Dit is een gastpost van Nan Zhu, Tech Lead Manager, SafeGraph, en Dave Thibault, Sr. Solutions Architect – AWS
SafeGraph is een geospatiaal databedrijf dat meer dan 41 miljoen wereldwijde interessante punten (POI's) beheert met gedetailleerde kenmerken, zoals merkverbondenheid, geavanceerde categorietagging en open uren, evenals hoe mensen omgaan met die plaatsen. We gebruiken Apache Spark als onze belangrijkste gegevensverwerkingsengine en hebben elke dag meer dan 1,000 Spark-applicaties die enorme hoeveelheden gegevens verwerken. Deze Spark-applicaties implementeren onze bedrijfslogica, variërend van gegevenstransformatie, machine learning (ML) modelinferentie tot operationele taken.
SafeGraph bevond zich met een niet-optimale Spark-omgeving bij hun gevestigde Spark-leverancier. Hun kosten stegen. Hun taken zouden regelmatig opnieuw worden geprobeerd door Spot Instance-beëindiging. Ontwikkelaars besteedden te veel tijd aan het oplossen van problemen en het wijzigen van taakconfiguraties en niet genoeg tijd aan het verzenden van bedrijfswaardecode. SafeGraph was nodig om de kosten te beheersen, de iteratiesnelheid van ontwikkelaars te verbeteren en de betrouwbaarheid van taken te verbeteren. Uiteindelijk koos SafeGraph Amazon EMR op Amazon EKS om aan hun behoeften te voldoen en realiseerden 50% besparingen ten opzichte van hun vorige Spark-leverancier van beheerde services.
Als het bouwen van Spark-toepassingen voor ons product is als het kappen van een boom, is het hebben van een scherpe zaag cruciaal. Het Spark-platform is de zaag. De volgende afbeelding belicht de engineeringworkflow bij het werken met Spark, en het Spark-platform moet elke actie in de workflow ondersteunen en optimaliseren. De technici beginnen meestal met het schrijven en bouwen van de Spark-toepassingscode, dienen de toepassing vervolgens in bij de computerinfrastructuur en sluiten ten slotte de cirkel door de Spark-toepassingen te debuggen. Bovendien moeten platform- en infrastructuurteams de drie stappen in de engineeringworkflow continu uitvoeren en optimaliseren.
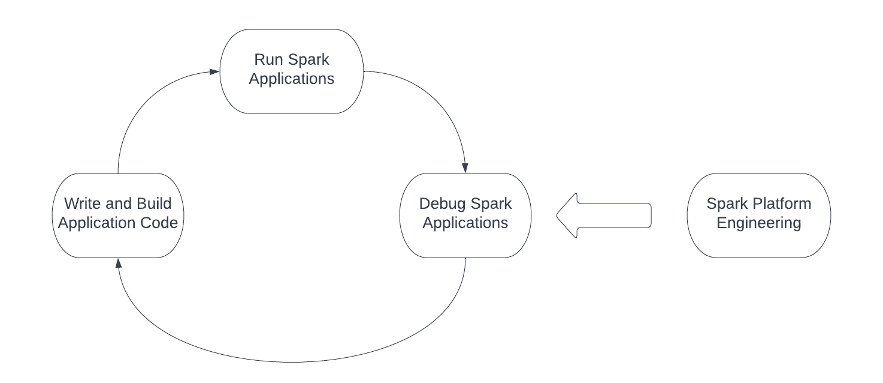
Er zijn verschillende uitdagingen bij elke actie bij het bouwen van een Spark-platform:
- Betrouwbaar afhankelijkheidsbeheer – Een gecompliceerde Spark-applicatie brengt meestal veel afhankelijkheden met zich mee. Om een Spark-toepassing uit te voeren, moeten we alle afhankelijkheden identificeren, eventuele conflicten oplossen, afhankelijke bibliotheken betrouwbaar inpakken en naar het Spark-cluster verzenden. Afhankelijkheidsbeheer is een van de grootste uitdagingen voor ingenieurs, vooral wanneer ze met PySpark-applicaties werken.
- Betrouwbare computerinfrastructuur – De betrouwbaarheid van de computerinfrastructuur die Spark-applicaties host, vormt de basis van het hele Spark-platform. Onstabiele resourcevoorziening zal niet alleen een negatieve invloed hebben op de technische efficiëntie, maar zal ook de infrastructuurkosten verhogen als gevolg van herhalingen van de Spark-applicaties.
