Veriff is een platformpartner voor identiteitsverificatie voor innovatieve, groeigedreven organisaties, waaronder pioniers op het gebied van financiële dienstverlening, FinTech, crypto, gaming, mobiliteit en online marktplaatsen. Ze bieden geavanceerde technologie die AI-aangedreven automatisering combineert met menselijke feedback, diepgaande inzichten en expertise.

Veriff levert een bewezen infrastructuur waarmee hun klanten kunnen vertrouwen op de identiteit en persoonlijke kenmerken van hun gebruikers op alle relevante momenten in hun klanttraject. Veriff wordt vertrouwd door klanten als Bolt, Deel, Monese, Starship, Super Awesome, Trustpilot en Wise.
Als AI-aangedreven oplossing moet Veriff tientallen machine learning (ML)-modellen op een kosteneffectieve manier creëren en uitvoeren. Deze modellen variëren van lichtgewicht boomgebaseerde modellen tot deep learning computer vision-modellen, die op GPU's moeten draaien om een lage latentie te bereiken en de gebruikerservaring te verbeteren. Veriff voegt momenteel ook meer producten toe aan zijn aanbod, gericht op een hypergepersonaliseerde oplossing voor zijn klanten. Het bedienen van verschillende modellen voor verschillende klanten draagt bij aan de behoefte aan een schaalbare oplossing voor het bedienen van modellen.
In dit bericht laten we u zien hoe Veriff hun modelimplementatieworkflow heeft gestandaardiseerd met behulp van Amazon Sage Maker, waardoor de kosten en ontwikkelingstijd worden verlaagd.
Infrastructuur- en ontwikkelingsuitdagingen
De backend-architectuur van Veriff is gebaseerd op een microservices-patroon, waarbij services draaien op verschillende Kubernetes-clusters die worden gehost op de AWS-infrastructuur. Deze aanpak werd aanvankelijk gebruikt voor alle bedrijfsservices, inclusief microservices waarop dure computer vision ML-modellen draaien.
Voor sommige van deze modellen was implementatie op GPU-instanties vereist. Zich bewust van de relatief hogere kosten van door GPU ondersteunde instantietypen, ontwikkelde Veriff een aangepaste oplossing op Kubernetes om de bronnen van een bepaalde GPU te delen tussen verschillende servicereplica's. Eén enkele GPU heeft doorgaans voldoende VRAM om meerdere computervisiemodellen van Veriff in het geheugen op te slaan.
Hoewel de oplossing de GPU-kosten verlichtte, bracht deze ook de beperking met zich mee dat datawetenschappers vooraf moesten aangeven hoeveel GPU-geheugen hun model nodig zou hebben. Bovendien werd DevOps belast met het handmatig inrichten van GPU-instanties als reactie op vraagpatronen. Dit veroorzaakte operationele overhead en overprovisioning van instances, wat resulteerde in een suboptimaal kostenprofiel.
Naast GPU-provisioning vereiste deze opzet ook dat datawetenschappers voor elk model een REST API-wrapper bouwden, wat nodig was om een generieke interface te bieden die andere bedrijfsservices konden gebruiken, en om de voor- en naverwerking van modelgegevens in te kapselen. Deze API's vereisten code van productiekwaliteit, wat het voor datawetenschappers een uitdaging maakte om modellen te productioniseren.
Het data science-platformteam van Veriff zocht naar alternatieve manieren voor deze aanpak. Het hoofddoel was om de datawetenschappers van het bedrijf te ondersteunen bij een betere overgang van onderzoek naar productie door eenvoudigere implementatiepijplijnen te bieden. Het secundaire doel was het verlagen van de operationele kosten voor het inrichten van GPU-instances.
Overzicht oplossingen
Veriff had een nieuwe oplossing nodig die twee problemen oploste:
- Maak het mogelijk om eenvoudig REST API-wrappers rond ML-modellen te bouwen
- Maak het mogelijk om de ingerichte GPU-instantiecapaciteit optimaal en, indien mogelijk, automatisch te beheren
Uiteindelijk kwam het team van het ML-platform tot de beslissing om het te gebruiken Sagemaker-eindpunten met meerdere modellen (MME's). Deze beslissing werd ingegeven door de steun van MME voor NVIDIA Triton Inference-server (een op ML gerichte server die het gemakkelijk maakt om modellen als REST API's in te pakken; Veriff experimenteerde ook al met Triton), evenals de mogelijkheid om de automatische schaling van GPU-instanties native te beheren via eenvoudig automatisch schalingsbeleid.
Bij Veriff zijn twee MME's gemaakt, één voor enscenering en één voor productie. Met deze aanpak kunnen ze teststappen uitvoeren in een testomgeving zonder de productiemodellen te beïnvloeden.
