
Afbeelding door redacteur
Grote taalmodellen (LLM's) zoals OpenAI's GPT-3, Google's BERT en Meta's LLaMA brengen een revolutie teweeg in verschillende sectoren met hun vermogen om een breed scala aan tekst te genereren - van marketingteksten en datawetenschapsscripts tot poëzie.
Hoewel de intuïtieve interface van ChatGPT tegenwoordig op de apparaten van de meeste mensen aanwezig is, is er nog steeds een enorm landschap van onbenut potentieel voor het gebruik van LLM's in diverse software-integraties.
Het hoofdprobleem?
De meeste toepassingen vereisen vloeiendere en native communicatie met LLM's.
En dit is precies waar LangChain in actie komt!
Als u geïnteresseerd bent in generatieve AI en LLM's, is deze tutorial op maat voor u gemaakt.
Dus laten we beginnen!
Voor het geval je in een grot hebt gewoond en de laatste tijd geen nieuws hebt gekregen, zal ik kort Large Language Models of LLM's uitleggen.
Een LLM is een geavanceerd systeem voor kunstmatige intelligentie dat is gebouwd om mensachtig tekstbegrip en -generatie na te bootsen. Door te trainen op enorme datasets kunnen deze modellen ingewikkelde patronen onderscheiden, taalkundige subtiliteiten begrijpen en samenhangende resultaten produceren.
Als u zich afvraagt hoe u met deze AI-aangedreven modellen kunt omgaan, zijn er twee manieren om dit te doen:
- De meest voorkomende en directe manier is praten of chatten met het model. Het omvat het maken van een prompt, het verzenden ervan naar het AI-aangedreven model en het ontvangen van een op tekst gebaseerde uitvoer als antwoord.
- Een andere methode is het omzetten van tekst in numerieke arrays. Dit proces omvat het samenstellen van een prompt voor de AI en het ontvangen van een numerieke array in ruil daarvoor. Wat algemeen bekend staat als een ‘inbedding’. Het heeft een recente golf van vectordatabases en semantisch zoeken meegemaakt.
En het zijn precies deze twee hoofdproblemen die LangChain probeert aan te pakken. Als u geïnteresseerd bent in de belangrijkste problemen bij de interactie met LLM's, kunt u dit artikel lezen hier.
LangChain is een open-sourceframework gebouwd rond LLM's. Het brengt een arsenaal aan tools, componenten en interfaces naar voren die de architectuur van LLM-aangedreven applicaties stroomlijnen.
Met LangChain wordt het werken met taalmodellen, het onderling koppelen van verschillende componenten en het integreren van assets zoals API's en databases een fluitje van een cent. Dit intuïtieve raamwerk vereenvoudigt het ontwikkelingstraject van LLM-applicaties aanzienlijk.
Het kernidee van Long Chain is dat we verschillende componenten of modules, ook wel ketens genoemd, met elkaar kunnen verbinden om meer geavanceerde LLM-aangedreven oplossingen te creëren.
Hier zijn enkele opvallende kenmerken van LangChain:
- Aanpasbare promptsjablonen om onze interacties te standaardiseren.
- Kettingschakelcomponenten op maat gemaakt voor geavanceerde gebruiksscenario's.
- Naadloze integratie met toonaangevende taalmodellen, waaronder de GPT's van OpenAI en die op HuggingFace Hub.
- Modulaire componenten voor een mix-and-match-aanpak om elk specifiek probleem of elke taak te beoordelen.

Afbeelding door auteur
LangChain onderscheidt zich door de focus op aanpassingsvermogen en modulair ontwerp.
Het belangrijkste idee achter LangChain is het opsplitsen van de natuurlijke taalverwerkingsvolgorde in afzonderlijke delen, waardoor ontwikkelaars workflows kunnen aanpassen op basis van hun vereisten.
Deze veelzijdigheid positioneert LangChain als een eerste keuze voor het bouwen van AI-oplossingen in verschillende situaties en industrieën.
Enkele van de belangrijkste componenten zijn...