- Handige hulpprogramma's voor foutopsporing voor Spark-toepassingen - De tooling voor foutopsporing speelt een sleutelrol voor ingenieurs om Spark-applicaties snel te herhalen. Performante toegang tot de Spark History Server (SHS) is een must voor iteratiesnelheid van ontwikkelaars. Omgekeerd vertragen slechte SHS-prestaties ontwikkelaars en verhogen ze de kosten van verkochte goederen voor softwarebedrijven.
- Beheerbare Spark-infrastructuur - Een succesvolle Spark-platformengineering omvat meerdere aspecten, zoals versiebeheer van Spark-distributie, SKU-beheer en -optimalisatie van computerresources, en meer. Het hangt er grotendeels van af of de Spark-serviceleveranciers de juiste basis bieden voor platformteams om te gebruiken. De verkeerde abstractie van distributieversie en computerresources kan bijvoorbeeld de ROI van platformengineering aanzienlijk verminderen.
Bij SafeGraph hebben we alle bovengenoemde uitdagingen ervaren. Om ze op te lossen, verkenden we de markt en ontdekten dat het bouwen van een nieuw Spark-platform bovenop EMR op EKS de oplossing was voor onze wegversperringen. In dit bericht delen we onze reis van het bouwen van ons nieuwste Spark-platform en hoe EMR op EKS dient als een robuuste en efficiënte basis ervoor.
Betrouwbaar Python-afhankelijkheidsbeheer
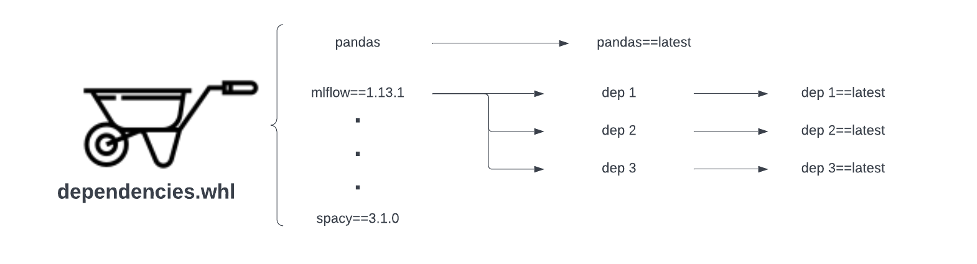
Een van de grootste uitdagingen voor onze gebruikers bij het schrijven en bouwen van Spark-toepassingscode is de strijd om afhankelijkheden betrouwbaar te beheren, vooral voor PySpark-toepassingen. De meeste van onze ML-gerelateerde Spark-applicaties zijn gebouwd met PySpark. Bij onze vorige Spark-serviceleverancier was de enige ondersteunde manier om Python-afhankelijkheden te beheren via een wheel-bestand. Ondanks zijn populariteit is op wielen gebaseerd afhankelijkheidsbeheer kwetsbaar. De volgende afbeelding toont twee soorten betrouwbaarheidsproblemen waarmee afhankelijkheidsbeheer op basis van wielen wordt geconfronteerd:
- Losgemaakte directe afhankelijkheid – Als het .whl-bestand de versie van een bepaalde directe afhankelijkheid, Panda's in dit voorbeeld, niet aanwijst, haalt het altijd de nieuwste versie van stroomopwaarts, die mogelijk een ingrijpende wijziging bevat en onze Spark-applicaties verwijdert.
- Losgemaakte transitieve afhankelijkheid – Het tweede type betrouwbaarheidsprobleem ligt meer buiten onze controle. Hoewel we de directe afhankelijkheidsversie hebben vastgezet bij het bouwen van het .whl-bestand, kan de directe afhankelijkheid zelf de transitieve afhankelijkhedenversies missen (MLFlow in dit voorbeeld). De directe afhankelijkheid haalt in dit geval altijd de nieuwste versies van deze transitieve afhankelijkheden op die mogelijk belangrijke wijzigingen bevatten en onze pijplijnen kunnen uitschakelen.
Het andere probleem dat we tegenkwamen, was de onnodige installatie van alle Python-pakketten waarnaar wordt verwezen door de wheel-bestanden voor elke Spark-applicatie-initialisatie. Met onze vorige configuratie moesten we het installatiescript uitvoeren om wielbestanden voor elke Spark-toepassing te installeren bij het starten, zelfs als er geen afhankelijkheidsverandering is. Deze installatie verlengt de starttijd van de Spark-toepassing van 3 tot 4 minuten tot ten minste 7 tot 8 minuten. De vertraging is frustrerend, vooral wanneer onze technici actief wijzigingen herhalen.
