Dit bericht is geschreven in samenwerking met Vijay Chitoor, mede-oprichter en CEO, en Mehul Shah, mede-oprichter en CTO van het Blueshift-team, als hoofdauteurs.
blueshift is een in San Francisco gevestigde startup die marketeers helpt bij het leveren van uitzonderlijke klantervaringen op elk kanaal en relevante gepersonaliseerde marketing levert. Blueshift's SmartHub Customer Data Platform (CDP) stelt marketingteams in staat om hun eigen klantgegevens te activeren om 1:1 personalisatie te stimuleren op eigen (e-mail, mobiel) en betaalde (Google, Facebook, enzovoort) website en klantkanalen (CX) .
In dit bericht bespreekt het oprichtende team van Blueshift hoe ze gebruikten Amazon Redshift-gegevens-API om gegevens van hun klanten te integreren Amazon roodverschuiving datawarehouse met hun CDP-omgeving om marketeers te helpen hun bedrijfsgegevens te activeren en de groei van hun bedrijf te stimuleren.
Zakkelijke behoefte
In de huidige omnichannelwereld krijgen marketingteams van moderne ondernemingen de taak om klanten via meerdere kanalen aan zich te binden. Om met succes intelligente klantbetrokkenheid te leveren, moeten marketeers werken met een 360-gradenbeeld van hun klanten dat rekening houdt met verschillende soorten gegevens, waaronder klantgedrag, demografische gegevens, toestemming en voorkeuren, transacties, gegevens van door mensen ondersteunde en digitale interacties, en meer . Het is echter vaak een gigantische taak om deze gegevens te verenigen en bruikbaar te maken voor marketeers. Nu, voor het eerst, met de integratie van Blueshift met Amazon Redshift, kunnen bedrijven meer data dan ooit gebruiken voor intelligente cross-channel betrokkenheid.
Amazon Redshift is een snel, volledig beheerd datawarehouse in de cloud. Tienduizenden klanten gebruiken Amazon Redshift als hun analyse-infrastructuur. Gebruikers zoals data-analisten, database-ontwikkelaars en datawetenschappers gebruiken SQL om hun gegevens in de datawarehouses van Amazon Redshift te analyseren. Amazon Redshift biedt naast ondersteuning voor connectiviteit via ODBC/JDBC of de Redshift Data API ook een webgebaseerde query-editor.
Blueshift heeft tot doel zakelijke gebruikers in staat te stellen gegevens in dergelijke datawarehouses te ontsluiten en doelgroepen te activeren met gepersonaliseerde trajecten voor segmentatie, 1:1 messaging, website, mobiel en betaalde media use cases. Bovendien kan Blueshift helpen deze gegevens in de datawarehouses van Amazon Redshift te combineren met realtime website- en mobiele gegevens voor realtime profielen en activering, waardoor deze gegevens kunnen worden gebruikt door marketeers in deze bedrijven.
Hoewel de gegevens in Amazon Redshift ongelooflijk krachtig zijn, kunnen marketeers deze om verschillende redenen niet in hun oorspronkelijke vorm gebruiken voor klantbetrokkenheid. Ten eerste vereist het opvragen van de gegevens kennis van opvraagtalen zoals SQL, waar marketeers niet noodzakelijkerwijs bedreven in zijn. Bovendien moeten marketeers de gegevens in het magazijn combineren met aanvullende gegevensbronnen die cruciaal zijn voor klantbetrokkenheid, waaronder real-time gebeurtenissen (bijvoorbeeld een webpagina die door een klant wordt bekeken), evenals machtigingen en identiteit op kanaalniveau .
Met de nieuwe integratie kunnen Blueshift-klanten multidimensionale gegevenstabellen van Amazon Redshift (bijvoorbeeld een klantentabel, transactietabel en productcatalogustabel) opnemen in Blueshift om een enkel klantbeeld op te bouwen dat toegankelijk is voor marketeers. De bidirectionele integratie zorgt er ook voor dat voorspellende gegevenskenmerken die in Blueshift zijn berekend, evenals gegevens over campagnebetrokkenheid van Blueshift, worden teruggeschreven naar Amazon Redshift-tabellen, waardoor technologie- en analyseteams een uitgebreid beeld van de gegevens kunnen krijgen.