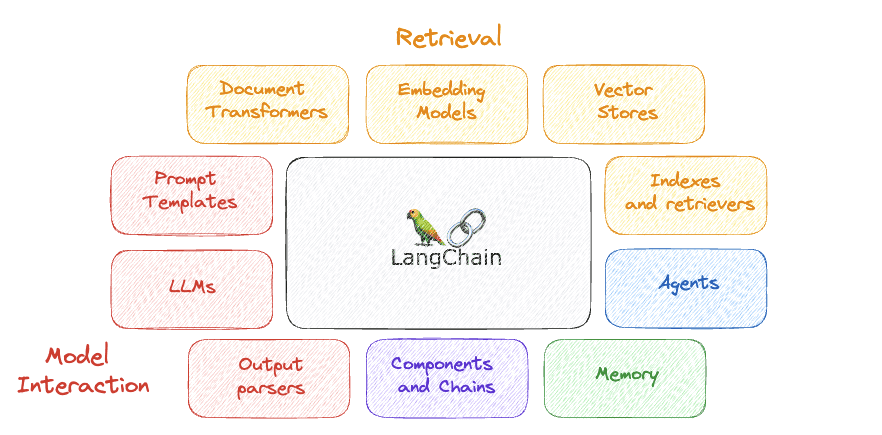
Afbeelding door auteur
1. LLM's
LLM's zijn fundamentele componenten die enorme hoeveelheden trainingsgegevens gebruiken om mensachtige tekst te begrijpen en te genereren. Ze vormen de kern van veel activiteiten binnen LangChain en bieden de noodzakelijke taalverwerkingsmogelijkheden voor het analyseren, interpreteren en reageren op tekstinvoer.
Gebruik: Het aandrijven van chatbots, het genereren van mensachtige tekst voor verschillende toepassingen, het helpen bij het ophalen van informatie en het uitvoeren van andere taalverwerking
2. Prompt-sjablonen
Aanwijzingen zijn van fundamenteel belang voor de interactie met LLM, en bij het werken aan specifieke taken is hun structuur meestal vergelijkbaar. Prompt-sjablonen, dit zijn vooraf ingestelde prompts die in meerdere ketens kunnen worden gebruikt, maken standaardisatie van 'prompts' mogelijk door specifieke waarden toe te voegen. Dit verbetert het aanpassingsvermogen en de aanpassing van elke LLM.
Gebruik: Het standaardiseren van het proces van interactie met LLM's.
3. Uitvoerparsers
Uitvoerparsers zijn componenten die de onbewerkte uitvoer van een voorgaande fase in de keten omzetten in een gestructureerd formaat. Deze gestructureerde data kunnen vervolgens in vervolgstappen effectiever worden gebruikt of als antwoord aan de eindgebruiker worden aangeleverd.
Gebruik: In een chatbot kan een uitvoerparser bijvoorbeeld het onbewerkte tekstantwoord uit een taalmodel halen, belangrijke stukjes informatie extraheren en deze in een gestructureerd antwoord formatteren.
4. Componenten en kettingen
In LangChain fungeert elke component als een module die verantwoordelijk is voor een bepaalde taak in de taalverwerkingsreeks. Deze componenten kunnen met elkaar worden verbonden ketens voor aangepaste werkstromen.
Gebruik: Het genereren van sentimentdetectie en responsgeneratorketens in een specifieke chatbot.
5. Geheugen
Geheugen in LangChain verwijst naar een component die een opslag- en ophaalmechanisme biedt voor informatie binnen een workflow. Dit onderdeel maakt de tijdelijke of permanente opslag mogelijk van gegevens die toegankelijk zijn en kunnen worden gemanipuleerd door andere componenten tijdens de interactie met de LLM.
Gebruik: Dit is handig in scenario's waarin gegevens in verschillende stadia van de verwerking moeten worden bewaard, bijvoorbeeld door de gespreksgeschiedenis op te slaan in een chatbot om contextbewuste antwoorden te bieden.
6. agenten
Agents zijn autonome componenten die acties kunnen ondernemen op basis van de gegevens die ze verwerken. Ze kunnen communiceren met andere componenten, externe systemen of gebruikers om specifieke taken uit te voeren binnen een LangChain-workflow.