Overstappen naar EMR op EKS stelt ons in staat om te gebruiken pEX (Python EXEcutable) om Python-afhankelijkheden te beheren. Een .pex-bestand verpakt alle afhankelijkheden (inclusief directe en transitieve) van een PySpark-toepassing in een uitvoerbare Python-omgeving in de geest van virtueel omgevingen.
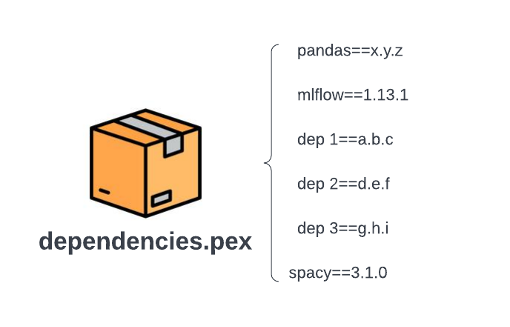
De volgende afbeelding toont de bestandsstructuur na het converteren van het eerder geïllustreerde wielbestand naar een .pex-bestand. Vergeleken met de op wielen gebaseerde workflow, hebben we geen transitieve afhankelijkheidstrekking of automatisch ophalen van de laatste versie meer. Alle versies van afhankelijkheden zijn vastgelegd als xyz, abc, enzovoort bij het bouwen van het .pex-bestand. Gegeven een .pex-bestand, zijn alle afhankelijkheden opgelost, zodat we geen last meer hebben van traagheid of kwetsbaarheid in een op wielen gebaseerd afhankelijkheidsbeheer. De kosten voor het bouwen van een .pex-bestand zijn ook eenmalige kosten.
Betrouwbare en efficiënte resourcevoorziening
Resourceprovisioning is het proces voor het Spark-platform om computerresources voor Spark-applicaties te krijgen en vormt de basis voor het hele Spark-platform. Bij het bouwen van een Spark-platform in de cloud maakt het gebruik van Spot Instances voor kostenoptimalisatie het inrichten van resources nog uitdagender. Spot-instances zijn reservecomputercapaciteit die voor u beschikbaar is met een besparing tot wel 90% in vergelijking met on-demandprijzen. Wanneer de vraag naar bepaalde instantietypen echter plotseling toeneemt, kan de beëindiging van een Spot-instantie gebeuren om prioriteit te geven aan het voldoen aan die eisen. Vanwege deze beëindigingen zagen we verschillende uitdagingen in onze eerdere versie van het Spark-platform:
- Onbetrouwbare Spark-applicaties – Toen de Spot Instance-beëindiging plaatsvond, werd de runtime van Spark-applicaties aanzienlijk verlengd vanwege de opnieuw geprobeerde rekenfasen.
- Gecompromitteerde ontwikkelaarservaring – De onstabiele levering van Spot Instances veroorzaakte frustratie bij ingenieurs en vertraagde onze ontwikkelingsiteraties vanwege de onvoorspelbare prestaties en het lage slagingspercentage van Spark-applicaties.
- Dure infrastructuurrekening – Onze factuur voor cloudinfrastructuur is aanzienlijk gestegen vanwege het opnieuw proberen van taken. We moesten duurder kopen Amazon Elastic Compute-cloud (Amazon EC2) instances met een hogere capaciteit en draaien in meerdere Availability Zones om problemen te verminderen, maar betaalden op hun beurt voor de hoge kosten van cross-Availability Zone-verkeer.