SageMaker MME's
SageMaker is een volledig beheerde service die ontwikkelaars en datawetenschappers de mogelijkheid biedt om snel ML-modellen te bouwen, trainen en implementeren. SageMaker MME's bieden een schaalbare en kosteneffectieve oplossing voor het inzetten van een groot aantal modellen voor real-time inferentie. MME's gebruiken een gedeelde servicecontainer en een vloot van bronnen die versnelde instanties zoals GPU's kunnen gebruiken om al uw modellen te hosten. Dit verlaagt de hostingkosten door het gebruik van endpoints te maximaliseren in vergelijking met het gebruik van single-model endpoints. Het vermindert ook de implementatieoverhead omdat SageMaker het laden en lossen van modellen in het geheugen beheert en ze schaalt op basis van de verkeerspatronen van het eindpunt. Bovendien profiteren alle real-time eindpunten van SageMaker van ingebouwde mogelijkheden om modellen te beheren en te bewaken, zoals het opnemen schaduw varianten, automatisch schalen, en native integratie met Amazon Cloud Watch (voor meer informatie, zie CloudWatch-statistieken voor implementaties van meerdere modellen van eindpunten).
Aangepaste Triton-ensemblemodellen
Er waren verschillende redenen waarom Veriff besloot Triton Inference Server te gebruiken, waarvan de belangrijkste:
- Hiermee kunnen datawetenschappers REST API's bouwen op basis van modellen door modelartefactbestanden in een standaard directory-indeling te rangschikken (geen code-oplossing)
- Het is compatibel met alle belangrijke AI-frameworks (PyTorch, Tensorflow, XGBoost en meer)
- Het biedt ML-specifieke low-level- en serveroptimalisaties zoals dynamisch batchen van verzoeken
Door Triton te gebruiken, kunnen datawetenschappers gemakkelijk modellen implementeren, omdat ze alleen geformatteerde modelrepository's hoeven te bouwen in plaats van code te schrijven om REST API's te bouwen (Triton ondersteunt ook Python-modellen als aangepaste inferentielogica vereist is). Dit verkort de implementatietijd van modellen en geeft datawetenschappers meer tijd om zich te concentreren op het bouwen van modellen in plaats van ze in te zetten.
Een ander belangrijk kenmerk van Triton is dat je ermee kunt bouwen modellenensembles, dit zijn groepen modellen die aan elkaar zijn gekoppeld. Deze ensembles kunnen worden uitgevoerd alsof ze één Triton-model zijn. Veriff maakt momenteel gebruik van deze functie om voor- en naverwerkingslogica te implementeren bij elk ML-model met behulp van Python-modellen (zoals eerder vermeld), zodat er geen mismatches zijn in de invoergegevens of modeluitvoer wanneer modellen in productie worden gebruikt.
Hieronder ziet u hoe een typische Triton-modelopslagplaats er voor deze werklast uitziet:
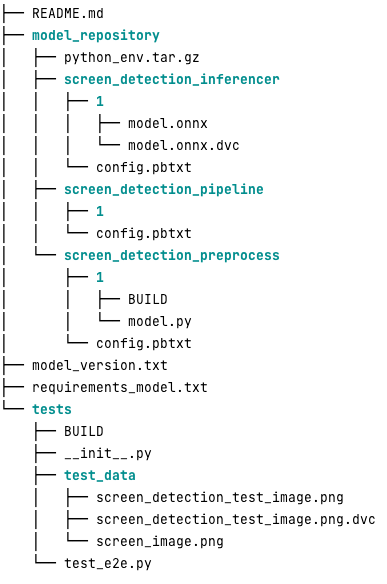
De model.py bestand bevat voorverwerkings- en naverwerkingscode. De getrainde modelgewichten bevinden zich in de screen_detection_inferencer directory, onder modelversie 1 (het model heeft in dit voorbeeld de ONNX-indeling, maar kan ook de TensorFlow-, PyTorch-indeling of andere zijn). De definitie van het ensemblemodel staat in de screen_detection_pipeline map, waar invoer en uitvoer tussen stappen worden toegewezen in een configuratiebestand.
Extra afhankelijkheden die nodig zijn om de Python-modellen uit te voeren, worden gedetailleerd beschreven in a requirements.txt bestand, en moeten conda-verpakt zijn om een Conda-omgeving te bouwen (python_env.tar.gz). Voor meer informatie, zie: Beheer van Python Runtime en bibliotheken. Ook moeten configuratiebestanden voor Python-stappen verwijzen naar python_env.tar.gz met de EXECUTION_ENV_PATH Richtlijn.
