Dit bericht is mede geschreven door Anshuman Varshney, technisch hoofd bij Gameskraft.
Gameskraft is een van India's toonaangevende online gamingbedrijven en biedt game-ervaringen in verschillende categorieën, zoals rummy, ludo, poker en nog veel meer onder de merken RummyCultuur, Ludo-cultuur, Zak52 en Speelschip. Gameskraft heeft de Guinness World Record voor het organiseren van 's werelds grootste online rummytoernooi, en is een van India's eerste gamingbedrijven die een ISO-gecertificeerd platform heeft gebouwd.
Amazon roodverschuiving is een volledig beheerde datawarehousing-service die zowel ingerichte als serverloze opties biedt, waardoor het efficiënter wordt om analyses uit te voeren en te schalen zonder dat u uw datawarehouse hoeft te beheren. Met Amazon Redshift kun je SQL gebruiken om gestructureerde en semi-gestructureerde gegevens in datawarehouses, operationele databases en datameren te analyseren, met behulp van door AWS ontworpen hardware en machine learning (ML) om de beste prijs-kwaliteitverhouding op schaal te leveren.
In dit bericht laten we zien hoe Gameskraft Amazon Redshift gebruikte het delen van gegevens met gelijktijdigheid schaling en WLM-optimalisatie ter ondersteuning van de groeiende analyseworkloads.
Amazon Redshift-gebruiksscenario
Gameskraft gebruikte Amazon Redshift RA3-instanties met Redshift Managed Storage (RMS) voor hun datawarehouse. De upstream datapijplijn is een robuust systeem dat verschillende databronnen integreert, waaronder Amazon Kinesis en Amazon Managed Streaming voor Apache Kafka (Amazon MSK) voor het afhandelen van clickstream-gebeurtenissen, Amazon relationele databaseservice (Amazon RDS) voor deltatransacties, en Amazon DynamoDB voor deltaspelgerelateerde informatie. Bovendien worden gegevens geëxtraheerd uit leveranciers-API's die gegevens bevatten die verband houden met product-, marketing- en klantervaring. Al deze uiteenlopende gegevens worden vervolgens geconsolideerd in de Amazon eenvoudige opslagservice (Amazon S3) data lake voordat het wordt geüpload naar het Redshift-datawarehouse. Deze upstream-gegevensbronnen vormen de componenten van de gegevensproducent.
Gameskraft gebruikte Amazon Redshift werklastbeheer (WLM) om prioriteiten binnen werklasten te beheren, waarbij een hogere prioriteit wordt toegewezen aan de wachtrij voor extraheren, transformeren en laden (ETL) die kritieke taken voor gegevensproducenten uitvoert. De downstream-consumenten bestaan uit business intelligence (BI)-tools, waarbij meerdere data science- en data-analyseteams hun eigen WLM-wachtrijen hebben met de juiste prioriteitswaarden.
Naarmate het portfolio van gamingproducten van Gameskraft toenam, leidde dit tot een ongeveer vijfvoudige groei van toegewijde data-analyse- en datawetenschapsteams. Als gevolg hiervan was er een vervijfvoudiging van het aantal data-integraties en een vervijfvoudiging van het aantal ad-hocquery's dat werd ingediend bij het Redshift-cluster. Deze vraagpatronen en gelijktijdigheid waren onvoorspelbaar van aard. Ook nam in de loop van de tijd het aantal BI-dashboards (zowel gepland als live) toe, wat ertoe bijdroeg dat er meer vragen werden ingediend bij het Redshift-cluster.
Met deze groeiende werkdruk zag Gameskraft de volgende uitdagingen:
- Verhoging van de kritieke ETL-taakruntime
- Verhoging van de wachttijd voor zoekopdrachten in meerdere wachtrijen
- Impact van onvoorspelbare ad-hocqueryworkloads in andere wachtrijen in het cluster
Gameskraft was op zoek naar een oplossing die hen zou helpen al deze uitdagingen het hoofd te bieden en flexibiliteit te bieden om de verwerking van de opname- en consumptiewerklast onafhankelijk te schalen. Gameskraft was ook op zoek naar een oplossing die tegemoet zou komen aan hun onvoorspelbare toekomstige groei.
Overzicht oplossingen
Gameskraft heeft deze uitdagingen gefaseerd aangepakt met behulp van Gelijktijdigheidschaling van Amazon Redshift, Amazon Redshift-gegevens delen, Amazon Redshift Serverloosen door Redshift ingerichte clusters.