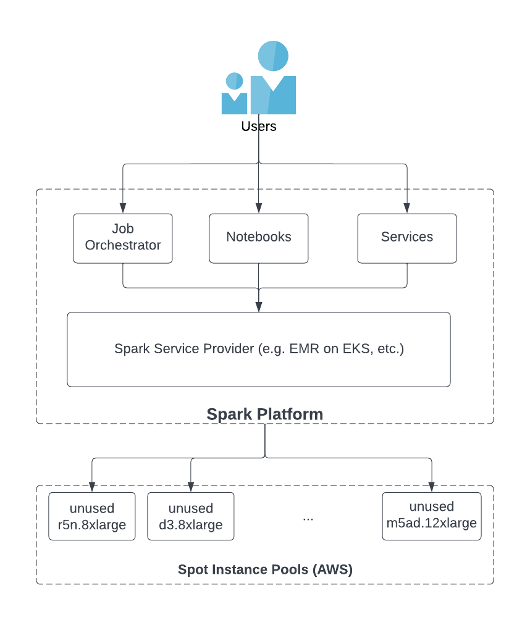
Spark Service Providers (SSP's) zoals EMR op EKS of andere softwareproducten van derden fungeren als intermediair tussen gebruikers en Spot Instance-pools en spelen een sleutelrol om te zorgen voor voldoende aanbod van Spot Instances. Zoals te zien is in de volgende afbeelding, starten gebruikers Spark-taken met job orchestrators, notebooks of services via SSP's. De SSP implementeert hun interne functionaliteit om toegang te krijgen tot de ongebruikte instanties in de Spot Instance-pool in cloudservices zoals AWS. Een van de best practices voor het gebruik van Spot-instanties is het diversifiëren van instantietypen (voor meer informatie, zie Kostenoptimalisatie met behulp van EC2 Spot Instances). Concreet zijn er twee belangrijke kenmerken voor een SSP om diversificatie van instanties te bereiken:
- De SSP moet toegang hebben tot alle soorten instanties in de Spot Instance-pool in AWS
- De SSP moet functionaliteit bieden waarmee gebruikers zoveel mogelijk instantietypen kunnen gebruiken bij het starten van Spark-applicaties
Onze laatste SSP biedt niet de verwachte oplossing voor deze twee punten. Ze ondersteunen slechts een beperkt aantal typen Spot-instanties en staan standaard toe dat slechts één type Spot-instantie wordt geselecteerd bij het starten van Spark-taken. Als gevolg hiervan draait elke Spark-toepassing slechts met een kleine capaciteit aan Spot-instanties en is deze kwetsbaar voor beëindiging van Spot-instanties.
EMR op EKS gebruikt Amazon Elastic Kubernetes-service (Amazon EKS) voor toegang tot Spot Instances in AWS. Amazon EKS ondersteunt alle beschikbare EC2-instantietypen, waardoor we een pool met veel hogere capaciteit krijgen. We gebruiken de kenmerken van Door Amazon EKS beheerde node-groepen en knooppuntkiezers en bederven om elke Spark-toepassing toe te wijzen aan een knooppuntgroep die uit meerdere instantietypen bestaat. Nadat we op EKS naar EMR waren overgestapt, zagen we de volgende voordelen:
- Spot Instance-beëindiging kwam minder vaak voor en de runtime van onze Spark-applicaties werd korter en bleef stabiel.
- Ingenieurs konden sneller itereren omdat ze verbetering zagen in de voorspelbaarheid van applicatiegedrag.
- De infrastructuurkosten daalden aanzienlijk omdat we geen dure tijdelijke oplossingen meer nodig hadden en tegelijkertijd hadden we een geavanceerde selectie van instanties in elke knooppuntgroep van Amazon EKS. We waren in staat om ongeveer 50% op de computerkosten te besparen zonder tijdelijke oplossingen zoals het werken in meerdere beschikbaarheidszones en tegelijkertijd het verwachte niveau van betrouwbaarheid te bieden.
Soepele foutopsporingservaring
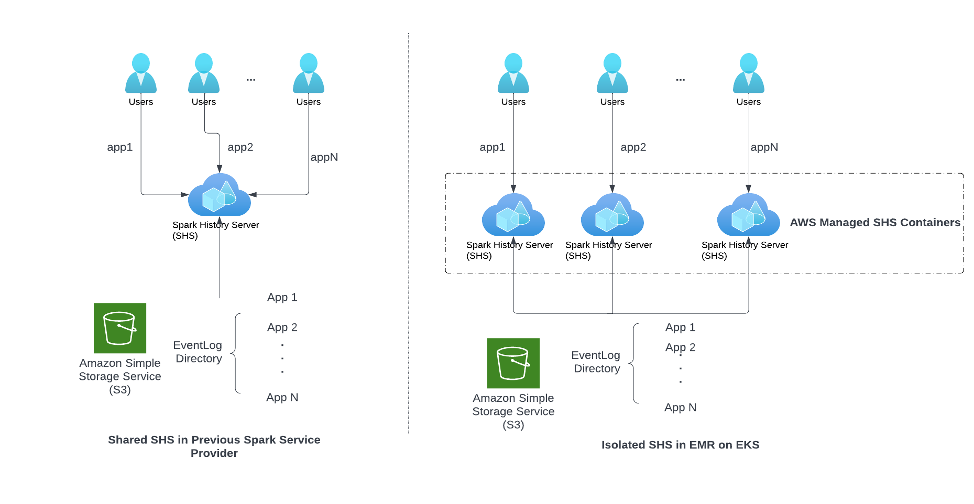
Een infrastructuur die technici ondersteunt bij het gemakkelijk debuggen van de Spark-toepassing, is van cruciaal belang om de lus van onze engineeringworkflow te sluiten. Apache Spark gebruikt event logs om de activiteiten van een Spark-toepassing vast te leggen, zoals het starten en beëindigen van taken. Deze gebeurtenissen zijn opgemaakt in JSON en worden door SHS gebruikt om de gebruikersinterface van Spark-toepassingen opnieuw weer te geven. Ingenieurs hebben toegang tot SHS om redenen voor het mislukken van taken of prestatieproblemen op te sporen.