De modelmap moet vervolgens met TAR worden gecomprimeerd en hernoemd met behulp van model_version.txt. Tenslotte het resultaat <model_name>_<model_version>.tar.gz bestand wordt gekopieerd naar het Amazon eenvoudige opslagservice (Amazon S3) bucket aangesloten op de MME, waardoor SageMaker het model kan detecteren en bedienen.
Modelversiebeheer en continue implementatie
Zoals uit de vorige paragraaf duidelijk is geworden, is het bouwen van een Triton-modelrepository eenvoudig. Het uitvoeren van alle noodzakelijke stappen om het te implementeren is echter vervelend en foutgevoelig als u het handmatig uitvoert. Om dit te ondervangen heeft Veriff een monorepo gebouwd met alle modellen die moeten worden geïmplementeerd in MME's, waar datawetenschappers samenwerken in een Gitflow-achtige aanpak. Deze monorepo heeft de volgende kenmerken:
- Het wordt beheerd met behulp van Broeken.
- Codekwaliteitstools zoals Black en MyPy worden toegepast met behulp van Pants.
- Voor elk model zijn eenheidstests gedefinieerd, die controleren of de modeluitvoer de verwachte uitvoer is voor een bepaalde modelinvoer.
- Modelgewichten worden opgeslagen naast modelopslagplaatsen. Deze gewichten kunnen grote binaire bestanden zijn, dus DVC wordt gebruikt om ze op versiebeheer met Git te synchroniseren.
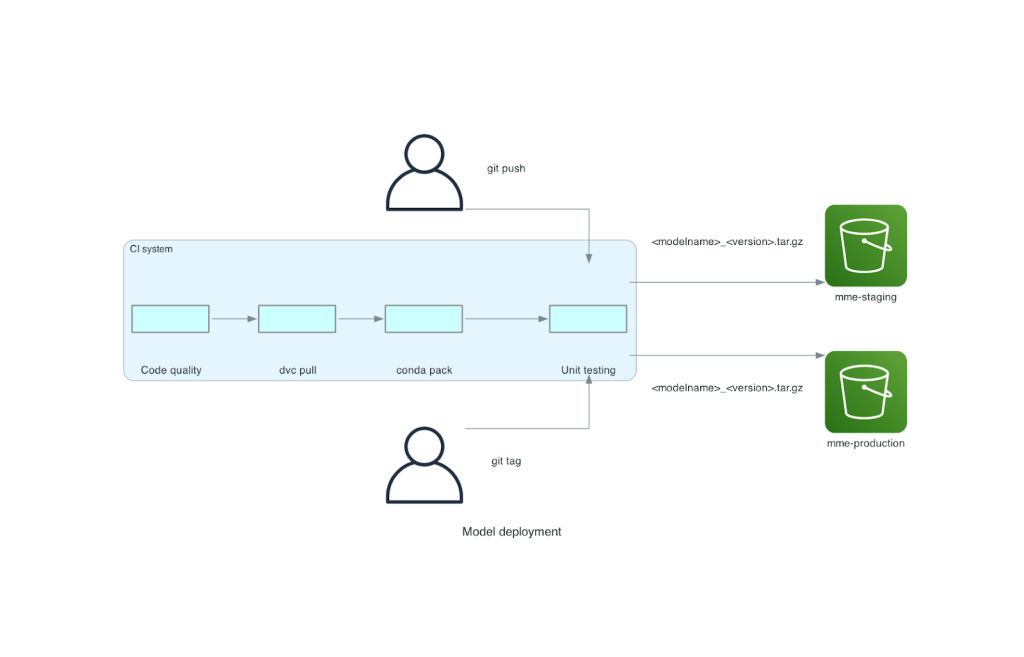
Deze monorepo is geïntegreerd met een continue integratietool (CI). Voor elke nieuwe push naar de repository of nieuw model worden de volgende stappen uitgevoerd:
- Doorloop de codekwaliteitscontrole.
- Download de modelgewichten.
- Bouw de Conda-omgeving.
- Start een Triton-server met behulp van de Conda-omgeving en gebruik deze om verzoeken te verwerken die zijn gedefinieerd in unit-tests.
- Bouw het uiteindelijke model TAR-bestand (
<model_name>_<model_version>.tar.gz).
Deze stappen zorgen ervoor dat modellen de kwaliteit hebben die nodig is voor implementatie, dus voor elke push naar een repo-vertakking wordt het resulterende TAR-bestand gekopieerd (in een andere CI-stap) naar de staging S3-bucket. Wanneer er pushes worden uitgevoerd in de hoofdvertakking, wordt het modelbestand gekopieerd naar de productie-S3-bucket. Het volgende diagram toont dit CI/CD-systeem.