Met Amazon Redshift-concurrency-schaling kunt u eenvoudig duizenden gelijktijdige gebruikers en gelijktijdige zoekopdrachten ondersteunen, met consistent snelle queryprestaties. Naarmate de gelijktijdigheid toeneemt, voegt Amazon Redshift binnen enkele seconden automatisch de verwerkingskracht van zoekopdrachten toe om zoekopdrachten zonder enige vertraging te verwerken. Wanneer de vraag naar werklast afneemt, wordt deze extra verwerkingskracht automatisch verwijderd, zodat u alleen betaalt voor de tijd dat clusters voor gelijktijdige schaalvergroting in gebruik zijn. Amazon Redshift biedt 1 uur gratis gelijktijdigheidsschaalcredits per actief cluster per dag, waardoor u 30 uur gratis credits per maand kunt verzamelen.
Gameskraft heeft gelijktijdigheidsschaling mogelijk gemaakt selectieve WLM-wachtrijen om de wachttijd voor query's in die wachtrijen tijdens piekgebruik te verminderen en ook de runtime van ETL-query's te verminderen. In de vorige configuratie hadden we vier gespecialiseerde wachtrijen voor ETL, ad-hocquery's, BI-tools en datawetenschap. Om blokkades voor andere processen te voorkomen, hebben we minimale time-outs voor query's opgelegd met behulp van regels voor querybewaking (QMR). De wachtrijen van zowel de ETL- als de BI-tools waren echter voortdurend bezet, wat een impact had op de prestaties van de resterende wachtrijen.
Gelijktijdig schalen hielp de wachttijd voor query's in de ad-hocquerywachtrij te verminderen. Toch bleef de uitdaging van downstream-consumptieworkloads (zoals ad-hocquery's) die van invloed waren op de opname bestaan, en Gameskraft was op zoek naar een oplossing om deze workloads onafhankelijk te beheren.
De volgende tabel geeft een overzicht van de configuratie van het werklastbeheer voorafgaand aan de implementatie van de oplossing.
| Queue | Gebruik | Gelijktijdigheidsschaalmodus | Gelijktijdigheid op hoofd-/geheugen% | Regels voor querybewaking |
etl |
Voor opname vanuit meerdere gegevensintegratie | korting | auto | Actie stoppen op: Queryruntime (seconden) > 2700 |
report |
Voor geplande rapportagedoeleinden | korting | auto | Actie stoppen op: Queryruntime (seconden) > 600 |
datascience |
Voor data science-workloads | korting | auto | Actie stoppen op: Queryruntime (seconden) > 300 |
readonly |
Voor ad hoc en dagelijkse analyses | auto | auto | Actie stoppen op: Queryruntime (seconden) > 120 |
bi_tool |
Voor BI-tools | auto | auto | Actie stoppen op: Queryruntime (seconden) > 300 |
Om flexibiliteit bij het schalen te bereiken, gebruikte Gameskraft Amazon Redshift-gegevens delen. Met het delen van gegevens met Amazon Redshift kunt u het gebruiksgemak, de prestaties en de kostenvoordelen van een enkel cluster uitbreiden naar implementaties met meerdere clusters, terwijl u gegevens kunt delen. Het delen van gegevens maakt directe, gedetailleerde en snelle gegevenstoegang mogelijk in de datawarehouses van Amazon Redshift, zonder dat deze hoeven te worden gekopieerd of verplaatst. Het delen van gegevens biedt live toegang tot gegevens, zodat gebruikers altijd de meest actuele en consistente informatie kunnen zien wanneer deze wordt bijgewerkt in het datawarehouse. U kunt veilig live gegevens delen tussen ingerichte clusters, serverloze eindpunten binnen AWS-accounts, tussen AWS-accounts en tussen AWS-regio's.
Het delen van gegevens bouwt voort op Redshift Managed Storage (RMS), dat de basis vormt voor door RA3 ingerichte clusters en serverloze werkgroepen, waardoor meerdere magazijnen dezelfde gegevens kunnen opvragen met afzonderlijke geïsoleerde rekenkracht. Query's die toegang krijgen tot gedeelde gegevens worden uitgevoerd op het consumentencluster en lezen gegevens rechtstreeks uit RMS zonder de prestaties van het producentencluster te beïnvloeden. U kunt nu snel workloads onboarden met diverse datatoegangspatronen en SLA-vereisten, zonder dat u zich zorgen hoeft te maken over conflicten over resources.