De grootste uitdaging voor ingenieurs in SafeGraph was het schaalbaarheidsprobleem in SHS. Zoals te zien is in het linkerdeel van de volgende afbeelding, dwong onze vorige SSP alle technici om dezelfde SHS-instantie te delen. Als gevolg hiervan stond SHS onder grote druk omdat veel technici tegelijkertijd toegang hadden om hun applicaties te debuggen, of omdat een Spark-applicatie een groot gebeurtenislogboek had dat moest worden weergegeven. Voordat we overstapten naar EMR op EKS, ondervonden we regelmatig traagheid van SHS of crashte SHS volledig.
Zoals te zien is in de volgende afbeelding, start EMR op EKS voor elk verzoek om de Spark-geschiedenis-UI te bekijken een onafhankelijke SHS-instantiecontainer in een door AWS beheerde omgeving. Het voordeel van deze architectuur is tweeledig:
- Verschillende gebruikers en Spark-applicaties concurreren niet meer om SHS-resources. Daarom ervaren we nooit traagheid of crashes van SHS.
- Alle SHS-containers worden beheerd door AWS; gebruikers hoeven geen extra financiële of operationele kosten te betalen om van de schaalbare architectuur te genieten.
Beheerbaar Spark-platform
Zoals te zien is in de engineeringworkflow, is het bouwen van een Spark-platform geen eenmalige inspanning en moeten platformteams het Spark-platform beheren en elke stap in de engineering-ontwikkelingsworkflow blijven optimaliseren. De rol van de SSP moet de juiste faciliteiten bieden om de operationele lasten zoveel mogelijk te verlichten. Hoewel er veel soorten operationele taken zijn, concentreren we ons in dit bericht op twee ervan: SKU-beheer van computerresources en beheer van Spark-distributieversies.
SKU-beheer van computerresources verwijst naar het ontwerp en het proces voor een Spark-platform, zodat gebruikers verschillende groottes van computerinstanties kunnen kiezen. Een dergelijk ontwerp en proces zouden grotendeels afhangen van de relevante functionaliteit die vanuit SSP's wordt geïmplementeerd.
De volgende afbeelding toont het SKU-beheer met onze vorige SSP.

De volgende afbeelding toont SKU-beheer met EMR op EKS.

Met onze vorige SSP stond taakconfiguratie alleen toe om expliciet één type Spot-instantie op te geven, en als dat type geen Spot-capaciteit meer had, schakelde de taak over naar On-Demand of kreeg het te maken met betrouwbaarheidsproblemen. Hierdoor hadden platformingenieurs de keuze om de instellingen van de vloot van Spark-jobs te wijzigen of ongewenste verrassingen te riskeren voor hun budget en de kosten van verkochte goederen.
EMR op EKS maakt het voor het platformteam veel eenvoudiger om computer-SKU's te beheren. In SafeGraph hebben we een Spark-serviceclient ingebed tussen gebruikers en EMR op EKS. De Spark-serviceclient stelt alleen verschillende niveaus van bronnen beschikbaar voor gebruikers (zoals klein, middelgroot en groot). Elke laag is toegewezen aan een bepaalde knooppuntgroep die is geconfigureerd in Amazon EKS. Dit ontwerp biedt de volgende voordelen:
- In het geval van prijs- en capaciteitswijzigingen is het voor ons gemakkelijk om configuraties in knooppuntgroepen bij te werken en deze geabstraheerd te houden van gebruikers. Gebruikers veranderen niets, of voelen het zelfs, en blijven genieten van de stabiele resourcevoorziening terwijl we de kosten en operationele overhead zo laag mogelijk houden.