Gebruik: Een agent kan bijvoorbeeld gebruikersinteracties afhandelen, inkomende verzoeken verwerken en de gegevensstroom door de keten coördineren om passende antwoorden te genereren.
7. Indexen en retrievers
Indexen en retrievers spelen een cruciale rol bij het efficiënt beheren en toegankelijk maken van gegevens. Indexen zijn datastructuren die informatie en metagegevens uit de trainingsgegevens van het model bevatten. Aan de andere kant zijn retrievers mechanismen die met deze indexen interageren om relevante gegevens op te halen op basis van gespecificeerde criteria en het model in staat te stellen beter te reageren door relevante context te bieden.
Gebruik: Ze spelen een belangrijke rol bij het snel ophalen van relevante gegevens of documenten uit een grote dataset, wat essentieel is voor taken als het ophalen van informatie of het beantwoorden van vragen.
8. Documenttransformatoren
In LangChain zijn Document Transformers gespecialiseerde componenten die zijn ontworpen om documenten te verwerken en te transformeren op een manier die ze geschikt maakt voor verdere analyse of verwerking. Deze transformaties kunnen taken omvatten zoals tekstnormalisatie, functie-extractie of de conversie van tekst naar een ander formaat.
Gebruik: Tekstgegevens voorbereiden voor daaropvolgende verwerkingsfasen, zoals analyse door machine learning-modellen of indexering voor efficiënt ophalen.
9. Modellen inbedden
Ze worden gebruikt om tekstgegevens om te zetten in numerieke vectoren in een hoogdimensionale ruimte. Deze modellen leggen semantische relaties tussen woorden en zinsdelen vast, waardoor een machinaal leesbare representatie mogelijk wordt. Ze vormen de basis voor verschillende downstream Natural Language Processing (NLP)-taken binnen het LangChain-ecosysteem.
Gebruik: Het faciliteren van semantische zoekopdrachten, vergelijkingen van overeenkomsten en andere machinale leertaken door een numerieke weergave van tekst te bieden.
10. Vectorwinkels
Type databasesysteem dat gespecialiseerd is in het opslaan en doorzoeken van informatie via inbedding, waarbij in essentie numerieke representaties van tekstachtige gegevens worden geanalyseerd. VectorStore dient als opslagfaciliteit voor deze inbedding.
Gebruik: Maakt efficiënt zoeken mogelijk op basis van semantische gelijkenis.
Installeer het met behulp van PIP
Het eerste dat we moeten doen is ervoor zorgen dat LangChain in onze omgeving is geïnstalleerd.
pip install langchain
Omgeving instellen
Het gebruik van LangChain betekent doorgaans integratie met onder meer diverse modelaanbieders, datastores en API's. En zoals u al weet, is het leveren van de relevante en correcte API-sleutels, net als bij elke integratie, cruciaal voor de werking van LangChain.
Stel je voor dat we onze OpenAI API willen gebruiken. We kunnen dit eenvoudig op twee manieren bereiken:
- Sleutel instellen als omgevingsvariabele
OPENAI_API_KEY="..."
or
import os
os.environ['OPENAI_API_KEY'] = “...”
Als u ervoor kiest om geen omgevingsvariabele in te stellen, heeft u de mogelijkheid om de sleutel rechtstreeks via de openai_api_key genoemde parameter op te geven bij het initiëren van de OpenAI LLM-klasse:
- Stel de sleutel direct in de betreffende klasse in.
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")Schakelen tussen LLM's wordt eenvoudig
LangChain biedt een LLM-klasse waarmee we kunnen communiceren met verschillende aanbieders van taalmodellen, zoals OpenAI en Hugging Face.
Het is vrij eenvoudig om met elke LLM aan de slag te gaan, omdat de meest elementaire en gemakkelijkst te implementeren functionaliteit van elke LLM alleen maar het genereren van tekst is.
Het is echter niet zo eenvoudig om dezelfde vraag aan verschillende LLM's tegelijk te stellen.