We hebben ervoor gekozen om alle ETL-workloads in het primaire producentencluster uit te voeren, zodat ETL onafhankelijk kan worden beheerd. We hebben het delen van gegevens gebruikt om alleen-lezen toegang tot gegevens te delen met een serverloze data science-werkgroep, een door BI ingericht cluster, een ad-hocquery ingericht cluster en een serverloze werkgroep voor gegevensintegratie. Teams die deze afzonderlijke computerbronnen gebruiken, kunnen vervolgens dezelfde gegevens opvragen zonder de gegevens tussen de producent en de consument te kopiëren. Daarnaast hebben we gelijktijdigheidsschaling geïntroduceerd voor de consumentenwachtrijen, waarbij we prioriteit hebben gegeven aan BI-tools, en hebben we de time-out voor de resterende wachtrijen verlengd. Deze wijzigingen hebben met name de algehele efficiëntie en doorvoer verbeterd.
De volgende tabel bevat een overzicht van de nieuwe configuratie voor werklastbeheer voor het producentencluster.
| Queue | Gebruik | Gelijktijdigheidsschaalmodus | Gelijktijdigheid op hoofd-/geheugen% | Regels voor querybewaking |
etl |
Voor opname vanuit meerdere gegevensintegratie | auto | auto | Actie stoppen op: Queryruntime (seconden) > 3600 |
De volgende tabel bevat een overzicht van de nieuwe configuratie voor werkbelastingbeheer voor het consumentencluster.
| Queue | Gebruik | Gelijktijdigheidsschaalmodus | Gelijktijdigheid op hoofd-/geheugen% | Regels voor querybewaking |
report |
Voor geplande rapportagedoeleinden | korting | auto | Actie stoppen op: Queryruntime (seconden) > 1200 Wachtrijtijd voor query's (seconden) > 1800 Aantal spectrumscanrijen (rijen) > 100000 Spectrumscan (MB) > 3072 |
datascience |
Voor data science-workloads | korting | auto | Actie stoppen op: Queryruntime (seconden) > 600 Wachtrijtijd voor query's (seconden) > 1800 Aantal spectrumscanrijen (rijen) > 100000 Spectrumscan (MB) > 3072 |
readonly |
Voor ad hoc en dagelijkse analyses | auto | auto | Actie stoppen op: Queryruntime (seconden) > 900 Wachtrijtijd voor query's (seconden) > 3600 Spectrumscan (MB) > 3072 Aantal spectrumscanrijen (rijen) > 100000 |
bi_tool_live |
Voor live BI-tools | auto | auto | Actie stoppen op: Queryruntime (seconden) > 900 Wachtrijtijd voor query's (seconden) > 1800 Spectrumscan (MB) > 1024 Aantal spectrumscanrijen (rijen) > 1000 |
bi_tool_schedule |
Voor geplande BI-tools | auto | auto | Actie stoppen op: Queryruntime (seconden) > 1800 Wachtrijtijd voor query's (seconden) > 3600 Spectrumscan (MB) > 1024 Aantal spectrumscanrijen (rijen) > 1000 |
Implementatie van oplossingen
Gameskraft is toegewijd aan het handhaven van ononderbroken systeemoperaties, waarbij naadloze oplossingen prioriteit krijgen boven downtime. Bij het nastreven van dit principe zijn strategische maatregelen genomen om een soepel migratieproces naar het mogelijk maken van het delen van gegevens te garanderen. Dit omvatte de volgende stappen:
- Planning:
- Het repliceren van gebruikers en groepen naar de consument, om potentiële toegangscomplicaties voor analyse-, datawetenschap- en BI-teams te beperken.
- Het opzetten van een uitgebreide opzet bij de consumenten, die essentiële componenten omvat, zoals externe schema's voor Amazon Roodverschuivingsspectrum.
- Het afstemmen van WLM-configuraties op maat van de wensen van de consument.
- Implementatie:
- Introductie van inzichtelijke monitoringdashboards in Grafana voor CPU-gebruik, lees-/schrijfdoorvoer, IOPS en latenties die specifiek zijn voor het consumentencluster, waardoor de toezichtmogelijkheden worden verbeterd.
- Het wijzigen van alle geïnterleavede sleuteltabellen op het producentencluster in samengestelde sorteersleuteltabellen om gegevens naadloos over te zetten.
- Het creëren van een extern schema vanuit de datashare-database op de consument, een weerspiegeling van dat van het producentencluster met identieke namen. Deze aanpak minimaliseert de noodzaak om query-aanpassingen op meerdere locaties aan te brengen.