In dit bericht beschrijven we hoe Blueshift integreert met Amazon Redshift. We benadrukken de bidirectionele integratie met gegevens die van het Amazon Redshift-datawarehouse van een klant naar de CDP-omgeving van Blueshift stromen en vice versa. Deze mechanismen worden mogelijk gemaakt door het gebruik van de Redshift Data API.
Overzicht oplossingen
De integratie tussen de twee omgevingen wordt gerealiseerd door middel van een connector. In deze sectie bespreken we de kerncomponenten van de connector. Blueshift maakt gebruik van een hybride aanpak met behulp van Redshift S3 UITLADEN, Roodverschuiving S3 KOPIEEn Redshift-gegevens-API om de integratie tussen Blueshift en te vereenvoudigen Amazon roodverschuiving, waardoor de gegevensbehoeften worden vergemakkelijkt om marketingteams te versterken. Het volgende stroomdiagram toont het overzicht van de oplossing.

Blueshift gebruikt containertechnologie om gegevens op te nemen en te verwerken. De containers voor gegevensopname en -uitvoer worden omhoog en omlaag geschaald, afhankelijk van de hoeveelheid gegevens die wordt verwerkt. Een van de belangrijkste ontwerpprincipes was om het ontwerp te vereenvoudigen door geen verbindingen of actieve verbindingspools te hoeven beheren. De Redshift Data API ondersteunt een op HTTP gebaseerde SQL-interface zonder dat verbindingen actief moeten worden beheerd. Zoals afgebeeld in de processtroom, de Redshift-gegevens-API geeft u toegang tot gegevens van Amazon Redshift met verschillende soorten traditionele, cloud-native, container-, serverloze webservice-gebaseerde applicaties en gebeurtenisgestuurde applicaties. De Blueshift-applicatie bevat een mix van programmeertalen, waaronder Ruby (voor het klantgerichte dashboard), Go (voor containerworkloads) en Python (voor data science-workloads). De Redshift Data API ondersteunt bindingen in Python, Go, Java, Node.js, PHP, Ruby en C++, wat het voor ontwikkelteams eenvoudig maakt om snel te integreren.
Met de Redshift Data API-integratie in de applicatie van Blueshift kunnen IT-gebruikers van Blueshift-klanten de dataverbinding opzetten en valideren, en vervolgens kunnen de zakelijke gebruikers van Blueshift (marketeers) naadloos waarde uit data halen door inzichten te ontwikkelen en die inzichten om te zetten in actie voor de klantdata naadloos ondergebracht in AWS Redshift. Daarom verlaagt het proces dat door Blueshift is ontwikkeld met behulp van de Redshift Data API de toetredingsdrempel aanzienlijk voor nieuwe gebruikers zonder ervaring met datawarehousing of voortdurende IT-afhankelijkheid voor de zakelijke gebruiker.
De oplossingsarchitectuur die in de volgende afbeelding wordt weergegeven, laat zien hoe de verschillende componenten van de CDP-omgeving en Amazon Redshift integreren om de end-to-end-oplossing te bieden.