Dit is waar LangChain van start gaat...
Terugkomend op de eenvoudigste functionaliteit van elke LLM, kunnen we eenvoudig een applicatie bouwen met LangChain die een stringprompt krijgt en de uitvoer van onze aangewezen LLM retourneert.
Code door auteur
We kunnen eenvoudigweg dezelfde prompt gebruiken en binnen enkele regels code het antwoord van twee verschillende modellen krijgen!
Code door auteur
Indrukwekkend... toch?
Structuur aanbrengen in onze prompts met promptsjablonen
Een veelvoorkomend probleem met taalmodellen (LLM's) is hun onvermogen om complexe applicaties te escaleren. LangChain pakt dit aan door een oplossing aan te bieden om het proces van het maken van aanwijzingen te stroomlijnen, wat vaak ingewikkelder is dan alleen het definiëren van een taak, omdat het de persoonlijkheid van de AI moet schetsen en feitelijke nauwkeurigheid moet garanderen. Een aanzienlijk deel hiervan betreft repetitieve standaardtekst. LangChain verhelpt dit door promptsjablonen aan te bieden, die automatisch standaardtekst in nieuwe prompts opnemen, waardoor het maken van prompts wordt vereenvoudigd en de consistentie tussen verschillende taken wordt gewaarborgd.
Code door auteur
Gestructureerde antwoorden krijgen met uitvoerparers
Bij op chat gebaseerde interacties bestaat de uitvoer van het model uitsluitend uit tekst. Toch verdient het hebben van een gestructureerde uitvoer binnen softwaretoepassingen de voorkeur, omdat dit verdere programmeeracties mogelijk maakt. Bij het genereren van een dataset is het bijvoorbeeld gewenst om het antwoord in een specifiek formaat zoals CSV of JSON te ontvangen. Ervan uitgaande dat er een prompt kan worden gemaakt om een consistent en passend geformatteerd antwoord van de AI te ontlokken, is er behoefte aan tools om deze uitvoer te beheren. LangChain komt aan deze eis tegemoet door output-parsertools aan te bieden waarmee de gestructureerde output effectief kan worden verwerkt en gebruikt.
Code door auteur
Je kunt de hele code op mijn GitHub.
Nog niet zo lang geleden lieten de geavanceerde mogelijkheden van ChatGPT ons versteld staan. Toch verandert de technologische omgeving voortdurend en nu zijn tools als LangChain binnen handbereik, waardoor we in slechts een paar uur uitstekende prototypes van onze personal computers kunnen maken.
LangChain, een gratis beschikbaar Python-platform, biedt gebruikers de mogelijkheid om applicaties te ontwikkelen die zijn verankerd door LLM's (Language Model Models). Dit platform levert een flexibele interface voor een verscheidenheid aan fundamentele modellen, stroomlijnt de afhandeling van prompts en fungeert als knooppunt voor elementen zoals promptsjablonen, meer LLM's, externe informatie en andere bronnen via agenten, vanaf de huidige documentatie.
Stel je chatbots, digitale assistenten, vertaalhulpmiddelen en hulpprogramma's voor sentimentanalyse voor; al deze LLM-compatibele applicaties komen tot leven met LangChain. Ontwikkelaars gebruiken dit platform om op maat gemaakte taalmodeloplossingen te maken die aan specifieke vereisten voldoen.
Naarmate de horizon van natuurlijke taalverwerking groter wordt en de adoptie ervan zich verdiept, lijkt het domein van de toepassingen ervan grenzeloos.
Joseph Ferrer is een analytisch ingenieur uit Barcelona. Hij is afgestudeerd in natuurkunde en werkt momenteel op het gebied van datawetenschap toegepast op menselijke mobiliteit. Hij is een parttime contentmaker die zich richt op datawetenschap en -technologie. U kunt contact met hem opnemen via LinkedIn, Twitter or Medium.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/how-to-make-large-language-models-play-nice-with-your-software-using-langchain?utm_source=rss&utm_medium=rss&utm_campaign=how-to-make-large-language-models-play-nice-with-your-software-using-langchain