- testen:
- Het uitvoeren van een intern regressietest- en auditproces van een week om alle datapunten nauwgezet te valideren door dezelfde werklast en tweemaal de werklast uit te voeren.
- Laatste wijzigingen:
- Het bijwerken van de DNS-record voor het clustereindpunt, waaronder het vervangen van het eindpunt van het consumentencluster naar hetzelfde domein als het eindpunt van het producentencluster, om verbindingen te stroomlijnen en te voorkomen dat er op meerdere plaatsen wijzigingen worden aangebracht.
- Zorgen voor gegevensbeveiliging en toegangscontrole door groeps- en gebruikersrechten van het producentencluster in te trekken.
Het volgende diagram illustreert de Gameskraft Amazon Redshift-architectuur voor het delen van gegevens.
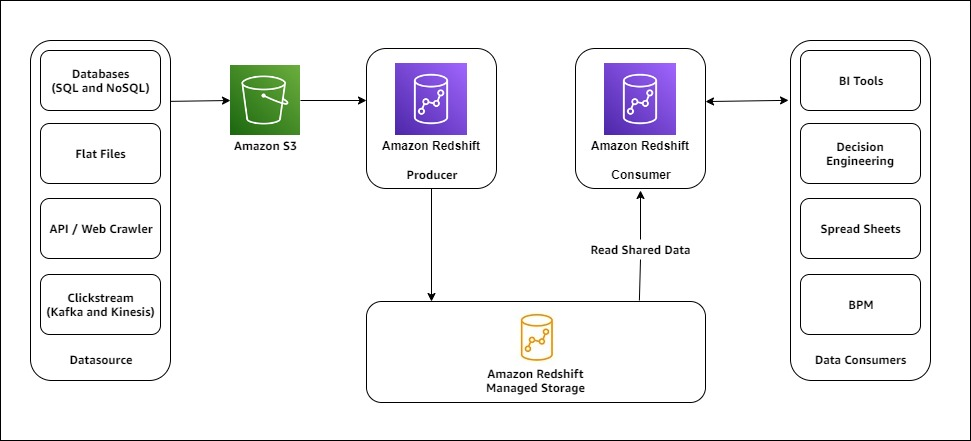
Het volgende diagram illustreert de Amazon Redshift-architectuur voor het delen van gegevens met meerdere consumentenclusters.
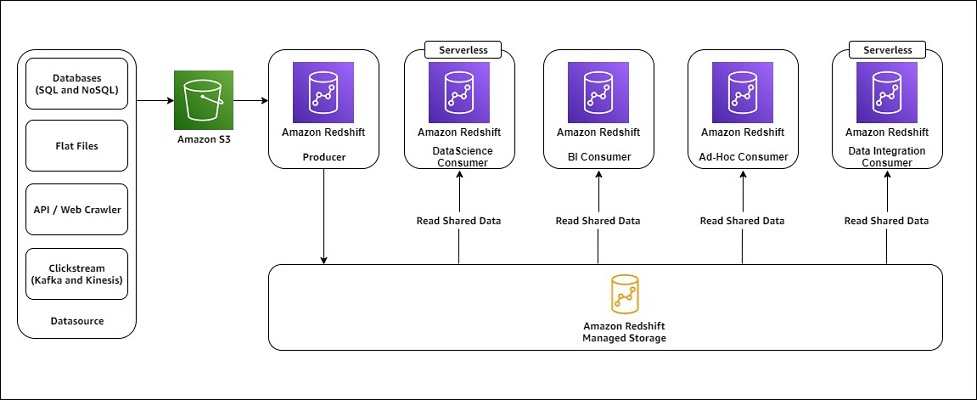
Met de implementatie van het delen van gegevens kon Gameskraft de werklasten van producenten en consumenten isoleren. Het delen van gegevens bood ook de flexibiliteit om de datawarehouses voor producenten en consumenten onafhankelijk van elkaar te schalen.
De implementatie van de totaaloplossing hielp Gameskraft bij het ondersteunen van frequentere gegevensverversing (43% reductie in de totale taakruntime) voor de ETL-werklast, die draait op het producentencluster, samen met mogelijkheden om een groeiend (vijf keer groter aantal gebruikers, BI) te ondersteunen werklasten en ad-hocquery's) en onvoorspelbare werklast voor consumenten.
