als u de informatie wilt behouden), omdat de opschoonfunctie kan een time-out optreden en vervolgens de AWS CloudFormation-stack vernietigen.
Conclusie
In dit bericht hebben we u laten zien hoe u een volledige oplossing kunt implementeren om een groot aantal documenten op te nemen in een OpenSearch-index, die klaar zijn om te worden gebruikt voor zoekgebruik. De afzonderlijke componenten van de implementatie werden besproken, evenals schaaloverwegingen, kosten en aanpassingsopties. Alle code is toegankelijk als OpenSource op GitHub als IDP CDK-monsters en als IDP CDK-constructen om uw eigen oplossingen vanaf nul te bouwen. Als volgende stap kunt u beginnen met het aanpassen van de workflow, het toevoegen van informatie aan de documenten in de zoekindex en het verkennen van de IDP-workshop. Geef hieronder commentaar op uw ervaringen en ideeën om de huidige oplossing uit te breiden.
Over de auteur
 Martin Schade is een Senior ML Product SA met het Amazon Textract-team. Hij heeft meer dan 20 jaar ervaring met internetgerelateerde technologieën, engineering en architectuuroplossingen. Hij kwam in 2014 bij AWS, waar hij eerst enkele van de grootste AWS-klanten begeleidde bij het meest efficiënte en schaalbare gebruik van AWS-services, en zich later toelegde op AI/ML met een focus op computervisie. Momenteel is hij geobsedeerd door het extraheren van informatie uit documenten.
Martin Schade is een Senior ML Product SA met het Amazon Textract-team. Hij heeft meer dan 20 jaar ervaring met internetgerelateerde technologieën, engineering en architectuuroplossingen. Hij kwam in 2014 bij AWS, waar hij eerst enkele van de grootste AWS-klanten begeleidde bij het meest efficiënte en schaalbare gebruik van AWS-services, en zich later toelegde op AI/ML met een focus op computervisie. Momenteel is hij geobsedeerd door het extraheren van informatie uit documenten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- ChartPrime. Verhoog uw handelsspel met ChartPrime. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/implement-smart-document-search-index-with-amazon-textract-and-amazon-opensearch/

