Introductie
In de steeds voortschrijdende technologische wereld van vandaag staat er een opwindende ontwikkeling aan de horizon: geavanceerde multimodale generatieve AI. Deze baanbrekende technologie gaat over het innovatiever en geweldiger maken van computers, het creëren van inhoud en begrip. Stel je een digitale assistent voor die naadloos met tekst, afbeeldingen en geluiden werkt en informatie genereert. In dit artikel zullen we bekijken hoe deze technologie functioneert in zijn real-time/praktische toepassingen en voorbeelden en zelfs vereenvoudigde codefragmenten bieden om het allemaal beschikbaar en begrijpelijk te maken. Laten we er dus in duiken en de wereld van geavanceerde multimodale generatieve AI verkennen.

In de volgende paragrafen zullen we de kernmodules van multimodale AI ontrafelen, van Input tot Fusion en Output, waardoor we een duidelijker inzicht krijgen in hoe ze samenwerken om deze technologie naadloos te laten functioneren. Daarnaast zullen we praktische codevoorbeelden verkennen die de mogelijkheden ervan en praktijkvoorbeelden illustreren. Geavanceerde multimodale generatieve AI is een sprong naar een interactiever, creatiever en efficiënter digitaal tijdperk waarin machines ons begrijpen en met ons communiceren op manieren die wij ons hebben voorgesteld.
leerdoelen
- Begrijp de basisprincipes van geavanceerde multimodale generatieve AI in eenvoudige bewoordingen.
- Ontdek hoe multimodale AI functioneert via de input-, fusie- en outputmodules.
- Krijg inzicht in de innerlijke werking van multimodale AI met praktische codevoorbeelden.
- Ontdek de real-world toepassingen van multimodale AI met real-world use cases.
- Maak onderscheid tussen single-modale en multi-modale AI en hun mogelijkheden.
- Verdiep u hierin wanneer u multimodale AI in praktijkscenario's inzet.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Geavanceerde multimodale generatieve AI begrijpen
Stel je voor dat je een robotvriend hebt, Robbie, die ongelooflijk slim is en je op veel verschillende manieren kan begrijpen. Als je Robbie een grappig verhaal wilt vertellen over je dagje op het strand, kun je ervoor kiezen om met hem te praten, een kunst/afbeelding te tekenen of hem zelfs een foto te laten zien. Dan kan Robbie uw woorden, afbeeldingen en meer begrijpen/begrijpen. Dit vermogen om verschillende manieren van communiceren en begrijpen te begrijpen en te gebruiken, is de essentie van ‘Multimodaal’.
Hoe werkt multimodale AI?
Multimodale AI is ontworpen om inhoud in verschillende datamodi, zoals tekst, afbeeldingen en audio, te begrijpen en te genereren. Het bereikt dit door drie belangrijke modules.

- Ingangsmodule
- Fusiemodule
- Uitgangsmodule
Laten we deze modules eens bekijken om te begrijpen hoe multimodale AI werkt.
Ingangsmodule
De Invoermodule is als de deur waar verschillende gegevenstypen worden ingevoerd. Dit is wat het doet:
- Tekstgegevens: Er wordt gekeken naar woorden en zinnen en hoe ze zich verhouden tot zinnen, zoals het begrijpen van taal.
- Afbeeldingsgegevens: Het controleert afbeeldingen en zoekt uit wat erin zit, zoals objecten, scènes of patronen.
- Audiogegevens: Het luistert naar geluiden en zet ze om in woorden, zodat AI het kan begrijpen.
De invoermodule neemt al deze gegevens en zet ze om in een taal die AI kan begrijpen. Het vindt de kritieke zaken en bereidt het voor op de volgende stap.
Fusiemodule
De Fusion Module is waar dingen samenkomen.
- Tekst-beeldfusie: Het brengt woorden en beelden samen. Dit helpt ons de voorwaarden en wat er op de afbeeldingen staat te begrijpen, waardoor het allemaal logisch wordt.
- Tekst-audiofusie: Met geluiden Het vormt de woorden. Dit helpt bij het opvangen van dingen zoals hoe iemand praat of de stemming, die je met alleen het geluid mist.
- Beeld-audiofusie: Dit deel verbindt wat je ziet met wat je hoort. Het is handig om te beschrijven wat er gebeurt of om dingen als video's ontspannender te maken.
De Fusion Module maakt het mogelijk door al deze informatie samen te voegen en het gemakkelijker te maken deze te verkrijgen.