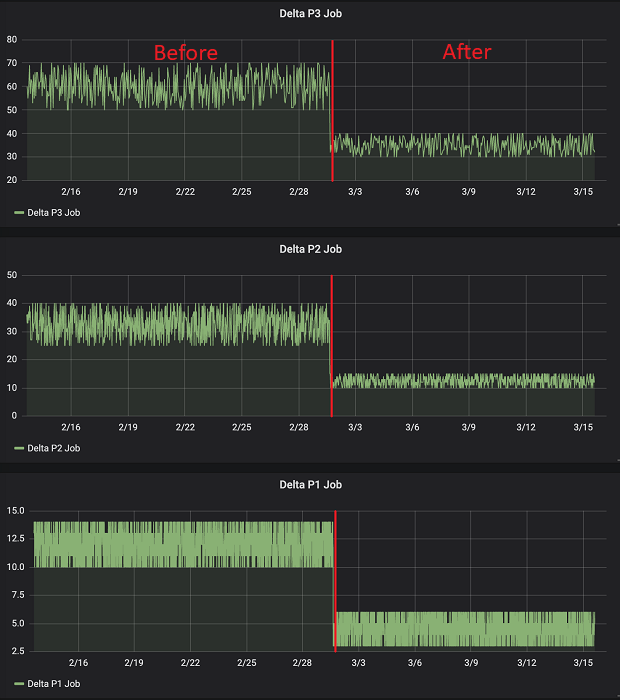
De volgende dashboards tonen enkele van de kritieke runtimes van de ETL-pijplijn (vóór de implementatie van de oplossing en na de implementatie van de oplossing).
De eerste toont de delta P1/P2/P3-taak die wordt uitgevoerd vóór en na de implementatie van de oplossing (duur in minuten).
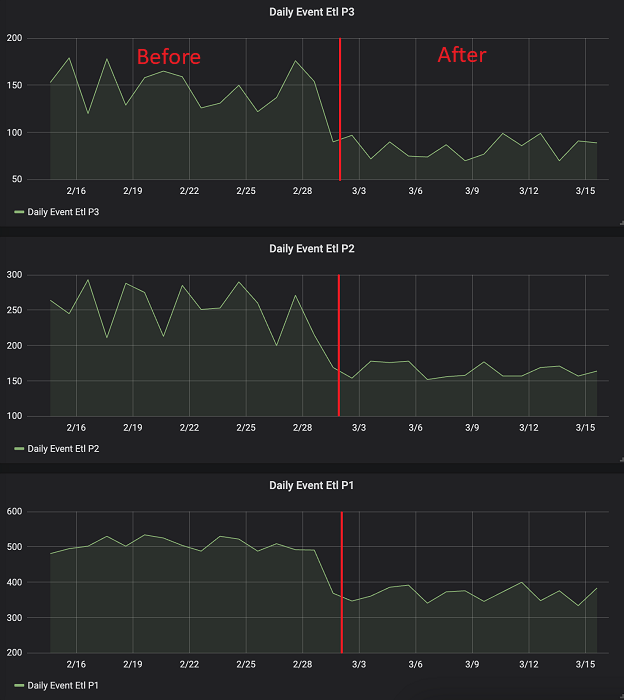
Hieronder ziet u hoe de dagelijkse gebeurtenis ETL P1/P2/P3-taak wordt uitgevoerd vóór en na de implementatie van de oplossing (duur in minuten).
Belangrijke overwegingen
Gameskraft omarmt een moderne data-architectuur, waarbij het datameer zich in Amazon S3 bevindt. Om naadloze toegang tot het datameer te bieden, maken we gebruik van de innovatieve mogelijkheden van Redshift Spectrum, een brug tussen het datawarehouse (Amazon Redshift) en het datameer (Amazon S3). Hiermee kunt u gegevenstransformaties en analyses rechtstreeks uitvoeren op gegevens die zijn opgeslagen in Amazon S3, zonder dat u de gegevens naar uw Redshift-cluster hoeft te dupliceren.
Gameskraft heeft een aantal belangrijke lessen geleerd tijdens de implementatie van deze oplossing voor het delen van gegevens:
- Ten eerste, op het moment van schrijven, het delen van gegevens door Amazon Redshift ondersteunt niet het toevoegen van externe schema's, tabellen of laatbindende weergaven van externe tabellen aan de gegevensshare. Om dit mogelijk te maken, hebben we een extern schema gemaakt als verwijzing naar AWS lijm database. Er wordt verwezen naar dezelfde AWS Glue-database in het externe schema aan de consumentenzijde.