- Bij het kiezen van de juiste bronnen voor de Spark-toepassing hoeven eindgebruikers geen giswerk te doen, omdat de keuze eenvoudig is dankzij de vereenvoudigde configuratie.
Verbeterd releasebeheer van Spark-distro's is het andere voordeel dat we halen uit EMR op EKS. Voordat we EMR op EKS gebruikten, hadden we last van de niet-transparante release van Spark-distro in onze SSP. Elke 1-2 maanden wordt er een nieuwe gepatchte versie van Spark-distro uitgebracht voor gebruikers. Deze versies worden allemaal via hun gebruikersinterface aan gebruikers getoond. Dit resulteerde erin dat ingenieurs verschillende versies van distro kozen, waarvan sommige niet waren getest met onze interne tools. Het verhoogde het uitvalpercentage van onze pijplijnen, interne systemen en de ondersteuningslast van platformteams aanzienlijk. We verwachten dat het risico van releases van Spark-distributies minimaal en transparant moet zijn voor gebruikers met een EMR op EKS-architectuur.
EMR op EKS volgt de best practices met een stabiele basis Docker-image met een vaste versie van Spark-distro. Voor elke wijziging van Spark-distro moeten we de Docker-image expliciet opnieuw opbouwen en uitrollen. Met EMR op EKS kunnen we een nieuwe versie van Spark-distro verborgen houden voor gebruikers voordat we deze testen met onze interne tools en systemen en een formele release doen.
Conclusie
In dit bericht deelden we onze reis door een Spark-platform te bouwen bovenop EMR op EKS. EMR op EKS als SSP dient als een sterke basis van ons Spark-platform. Met EMR op EKS waren we in staat om uitdagingen op te lossen, variërend van afhankelijkheidsbeheer, resourcevoorziening en foutopsporingservaring, en konden we ook onze computerkosten aanzienlijk verlagen met 50% dankzij de hogere beschikbaarheid van Spot Instance-typen en -groottes.
We hopen dat dit bericht enkele inzichten kan delen met de gemeenschap bij het kiezen van de juiste SSP voor uw bedrijf. Meer informatie over EMR op EKS, inclusief voordelen, functies en hoe u aan de slag kunt.
Over de auteurs
 Nan Zhu is de Tech Lead Manager van het platformteam in SafeGraph. Hij leidt het team om een breed scala aan infrastructuur en interne tooling te bouwen om de betrouwbaarheid, efficiëntie en productiviteit van het SafeGraph-engineeringproces te verbeteren, bijvoorbeeld het interne Spark-ecosysteem, metrische opslag en CI/CD voor grote mono-repo's, enz. Hij is ook betrokken in meerdere open source-projecten zoals Apache Spark, Apache Iceberg, Gluten, etc.
Nan Zhu is de Tech Lead Manager van het platformteam in SafeGraph. Hij leidt het team om een breed scala aan infrastructuur en interne tooling te bouwen om de betrouwbaarheid, efficiëntie en productiviteit van het SafeGraph-engineeringproces te verbeteren, bijvoorbeeld het interne Spark-ecosysteem, metrische opslag en CI/CD voor grote mono-repo's, enz. Hij is ook betrokken in meerdere open source-projecten zoals Apache Spark, Apache Iceberg, Gluten, etc.
 Dave Thibaut is een Sr. Solutions Architect die de klanten van AWS's Independent Software Vendor (ISV) bedient. Hij heeft een passie voor bouwen met serverloze technologieën, machine learning en het versnellen van het zakelijke succes van zijn AWS-klanten. Voordat hij bij AWS kwam, werkte Dave 17 jaar bij life sciences-bedrijven waar hij IT en informatica deed voor onderzoeks-, ontwikkelings- en klinische productiegroepen. Hij houdt ook van snowboarden, plein air olieverfschilderijen en tijd doorbrengen met zijn gezin.
Dave Thibaut is een Sr. Solutions Architect die de klanten van AWS's Independent Software Vendor (ISV) bedient. Hij heeft een passie voor bouwen met serverloze technologieën, machine learning en het versnellen van het zakelijke succes van zijn AWS-klanten. Voordat hij bij AWS kwam, werkte Dave 17 jaar bij life sciences-bedrijven waar hij IT en informatica deed voor onderzoeks-, ontwikkelings- en klinische productiegroepen. Hij houdt ook van snowboarden, plein air olieverfschilderijen en tijd doorbrengen met zijn gezin.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/how-safegraph-built-a-reliable-efficient-and-user-friendly-spark-platform-with-amazon-emr-on-amazon-eks/