Uitgangsmodule
De uitvoermodule is als het terugspreekgedeelte. Het zegt dingen op basis van wat het heeft geleerd. Hier is hoe:
- Tekst generatie: Het gebruikt woorden om zinnen te maken, van het beantwoorden van vragen tot het verzinnen van fantastische verhalen.
- Afbeelding genereren: Het maakt foto's die passen bij wat er gebeurt, zoals scènes of dingen.
- Spraakgeneratie: Het praat terug met woorden en klinkt als een natuurlijk persoon, dus het is gemakkelijk te begrijpen.
De Output Module zorgt ervoor dat de antwoorden van AI nauwkeurig zijn en kloppen met wat het hoort.
In een notendop: Multimodale AI voegt gegevens van verschillende plaatsen in de Input-module samen, krijgt het grote beeld in de Fusion-module en zegt dingen die passen bij wat het heeft geleerd in de Output-module. Dit helpt AI ons beter te begrijpen en met ons te praten, ongeacht welke gegevens het krijgt.
# Import the Multimodal AI library
from multimodal_ai import MultimodalAI # Initialize the Multimodal AI model
model = MultimodalAI() # Input data for each modality
text_data = "A cat chasing a ball."
image_data = load_image("cat_chasing_ball.jpg")
audio_data = load_audio("cat_sound.wav") # Process each modality separately
text_embedding = model.process_text(text_data)
image_embedding = model.process_image(image_data)
audio_embedding = model.process_audio(audio_data) # Combine information from different modalities
combined_embedding = model.combine_modalities(text_embedding, image_embedding, audio_embedding) # Generate a response based on the combined information
response = model.generate_response(combined_embedding) # Print the generated response
print(response)
In deze code wordt getoond hoe multimodale AI informatie uit veel verschillende modaliteiten kan verwerken en combineren om een betekenisvol antwoord te genereren. Het is een vereenvoudigd voorbeeld om u te helpen het concept te begrijpen zonder onnodige complexiteit.
De innerlijke werking
Ben je nieuwsgierig naar de innerlijke werking? Laten we eens kijken naar de verschillende segmenten ervan:

Multimodale inputs
Invoer kan tekst, afbeeldingen, audio zijn, of zelfs deze modellen kunnen een combinatie hiervan accepteren. Dit wordt bereikt door elke modaliteit te verwerken via speciale subnetwerken, terwijl interacties daartussen mogelijk zijn.
from multimodal_generative_ai import MultiModalModel # Initialize a Multi-Modal Model
model = MultiModalModel() # Input data in the form of text, image, and audio
text_data = "A beautiful sunset at the beach."
image_data = load_image("beach_sunset.jpg")
audio_data = load_audio("ocean_waves.wav") # Process each modality through dedicated sub-networks
text_embedding = model.process_text(text_data)
image_embedding = model.process_image(image_data)
audio_embedding = model.process_audio(audio_data) # Allow interactions between modalities
output = model.generate_multi_modal_output(text_embedding, image_embedding, audio_embedding)In deze code ontwikkelen we een multimodaal model dat diverse invoer, zoals tekst, afbeeldingen en audio, kan verwerken.
Cross-modaal begrip
Een van de belangrijkste kenmerken is het vermogen van het model om relaties tussen verschillende modaliteiten te begrijpen. Het kan bijvoorbeeld een afbeelding beschrijven op basis van een tekstuele beschrijving of relevante afbeeldingen genereren op basis van een tekstformaat.
from multimodal_generative_ai import CrossModalModel # Initialize a Cross-Modal Model
model = CrossModalModel() # Input textual description and image
description = "A cabin in the snowy woods."
image_data = load_image("snowy_cabin.jpg") # Generating text based on the image
generated_text = model.generate_text_from_image(image_data)
generated_image = model.generate_image_from_text(description)In deze code werken we met een cross-modaal model dat uitblinkt in het begrijpen en genereren van inhoud over verschillende modaliteiten heen. Zoals het een afbeelding kan beschrijven op basis van tekstuele invoer zoals 'Een hut in het besneeuwde bos'. Als alternatief kan het een afbeelding genereren op basis van een tekstuele beschrijving, waardoor het een zeer belangrijk hulpmiddel is voor taken zoals het ondertitelen van afbeeldingen of het maken van inhoud.