Kosten- en implementatiesnelheidvoordelen
Door MME's te gebruiken, kan Veriff een monorepo-aanpak gebruiken om modellen in productie te nemen. Samenvattend bestaat de nieuwe modelimplementatieworkflow van Veriff uit de volgende stappen:
- Maak een vertakking in de monorepo met het nieuwe model of de nieuwe modelversie.
- Unit-tests definiëren en uitvoeren in een ontwikkelmachine.
- Push de vertakking wanneer het model gereed is om te worden getest in de testomgeving.
- Voeg de vertakking samen met main wanneer het model klaar is om in productie te worden gebruikt.
Met deze nieuwe oplossing is het implementeren van een model bij Veriff een eenvoudig onderdeel van het ontwikkelingsproces. De ontwikkeltijd voor nieuwe modellen is teruggebracht van 10 dagen naar gemiddeld 2 dagen.
De beheerde infrastructuurvoorziening en automatische schalingsfuncties van SageMaker brachten Veriff extra voordelen. Ze gebruikten de InvocationsPerInstance CloudWatch-statistiek kan worden geschaald op basis van verkeerspatronen, waardoor kosten worden bespaard zonder dat dit ten koste gaat van de betrouwbaarheid. Om de drempelwaarde voor de metriek te definiëren, voerden ze belastingtests uit op het staging-eindpunt om de beste afweging tussen latentie en kosten te vinden.
Na het implementeren van zeven productiemodellen op MME's en het analyseren van de uitgaven, rapporteerde Veriff een kostenbesparing van 75% in het GPU-model in vergelijking met de oorspronkelijke, op Kubernetes gebaseerde oplossing. Ook de operationele kosten werden verlaagd, omdat de last van het handmatig inrichten van instances werd weggenomen van de DevOps-engineers van het bedrijf.
Conclusie
In dit bericht hebben we besproken waarom Veriff Sagemaker MME's verkoos boven zelfbeheerde modelimplementatie op Kubernetes. SageMaker neemt het ongedifferentieerde zware werk op zich, waardoor Veriff de ontwikkelingstijd van modellen kan verkorten, de technische efficiëntie kan verhogen en de kosten voor realtime gevolgtrekkingen dramatisch kan verlagen, terwijl de prestaties behouden blijven die nodig zijn voor hun bedrijfskritische activiteiten. Ten slotte hebben we de eenvoudige maar effectieve modelimplementatie CI/CD-pijplijn en het modelversiemechanisme van Veriff gedemonstreerd, die kunnen worden gebruikt als referentie-implementatie voor het combineren van best practices voor softwareontwikkeling en SageMaker MME's. U kunt codevoorbeelden vinden over het hosten van meerdere modellen met behulp van SageMaker MME's op GitHub.
Over de auteurs
 Ricard Borras is Senior Machine Learning bij Veriff, waar hij leiding geeft aan de MLOps-inspanningen in het bedrijf. Hij helpt datawetenschappers om snellere en betere AI/ML-producten te bouwen door bij het bedrijf een Data Science Platform te bouwen en verschillende open source-oplossingen te combineren met AWS-services.
Ricard Borras is Senior Machine Learning bij Veriff, waar hij leiding geeft aan de MLOps-inspanningen in het bedrijf. Hij helpt datawetenschappers om snellere en betere AI/ML-producten te bouwen door bij het bedrijf een Data Science Platform te bouwen en verschillende open source-oplossingen te combineren met AWS-services.
 Joao Moura is een AI/ML Specialist Solutions Architect bij AWS, gevestigd in Spanje. Hij helpt klanten met diepgaande leermodellen, grootschalige training en optimalisatie van gevolgtrekkingen, en bredere bouw van grootschalige ML-platforms op AWS.
Joao Moura is een AI/ML Specialist Solutions Architect bij AWS, gevestigd in Spanje. Hij helpt klanten met diepgaande leermodellen, grootschalige training en optimalisatie van gevolgtrekkingen, en bredere bouw van grootschalige ML-platforms op AWS.
 Miguel Ferreira werkt als Sr. Solutions Architect bij AWS, gevestigd in Helsinki, Finland. AI/ML is al een levenslange interesse en hij heeft meerdere klanten geholpen Amazon SageMaker te integreren in hun ML-workflows.
Miguel Ferreira werkt als Sr. Solutions Architect bij AWS, gevestigd in Helsinki, Finland. AI/ML is al een levenslange interesse en hij heeft meerdere klanten geholpen Amazon SageMaker te integreren in hun ML-workflows.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/how-veriff-decreased-deployment-time-by-80-using-amazon-sagemaker-multi-model-endpoints/