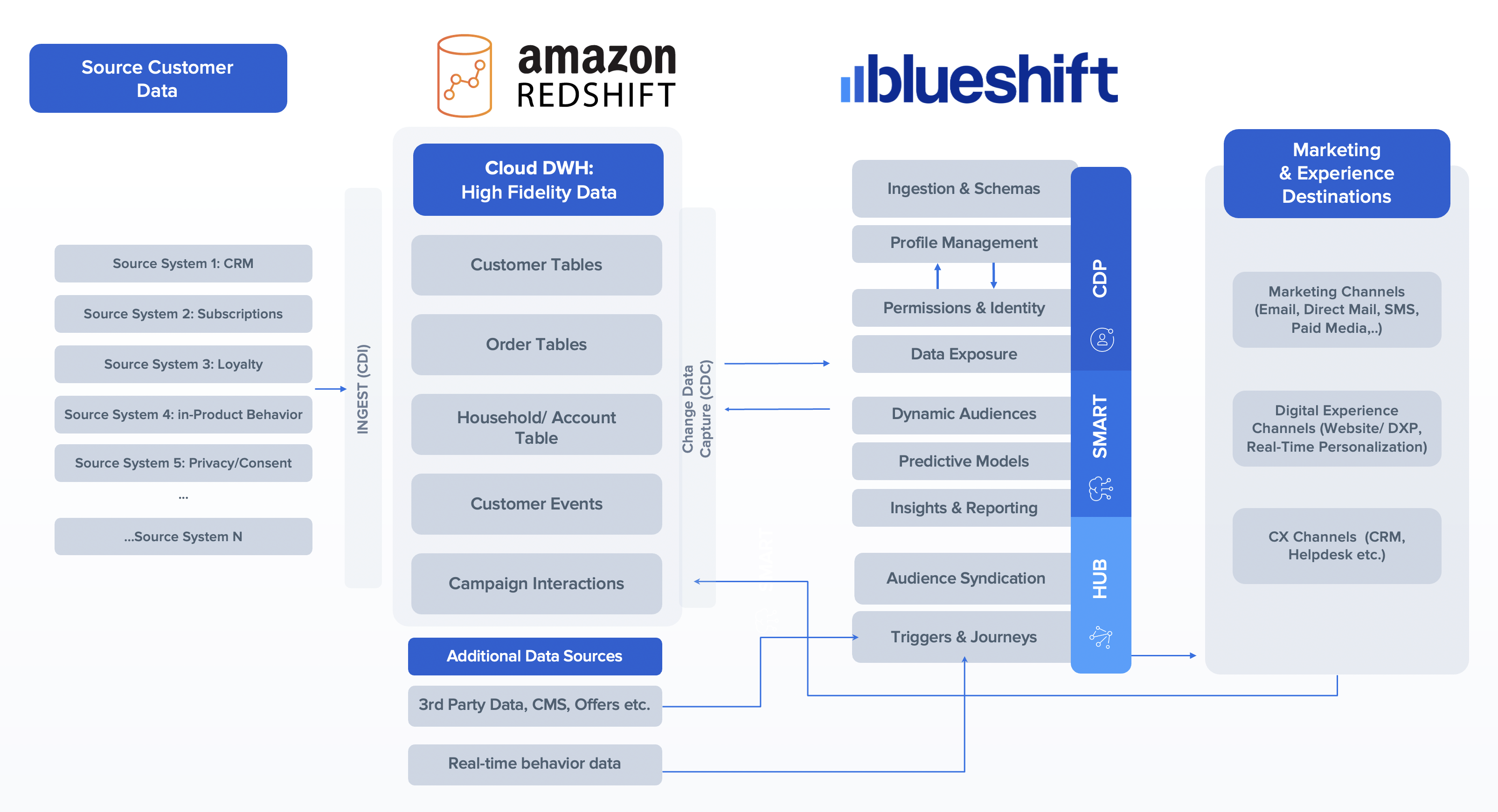
Voorwaarden
In deze sectie beschrijven we de vereisten van de integratieoplossing tussen de twee infrastructuren. Een typische gegevensimplementatie bij klanten omvat gegevens van Amazon Redshift die worden opgenomen in de Blueshift CDP-omgeving. Dit opnamemechanisme moet geschikt zijn voor verschillende gegevenstypen, zoals de volgende:
- Klant-CRM-gegevens (gebruikers-ID's en verschillende CRM-velden). Een typisch bereik voor het gegevensvolume dat voor dit gegevenstype moet worden ondersteund, is 50-500 GB eenmaal in eerste instantie opgenomen.
- Realtime gedrags- of gebeurtenisgegevens (bijvoorbeeld het afspelen of pauzeren van een film).
- Transactiegegevens, zoals abonnementsaankopen. Typische gegevensvolumes die dagelijks worden opgenomen voor gebeurtenissen en transacties liggen tussen de 500 GB en 1 TB.
- Catalogusinhoud (bijvoorbeeld een lijst met programma's of films om te ontdekken), die doorgaans ongeveer 1 GB groot is en dagelijks wordt ingenomen.
De integratie moet ook de CDP-platformomgeving van Blueshift ondersteunen om gegevens naar Amazon Redshift te exporteren. Dit omvat gegevens zoals campagneactiviteiten zoals e-mails die worden bekeken, die kunnen oplopen tot tientallen TB, en segment- of gebruikersexports ter ondersteuning van een lijst met gebruikers die deel uitmaken van een segmentdefinitie, doorgaans 50-500 GB die dagelijks wordt geëxporteerd.