Contextueel bewustzijn
Deze AI-systemen blinken uit in het vastleggen van context. Ze begrijpen nuances en kunnen inhoud genereren die contextueel relevant is. Dit contextuele bewustzijn is waardevol bij het genereren van inhoud en bij taken van aanbevelingssystemen.
from multimodal_generative_ai import ContextualModel # Initialize a Contextual Model
model = ContextualModel() # Input contextual data
context = "In a bustling city street, people rush to respective homes." # Generate contextually relevant content
generated_content = model.generate_contextual_content(context)Deze code toont een contextueel model dat is ontworpen om context effectief vast te leggen. Er is input nodig zoals context = "In een drukke stadsstraat haasten mensen zich naar hun respectievelijke huizen." en genereert inhoud die aansluit bij de geboden context. Dit vermogen om contextueel relevante inhoud te produceren is nuttig bij taken zoals het genereren van inhoud en aanbevelingssystemen, waarbij het begrijpen van de context cruciaal is voor het genereren van passende reacties.
Trainingsdata
Deze modellen zouden multimodale trainingsgegevens moeten vereisen en ook de trainingsgegevens zouden zwaar en meer moeten zijn. Dit omvat tekst gecombineerd met afbeeldingen, audio gecombineerd met video en andere combinaties, waardoor het model betekenisvolle cross-modale representaties kan leren.
from multimodal_generative_ai import MultiModalTrainer # Initialize a Multi-Modal Trainer
trainer = MultiModalTrainer() # Load multimodal training data (text paired with images, audio paired with video, etc.)
training_data = load_multi_modal_data() # Train the Multi-Modal Model
model = trainer.train_model(training_data)Dit codevoorbeeld toont een multimodale trainer die de training van een multimodaal model vergemakkelijkt met behulp van diverse trainingsgegevens.
Toepassingen in de echte wereld
Geavanceerde multimodale generatieve AI heeft een grote behoefte en helpt bij veel praktische toepassingen op veel verschillende gebieden. Laten we enkele eenvoudige voorbeelden bekijken van hoe deze technologie kan worden toegepast, samen met codefragmenten en uitleg.
Inhoud genereren
Stel je een systeem voor dat inhoud zoals artikelen, afbeeldingen en zelfs audio kan creëren op basis van een korte beschrijving. Dit kan een game-changer zijn voor de productie van inhoud, reclame en de creatieve industrie. Hier is een codefragment:
from multimodal_generative_ai import ContentGenerator # Initialize the Content Generator
generator = ContentGenerator() # Input a description
description = "A beautiful sunset at the beach." # Generate content
generated_text = generator.generate_text(description)
generated_image = generator.generate_image(description)
generated_audio = generator.generate_audio(description)In dit voorbeeld neemt de Content Generator een beschrijving als invoer en genereert tekst, afbeeldingen en audio-inhoud gerelateerd aan die beschrijving.
Ondersteunende gezondheidszorg
In de gezondheidszorg kan multimodale AI het verleden van patiënten en huidige gegevens analyseren, inclusief tekst, medische beelden en audionotities en een combinatie van deze drie. Het kan helpen bij het diagnosticeren van ziekten, het opstellen van behandelplannen en zelfs het voorspellen van de toekomstige uitkomst van de patiënt door alle relevante gegevens te verzamelen.
from multimodal_generative_ai import HealthcareAssistant # Initialize the Healthcare Assistant
assistant = HealthcareAssistant() # Input a patient record
patient_record = { "text": "Patient complains of persistent cough and fatigue.", "images": ["xray1.jpg", "mri_scan.jpg"], "audio_notes": ["heartbeat.wav", "breathing_pattern.wav"]
} # Analyze the patient record
diagnosis = assistant.diagnose(patient_record)
treatment_plan = assistant.create_treatment_plan(patient_record)
predicted_outcome = assistant.predict_outcome(patient_record)Deze code laat zien hoe de Zorgassistent het dossier van een patiënt kan verwerken, waarbij tekst, afbeeldingen en audio worden gecombineerd om te helpen bij de medische diagnose en behandelplanning.
Interactieve chatbots
Chatbots zijn aantrekkelijker en behulpzamer geworden dankzij multimodale AI-mogelijkheden. Ze kunnen zowel tekst als afbeeldingen begrijpen, waardoor interacties met gebruikers natuurlijker en effectiever worden. Hier is een codefragment:
from multimodal_generative_ai import Chatbot # Initialize the Chatbot
chatbot = Chatbot() # User input
user_message = "Show me images of cute cats." # Engage with the user
response = chatbot.interact(user_message)Deze code laat zien hoe de Chatbot, aangedreven door Multimodale AI, effectief kan reageren op gebruikersinvoer die zowel tekst- als beeldverzoeken omvat.