- Ten tweede ondersteunt Amazon Redshift het delen van tabellen met interleaved sorteersleutels en views die verwijzen naar tabellen met interleaved sorteersleutels niet. Vanwege de aanwezigheid van interleaved sorteersleutels in talloze tabellen en weergaven, is een voorwaarde voor opname in de gegevensshare het herzien van de sorteersleutelconfiguratie om samengestelde sorteersleutels te gebruiken.
Conclusie
In dit bericht zagen we hoe Gameskraft het delen van gegevens en het schalen van gelijktijdigheid in Amazon Redshift gebruikte met een producenten- en consumentenclusterarchitectuur om het volgende te bereiken:
- Verkort de wachttijd voor query's voor alle wachtrijen in de producer en consumer
- Schaal de producent en consument onafhankelijk op basis van de werklast en wachtrijvereisten
- Verbeter de prestaties van de ETL-pijplijn en de gegevensvernieuwingscyclus om frequentere vernieuwingen in het producentencluster te ondersteunen
- Zorg voor meer wachtrijen en werklasten (BI-toolswachtrij, data-integratiewachtrij, datawetenschapswachtrij, downstream-teamwachtrij, ad-hocquerywachtrij) in de consument zonder gevolgen voor de ETL-pijplijn in het producentencluster
- Flexibiliteit om meerdere consumenten te gebruiken met een mix van een ingericht Redshift-cluster en Redshift Serverless
Deze Amazon Redshift-functies en -architectuur kunnen een groeiende en onvoorspelbare analysewerklast helpen ondersteunen.
Over de auteurs
 Anshuman Varshney is Technical Lead bij Gameskraft met een achtergrond in zowel backend als data engineering. Hij heeft een bewezen staat van dienst in het leiden en begeleiden van multifunctionele teams om hoogwaardige, schaalbare oplossingen te leveren. Naast zijn werk geniet hij van momenten met zijn gezin, geniet hij van filmische ervaringen en grijpt hij elke gelegenheid aan om via reizen nieuwe bestemmingen te verkennen.
Anshuman Varshney is Technical Lead bij Gameskraft met een achtergrond in zowel backend als data engineering. Hij heeft een bewezen staat van dienst in het leiden en begeleiden van multifunctionele teams om hoogwaardige, schaalbare oplossingen te leveren. Naast zijn werk geniet hij van momenten met zijn gezin, geniet hij van filmische ervaringen en grijpt hij elke gelegenheid aan om via reizen nieuwe bestemmingen te verkennen.
 Prafulla Wani is een Amazon Redshift Specialist Solution Architect bij AWS. Hij werkt met AWS-klanten aan analytische architectuurontwerpen en Amazon Redshift proofs of concept. In zijn vrije tijd speelt hij schaak met zijn zoon.
Prafulla Wani is een Amazon Redshift Specialist Solution Architect bij AWS. Hij werkt met AWS-klanten aan analytische architectuurontwerpen en Amazon Redshift proofs of concept. In zijn vrije tijd speelt hij schaak met zijn zoon.
 Saurov Nandy is een oplossingsarchitect bij AWS. Hij werkt samen met AWS-klanten om oplossingen te ontwerpen en te implementeren die complexe zakelijke problemen oplossen. In zijn vrije tijd verkent hij graag nieuwe plekken en houdt hij zich bezig met fotografie en videobewerking.
Saurov Nandy is een oplossingsarchitect bij AWS. Hij werkt samen met AWS-klanten om oplossingen te ontwerpen en te implementeren die complexe zakelijke problemen oplossen. In zijn vrije tijd verkent hij graag nieuwe plekken en houdt hij zich bezig met fotografie en videobewerking.
 Shashank Tewari is een Senior Technisch Accountmanager bij AWS. Hij helpt AWS-klanten hun architecturen te optimaliseren om prestaties, schaalbaarheid en kostenefficiëntie te bereiken. In zijn vrije tijd speelt hij graag videogames met zijn kinderen. Tijdens vakanties houdt hij ervan om door de bergen te trekken en avontuurlijke sporten te beoefenen.
Shashank Tewari is een Senior Technisch Accountmanager bij AWS. Hij helpt AWS-klanten hun architecturen te optimaliseren om prestaties, schaalbaarheid en kostenefficiëntie te bereiken. In zijn vrije tijd speelt hij graag videogames met zijn kinderen. Tijdens vakanties houdt hij ervan om door de bergen te trekken en avontuurlijke sporten te beoefenen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/how-gameskraft-uses-amazon-redshift-data-sharing-to-support-growing-analytics-workloads/