Integreer Amazon Redshift met data-applicaties
Amazon Redshift biedt verschillende manieren om datatoepassingen snel te integreren.
Voor de eerste gegevensladingen gebruikt Blueshift Redshift S3 UNLOAD om Amazon Redshift-gegevens in te dumpen Amazon eenvoudige opslagservice (Amazone S3). Blueshift gebruikt native Amazon S3 als een permanente objectopslag en ondersteunt bulkopname en export vanuit Amazon S3. Dataloads van Amazon S3 worden parallel opgenomen en verkorten de laadtijden van data, waardoor Blueshift-clients snel kunnen instappen.
Voor incrementele gegevensopname volgen Blueshift-gegevensimporttaken de laatste keer dat een import is uitgevoerd en importeren nieuwe rijen met gegevens die zijn toegevoegd of bijgewerkt sinds de vorige import is uitgevoerd. Blueshift blijft synchroon met wijzigingen (updates of toevoegingen) aan het Amazon Redshift-datawarehouse met behulp van de Redshift Data API. Blueshift gebruikt de last_updated_at kolom in Amazon Redshift-tabellen om nieuwe of bijgewerkte rijen te bepalen en deze vervolgens op te nemen met behulp van de Redshift Data API. De cronjob voor gegevensintegratie van Blueshift synchroniseert gegevens bijna in real-time met behulp van de Redshift Data API door regelmatig naar updates te zoeken (bijvoorbeeld elke 10 minuten, elk uur of dagelijks). De cadans kan worden afgestemd, afhankelijk van de vereisten voor de versheid van gegevens.
De volgende tabel geeft een overzicht van de integratietypen.
| Integratietype | Integratie mechanisme | Voordeel |
| Eerste gegevensopname van Amazon Redshift naar Blueshift | Redshift S3 UNLOAD-opdracht | Initiële gegevens worden geëxporteerd van Amazon Redshift via Amazon S3 om sneller parallel laden in Blueshift mogelijk te maken met behulp van de Amazon Redshift UNLOAD-opdracht. |
| Incrementele gegevensopname van Amazon Redshift naar Blueshift | Redshift-gegevens-API | Incrementele gegevenswijzigingen worden bijna in realtime gesynchroniseerd met behulp van de Redshift Data API. |
| Gegevensexport van Blueshift naar Amazon Redshift | Redshift S3 COPY-opdracht | Blueshift slaat native campagneactiviteit en segmentgegevens op in Amazon S3, die in Amazon Redshift wordt geladen met behulp van de Redshift S3 COPY-opdracht. |
Redshift ondersteunt tal van kant-en-klare mechanismen om gegevenstoegang te bieden. Blueshift was in staat om de onboarding-tijd van gegevens voor klanten te verkorten door een hybride benadering te gebruiken van integratie met Amazon Redshift met Redshift S3 UNLOAD, de Redshift Data API en Redshift S3 COPY. Blueshift kan de initiële laadtijd van gegevens verkorten en in bijna realtime worden bijgewerkt met wijzigingen in Amazon Redshift en vice versa.
Conclusie
In dit bericht hebben we laten zien hoe Blueshift is geïntegreerd met de Redshift Data API om klantgegevens op te nemen. Deze integratie verliep naadloos en liet zien hoe eenvoudig de Redshift Data API integratie met externe applicaties, zoals Blueshift's CDP-omgeving voor marketing, met Amazon Redshift mogelijk maakt. De geschetste use-cases in dit bericht zijn slechts enkele voorbeelden van hoe de Redshift Data API kan worden gebruikt om interacties tussen gebruikers en Amazon Redshift-clusters te vereenvoudigen.
Ga nu Amazon Redshift bouwen en integreren met Blueshift.
Over de auteurs
 Vijay Chittoor is de CEO en mede-oprichter van Blueshift. Vijay heeft een schat aan ervaring op het gebied van AI, marketingtechnologie en e-commerce. Vijay was eerder de mede-oprichter en CEO van Mertado (overgenomen door Groupon om Groupon Goods te worden), en een vroeg teamlid bij Kosmix (overgenomen door Walmart om @WalmartLabs te worden). Vijay, voormalig consultant bij McKinsey & Co., is afgestudeerd aan het MBA-programma van de Harvard Business School. Hij heeft ook een bachelor- en masterdiploma in elektrotechniek van het Indian Institute of Technology, Bombay.