Inhoud moderatie
Multimodale AI kan de detectie en moderatie van ongepaste inhoud op onlineplatforms verbeteren door zowel tekst- als visuele of auditieve elementen te analyseren. Hier is een codefragment:
from multimodal_generative_ai import ContentModerator # Initialize the Content Moderator
moderator = ContentModerator() # User-generated content
user_content = { "text": "Inappropriate text message.", "image": "inappropriate_image.jpg", "audio": "offensive_audio.wav"
} # Moderate the user-generated content
moderated = moderator.moderate_content(user_content)In dit voorbeeld kan de Content Moderator door gebruikers gegenereerde inhoud analyseren, waardoor een veiligere onlineomgeving wordt gegarandeerd door rekening te houden met alle verschillende modaliteiten.
Deze praktische voorbeelden illustreren de praktische toepassingen van geavanceerde multimodale generatieve AI. Deze technologie heeft het potentieel in een groot aantal bedrijfstakken door het begrijpen en genereren van inhoud over verschillende soorten gegevens heen.
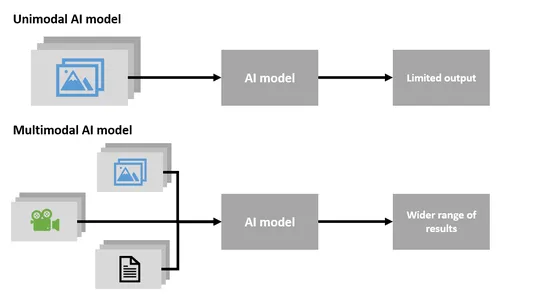
Single-modaal versus multi-modaal

Multimodale AI
- Multi-modale AI is een zeer unieke en belangrijke technologie die verschillende soorten gegevens tegelijkertijd kan verwerken, waaronder tekst, afbeeldingen en audio.
- Het blinkt uit in het begrijpen en genereren van inhoud die deze verschillende gegevenstypen combineert.
- Multi-modale AI kan tekst genereren op basis van afbeeldingen of afbeeldingen maken op basis van tekstbeschrijvingen, waardoor deze zeer aanpasbaar is.
- Deze technologie is in staat een breed scala aan informatie te verwerken en te begrijpen.
Single-modale AI
- Single-Modal AI is gespecialiseerd in het werken met slechts één type data, zoals tekst of afbeeldingen.
- Het kan niet meerdere gegevenstypen tegelijkertijd verwerken of inhoud genereren die verschillende modaliteiten combineert.
- Single-Modal AI is beperkt tot het specifieke datatype en mist het aanpassingsvermogen van Multi-Modal AI.
Samenvattend kan Multi-Modal AI met meerdere soorten gegevens tegelijk werken, waardoor het veelzijdiger wordt en in staat is om inhoud op verschillende manieren te begrijpen en te genereren. Single-Modal AI daarentegen is gespecialiseerd in één datatype en kan de diversiteit van Multi-Modal AI niet aan.
Ethische overwegingen
Privacybezorgdheden
- Zorg voor een juiste omgang met gevoelige gebruikersgegevens, vooral in toepassingen in de gezondheidszorg.
- Implementeer robuuste technieken voor gegevensversleuteling en anonimisering om de privacy van gebruikers te beschermen.
Vooringenomenheid en eerlijkheid
- Pak mogelijke vooroordelen in de trainingsgegevens aan om oneerlijke resultaten te voorkomen.
- Controleer en update het model regelmatig om vooroordelen bij het genereren van inhoud te minimaliseren.
Inhoud moderatie
- Implementeer effectieve inhoudsmoderatie om ongepaste of schadelijke inhoud die door AI wordt gegenereerd, eruit te filteren.
- Stel duidelijke richtlijnen en beleid op zodat gebruikers zich aan ethische normen kunnen houden.
Transparantie
- Maak door AI gegenereerde inhoud onderscheidbaar van door mensen gegenereerde inhoud om de transparantie te behouden.
- Geef gebruikers duidelijke informatie over de betrokkenheid van AI bij het creëren van content.
Verantwoording
- Definieer de verantwoordelijkheden voor het gebruik en de inzet van multimodale AI, en zorg ervoor dat er verantwoording wordt afgelegd over de acties ervan.