Vijay Chittoor is de CEO en mede-oprichter van Blueshift. Vijay heeft een schat aan ervaring op het gebied van AI, marketingtechnologie en e-commerce. Vijay was eerder de mede-oprichter en CEO van Mertado (overgenomen door Groupon om Groupon Goods te worden), en een vroeg teamlid bij Kosmix (overgenomen door Walmart om @WalmartLabs te worden). Vijay, voormalig consultant bij McKinsey & Co., is afgestudeerd aan het MBA-programma van de Harvard Business School. Hij heeft ook een bachelor- en masterdiploma in elektrotechniek van het Indian Institute of Technology, Bombay.
 Mehul Sjah is mede-oprichter en CTO bij Blueshift. Voorheen was hij mede-oprichter en CTO bij Mertado, dat door Groupon werd overgenomen om Groupon Goods te worden. Mehul was een vroege werknemer bij Kosmix dat door Walmart werd overgenomen om @WalmartLabs te worden. Mehul is een Y Combinator-alumni en afgestudeerd aan de University of Southern California. Mehul is mede-uitvinder van meer dan 12 patenten en coacht een robotteam op de middelbare school.
Mehul Sjah is mede-oprichter en CTO bij Blueshift. Voorheen was hij mede-oprichter en CTO bij Mertado, dat door Groupon werd overgenomen om Groupon Goods te worden. Mehul was een vroege werknemer bij Kosmix dat door Walmart werd overgenomen om @WalmartLabs te worden. Mehul is een Y Combinator-alumni en afgestudeerd aan de University of Southern California. Mehul is mede-uitvinder van meer dan 12 patenten en coacht een robotteam op de middelbare school.
 Manohar Vellala is een Senior Solutions Architect bij AWS en werkt met digital native klanten aan hun cloud native reis. Hij is gevestigd in San Francisco Bay Area en is gepassioneerd om klanten te helpen bij het bouwen van moderne applicaties die optimaal kunnen profiteren van de cloud. Voorafgaand aan AWS werkte hij bij H2O.ai, waar hij klanten hielp bij het bouwen van ML-modellen. Zijn interesses zijn Storage, Data Analytics en AI/ML.
Manohar Vellala is een Senior Solutions Architect bij AWS en werkt met digital native klanten aan hun cloud native reis. Hij is gevestigd in San Francisco Bay Area en is gepassioneerd om klanten te helpen bij het bouwen van moderne applicaties die optimaal kunnen profiteren van de cloud. Voorafgaand aan AWS werkte hij bij H2O.ai, waar hij klanten hielp bij het bouwen van ML-modellen. Zijn interesses zijn Storage, Data Analytics en AI/ML.
 Prashant Tyagi trad in september 2020 in dienst bij AWS, waar hij nu leiding geeft aan het oplossingsarchitectuurteam dat zich richt op het mogelijk maken van digitale native-bedrijven. Prashant werkte eerder bij ThermoFisher Scientific en GE Digital, waar hij functies bekleedde als Sr. Director voor hun initiatieven op het gebied van digitale transformatie. Prashant heeft digitale transformatie mogelijk gemaakt voor klanten in de Life Sciences en andere branches. Hij heeft ervaring in IoT, Data Lakes en AI/ML technische domeinen. Hij woont in de Bay Area in Californië.
Prashant Tyagi trad in september 2020 in dienst bij AWS, waar hij nu leiding geeft aan het oplossingsarchitectuurteam dat zich richt op het mogelijk maken van digitale native-bedrijven. Prashant werkte eerder bij ThermoFisher Scientific en GE Digital, waar hij functies bekleedde als Sr. Director voor hun initiatieven op het gebied van digitale transformatie. Prashant heeft digitale transformatie mogelijk gemaakt voor klanten in de Life Sciences en andere branches. Hij heeft ervaring in IoT, Data Lakes en AI/ML technische domeinen. Hij woont in de Bay Area in Californië.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/how-blueshift-integrated-their-customer-data-environment-with-amazon-redshift-to-unify-and-activate-customer-data-for-marketing/