- Breng mechanismen tot stand voor het aanpakken van problemen of fouten die kunnen voortkomen uit door AI gegenereerde inhoud.
Informed Consent
- Vraag toestemming van gebruikers bij het verzamelen en gebruiken van hun gegevens voor training en verbetering van het AI-model.
- Communiceer duidelijk hoe gebruikersgegevens zullen worden gebruikt om vertrouwen bij gebruikers op te bouwen.
Toegankelijkheid
- Zorg ervoor dat door AI gegenereerde inhoud toegankelijk is voor gebruikers met een handicap door te voldoen aan de toegankelijkheidsnormen.
- Implementeer functies zoals schermlezers voor visueel gehandicapte gebruikers.
Continue monitoring
- Controleer regelmatig door AI gegenereerde inhoud op naleving van ethische richtlijnen.
- Pas het AI-model aan en verfijn het om het af te stemmen op de evoluerende ethische normen.
Deze ethische overwegingen zijn essentieel voor de verantwoorde ontwikkeling en inzet van geavanceerde multimodale generatieve AI, waarbij wordt gegarandeerd dat de samenleving hiervan profiteert en tegelijkertijd de ethische normen en gebruikersrechten worden gehandhaafd.
Conclusie
Terwijl we door het complexe landschap van moderne technologie navigeren, lonkt de horizon met een fascinerende ontwikkeling: geavanceerde multimodale generatieve AI. Deze baanbrekende technologie belooft een revolutie teweeg te brengen in de manier waarop computers inhoud genereren en onze veelzijdige wereld begrijpen. Stel je een digitale assistent voor die naadloos werkt met tekst, afbeeldingen en geluiden, communiceert in meerdere talen en innovatieve inhoud maakt. Ik hoop dat dit artikel je meeneemt op een reis door de fijne kneepjes van geavanceerde multimodale generatieve AI, waarbij we de praktische toepassingen ervan onderzoeken, codefragmenten voor de duidelijkheid, en het potentieel ervan om onze digitale interacties opnieuw vorm te geven.
“Multimodale AI is de brug die computers helpt tekst, afbeeldingen en audio te begrijpen en te verwerken, wat een revolutie teweegbrengt in de manier waarop we met machines omgaan.”
Key Takeaways
- Geavanceerde multimodale generatieve AI is een game-changer in technologie, waardoor computers inhoud in tekst, afbeeldingen en audio kunnen begrijpen en genereren.
- De drie kernmodules, Input, Fusion en Output, werken naadloos samen om informatie effectief te verwerken en te genereren.
- Multimodale AI kan toepassingen vinden bij het genereren van content, gezondheidszorghulp, interactieve chatbots en contentmoderatie, waardoor het veelzijdig en praktisch is.
- Cross-modaal begrip, contextueel bewustzijn en uitgebreide trainingsgegevens zijn cruciale aspecten die de mogelijkheden ervan vergroten.
- Multimodale AI heeft het potentieel om een revolutie teweeg te brengen in industrieën door een nieuwe manier van interactie met machines aan te bieden en op creatievere wijze inhoud te genereren.
- Het vermogen om meerdere datamodi te combineren verbetert het aanpassingsvermogen en de bruikbaarheid in de echte wereld.
Veelgestelde Vragen / FAQ
A. Geavanceerde multimodale generatieve AI onderscheidt zich door zijn vermogen om inhoud te begrijpen en te genereren met behulp van verschillende gegevenstypen, zoals tekst, afbeeldingen en audio, terwijl traditionele AI zich vaak op één gegevenstype richt.
A. Geavanceerde multimodale generatieve AI onderscheidt zich door zijn vermogen om inhoud te begrijpen en te genereren met behulp van diverse datatypen, waaronder tekst, afbeeldingen en audio, terwijl traditionele AI zich doorgaans specialiseert in één enkel datatype.
A. Multimodale AI werkt bedreven in meerdere talen door tekst in de gewenste taal te verwerken en te begrijpen.
A. Ja, multimodale AI is in staat creatieve inhoud te produceren op basis van tekstuele beschrijvingen of aanwijzingen, die tekst, afbeeldingen en audio omvatten.
A. Multimodale AI biedt voordelen op een breed scala aan domeinen, waaronder het genereren van inhoud, de gezondheidszorg, chatbots en het modereren van inhoud, dankzij de vaardigheid in het begrijpen en genereren van inhoud in verschillende datamodi.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/10/exploring-the-advanced-multi-modal-generative-ai/

